

YDD-SLAM: Indoor Dynamic Visual SLAM Fusing YOLOv5 with Depth Information


Abstract
:1. Introduction
- (1)
- To make full use of the prior information of objects, we divided common indoor objects into eight subcategories according to their motion characteristics and depth values, so as to facilitate the adoption of dynamic feature point elimination and judgment methods suitable for different objects.
- (2)
- To solve the complex problem of the range change of the depth value of non-rigid dynamic objects, we matched the information of ‘person’, ‘head’, and ‘hand’ and the corresponding depth value in the object detection class and combined them into the depth range of ‘human body’ for the final selection of dynamic feature points, which can adapt to changes with the movement of ‘human body’.
- (3)
- Aiming at the problem of achieving sufficient positioning accuracy and real-time performance of the dynamic VSLAM algorithm, we proposed an improved indoor dynamic VSLAM algorithm based on ORB-SLAM3 -YDD-SLAM to avoid excessive feature point elimination due to the overly large object detection box area of the object detection algorithm. This approach introduces short-time-consumption YOLOv5 and deep information fusion to achieve the fine elimination of dynamic feature points in the object detection box and to retain static feature points in the detection box as much as possible. The removal effect of dynamic feature points is close to that of image segmentation, but it can save a considerable amount of time.
- (4)
- To solve the robustness problem of the dynamic VSLAM algorithm, we propose a series of feature point optimization strategies based on depth information and feature point extraction methods to improve its positioning accuracy and robustness in complex scenes.
2. Related Works
2.1. Method Based on Deep Learning and Geometric Information Fusion
2.2. Feature Point Classification
3. Materials and Methods
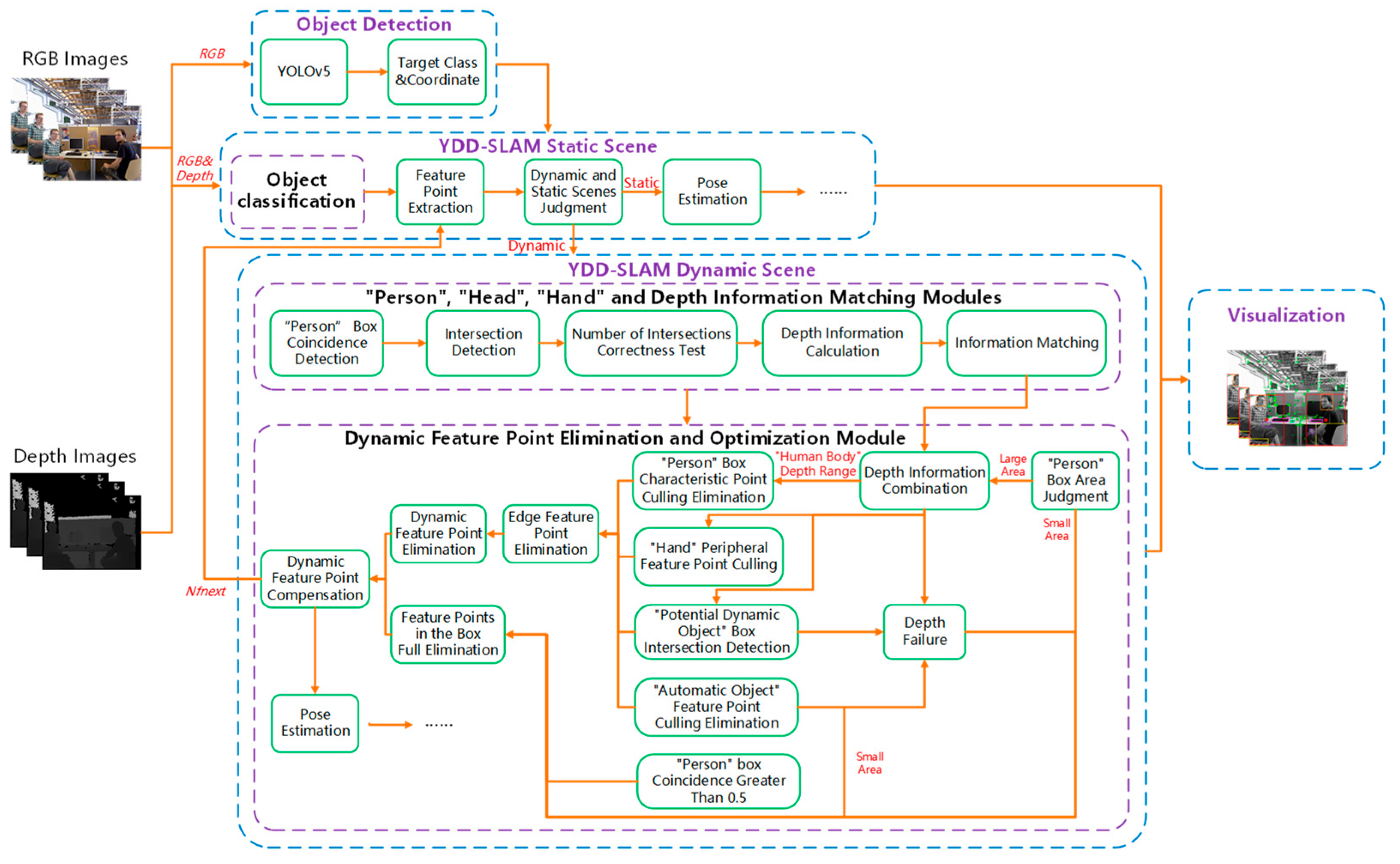
3.1. Overview of the YDD-SLAM System
- (1)
- Object detection: To balance the detection speed and accuracy of the YOLOv5 object detection algorithm, the YOLOv5s model was used for object detection in this study. The RGB image is passed to the YOLOv5 object detection algorithm. The detection box is coordinated, and class name results are passed to the YDD-SLAM algorithm.
- (2)
- YDD-SLAM dynamic and static scenes: According to the class name information passed by YOLOv5, the YDD-SLAM algorithm divides indoor objects into three categories: dynamic, potentially dynamic, and static. On this basis, objects are subdivided into eight subcategories. Then, the total number of feature points to be extracted is calculated by the dynamic feature point compensation strategy of the previous frame, and the feature points are extracted according to the number requirements of the current RGB image frame. Next, according to the object classification information, the action and static scene of the current image frame are judged. If no ‘dynamic object’ information is detected in the image for five or more consecutive frames, the current image frame is considered to be a static scene, and the pose estimation in the static scene is consistent with the ORB-SLAM3 algorithm. Otherwise, the current image frame is considered to be a dynamic scene, which needs to match the information of ‘person’, ‘head’, ‘hand’, and depth. The matching results are transmitted to the dynamic feature point elimination and optimization module, and the feature points are dynamically judged and eliminated. The static feature points are used for the pose estimation.
- (3)
- Information matching module: Firstly, the coincidence degree of the ‘person’ detection box in the current image frame is calculated. When the coincidence degree of the ‘person’ box is greater than 50%, the dynamic feature point elimination and optimization module adopts the strategy of all feature points in the frame. The ‘person’ box with a coincidence degree less than 50% matches the ‘person’, ‘head’, ‘hand’, and depth information. Secondly, the intersection detection of the ‘person’ box information and the ‘head’ and ‘hand’ boxes of the current frame is conducted, and the correctness judgment is made according to the number of ‘person’, ‘head’, and ‘hand’ boxes. If the number is correct, the corresponding calculated depth information is directly matched and attached. When the number of intersections is abnormal, matching must be performed according to the geometry and depth information.
- (4)
- Dynamic feature point elimination and optimization module: Firstly, the area of the ‘person’ box is judged; the ‘person’, ‘head’, ‘hand’, and depth matching information are carried out on the large area ‘person’ box; and the depth information of the ‘human body’ related categories is combined to calculate the final depth range of the ‘human body’. Secondly, the dynamic character of the ‘potentially dynamic object’ is judged. Then, the feature points in the box of ‘dynamic object’ and ‘potentially dynamic object’ are combined with the depth range information to eliminate the dynamic feature points. When the depth value of the feature points in the box is within this depth range, the feature points are determined to be dynamic feature points and eliminated. Meanwhile, the feature points around the ‘hand’ and the edge feature points are eliminated. The strategy of eliminating all feature points in the detection box was adopted for the three cases of small area ‘human’ box, the object with failed depth, and the ‘human’ box with a coincidence degree greater than 50%. Finally, the static feature points are used for the pose estimation, and the total number of feature points to be extracted in the next frame is calculated by the dynamic feature point compensation strategy and passed to the feature point extraction part.
- (5)
- Visualization: Different colored boxes are used to visualize the object detection results of various objects. Simultaneously, the central position of the ‘person’ box is marked, the dynamic feature points are removed and not displayed, and the retained static feature points are displayed.
3.2. Indoor Object Classification
3.3. Information Matching
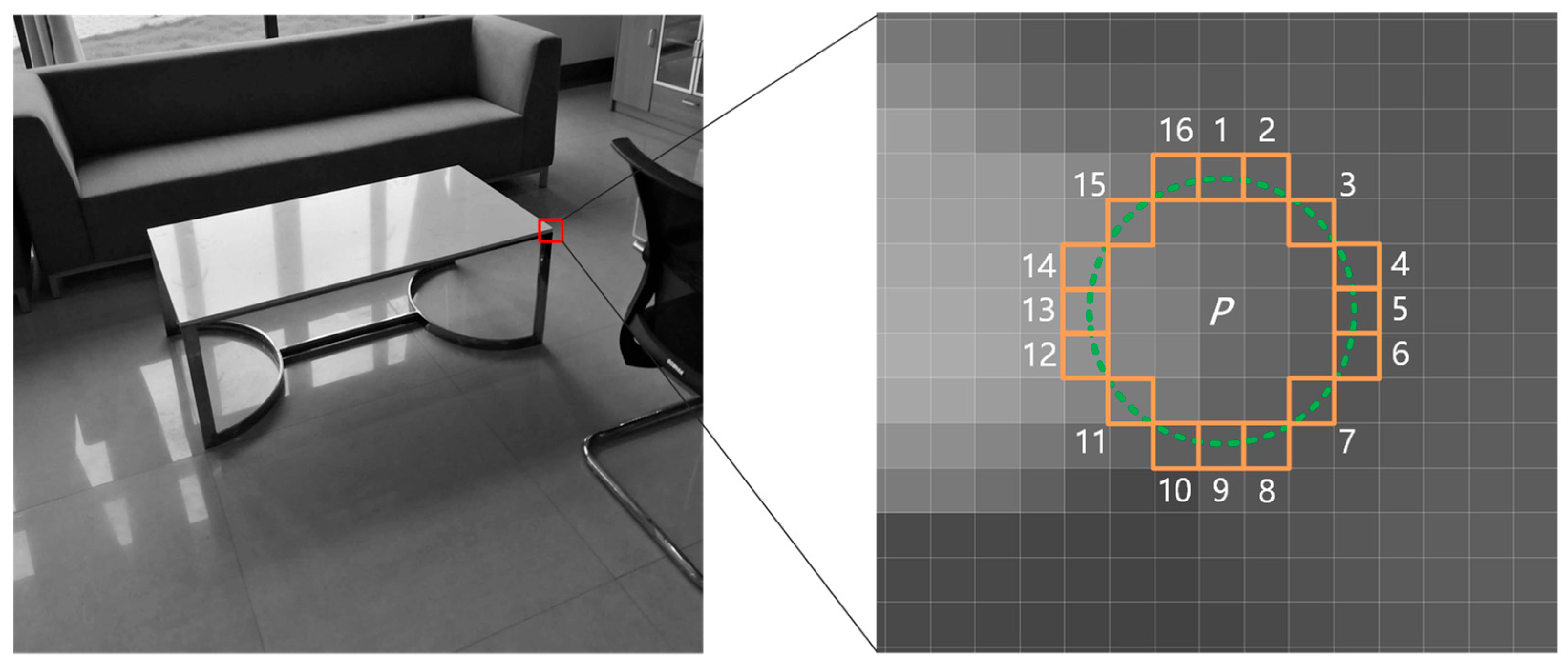
3.3.1. Appropriate Minimum Depth of Object
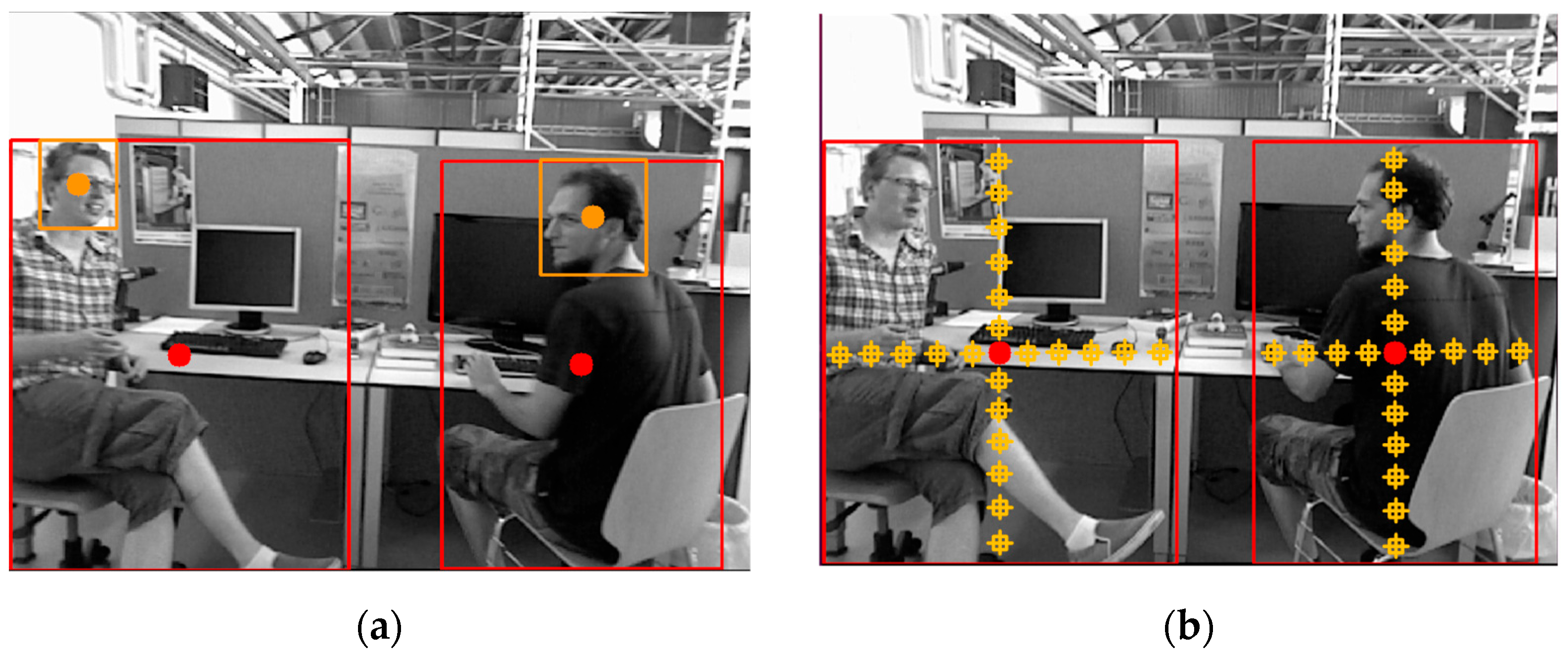
3.3.2. ‘Person’, ‘Head’, ‘Hand’, and Depth Information Match
3.4. Dynamic Feature Point Elimination
3.4.1. ORB-SLAM3 Fusion with YOLOv5
3.4.2. Feature Point Removal of ‘Dynamic Object’
3.4.3. Feature Point Removal of ‘Potentially Dynamic Object’
3.5. Dynamic VSLAM Feature Point Optimization Strategy
3.5.1. Edge Feature Point Elimination
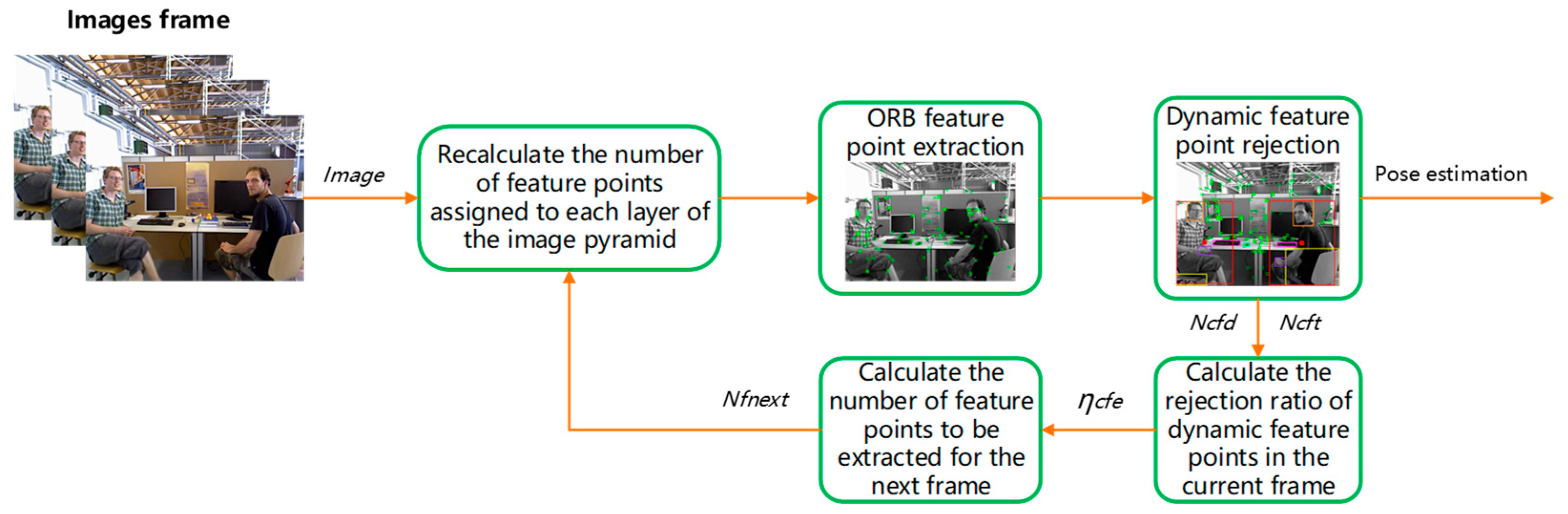
3.5.2. Dynamic Feature Point Compensation
3.5.3. ‘Hand’ Peripheral Feature Point Culling
3.5.4. Full Rejection of Complex Dynamic Feature Points
- (1)
- Because the method proposed in this paper combines YOLOv5 and depth information to refine the exclusion range of the feature points in the dynamic detection box, the failure of image depth information will affect the pose estimation of YDD-SLAM. To improve the robustness of YDD-SLAM, when the depth information fails, the feature points in the dynamic object detection box are eliminated completely. For example, if the object detected exceeds the depth detection range of the depth camera, the depth information of part of the image will fail. When the depth of this part of the image must be used to determine whether the feature points in the object box are deleted, the feature points in the object box will be completely eliminated.
- (2)
- When the ratio of the detection box areas of ‘person’ and ‘automatic objects’ to the total area of the image is too small, such as if the ‘person’ is in the distance or partially obscured, the detection box will be too small. At this time, the number of static feature points in the box is small, and the accuracy of the depth value of the distant person is not high. To improve the real-time performance and robustness of YDD-SLAM, a rejection judgment is skipped for the feature points in the detection boxes of ‘person’ and ‘automatic objects’ with excessively small areas, and the full rejection strategy is implemented.
- (3)
- When the coincidence degree of the ‘person’ box is greater than 50%, the information in the ‘person’ box is too redundant and leads to information matching difficulties. Therefore, a total elimination strategy is adopted for the feature points in the ‘person’ box in this case.
4. Experimental Results and Discussion
4.1. Performance of YDD-SLAM
4.2. Comparison of YDD-SLAM-Derived Algorithms
4.3. Comparison of Mainstream Dynamic VSLAM
4.4. Actual Scenario Verification
5. Conclusions
- (1)
- The feature points in the dynamic depth range will be further evaluated by adding methods such as Epipolar Geometry or optical flow.
- (2)
- To avoid missing detection in the object detection algorithm, the missing detection will be processed by the speed information of the image frame or the IMU information.
- (3)
- Dynamic VSLAM algorithms for audio information and visual attention will be introduced to further deal with more interesting dynamic target regions.
- (4)
- Various means will be combined to cryptographically protect the data information of the dynamic VSLAM algorithm.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Shang, G.; Ji, A.; Zhou, C.; Wang, X.; Xu, C.; Li, Z. An overview on visual slam: From tradition to semantic. Remote Sens. 2022, 14, 3010. [Google Scholar] [CrossRef]
- Min, X.; Ma, K.; Gu, K.; Zhai, G.; Wang, Z.; Lin, W. Unified blind quality assessment of compressed natural, graphic, and screen content images. IEEE Trans. Image Process. 2017, 26, 5462–5474. [Google Scholar] [CrossRef] [PubMed]
- Min, X.; Zhai, G.; Gu, K.; Yang, X.; Guan, X. Objective quality evaluation of dehazed images. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2879–2892. [Google Scholar] [CrossRef]
- Min, X.; Zhou, J.; Zhai, G.; Le Callet, P.; Yang, X.; Guan, X. A metric for light field reconstruction, compression, and display quality evaluation. IEEE Trans. Image Process. 2020, 29, 3790–3804. [Google Scholar] [CrossRef]
- Lee, T.; Kim, C.; Cho, D.D. A monocular vision sensor-based efficient SLAM method for indoor service robots. IEEE Trans. Ind. Electron. 2018, 66, 318–328. [Google Scholar] [CrossRef]
- Fang, B.; Mei, G.; Yuan, X.; Wang, L.; Wang, Z.; Wang, J. Visual SLAM for robot navigation in healthcare facility. Pattern Recognit. 2021, 113, 107822. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Cao, S.; Lu, X.; Shen, S. GVINS: Tightly coupled GNSS–visual–inertial fusion for smooth and consistent state estimation. IEEE Trans. Robot. 2022, 38, 2004–2021. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Pistacaway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Lu, X.; Wang, H.; Tang, S.; Huang, H.; Li, C. DM-SLAM: Monocular SLAM in dynamic environments. Appl. Sci. 2020, 10, 4252. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Motion removal for reliable RGB-D SLAM in dynamic environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Fu, Y.; Han, B.; Hu, Z.; Shen, X.; Zhao, Y. CBAM-SLAM: A Semantic SLAM Based on Attention Module in Dynamic Environment. In Proceedings of the 2022 6th Asian Conference on Artificial Intelligence Technology (ACAIT), Changzhou, China, 9–11 December 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Liu, Y.; Miura, J. RDMO-SLAM: Real-time visual SLAM for dynamic environments using semantic label prediction with optical flow. IEEE Access 2021, 9, 106981–106997. [Google Scholar] [CrossRef]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. PWC-Net: Cnns for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8934–8943. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. Proc. IEEE Int. Conf. Comput. Vis. 2017, 2961–2969. [Google Scholar]
- Yan, H.; Zhou, X.; Liu, J.; Yin, Z.; Yang, Z. Robust Vision SLAM Based on YOLOX for Dynamic Environments. In Proceedings of the 2022 IEEE 22nd International Conference on Communication Technology (ICCT), Nanjing, China, 11–14 November 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 1655–1659. [Google Scholar]
- Gökcen, B.; Uslu, E. Object aware RGBD SLAM in Dynamic Environments. In Proceedings of the 2022 International Conference on Innovations in Intelligent Systems and Applications (INISTA), Biarritz, France, 8–10 August 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Gong, H.; Gong, L.; Ma, T.; Sun, Z.; Li, L. AHY-SLAM: Toward faster and more accurate visual SLAM in dynamic scenes using homogenized feature extraction and object detection method. Sensors 2023, 23, 4241. [Google Scholar] [CrossRef] [PubMed]
- YOLO-V5. Available online: https://github.com/ultralytics/yolov5/releases (accessed on 12 October 2021).
- Wang, Y.; Bu, H.; Zhang, X.; Cheng, J. YPD-SLAM: A real-time VSLAM system for handling dynamic indoor environments. Sensors 2022, 22, 8561. [Google Scholar] [CrossRef]
- Cheng, S.; Sun, C.; Zhang, S.; Zhang, D. SG-SLAM: A real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information. IEEE Trans. Instrum. Meas. 2022, 72, 7501012. [Google Scholar] [CrossRef]
- Zhao, X.; Ye, L. Object Detection-Based Visual SLAM for Dynamic Scenes. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 1153–1158. [Google Scholar]
- Su, P.; Luo, S.; Huang, X. Real-time dynamic SLAM algorithm based on deep learning. IEEE Access 2022, 10, 87754–87766. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, S.; Huang, G.; Bai, L.; Li, Q. WF-SLAM: A robust VSLAM for dynamic scenarios via weighted features. IEEE Sens. J. 2022, 22, 10818–10827. [Google Scholar] [CrossRef]
- Sun, L.; Wei, J.; Su, S.; Wu, P. Solo-slam: A parallel semantic slam algorithm for dynamic scenes. Sensors 2022, 22, 6977. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Zhao, C.; Wu, Z.; Wang, Y.; Wang, G.; Li, D. Visual SLAM based on semantic segmentation and geometric constraints for dynamic indoor environments. IEEE Access 2022, 10, 69636–69649. [Google Scholar] [CrossRef]
- Eslamian, A.; Ahmadzadeh, M.R. Det-SLAM: A Semantic Visual SLAM for Highly Dynamic Scenes using Detectron 2. In Proceedings of the 2022 8th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Mazandaran, Iran, 28–29 December 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Tian, Y.L.; Xu, G.C.; Li, J.X.; Sun, Y. Visual SLAM Based on YOLOX-S in Dynamic Scenes. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 262–266. [Google Scholar]
- Liu, J.; Li, X.; Liu, Y.; Chen, H. RGB-D inertial odometry for a resource-restricted robot in dynamic environments. IEEE Robot. Autom. Lett. 2022, 7, 9573–9580. [Google Scholar] [CrossRef]
- Wang, Y.I.; Mikawa, M.; Fujisawa, M. FCH-SLAM: A SLAM Method for Dynamic Environments using Semantic Segmentation. In Proceedings of the 2022 2nd International Conference on Image Processing and Robotics (ICIPRob), Colombo, Sri Lanka, 12–13 March 2022; IEEE: Pistacaway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Bahraini, M.S.; Bozorg, M.; Rad, A.B. SLAM in dynamic environments via ML-RANSAC. Mechatronics 2018, 49, 105–118. [Google Scholar] [CrossRef]
- Cui, L.; Ma, C. SOF-SLAM: A semantic visual SLAM for dynamic environments. IEEE Access 2019, 7, 166528–166539. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Bârsan, I.A.; Liu, P.; Pollefeys, M.; Geiger, A. Robust Dense Mapping for Large-Scale Dynamic Environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Pistacaway, NJ, USA, 2018; pp. 7510–7517. [Google Scholar]
- Ran, T.; Yuan, L.; Zhang, J.; Tang, D.; He, L. RS-SLAM: A robust semantic SLAM in dynamic environments based on RGB-D sensor. IEEE Sens. J. 2021, 21, 20657–20664. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, J.; Luo, Y.; Ou, J. Semantic SLAM based on improved DeepLabv3⁺ in dynamic scenarios. IEEE Access 2022, 10, 21160–21168. [Google Scholar] [CrossRef]
- Wen, S.; Liu, X.; Wang, Z.; Zhang, H.; Zhang, Z.; Tian, W. An improved multi-object classification algorithm for visual SLAM under dynamic environment. Intell. Serv. Robot. 2022, 15, 39–55. [Google Scholar] [CrossRef]
- Yang, B.; Ran, W.; Wang, L.; Lu, H.; Chen, Y.P.P. Multi-classes and motion properties for concurrent visual slam in dynamic environments. IEEE Trans. Multimed. 2021, 24, 3947–3960. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Pistacaway, NJ, USA, 2012; pp. 573–580. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM Towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; IEEE: Pistacaway, NJ, USA, 2018; pp. 1168–1174. [Google Scholar]
- Min, X.; Zhai, G.; Gu, K.; Yang, X. Fixation Prediction through Multimodal Analysis. In ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM); Association for Computing Machinery: New York, NY, USA, 2016; Volume 13, pp. 1–23. [Google Scholar]
- Min, X.; Zhai, G.; Zhou, J.; Zhang, X.P.; Yang, X.; Guan, X. A multimodal saliency model for videos with high audio-visual correspondence. IEEE Trans. Image Process. 2020, 29, 3805–3819. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Min, X.; Sun, W.; Zhai, G. Attention-Guided Neural Networks for Full-Reference and No-Reference Audio-Visual Quality Assessment. IEEE Trans. Image Process. 2023, 32, 1882–1896. [Google Scholar] [CrossRef] [PubMed]
- Bakalos, N.; Voulodimos, A.; Doulamis, N.; Doulamis, A.; Ostfeld, A.; Salomons, E.; Caubet, J.; Jimenez, V.; Li, P. Protecting water infrastructure from cyber and physical threats: Using multimodal data fusion and adaptive deep learning to monitor critical systems. IEEE Signal Process. Mag. 2019, 36, 36–48. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | Geometric Method | Deep Learning Method | |
|---|---|---|---|
| Image Segmentation | Object Detection | ||
| Advantages | Dynamic feature points in the environment can be eliminated well. | Accurate dynamic feature point rejection | Good real-time performance |
| Disadvantages | The removal of dynamic feature points is general and too dependent on thresholds. | Poor real-time performance | Static feature points are over-rejected. |
| Dhead | Dhand | Dhalfhand | Dsmall | Dmedium | Dlarge |
|---|---|---|---|---|---|
| 0.2 | 0.18 | 0.5 | 0.2 | 0.45 | 0.7 |
| Sequences | ORB-SLAM3 | YDD-SLAM | Improvements (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | |
| fr3_w_xyz | 0.6930 | 0.5810 | 0.4500 | 0.3742 | 0.0151 | 0.0132 | 0.0117 | 0.0075 | 97.82 | 97.73 | 97.40 | 98.00 |
| fr3_w_rpy | 0.6381 | 0.5468 | 0.5151 | 0.3263 | 0.0355 | 0.0287 | 0.0230 | 0.0208 | 94.44 | 94.75 | 95.54 | 93.63 |
| fr3_w_half | 0.3196 | 0.2910 | 0.2667 | 0.1272 | 0.0275 | 0.0241 | 0.0217 | 0.0132 | 91.40 | 91.72 | 91.86 | 89.62 |
| fr3_w_static | 0.3274 | 0.3010 | 0.2999 | 0.1207 | 0.0082 | 0.0067 | 0.0060 | 0.0047 | 97.50 | 97.77 | 98.00 | 96.11 |
| fr3_s_static | 0.0108 | 0.0093 | 0.0082 | 0.0054 | 0.0067 | 0.0059 | 0.0052 | 0.0033 | 37.96 | 36.56 | 36.59 | 38.89 |
| Sequences | ORB-SLAM3 | YDD-SLAM | Improvements (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | |
| fr3_w_xyz | 0.0251 | 0.0201 | 0.0161 | 0.0150 | 0.0119 | 0.0097 | 0.0081 | 0.0068 | 52.59 | 51.74 | 49.69 | 54.67 |
| fr3_w_rpy | 0.0286 | 0.0217 | 0.0167 | 0.0185 | 0.0212 | 0.0153 | 0.0120 | 0.0147 | 25.87 | 29.49 | 28.14 | 20.54 |
| fr3_w_half | 0.0227 | 0.0162 | 0.0120 | 0.0158 | 0.0142 | 0.0116 | 0.0098 | 0.0082 | 37.45 | 28.40 | 18.33 | 48.10 |
| fr3_w_static | 0.0187 | 0.0103 | 0.0067 | 0.0154 | 0.0072 | 0.0055 | 0.0046 | 0.0046 | 61.50 | 46.60 | 31.34 | 70.13 |
| fr3_s_static | 0.0058 | 0.0050 | 0.0043 | 0.0031 | 0.0054 | 0.0043 | 0.0037 | 0.0030 | 6.90 | 14.00 | 13.95 | 3.23 |
| Sequences | ORB-SLAM3 | YDD-SLAM | Improvements (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | |
| fr3_w_xyz | 0.0148 | 0.0117 | 0.0096 | 0.0091 | 0.0095 | 0.0067 | 0.0056 | 0.0067 | 35.81 | 42.74 | 41.67 | 26.37 |
| fr3_w_rpy | 0.0162 | 0.0131 | 0.0110 | 0.0095 | 0.0122 | 0.0090 | 0.0072 | 0.0083 | 24.69 | 31.30 | 34.55 | 12.63 |
| fr3_w_half | 0.0187 | 0.0109 | 0.0089 | 0.0140 | 0.0102 | 0.0087 | 0.0075 | 0.0054 | 45.46 | 20.18 | 15.73 | 61.43 |
| fr3_w_static | 0.0091 | 0.0060 | 0.0045 | 0.0067 | 0.0046 | 0.0038 | 0.0033 | 0.0026 | 49.45 | 36.67 | 26.67 | 61.19 |
| fr3_s_static | 0.0114 | 0.0036 | 0.0030 | 0.0022 | 0.0039 | 0.0032 | 0.0027 | 0.0021 | 7.14 | 11.11 | 10.00 | 4.55 |
| Sequences | ORB-SLAM3 | YOLO-SLAM3 | Person-SLAM3 | YDD-SLAM |
|---|---|---|---|---|
| fr3_walking_xyz | 0.6930 | 0.0166 | 0.0162 | 0.0151 |
| fr3_walking_rpy | 0.6381 | 0.0607 | 0.0414 | 0.0355 |
| fr3_walking_half | 0.3196 | 0.0341 | 0.0308 | 0.0275 |
| Sequences | ORB-SLAM3 | YOLO-SLAM3 | Person-SLAM3 | YDD-SLAM |
|---|---|---|---|---|
| fr3_walking_xyz | 0.0251 | 0.0130 | 0.0124 | 0.0119 |
| fr3_walking_rpy | 0.0286 | 0.0301 | 0.0265 | 0.0213 |
| fr3_walking_half | 0.0227 | 0.0175 | 0.0153 | 0.0142 |
| Sequences | ORB-SLAM3 | YOLO-SLAM3 | Person-SLAM3 | YDD-SLAM |
|---|---|---|---|---|
| fr3_walking_xyz | 0.0148 | 0.0099 | 0.0097 | 0.0095 |
| fr3_walking_rpy | 0.0162 | 0.0235 | 0.0139 | 0.0122 |
| fr3_walking_half | 0.0187 | 0.0107 | 0.0105 | 0.0102 |
| Sequences | ORB-SLAM3 | Dynamic-VINS [33] | RS-SLAM [39] | DS-SLAM [44] | Det-SLAM [31] | YDD-SLAM (Ours) |
|---|---|---|---|---|---|---|
| fr3_walking_xyz | 0.6930 | 0.0486 | 0.0146 | 0.0247 | 0.0482 | 0.0151 |
| fr3_walking_rpy | 0.6381 | 0.0629 | 0.1869 | 0.4442 | 0.0389 | 0.0355 |
| fr3_walking_half | 0.3196 | 0.0608 | 0.0425 | 0.0303 | 0.0925 | 0.0275 |
| fr3_walking_static | 0.3274 | 0.0077 | 0.0067 | 0.0081 | 0.0017 | 0.0082 |
| fr3_sitting_static | 0.0108 | - | 0.0066 | 0.0065 | 0.0036 | 0.0067 |
| Sequences | fr3_walking_xyz | fr3_walking_rpy | fr3_walking_half | fr3_walking_static | fr3_sitting_static |
|---|---|---|---|---|---|
| Times-Median (CPU) | 69.5404 | 69.5308 | 70.0303 | 69.9896 | 69.9784 |
| Times-Mean (CPU) | 69.8520 | 70.0031 | 70.6693 | 70.4850 | 69.1083 |
| Times-Median (CPU + GPU) | 15.7447 | 16.0031 | 16.7050 | 14.7780 | 15.3516 |
| Times-Mean (CPU + GPU) | 16.3400 | 16.2513 | 17.2688 | 15.8070 | 15.9183 |
| SLAM Algorithm | Dynamic Feature Point Processing | Deep Learning | Tracking Time per Frame | Experimental Platforms |
|---|---|---|---|---|
| RS-SLAM [39] | - | 158.13 | - | Inter i5-7500 CPU Nvidia GTX 1060 GPU (RAM 16 GB) |
| DS-SLAM [44] | 29.5087 | 37.5333 | 59.4 | Inter i7 CPU P 4000 GPU (RAM 32 GB) |
| Dynamic-VINS [33] | 1.3424 | 17.5850 | 19.8980 | HUAWEI Atlas200 DK |
| ORB-SLAM3 | - | - | 15.6624 | AMD R7 4800H CPU Nvidia GTX 2060 GPU (RAM 16 GB) |
| YDD-SLAM | 0.9132 | 11.5 | 16.3171 | AMD R7 4800H CPU Nvidia GTX 2060 GPU (RAM 16 GB) |
| Algorithms | VIRT (MB) | RES (MB) | SHR (MB) | CPU (%) | GPU (MB) |
|---|---|---|---|---|---|
| ORB-SLAM3 (CPU) | 2740.60 | 673.40 | 101.40 | 11.88 | - |
| YOLOv5 (CPU) | 9789.44 | 1550.00 | 405.20 | 49.80 | - |
| YDD-SLAM (CPU) | 12,546.44 | 2192.20 | 507.80 | 61.06 | - |
| YOLOv5 (CPU+GPU) | 12,185.60 | 2827.40 | 684.40 | 3.56 | 1054.80 |
| YDD-SLAM (CPU+GPU) | 14,886.40 | 3496.80 | 786.80 | 16.60 | 1054.80 |
| Sequences | ORB-SLAM3/Linear | YDD-SLAM/Linear | ORB-SLAM3/Annular | YDD-SLAM/Annular |
|---|---|---|---|---|
| Times-Median (CPU) | 14.5005 | 56.6352 | 15.9373 | 56.1799 |
| Times-Mean (CPU) | 15.4729 | 56.3241 | 17.0308 | 55.7422 |
| Times-Median (CPU + GPU) | - | 14.5367 | - | 14.3323 |
| Times-Mean (CPU + GPU) | - | 15.1504 | - | 14.8671 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cong, P.; Liu, J.; Li, J.; Xiao, Y.; Chen, X.; Feng, X.; Zhang, X. YDD-SLAM: Indoor Dynamic Visual SLAM Fusing YOLOv5 with Depth Information. Sensors 2023, 23, 9592. https://doi.org/10.3390/s23239592
Cong P, Liu J, Li J, Xiao Y, Chen X, Feng X, Zhang X. YDD-SLAM: Indoor Dynamic Visual SLAM Fusing YOLOv5 with Depth Information. Sensors. 2023; 23(23):9592. https://doi.org/10.3390/s23239592
Chicago/Turabian StyleCong, Peichao, Junjie Liu, Jiaxing Li, Yixuan Xiao, Xilai Chen, Xinjie Feng, and Xin Zhang. 2023. "YDD-SLAM: Indoor Dynamic Visual SLAM Fusing YOLOv5 with Depth Information" Sensors 23, no. 23: 9592. https://doi.org/10.3390/s23239592
APA StyleCong, P., Liu, J., Li, J., Xiao, Y., Chen, X., Feng, X., & Zhang, X. (2023). YDD-SLAM: Indoor Dynamic Visual SLAM Fusing YOLOv5 with Depth Information. Sensors, 23(23), 9592. https://doi.org/10.3390/s23239592