
Fake News Detection Model on Social Media by Leveraging Sentiment Analysis of News Content and Emotion Analysis of Users’ Comments



Abstract
:1. Introduction
- Analyzing the sentiments of news titles and also analyzing the emotions of users’ comments on this news and their relationship to fake news in the Fakeddit dataset.
- Examine the textual content of news headlines in detecting fake news.
- Investigating the use of sentiment-based features of news headlines, as well as features based on the emotions of users’ comments, to detect fake news.
- Proposing a model based on Bi-LSTM on both textual features of news headlines and features extracted from both news sentiment analysis and comment emotion analysis to achieve state-of-the-art results for fake news detection.
- Demonstrating the results on the real dataset (Fakeddit).
2. Background of Study
2.1. Fake News Overview
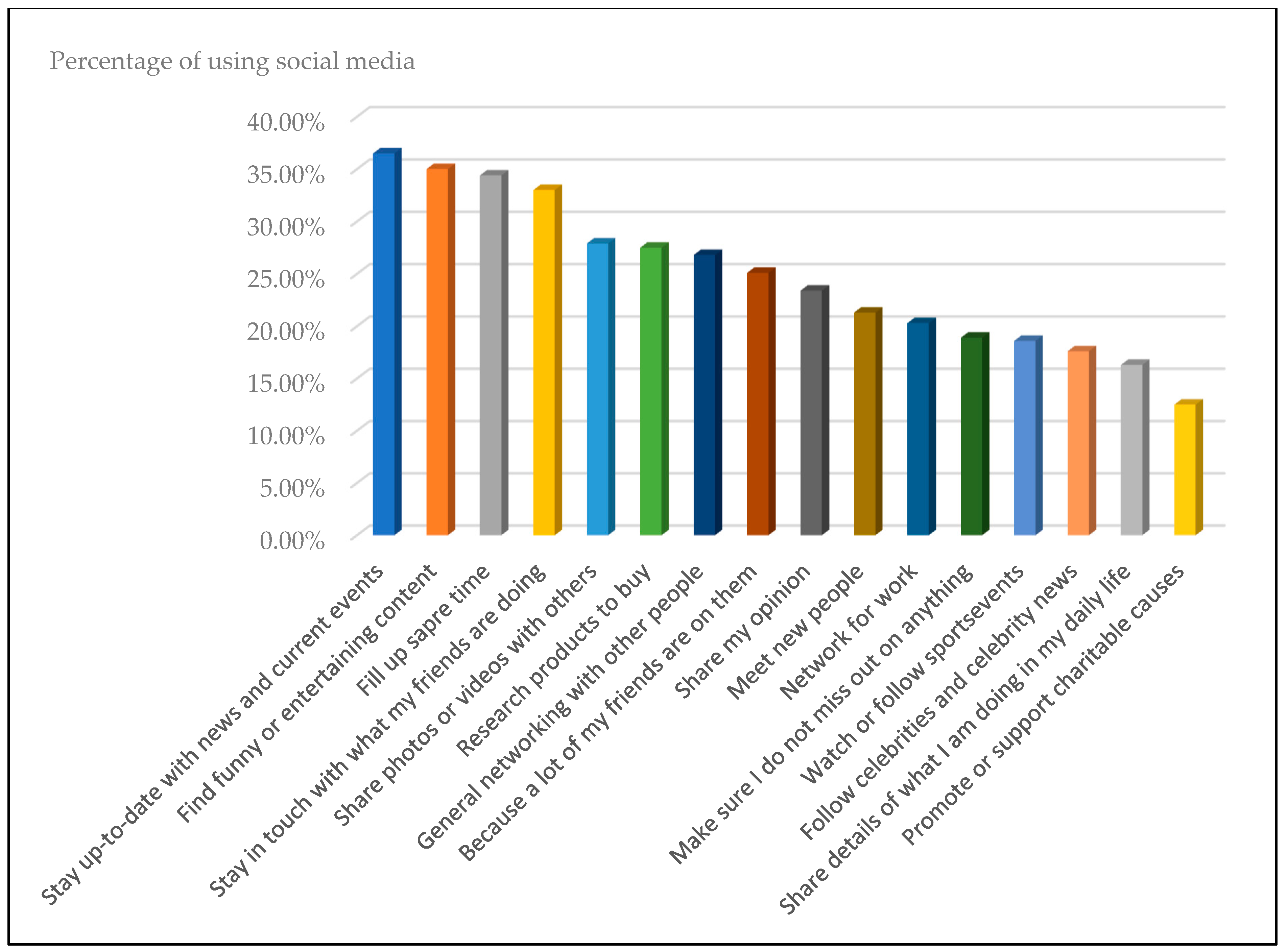
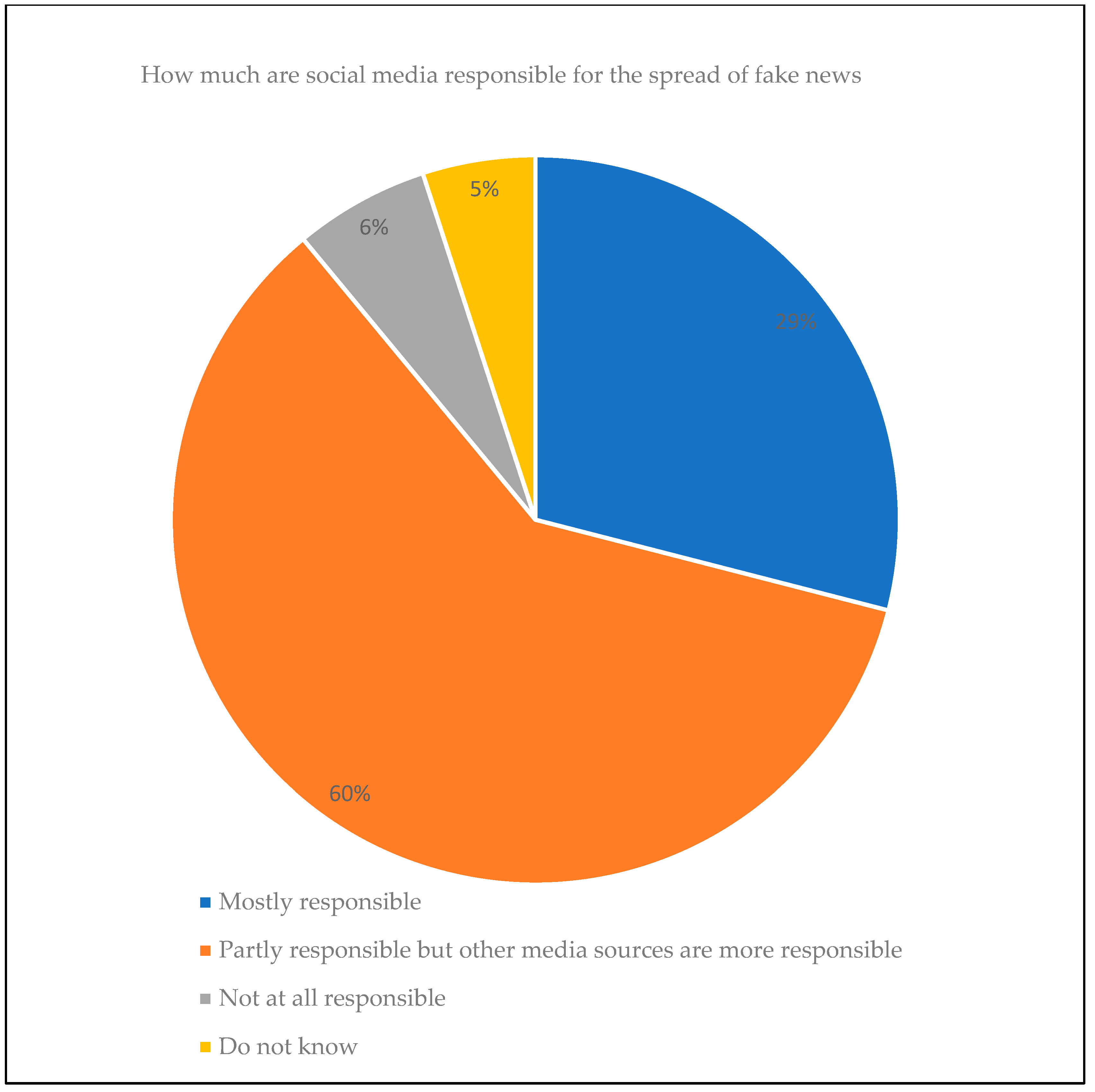
2.2. Social Media
2.3. Sentiment and Emotion Analysis in Natural Language Processing (NLP)
3. Previous Studies
3.1. Fake News Detection Models Based on Sentiments and Emotions Analysis
3.2. Baseline Models
4. Materials and Methods
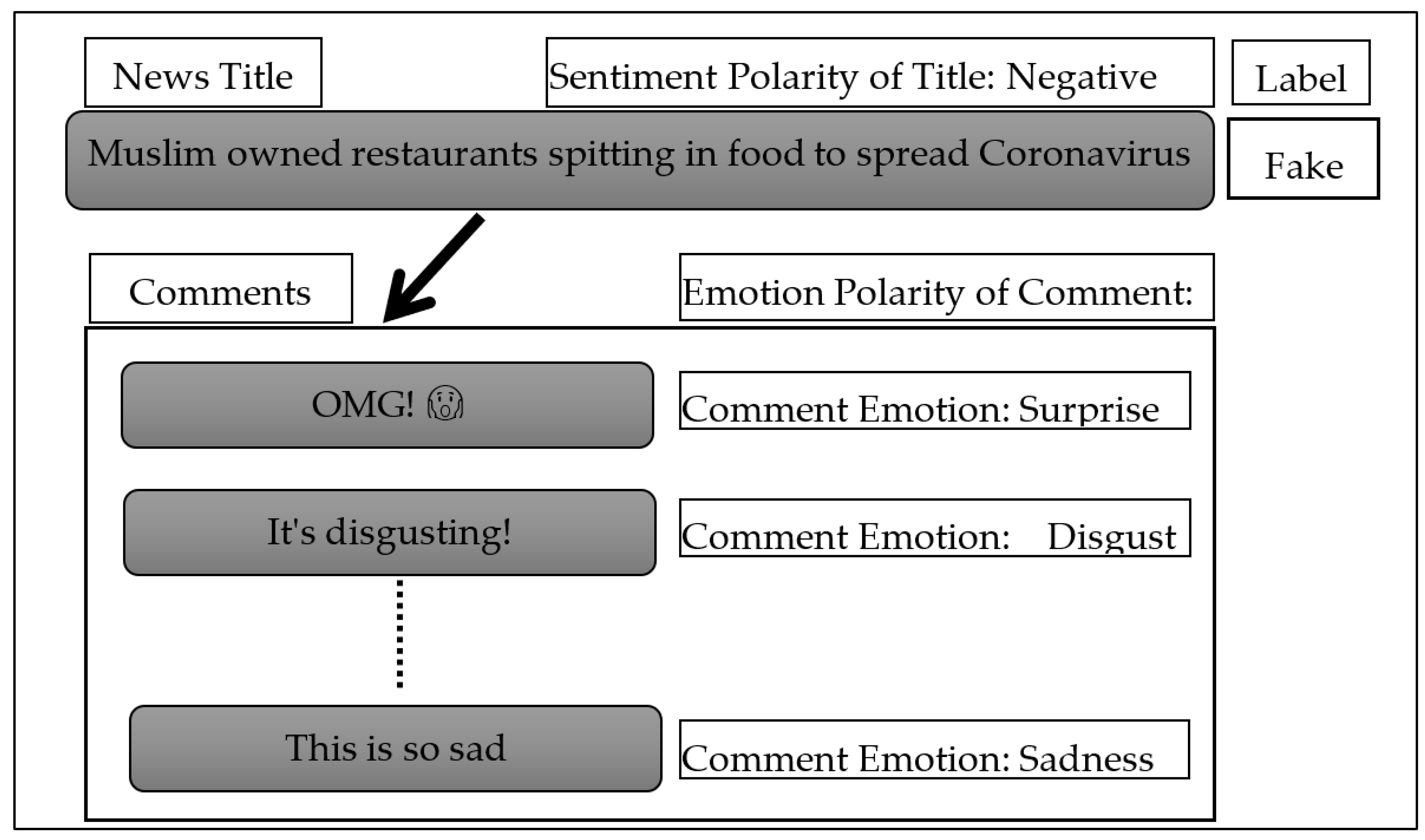
4.1. Dataset
4.1.1. Dataset Description
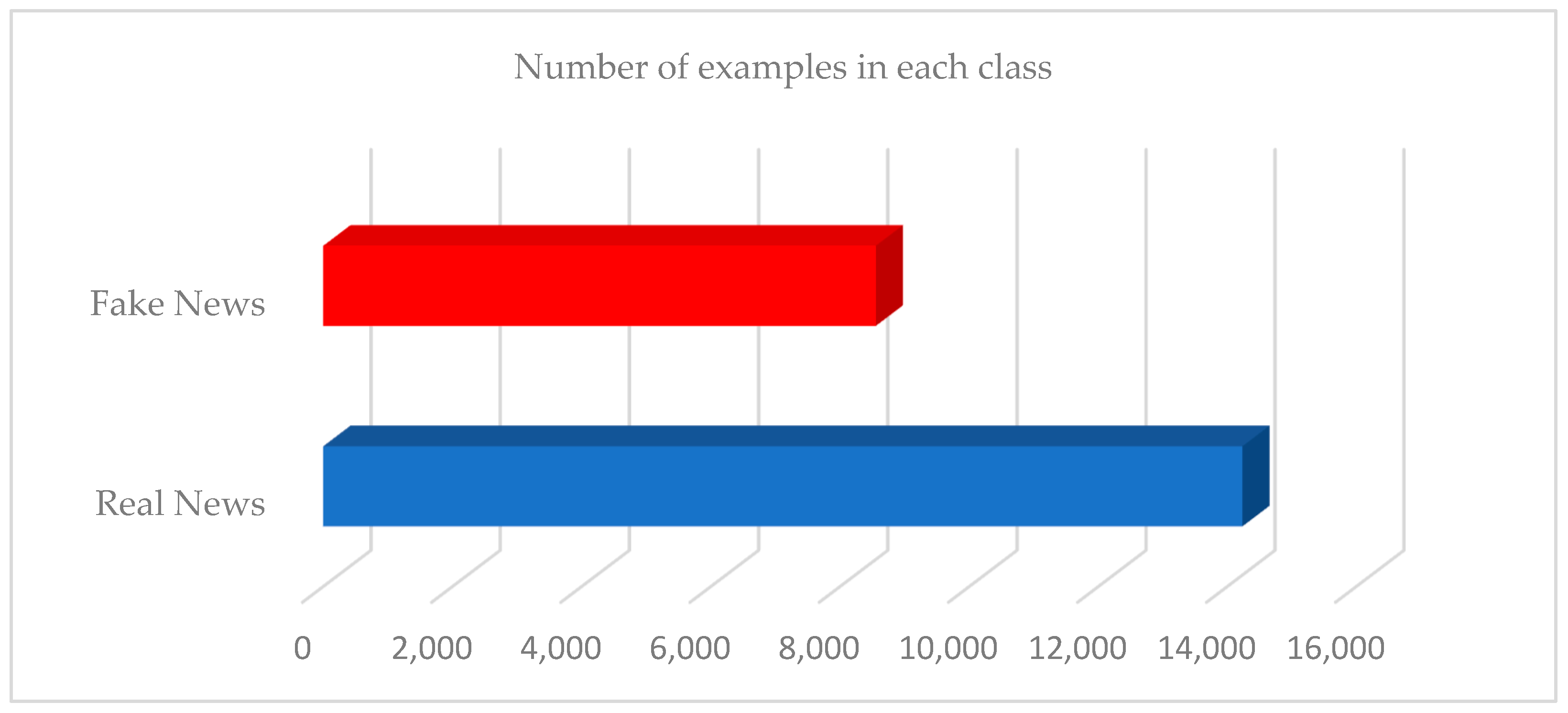
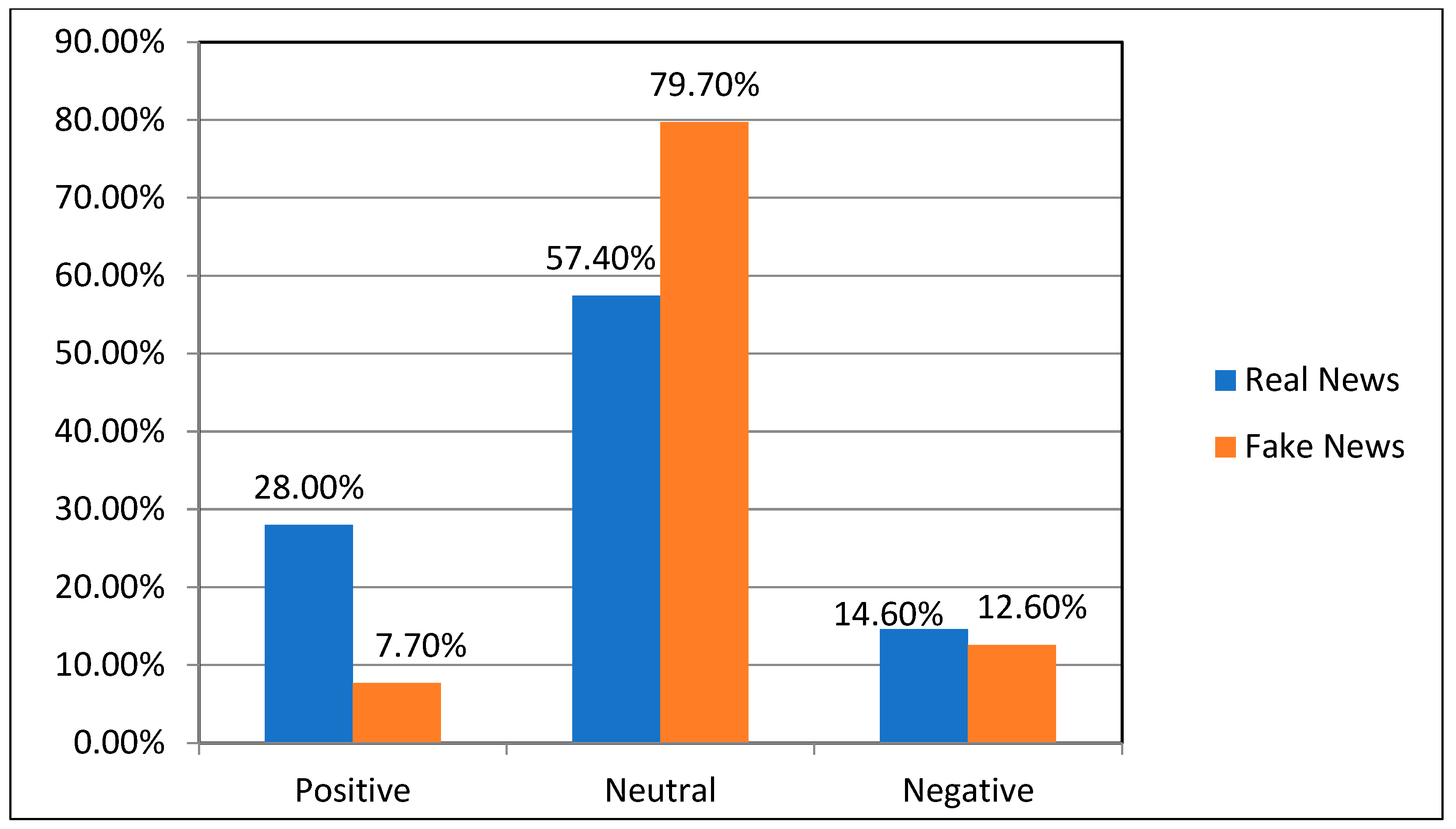
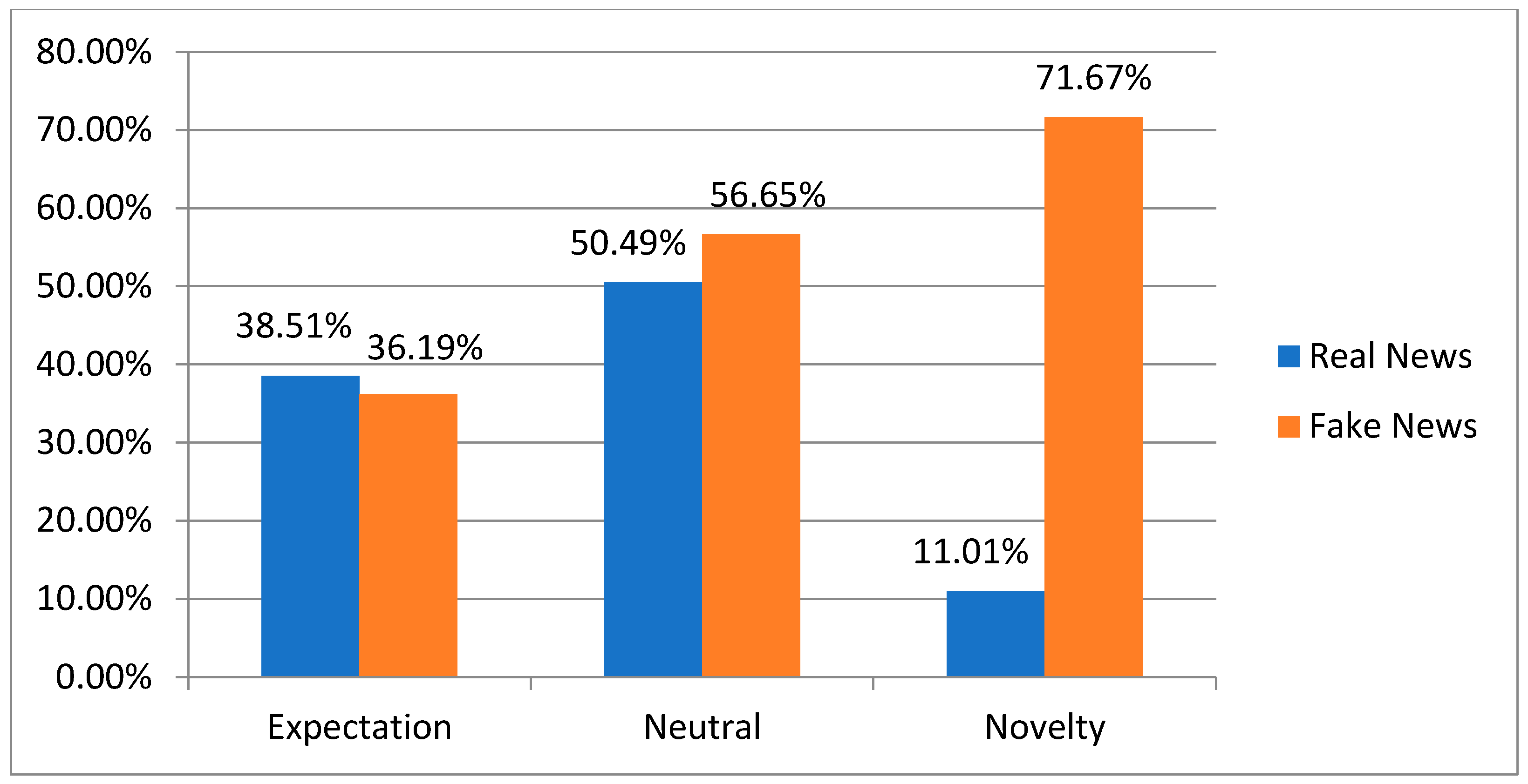
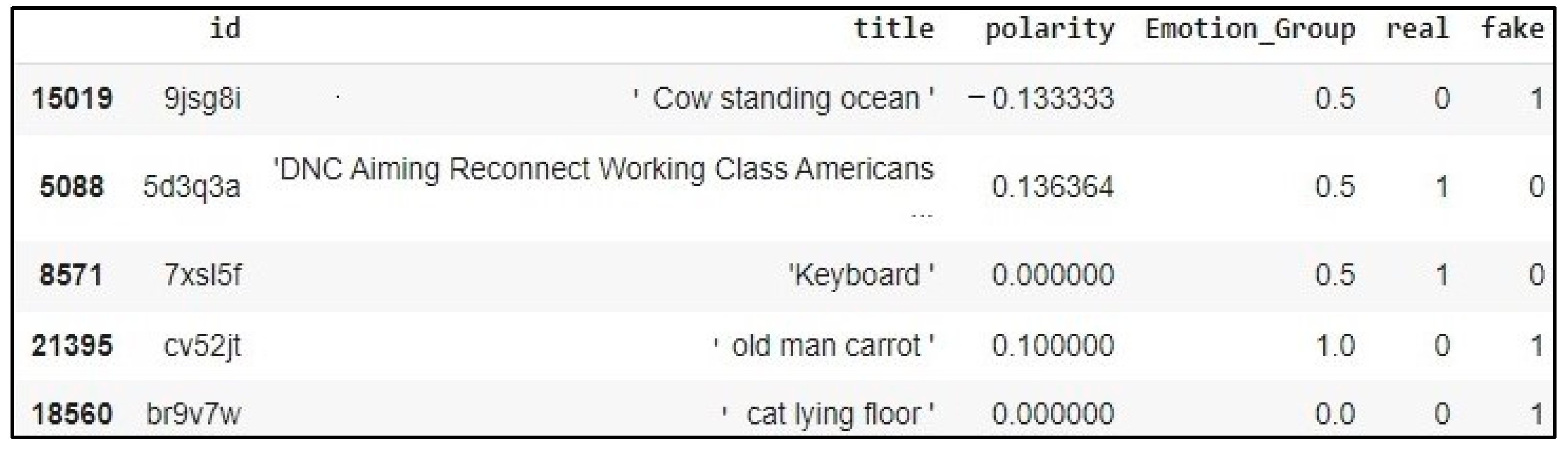
4.1.2. Dataset Visualization
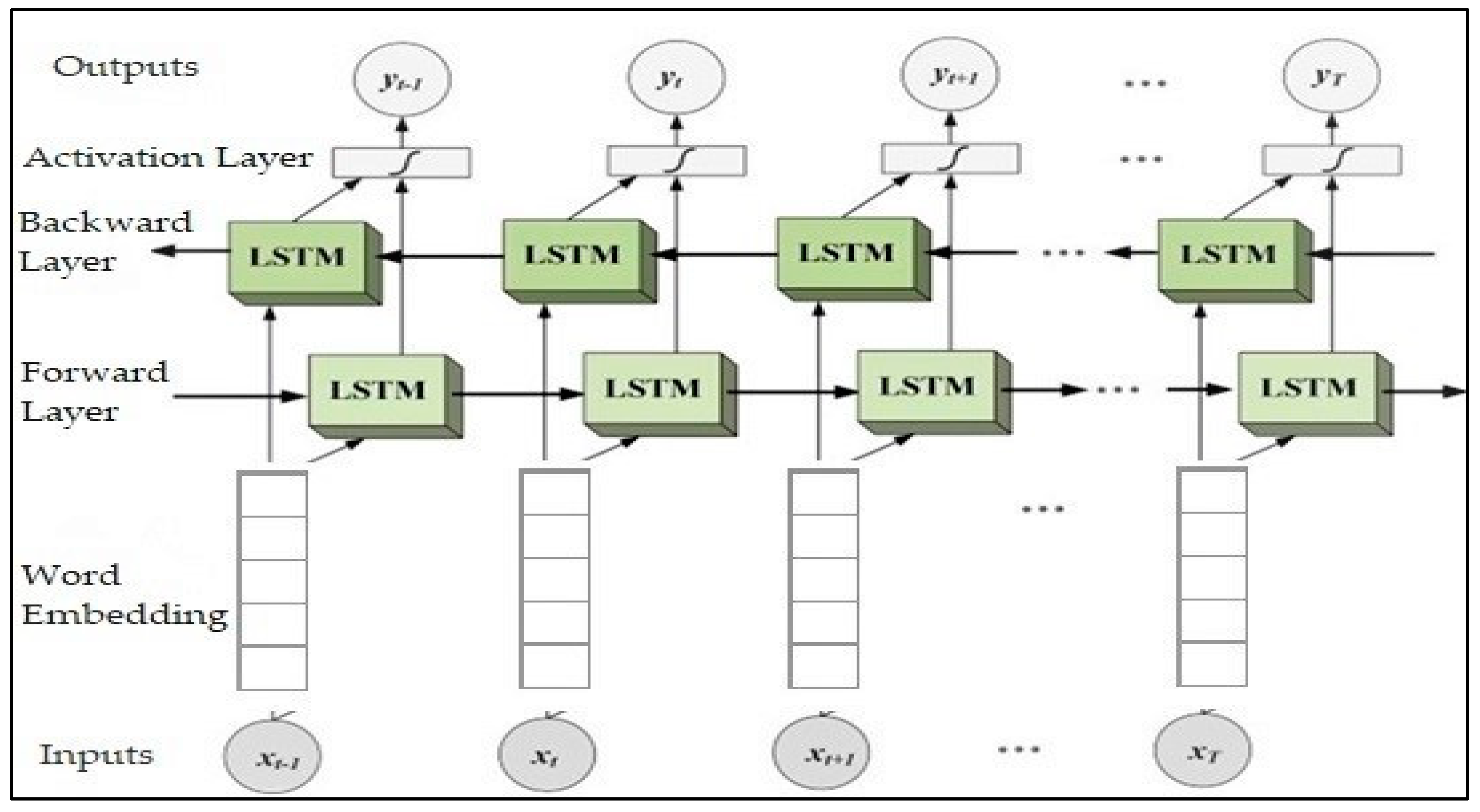
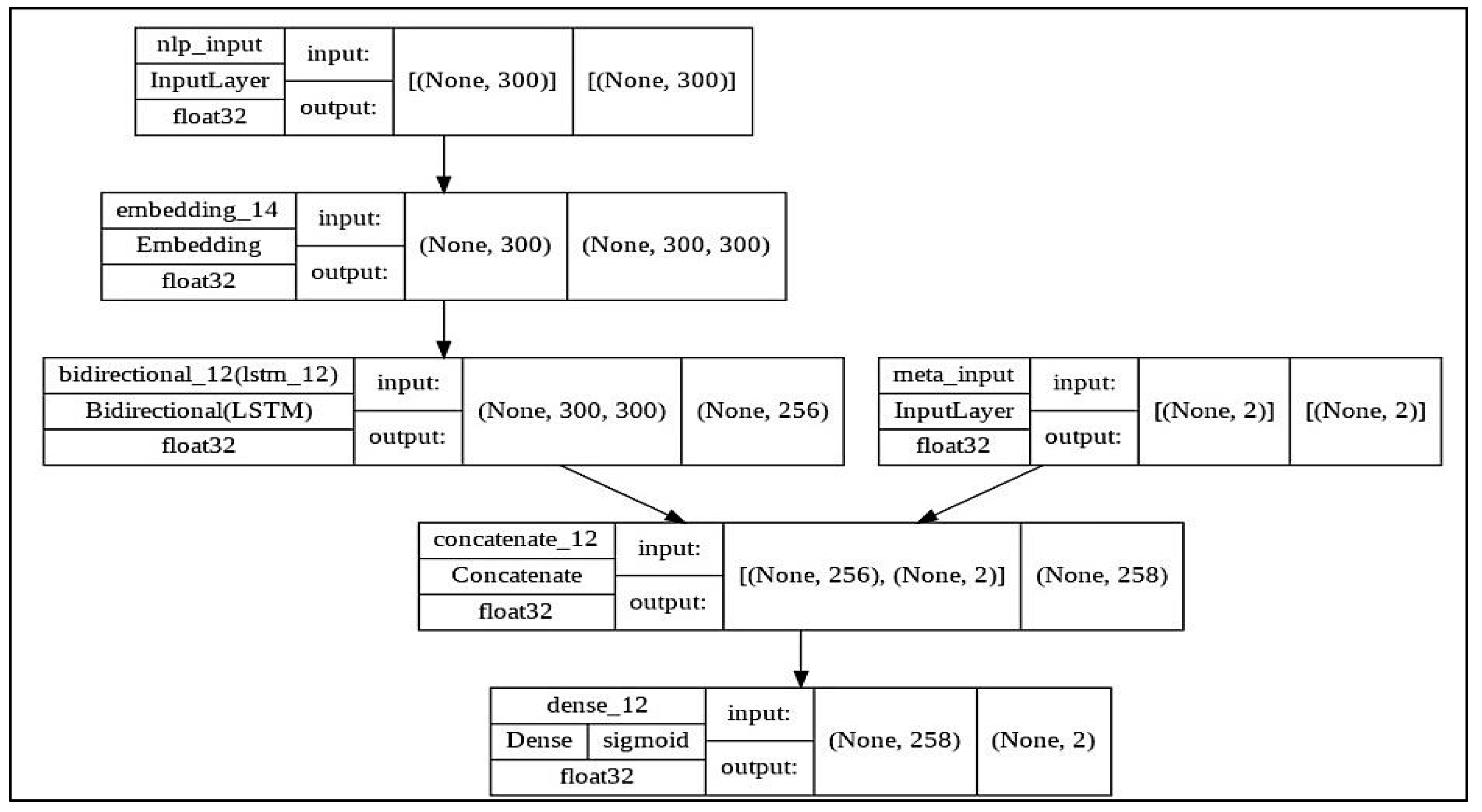
4.2. The Proposed Detection Model
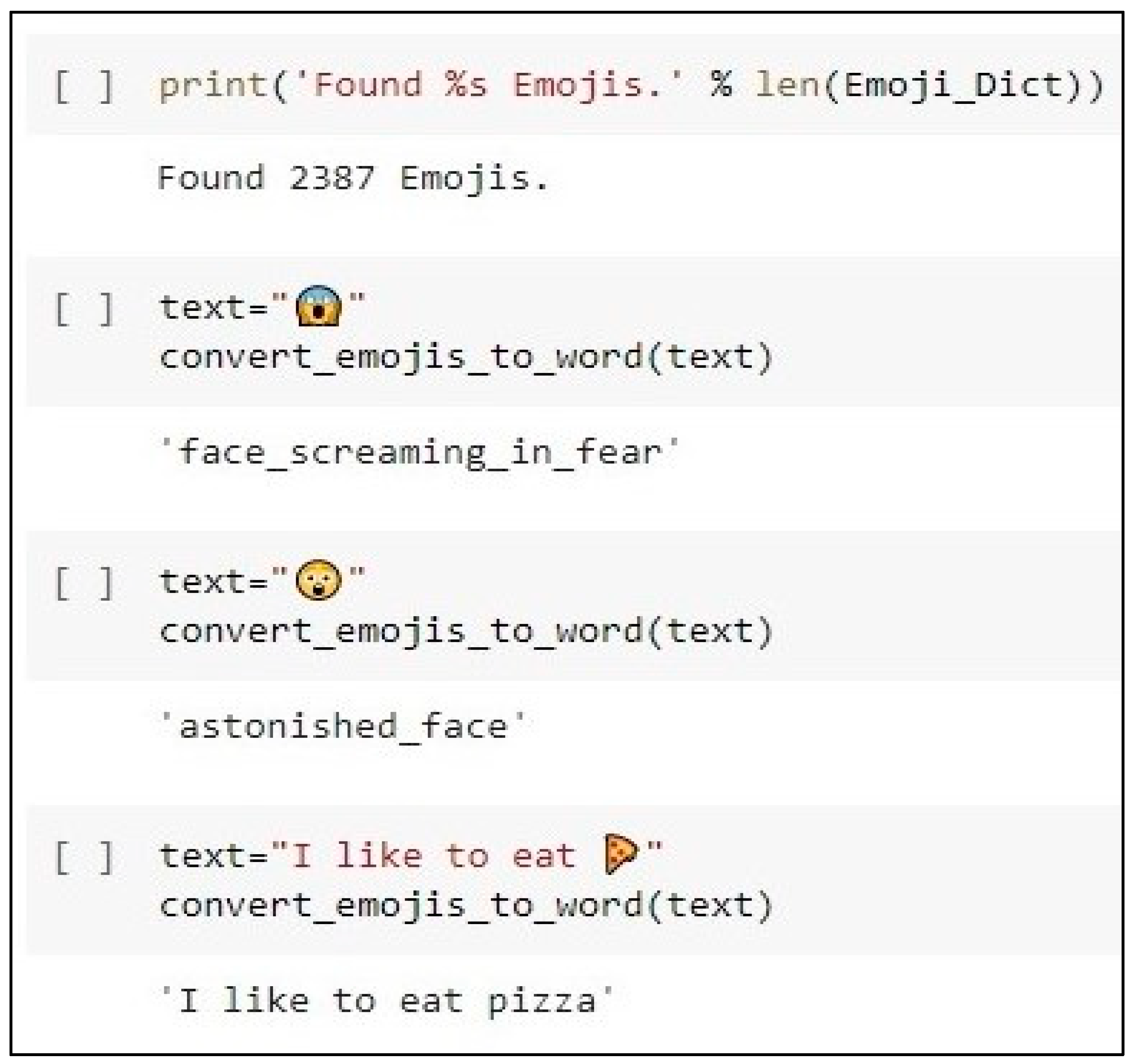
4.2.1. Emotion Analysis Unit
- Remove new lines and tabs.
- Striping HTML Tags
- Remove the links
- Remove accented characters.
- Expanding contractions
- Removing special characters except (!, ?)
- Reduce repeated characters
- Correcting misspelled words
- Remove stopwords
- Remove whitespaces
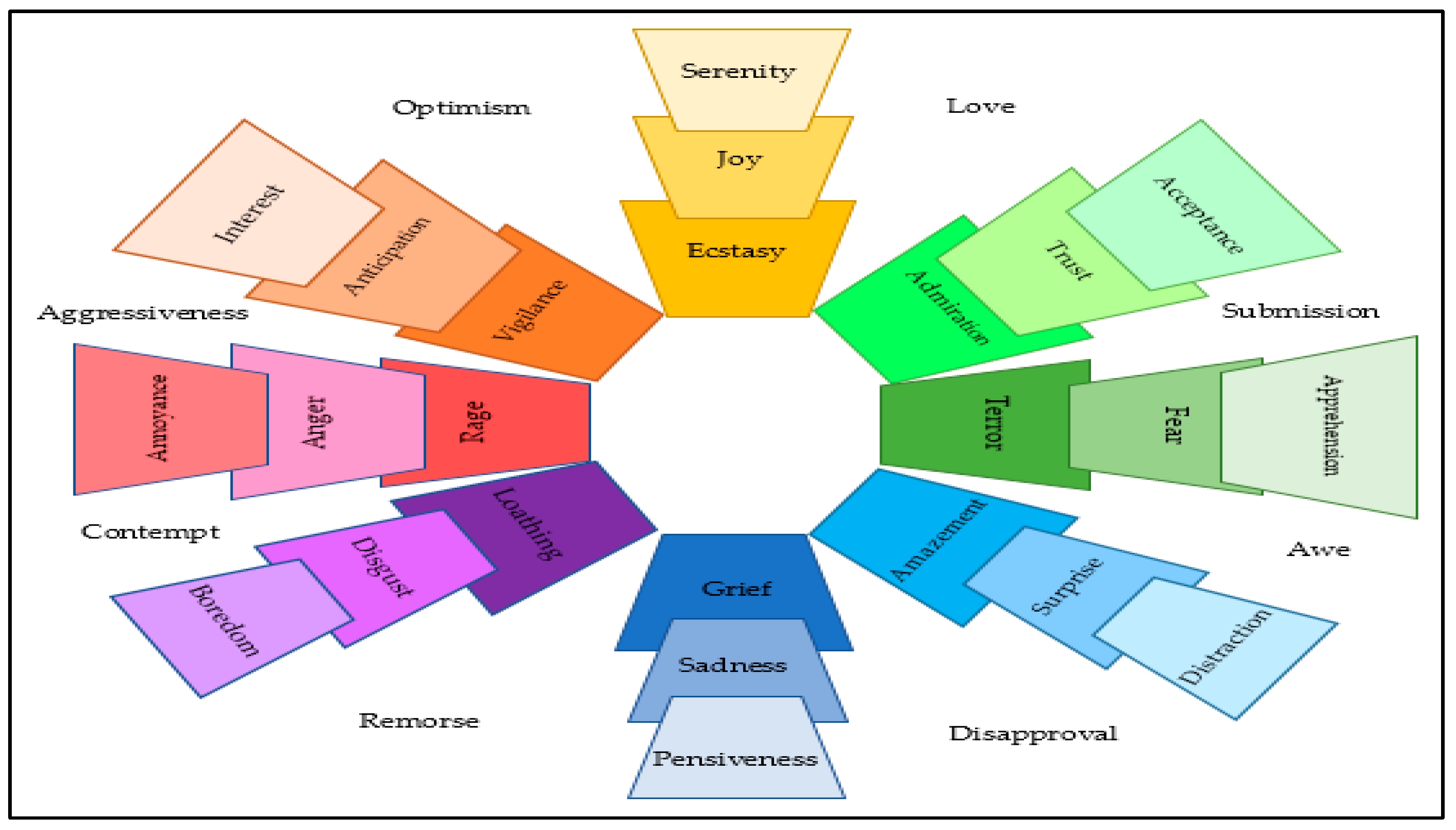
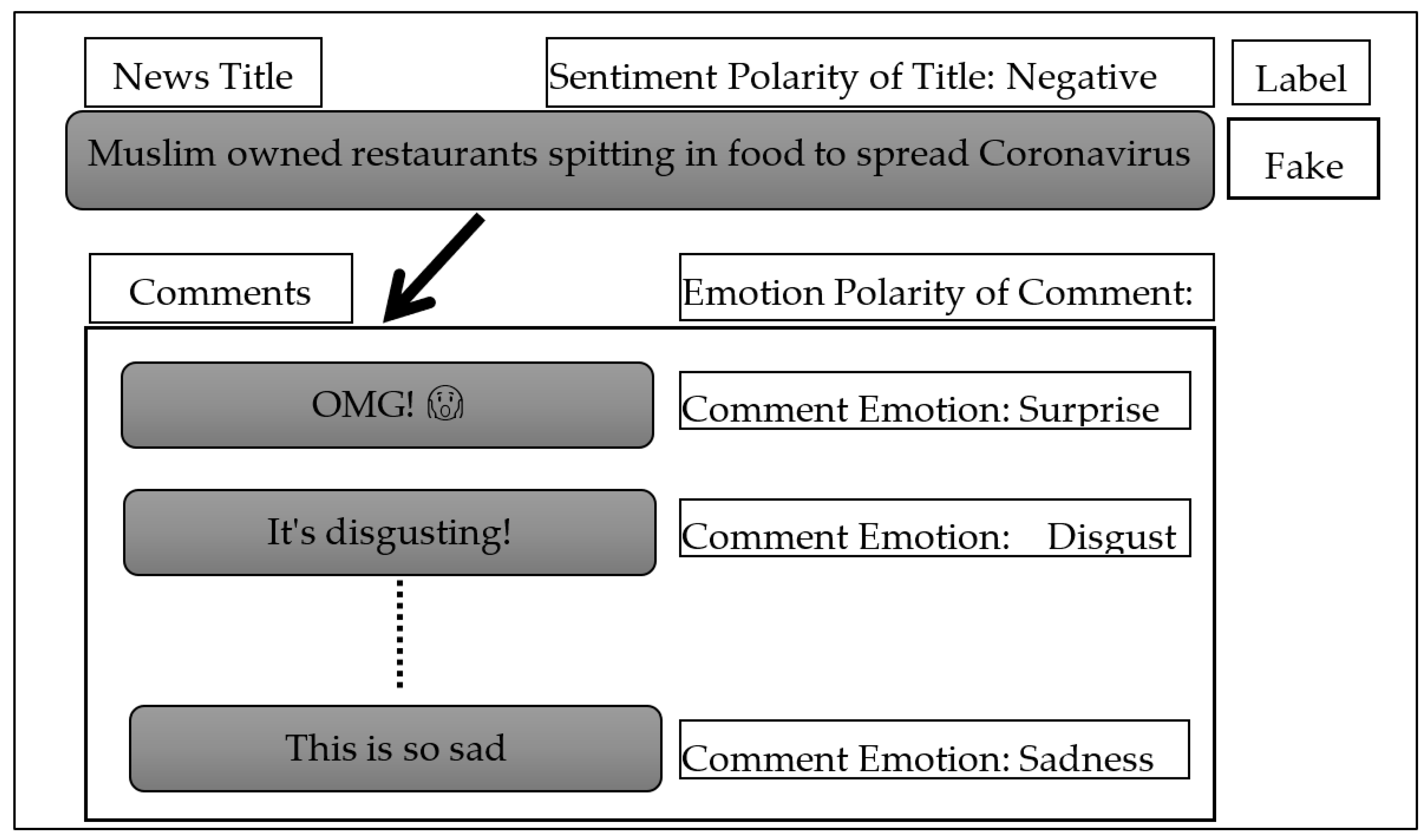
- The novelty group contains the emotions of (fear, disgust, and surprise).
- The expectation group contains the emotions of (anticipation, sadness, joy, and trust).
- The neutral group, in which the emotions of the novelty group are equal to the emotions of the expectation group.
- Analyzing each comment according to the emotions it carries based on NRCLex.
- Categorizing each comment to the group it belongs to (novelty, expectation, and neutral) based on emotional polarity.
- Grouping the comments for each piece of news based on ID.
- Assign the largest group (most frequent group) of all comments for each piece of news. In the case of equality between the two groups (novelty, expectation), we assign the neutral group to the news.
4.2.2. Sentiment Analysis Unit
4.2.3. Text Classification Unit
- i.
- Concatenation Layer
- ii.
- Dense Layer
4.3. Performance Evaluation
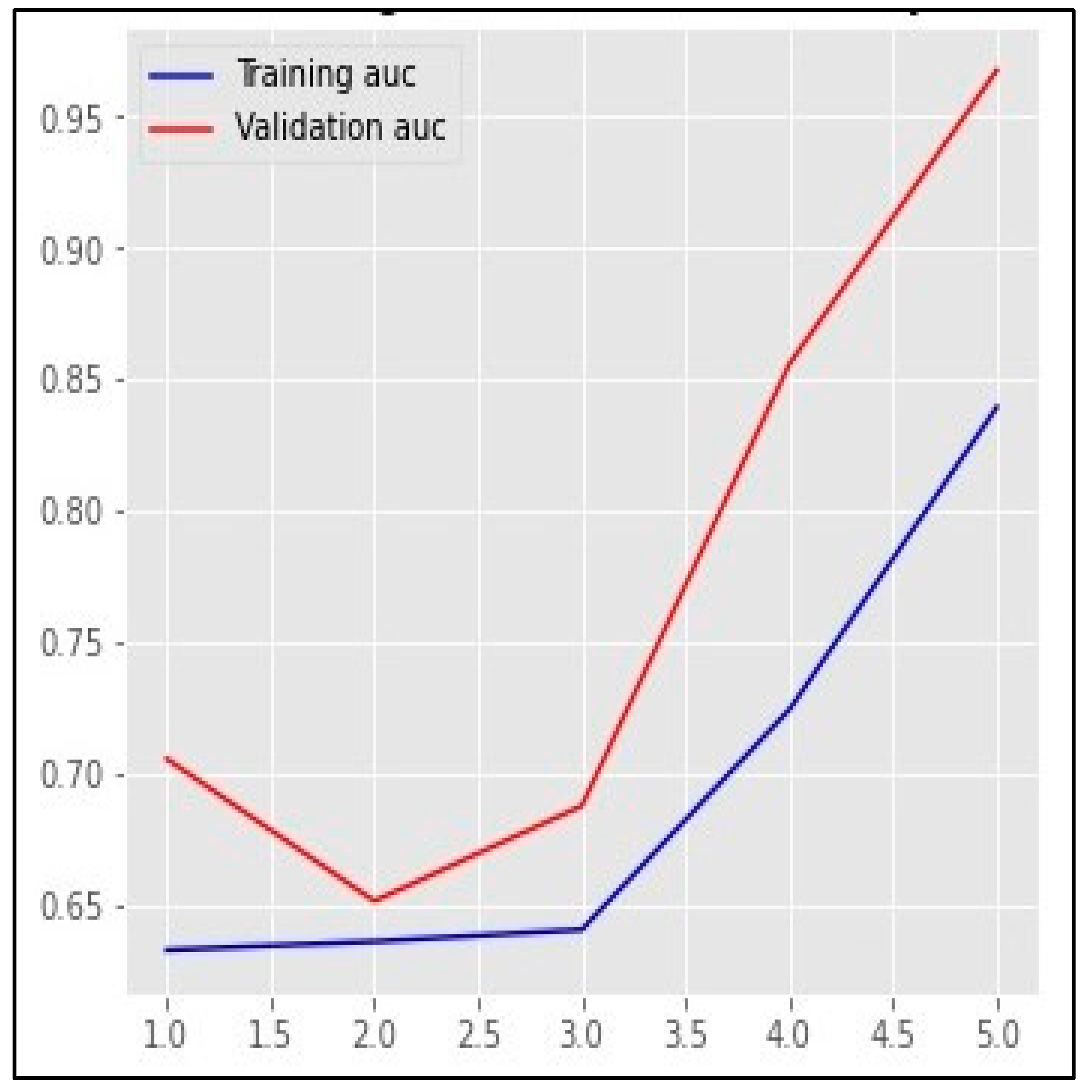
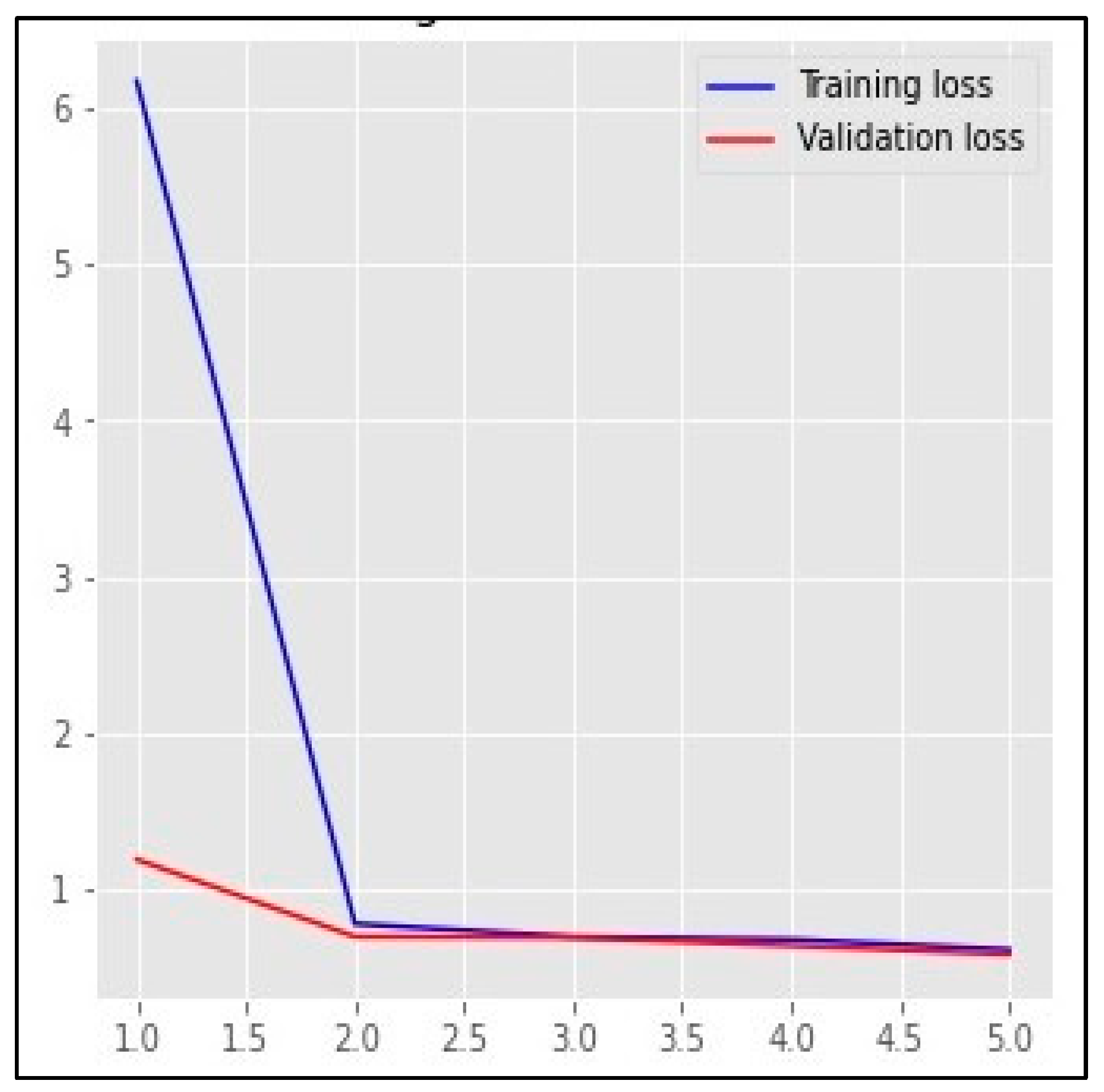
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shrivastava, G.; Kumar, P.; Ojha, R.P.; Srivastava, P.K.; Mohan, S.; Srivastava, G. Defensive modeling of fake news through online social networks. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1159–1167. [Google Scholar] [CrossRef]
- Ni, S.; Li, J.; Kao, H.-Y. HAT4RD: Hierarchical Adversarial Training for Rumor Detection in Social Media. Sensors 2022, 22, 6652. [Google Scholar] [CrossRef]
- Xu, K.; Wang, F.; Wang, H.; Yang, B. Detecting fake news over online social media via domain reputations and content understanding. Tsinghua Sci. Technol. 2019, 25, 20–27. [Google Scholar] [CrossRef]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake news detection using deep learning models: A novel approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Habib, A.; Asghar, M.Z.; Khan, A.; Habib, A.; Khan, A. False information detection in online content and its role in decision making: A systematic literature review. Soc. Netw. Anal. Min. 2019, 9, 50. [Google Scholar] [CrossRef]
- Rath, B.; Gao, W.; Ma, J.; Srivastava, J. Utilizing computational trust to identify rumor spreaders on Twitter. Soc. Netw. Anal. Min. 2018, 8, 64. [Google Scholar] [CrossRef]
- Xarhoulacos, C.-G.; Anagnostopoulou, A.; Stergiopoulos, G.; Gritzalis, D. Misinformation vs. Situational Awareness: The Art of Deception and the Need for Cross-Domain Detection. Sensors 2021, 21, 5496. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.-W. Fake news stance detection using deep learning architecture (cnn-lstm). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Atodiresei, C.-S.; Tănăselea, A.; Iftene, A. Identifying fake news and fake users on Twitter. Procedia Comput. Sci. 2018, 126, 451–461. [Google Scholar] [CrossRef]
- Liang, X.; Straub, J. Deceptive Online Content Detection Using Only Message Characteristics and a Machine Learning Trained Expert System. Sensors 2021, 21, 7083. [Google Scholar] [CrossRef]
- Pathuri, S.K.; Anbazhagan, N.; Joshi, G.P.; You, J. Feature-Based Sentimental Analysis on Public Attention towards COVID-19 Using CUDA-SADBM Classification Model. Sensors 2021, 22, 80. [Google Scholar] [CrossRef]
- Eke, C.I.; Norman, A.A.; Shuib, L.; Nweke, H.F. Sarcasm identification in textual data: Systematic review, research challenges and open directions. Artif. Intell. Rev. 2020, 53, 4215–4258. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Y.-F.B. Fned: A deep network for fake news early detection on social media. ACM Trans. Inf. Syst. (TOIS) 2020, 38, 1–33. [Google Scholar] [CrossRef]
- Lin, L.; Chen, Z. Social rumor detection based on multilayer transformer encoding blocks. Concurr. Comput. Pract. Exp. 2021, 33, e6083. [Google Scholar] [CrossRef]
- Goksu, M.; Cavus, N. Fake news detection on social networks with artificial intelligence tools: Systematic literature review. In Proceedings of the 10th International Conference on Theory and Application of Soft Computing, Computing with Words and Perceptions-ICSCCW-2019, Prague, Czech Republic, 27–28 August 2019; pp. 47–53. [Google Scholar]
- Ali, A.M.; Ghaleb, F.A.; Al-Rimy, B.A.S.; Alsolami, F.J.; Khan, A.I. Deep Ensemble Fake News Detection Model Using Sequential Deep Learning Technique. Sensors 2022, 22, 6970. [Google Scholar] [CrossRef] [PubMed]
- de Souza, J.V.; Gomes, J., Jr.; de Souza Filho, F.M.; de Oliveira Julio, A.M.; de Souza, J.F. A systematic mapping on automatic classification of fake news in social media. Soc. Netw. Anal. Min. 2020, 10, 48. [Google Scholar] [CrossRef]
- Guo, M.; Xu, Z.; Liu, L.; Guo, M.; Zhang, Y. An Adaptive Deep Transfer Learning Model for Rumor Detection without Sufficient Identified Rumors. Math. Probl. Eng. 2020, 2020, 7562567. [Google Scholar] [CrossRef]
- Varshney, D.; Vishwakarma, D.K. Vishwakarma, Hoax news-inspector: A real-time prediction of fake news using content resemblance over web search results for authenticating the credibility of news articles. J. Ambient Intell. Humaniz. Comput. 2020, 12, 8961–8974. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, H.K.; Kim, H.; Hong, J.B. Do Many Models Make Light Work? Evaluating Ensemble Solutions for Improved Rumor Detection. IEEE Access 2020, 8, 150709–150724. [Google Scholar] [CrossRef]
- Yaakub, M.R.; Latiffi, M.I.A.; Zaabar, L.S. A review on sentiment analysis techniques and applications. IOP Conf. Ser. Mater. Sci. Eng. 2019, 551, 012070. [Google Scholar] [CrossRef]
- Santhoshkumar, S.; Babu, L.D. Earlier detection of rumors in online social networks using certainty-factor-based convolutional neural networks. Soc. Netw. Anal. Min. 2020, 10, 20. [Google Scholar] [CrossRef]
- Tian, L.; Zhang, X.; Wang, Y.; Liu, H. Early detection of rumours on twitter via stance transfer learning. In Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020, Proceedings, Part I 42; Springer: Cham, Switzerland, 2020; Volume 12035, p. 575. [Google Scholar]
- Albahar, M. A hybrid model for fake news detection: Leveraging news content and user comments in fake news. IET Inf. Secur. 2021, 15, 169–177. [Google Scholar] [CrossRef]
- Alonso, M.A.; Vilares, D.; Gómez-Rodríguez, C.; Vilares, J. Sentiment analysis for fake news detection. Electronics 2021, 10, 1348. [Google Scholar] [CrossRef]
- Ghanem, B.; Rosso, P.; Rangel, F. An emotional analysis of false information in social media and news articles. ACM Trans. Internet Technol. (TOIT) 2020, 20, 1–18. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Kumari, R.; Ashok, N.; Ghosal, T.; Ekbal, A. What the fake? Probing misinformation detection standing on the shoulder of novelty and emotion. Inf. Process. Manag. 2022, 59, 102740. [Google Scholar] [CrossRef]
- Zhang, X.; Cao, J.; Li, X.; Sheng, Q.; Zhong, L.; Shu, K. Mining dual emotion for fake news detection. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3465–3476. [Google Scholar]
- Zimbra, D.; Abbasi, A.; Zeng, D.; Chen, H. The state-of-the-art in Twitter sentiment analysis: A review and benchmark evaluation. ACM Trans. Manag. Inf. Syst. (TMIS) 2018, 9, 1–29. [Google Scholar] [CrossRef]
- Feng, Z. Hot news mining and public opinion guidance analysis based on sentiment computing in network social media. Pers. Ubiquitous Comput. 2019, 23, 373–381. [Google Scholar] [CrossRef]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-cultural polarity and emotion detection using sentiment analysis and deep learning on COVID-19 related tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef]
- Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An effective BERT-based pipeline for Twitter sentiment analysis: A case study in Italian. Sensors 2020, 21, 133. [Google Scholar] [CrossRef]
- Dang, C.N.; Moreno-García, M.N.; Prieta, F.D.L. An approach to integrating sentiment analysis into recommender systems. Sensors 2021, 21, 5666. [Google Scholar] [CrossRef]
- Islam, M.R.; Liu, S.; Wang, X.; Xu, G. Deep learning for misinformation detection on online social networks: A survey and new perspectives. Soc. Netw. Anal. Min. 2020, 10, 82. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Hu, Q.; Lu, Y.; Yang, Y.; Cheng, J. Multi-level word features based on CNN for fake news detection in cultural communication. Pers. Ubiquitous Comput. 2020, 24, 259–272. [Google Scholar]
- Correia, F.; Madureira, A.M.; Bernardino, J. Deep Neural Networks Applied to Stock Market Sentiment Analysis. Sensors 2022, 22, 4409. [Google Scholar] [CrossRef] [PubMed]
- Bahad, P.; Saxena, P.; Kamal, R. Fake News Detection using Bi-directional LSTM-Recurrent Neural Network. Procedia Comput. Sci. 2019, 165, 74–82. [Google Scholar] [CrossRef]
- Subramani, S.; Wang, H.; Vu, H.Q.; Li, G. Domestic violence crisis identification from facebook posts based on deep learning. IEEE Access 2018, 6, 54075–54085. [Google Scholar] [CrossRef]
- Alkhodair, S.A.; Ding, S.H.; Fung, B.C.; Liu, J. Detecting breaking news rumors of emerging topics in social media. Inf. Process. Manag. 2020, 57, 102018. [Google Scholar] [CrossRef]
- Al-Rakhami, M.S.; Al-Amri, A.M. Lies Kill, Facts Save: Detecting COVID-19 Misinformation in Twitter. IEEE Access 2020, 8, 155961–155970. [Google Scholar] [CrossRef]
- Aldayel, A.; Magdy, W. Your stance is exposed! analysing possible factors for stance detection on social media. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–20. [Google Scholar] [CrossRef]
- Zubair, T.; Raquib, A.; Qadir, J. Combating Fake News, Misinformation, and Machine Learning Generated Fakes: Insight’s from the Islamic Ethical Tradition. ICR J. 2019, 10, 189–212. [Google Scholar] [CrossRef]
- de Oliveira, N.R.; Medeiros, D.S.; Mattos, D.M. A sensitive stylistic approach to identify fake news on social networking. IEEE Signal Process. Lett. 2020, 27, 1250–1254. [Google Scholar] [CrossRef]
- Kapusta, J.; Hájek, P.; Munk, M.; Benko, Ľ. Comparison of fake and real news based on morphological analysis. Procedia Comput. Sci. 2020, 171, 2285–2293. [Google Scholar] [CrossRef]
- Zhou, X.; Jain, A.; Phoha, V.V.; Zafarani, R. Fake news early detection: A theory-driven model. Digit. Threat. Res. Pract. 2020, 1, 1–25. [Google Scholar] [CrossRef]
- DataReportal. Digital 2021 Global Digital Overview; DataReportal: Singapore, 2021. [Google Scholar]
- Machová, K.; Mach, M.; Porezaný, M. Deep Learning in the Detection of Disinformation about COVID-19 in Online Space. Sensors 2022, 22, 9319. [Google Scholar] [CrossRef]
- Sansonetti, G.; Gasparetti, F.; D’aniello, G.; Micarelli, A. Unreliable Users Detection in Social Media: Deep Learning Techniques for Automatic Detection. IEEE Access 2020, 8, 213154–213167. [Google Scholar] [CrossRef]
- Tchakounté, F.; Calvin, K.A.; Ari, A.A.A.; Mbogne, D.J.F.J.J.o.K.S.U.-C.; Sciences, I. A smart contract logic to reduce hoax propagation across social media. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 3070–3078. [Google Scholar] [CrossRef]
- Lee, S.; Shafqat, W.; Kim, H.-c. Backers Beware: Characteristics and Detection of Fraudulent Crowdfunding Campaigns. Sensors 2022, 22, 7677. [Google Scholar] [CrossRef]
- Evolvi, G. Hate in a tweet: Exploring internet-based islamophobic discourses. Religions 2018, 9, 307. [Google Scholar] [CrossRef]
- Al-Makhadmeh, Z.; Tolba, A. Automatic hate speech detection using killer natural language processing optimizing ensemble deep learning approach. Computing 2020, 102, 501–522. [Google Scholar] [CrossRef]
- Garzia, F.; Borghini, F.; Bruni, A.; Lombardi, M.; Minò, L.; Ramalingam, S.; Tricarico, G. Sentiment and emotional analysis of risk perception in the Herculaneum Archaeological Park during COVID-19 pandemic. Sensors 2022, 22, 8138. [Google Scholar] [CrossRef] [PubMed]
- Latiffi, M.I.A.; Yaakub, M.R. Sentiment analysis: An enhancement of ontological-based using hybrid machine learning techniques. Asian J. Inf. Technol. 2018, 7, 61–69. [Google Scholar] [CrossRef]
- Prottasha, N.J.; Sami, A.A.; Kowsher, M.; Murad, S.A.; Bairagi, A.K.; Masud, M.; Baz, M. Transfer Learning for Sentiment Analysis Using BERT Based Supervised Fine-Tuning. Sensors 2022, 22, 4157. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.S.; Bakar, A.A.; Yaakub, M.R.; Darwich, M. Beyond sentiment classification: A novel approach for utilizing social media data for business intelligence. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 437–441. [Google Scholar] [CrossRef]
- Wang, J.-H.; Liu, T.-W.; Luo, X. Combining Post Sentiments and User Participation for Extracting Public Stances from Twitter. Appl. Sci. 2020, 10, 8035. [Google Scholar] [CrossRef]
- Kumar, Y.; Goel, N. AI-Based Learning Techniques for Sarcasm Detection of Social Media Tweets: State-of-the-Art Survey. SN Comput. Sci. 2020, 1, 318. [Google Scholar] [CrossRef]
- Ho, T.-T.; Huang, Y. Stock Price Movement Prediction Using Sentiment Analysis and CandleStick Chart Representation. Sensors 2021, 21, 7957. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, W.; Li, J.; Mai, F.; Ma, Z. Effect of online review sentiment on product sales: The moderating role of review credibility perception. Comput. Hum. Behav. 2022, 133, 107272. [Google Scholar] [CrossRef]
- Bhutani, B.; Rastogi, N.; Sehgal, P.; Purwar, A. Fake news detection using sentiment analysis. In Proceedings of the 2019 Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–5. [Google Scholar]
- Paschen, J. Investigating the emotional appeal of fake news using artificial intelligence and human contributions. J. Prod. Brand Manag. 2019, 29, 223–233. [Google Scholar] [CrossRef]
- Zhao, J.; Dong, W.; Shi, L.; Qiang, W.; Kuang, Z.; Xu, D.; An, T. Multimodal Feature Fusion Method for Unbalanced Sample Data in Social Network Public Opinion. Sensors 2022, 22, 5528. [Google Scholar] [CrossRef]
- Ahmad, I.S.; Bakar, A.A.; Yaakub, M.R.; Muhammad, S.H. A survey on machine learning techniques in movie revenue prediction. SN Comput. Sci. 2020, 1, 235. [Google Scholar] [CrossRef]
- Angel Deborah, S.; Mirnalinee, T.; Rajendram, S.M. Emotion analysis on text using multiple kernel gaussian. Neural Process. Lett. 2021, 53, 1187–1203. [Google Scholar] [CrossRef]
- Arnold, M.B. Emotion and Personality; List, H.B., Ed.; Columbia University Press: New York, NY, USA, 1960; Volume 1. [Google Scholar]
- Plutchik, R. A general psychoevolutionary theory of emotion. In Theories of Emotion; Elsevier: Amsterdam, The Netherlands, 1980; pp. 3–33. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Parrott, W.G. Emotions in Social Psychology: Essential Readings; Psychology Press: London, UK, 2001. [Google Scholar]
- Giachanou, A.; Rosso, P.; Crestani, F. Leveraging emotional signals for credibility detection. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 877–880. [Google Scholar]
- Ajao, O.; Bhowmik, D.; Zargari, S. Sentiment aware fake news detection on online social networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2507–2511. [Google Scholar]
- Kukkar, A.; Mohana, R.; Nayyar, A.; Kim, J.; Kang, B.-G.; Chilamkurti, N. A novel deep-learning-based bug severity classification technique using convolutional neural networks and random forest with boosting. Sensors 2019, 19, 2964. [Google Scholar] [CrossRef]
- Hsu, J.-L.; Hsu, T.-J.; Hsieh, C.-H.; Singaravelan, A. Applying convolutional neural networks to predict the ICD-9 codes of medical records. Sensors 2020, 20, 7116. [Google Scholar] [CrossRef]
- Nakamura, K.; Levy, S.; Wang, W.Y. r/fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection. arXiv 2019, arXiv:1911.03854. [Google Scholar]
- Kaliyar, R.K.; Kumar, P.; Kumar, M.; Narkhede, M.; Namboodiri, S.; Mishra, S. DeepNet: An efficient neural network for fake news detection using news-user engagements. In Proceedings of the 2020 5th International Conference on Computing, Communication and Security (ICCCS), Patna, India, 14–16 October 2020; pp. 1–6. [Google Scholar]
- Kirchknopf, A.; Slijepčević, D.; Zeppelzauer, M. Multimodal Detection of Information Disorder from Social Media. In Proceedings of the 2021 International Conference on Content-Based Multimedia Indexing (CBMI), Lille, France, 28–30 June 2021; pp. 1–4. [Google Scholar]
- Xie, J.; Liu, S.; Liu, R.; Zhang, Y.; Zhu, Y. SeRN: Stance extraction and reasoning network for fake news detection. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2520–2524. [Google Scholar]
- Raza, S.; Ding, C. Fake news detection based on news content and social contexts: A transformer-based approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word–emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Chang, W.-L.; Tseng, H.-C. The impact of sentiment on content post popularity through emoji and text on social platforms. In Cyber Influence and Cognitive Threats; Elsevier: Amsterdam, The Netherlands, 2020; pp. 159–184. [Google Scholar]
- Batbaatar, E.; Li, M.; Ryu, K.H. Semantic-emotion neural network for emotion recognition from text. IEEE Access 2019, 7, 111866–111878. [Google Scholar] [CrossRef]
- Ilie, V.-I.; Truică, C.-O.; Apostol, E.-S.; Paschke, A. Context-Aware Misinformation Detection: A Benchmark of Deep Learning Architectures Using Word Embeddings. IEEE Access 2021, 9, 162122–162146. [Google Scholar] [CrossRef]
- Kumar, A.; Sangwan, S.R.; Arora, A.; Nayyar, A.; Abdel-Basset, M. Sarcasm detection using soft attention-based bidirectional long short-term memory model with convolution network. IEEE Access 2019, 7, 23319–23328. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Akkaradamrongrat, S.; Kachamas, P.; Sinthupinyo, S. Text generation for imbalanced text classification. In Proceedings of the 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), Chonburi, Thailand, 10–12 July 2019; pp. 181–186. [Google Scholar]
- Rupapara, V.; Rustam, F.; Shahzad, H.F.; Mehmood, A.; Ashraf, I.; Choi, G.S. Impact of SMOTE on imbalanced text features for toxic comments classification using RVVC model. IEEE Access 2021, 9, 78621–78634. [Google Scholar] [CrossRef]
- Suhaimi, N.S.; Othman, Z.; Yaakub, M.R. Comparative Analysis Between Macro and Micro-Accuracy in Imbalance Dataset for Movie Review Classification. In Proceedings of the Seventh International Congress on Information and Communication Technology (ICICT 2022), London, UK, 21–24 February 2022; pp. 83–93. [Google Scholar]
- Nakamura, K.; Hong, B.-W. Adaptive weight decay for deep neural networks. IEEE Access 2019, 7, 118857–118865. [Google Scholar] [CrossRef]
- Hahn, S.; Choi, H. Understanding dropout as an optimization trick. Neurocomputing 2020, 398, 64–70. [Google Scholar] [CrossRef]
- Agarwal, A.; Mittal, M.; Pathak, A.; Goyal, L.M. Fake news detection using a blend of neural networks: An application of deep learning. SN Comput. Sci. 2020, 1, 143. [Google Scholar] [CrossRef]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. batch normalization: An empirical study of their impact to deep learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Elhadad, M.K.; Li, K.F.; Gebali, F. Detecting Misleading Information on COVID-19. IEEE Access 2020, 8, 165201–165215. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Details Related to Social Media Users | Number or Percentage |
|---|---|
| Total number of active social media users | 4.20 Billion |
| Social media users as a percentage of the global population | 53.60% |
| Annual change in the number of global social media users | +13.2% (+490 Million) |
| Total number of social medias accessing via mobile phones | 4.15 Billion |
| Percentage of total social media users accessing via mobile | 98.80% |
| Feature | Description |
|---|---|
| Author | A person or bot that registers on social networking sites. |
| Title | The title or brief description of the post. |
| Domain | The source of news. |
| Has_image | The post whether attached with an image or not. |
| Id | The ID of the post. |
| Num_comments | The number of comments on the post; this feature represents the level of popularity of the post. |
| Score | The numerical score another user gives to the post; This feature shows if another user approves or declines to share the post. |
| Upvote_ratio | A value representing an estimate of the approval/disapproval of other users on posts. |
| Body | The content of the comment. |
| Group Name | Emotion Categories of the Group | Normalized Label |
|---|---|---|
| Novelty | Fear, disgust, surprise | 1 |
| Expectation | Anticipation, sadness, joy, trust | 0 |
| Neutral | (Fear, disgust, surprise) = (anticipation, sadness, joy, trust) | 0.5 |
| No. | Structure or Hyperparameter Name | Type or Value |
|---|---|---|
| 1 | Layers | Embedding layer Bidirectional LSTM layer Dense layer |
| 2 | Word embedding dimension | 300 |
| 3 | No. of hidden states | 128 |
| 4 | Dropout | 0.2 |
| 5 | Recurrent dropout | 0.2 |
| 6 | Regularizer L1 | 0.0001 |
| 7 | Regularizer L2 | 0.001 |
| 8 | Activation function | Sigmoid |
| 9 | Loss function | Binary_Crossentropy |
| 10 | Optimizer | Adam |
| 11 | Learning rate | 0.1 |
| 12 | Batch size | 256 |
| 13 | No. of epochs | 5 |
| Model | Textual Content Features (News Titles) | Features Based on Titles’ Sentiment | Features Based on Comments’ Emotions | AUC | F1-Score |
|---|---|---|---|---|---|
| LSTM | √ | 89.99% | 90.98% | ||
| LSTM | √ | √ | √ | 90.16% | 91.78% |
| GRU | √ | 91.65% | 92.23% | ||
| GRU | √ | √ | √ | 92.60% | 94.09% |
| CNN | √ | 94.14% | 96.39% | ||
| CNN | √ | √ | √ | 96.05% | 97.76% |
| BI-LSTM | √ | 94.65% | 95.54% | ||
| BI-LSTM | √ | √ | √ | 96.77% | 97.81% |
| Study | Model | Textual Content | Visual Content | Social-Based Features | Metadata-Based Features | Comments-Based Features | Emotions-Based Features | Sentiments-Based Features |
|---|---|---|---|---|---|---|---|---|
| Nakamura, Levy [76] | BERT + ResNet50 | √ | √ | √ | √ | √ | ||
| Kaliyar, Kumar [77] | DeepNet | √ | √ | |||||
| Kirchknopf, Slijepčević [78] | Multimodal architecture (BERT + CNN + MLP) | √ | √ | √ | √ | √ | ||
| Xie, Liu [79] | SERN model based on (BERT + ResNet + MLP) | √ | √ | √ | ||||
| Raza and Ding [80] | FND-NS model based on BART | √ | √ | √ | √ | |||
| Our Proposed Model | Bi-LSTM model | √ | √ | √ | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamed, S.K.; Ab Aziz, M.J.; Yaakub, M.R. Fake News Detection Model on Social Media by Leveraging Sentiment Analysis of News Content and Emotion Analysis of Users’ Comments. Sensors 2023, 23, 1748. https://doi.org/10.3390/s23041748
Hamed SK, Ab Aziz MJ, Yaakub MR. Fake News Detection Model on Social Media by Leveraging Sentiment Analysis of News Content and Emotion Analysis of Users’ Comments. Sensors. 2023; 23(4):1748. https://doi.org/10.3390/s23041748
Chicago/Turabian StyleHamed, Suhaib Kh., Mohd Juzaiddin Ab Aziz, and Mohd Ridzwan Yaakub. 2023. "Fake News Detection Model on Social Media by Leveraging Sentiment Analysis of News Content and Emotion Analysis of Users’ Comments" Sensors 23, no. 4: 1748. https://doi.org/10.3390/s23041748
APA StyleHamed, S. K., Ab Aziz, M. J., & Yaakub, M. R. (2023). Fake News Detection Model on Social Media by Leveraging Sentiment Analysis of News Content and Emotion Analysis of Users’ Comments. Sensors, 23(4), 1748. https://doi.org/10.3390/s23041748