4.1. Dataset and Data Preprocessing
First, this paper uses the C-MAPSS dataset provided by the NASA-Ames Research Center [
26], divided into four subsets, FD001~FD004, according to different operating conditions and failure modes. Each subset consists of a training set and a test set. The training dataset contains the whole lifetime data, and the testing dataset includes the initial degradation data within a period of time, which are used for model validation. The detailed setup is shown in
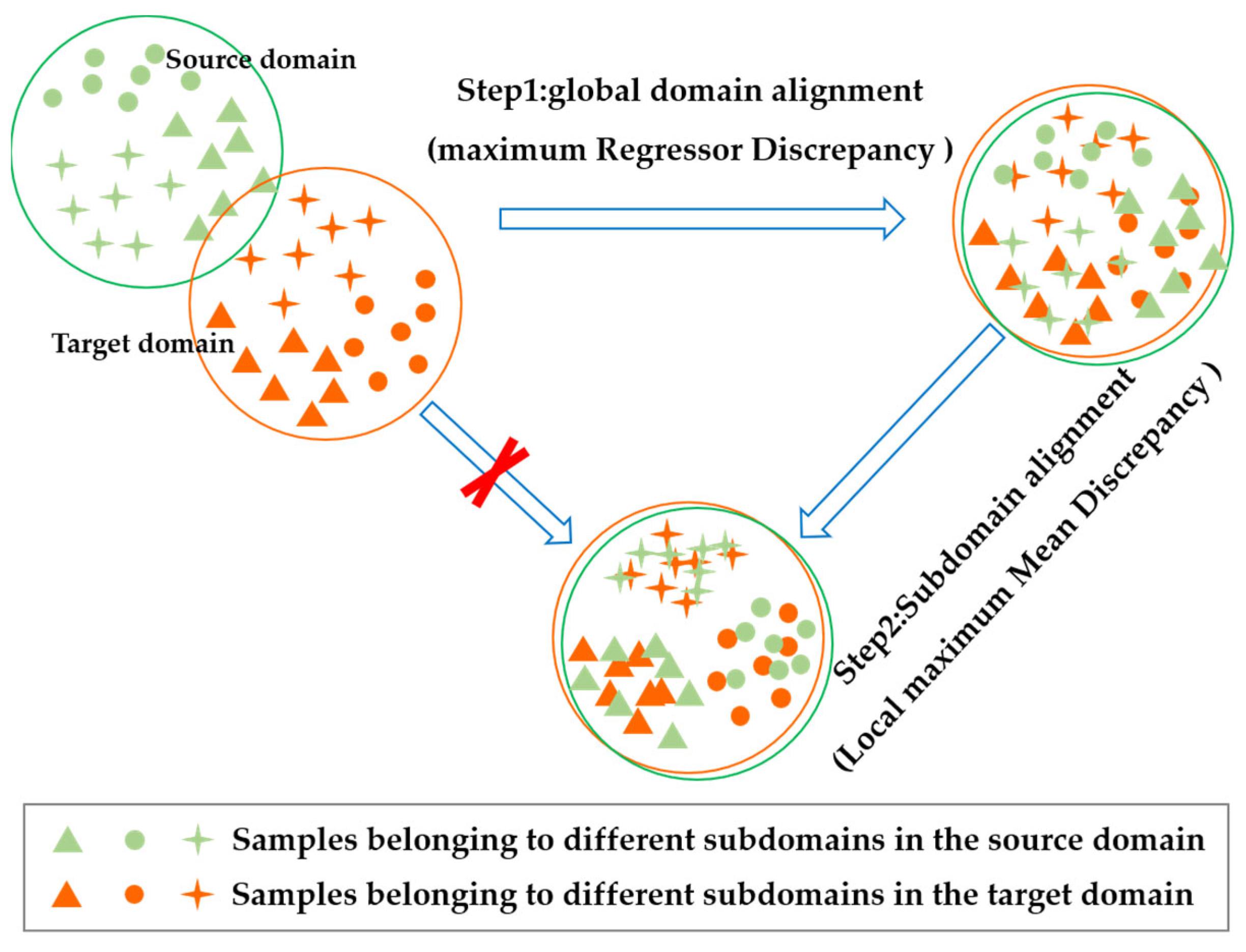
Table 1. Since the four sub-datasets were obtained under different failure modes and operating conditions, the data distributions significantly differed. In this sense, the research objective of this paper is to train the BDnet only using the labeled source domain data under a certain operational condition and the unlabeled target domain data under another operational condition. Furthermore, the RUL prediction is implemented for the online target domain data.
The monitoring data for each flight cycle consist of 26 dimensions of feature data, where the first two dimensions denote the engine (unit) number and the cycle number. The following three dimensions are the flight conditions (flight altitude, Mach number, and throttle-stick solver angle), and the remaining 21 dimensions are the monitoring data. In addition, to prevent the redundancy and interaction of the multidimensional sensor data from adversely affecting the RUL prediction, this paper analyzes the degree of correlation among the sensors and the trend of degradation of each sensor over time to select the optimal sensor signal for the RUL prediction. The correlation and monotonicity measures can be expressed as follows [
27].
where
c and
represent correlation and monotonicity, respectively.
represents the feature value at cycle
.
represents the unit step function.
indicates the quantity of the signals. The range of both
and
is [0, 1].
c = 1 represents the complete correlation, and
m = 1 represents the monotonic increasing or monotonic decreasing. Thus, sensors with a larger
can better represent the changing trend and are selected. Take FD001 as an example: #2, #3, #4, #7, #8, #11, #12, #13, #15, #17, #20, and #21 are selected when the threshold is set to 0.75.
Moreover, the same sensor may have different measurements under different operating conditions. In order to reduce the effect of the operating conditions, the sensor data under each operating condition are min–max normalized so that the data size is limited to the range of [0, 1]. Finally, a time window with a window size of 30 and a step size of 1 is utilized to divide the raw data to generate the training and testing datasets.
4.2. Simulation Conditions and Parameter Settings
The hardware and software environment of the simulation is an NVIDIA GeForce RTX 3060 Laptop GPU, an Intel Core i7-11800 H CPU, 32 G RAM, Windows 11, and Python 3.7, based on the PyTorch framework. Manufacturer is Lenovo (Beijing, China).
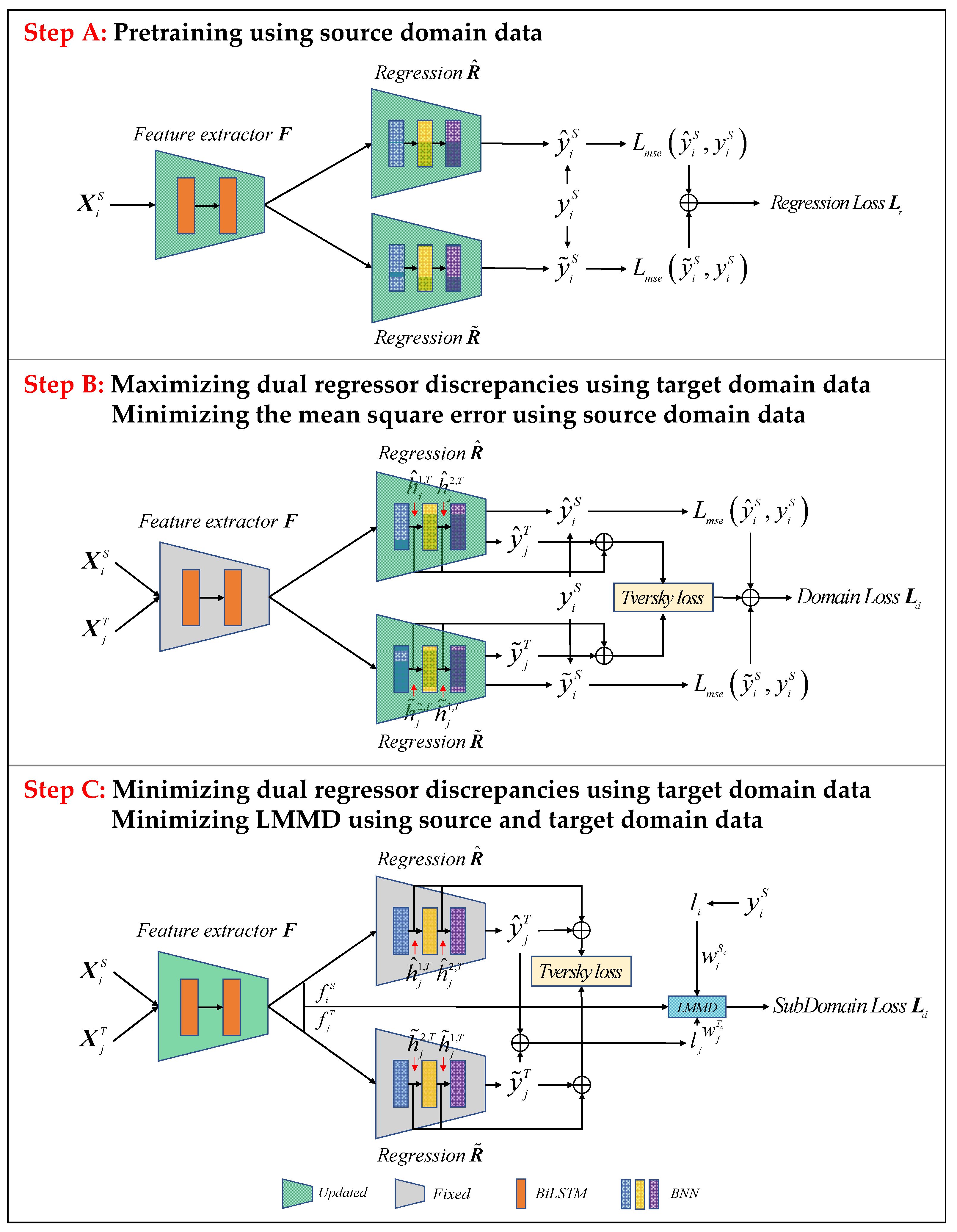
The BDnet consists of three main parts: a feature extractor, a dual regressor, and a subdomain adaptor. The main parameters are defined as follows: the time window length is set to 30, the number of loops is 200, the early stop mechanism is set, the degeneracy inflection point is 125, the hidden layer dimension of the dual regressor is 32, and the optimizer adopts the Adam optimizer. In addition, the performance of the prediction model may be affected by the different batch sizes in the neural network, the learning rate of the feature extractor, the learning rate of the dual regressor, the dimension of the hidden layer of the Bi-LSTM, the number of layers of the Bi-LSTM, and the scaling factor. Therefore, it is essential to investigate the adaptability and robustness of the model for different tasks by adjusting the hyperparameters. The hyperparameter configuration is shown in
Table 2.
Take FD001–FD002 as an example to discuss the influence of the hyperparameters on prediction performance, and the results are shown in
Figure 4. As shown in
Figure 4, the cross-domain prediction performance is best when the batch size is 256, the feature extractor learning rate is 0.005, the dual regressor learning rate is 0.01, the number of Bi-LSTM layers is five, the dimension of the Bi-LSTM hidden layer is 32, and
is 0.3. The hyperparameter settings for all the cross-domain combinatorial research tasks are shown in
Table 3.
4.4. Experimental Results Analysis and Discussions
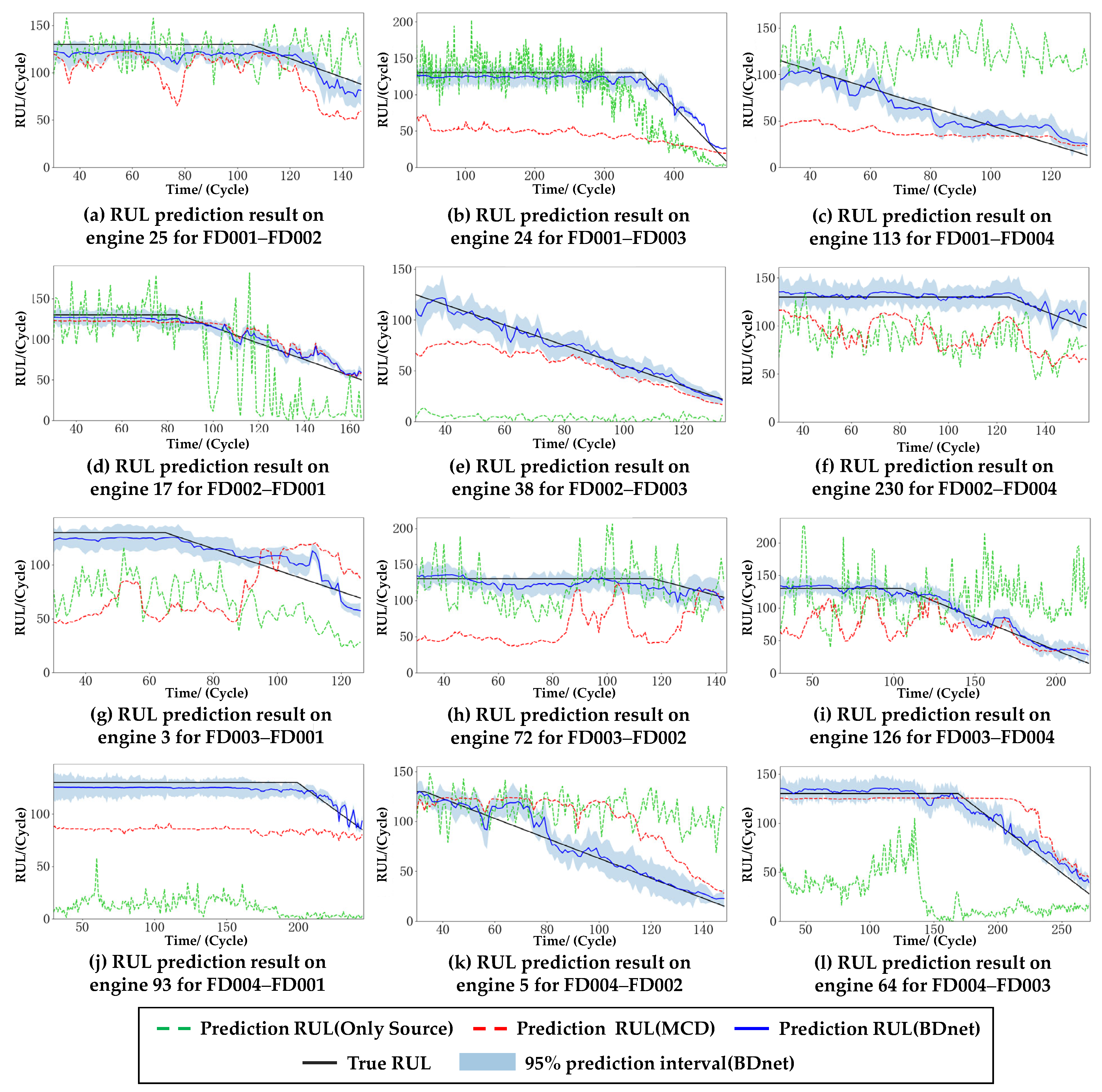
In order to validate the performance of the BDnet on the cross-domain prediction tasks, ablation experiments are first performed. The model that only utilizes the feature extractor and dual regressor directly trained with the source domain data on the target domain data is defined as model 1, which can be considered as the benchmark model for the RUL prediction problem. The model that uses the MCD is defined as model 2, and the model that uses both the MCD and the LMMD is defined as model 3. The three models’ predictions, as mentioned above, are compared with the real RUL. The models are trained using the source domain data and evaluated on the target domain. Since the C-MAPSS dataset has four subsets, 12 cross-domain prediction tasks are generated, and the results are shown in
Figure 5.
First, model 3 gives the highest accuracy on all 12 cross-domain prediction tasks. Second, model 2 and model 3 are more stable and less fluctuating than model 1.
Taking FD001 as the source domain data, the cross-domain prediction results for the target domains of FD002, FD003, and FD004 are shown in
Figure 5a–c, respectively. Since FD001 has a significant distributional discrepancy compared to FD002 and FD004, an apparent two-stage optimization structure can be seen, i.e., the distribution of the source and target domains is firstly brought closer by the GDA to learn the degradation trend of the target domain (red dashed line). Then, the prediction results are fine-tuned by the SDA to better fit with the real RUL (blue solid line). Although the data distributions of FD001 and FD003 are more similar, model 2 in
Figure 5b gives the most significant prediction error compared to model 2 in
Figure 5a,c. This is mainly because the maximum regressor difference is optimized by finding the difference features between the source and target domains. If the difference is slight, then multiple pieces of training may lead to overfitting. Therefore, we increase the degree of subdomain adaptivity by increasing the value of
to achieve higher prediction accuracy.
Figure 5d–f demonstrate the cross-domain prediction results with the source domain as FD002 and the target domains as FD001, FD003, and FD004. Similar to the results with the source domain as FD001, the prediction accuracy is higher when the target domains are FD001 and FD003, and FD001 does not need subdomain adaptation because FD001 has only one failure mode compared to FD003.
Figure 5g–i demonstrate the cross-domain prediction results with FD003 as the source domain, and the prediction results of model 2 for all three tasks are significantly degraded, which is mainly due to the multi-fault modes. In addition, the degradation trend of the target domains, FD002 and FD004, is consistent with the real RUL. In contrast, the degradation trend of the target domain, FD001, shows a significant deviation from the real RUL. Thus, the λ of this group of experiments is increased in comparison with that of the previous two groups of experiments.
Like the last set of experiments, the source domain, FD004, also has two fault modes. However, the prediction results are better because FD004 has more training data and adequate feature extraction.
As shown in
Table 4, model 1 has the worst prediction performance, and its prediction results heavily rely on the similarity between the source and target domain data distributions. For model 2, except for the four results of the RMSE and the two results of the SF (underlined) that are higher than their counterparts in model 1, the other results are better than their counterparts in model 1, and the result of the RMSE for FD002–FD001 in model 2 is the optimal result for the three models (bold). For model 3, all results are optimal for the three models, except for a result of the RMSE that is slightly higher than the corresponding result in model 2. Compared to model 1, the prediction model without domain adaptation, model 3 has an average reduction of 50.62% and 76.99% for the results of the RMSE and SF. Compared to model 2, with only global domain adaptation, model 3 has an average reduction of 35.16% and 47.66% for the results of the RMSE and SF. Therefore, in most cases, model 3 predicts better than model 1 and model 2, proving the effectiveness of the BDnet-based prediction model.
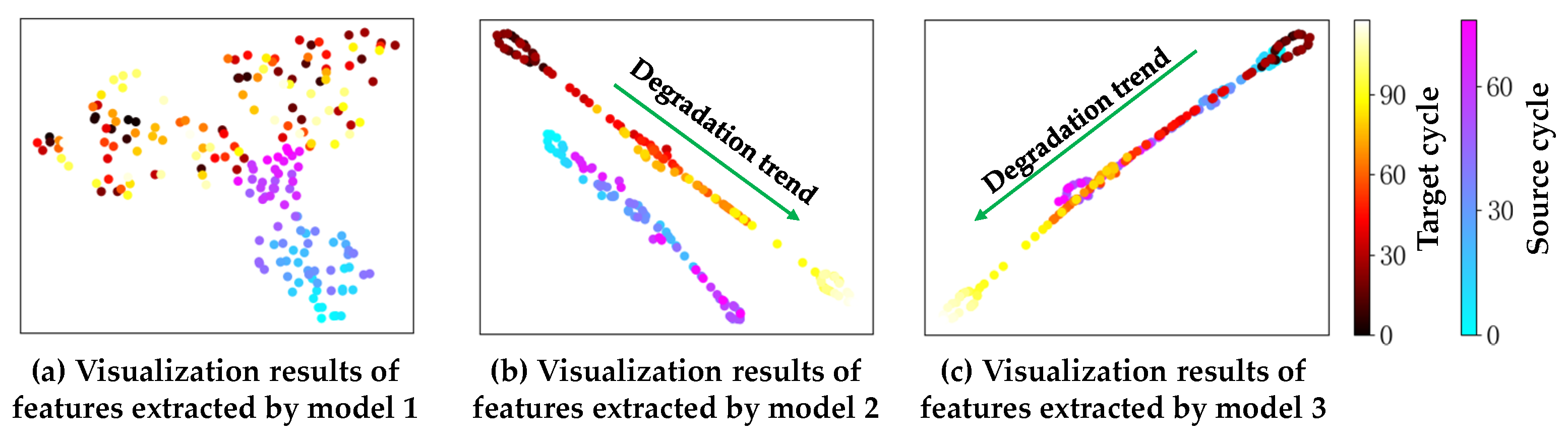
Figure 6 depicts the distribution of the feature vectors extracted by the three models to further validate the migration learning effect based on the BDnet prediction model (t-SNE is used in this work). For model 1, the representations of the features extracted from the source and target domains are more dispersed in two-dimensional space, and the degradation trend is not apparent enough, which further illustrates the discrepancy in the data distribution under different operating conditions and fault modes. With global domain adaptation, the degradation trend shown in
Figure 6b is pronounced, and there is only a slight deviation in the distribution of features extracted from the two domains. Fine-tuned by subdomain adaptation, the health status of the two domains in model 3 are clustered in the same region, and the degradation processes are well-aligned. Thus, the visualization results intuitively validate the effectiveness of the BDnet-based prediction model.
To assess the quality of the model in transferring the degradation patterns from a source to a target domain, the BDnet-based predictive model is compared with four mainstream UDA methods targeting the C-MAPSS dataset. TCA-DNN and CORAL-DNN are UDA methods that combine traditional machine learning algorithms with deep neural architectures. TCA [
28] uses MMD to learn cross-domain migration components in the regenerative kernel RKHS to construct a feature space that minimizes the domain differences. CORAL [
29] aligns the second-order statistical features of the distributions of the source and the target domains using linear transformations. LSTM-DNN [
19] and CADA [
20] are typical adversarial UDA methods. LSTM-DNN consists of a feature extractor, a RUL predictor, and a domain discriminator, whereas CADA adds a contrast loss estimation module to minimize adversarial loss.
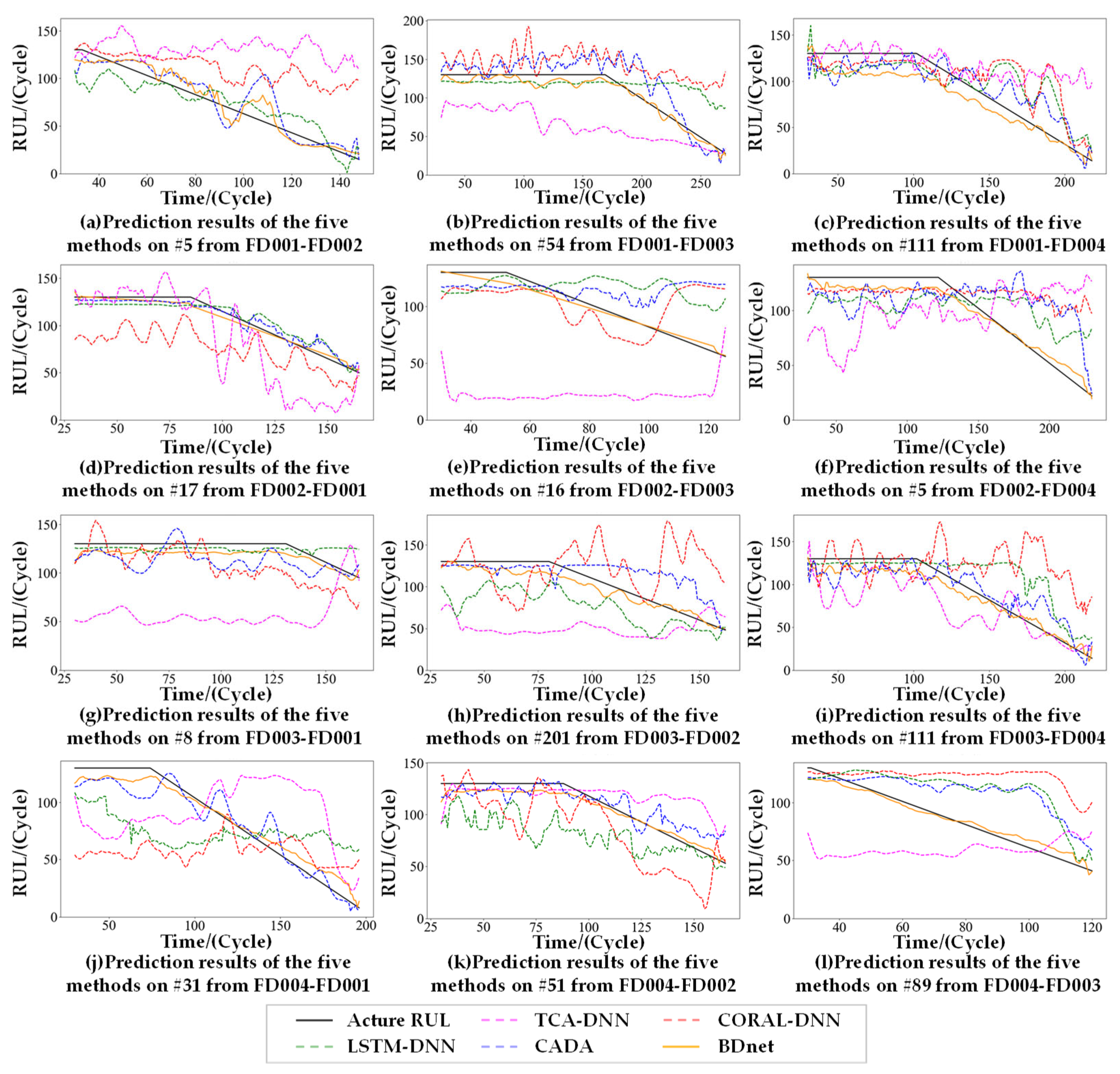
Twelve engines were randomly selected for comparison experiments on 12 cross-domain prediction tasks, and
Figure 7 demonstrates the combined comparison results of the 12 engines for the five methods. The proposed method achieves good prediction performance compared to the four mainstream methods. TCA-DNN and CORAL-DNN are basically unable to learn the trend information of the degradation process. Although LSTM-DNN can learn the trend information of the degradation process, the prediction results significantly differ from the actual value due to the lack of local subdomain adaptation. In contrast, CADA obtained better prediction results by the contrastive loss module for fine-tuning, but, compared with the BDnet, CADA’s prediction results have greater volatility.
The comparative experimental results of the RMSE are shown in
Table 5. The proposed method is better than TCA-DNN, CORAL-DNN, and LSTM-DNN on all 12 cross-domain prediction tasks, with only four tasks being slightly lower than CADA, with an average reduction of 77.24%, 61.72%, 38.97%, and 3.35% in the RMSE values compared to the four comparison methods.
The comparative experimental results of the SF are shown in
Table 6. The proposed method is better than TCA-DNN [
19], CORAL-DNN [
19], and LSTM-DNN [
19] on all 12 cross-domain prediction tasks, with six tasks being slightly lower than CADA [
20], with an average reduction of 42.12% in the RMSE values compared to CADA.
In addition, the BDnet significantly improves the prediction performance of the larger domain offset prediction task while maintaining the performance of the smaller domain offset prediction task, proving the superiority of the BDnet without introducing other auxiliary models.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}