
Zero-Shot Traffic Sign Recognition Based on Midlevel Feature Matching


Abstract
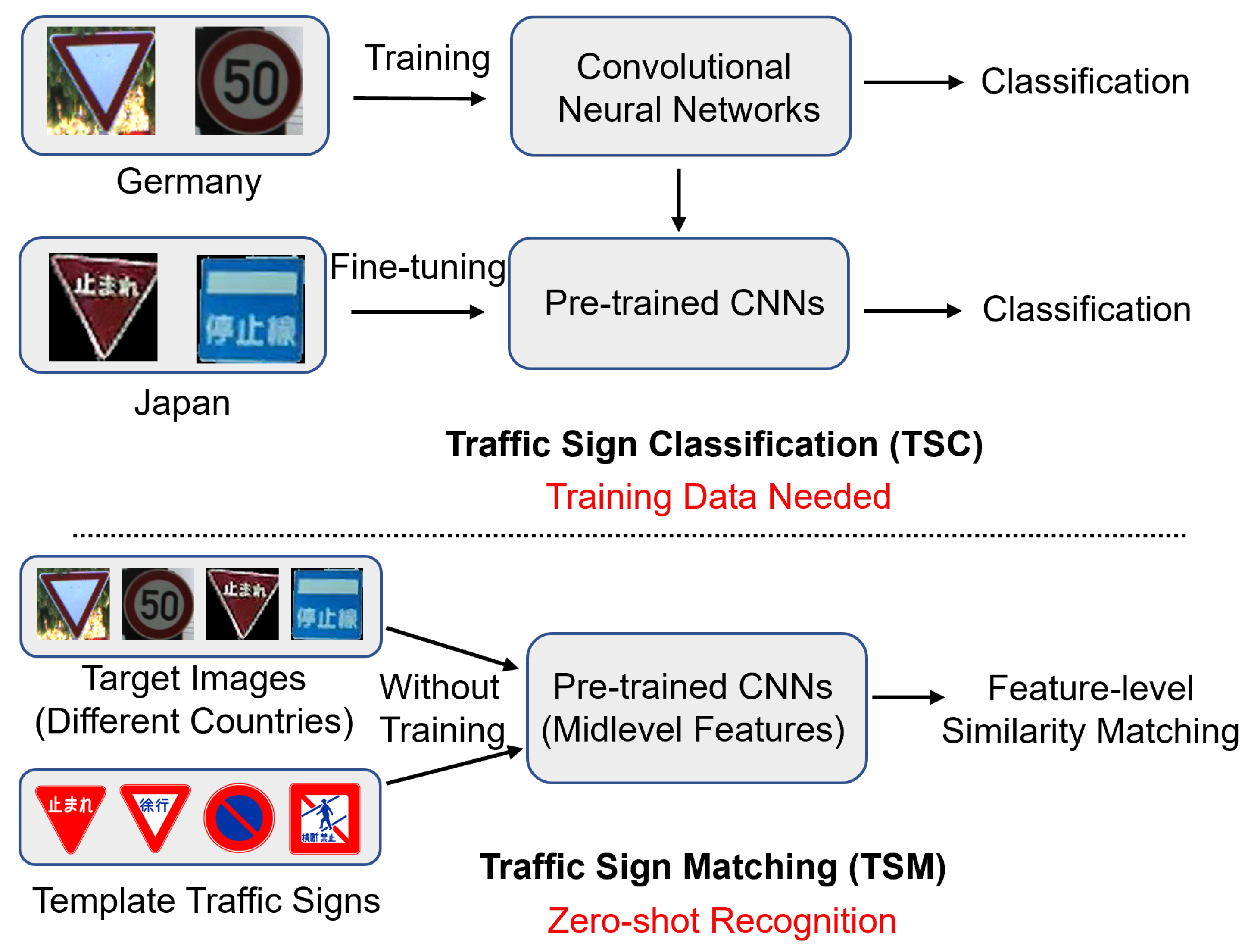
:1. Introduction
- We propose a novel TSM method for zero-shot recognition, which can achieve high-accuracy traffic sign recognition without additional training data.
- We introduce midlevel feature matching for the first time and perform the extraction of midlevel features on several CNN structures.
- We realize promising traffic sign recognition results on the German Traffic Sign Recognition Benchmark open dataset and a real-world dataset taken from Sapporo City, Japan.
2. Related Works
2.1. Traditional Traffic Sign Recognition Methods
2.2. Deep-Learning-Based Traffic Sign Recognition Methods
2.3. Traffic Sign Matching Methods
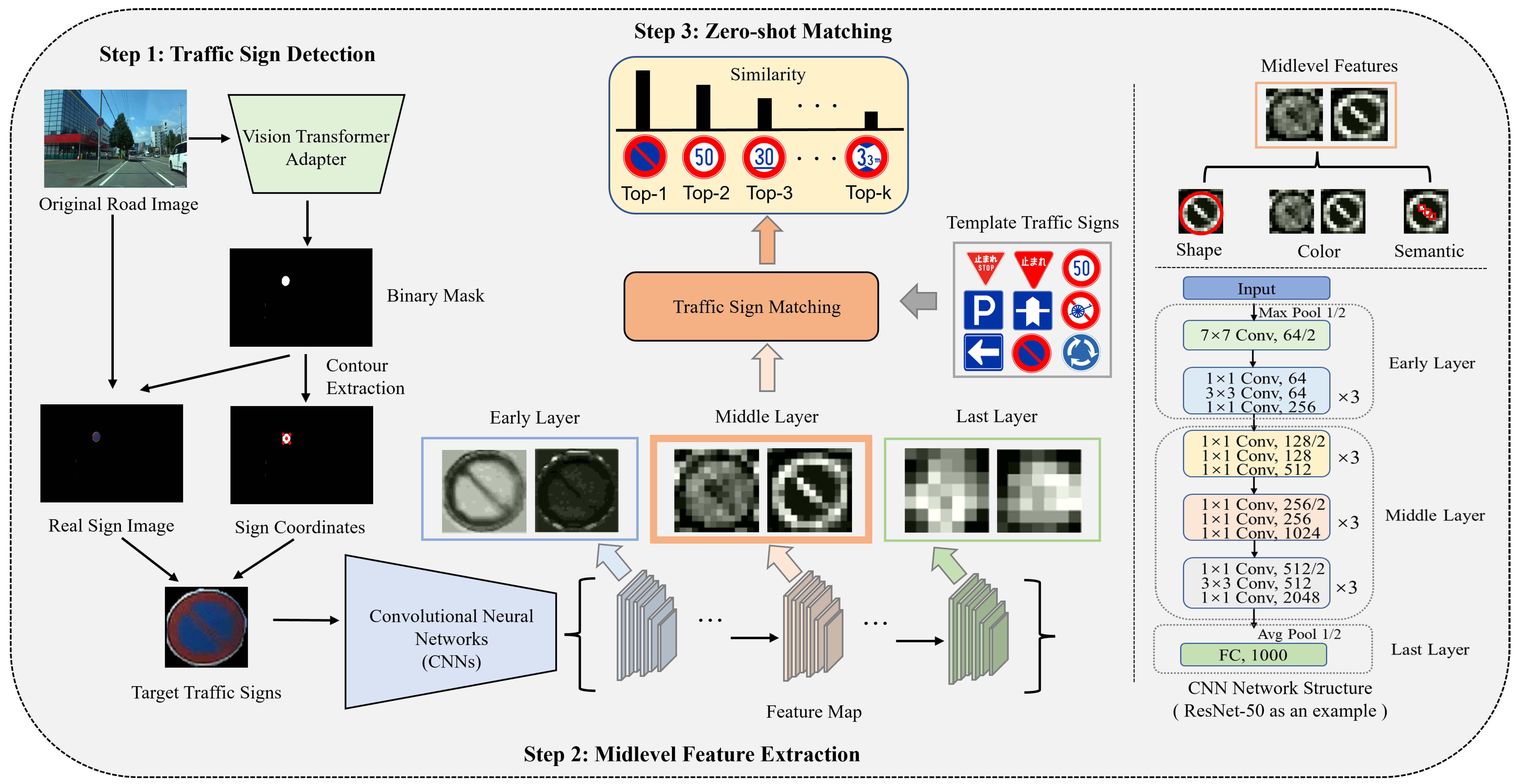
3. TSM Method Using Midlevel Features
3.1. Traffic Sign Detection
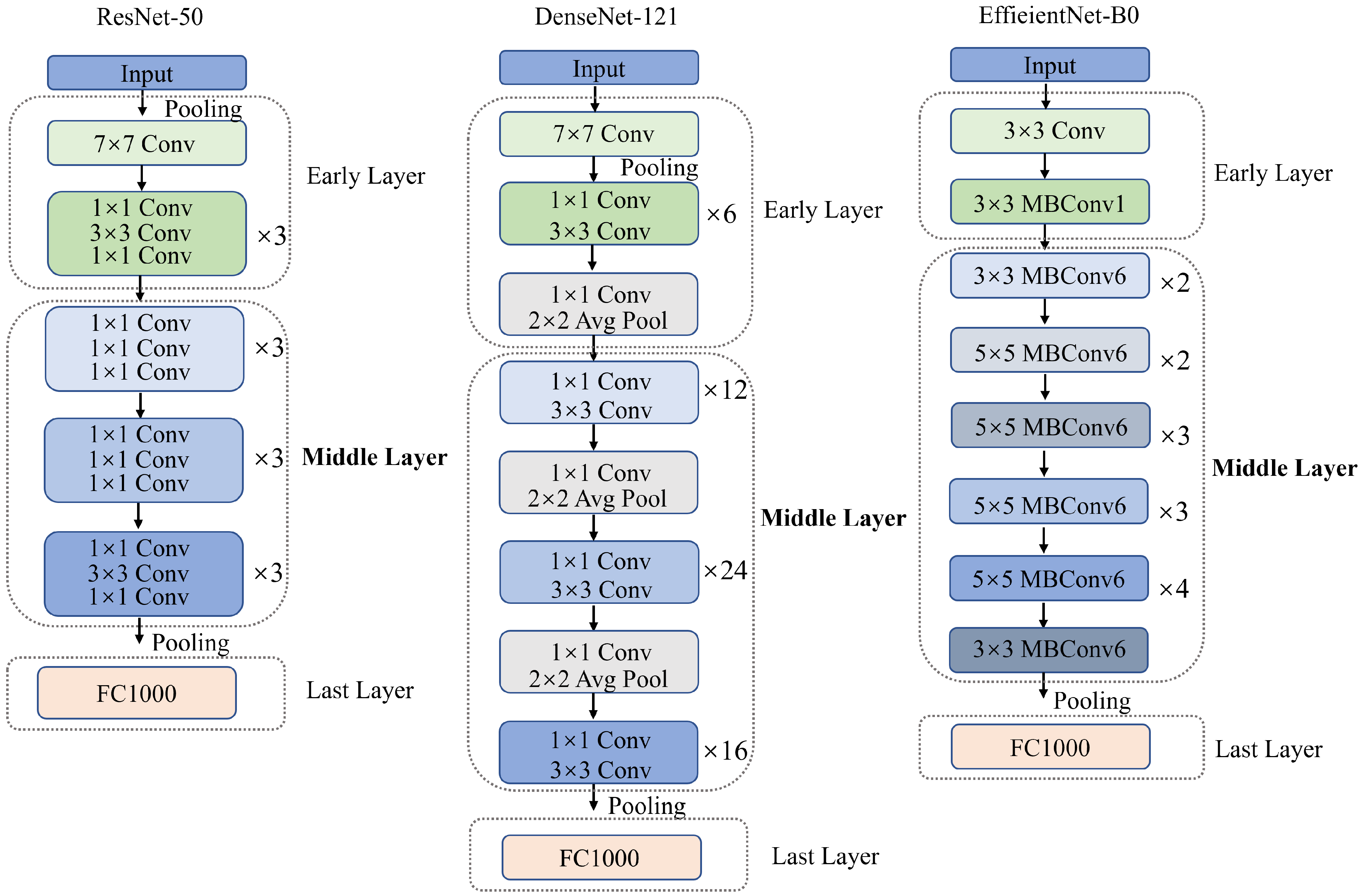
3.2. Midlevel Feature Extraction
3.3. Zero-Shot Matching
4. Experiments
4.1. Experimental Settings
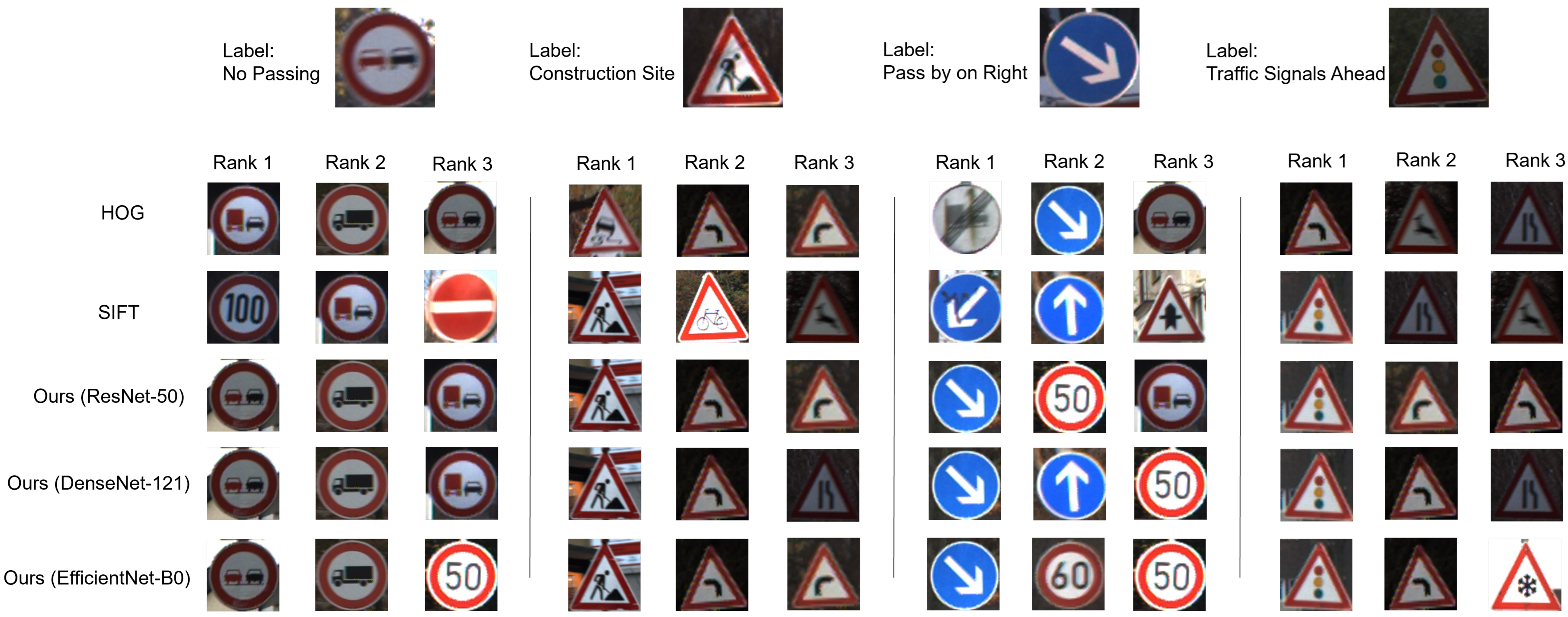
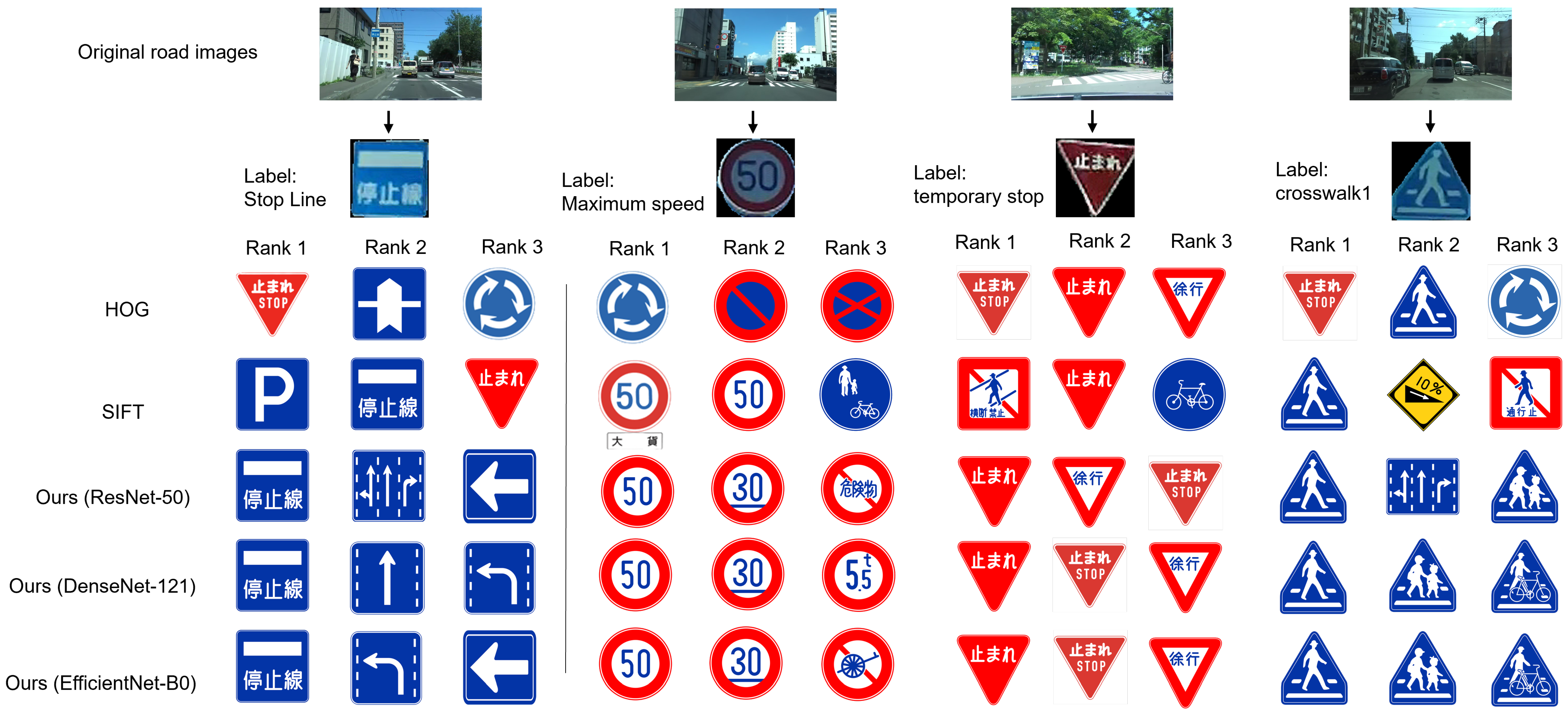
4.2. Experimental Results
5. Discussion
5.1. Interpretation of Results
5.2. Implications
5.3. Determining the Final Matched Traffic Signs
5.4. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Form |
|---|---|
| CNNs | Convolutional Neural Networks |
| DASs | Driver Assistance Systems |
| SIFT | Scale-invariant Feature Transform |
| HOG | Histogram of Oriented Gradients |
| TSD | Traffic Sign Detection |
| TSC | Traffic Sign Classification |
| TSM | Traffic Sign Matching |
| GTSRB | German Traffic Sign Recognition Benchmark |
References
- Hu, Y.; Li, Y.; Huang, H.; Lee, J.; Yuan, C.; Zou, G. A high-resolution trajectory data driven method for real-time evaluation of traffic safety. Accid. Anal. Prev. 2022, 165, 106503. [Google Scholar] [CrossRef] [PubMed]
- Zaki, P.S.; William, M.M.; Soliman, B.K.; Alexsan, K.G.; Khalil, K.; El-Moursy, M. Traffic signs detection and recognition system using deep learning. arXiv 2020, arXiv:2003.03256. [Google Scholar]
- Ren, F.; Huang, J.; Jiang, R.; Klette, R. General traffic sign recognition by feature matching. In Proceedings of the International Conference Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 23–25 November 2009; pp. 409–414. [Google Scholar]
- Dewi, C.; Chen, R.C.; Liu, Y.T.; Tai, S.K. Synthetic Data generation using DCGAN for improved traffic sign recognition. Neural Comput. Appl. 2022, 34, 21465–21480. [Google Scholar] [CrossRef]
- Xie, K.; Zhang, Z.; Li, B.; Kang, J.; Niyato, D.; Xie, S.; Wu, Y. Efficient federated learning with spike neural networks for traffic sign recognition. IEEE Trans. Veh. Technol. 2022, 71, 9980–9992. [Google Scholar] [CrossRef]
- Abdel-Salam, R.; Mostafa, R.; Abdel-Gawad, A.H. RIECNN: Real-time image enhanced CNN for traffic sign recognition. Neural Comput. Appl. 2022, 34, 6085–6096. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley Longman Publishing Co., Inc.: New York, NY, USA, 1989. [Google Scholar]
- De la Escalera, A.; Armingol, J.M.; Mata, M. Traffic sign recognition and analysis for intelligent vehicles. Image Vis. Comput. 2003, 21, 247–258. [Google Scholar] [CrossRef]
- De La Escalera, A.; Moreno, L.E.; Salichs, M.A.; Armingol, J.M. Road traffic sign detection and classification. IEEE Trans. Ind. Electron. 1997, 44, 848–859. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1150–1157. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Maldonado-Bascón, S.; Lafuente-Arroyo, S.; Gil-Jimenez, P.; Gómez-Moreno, H.; López-Ferreras, F. Road-sign detection and recognition based on support vector machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 264–278. [Google Scholar] [CrossRef]
- Shadeed, W.; Abu-Al-Nadi, D.I.; Mismar, M.J. Road traffic sign detection in color images. In Proceedings of the IEEE International Conference on Electronics, Circuits and Systems (ICECS), Sharjah, United Arab Emirates, 14–17 December 2003; Volume 2, pp. 890–893. [Google Scholar]
- Yang, Y.; Luo, H.; Xu, H.; Wu, F. Towards real-time traffic sign detection and classification. IEEE Trans. Intell. Transp. Syst. 2015, 17, 2022–2031. [Google Scholar] [CrossRef]
- Liu, C.; Li, S.; Chang, F.; Wang, Y. Machine vision based traffic sign detection methods: Review, analyses and perspectives. IEEE Access 2019, 7, 86578–86596. [Google Scholar] [CrossRef]
- Hussain, S.; Abualkibash, M.; Tout, S. A survey of traffic sign recognition systems based on convolutional neural networks. In Proceedings of the IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 0570–0573. [Google Scholar]
- Mathias, M.; Timofte, R.; Benenson, R.; Van Gool, L. Traffic sign recognition—How far are we from the solution? In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Li, J.; Wang, Z. Real-time traffic sign recognition based on efficient CNNs in the wild. IEEE Trans. Intell. Transp. Syst. 2018, 20, 975–984. [Google Scholar] [CrossRef]
- Luo, H.; Yang, Y.; Tong, B.; Wu, F.; Fan, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1100–1111. [Google Scholar] [CrossRef]
- Liu, Z.; Du, J.; Tian, F.; Wen, J. MR-CNN: A multi-scale region-based convolutional neural network for small traffic sign recognition. IEEE Access 2019, 7, 57120–57128. [Google Scholar] [CrossRef]
- Ni, K.; Wu, Y. Scene classification from remote sensing images using mid-level deep feature learning. Int. J. Remote Sens. 2020, 41, 1415–1436. [Google Scholar] [CrossRef]
- Fernando, B.; Fromont, E.; Tuytelaars, T. Mining mid-level features for image classification. Int. J. Comput. Vis. 2014, 108, 186–203. [Google Scholar] [CrossRef]
- Brust, C.A.; Guindon, B. Efficient and robust vehicle localization in urban environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Bertozzi, M.; Broggi, A.; Fascioli, A.; Gold, R.; Uras, S. Automatic vehicle guidance: The experience of the ARGO autonomous vehicle. IEEE Trans. Robot. Autom. 1997, 13, 672–685. [Google Scholar]
- Soni, D.; Chaurasiya, R.K.; Agrawal, S. Improving the Classification Accuracy of Accurate Traffic Sign Detection and Recognition System Using HOG and LBP Features and PCA-Based Dimension Reduction. In Proceedings of the International Conference on Sustainable Computing in Science, Technology and Management (SUSCOM), Jaipur, India, 26–28 February 2019. [Google Scholar]
- Namyang, N.; Phimoltares, S. Thai traffic sign classification and recognition system based on histogram of gradients, color layout descriptor, and normalized correlation coefficient. In Proceedings of the International Conference on Information Technology (ICIT), Xi’an, China, 25–27 December 2020; pp. 270–275. [Google Scholar]
- Kerim, A.; Efe, M.Ö. Recognition of traffic signs with artificial neural networks: A novel dataset and algorithm. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 171–176. [Google Scholar]
- Li, W.; Song, H.; Wang, P. Finely Crafted Features for Traffic Sign Recognition. Int. J. Circuits Syst. Signal Process. 2022, 16, 159–170. [Google Scholar] [CrossRef]
- Sapijaszko, G.; Alobaidi, T.; Mikhael, W.B. Traffic sign recognition based on multilayer perceptron using DWT and DCT. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems (IMSCAS), Dallas, TX, USA, 4–7 August 2019; pp. 440–443. [Google Scholar]
- Weng, H.M.; Chiu, C.T. Resource efficient hardware implementation for real-time traffic sign recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1120–1124. [Google Scholar]
- Aziz, S.; Mohamed, E.A.; Youssef, F. Traffic sign recognition based on multi-feature fusion and ELM classifier. Procedia Comput. Sci. 2018, 127, 146–153. [Google Scholar] [CrossRef]
- Wang, B. Research on the Optimal Machine Learning Classifier for Traffic Signs. SHS Web Conf. 2022, 144, 03014. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. (NeurIPS) 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kim, C.i.; Park, J.; Park, Y.; Jung, W.; Lim, Y.S. Deep Learning-Based Real-Time Traffic Sign Recognition System for Urban Environments. Infrastructures 2023, 8, 20. [Google Scholar] [CrossRef]
- Zhu, Y.; Yan, W.Q. Traffic sign recognition based on deep learning. Multimed. Tools Appl. 2022, 81, 17779–17791. [Google Scholar] [CrossRef]
- Alghmgham, D.A.; Latif, G.; Alghazo, J.; Alzubaidi, L. Autonomous traffic sign (ATSR) detection and recognition using deep CNN. Procedia Comput. Sci. 2019, 163, 266–274. [Google Scholar] [CrossRef]
- Zaibi, A.; Ladgham, A.; Sakly, A. A lightweight model for traffic sign classification based on enhanced LeNet-5 network. J. Sens. 2021, 2021, 8870529. [Google Scholar] [CrossRef]
- Sreya, K.V.N. Traffic Sign Classification Using CNN. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 1952–1956. [Google Scholar] [CrossRef]
- Abudhagir, U.S.; Ashok, N. Highly sensitive Deep Learning Model for Road Traffic Sign Identification. Math. Stat. Eng. Appl. 2022, 71, 3194–3205. [Google Scholar]
- Rajendran, S.P.; Shine, L.; Pradeep, R.; Vijayaraghavan, S. Real-time traffic sign recognition using YOLOv3 based detector. In Proceedings of the International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–7. [Google Scholar]
- Mogelmose, A.; Trivedi, M.M.; Moeslund, T.B. Vision-based traffic sign detection and analysis for intelligent driver assistance systems: Perspectives and survey. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1484–1497. [Google Scholar] [CrossRef]
- Kang, M.; Lee, S.; Kim, J. Meta-transfer learning for robust traffic sign recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jin, Y.; Fu, Y.; Wang, W.; Guo, J.; Ren, C.; Xiang, X. Multi-feature fusion and enhancement single shot detector for traffic sign recognition. IEEE Access 2020, 8, 38931–38940. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Y.; Mei, T. Deep multi-modal vehicle re-identification in urban space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lampkins, J.; Chan, D.; Perry, A.; Strelnikoff, S.; Xu, J.; Ashari, A.E. Multimodal Road Sign Interpretation for Autonomous Vehicles. In Proceedings of the IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 5979–5987. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Peker, A.U.; Tosun, O.; Akın, H.L.; Acarman, T. Fusion of map matching and traffic sign recognition. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Ypsilanti, MI, USA, 8–11 June 2014; pp. 867–872. [Google Scholar]
- Gordo, A. Supervised mid-level features for word image representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2956–2964. [Google Scholar]
- Lim, J.J.; Zitnick, C.L.; Dollár, P. Sketch tokens: A learned mid-level representation for contour and object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3158–3165. [Google Scholar]
- Liu, L.; Mou, L.; Zhu, X.X.; Mandal, M. Automatic skin lesion classification based on mid-level feature learning. Comput. Med. Imaging Graph. 2020, 84, 101765. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Sullivan, J.; Li, H. Leveraging mid-level deep representations for predicting face attributes in the wild. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3239–3243. [Google Scholar]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision transformer adapter for dense predictions. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Suzuki, S. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef]





| Network | Layer | Dimension |
|---|---|---|
| Early layer | 256 × 56 × 56 | |
| ResNet-50 | Middle layer | 1024 × 14 × 14 |
| Last layer | 2048 × 1 × 1 | |
| Early layer | 256 × 56 × 56 | |
| DenseNet-121 | Middle layer | 1024 × 14 × 14 |
| Last layer | 1024 × 7 × 7 | |
| Early layer | 16 × 112 × 112 | |
| EfficientNet-B0 | Middle layer | 320 × 7 × 7 |
| Last layer | 1280 × 7 × 7 |
| Method | Top1 | Top5 | Top10 | |
|---|---|---|---|---|
| HOG [11] | 0.089 | 0.196 | 0.329 | |
| SIFT [3] | 0.238 | 0.551 | 0.709 | |
| Early Layer | 0.141 | 0.352 | 0.569 | |
| ResNet-50 | Middle Layer (PM) | 0.521 | 0.781 | 0.930 |
| Last Layer | 0.148 | 0.359 | 0.559 | |
| Early Layer | 0.081 | 0.227 | 0.374 | |
| DenseNet-121 | Middle Layer (PM) | 0.468 | 0.769 | 0.910 |
| Last Layer | 0.394 | 0.680 | 0.864 | |
| Early Layer | 0.245 | 0.520 | 0.687 | |
| EfficientNet-B0 | Middle Layer (PM) | 0.444 | 0.767 | 0.921 |
| Last Layer | 0.333 | 0.678 | 0.848 | |
| Method | Top1 | Top5 | Top10 | |
|---|---|---|---|---|
| HOG [11] | 0.014 | 0.296 | 0.465 | |
| SIFT [3] | 0.127 | 0.310 | 0.338 | |
| Early Layer | 0.014 | 0.211 | 0.338 | |
| ResNet-50 | Middle Layer (PM) | 0.338 | 0.761 | 0.873 |
| Last Layer | 0.028 | 0.070 | 0.141 | |
| Early Layer | 0.014 | 0.141 | 0.268 | |
| DenseNet-121 | Middle Layer (PM) | 0.817 | 0.873 | 0.915 |
| Last Layer | 0.169 | 0.606 | 0.732 | |
| Early Layer | 0.099 | 0.169 | 0.239 | |
| EfficientNet-B0 | Middle Layer (PM) | 0.437 | 0.732 | 0.845 |
| Last Layer | 0.169 | 0.423 | 0.634 | |
| Dataset | Class | Proposed Method | Computation Time (Seconds) |
|---|---|---|---|
| ResNet-50 | 1.15 | ||
| GTSRB | 43 | DenseNet-121 | 1.26 |
| EfficientNet-B0 | 1.82 | ||
| ResNet-50 | 3.63 | ||
| Sapporo Urban Road | 111 | DenseNet-121 | 4.01 |
| EfficientNet-B0 | 5.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, Y.; Li, G.; Togo, R.; Maeda, K.; Ogawa, T.; Haseyama, M. Zero-Shot Traffic Sign Recognition Based on Midlevel Feature Matching. Sensors 2023, 23, 9607. https://doi.org/10.3390/s23239607
Gan Y, Li G, Togo R, Maeda K, Ogawa T, Haseyama M. Zero-Shot Traffic Sign Recognition Based on Midlevel Feature Matching. Sensors. 2023; 23(23):9607. https://doi.org/10.3390/s23239607
Chicago/Turabian StyleGan, Yaozong, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2023. "Zero-Shot Traffic Sign Recognition Based on Midlevel Feature Matching" Sensors 23, no. 23: 9607. https://doi.org/10.3390/s23239607
APA StyleGan, Y., Li, G., Togo, R., Maeda, K., Ogawa, T., & Haseyama, M. (2023). Zero-Shot Traffic Sign Recognition Based on Midlevel Feature Matching. Sensors, 23(23), 9607. https://doi.org/10.3390/s23239607