

An Adaptive ORB-SLAM3 System for Outdoor Dynamic Environments

Abstract
1. Introduction
- We proposed an adaptive feature point system to enhance the accuracy of ORB-SLAM systems in dynamic environments. This system utilizes YOLOv5s with coordinate attention to detect dynamic objects a priori in the frame and is combined with the LK optical flow method for accurate determination of dynamic areas. Additionally, an adaptive feature point selector is proposed to remove dynamic feature points based on the frame share and the number of a priori dynamic objects bounding boxes in the current frame. By utilizing only static feature points for mapping, the mapping error of the system in dynamic environments is reduced.
- In the adaptive feature point selector, we proposed a geometric method for identifying dynamic regions. We calculate the infinitesimal parametrization of the essential matrix of feature points within the bounding box and the bounding box expansion layers, and determine the dynamic region based on the ratio of the two infinitesimal parametrizations.
2. Materials and Methods
2.1. System Framework
2.2. YOLOv5 with Coordinate Attention
2.3. Adaptive Feature Points Selector
| Algorithm 1: Adaptive dynamic feature point selection strategy. |
Input: Original feature point, Bounding box Output: Static feature point 1: if feature points in the boundingbox then 2: Use LK optical flow to match a prior dynamic objects between frames 3: if a priori dynamic object screen share ≥ 50% then 4: Determine if the number of a priori dynamic objects is greater than the threshold 5: if number of a prior dynamic objects ≥ 5 then 6: Calculate essential matrix of prior dynamic region bwtween frame 7: Calculating infinite norms of essential matrix 8: Calculate the essential matrix of the expansion layer bwtween frame 9: Calculating infinite norms of essential matrix 10: if ratio of two infinite norm is greater than the threshold value then 11: Delete dynamic feature points 12: else 13: ORB matches 14: end if 15: end if 16: end if 17: end if 18: return Outputs |
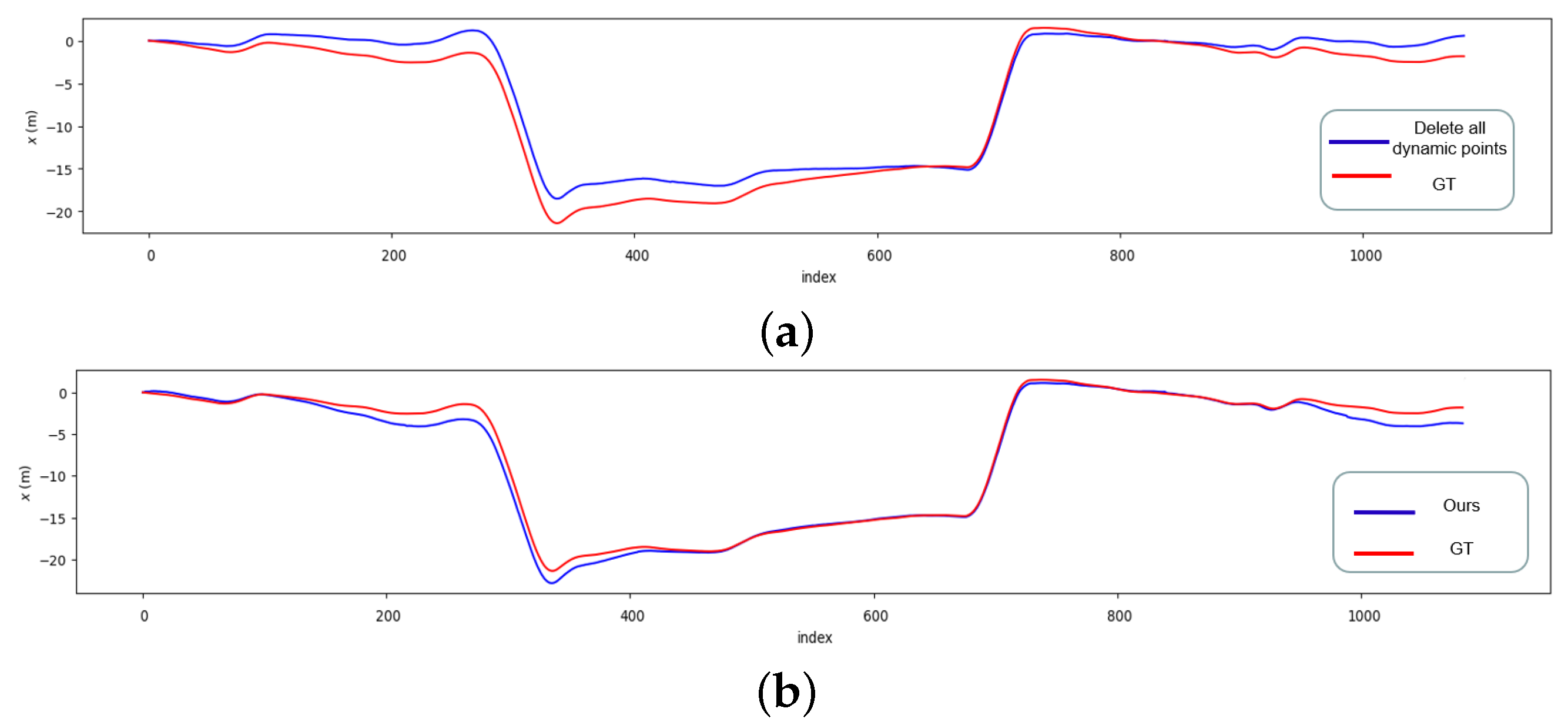
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| APE | Absolute pose error |
| RPE | Relative pose error |
| RANSAC | RANdom SAmple Consensus |
| SLAM | Simultaneous localization and mapping |
| VSLAM | Visual simultaneous localization and mapping system |
| ROS | Robot Operating System |
| GT | Ground truth |
| KITTI | Karlsruhe Institute of Technology and Toyota Technological Institute |
| VINS | Visual–inertial navigation systems |
| VDO | Visual Dynamic Object-aware |
| TANDEM | Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo |
| TSDF | Truncated signed distance function |
| GMM | Gaussian mixture model |
| CIOU | Complete Intersection over Union |
References
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Koestler, L.; Yang, N.; Zeller, N.; Cremers, D. Tandem: Tracking and dense mapping in real-time using deep multi-view stereo. In Conference on Robot Learning; PMLR: London, UK, 2022; pp. 34–45. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Cheng, J.; Zhang, L.; Chen, Q.; Hu, X.; Cai, J. A review of visual SLAM methods for autonomous driving vehicles. Eng. Appl. Artif. Intell. 2022, 114, 104992. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Gu, D. Ongoing evolution of visual slam from geometry to deep learning: Challenges and opportunities. Cogn. Comput. 2018, 10, 875–889. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Yao, E.; Zhang, H.; Song, H.; Zhang, G. Fast and robust visual odometry with a low-cost IMU in dynamic environments. Ind. Robot. Int. J. Robot. Res. Appl. 2019, 46, 882–894. [Google Scholar] [CrossRef]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. VDO-SLAM: A visual dynamic object-aware SLAM system. arXiv 2020, arXiv:2005.11052. [Google Scholar]
- Zhang, C.; Huang, T.; Zhang, R.; Yi, X. PLD-SLAM: A new RGB-D SLAM method with point and line features for indoor dynamic scene. ISPRS Int. J. -Geo-Inf. 2021, 10, 163. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-coupled multi-object tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Wu, W.; Guo, L.; Gao, H.; You, Z.; Liu, Y.; Chen, Z. YOLO-SLAM: A semantic SLAM system towards dynamic environment with geometric constraint. Neural Comput. Appl. 2022, 34, 6011–6026. [Google Scholar] [CrossRef]
- Liu, J.; Gu, Q.; Chen, D.; Yan, D. VSLAM method based on object detection in dynamic environments. Front. Neurorobotics 2022, 16. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, R.; Wang, X. Visual slam mapping based on yolov5 in dynamic scenes. Appl. Sci. 2022, 12, 11548. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, S.; Huang, G.; Bai, L.; Li, Q. WF-SLAM: A Robust VSLAM for Dynamic Scenarios via Weighted Features. IEEE Sens. J. 2022. [Google Scholar] [CrossRef]
- Chen, B.; Peng, G.; He, D.; Zhou, C.; Hu, B. Visual SLAM Based on Dynamic Object Detection. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 5966–5971. [Google Scholar]
- Han, S.; Xi, Z. Dynamic scene semantics SLAM based on semantic segmentation. IEEE Access 2020, 8, 43563–43570. [Google Scholar] [CrossRef]
- Wolf, L.; Hassner, T.; Taigman, Y. Descriptor based methods in the wild. In Proceedings of the Workshop on Faces in’Real-Life’images: Detection, Alignment, and Recognition, Marseille, France, 10 May 2008. [Google Scholar]
- Xu, Z.; Rong, Z.; Wu, Y. A survey: Which features are required for dynamic visual simultaneous localization and mapping? Vis. Comput. Ind. Biomed. Art 2021, 4, 20. [Google Scholar] [CrossRef]
- Yang, S.; Scherer, S. Cubeslam: Monocular 3-d object slam. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Qian, R.; Lai, X.; Li, X. 3D object detection for autonomous driving: A survey. Pattern Recognit. 2022, 108796. [Google Scholar] [CrossRef]
- Chang, Z.; Wu, H.; Sun, Y.; Li, C. RGB-D Visual SLAM Based on Yolov4-Tiny in Indoor Dynamic Environment. Micromachines 2022, 13, 230. [Google Scholar] [CrossRef] [PubMed]
- Fraundorfer, F.; Scaramuzza, D. Visual odometry: Part i: The first 30 years and fundamentals. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar]
- Wan Aasim, W.F.A.; Okasha, M.; Faris, W.F. Real-Time Artificial Intelligence Based Visual Simultaneous Localization and Mapping in Dynamic Environments—A Review. J. Intell. Robot. Syst. 2022, 105, 15. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Cui, L.; Ma, C. Sof-slam: A semantic visual slam for dynamic environments. IEEE Access 2019, 7, 166528–166539. [Google Scholar] [CrossRef]
- Ai, Y.; Rui, T.; Lu, M.; Fu, L.; Liu, S.; Wang, S. DDL-SLAM: A robust RGB-D SLAM in dynamic environments combined with deep learning. IEEE Access 2020, 8, 162335–162342. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19 June 2021; pp. 13713–13722. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ international conference on intelligent robots and systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Advantages | Disadvantages |
|---|---|---|
| VDO-SLAM [10] | VDO-SLAM uses semantic information for accurate motion estimation and tracking of dynamic rigid objects, without prior knowledge of shape or models. | A significant quantity of dynamic objects in the scene increases system computational demands. |
| PLD-SLAM [11] | PLD-SLAM improves trajectory estimation in dynamic environments by using point and line features and two consistency check techniques to filter dynamic features. | Identifying potential dynamic objects incurs significant computation time. |
| DS-SLAM [12] | DS-SLAM reduces trajectory errors by combining semantic segmentation networks and motion consistency checking and generates a dense semantic octree map. | Upon detection of loop closure, the octree map must be reconstructed. |
| DynaSLAM [13] | Dynaslam constructs an static scene map by repairing parts of the background that have been obscured by dynamic objects. Trajectories of the system exhibit a very high degree of precision. | The performance of the system is hindered by the utilization of a CNN network, resulting in a lack of real-time capability. |
| Zhang et al.’s system [17] | Use YOLOv5 with optical flow method to determine dynamic objects and use key frames to build maps, reducing trajectory errors. | Dynamic objects that are stationary for a long time can cause background blurring and thus cause. |
| Model | AP | mAP@0.5 | ||
|---|---|---|---|---|
| Car | Pedestrian | Cyclist | ||
| YOLOv5 | 0.963 | 0.82 | 0.835 | 0.873 |
| YOLOv5 with | ||||
| Coordinate Attention | 0.961 | 0.826 | 0.862 | 0.883 |
| YOLOv5 with | ||||
| transformer | 0.962 | 0.824 | 0.853 | 0.879 |
| YOLOv5 with | ||||
| transformer and CA | 0.958 | 0.805 | 0.863 | 0.875 |
| YOLOv5 with | ||||
| C3SE | 0.960 | 0.803 | 0.862 | 0.875 |
| YOLOv5 with | ||||
| CBAM | 0.963 | 0.818 | 0.852 | 0.877 |
| YOLOv5 with | ||||
| CBAM and C3SE | 0.960 | 0.804 | 0.875 | 0.879 |
| Model | AP | mAP@0.5 | ||
|---|---|---|---|---|
| Car | Pedestrian | Cyclist | ||
| YOLOv5 with | ||||
| Coordinate Attention | 0.959 | 0.824 | 0.849 | 0.878 |
| Sequences | 1 Pixel | 2 Pixel | 3 Pixel |
|---|---|---|---|
| 04 | 0.19 | 0.20 | 0.21 |
| 06 | 0.73 | 1.16 | 1.19 |
| Sequences | Threshold 3 | Threshold 4 | Threshold 5 | Threshold 6 |
|---|---|---|---|---|
| 00 | 2.443 | 2.717 | 1.630 | 1.650 |
| 01 | 3.522 | 3.979 | 5.291 | 3.988 |
| 02 | 4.605 | 7.057 | 5.572 | 7.453 |
| 04 | 0.204 | 0.207 | 0.198 | 0.277 |
| 05 | 1.160 | 1.425 | 1.107 | 1.498 |
| 06 | 1.209 | 1.270 | 1.185 | 1.197 |
| 07 | 0.640 | 0.627 | 0.628 | 0.709 |
| 09 | 1.249 | 1.209 | 1.241 | 1.236 |
| 10 | 1.372 | 1.441 | 1.278 | 1.593 |
| Sequences | ORB_SLAM3 | Delete All Dynamic Points | Geometric Method | Ours |
|---|---|---|---|---|
| 00 | 1.92 | 1.69 | 2.28 | 1.64 |
| 01 | 6.31 | 5.94 | 4.86 | 6.72 |
| 02 | 5.41 | 6.37 | 5.04 | 5.35 |
| 04 | 0.22 | 0.22 | 0.2 | 0.19 |
| 05 | 0.99 | 1.02 | 1.01 | 0.94 |
| 06 | 1.2 | 0.88 | 0.92 | 0.73 |
| 07 | 0.63 | 0.5 | 0.63 | 0.62 |
| 09 | 0.99 | 1.23 | 1.18 | 1.17 |
| 10 | 1.46 | 1.2 | 1.47 | 1.25 |
| ORB_SLAM3 | Delete All Dynamic Points | Geometric Method | Ours | |||||
|---|---|---|---|---|---|---|---|---|
| Sequences | RPE[%] | RPE[°/100M] | RPE[%] | RPE[°/100M] | RPE[%] | RPE[°/100M] | RPE[%] | RPE[°/100M] |
| 00 | 5.23 | 1.85 | 5.82 | 2.02 | 5.04 | 1.78 | 5.07 | 1.76 |
| 01 | 1.6 | 0.36 | 1.6 | 0.35 | 1.57 | 0.33 | 1.55 | 0.35 |
| 02 | 1.82 | 0.46 | 2.47 | 0.83 | 2.4 | 0.68 | 2.01 | 0.58 |
| 04 | 1.65 | 0.2 | 1.65 | 0.21 | 1.65 | 0.18 | 1.54 | 0.14 |
| 05 | 1.21 | 0.41 | 1.09 | 0.31 | 1.65 | 0.57 | 1.37 | 0.44 |
| 06 | 1.41 | 0.32 | 1.45 | 0.25 | 1.41 | 0.36 | 1.27 | 0.25 |
| 07 | 1.48 | 0.58 | 1.1 | 0.36 | 1.24 | 0.47 | 1.5 | 0.58 |
| 09 | 1.42 | 0.39 | 1.63 | 0.47 | 1.6 | 0.45 | 1.48 | 0.39 |
| 10 | 1.48 | 0.56 | 1.46 | 0.54 | 1.47 | 0.58 | 1.44 | 0.55 |
| Sequences | ORB_SLAM3 | DynaSLAM | Ours |
|---|---|---|---|
| 00 | 1.92 | 1.3 | 1.64 |
| 01 | 6.31 | 10.47 | 6.72 |
| 02 | 5.41 | 5.73 | 5.35 |
| 04 | 0.22 | 0.22 | 0.19 |
| 05 | 0.99 | 0.83 | 0.94 |
| 06 | 1.2 | 0.76 | 0.73 |
| 07 | 0.63 | 0.52 | 0.62 |
| 09 | 0.99 | 3.08 | 1.17 |
| 10 | 1.46 | 1.05 | 1.25 |
| ORB_SLAM3 | Ours | Dyna Slam | |||
|---|---|---|---|---|---|
| Sequences | Mean Total Tracking Time [ms] | Mean Total Local MAPPING Time [ms] | Mean Total Tracking Time [ms] | Mean Total Local Mapping Time [ms] | Mean Total Tracking Time [ms] |
| 00 | 27.36 | 141.14 | 28.34 | 145.4 | 61.07 |
| 01 | 28.27 | 105.33 | 31.53 | 105.21 | 70.85 |
| 02 | 27.13 | 117.74 | 28.61 | 117.01 | 60.53 |
| 04 | 28.38 | 138.56 | 30.07 | 138.93 | 61.24 |
| 05 | 28.52 | 129.78 | 29.99 | 137.95 | 62.04 |
| 06 | 29.29 | 150.26 | 31.18 | 150.41 | 63.81 |
| 07 | 27.82 | 91.89 | 28.4 | 95.34 | 58.35 |
| 09 | 27.74 | 95.75 | 28.5 | 98.17 | 58.7 |
| 10 | 26.69 | 78.5 | 27.85 | 81.8 | 57.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zang, Q.; Zhang, K.; Wang, L.; Wu, L. An Adaptive ORB-SLAM3 System for Outdoor Dynamic Environments. Sensors 2023, 23, 1359. https://doi.org/10.3390/s23031359
Zang Q, Zhang K, Wang L, Wu L. An Adaptive ORB-SLAM3 System for Outdoor Dynamic Environments. Sensors. 2023; 23(3):1359. https://doi.org/10.3390/s23031359
Chicago/Turabian StyleZang, Qiuyu, Kehua Zhang, Ling Wang, and Lintong Wu. 2023. "An Adaptive ORB-SLAM3 System for Outdoor Dynamic Environments" Sensors 23, no. 3: 1359. https://doi.org/10.3390/s23031359
APA StyleZang, Q., Zhang, K., Wang, L., & Wu, L. (2023). An Adaptive ORB-SLAM3 System for Outdoor Dynamic Environments. Sensors, 23(3), 1359. https://doi.org/10.3390/s23031359