
Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples

Abstract
:1. Introduction
2. PolSAR Image Data and Features
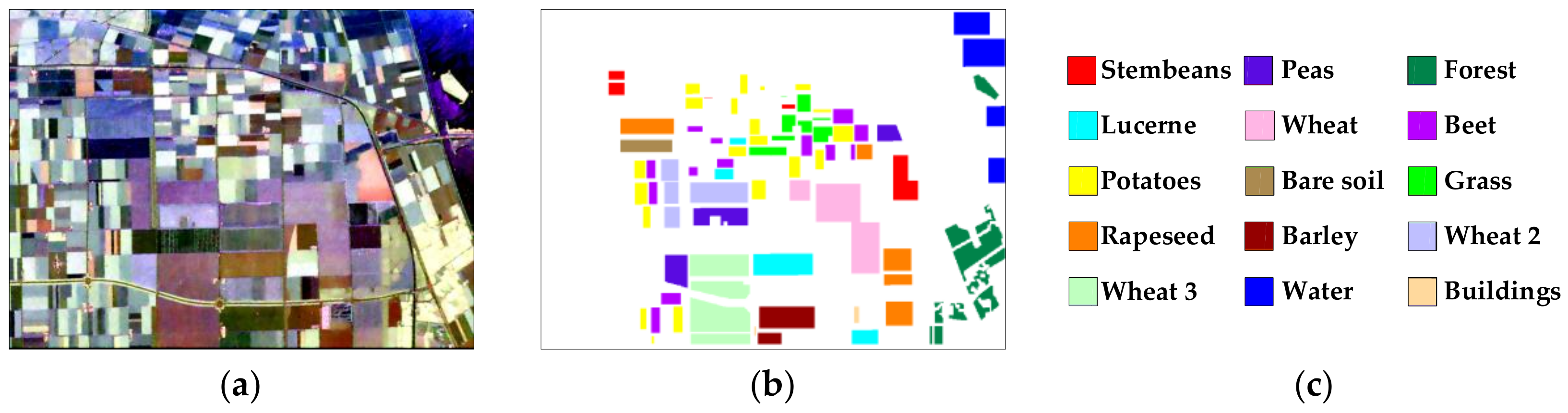
2.1. PolSAR Image Data
2.2. PolSAR Image Features
3. Methodology
3.1. Base Classifiers
3.1.1. Convolutional Neural Network
3.1.2. Support Vector Machine
3.2. Construction of Feature Views
3.3. Co-Training Method of CNN and SVM
| Algorithm 1: Co-training of CNN and SVM |
Input:
The trained CNN and SVM Process: Construct a buffer pool of unlabeled samples: Select h samples randomly from to form a buffer pool , and remove the selected samples from . While
break End |
4. Experimental Results and Discussions
4.1. Datasets Description and Parameters Settings
4.2. Comparison of Fully Supervised SVM and CNN
4.3. Comparison of Co-Training and Self-Training Methods
4.4. Comparison with Other Semi-Supervised Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, J.-S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Chen, S.-W.; Tao, C.-S. PolSAR Image Classification Using Polarimetric-Feature-Driven Deep Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Moriyama, T.; Ishido, M.; Yamada, H. Four-Component Scattering Model for Polarimetric SAR Image Decomposition. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1699–1706. [Google Scholar] [CrossRef]
- Chen, S.-W.; Wang, X.-S.; Motoyuki, S. Uniform Polarimetric Matrix Rotation Theory and Its Applications. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4756–4770. [Google Scholar] [CrossRef]
- He, C.; Li, S.; Liao, Z.; Liao, M. Texture Classification of PolSAR Data Based on Sparse Coding of Wavelet Polarization Textons. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4576–4590. [Google Scholar] [CrossRef]
- Fukuda, S.; Hirosawa, H. A wavelet-based texture feature set applied to classification of multifrequency polarimetric SAR images. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2282–2286. [Google Scholar] [CrossRef]
- Zhai, W.; Shen, H.; Huang, C.; Pei, W. Fusion of polarimetric and texture information for urban building extraction from fully polarimetric SAR imagery. Remote Sens. Lett. 2015, 7, 31–40. [Google Scholar] [CrossRef]
- Uhlmann, S.; Kiranyaz, S. Integrating Color Features in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2197–2216. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R.; Kwok, R. Classification of multi-look polarimetric SAR imagery based on complex Wishart distribution. Int. J. Remote Sens. 1994, 15, 2299–2311. [Google Scholar] [CrossRef]
- Yin, Q.; Cheng, J.; Zhang, F.; Zhou, Y.; Shao, L.; Hong, W. Interpretable POLSAR Image Classification Based on Adaptive-Dimension Feature Space Decision Tree. IEEE Access 2020, 8, 173826–173837. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Zhang, X.; Wu, H.; Guo, M. Land Cover Classification from Polarimetric SAR Data Based on Image Segmentation and Decision Trees. Can. J. Remote Sens. 2015, 41, 40–50. [Google Scholar] [CrossRef]
- Wang, S.; Guo, Y.; Hua, W.; Liu, X.; Song, G.; Hou, B.; Jiao, L. Semi-Supervised PolSAR Image Classification Based on Improved Tri-Training With a Minimum Spanning Tree. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8583–8597. [Google Scholar] [CrossRef]
- Shah Hosseini, R.; Entezari, I.; Homayouni, S.; Motagh, M.; Mansouri, B. Classification of polarimetric SAR images using Support Vector Machines. Can. J. Remote Sens. 2014, 37, 220–233. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.-Q. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.-Q. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Qin, X.; Zou, H.; Yu, W.; Wang, P. Superpixel-Oriented Classification of PolSAR Images Using Complex-Valued Convolutional Neural Network Driven by Hybrid Data. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10094–10111. [Google Scholar] [CrossRef]
- Shang, R.; Wang, J.; Jiao, L.; Yang, X.; Li, Y. Spatial feature-based convolutional neural network for PolSAR image classification. Appl. Soft Comput. 2022, 123, 108922. [Google Scholar] [CrossRef]
- Zhou, Z. Machine Learning; Tsinghua University Press: Beijing, China, 2016. [Google Scholar]
- Bi, H.; Sun, J.; Xu, Z. A Graph-Based Semisupervised Deep Learning Model for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2116–2132. [Google Scholar] [CrossRef]
- Geng, J.; Ma, X.; Fan, J.; Wang, H. Semisupervised Classification of Polarimetric SAR Image via Superpixel Restrained Deep Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 122–126. [Google Scholar] [CrossRef]
- Hua, W.; Wang, S.; Liu, H.; Liu, K.; Guo, Y.; Jiao, L. Semisupervised PolSAR Image Classification Based on Improved Cotraining. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4971–4986. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Y.; Yang, S.; Wang, S.; Feng, J.; Jiao, L. Large Polarimetric SAR Data Semi-Supervised Classification With Spatial-Anchor Graph. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1439–1458. [Google Scholar] [CrossRef]
- Xie, W.; Ma, G.; Zhao, F.; Liu, H.; Zhang, L. PolSAR Image Classification via a Novel Semi-Supervised Recurrent Complex-Valued Convolution Neural Network. Neurocomputing 2020, 388, 255–268. [Google Scholar] [CrossRef]
- Qin, X.; Yu, W.; Wang, P.; Chen, T.; Zou, H. Semi-supervised Classification of PolSAR Image Based on Self-training Convolutional Neural Network. In Proceedings of the 6th China High Resolution Earth Observation Conference (CHREOC 2019), Chengdu, China, 1 September 2019; Springer: Singapore, 2020; pp. 405–417. [Google Scholar]
- Li, Y.; Xing, R.; Jiao, L.; Chen, Y.; Chai, Y.; Marturi, N.; Shang, R. Semi-Supervised PolSAR Image Classification Based on Self-Training and Superpixels. Remote Sens. 2019, 11, 1933. [Google Scholar] [CrossRef]
- Hua, W.; Wang, S.; Hou, B. Semi-supervised learning for classification of polarimetric SAR images based on SVM-Wishart. J. Radars 2015, 4, 93–98. [Google Scholar] [CrossRef]
- Hua, W.; Wang, S.; Guo, Y.; Xie, W. Semi-supervised PolSAR image classification based on the neighborhood minimum spanning tree. J. Radars 2019, 8, 458–470. [Google Scholar] [CrossRef]
- Ning, X.; Wang, X.; Xu, S.; Cai, W.; Zhang, L.; Yu, L.; Li, W. A review of research on co-training. Concurr. Comput. Pract. Exp. 2021, e6276. [Google Scholar] [CrossRef]
- Zhao, F.; Liu, L.; Zhang, L.; Liu, H.; Cheng, Y. Semi-Supervised PolSAR Image Classification Based on Deep Co-Training with Superpixel Restrained Strategy. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Online, 12–16 July 2021; pp. 5386–5389. [Google Scholar]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Yin, Z.; Hou, J. Recent advances on SVM based fault diagnosis and process monitoring in complicated industrial processes. Neurocomputing 2016, 174, 643–650. [Google Scholar] [CrossRef]
- Niu, X.; Yang, C.; Wang, H.; Wang, Y. Investigation of ANN and SVM based on limited samples for performance and emissions prediction of a CRDI-assisted marine diesel engine. Appl. Therm. Eng. 2017, 111, 1353–1364. [Google Scholar] [CrossRef]
- Chi, M.; Feng, R.; Bruzzone, L. Classification of hyperspectral remote-sensing data with primal SVM for small-sized training dataset problem. Adv. Space Res. 2008, 41, 1793–1799. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qin, X.; Hu, T.; Zou, H.; Yu, W.; Wang, P. Polsar Image Classification Via Complex-Valued Convolutional Neural Network Combining Measured Data and Artificial Features. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 3209–3212. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015; pp. 1–9. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Debnath, R.; Takahide, N.; Takahashi, H. A decision based one-against-one method for multi-class support vector machine. Pattern Anal. Appl. 2004, 7, 164–175. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Barrenechea, E.; Bustince, H.; Herrera, F. An overview of ensemble methods for binary classifiers in multi-class problems: Experimental study on one-vs-one and one-vs-all schemes. Pattern Recognit. 2011, 44, 1761–1776. [Google Scholar] [CrossRef]
- Ren, Y.X.; Yang, J.; Zhao, L.L.; Li, P.X.; Liu, Z.Q.; Shi, L. A Global Weighted Least-Squares Optimization Framework for Speckle Filtering of PolSAR Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1265–1277. [Google Scholar] [CrossRef]
- Qin, X.; Yu, W.; Wang, P.; Chen, T.; Zou, H. Weakly supervised classification of PolSAR images based on sample refinement with complex-valued convolutional neural network. J. Radars 2020, 9, 525–538. [Google Scholar] [CrossRef]
- Available online: https://scikit-learn.org/dev/index.html (accessed on 17 November 2022).
- Zhang, L.; Jiao, L.; Ma, W.; Duan, Y.; Zhang, D. PolSAR image classification based on multi-scale stacked sparse autoencoder. Neurocomputing 2019, 351, 167–179. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | OA (%) | Kappa | ||||
|---|---|---|---|---|---|---|---|
| 3 LSPC | 5 LSPC | 10 LSPC | 3 LSPC | 5 LSPC | 10 LSPC | ||
| Dataset 1 | FS-CNN | 66.63 | 68.13 | 71.36 | 0.6364 | 0.6343 | 0.6837 |
| FS-SVM | 80.51 | 83.62 | 88.21 | 0.7883 | 0.8221 | 0.8717 | |
| ST-CNN | 85.07 | 88.51 | 90.48 | 0.8377 | 0.8766 | 0.8963 | |
| ST-SVM | 82.03 | 85.01 | 89.69 | 0.8026 | 0.8366 | 0.8875 | |
| CNN-KNN | 81.04 | 89.31 | 92.29 | 0.7941 | 0.8839 | 0.9160 | |
| CNN-MLP | 86.09 | 91.14 | 93.58 | 0.8486 | 0.9033 | 0.9299 | |
| Proposed | 89.68 | 93.22 | 97.84 | 0.8759 | 0.9261 | 0.9764 | |
| Dataset 2 | FS-CNN | 64.83 | 71.53 | 73.36 | 0.6031 | 0.6754 | 0.6920 |
| FS-SVM | 77.53 | 81.95 | 87.64 | 0.7435 | 0.7894 | 0.8311 | |
| ST-CNN | 83.79 | 86.45 | 94.69 | 0.8158 | 0.8430 | 0.9379 | |
| ST-SVM | 80.46 | 83.58 | 89.73 | 0.7816 | 0.8094 | 0.8801 | |
| CNN-KNN | 76.89 | 88.22 | 92.15 | 0.7372 | 0.8632 | 0.9084 | |
| CNN-MLP | 82.02 | 91.44 | 94.86 | 0.7932 | 0.9001 | 0.9398 | |
| Proposed | 91.28 | 93.52 | 96.38 | 0.8984 | 0.9241 | 0.9576 | |
| Dataset 3 | FS-CNN | 60.76 | 68.37 | 75.61 | 0.4521 | 0.6139 | 0.7076 |
| FS-SVM | 76.37 | 76.89 | 81.69 | 0.6678 | 0.6715 | 0.7402 | |
| ST-CNN | 81.53 | 90.15 | 91.83 | 0.7322 | 0.8588 | 0.8839 | |
| ST-SVM | 78.10 | 80.39 | 84.63 | 0.6874 | 0.7201 | 0.7813 | |
| CNN-KNN | 75.91 | 85.83 | 86.45 | 0.6633 | 0.7988 | 0.8056 | |
| CNN-MLP | 80.51 | 84.30 | 87.23 | 0.7206 | 0.7757 | 0.8164 | |
| Proposed | 87.75 | 92.21 | 93.97 | 0.8269 | 0.8890 | 0.9140 | |
| Method. | Stembeans | Rapeseed | Bare Land | Potato | Beet | Wheat 2 | Peas | Wheat 3 | Lucerne |
|---|---|---|---|---|---|---|---|---|---|
| TT-NMST [14] | 96.40 | 81.95 | 99.31 | 65.31 | 93.45 | 72.84 | 92.29 | 90.50 | 95.07 |
| ST-NMST [29] | 98.75 | 59.58 | 96.75 | 81.99 | 94.60 | 89.86 | 97.56 | 97.05 | 95.06 |
| Proposed | 100 | 97.10 | 99.48 | 98.41 | 98.51 | 91.17 | 98.14 | 98.96 | 98.86 |
| Method | Barley | Wheat | Grass | Forest | Water | Building | OA | Kappa | |
| TT-NMST [14] | 95.64 | 87.09 | 72.13 | 90.32 | 96.30 | 76.87 | 87.01 | 0.8542 | |
| ST-NMST [29] | 98.39 | 85.41 | 80.08 | 94.77 | 93.35 | 85.58 | 89.92 | 0.8852 | |
| Proposed | 97.80 | 99.08 | 90.83 | 99.98 | 99.08 | 86.70 | 97.84 | 0.9764 |
| Method | Stembeans | Rapeseed | Bare Land | Potato | Beet | Wheat 2 | Peas | Wheat 3 | Lucerne |
|---|---|---|---|---|---|---|---|---|---|
| SSAE [49] | 98.33 | 97.57 | 98.66 | 98.72 | 99.40 | 98.10 | 98.97 | 99.00 | 98.72 |
| RCV-CNN2 [25] | 98.61 | 97.07 | 98.05 | 98.90 | 94.14 | 97.28 | 98.56 | 98.56 | 98.22 |
| SRDNN-MD [22] | 98.18 | 93.68 | 95.06 | 94.81 | 97.13 | 90.98 | 95.91 | 98.23 | 97.72 |
| SPGraphCNN [21] | 99.07 | 99.26 | 100 | 98.83 | 99.76 | 99.65 | 99.12 | 99.50 | 99.72 |
| SSA1 [24] | 93.25 | 78.08 | 92.99 | 87.64 | 93.05 | 70.98 | 93.95 | 91.03 | 88.15 |
| SSA2 [24] | 94.14 | 80.88 | 96.09 | 87.71 | 94.17 | 76.96 | 93.01 | 90.98 | 90.19 |
| Proposed | 99.87 | 99.77 | 99.68 | 99.35 | 99.63 | 96.84 | 99.26 | 100 | 99.38 |
| Method | Barley | Wheat | Grass | Forest | Water | Building | OA | Kappa | |
| SSAE [49] | 97.93 | 98.08 | 91.50 | 99.71 | 96.41 | 96.31 | 98.18 | 0.9802 | |
| RCV-CNN2 [25] | 98.20 | 94.50 | 89.17 | 97.81 | 99.89 | 80.88 | 97.22 | 0.8930 | |
| SRDNN-MD [22] | 99.38 | 89.17 | 94.37 | 86.24 | 100 | 97.64 | 94.98 | 0.9453 | |
| SPGraphCNN [21] | 99.68 | 99.10 | 90.72 | 98.81 | 100 | 98.31 | 98.82 | NULL | |
| SSA1 [24] | 95.50 | 87.04 | 58.75 | 86.20 | 89.33 | 74.06 | 85.33 | NULL | |
| SSA2 [24] | 96.23 | 90.74 | 65.25 | 86.44 | 92.63 | 78.25 | 87.58 | NULL | |
| Proposed | 99.38 | 99.16 | 95.17 | 99.61 | 99.81 | 99.00 | 99.20 | 0.9913 |
| Method | Potato | Fruits | Oats | Beet | Barley | Onion | Wheat | Beans |
|---|---|---|---|---|---|---|---|---|
| RCV-CNN1 [25] | 99.56 | 98.87 | 97.42 | 96.92 | 99.03 | 42.16 | 99.38 | 74.03 |
| RCV-CNN2 [25] | 99.71 | 97.91 | 95.55 | 96.86 | 99.23 | 30.09 | 99.20 | 86.69 |
| Proposed | 99.87 | 99.84 | 97.85 | 99.52 | 99.86 | 77.22 | 99.81 | 97.08 |
| Method | Peas | Maize | Flax | Rapeseed | Grass | Lucerne | OA | Kappa |
| RCV-CNN1 [25] | 99.35 | 79.92 | 96.88 | 99.71 | 78.26 | 89.33 | 96.93 | 0.8852 |
| RCV-CNN2 [25] | 99.77 | 80.85 | 97.40 | 99.55 | 83.68 | 88.89 | 96.97 | 0.8888 |
| Proposed | 99.95 | 91.21 | 97.31 | 99.99 | 98.01 | 100 | 99.17 | 0.9903 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Cheng, Y.; Qin, X.; Yu, W.; Wang, P. Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples. Sensors 2023, 23, 2109. https://doi.org/10.3390/s23042109
Zhao M, Cheng Y, Qin X, Yu W, Wang P. Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples. Sensors. 2023; 23(4):2109. https://doi.org/10.3390/s23042109
Chicago/Turabian StyleZhao, Mingjun, Yinglei Cheng, Xianxiang Qin, Wangsheng Yu, and Peng Wang. 2023. "Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples" Sensors 23, no. 4: 2109. https://doi.org/10.3390/s23042109
APA StyleZhao, M., Cheng, Y., Qin, X., Yu, W., & Wang, P. (2023). Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples. Sensors, 23(4), 2109. https://doi.org/10.3390/s23042109