
Remote Sensing Image Ship Matching Utilising Line Features for Resource-Limited Satellites



Abstract
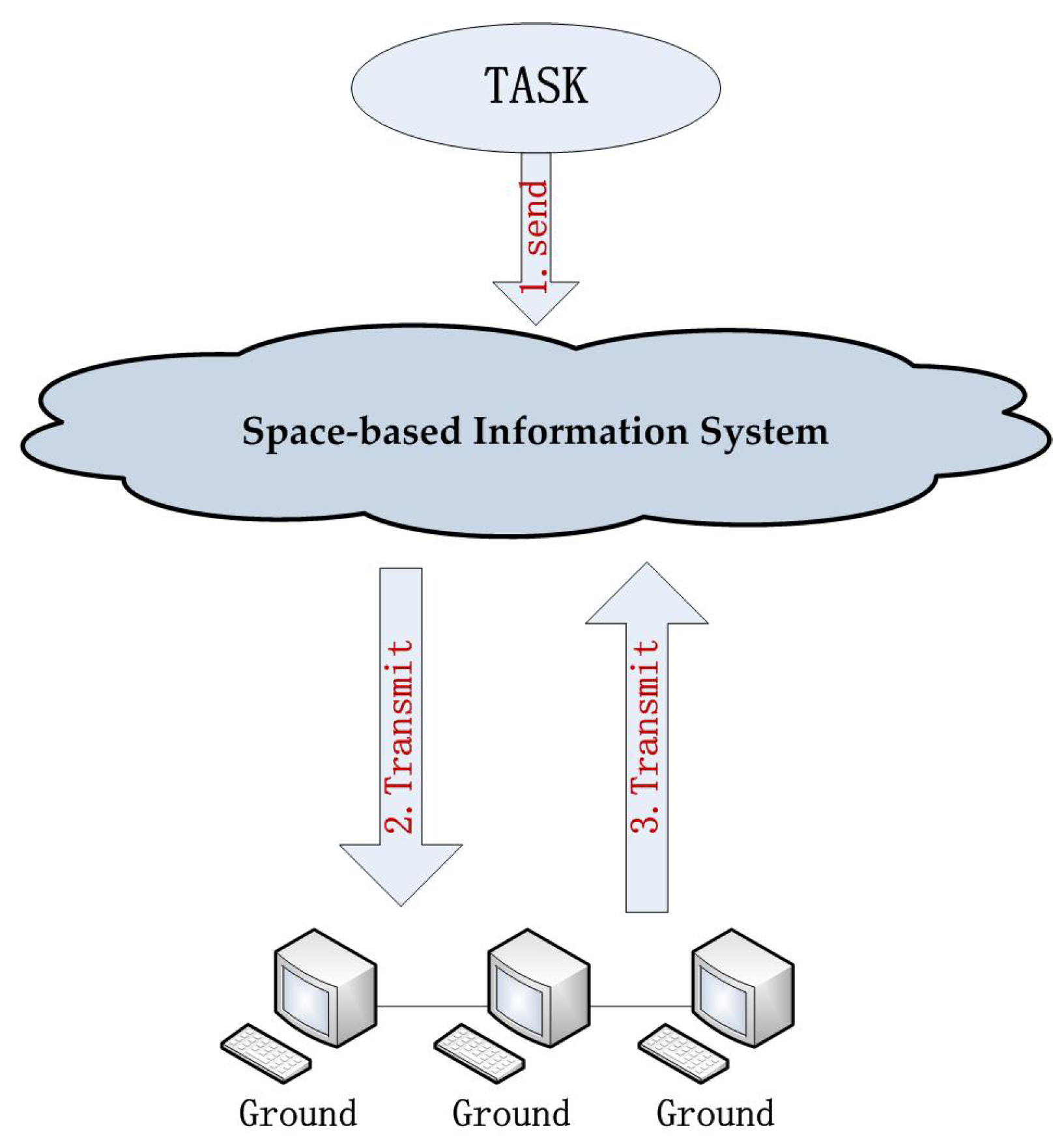
:1. Introduction
- (1)
- We propose a keypoint extraction method, utilising line features to assist the keypoint selection. The keypoints selected in this way are sparse and more reasonable/precise, which aid to improve the accuracy and efficiency of the algorithm.
- (2)
- We use a function to crop images during the matching process, which achieves end-to-end matching.
- (3)
- We create new remote sensing image dataset about three kinds of ships (i.e., aircraft carrier, cargo ship and submarine), with variations in light, angle and size. Using this created remote sensing data, we experimentally show that too many dense keypoints are generally unnecessary for this image matching task partly because the fundamental matrix for image matching can be calculated with only eight points [11].
2. Related Work
2.1. Overview of Feature Detectors
2.2. Image Matching Models
2.3. Image Matching in Remote Sensing
3. Proposed Method
3.1. Keypoints Extraction with Line Features
3.2. Matching Process
| Algorithm 1: Matching algorithm for remote sensing utilising line features |
Input: an image pair , Output: the matching set
|
4. Results
4.1. Data
4.1.1. Dataset NWPU VHR-10
4.1.2. Dataset HRSC
4.1.3. Our Dataset
4.2. Evaluation Metric
4.3. Results
4.4. Ablation Study
4.5. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DCSS | Deformed Contour Segment Similarity |
| CNN | Convolutional Neural Network |
| SIFT | Scale Invariant Feature Transform |
| SURF | Speeded Up Robust Features |
| ORB | Oriented Fast and Rotated Brief |
| LoG | Laplacian of Gaussian |
| DoG | Difference of Gaussians |
| FLD | Fast Line Detector |
| LSD | Line Segment Detector |
References
- Li, D.; Shen, X.; Chen, N.; Xiao, Z. Space-based information service in internet plus era. Sci. China Inf. Sci. 2017, 60, 102308. [Google Scholar] [CrossRef]
- Liu, T.; Yang, Z.; Marino, A.; Gao, G.; Yang, J. Robust CFAR detector based on truncated statistics for polarimetric synthetic aperture radar. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6731–6747. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Du, W.; Wu, W. Saliency-aware convolution neural network for ship detection in surveillance video. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 781–794. [Google Scholar] [CrossRef]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Capobianco, S.; Forti, N.; Millefiori, L.M.; Braca, P.; Willett, P. Recurrent encoder-decoder networks for vessel trajectory prediction with uncertainty estimation. IEEE Trans. Aerosp. Electron. Syst. 2022, 59, 2554–2565. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. IJCV 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13 June–19 June 2020; pp. 4938–4947. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up Robust Features. In Computer Vision–ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and robust matching for multimodal remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-modal image matching based on radiation-variation insensitive feature transform. IEEE Trans. Image Process. 2019, 29, 3296–3310. [Google Scholar] [CrossRef]
- Hartley, R.I. In defense of the eight-point algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 580–593. [Google Scholar] [CrossRef]
- Moravec, H.P. Towards Automatic Visual Obstacle Avoidance. In Proceedings of the IJCAI1977, Cambridge, MA, USA, 22–25 August 1977. [Google Scholar]
- Harris, C.G.; Stephens, M.J. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, September 1988. [Google Scholar] [CrossRef]
- Rosten, E. Machine Learning for High-Speed Corner Detection. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Smith, S.M.; Brady, J.M. SUSAN—A New Approach to Low Level Image Processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Canny, J.F. A computational approach to edge detection. Readings Comput. Vis. 1987, 184–203. [Google Scholar] [CrossRef]
- Perona, P.; Malik, J. Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639. [Google Scholar] [CrossRef]
- Sandu, I.R.; Antoniu, E. Laplacian-of-Gaussian Filter in Edge Detection. Tensor 1993, 53, 215–222. [Google Scholar]
- Lindeberg, T. Scale-Space Theory: A Framework for Handling Image Structures at Multiple Scales. 1996. Available online: https://cds.cern.ch/record/400314/files/p27.pdf (accessed on 8 October 2023).
- Derpanis, K.G. The Harris Corner Detector. In Symposium Svenska Sllskapet Fr Bildanalys; York University: Toronto, ON, Canada, 2004. [Google Scholar]
- Shi, J.; Tomasi, C. Good Features to Track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; IEEE: Piscataway, NJ, USA, 2002. [Google Scholar]
- John, C. A computational approach for edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Lepetit, V.; Fua, P. Keypoint Recognition Using Randomized Trees. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1465–1479. [Google Scholar] [CrossRef] [PubMed]
- Strecha, C.; Lindner, A.; Ali, K.; Fua, P.; Süsse, H. Training for Task Specific Keypoint Detection; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hartmann, W.; Havlena, M.; Schindler, K. Predicting Matchability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Verdie, Y.; Yi, K.; Fua, P.; Lepetit, V. TILDE: A Temporally Invariant Learned DEtector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zitová, B.; Flusser, J. Image Registration Methods: A Survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Li, Z.; Mahapatra, D.; Tielbeek, J.A.W.; Stoker, J.; Vliet, L.J.V.; Vos, F.M. Image Registration Based on Autocorrelation of Local Structure. In Proceedings of the Interspeech, Singapore, 14–18 September 2014. [Google Scholar]
- Reddy, B.S.; Chatterji, B.N. An FFT-based technique for translation, rotation, and scale-invariant image registration. IEEE Trans. Image Process. 1996, 5, 1266–1271. [Google Scholar] [CrossRef]
- Lin, W.Y.; Liu, S.; Jiang, N.; Do, M.N.; Lu, J. RepMatch: Robust Feature Matching and Pose for Reconstructing Modern Cities. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lazaridis, G.; Petrou, M. Image registration using the Walsh transform. IEEE Trans. Image Process. 2006, 15, 2343–2357. [Google Scholar] [CrossRef]
- Wei, S.D.; Pan, W.H.; Lai, S.H. Efficient NCC-Based Image Matching Based on Novel Hierarchical Bounds. In Proceedings of the Pacific Rim Conference on Multimedia: Advances in Multimedia Information Processing, Bangkok, Thailand, 15–18 December 2009. [Google Scholar]
- Wu, Q.; Xu, G.; Cheng, Y.; Wang, Z.; Li, Z. Deformed contour segment matching for multi-source images. Pattern Recognit. 2021, 117, 107968. [Google Scholar] [CrossRef]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. arXiv 2019, arXiv:1905.00537. [Google Scholar]
- Wang, G.; Luo, C.; Xiong, Z.; Zeng, W. Spm-tracker: Series-parallel matching for real-time visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3643–3652. [Google Scholar]
- Liao, Y.; Liu, S.; Wang, F.; Chen, Y.; Qian, C.; Feng, J. Ppdm: Parallel point detection and matching for real-time human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 482–490. [Google Scholar]
- Cheng, L.; Li, M.; Liu, Y.; Cai, W.; Chen, Y.; Yang, K. Remote sensing image matching by integrating affine invariant feature extraction and RANSAC. Comput. Electr. Eng. 2012, 38, 1023–1032. [Google Scholar] [CrossRef]
- Zhu, H.; Jiao, L.; Ma, W.; Liu, F.; Zhao, W. A Novel Neural Network for Remote Sensing Image Matching. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2853–2865. [Google Scholar] [CrossRef] [PubMed]
- Sedaghat, A.; Mohammadi, N. Illumination-Robust remote sensing image matching based on oriented self-similarity. ISPRS J. Photogramm. Remote Sens. 2019, 153, 21–35. [Google Scholar] [CrossRef]
- Su, J.; Lin, X.; Liu, D. Change detection algorithm for remote sensing images based on object matching. Qinghua Daxue Xuebao/J. Tsinghua Univ. 2007, 47, 1610–1613. [Google Scholar]
- Hou, B.; Ren, Z.; Zhao, W.; Wu, Q.; Jiao, L. Object Detection in High-Resolution Panchromatic Images Using Deep Models and Spatial Template Matching. IEEE Trans. Geosci. Remote. Sens. 2019, 58, 956–970. [Google Scholar] [CrossRef]
- Li, L.; Liu, M.; Ma, L.; Han, L. Cross-Modal feature description for remote sensing image matching. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102964. [Google Scholar] [CrossRef]
- Fan, X.; Xing, L.; Chen, J.; Chen, S.; Bai, H.; Xing, L.; Zhou, C.; Yang, Y. VLSG-SANet: A feature matching algorithm for remote sensing image registration. Knowl. Based Syst. 2022, 255, 109609. [Google Scholar] [CrossRef]
- Zhu, B.; Yang, C.; Dai, J.; Fan, J.; Qin, Y.; Ye, Y. R2FD2: Fast and Robust Matching of Multimodal Remote Sensing Images via Repeatable Feature Detector and Rotation-Invariant Feature Descriptor. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5606115. [Google Scholar] [CrossRef]
- Ye, Y.; Zhu, B.; Tang, T.; Yang, C.; Xu, Q.; Zhang, G. A Robust Multimodal Remote Sensing Image Registration Method and System Using Steerable Filters with First- and Second-order Gradients. ISPRS J. Photogramm. Remote Sens. 2022, 188, 331–350. [Google Scholar] [CrossRef]
- Bradski, G.; Kaehler, A.; OpenCV. Dr. Dobb’s Journal of Software Tools. Available online: https://opencv.org/ (accessed on 8 October 2023).
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Mishchuk, A.; Mishkin, D.; Radenovic, F.; Matas, J. Working hard to know your neighbor’s margins: Local descriptor learning loss. Adv. Neural Inf. Process. Syst. 2017, 30, 4829–4840. [Google Scholar]
- Tian, Y.; Yu, X.; Fan, B.; Wu, F.; Heijnen, H.; Balntas, V. Sosnet: Second order similarity regularization for local descriptor learning. In Proceedings of the CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 11016–11025. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Image | Characteristic |
|---|---|---|
| Aircraft carrier |  | Large size, near harbors or in the ocean |
| Cargo ship |  | Small size, always in the ocean |
| Submarine |  | Small size, always near harbors |
| Category | SIFT | SIFT+CNN | LFKD | LFKD+CNN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aircraft Carrier | illumination | 14,188 | 15788 | 0.898 | 3346 | 3446 | 0.970 | 7821 | 7353 | 0.940 | 3353 | 3441 | 0.974 |
| size | 17,287 | 18,083 | 0.955 | 3412 | 3421 | 0.997 | 8705 | 8454 | 0.971 | 3457 | 3461 | 0.998 | |
| angle | 14,962 | 16,299 | 0.917 | 131 | 135 | 0.970 | 8484 | 8117 | 0.956 | 128 | 132 | 0.969 | |
| Cargo Ship | illumination | 27,179 | 27434 | 0.990 | 4230 | 4235 | 0.998 | 630 | 590 | 0.936 | 539 | 539 | 1 |
| size | 16,182 | 16,683 | 0.969 | 2255 | 2268 | 0.994 | 694 | 684 | 0.985 | 535 | 535 | 1 | |
| angle | 14,022 | 19,146 | 0.733 | 35 | 44 | 0.795 | 539 | 574 | 0.939 | 29 | 30 | 0.996 | |
| Submarine | illumination | 12,904 | 13,987 | 0.922 | 3774 | 3837 | 0.983 | 2528 | 2397 | 0.948 | 1880 | 1915 | 0.984 |
| size | 10,468 | 11,733 | 0.892 | 3607 | 3623 | 0.995 | 2664 | 2536 | 0.951 | 1950 | 1955 | 0.997 | |
| angle | 8465 | 14344 | 0.590 | 31 | 40 | 0.775 | 2017 | 1779 | 0.882 | 36 | 43 | 0.837 | |
| Average | 0.874 | 0.941 | 0.945 | 0.972 | |||||||||
| Method | Memory Cost (M) | Test Time (T) |
|---|---|---|
| SIFT | 107 MB | 69 ms |
| SIFT+CNN | 532 MB | 179 ms |
| LFKD | 64 MB | 42 ms |
| LFKD+CNN | 313 MB | 138 ms |
| Category | SIFT | SIFT+CNN | LFKD | LFKD+CNN | |
|---|---|---|---|---|---|
| NWPU VHR-10 | illumination | 0.991 | 0.983 | 0.992 | 0.985 |
| size | 0.873 | 0.885 | 0.879 | 0.894 | |
| angle | 0.720 | 0.837 | 0.868 | 0.954 | |
| HRSC | illumination | 0.975 | 0.980 | 0.977 | 0.982 |
| size | 0.891 | 0.900 | 0.900 | 0.895 | |
| angle | 0.815 | 0.850 | 0.841 | 0.889 | |
| Category | SIFT | SIFT+CNN | LFKD | LFKD+CNN |
|---|---|---|---|---|
| 1 | 0.879 | 0.915 | 0.908 | 0.920 |
| 2 | 0.729 | 0.836 | 0.827 | 0.898 |
| 3 | 0.902 | 0.947 | 0.939 | 0.964 |
| 4 | 0.835 | 0.886 | 0.836 | 0.844 |
| 5 | 0.895 | 0.926 | 0.931 | 0.939 |
| Method | SIFT+ SOSNet | LFKD+ SOSNet | SIFT+ CSNet | LFKD+ CSNet | |
|---|---|---|---|---|---|
| Aircraft Carrier | illumination | 0.971 | 0.974 | 0.971 | 0.973 |
| size | 0.995 | 0.997 | 0.995 | 0.997 | |
| angle | 0.970 | 0.970 | 0.959 | 0.965 | |
| Cargo Ship | illumination | 0.997 | 0.997 | 0.998 | 1 |
| size | 0.997 | 1 | 0.994 | 1 | |
| angle | 0.801 | 0.993 | 0.792 | 0.998 | |
| Submarine | illumination | 0.980 | 0.979 | 0.988 | 0.982 |
| size | 0.995 | 0.996 | 0.996 | 0.995 | |
| angle | 0.760 | 0.825 | 0.779 | 0.838 | |
| Method | Precision () | Memory Cost (T) | Testing Time (M) |
|---|---|---|---|
| SURF+CNN | 0.956 | 352 MB | 162 ms |
| ORB+CNN | 0.906 | 328 MB | 159 ms |
| Harris+CNN | 0.968 | 375 MB | 154 ms |
| Superpoint+CNN | 0.973 | 526 MB | 173 ms |
| LFKD+CNN | 0.972 | 313 MB | 138 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Cao, G.; Liu, J.; Cai, X. Remote Sensing Image Ship Matching Utilising Line Features for Resource-Limited Satellites. Sensors 2023, 23, 9479. https://doi.org/10.3390/s23239479
Li L, Cao G, Liu J, Cai X. Remote Sensing Image Ship Matching Utilising Line Features for Resource-Limited Satellites. Sensors. 2023; 23(23):9479. https://doi.org/10.3390/s23239479
Chicago/Turabian StyleLi, Leyang, Guixing Cao, Jun Liu, and Xiaohao Cai. 2023. "Remote Sensing Image Ship Matching Utilising Line Features for Resource-Limited Satellites" Sensors 23, no. 23: 9479. https://doi.org/10.3390/s23239479
APA StyleLi, L., Cao, G., Liu, J., & Cai, X. (2023). Remote Sensing Image Ship Matching Utilising Line Features for Resource-Limited Satellites. Sensors, 23(23), 9479. https://doi.org/10.3390/s23239479