
Multimodal Sensor-Input Architecture with Deep Learning for Audio-Visual Speech Recognition in Wild



Abstract
:1. Introduction
2. Related Works on Multimodal-Sensor Architectures for Speech Recognition in Wild Environments
2.1. Research Works for ASR in the Wild
2.2. Research Works for AVSR in the Wild
2.3. Research Works on Emotion Recognition in the Wild
2.4. Other Research Works on In-The-Wild Scenarios
3. Methodology
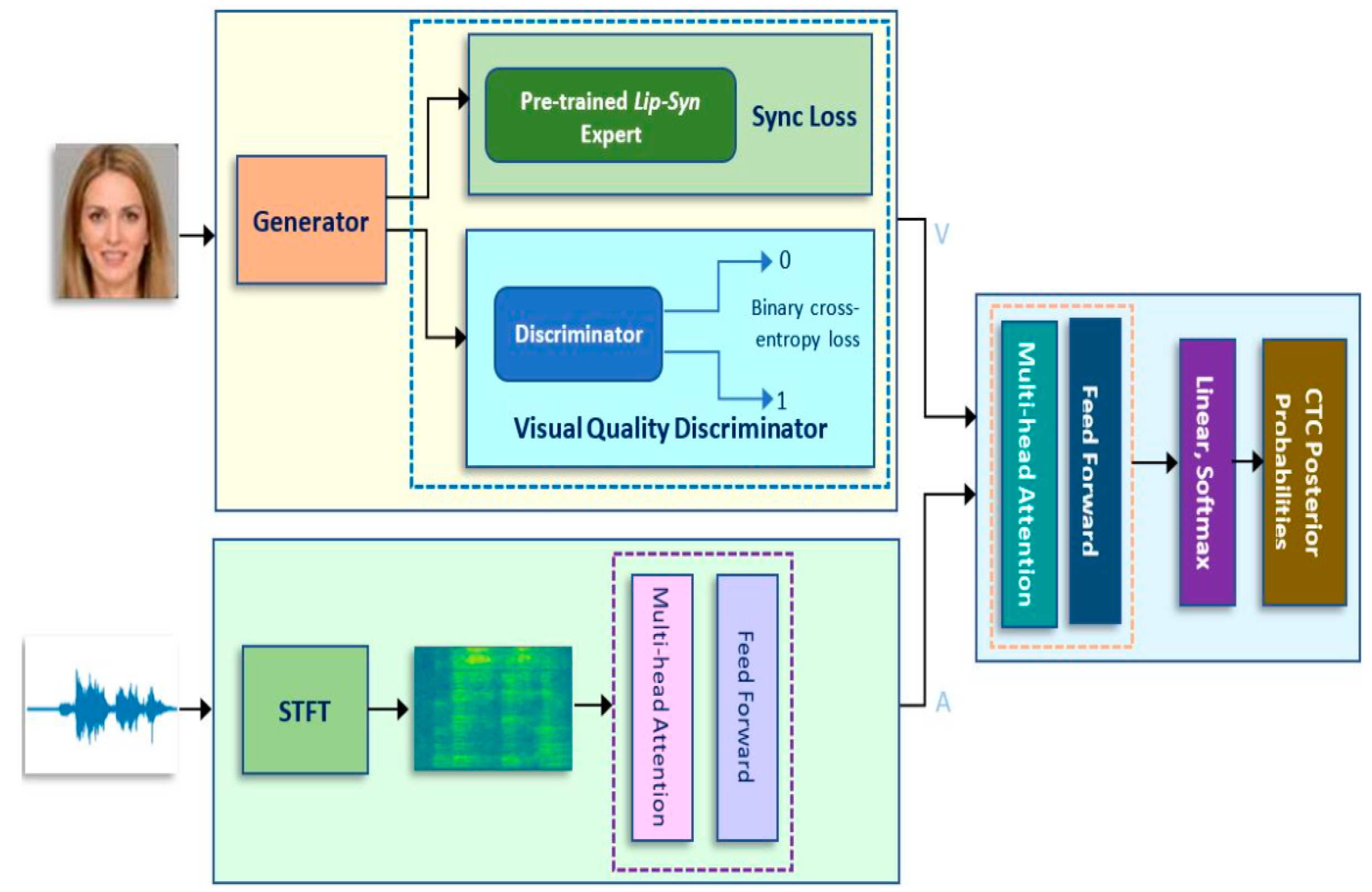
Proposed Multimodal Sensor-Input Architecture with Deep Learning for AVSR in the Wild
4. Experiment and Results
4.1. Description of Datasets
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Haton, J.-P. Neural networks for automatic speech recognition: A review. In Speech Processing, Recognition and Artificial Neural Networks: Proceedings of the 3rd International School on Neural Nets “Eduardo R. Caianiello”; Springer: London, UK, 1999; pp. 259–280. [Google Scholar]
- Phillips, W.; Tosuner, C.; Robertson, W.M. Speech recognition techniques using RBF networks. In IEEE WESCANEX 95. Communications, Power, and Computing. Conference Proceedings; IEEE: New York, NY, USA, 1995; Volume 1, pp. 185–190. [Google Scholar]
- Lim, K.H.; Seng, K.P.; Ang, L.M.; Chin, S.W. Lyapunov theory-based multilayered neural network. IEEE Trans. Circuits Syst. II Express Briefs 2009, 56, 305–309. [Google Scholar]
- Kinjo, T.; Funaki, K. On HMM speech recognition based on complex speech analysis. In IECON 2006-32nd Annual Conference on IEEE Industrial Electronics; IEEE: New York, NY, USA, 2006; pp. 3477–3480. [Google Scholar]
- Zweig, G.; Nguyen, P. A segmental CRF approach to large vocabulary continuous speech recognition. In 2009 IEEE Workshop on Automatic Speech Recognition & Understanding; IEEE: New York, NY, USA, 2009; pp. 152–157. [Google Scholar]
- Fujimoto, M.; Riki, Y. Robust speech recognition in additive and channel noise environments using GMM and EM algorithm. In 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; IEEE: New York, NY, USA, 2004; Volume 1, pp. 1–941. [Google Scholar]
- Deng, L. Deep learning: From speech recognition to language and multimodal processing. APSIPA Trans. Signal Inf. Process. 2016, 5, e1. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan., K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Dupont, S.; Luettin, J. Audio-visual speech modeling for continuous speech recognition. IEEE Trans. Multimedia 2000, 2, 141–151. [Google Scholar] [CrossRef]
- Aleksic, P.S.; Katsaggelos, A.K. Audio-Visual Biometrics. Proc. IEEE 2006, 94, 2025–2044. [Google Scholar] [CrossRef]
- Seng, K.P.; Ang, L.-M. Video Analytics for Customer Emotion and Satisfaction at Contact Centers. IEEE Trans. Human-Machine Syst. 2017, 48, 266–278. [Google Scholar] [CrossRef]
- Tian, Y.; Shi, J.; Li, B.; Duan, Z.; Xu, C. Audio-visual event localization in unconstrained videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 247–263. [Google Scholar]
- Son Chung, J.; Senior, A.; Vinyals, O.; Zisserman, A. Lip reading sentences in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6447–6456. [Google Scholar]
- Yu, J.; Zhang, S.X.; Wu, J.; Ghorbani, S.; Wu, B.; Kang, S.; Yu, D. Audio-visual recognition of overlapped speech for the lrs2 dataset. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA; pp. 6984–6988. [Google Scholar]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 44, 8717–8727. [Google Scholar] [CrossRef] [PubMed]
- Shoumy, N.J.; Ang, L.-M.; Rahaman, D.M.M.; Zia, T.; Seng, K.P.; Khatun, S. Augmented audio data in improving speech emotion classification tasks. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Federal Territory of Kuala Lumpur, Malaysia, 26–29 July 2021; pp. 360–365. [Google Scholar]
- Stafylakis, T.; Tzimiropoulos, G. Zero-shot keyword spotting for visual speech recognition in-the-wild. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 513–529. [Google Scholar]
- Han, K.J.; Hahm, S.; Kim, B.-H.; Kim, J.; Lane, I. Deep Learning-Based Telephony Speech Recognition in the Wild. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1323–1327. [Google Scholar]
- Ali, A.; Vogel, S.; Renals, S. Speech recognition challenge in the wild: Arabic MGB-3. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 316–322. [Google Scholar]
- Li, S.; Zheng, W.; Zong, Y.; Lu, C.; Tang, C.; Jiang, X.; Xia, W. Bi-modality fusion for emotion recognition in the wild. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 589–594. [Google Scholar]
- Lu, C.; Zheng, W.; Li, C.; Tang, C.; Liu, S.; Yan, S.; Zong, Y. Multiple spatio-temporal feature learning for video-based emotion recognition in the wild. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 646–652. [Google Scholar]
- Chen, J.; Wang, C.; Wang, K.; Yin, C.; Zhao, C.; Xu, T.; Zhang, X.; Huang, Z.; Liu, M.; Yang, T. HEU Emotion: A large-scale database for multimodal emotion recognition in the wild. Neural Comput. Appl. 2021, 33, 8669–8685. [Google Scholar] [CrossRef]
- Hajavi, A.; Etemad, A. Siamese capsule network for end-to-end speaker recognition in the wild. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7203–7207. [Google Scholar]
- Nguyen, H.; Maclagan, S.J.; Nguyen, T.D.; Nguyen, T.; Flemons, P.; Andrews, K.; Ritchie, E.G.; Phung, D. Animal Recognition and Identification with Deep Convolutional Neural Networks for Automated Wildlife Monitoring. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Prajwal, K.R.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 484–492. [Google Scholar]
- The Oxford-BBC Lip Reading Sentences 2 (LRS2) Dataset. Available online: https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrs2.html (accessed on 20 November 2022).
- Lip Reading Sentences 3 (LRS3) Dataset. Available online: https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrs3.html (accessed on 10 November 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category/Domain Area | Year | Main Contributions | Datasets | Reference |
|---|---|---|---|---|
| Research works on ASR in the wild | 2022 | Visual speech recognition in the wild—proposed zero-shot learning architecture for visual-only keyword spotting (KWS) tasks | LRS2 dataset | Stafylakis and Tzimiropoulos, 2018 [17] |
| 2021 | Conversational-telephony speech recognition in the wild—evaluated three deep-learning architectures (time-delay neural network (TDNN), bidirectional long short-term memory (BLSTM), convolutional neural network BLSTM (CNN–BLSTM)) | Switchboard and CallHome datasets | Han et al. [18] | |
| 2018 | In-the-wild ASR for Arabic language—submissions from 13 teams, best performance, with 80% accuracy, obtained using a combined approach of GANs and lexical information | Arabic MGB-3 Challenge dataset | Ali, Vogel and Renals [19] | |
| Research works on AVSR in the wild | 2020 | In-the-wild AVSR for speech with overlapped speech (interfering speakers)—proposed time-delay neural networks (TDNNs) with lattice-free MMI (LF-MMI TDNN system), outperformed audio-only ASR baseline by 29% WER | LRS2 dataset | Yu et al. [14] |
| 2018 | An AVSR deep-learning transformer models—proposed two transformer (TM) models and architectures for AVSR: (1) encoder–decoder-attention-structure TM architecture; and (2) self-attention TM stack architecture (TM–CTC) | LRS2-BBC dataset | Afouras et al. [15] | |
| 2017 | An AVSR watch, listen, attend and Spell (WLAS) network model with the ability to transcribe speech into characters | LRS and GRID datasets | Son Chung et al. [13] | |
| Research works on emotion recognition in the wild | 2019 | Bimodal fusion approach for emotion recognition in the wild from video—experimental results from EmotiW2019 dataset gave a performance of 63% | EmotiW2019 dataset | Li et al. [20] |
| 2018 | Spatiotemporal-feature fusion (MSFF) architecture—experimental results from EmotionW2018 dataset gave a performance of 60% | EmotionW2018 dataset | Lu et al. [21] | |
| 2021 | Dataset for multimodal emotion recognition in the wild (HEU Emotion)—videos from 19,004 video clips and 9,951 people with ten emotions and multiple modalities (facial expression, body posture and emo-tional speech) | HEU dataset | Chen et al. [22] | |
| Research works on other in-the-wild applications | 2021 | Speaker recognition in the wild—Siamese network architecture using capsules and dynamic routing, experimental results gave an error rate (EER) of 3.14% | VoxCeleb dataset | Hajavi and Etemad [23] |
| 2017 | Animal recognition in the wild—convolutional neural networks (CNNs) to monitor animals in their natural environments. Experimental results gave a classification performance of around 90% in identifying three common animals in Australia | Wildlife Spotter datasets | Nguyen et al. [24] |
| AVSR Architecture | Greedy Search | Beam Search (+LM) | |
|---|---|---|---|
| Clean Input | |||
| TM–CTC+Wav2Lip GANs | AO | 11.30% | 8.70% |
| TM–CTC+Wav2Lip GANs | VO | 73.00% | 61.50% |
| TM–CTC+Wav2Lip GANs | AV | 11.90% | 8.40% |
| TM–CTC | AO | 11.70% | 8.90% |
| TM–CTC | VO | 61.60% | 55.00% |
| TM–CTC | AV | 10.80% | 7.10% |
| Added Noise | |||
| TM–CTC+Wav2Lip Gans | AO | 60.20% | 52% |
| TM–CTC+Wav2Lip Gans | AV | 35.70% | 27.90% |
| TM–CTC | AO | 65.60% | 56.10% |
| TM–CTC | AV | 32.20% | 23.70% |
| AVSR Architecture | Greedy Search | Beam Search (+LM) | |
|---|---|---|---|
| Clean Input | |||
| TM–CTC+Wav2Lip GANs | AO | 11.80% | 9.80% |
| TM–CTC+Wav2Lip GANs | VO | 88.00% | 74.00% |
| TM–CTC+Wav2Lip GANs | AV | 13.80% | 12.60% |
| TM–CTC | AO | 12.20% | 10.50% |
| TM–CTC | VO | 76.80% | 67% |
| TM–CTC | AV | 12.50% | 11.30% |
| Added Noise | |||
| TM–CTC+Wav2Lip Gans | AO | 56.00% | 51.50% |
| TM–CTC+Wav2Lip Gans | AV | 39.20% | 31.90% |
| TM–CTC | AO | 61.90% | 55.40% |
| TM–CTC | AV | 35.60% | 27.70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Seng, K.P.; Ang, L.M. Multimodal Sensor-Input Architecture with Deep Learning for Audio-Visual Speech Recognition in Wild. Sensors 2023, 23, 1834. https://doi.org/10.3390/s23041834
He Y, Seng KP, Ang LM. Multimodal Sensor-Input Architecture with Deep Learning for Audio-Visual Speech Recognition in Wild. Sensors. 2023; 23(4):1834. https://doi.org/10.3390/s23041834
Chicago/Turabian StyleHe, Yibo, Kah Phooi Seng, and Li Minn Ang. 2023. "Multimodal Sensor-Input Architecture with Deep Learning for Audio-Visual Speech Recognition in Wild" Sensors 23, no. 4: 1834. https://doi.org/10.3390/s23041834
APA StyleHe, Y., Seng, K. P., & Ang, L. M. (2023). Multimodal Sensor-Input Architecture with Deep Learning for Audio-Visual Speech Recognition in Wild. Sensors, 23(4), 1834. https://doi.org/10.3390/s23041834