



An IoT Enable Anomaly Detection System for Smart City Surveillance




Abstract
1. Introduction
2. Related Work
2.1. Hand Crafted
2.2. Deep Learning
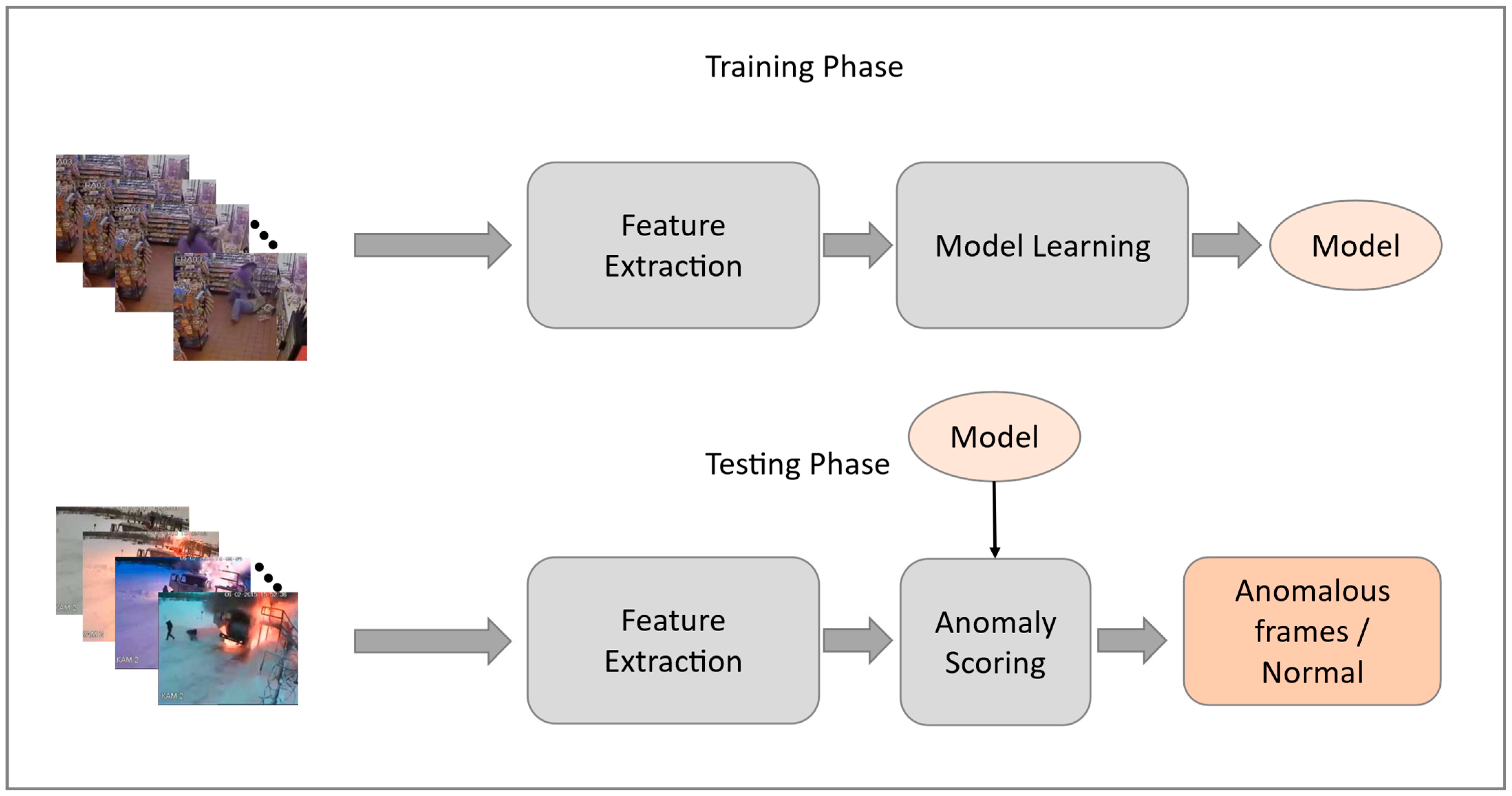
3. The Proposed Method
3.1. Feature Extraction
3.2. Autoencoder
3.3. Echo State Network
3.4. Architecture
4. Results
4.1. Datasets
4.2. Comparative Analysis with Baselines
4.3. Ablation Study
4.4. Time Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Skogan, W.G. The future of CCTV. Criminol. Pub. Pol’y 2019, 18, 161. [Google Scholar]
- Husman, M.A.; Albattah, W.; Abidin, Z.Z.; Mustafah, Y.M.; Kadir, K.; Habib, S.; Islam, M.; Khan, S. Unmanned Aerial Vehicles for Crowd Monitoring and Analysis. Electronics 2021, 10, 2974. [Google Scholar]
- Chu, W.; Xue, H.; Yao, C.; Cai, D. Sparse coding guided spatiotemporal feature learning for abnormal event detection in large videos. IEEE Trans. Multimed. 2018, 21, 246–255. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Haq, I.U.; Muhammad, K.; Sajjad, M.; Baik, S.W. CNN features with bi-directional LSTM for real-time anomaly detection in surveillance networks. Multimed. Tools Appl. 2021, 80, 16979–16995. [Google Scholar] [CrossRef]
- Zhao, B.; Fei-Fei, L.; Xing, E.P. Online detection of unusual events in videos via dynamic sparse coding. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR 11), Colorado Springs, CO, USA, 20-25 June 2011; pp. 3313–3320. [Google Scholar]
- Rezaee, K.; Rezakhani, S.M.; Khosravi, M.R.; Moghimi, M.K. A survey on deep learning-based real-time crowd anomaly detection for secure distributed video surveillance. Pers. Ubiquitous Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Ren, J.; Xia, F.; Liu, Y.; Lee, I. Deep Video Anomaly Detection: Opportunities and Challenges; IEEE: Piscataway, NJ, USA, 2021; pp. 959–966. [Google Scholar]
- Ullah, W.; Hussain, T.; Khan, Z.A.; Haroon, U.; Baik, S.W. Intelligent dual stream CNN and echo state network for anomaly detection. Knowl. Based Syst. 2022, 253, 109456. [Google Scholar] [CrossRef]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection–a new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Michau, G.; Fink, O. Unsupervised transfer learning for anomaly detection: Application to complementary operating condition transfer. Knowl. Based Syst. 2021, 216, 106816. [Google Scholar] [CrossRef]
- Nayak, R.; Pati, U.C.; Das, S.K. A comprehensive review on deep learning-based methods for video anomaly detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Ramachandra, B.; Jones, M.; Vatsavai, R.R. A survey of single-scene video anomaly detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2293–2312. [Google Scholar]
- Kiran, B.R.; Thomas, D.M.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Muhammad, K.; Heidari, A.A.; Del Ser, J.; Baik, S.W.; De Albuquerque, V.H.C. Artificial Intelligence of Things-assisted two-stream neural network for anomaly detection in surveillance Big Video Data. Future Gener. Comput. Syst. 2022, 129, 286–297. [Google Scholar] [CrossRef]
- Wu, S.; Moore, B.E.; Shah, M. Chaotic invariants of Lagrangian particle trajectories for anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13-18 June 2010; pp. 2054–2060. [Google Scholar]
- Mohammadi, B.; Fathy, M.; Sabokrou, M. Image/video deep anomaly detection: A survey. arXiv Prepr. 2021, arXiv:2103.01739. [Google Scholar]
- Park, H.; Noh, J.; Ham, B. Learning memory-guided normality for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, online, 14–19 June 2020; pp. 14372–14381. [Google Scholar]
- Albattah, W.; Habib, S.; Alsharekh, M.F.; Islam, M.; Albahli, S.; Dewi, D.A. An Overview of the Current Challenges, Trends, and Protocols in the Field of Vehicular Communication. Electronics 2022, 11, 3581. [Google Scholar] [CrossRef]
- Albattah, W.; Kaka Khel, M.H.; Habib, S.; Islam, M.; Khan, S.; Abdul Kadir, K. Hajj Crowd Management Using CNN-Based Approach. Comput. Mater. Contin. 2020, 66, 2183–2197. [Google Scholar] [CrossRef]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 18–32. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos; IEEE: Piscataway, NJ, USA, 2018; pp. 6479–6488. [Google Scholar]
- Huang, C.; Li, Y.; Nevatia, R. Multiple target tracking by learning-based hierarchical association of detection responses. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 898–910. [Google Scholar] [CrossRef]
- Bera, A.; Kim, S.; Manocha, D. Realtime anomaly detection using trajectory-level crowd behavior learning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 50–57. [Google Scholar]
- Singh, D.; Mohan, C.K. Graph formulation of video activities for abnormal activity recognition. Pattern Recognit. 2017, 65, 265–272. [Google Scholar] [CrossRef]
- Cheng, K.-W.; Chen, Y.-T.; Fang, W.-H. Gaussian process regression-based video anomaly detection and localization with hierarchical feature representation. IEEE Trans. Image Process. 2015, 24, 5288–5301. [Google Scholar] [CrossRef]
- Kaltsa, V.; Briassouli, A.; Kompatsiaris, I.; Hadjileontiadis, L.J.; Strintzis, M.G. Swarm intelligence for detecting interesting events in crowded environments. IEEE Trans. Image Process. 2015, 24, 2153–2166. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, H.; Zhang, L.; Ruan, X. Combining motion and appearance cues for anomaly detection. Pattern Recognit. 2016, 51, 443–452. [Google Scholar] [CrossRef]
- Colque, R.V.H.M.; Caetano, C.; de Andrade, M.T.L.; Schwartz, W.R. Histograms of optical flow orientation and magnitude and entropy to detect anomalous events in videos. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 673–682. [Google Scholar] [CrossRef]
- Alsharekh, M.F.; Habib, S.; Dewi, D.A.; Albattah, W.; Islam, M.; Albahli, S. Improving the Efficiency of Multistep Short-Term Electricity Load Forecasting via R-CNN with ML-LSTM. Sensors 2022, 22, 6913. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Chen, Y.; Luo, W.; Wu, H.; Zhang, C. Discriminative clip mining for video anomaly detection. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25-28 October 2020; pp. 2121–2125. [Google Scholar]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. arXiv Prepr. 2019, arXiv:1907.10211. [Google Scholar]
- Ullah, A.; Muhammad, K.; Haydarov, K.; Haq, I.U.; Lee, M.; Baik, S.W. One-shot learning for surveillance anomaly recognition using siamese 3D CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Berroukham, A.; Housni, K.; Lahraichi, M.; Boulfrifi, I. Deep learning-based methods for anomaly detection in video surveillance: A review. Bull. Electr. Eng. Inform. 2023, 12, 314–327. [Google Scholar] [CrossRef]
- Shikalgar, S.; Yadav, R.K.; Mahalle, P.N. An AI Federated System for Anomalies Detection in Videos using Convolution Neural Network Mechanism. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 218–227. [Google Scholar]
- Taghinezhad, N.; Yazdi, M. A new unsupervised video anomaly detection using multi-scale feature memorization and multipath temporal information prediction. IEEE Access 2023, 11, 9295–9310. [Google Scholar] [CrossRef]
- Kamoona, A.M.; Gostar, A.K.; Bab-Hadiashar, A.; Hoseinnezhad, R. Multiple instance-based video anomaly detection using deep temporal encoding–decoding. Expert Syst. Appl. 2023, 214, 119079. [Google Scholar] [CrossRef]
- Chen, H.; Mei, X.; Ma, Z.; Wu, X.; Wei, Y. Spatial–temporal graph attention network for video anomaly detection. Image Vis. Comput. 2023, 131, 104629. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Ullah, F.U.M.; Gupta, S.K.; Lee, M.Y.; Baik, S.W. Randomly initialized CNN with densely connected stacked autoencoder for efficient fire detection. Eng. Appl. Artif. Intell. 2022, 116, 105403. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Agarwal, M.; Khan, Z.A.; Gupta, S.K.; Baik, S.W. Optimized dual fire attention network and medium-scale fire classification benchmark. IEEE Trans. Image Process. 2022, 31, 6331–6343. [Google Scholar] [CrossRef]
- Khan, K.; Khan, R.U.; Albattah, W.; Nayab, D.; Qamar, A.M.; Habib, S.; Islam, M. Crowd Counting Using End-to-End Semantic Image Segmentation. Electronics 2021, 10, 1293. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Khan, Z.A.; Baik, S.W. An efficient anomaly recognition framework using an attention residual LSTM in surveillance videos. Sensors 2021, 21, 2811. [Google Scholar] [CrossRef] [PubMed]
- Khan, Z.A.; Hussain, T.; Ullah, A.; Rho, S.; Lee, M.; Baik, S.W. Towards efficient electricity forecasting in residential and commercial buildings: A novel hybrid CNN with a LSTM-AE based framework. Sensors 2020, 20, 1399. [Google Scholar] [CrossRef] [PubMed]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A novel CNN-GRU-based hybrid approach for short-term residential load forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Khan, Z.A.; Ullah, A.; Ullah, W.; Rho, S.; Lee, M.; Baik, S.W. Electrical energy prediction in residential buildings for short-term horizons using hybrid deep learning strategy. Appl. Sci. 2020, 10, 8634. [Google Scholar] [CrossRef]
- Khan, Z.A.; Ullah, A.; Haq, I.U.; Hamdy, M.; Maurod, G.M.; Muhammad, K.; Hijji, M.; Baik, S.W. Efficient short-term electricity load forecasting for effective energy management. Sustain. Energy Technol. Assess. 2022, 53, 102337. [Google Scholar] [CrossRef]
- Muhammad, K.; Ullah, H.; Khan, Z.A.; Saudagar, A.K.J.; AlTameem, A.; AlKhathami, M.; Khan, M.B.; Abul Hasanat, M.H.; Mahmood Malik, K.; Hijji, M. WEENet: An intelligent system for diagnosing COVID-19 and lung cancer in IoMT environments. Front. Oncol. 2022, 11, 5410. [Google Scholar] [CrossRef]
- Yar, H.; Imran, A.S.; Khan, Z.A.; Sajjad, M.; Kastrati, Z. Towards smart home automation using IoT-enabled edge-computing paradigm. Sensors 2021, 21, 4932. [Google Scholar] [CrossRef]
- Huang, L.; Liu, G.; Wang, Y.; Yuan, H.; Chen, T. Fire detection in video surveillances using convolutional neural networks and wavelet transform. Eng. Appl. Artif. Intell. 2022, 110, 104737. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Khan, Z.A.; Koundal, D.; Lee, M.Y.; Baik, S.W. Vision sensor-based real-time fire detection in resource-constrained IoT environments. Comput. Intell. Neurosci. 2021, 2021, 5195508. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Gallicchio, C.; Micheli, A.; Pedrelli, L. Deep reservoir computing: A critical experimental analysis. Neurocomputing 2017, 268, 87–99. [Google Scholar] [CrossRef]
- Jaeger, H. The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn Ger. Ger. Natl. Res. Cent. Inf. Technol. GMD Tech. Rep. 2001, 148, 13. [Google Scholar]
- Khan, Z.A.; Hussain, T.; Baik, S.W. Boosting energy harvesting via deep learning-based renewable power generation prediction. J. King Saud Univ. Sci. 2022, 34, 101815. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Haq, I.U.; Ullah, F.U.M.; Baik, S.W. Towards efficient and effective renewable energy prediction via deep learning. Energy Rep. 2022, 8, 10230–10243. [Google Scholar] [CrossRef]
- Zhong, J.-X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1237–1246. [Google Scholar]
- Habib, S.; Hussain, A.; Islam, M.; Khan, S.; Albattah, W. Towards Efficient Detection and Crowd Management for Law Enforcing Agencies. In Proceedings of the IEEE 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 62–68. [Google Scholar]
- Bermejo Nievas, E.; Deniz Suarez, O.; Bueno García, G.; Sukthankar, R. Violence detection in video using computer vision techniques. In Computer Analysis of Images and Patterns: 14th International Conference, CAIP 2011, Seville, Spain, 2–31 August 2011, Proceedings, Part II 14; Springer: Berlin/Heidelberg, Germany, 2011; pp. 332–339. [Google Scholar]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar]
- Habib, S.; Hussain, A.; Albattah, W.; Islam, M.; Khan, S.; Khan, R.U.; Khan, K. Abnormal Activity Recognition from Surveillance Videos Using Convolutional Neural Network. Sensors 2021, 21, 8291. [Google Scholar] [CrossRef]
- Luo, W.; Liu, W.; Gao, S. A revisit of sparse coding based anomaly detection in stacked RNN framework. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 341–349. [Google Scholar]
- Markovitz, A.; Sharir, G.; Friedman, I.; Zelnik-Manor, L.; Avidan, S. Graph embedded pose clustering for anomaly detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10539–10547. [Google Scholar]
- Habib, S.; Alyahya, S.; Islam, M.; Alnajim, A.M.; Alabdulatif, A.; Alabdulatif, A. Design and Implementation: An IoT-Framework-Based Automated Wastewater Irrigation System. Electronics 2023, 12, 28. [Google Scholar] [CrossRef]
- Yang, X.; Wang, Z.; Wu, K.; Xie, Z.; Hou, J. Deep social force network for anomaly event detection. IET Image Process. 2021, 15, 3441–3453. [Google Scholar] [CrossRef]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 FPS in MATLAB. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Astrid, M.; Lee, S.-I. Claws: Clustering assisted weakly supervised learning with normalcy suppression for anomalous event detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXII 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 358–376. [Google Scholar]
- Farman, H.; Khalil, A.; Ahmad, N.; Albattah, W.; Khan, M.A.; Islam, M. A Privacy Preserved, Trust Relationship (PTR) Model for Internet of Vehicles. Electronics 2021, 10, 3105. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Muhammad, K.; Haq, I.U.; Khan, N.; Heidari, A.A.; Baik, S.W.; de Albuquerque, V.H.C. AI-Assisted Edge Vision for Violence Detection in IoT-Based Industrial Surveillance Networks. IEEE Trans. Ind. Inform. 2021, 18, 5359–5370. [Google Scholar] [CrossRef]
- Momin, A.M.; Ahmad, I.; Islam, M. Weed Classification Using Two Dimensional Weed Coverage Rate (2D-WCR) for Real-Time Selective Herbicide Applications. In Proceedings of the International Conference on Computing, Information and Systems Science and Engineering, Bangkok, Thailand, 29–31 January 2007. [Google Scholar]
- Ye, M.; Peng, X.; Gan, W.; Wu, W.; Qiao, Y. Anopcn: Video anomaly detection via deep predictive coding network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1805–1813. [Google Scholar]
- Tang, Y.; Zhao, L.; Zhang, S.; Gong, C.; Li, G.; Yang, J. Integrating prediction and reconstruction for anomaly detection. Pattern Recognit. Lett. 2020, 129, 123–130. [Google Scholar] [CrossRef]
- Chang, Y.; Tu, Z.; Xie, W.; Yuan, J. Clustering driven deep autoencoder for video anomaly detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23-28 August 2020, Proceedings, Part XV 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 329–345. [Google Scholar]
- Zhang, T.; Jia, W.; He, X.; Yang, J. Discriminative dictionary learning with motion weber local descriptor for violence detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 696–709. [Google Scholar] [CrossRef]
- Mahmoodi, J.; Salajeghe, A. A classification method based on optical flow for violence detection. Expert Syst. Appl. 2019, 127, 121–127. [Google Scholar] [CrossRef]
- Febin, I.P.; Jayasree, K.; Joy, P.T. Violence detection in videos for an intelligent surveillance system using MoBSIFT and movement filtering algorithm. Pattern Anal. Appl. 2020, 23, 611–623. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Violence detection using spatiotemporal features with 3D convolutional neural network. Sensors 2019, 19, 2472. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Song, W.; Zhou, G.; Hou, J.-j. Violent scene detection algorithm based on kernel extreme learning machine and three-dimensional histograms of gradient orientation. Multimed. Tools Appl. 2019, 78, 8497–8512. [Google Scholar] [CrossRef]
- Jain, A.; Vishwakarma, D.K. Deep NeuralNet for violence detection using motion features from dynamic images. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 826–831. [Google Scholar]
- Roman, D.G.C.; Chávez, G.C. Violence detection and localization in surveillance video. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 248–255. [Google Scholar]
- Rabiee, H.; Mousavi, H.; Nabi, M.; Ravanbakhsh, M. Detection and localization of crowd behavior using a novel tracklet-based model. Int. J. Mach. Learn. Cybern. 2018, 9, 1999–2010. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | False Alarm | AUC |
|---|---|---|
| AED-SC [69] | 27.20 | 50.60 |
| Autoencoder [21] | 3.10 | 65.51 |
| C3D [22] | 1.90 | 75.41 |
| GCN [56] | 0.10 | 82.12 |
| CLAWS [66] | - | 83.03 |
| DSN [8] | 0.021 | 85.82 |
| Proposed | 0.0017 | 87.55 |
| Method | False Alarm | AUC |
|---|---|---|
| RNN [61] | - | 68.0 |
| FFP [9] | - | 72.8 |
| VAD-DPCN [70] | - | 73.6 |
| IPC-AD [71] | - | 73.0 |
| CAE-VAD [72] | - | 73.3 |
| VAD-SCI [60] | - | 69.63 |
| AD-MGN [17] | - | 70.50 |
| ST-AD [63] | - | 73.40 |
| GEPC-AD [62] | - | 76.10 |
| GCN [56] | - | 76.44 |
| DSFN [64] | 0.74 | 82.14 |
| DSN [8] | 0.054 | 84.90 |
| Proposed | 0.023 | 86.74 |
| Method | False Alarm | AUC |
|---|---|---|
| CNN-BiLSTM [57] | - | 72.0 |
| CNN-LSTM [67] | - | 74.0 |
| CNN-ConvLSTM [68] | - | 75.9 |
| DSN [8] | 0.035 | 93.1 |
| Proposed | 0.018 | 95.8 |
| Method | False Alarm | ACC |
|---|---|---|
| Motion-IWLD [73] | - | 96.8 |
| HOMO-SVM [74] | - | 89.3 |
| SIFT [75] | - | 96.5 |
| 3dCNN [76] | - | 96.0 |
| BOW [77] | - | 95.5 |
| CNN [78] | - | 93.3 |
| CNN [79] | - | 96.4 |
| CNN-BiLSTM [57] | - | 96.0 |
| CNN-MLSTM [67] | - | 98.0 |
| CNN-ConvLSTM [68] | - | 98.5 |
| DSN [8] | 0.019 | 99 |
| Proposed | 0.0047 | 99.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.; Dukyil, A.S.; Alyahya, S.; Habib, S. An IoT Enable Anomaly Detection System for Smart City Surveillance. Sensors 2023, 23, 2358. https://doi.org/10.3390/s23042358
Islam M, Dukyil AS, Alyahya S, Habib S. An IoT Enable Anomaly Detection System for Smart City Surveillance. Sensors. 2023; 23(4):2358. https://doi.org/10.3390/s23042358
Chicago/Turabian StyleIslam, Muhammad, Abdulsalam S. Dukyil, Saleh Alyahya, and Shabana Habib. 2023. "An IoT Enable Anomaly Detection System for Smart City Surveillance" Sensors 23, no. 4: 2358. https://doi.org/10.3390/s23042358
APA StyleIslam, M., Dukyil, A. S., Alyahya, S., & Habib, S. (2023). An IoT Enable Anomaly Detection System for Smart City Surveillance. Sensors, 23(4), 2358. https://doi.org/10.3390/s23042358