
Resource Optimization for Multi-Unmanned Aerial Vehicle Formation Communication Based on an Improved Deep Q-Network


Abstract
1. Introduction
- Resource optimization based on the three-dimensional distribution of multiple UAVs, which is different from a random [28] or flat distribution [29] of UAVs, as used in the previous study. The multi-UAVs were located successively at edges or the eight vertices of a cube and kept a cube formation during their flight;
- In order to achieve joint power and channel resource optimization for the UAV formation, a DQN was used. Moreover, a CNN was used after the state data were preprocessed in the training process;
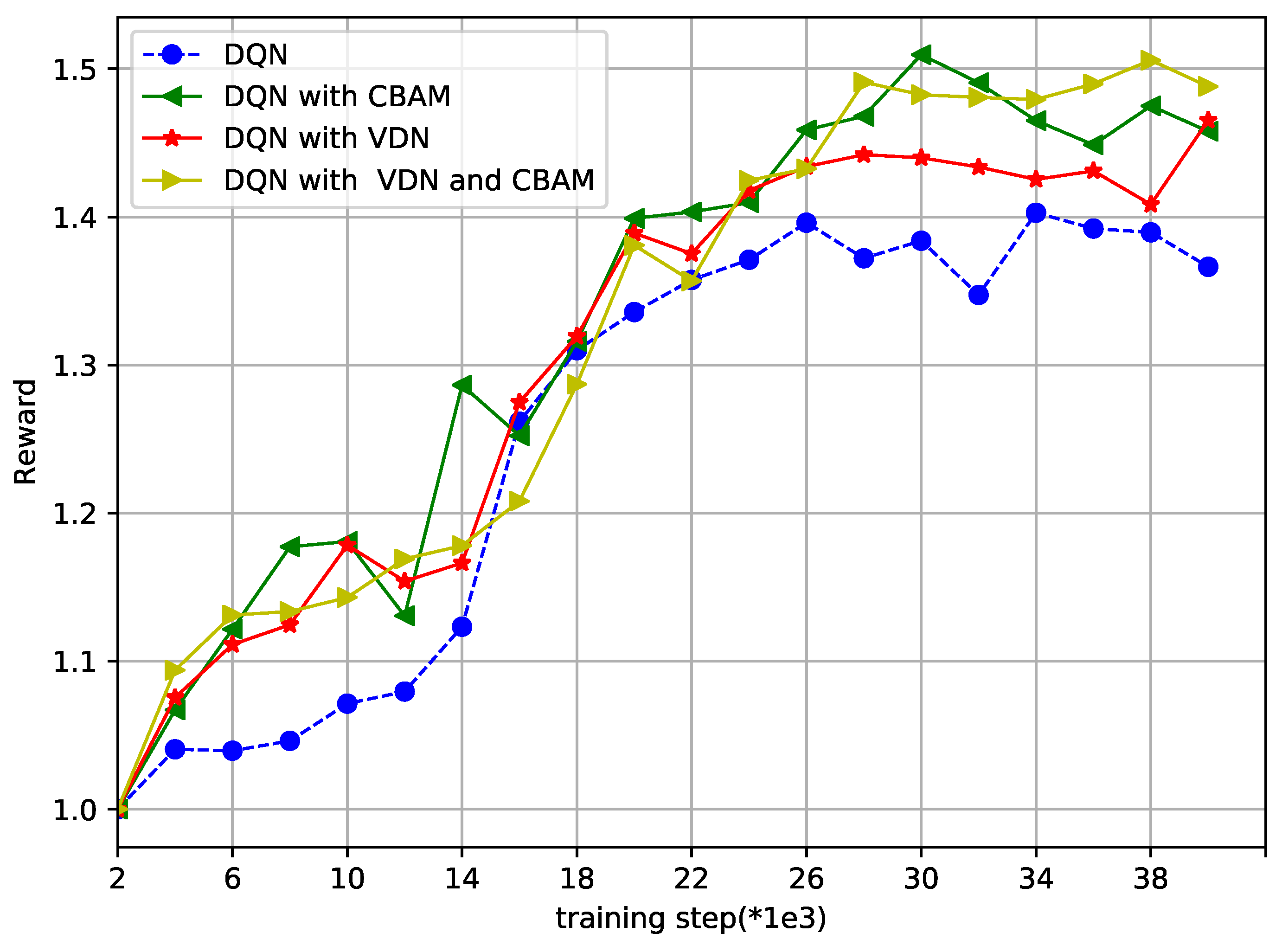
- Based on a DQN, the convolutional block attention module (CBAM) and value decomposition network (VDN) modules were introduced to further realize system performance improvement. The CBAM worked at the CNN layer to capture correlations of the feature map along both the channel and spatial aspects, and the VDN worked as the reward mechanism. The experimental results proved the effectiveness of the introduction of the CBAM and VDN.
2. System Model
2.1. Scenario Setting
2.2. Modeling the Line of Sight Probability
2.3. The Problem Optimization Objective
3. The Proposed Method
3.1. Introduction of the DQN
3.2. The DQN with the CBAM
3.3. The DQN with the VDN
3.4. Training and Validation
| Algorithm 1 The improved DQN for multi-UAV formation resource optimization with the CBAM and VDN (training stage) |
|
4. Simulation
5. Conclusions
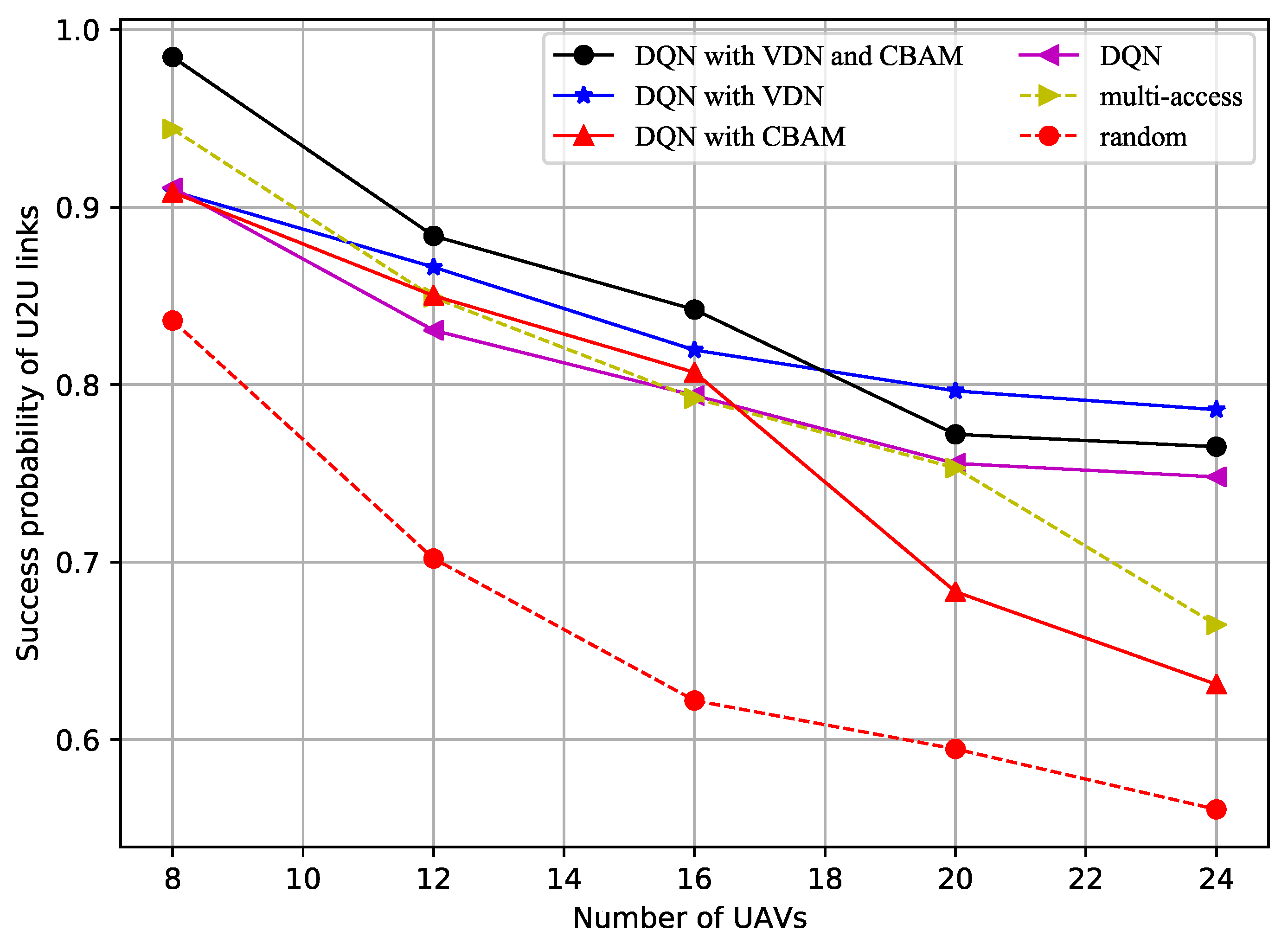
- This manuscript focuses on the realization of joint power and spectrum resource optimization using a DQN mechanism for a multi-UAV formation communication network, in which the UAVs are located in 3D forms when the multi-UAVs are on a mission. The objective was to maximize the transmission rate and increase the successful data transfer probability simultaneously.
- The main idea was that the U2U links were treated as agents and the CBAM and VDN were further introduced based on the DQN. Compared to the random and multichannel access methods, the DQN method slightly improved system performance, and the introduction of the CBAM and VDN further improved the data transfer rate of the U2B links and the successful data transfer probability of the U2B links.
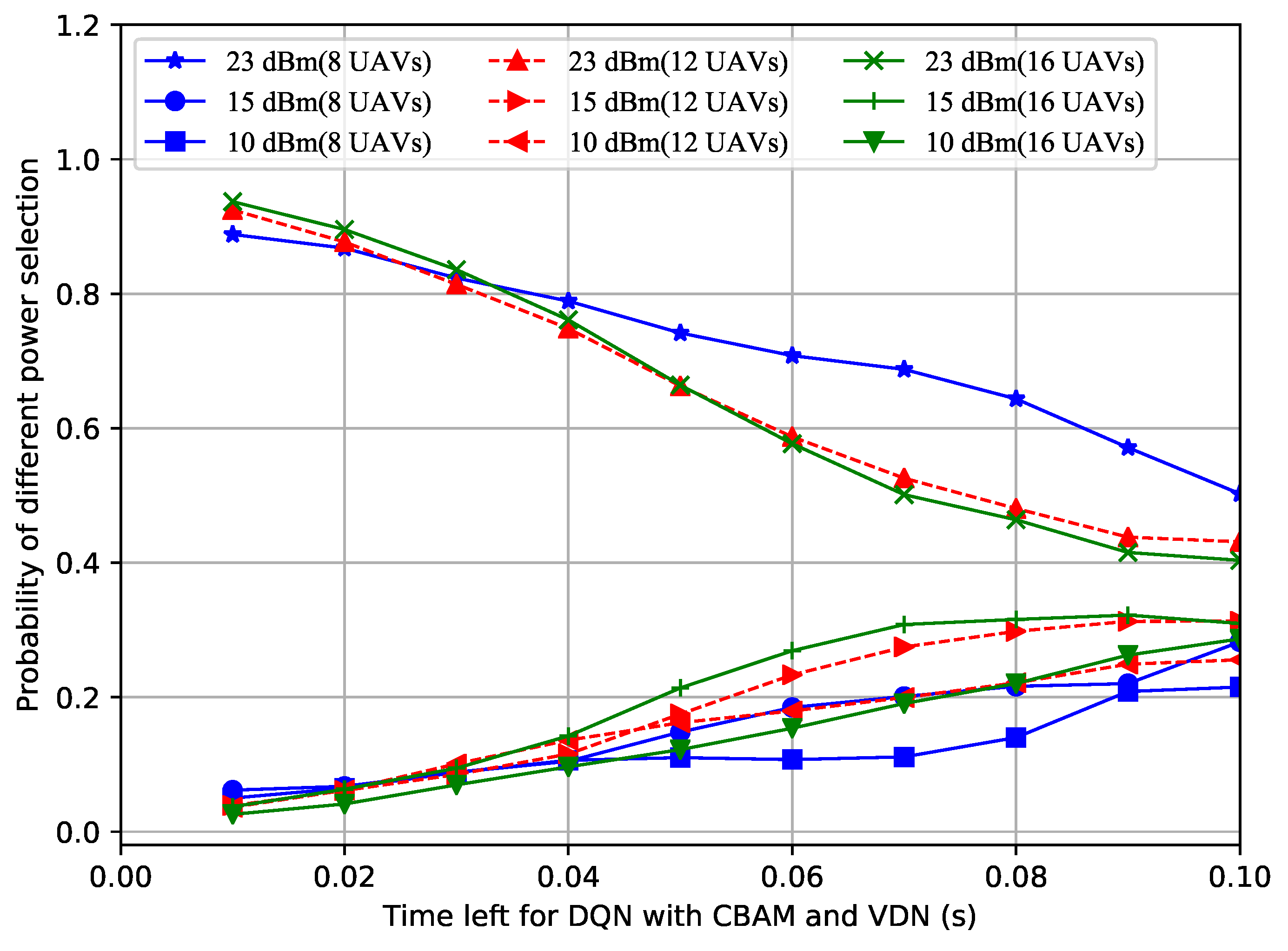
- The reason for the performance improvement is that the UAVs could intelligently choose the appropriate power and frequency based on the remaining time and the number of UAVs. The authors drew the conclusion that the superiority of the proposed method became more and more obvious as the number of UAVs in the formation increased.
- This model can be used in agricultural or military applications, such as disaster relief, environmental detection, remote situational awareness, deception and jamming. Even if a few UAVs break down, the overall capability of the UAVs will not be affected. However, the speed is low and the mobility and self-defense ability is poor. If the number of UAVs is small, they are easy to detect and intercept, and the different flight altitudes will affect the communication quality between the UAVs and the ground base station. In this work, the formation of the UAVs remained the same during the execution of tasks, and future work could focus on the situation with changing formations.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| DQN | deep Q-network; |
| UAVs | unmanned aerial vehicles; |
| U2B | UAV-to-base station; |
| U2U | UAV-to-UAV; |
| CBAM | convolutional block attention module; |
| VDN | value decomposition network; |
| DL | deep learning; |
| RL | reinforcement learning; |
| ML | machine learning; |
| DRL | deep reinforcement learning; |
| CNN | convolutional neural network; |
| BS | base station; |
| LoS | line-of-sight; |
| AWGN | additive white Gaussian noise; |
| NLoS | non-line-of-sight; |
| ITU | International Telecommunication Union; |
| SINR | signal-to-interference-plus-noise ratio; |
| CMDP | constrained Markov decision process; |
| NN | neural network; |
| ATG | air-to-ground. |
References
- Gupta, L.; Jain, R.; Vaszkun, G. Survey of Important Issues in UAV Communication Networks. IEEE Commun. Surv. Tutor. 2016, 18, 1123–1152. [Google Scholar] [CrossRef]
- Richard, A.; Abiodunmusa, A.; Bernard, E.; Jerry, A. Unmanned Aerial Vehicle (UAV) applications in coastal zone management. Environ. Monit. Assess. 2021, 193, 1–12. [Google Scholar]
- Fuhui, Z.; Rose, Q.H.; Zan, L.; Wang, Y. Mobile Edge Computing in Unmanned Aerial Vehicle Networks. IEEE Wirel. Commun. 2020, 27, 140–146. [Google Scholar]
- Wang, H.; Zhao, H.; Zhang, J. Survey on Unmanned Aerial Vehicle Networks: A Cyber Physical System Perspective. IEEE Commun. Surv. Tutor. 2020, 22, 1027–1070. [Google Scholar]
- binti Burhanuddin, L.A.; Liu, X.; Deng, Y.; Challita, U.; Zahemszky, A. QoE Optimization for Live Video Streaming in UAV-to-UAV Communications via Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2022, 71, 5358–5370. [Google Scholar] [CrossRef]
- Xu, H.; Huang, W.; Zhou, Y.; Yang, D.; Li, M.; Han, Z. Edge Computing Resource Allocation for Unmanned Aerial Vehicle Assisted Mobile Network with Blockchain Applications. IEEE Trans. Wirel. Commun. 2021, 20, 3107–3121. [Google Scholar]
- Avellar, G.S.; Pereira, G.A.; Pimenta, L.C.; Iscold, P. Multi-UAV routing for area coverage and remote sensing with minimum time. Sensors 2015, 15, 27783–27803. [Google Scholar] [CrossRef]
- Verykokou, S.; Ioannidis, C.; Athanasiou, G.; Doulamis, N.; Amditis, A. 3D reconstruction of disaster scenes for urban search and rescue. Multimed. Tools Appl. 2018, 77, 9691–9717. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, Z.; Bian, K.; Song, L.; Han, Z. Real-time profiling of fine-grained air quality index distribution using UAV sensing. IEEE Internet Things J. 2018, 5, 186–198. [Google Scholar] [CrossRef]
- Belkacem, K.; Munawar, K.; Muhammad, S.S. Distributed cooperative control of autonomous multi-agent UAV systems using smooth control. J. Syst. Eng. Electron. 2020, 31, 1297–1307. [Google Scholar]
- Chai, S.; Lau, V.K.N. Multi-UAV Trajectory and Power Optimization for Cached UAV Wireless Networks With Energy and Content Recharging-Demand Driven Deep Learning Approach. IEEE J. Sel. Areas Commun. 2021, 39, 3208–3224. [Google Scholar]
- Ding, R.; Chen, J.; Wu, W.; Liu, J.; Gao, F.; Shen, X. Packet Routing in Dynamic Multi-Hop UAV Relay Network: A Multi-Agent Learning Approach. IEEE Trans. Veh. Technol. 2022, 71, 10059–10072. [Google Scholar]
- Taehoon, Y.; Sangmin, L.; Kyeonghyun, Y.; Hwangnam, K. Reinforcement Learning Based Topology Control for UAV Networks. Sensors 2023, 23, 921. [Google Scholar]
- Qian, L.P.; Zhang, H.; Wang, Q.; Wu, Y.; Lin, B. Joint multi-domain resource allocation and trajectory optimization in UAV-assisted maritime IoT networks. IEEE Internet Things J. 2023, 10, 539–552. [Google Scholar] [CrossRef]
- Dai, X.; Duo, B.; Yuan, X.; Tang, W. Energy-efficient UAV communications: A generalized propulsion energy consumption model. IEEE Wirel. Commun. Lett. 2022, 11, 2150–2154. [Google Scholar] [CrossRef]
- Kai, C.; Li, H.; Xu, L.; Li, Y.; Jiang, T. Joint subcarrier assignment with power allocation for sum rate maximization of D2D communications in wireless cellular networks. IEEE Trans. Veh. Technol. 2019, 68, 4748–4759. [Google Scholar] [CrossRef]
- Zhao, W.T.; Wang, S.W. Resource allocation for device-to-device communication underlaying cellular networks: An alternating optimization method. IEEE Commun. Lett. 2015, 19, 1398–1401. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, H.; Di, B.; Song, L. Cellular UAV-to-X Communications: Design and Optimization for Multi-UAV Networks. IEEE Trans. Wirel. Commun. 2019, 18, 1346–1359. [Google Scholar]
- Gitae, P.; Kisong, L. Optimization of the Trajectory, Transmit Power, and Power Splitting Ratio for Maximizing the Available Energy of a UAV-Aided SWIPT System. Sensors 2022, 22, 9081. [Google Scholar]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A gated recurrent convolutional neural network for robust spoofing detection. IEEE-ACM Trans. Audio Speech Lang. Process. 2019, 27, 1985–1999. [Google Scholar] [CrossRef]
- Shao, J.T.; Zheng, J.J.; Zhang, B. Deep convolutional neural networks for thyroid tumor grading using Ultrasound B-mode Images. J. Acoust. Soc. Am. 2020, 148, 1529–1535. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Li, G.; Guo, S.; Zhang, T.; Li, H. Secure decentralized image classification with multiparty homomorphic encryption. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Liu, W.; Kou, K.; Miao, J.; Cai, Z. Quaternion scalar and vector norm decomposition: Quaternion PCA for color face recognition. IEEE Trans. Image Process. 2023, 32, 446–457. [Google Scholar] [CrossRef]
- Jie, H.; Li, S.; Samuel, A.; Gang, S.; Wu, E. Squeeze-and-Excitation Networks. Available online: https://arxiv.org/abs/1709.01507 (accessed on 5 April 2018).
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access. In Proceedings of the International Conference on Computing, Networking and Communications, Silicon Valley, CA, USA, 26–29 January 2017. [Google Scholar]
- Jie, L.; Sai, L.; Abdul, H.S. Joint Channel and Power Assignment for UAV Swarm Communication based on Multi-agent DRL. IEICE Trans. Commun. 2022, E105-B, 1249–1257. [Google Scholar]
- Jie, L.; Xiaoyu, D.; Sai, L. DQN-based decentralized multi-agent JSAP resource allocation for UAV swarm communication. J. Syst. Eng. Electron. 2023, 34. [Google Scholar]
- Al-Hourani, A.; Kandeepan, S.; Lardner, S. Optimal LAP Altitude for Maximum Coverage. IEEE Wirel. Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef]
- Athukoralage, D.; Guvenc, I.; Saad, W.; Bennis, M. Regret Based Learning for UAV Assisted LTE-U/WiFi Public Safety Networks. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- Al-Hourani, A.; Kandeepan, S.; Jamalipour, A. Modeling air-to-ground path loss for low altitude platforms in urban environments. In Proceedings of the IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014. [Google Scholar]
- Propagation Data and Prediction Methods Required for the Design of Terrestrial Broadband Radio Access Systems Operating in a Frequency Range from 3 to 60 GHz. Geneva, Switzerland, P.1410-5, P Series. Available online: https://www.itu.int/rec/R-REC-P.1410-5-201202-I/en (accessed on 23 February 2012).
- Enhanced LTE Support for Aerial Vehicles, Release 15. Release 15, Document 3GPP TS 36.777. Available online: https://www.3gpp.org/ftp/Specs/archive/36_series/36.777/ (accessed on 20 December 2017).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Number of UAVs (training) | 8 |
| Number of uplink | 8 |
| Number of UAVs (testing) | 8/12/16/20/24 |
| Carrier frequency | 1 GHz |
| Noise variance | −96 dBm |
| U2U link transmitter power | 23 dBm/15 dBm/10 dBm |
| U2B link transmitter power | 23 dBm |
| U2B channel parameter | 20 |
| U2B channel parameter | 1 |
| U2B channel parameter | 2 |
| U2B channel parameter | 0.135 |
| U2B channel parameter | 12 |
| U2U channel power gains factor h | −31.5 dB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Li, S.; Xue, C. Resource Optimization for Multi-Unmanned Aerial Vehicle Formation Communication Based on an Improved Deep Q-Network. Sensors 2023, 23, 2667. https://doi.org/10.3390/s23052667
Li J, Li S, Xue C. Resource Optimization for Multi-Unmanned Aerial Vehicle Formation Communication Based on an Improved Deep Q-Network. Sensors. 2023; 23(5):2667. https://doi.org/10.3390/s23052667
Chicago/Turabian StyleLi, Jie, Sai Li, and Chenyan Xue. 2023. "Resource Optimization for Multi-Unmanned Aerial Vehicle Formation Communication Based on an Improved Deep Q-Network" Sensors 23, no. 5: 2667. https://doi.org/10.3390/s23052667
APA StyleLi, J., Li, S., & Xue, C. (2023). Resource Optimization for Multi-Unmanned Aerial Vehicle Formation Communication Based on an Improved Deep Q-Network. Sensors, 23(5), 2667. https://doi.org/10.3390/s23052667