

SiamPKHT: Hyperspectral Siamese Tracking Based on Pyramid Shuffle Attention and Knowledge Distillation

Abstract
:1. Introduction
- The hyperspectral target tracking algorithm, which uses SiamCAR as the backbone, works at 43 FPS, meeting real-time requirements.
- A feature enhancement module based on pyramid shuffle attention is designed to increase the representation capability of similarity maps by establishing relationships between features and fusing multiscale information.
- To effectively alleviate the problem of overfitting, we design a hyperspectral knowledge distillation training approach that benefits from RGB datasets.
- Comprehensive experiments carried out with the HOT2022 benchmark demonstrate that PSA and HKD can improve the performance of the baseline method. Furthermore, the proposed tracker achieves exceptional performance in all HSVs.

2. Related Work
2.1. Siamese Trackers
2.2. The Attention Mechanism
2.3. Knowledge Distillation
3. Methodology
3.1. The SiamCAR Tracker
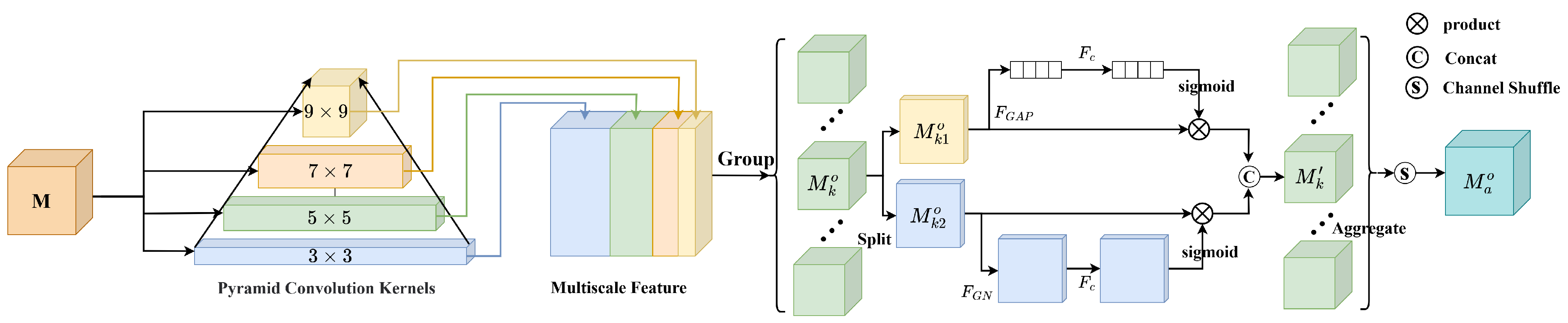
3.2. The Pyramid Shuffle Attention Module
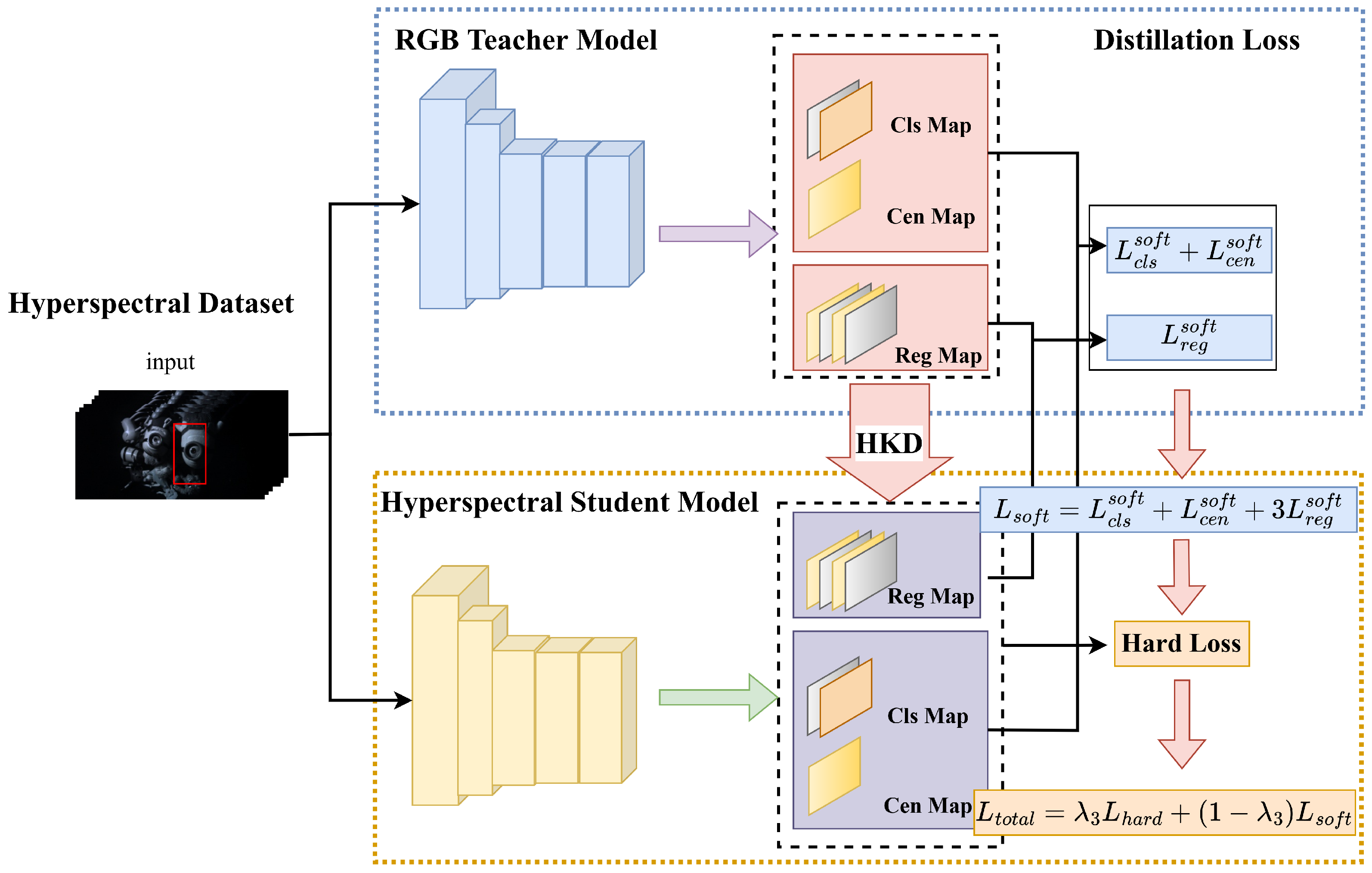
3.3. Hyperspectral Knowledge Distillation
4. Experiments
4.1. Experimental Data
4.2. Experimental Setup
4.3. Experimental Results and Analysis
4.3.1. Qualitative Comparison
4.3.2. Quantitative Comparison
4.3.3. The Ablation Study
- Baseline: The SiamCAR model trained solely on the GOT10K dataset was used as the baseline model.
- Baseline-PSA: The baseline exclusively utilizing the PSA module.
- Baseline-PSA-TL: The baseline with both the PSA module and transfer learning.
- Baseline-PSA-SelfKD: The baseline with both the PSA module and self-knowledge distillation.
- Baseline-PSA-HKD: The baseline with both the PSA module and hyspectral knowledge distillation.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: New York, NY, USA, 2010; pp. 2544–2550. [Google Scholar] [CrossRef]
- Dai, K.; Wang, D.; Lu, H.; Sun, C.; Li, J. Visual tracking via adaptive spatially-regularized correlation filters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4670–4679. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Yang, K.; He, Z.; Zhou, Z.; Fan, N. SiamAtt: Siamese attention network for visual tracking. Knowl.-Based Syst. 2020, 203, 106079. [Google Scholar] [CrossRef]
- Xiong, F.; Zhou, J.; Qian, Y. Material based object tracking in hyperspectral videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar] [CrossRef]
- Uzkent, B.; Rangnekar, A.; Hoffman, M.J. Tracking in aerial hyperspectral videos using deep kernelized correlation filters. IEEE Trans. Geosci. Remote Sens. 2018, 57, 449–461. [Google Scholar] [CrossRef]
- Qian, K.; Zhou, J.; Xiong, F.; Zhou, H.; Du, J. Object tracking in hyperspectral videos with convolutional features and kernelized correlation filter. In Proceedings of the Smart Multimedia: First International Conference, ICSM 2018, Toulon, France, 24–26 August 2018; Revised Selected Papers 1. Springer: Cham, Switzerland, 2018; pp. 308–319. [Google Scholar]
- Zhang, Z.; Qian, K.; Du, J.; Zhou, H. Multi-features integration based hyperspectral videos tracker. In Proceedings of the 2021 11th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 March 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, D.; Zhu, X.; Zhang, Z.; Arun, P.V.; Cao, J.; Wang, Q.; Zhou, H.; Jiang, H.; Hu, J.; Qian, K. Hyperspectral video target tracking based on pixel-wise spectral matching reduction and deep spectral cascading texture features. Signal Process. 2023, 209, 109033. [Google Scholar] [CrossRef]
- Li, Z.; Xiong, F.; Zhou, J.; Wang, J.; Lu, J.; Qian, Y. BAE-Net: A band attention aware ensemble network for hyperspectral object tracking. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: New York, NY, USA, 2020; pp. 2106–2110. [Google Scholar] [CrossRef]
- Wang, S.; Qian, K.; Shen, J.; Ma, H.; Chen, P. AD-SiamRPN: Anti-Deformation Object Tracking via an Improved Siamese Region Proposal Network on Hyperspectral Videos. Remote Sens. 2023, 15, 1731. [Google Scholar] [CrossRef]
- Li, W.; Hou, Z.; Zhou, J.; Tao, R. SiamBAG: Band Attention Grouping-based Siamese Object Tracking Network for Hyperspectral Videos. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5514712. [Google Scholar] [CrossRef]
- Li, Z.; Xiong, F.; Zhou, J.; Lu, J.; Qian, Y. Learning a Deep Ensemble Network with Band Importance for Hyperspectral Object Tracking. IEEE Trans. Image Process. 2023, 32, 2901–2914. [Google Scholar] [CrossRef]
- Gao, L.; Liu, P.; Jiang, Y.; Xie, W.; Lei, J.; Li, Y.; Du, Q. CBFF-Net: A New Framework for Efficient and Accurate Hyperspectral Object Tracking. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5506114. [Google Scholar] [CrossRef]
- Lei, J.; Liu, P.; Xie, W.; Gao, L.; Li, Y.; Du, Q. Spatial–spectral cross-correlation embedded dual-transfer network for object tracking using hyperspectral videos. Remote Sens. 2022, 14, 3512. [Google Scholar] [CrossRef]
- Qian, K.; Chen, P.; Zhao, D. GOMT: Multispectral video tracking based on genetic optimization and multi-features integration. IET Image Process. 2023, 17, 1578–1589. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar] [CrossRef]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Proceedings, Part II 14. Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Zhang, Z.; Liu, Y.; Wang, X.; Li, B.; Hu, W. Learn to match: Automatic matching network design for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13339–13348. [Google Scholar] [CrossRef]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.v.d.; Danelljan, M.; Khan, F.S. Learning the model update for siamese trackers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4010–4019. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Cham, Switzerland, 2020; pp. 771–787. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar] [CrossRef]
- Yang, J.; Ren, P.; Zhang, D.; Chen, D.; Wen, F.; Li, H.; Hua, G. Neural aggregation network for video face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4362–4371. [Google Scholar] [CrossRef]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Wang, Q.; Teng, Z.; Xing, J.; Gao, J.; Hu, W.; Maybank, S. Learning attentions: Residual attentional siamese network for high performance online visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4854–4863. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Zhong, Y.; Shu, M.; Sun, C. SiamHYPER: Learning a hyperspectral object tracker from an RGB-based tracker. IEEE Trans. Image Process. 2022, 31, 7116–7129. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 2235–2239. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Liu, I.J.; Peng, J.; Schwing, A.G. Knowledge flow: Improve upon your teachers. arXiv 2019, arXiv:1904.05878. [Google Scholar]
- Lin, S.; Ji, R.; Chen, C.; Tao, D.; Luo, J. Holistic cnn compression via low-rank decomposition with knowledge transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2889–2905. [Google Scholar] [CrossRef]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar] [CrossRef]
- Sepahvand, M.; Abdali-Mohammadi, F.; Taherkordi, A. An adaptive teacher—student learning algorithm with decomposed knowledge distillation for on-edge intelligence. Eng. Appl. Artif. Intell. 2023, 117, 105560. [Google Scholar] [CrossRef]
- Gao, W.; Xu, C.; Li, G.; Zhang, Y.; Bai, N.; Li, M. Cervical Cell Image Classification-Based Knowledge Distillation. Biomimetics 2022, 7, 195. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, X.; Gao, F.; Dong, J. Pair-Wise Similarity Knowledge Distillation for RSI Scene Classification. Remote Sens. 2022, 14, 2483. [Google Scholar] [CrossRef]
- Kim, S. A virtual knowledge distillation via conditional GAN. IEEE Access 2022, 10, 34766–34778. [Google Scholar] [CrossRef]
- Liu, T.; Lam, K.M.; Zhao, R.; Qiu, G. Deep cross-modal representation learning and distillation for illumination-invariant pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 315–329. [Google Scholar] [CrossRef]
- Chai, Y.; Fu, K.; Sun, X.; Diao, W.; Yan, Z.; Feng, Y.; Wang, L. Compact cloud detection with bidirectional self-attention knowledge distillation. Remote Sens. 2020, 12, 2770. [Google Scholar] [CrossRef]
- Wang, W.; Hong, W.; Wang, F.; Yu, J. Gan-knowledge distillation for one-stage object detection. IEEE Access 2020, 8, 60719–60727. [Google Scholar] [CrossRef]
- Park, S.; Heo, Y.S. Knowledge distillation for semantic segmentation using channel and spatial correlations and adaptive cross entropy. Sensors 2020, 20, 4616. [Google Scholar] [CrossRef]
- Qin, D.; Bu, J.J.; Liu, Z.; Shen, X.; Zhou, S.; Gu, J.J.; Wang, Z.H.; Wu, L.; Dai, H.F. Efficient medical image segmentation based on knowledge distillation. IEEE Trans. Med. Imaging 2021, 40, 3820–3831. [Google Scholar] [CrossRef] [PubMed]
- An, S.; Liao, Q.; Lu, Z.; Xue, J.H. Efficient semantic segmentation via self-attention and self-distillation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15256–15266. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar] [CrossRef]
- Duta, I.C.; Liu, L.; Zhu, F.; Shao, L. Pyramidal convolution: Rethinking convolutional neural networks for visual recognition. arXiv 2020, arXiv:2006.11538. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Hershey, J.R.; Olsen, P.A. Approximating the Kullback Leibler divergence between Gaussian mixture models. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; IEEE: New York, NY, USA, 2007; Volume 4, p. IV-317. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Wang, S.; Qian, K.; Chen, P. BS-SiamRPN: Hyperspectral video tracking based on band selection and the Siamese region proposal network. In Proceedings of the 2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Rome, Italy, 13–16 September 2022; IEEE: New York, NY, USA, 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar] [CrossRef]
- Kim, K.; Ji, B.; Yoon, D.; Hwang, S. Self-knowledge distillation: A simple way for better generalization. arXiv 2020, arXiv:2006.12000. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | Car2 | Forest2 | Paper | Pedestrian2 | Rider1 | Student |
|---|---|---|---|---|---|---|
| Frame | 131 | 363 | 278 | 363 | 336 | 396 |
| Resolution | 351 × 167 | 512 × 256 | 446 × 224 | 512 × 256 | 512 × 256 | 438 × 256 |
| Algorithm | Video Type | AUC | DP@20P | FPS |
|---|---|---|---|---|
| DaSiamRPN | false-color | 0.558 | 0.831 | 48 |
| SiamRPN++ | false-color | 0.529 | 0.834 | 41 |
| DeepHKCF | HSV | 0.385 | 0.737 | 2 |
| BS-SiamRPN | HSV | 0.533 | 0.845 | 55 |
| ADSiamRPN | HSV | 0.575 | 0.861 | 35 |
| MHT | HSV | 0.584 | 0.876 | 2 |
| MFIHVT | HSV | 0.601 | 0.891 | 2 |
| BAENet | HSV | 0.616 | 0.876 | ≈1 |
| Ours | HSV | 0.631 | 0.888 | 43 |
| Attributes | Ours | BAENet | MFIHVT | MHT | ADSiamRPN | BSSiamRPN | DeepHKCF | SiamRPN++ | DaSiamRPN |
|---|---|---|---|---|---|---|---|---|---|
| BC | 0.624 | 0.631 | 0.627 | 0.594 | 0.625 | 0.495 | 0.422 | 0.555 | 0.623 |
| DEF | 0.699 | 0.679 | 0.639 | 0.664 | 0.689 | 0.613 | 0.542 | 0.648 | 0.667 |
| FM | 0.590 | 0.607 | 0.589 | 0.541 | 0.528 | 0.576 | 0.377 | 0.539 | 0.532 |
| IPR | 0.676 | 0.699 | 0.692 | 0.670 | 0.632 | 0.565 | 0.549 | 0.569 | 0.632 |
| IV | 0.603 | 0.440 | 0.472 | 0.474 | 0.473 | 0.551 | 0.154 | 0.473 | 0.360 |
| LR | 0.579 | 0.491 | 0.513 | 0.478 | 0.535 | 0.558 | 0.187 | 0.531 | 0.449 |
| MB | 0.584 | 0.594 | 0.570 | 0.560 | 0.562 | 0.554 | 0.411 | 0.553 | 0.564 |
| OCC | 0.565 | 0.555 | 0.546 | 0.565 | 0.528 | 0.467 | 0.312 | 0.493 | 0.497 |
| OPR | 0.654 | 0.693 | 0.675 | 0.631 | 0.653 | 0.570 | 0.503 | 0.588 | 0.650 |
| OV | 0.641 | 0.516 | 0.606 | 0.620 | 0.356 | 0.554 | 0.312 | 0.505 | 0.353 |
| SV | 0.624 | 0.608 | 0.596 | 0.564 | 0.560 | 0.557 | 0.353 | 0.544 | 0.531 |
| Attributes | Ours | BAENet | MFIHVT | MHT | ADSiamRPN | BSSiamRPN | DeepHKCF | SiamRPN++ | DaSiamRPN |
|---|---|---|---|---|---|---|---|---|---|
| BC | 0.886 | 0.908 | 0.918 | 0.942 | 0.901 | 0.795 | 0.755 | 0.85 | 0.899 |
| DEF | 0.98 | 0.94 | 0.885 | 0.901 | 0.975 | 0.908 | 0.82 | 0.963 | 0.937 |
| FM | 0.877 | 0.871 | 0.832 | 0.841 | 0.859 | 0.872 | 0.874 | 0.807 | 0.859 |
| IPR | 0.935 | 0.985 | 0.951 | 0.964 | 0.918 | 0.873 | 0.846 | 0.868 | 0.914 |
| IV | 0.887 | 0.745 | 0.939 | 0.85 | 0.791 | 0.876 | 0.56 | 0.881 | 0.621 |
| LR | 0.855 | 0.733 | 0.872 | 0.801 | 0.853 | 0.912 | 0.563 | 0.846 | 0.699 |
| MB | 0.845 | 0.881 | 0.841 | 0.844 | 0.855 | 0.96 | 0.851 | 0.869 | 0.867 |
| OCC | 0.818 | 0.79 | 0.811 | 0.812 | 0.81 | 0.756 | 0.601 | 0.801 | 0.754 |
| OPR | 0.922 | 0.978 | 0.942 | 0.958 | 0.906 | 0.875 | 0.809 | 0.883 | 0.898 |
| OV | 0.855 | 0.864 | 0.895 | 0.851 | 0.488 | 0.859 | 0.918 | 0.846 | 0.488 |
| SV | 0.909 | 0.907 | 0.905 | 0.895 | 0.856 | 0.864 | 0.748 | 0.873 | 0.811 |
| Algorithm | Video Type | AUC | DP@20P |
|---|---|---|---|
| Baseline | false-color | 0.599 | 0.859 |
| Baseline-PSA | HSV | 0.617 | 0.881 |
| Baseline-PSA-TL | HSV | 0.619 | 0.873 |
| Baseline-PSA-SelfKD | HSV | 0.622 | 0.884 |
| Baseline-PSA-HKD | HSV | 0.631 | 0.888 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, K.; Wang, S.; Zhang, S.; Shen, J. SiamPKHT: Hyperspectral Siamese Tracking Based on Pyramid Shuffle Attention and Knowledge Distillation. Sensors 2023, 23, 9554. https://doi.org/10.3390/s23239554
Qian K, Wang S, Zhang S, Shen J. SiamPKHT: Hyperspectral Siamese Tracking Based on Pyramid Shuffle Attention and Knowledge Distillation. Sensors. 2023; 23(23):9554. https://doi.org/10.3390/s23239554
Chicago/Turabian StyleQian, Kun, Shiqing Wang, Shoujin Zhang, and Jianlu Shen. 2023. "SiamPKHT: Hyperspectral Siamese Tracking Based on Pyramid Shuffle Attention and Knowledge Distillation" Sensors 23, no. 23: 9554. https://doi.org/10.3390/s23239554
APA StyleQian, K., Wang, S., Zhang, S., & Shen, J. (2023). SiamPKHT: Hyperspectral Siamese Tracking Based on Pyramid Shuffle Attention and Knowledge Distillation. Sensors, 23(23), 9554. https://doi.org/10.3390/s23239554