Deep Learning-Based Automatic Modulation Classification Using Robust CNN Architecture for Cognitive Radio Networks


Abstract
:1. Introduction
1.1. Problem Statement
1.2. Our Contribution
- Design a novel convolutional neural network architecture based on a proposed convolutional block with a skip connection that remarkably improves classification accuracy at low SNR below 0 dB compared with state-of-the-art models. Thus, the proposed model is convenient in realistic scenarios.
- The proposed architecture has strong feature extraction abilities, which improves the discrimination of 16QAM and 64QAM which are challenging modulation schemes in DL-based AMC models.
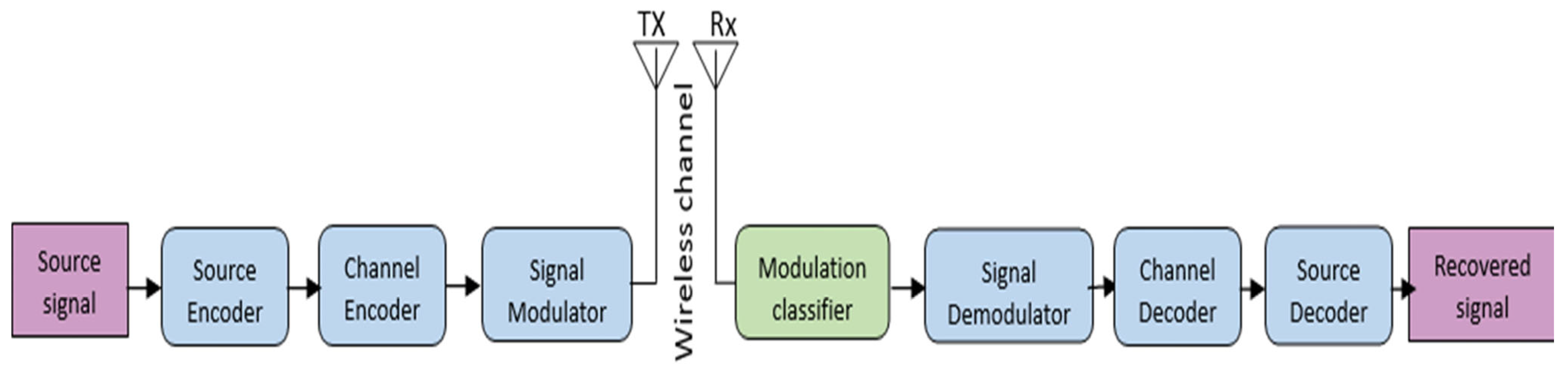
2. Signal Model and Dataset Generation
2.1. Signal Model
2.2. Dataset Generation
- Clock offset which has two effects on the received signal: frequency offset and sampling offset. The former is determined by the clock offset and center frequency (fc) and the latter by the clock offset and sampling rate (fs).
- Rician multipath fading is based on path delays, average path gains, Kfactor, and maximum doppler shift.
- Additive white Gaussian noise with an SNR range from −20 to 18 dB and with a 2 dB interval.
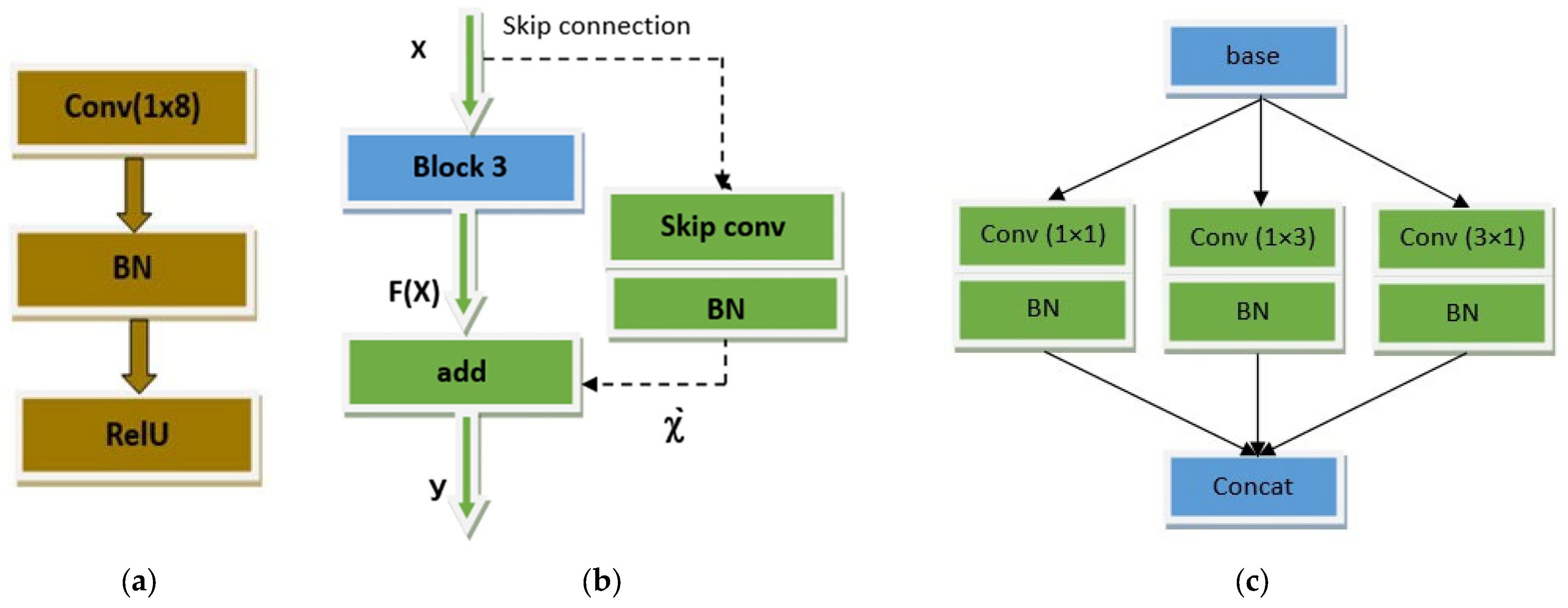
3. Proposed CNN Model
3.1. Fundamentals of CNN Architecture
3.2. Proposed CNN Architecture
4. Experimental Result and Analysis
4.1. Network Training
4.2. Training Complexity
| Algorithm 1: Proposed AMC system |
| Input: Dataset (raw I/Q sequences) |
| Results: modulation type |
| Procedure: |
| Step 1: Randomly divide the dataset into 80% for training, 10% for validation, and 10% for testing; |
| Step 2: Construct the network as shown in Figure 1; |
| Step 3: Set the training hyperparameters; |
| Step 4: Insert the training dataset into the proposed system; |
| Step 5: Train the network with the training dataset; |
| Step 6: The model training is evaluated by the holdout validation dataset; |
| Step 7: The weights are updated by the SGDM optimizer until the validation loss is not improved. |
| Load the model with the best validation loss. |
| Step 8: Train the proposed model 10 times; |
| Step 9: Apply the testing frames to each trained network; |
| Step 10: Select the trained model with the best classification accuracy; |
| Step 11: Recognize the modulation scheme; |
| Step 12: Calculate network accuracy. |
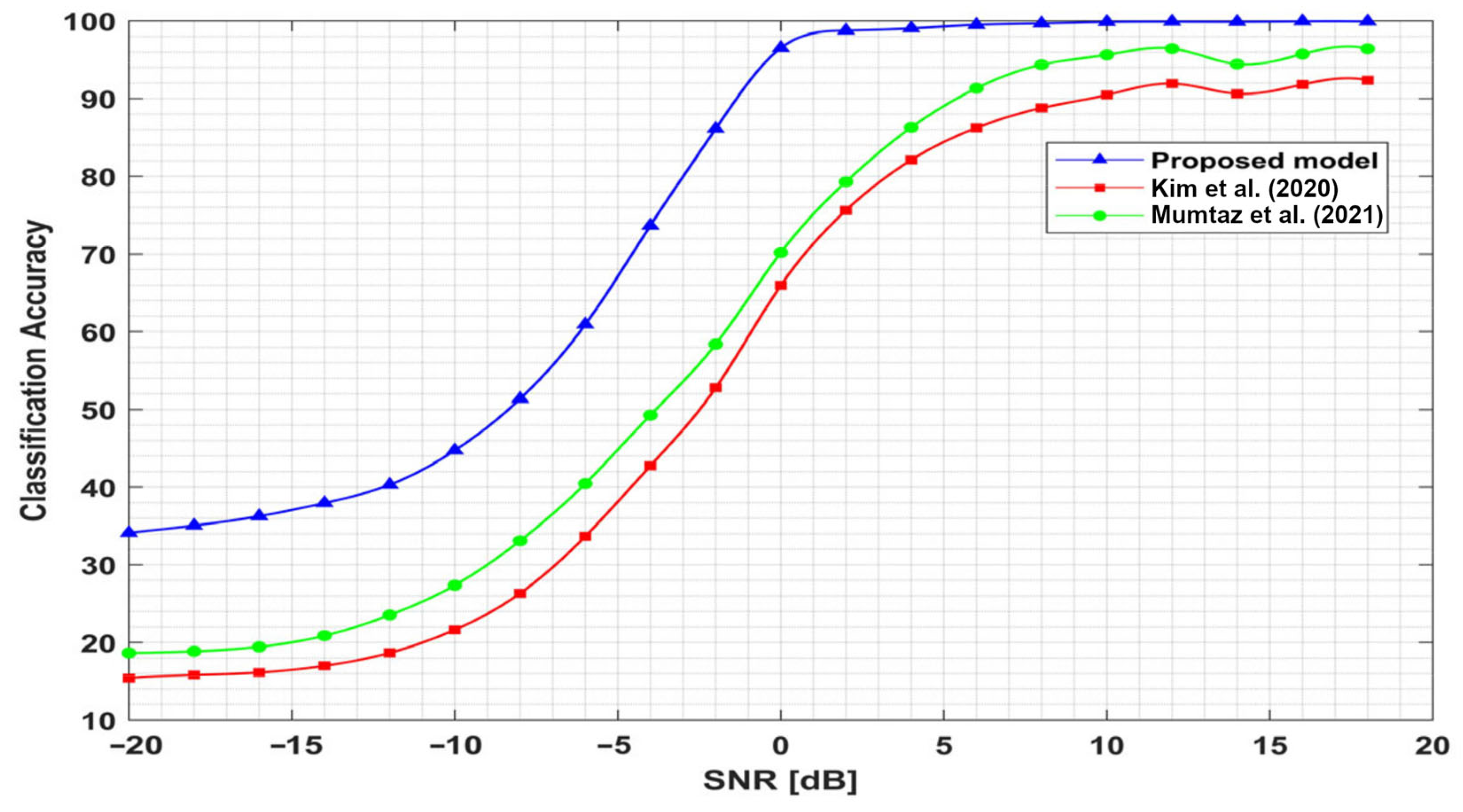
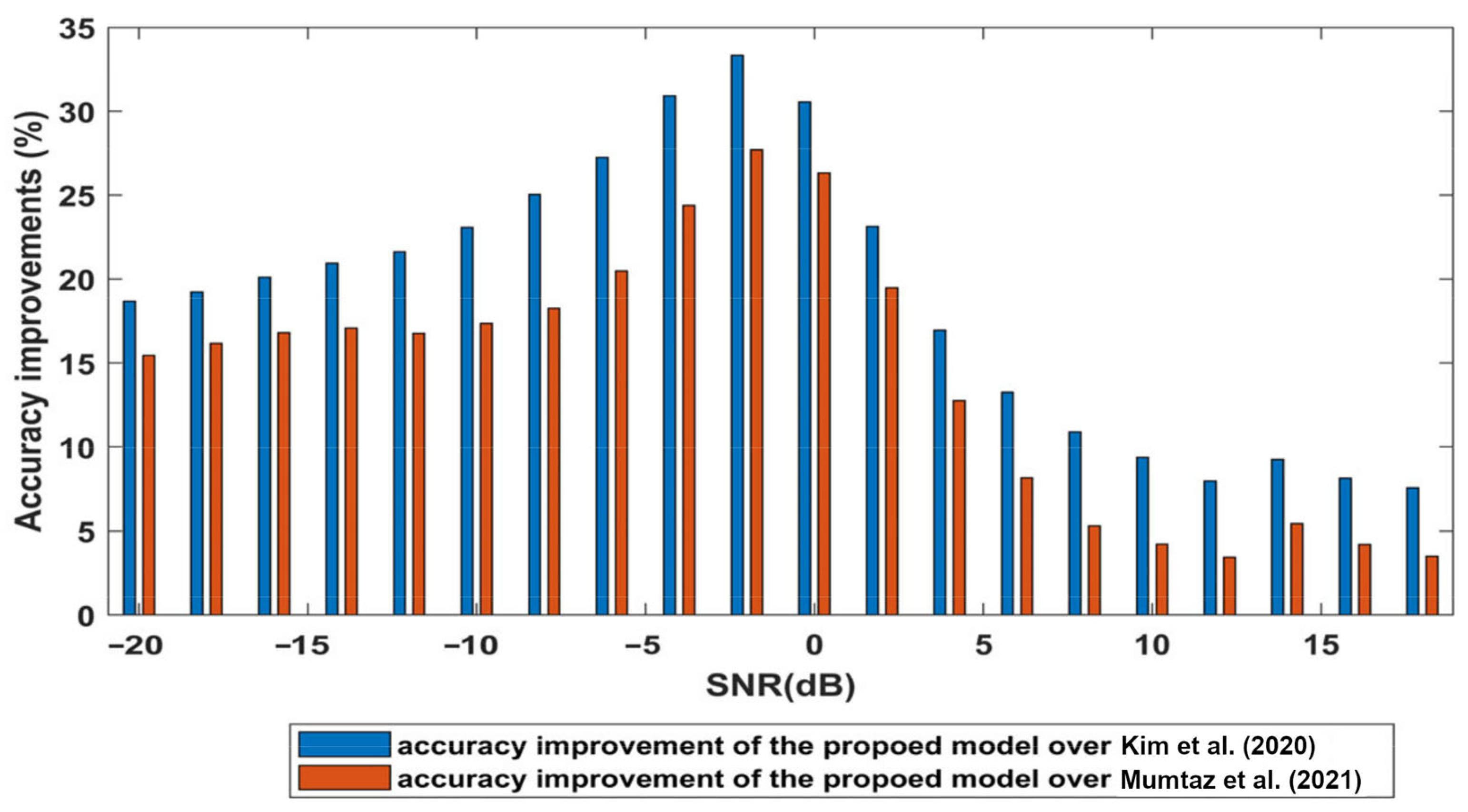
4.3. Classification Accuracy Comparison
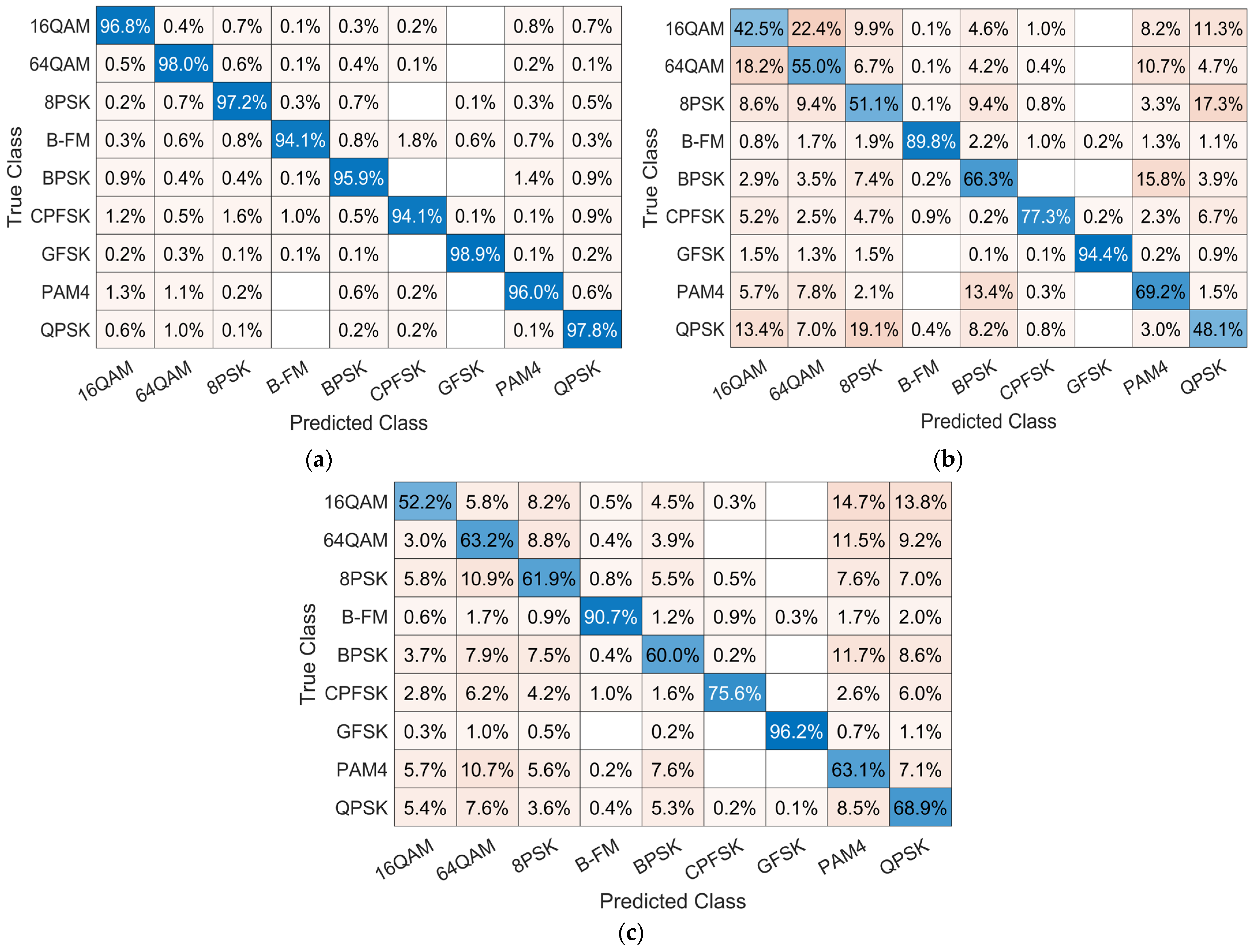
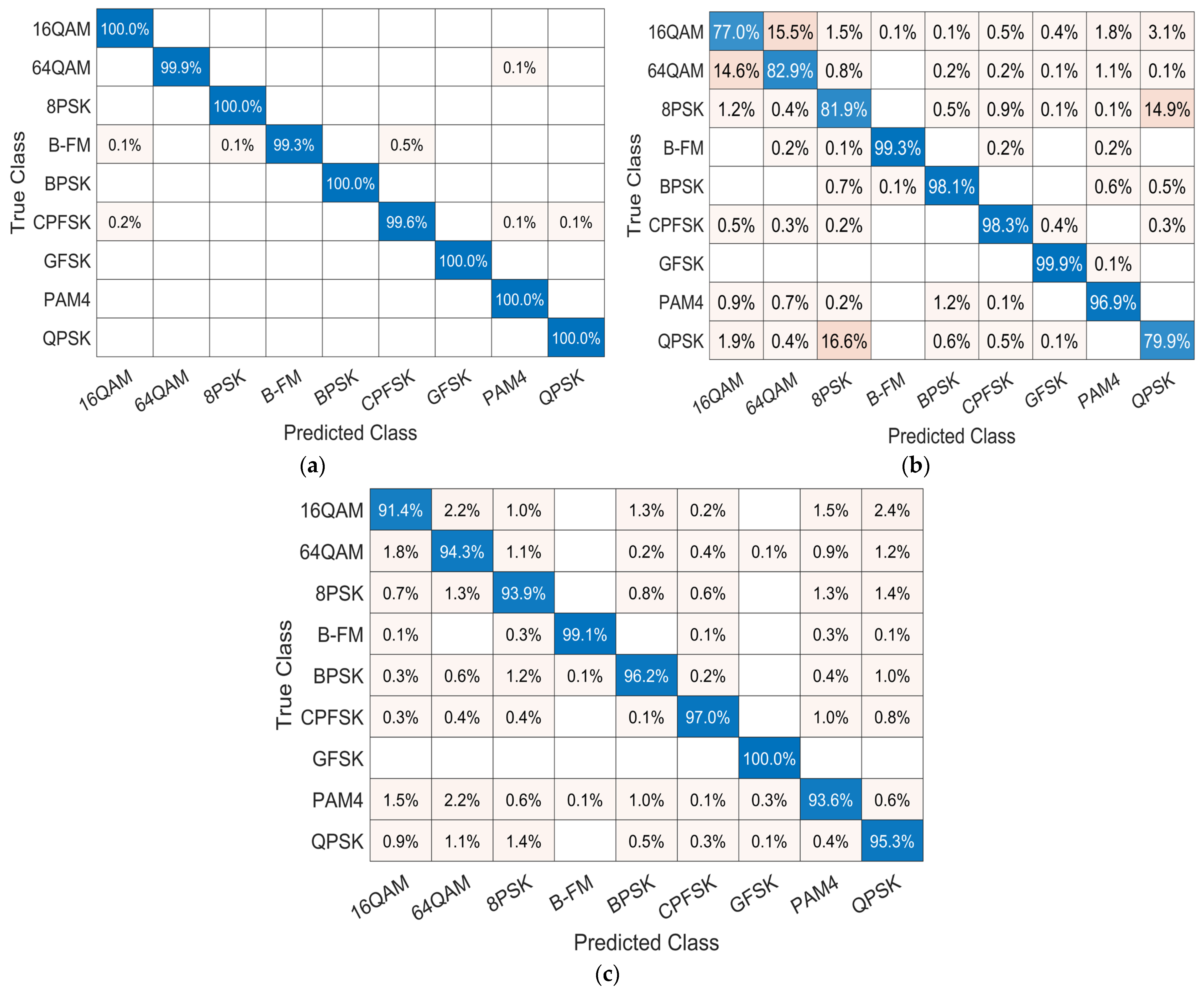
4.4. Confusion Matrix Comparison
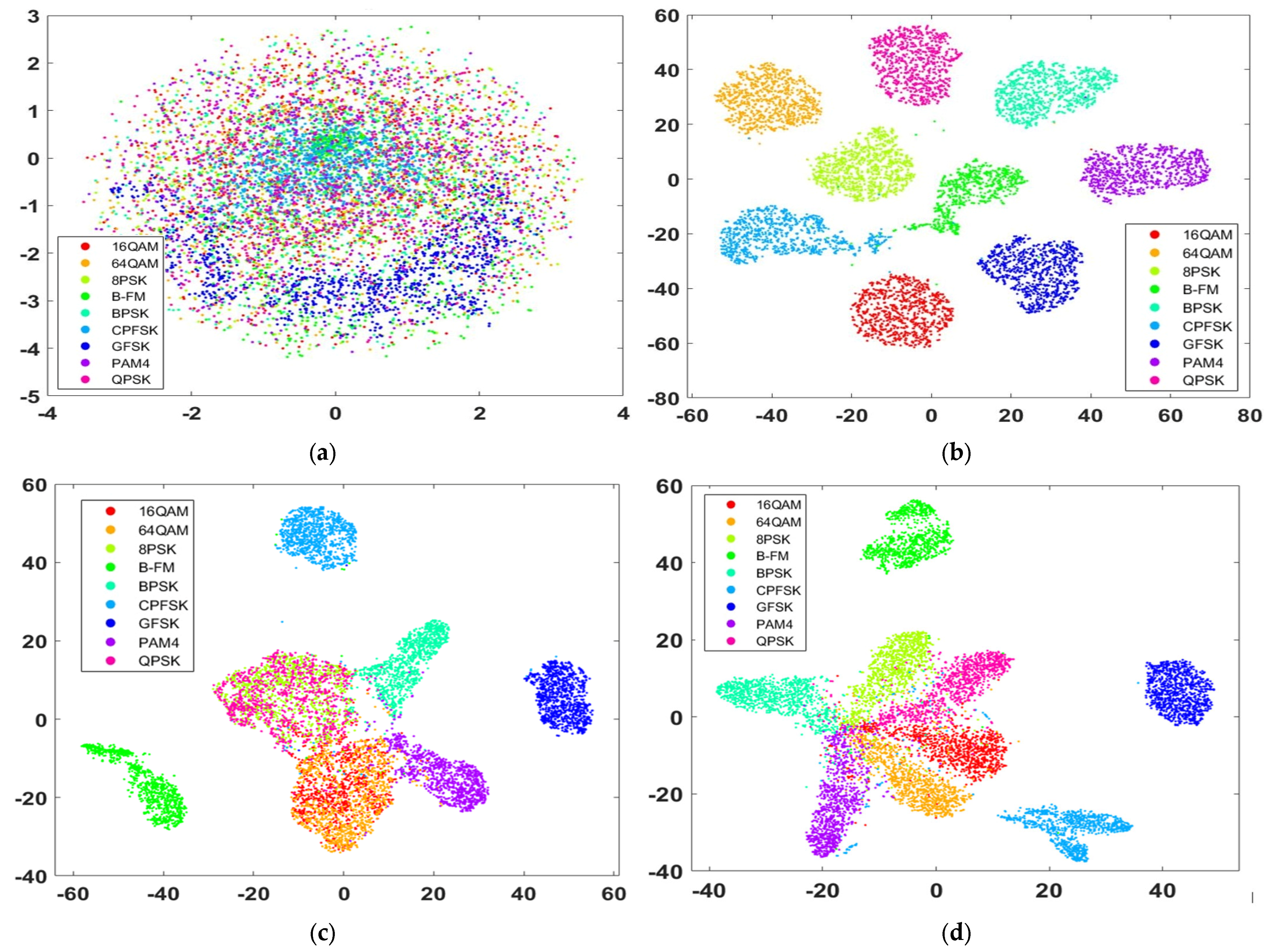
4.5. Learned Features Visualization
4.6. Computational Complexity Comparison
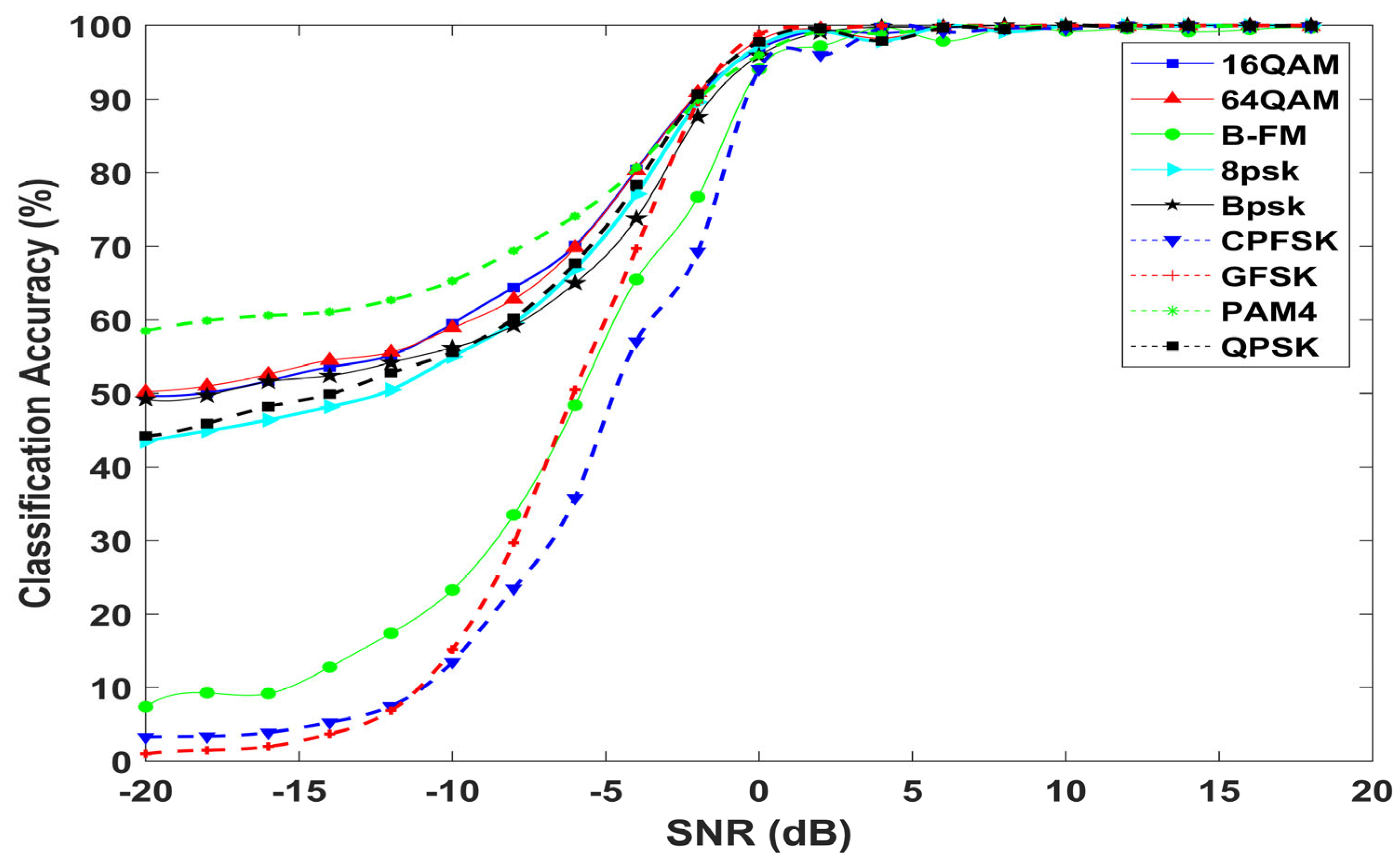
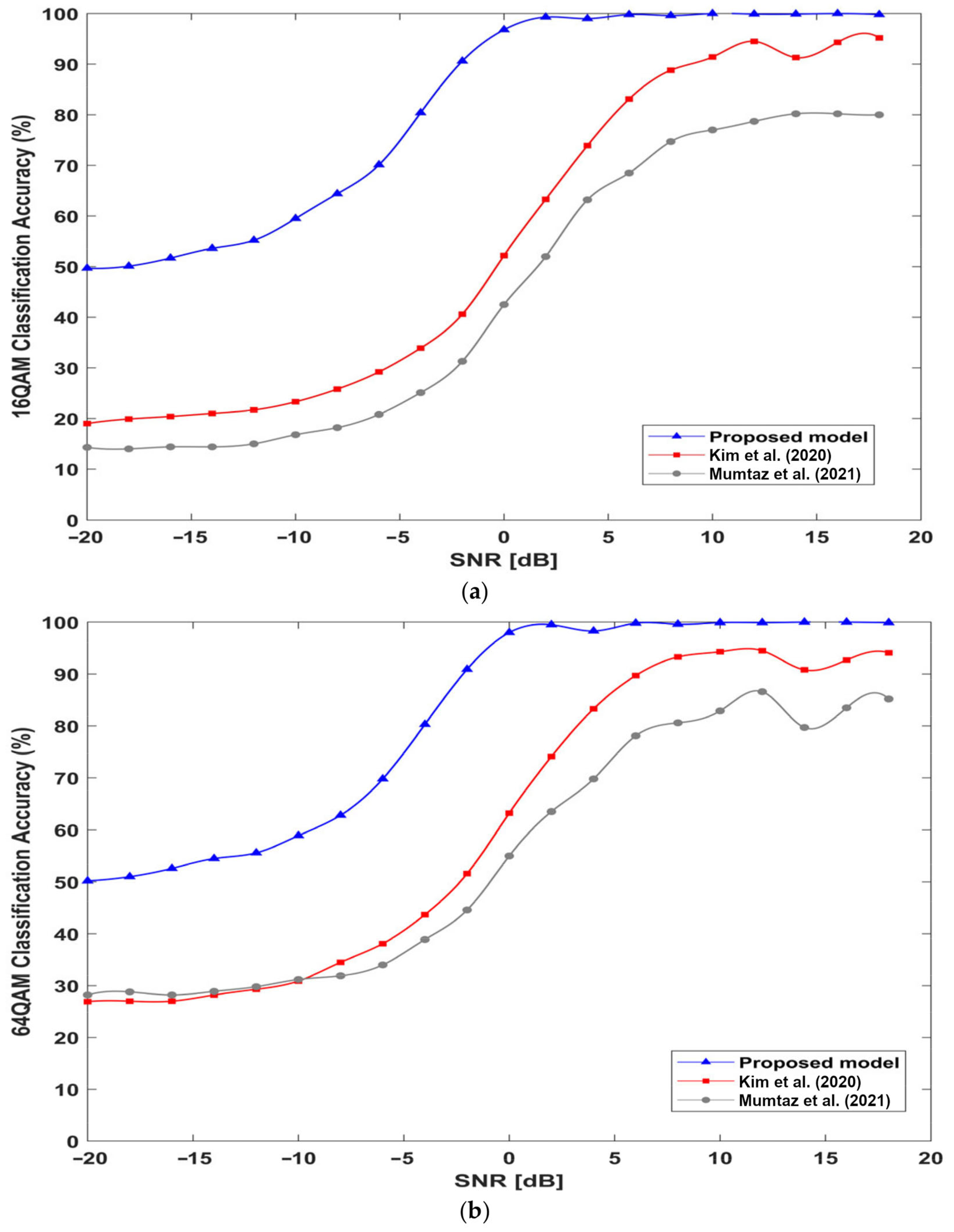
4.7. Individual Classification Accuracy
4.8. Effectiveness of the Proposed Architecture
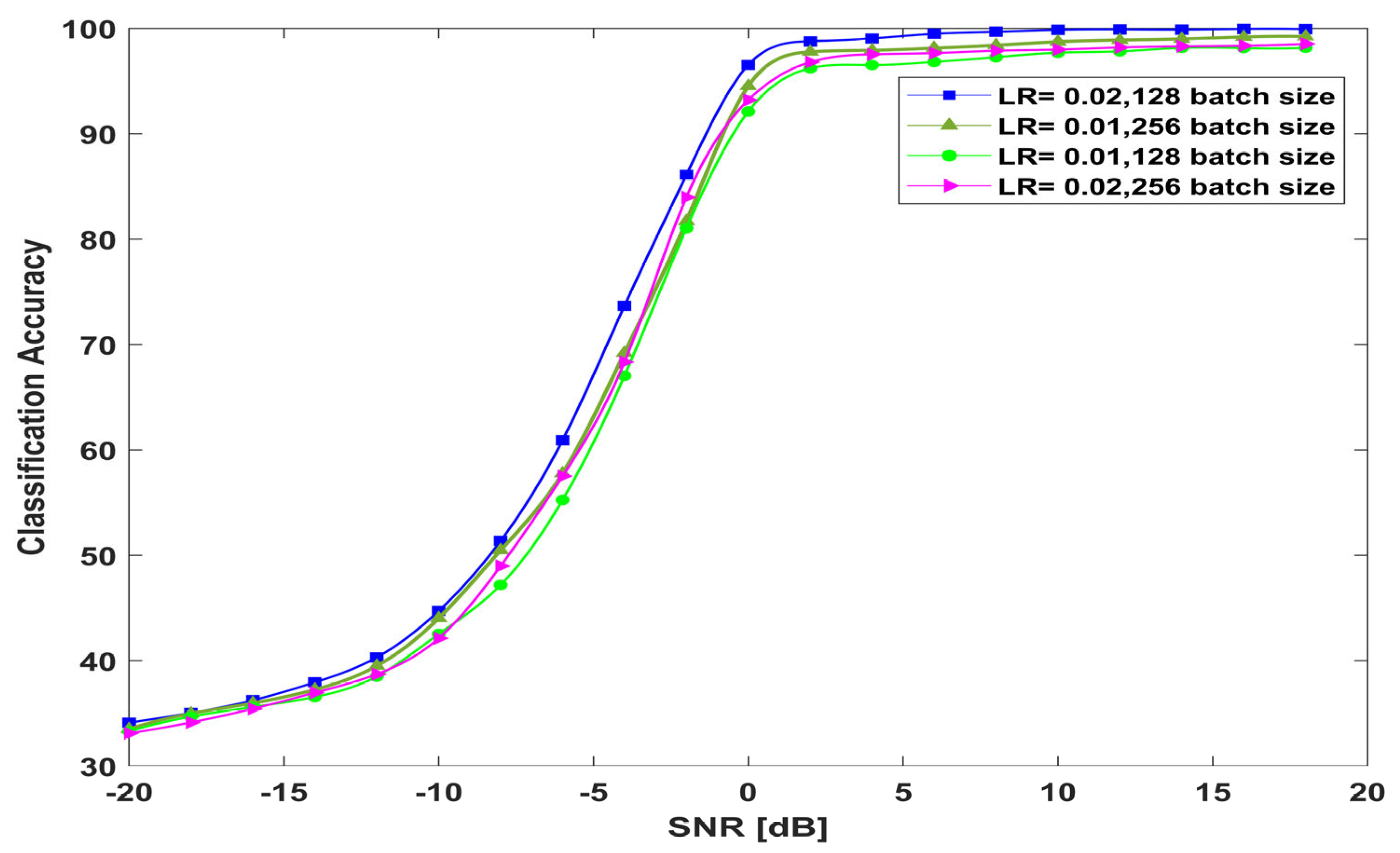
4.9. The Performance of the Proposed Model Versus the Model Hyperparameters
4.10. Ablation Study
4.10.1. Number of Proposed Convolution Blocks
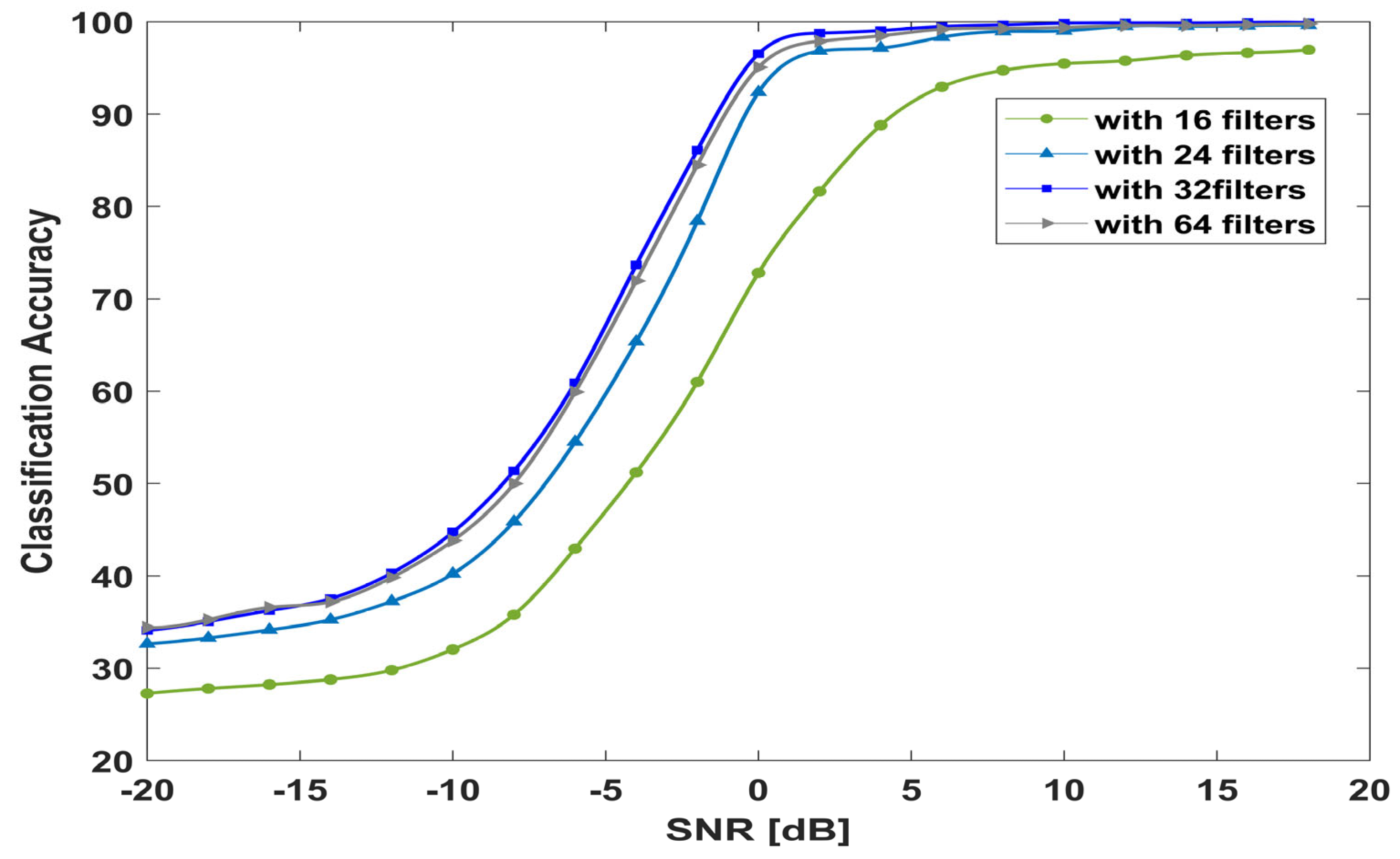
4.10.2. Number of Filters and Kernel Size
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, F.; Shang, T.; Hu, C.; Liu, Q. Automatic Modulation Classification Using Hybrid Data Augmentation and Lightweight Neural Network. Sensors 2023, 23, 4187. [Google Scholar] [CrossRef] [PubMed]
- Snoap, J.A.; Popescu, D.C.; Latshaw, J.A.; Spooner, C.M. Deep-Learning-Based Classification of Digitally Modulated Signals Using Capsule Networks and Cyclic Cumulants. Sensors 2023, 23, 5735. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Majhi, S.; Gui, G.; Wu, H.-C.; Yuen, C. A Survey of Blind Modulation Classification Techniques for OFDM Signals. Sensors 2022, 22, 1020. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z. Automatic Classification of Digital Communication Signal Modulations; Brunel University: London, UK, 2014. [Google Scholar]
- Hameed, F.; Dobre, O.; Popescu, D. On the Likelihood-Based Approach to Modulation Classification. IEEE Trans. Wirel. Commun. 2009, 8, 5884–5892. [Google Scholar] [CrossRef]
- Muhlhaus, M.S.; Oner, M.; Dobre, O.A.; Jondral, F.K. A low complexity modulation classification algorithm for MIMO systems. IEEE Commun. Lett. 2013, 17, 1881–1884. [Google Scholar] [CrossRef]
- Moser, E.; Moran, M.K.; Hillen, E.; Li, D.; Wu, Z. Automatic Modulation Classification via Instantaneous Features. In Proceedings of the 2015 National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 June 2015. [Google Scholar] [CrossRef]
- Liu, P.; Shui, P. A New Cumulant Estimator in Multipath Fading Channels for Digital Modulation Classification. IET Commun. 2014, 8, 2814–2824. [Google Scholar] [CrossRef]
- Al-Habashna, A.; Dobre, O.A.; Venkatesan, R.; Popescu, D.C. Second Order Cyclostationarity of Mobile WiMAX and LTE OFDM Signals and Application to Spectrum Awareness in Cognitive Radio Systems. IEEE J. Sel. Top. Signal Process. 2012, 6, 26–42. [Google Scholar] [CrossRef]
- Latif, G.; Iskandar, D.N.; Alghazo, J.M.; Mohammad, N. Enhanced MR Image Classification Using Hybrid Statistical and Wavelets Features. IEEE Access 2019, 7, 9634–9644. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Z.; Ma, S.; Lu, S.; Zhang, H.; Ding, G.; Li, S. Deep Learning for Signal Demodulation in Physical Layer Wireless Communications: Prototype Platform, Open Dataset, and Analytics. IEEE Access 2019, 7, 30792–30801. [Google Scholar] [CrossRef]
- Chirov, D.S.; Vynogradov, A.N.; Vorobyova, E.O. Application of the Decision Trees to Recognize the Types of Digital Modulation of Radio Signals in Cognitive Systems of HF Communication. In Proceedings of the 2018 System of Signal Synchronization, Generating and Processing in Telecommunications (SYNCHROINFO), Minsk, Belarus, 4–5 July 2018. [Google Scholar] [CrossRef]
- Aslam, M.W.; Zhu, Z.; Nandi, A.K. Automatic Modulation Classification Using Combination of Genetic Programming and KNN. IEEE Trans. Wirel. Commun. 2012, 11, 2742–2750. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Rajendran, S.; Meert, W.; Giustiniano, D.; Lenders, V.; Pollin, S. Deep Learning Models for Wireless Signal Classification with Distributed Low-Cost Spectrum Sensors. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 433–445. [Google Scholar] [CrossRef]
- Elsagheer, M.M.; Ramzy, S.M. A hybrid model for automatic modulation classification based on residual neural networks and long short-term memory. Alex. Eng. J. 2022, 67, 117–128. [Google Scholar] [CrossRef]
- Hu, S.; Pei, Y.; Liang, P.P.; Liang, Y.-C. Robust Modulation Classification under Uncertain Noise Condition Using Recurrent Neural Network. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Yao, Y.-D. Modulation Classification Using Convolutional Neural Network Based Deep Learning Model. In Proceedings of the 2017 26th Wireless and Optical Communication Conference (WOCC), Newark, NJ, USA, 7–8 April 2017. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y.-D. Modulation Classification Based on Signal Constellation Diagrams and Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 718–727. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Sun, B.; Su, S.; Wei, J.; Zhao, J.; Wen, X. Automatic Modulation Classification Based on Deep Learning for Software-Defined Radio. Math. Probl. Eng. 2020, 2020, 2678310. [Google Scholar] [CrossRef]
- Dileep, P.; Das, D.; Bora, P.K. Dense Layer Dropout Based CNN Architecture for Automatic Modulation Classification. In Proceedings of the 2020 National Conference on Communications (NCC), Kharagpur, India, 21–23 February 2020. [Google Scholar] [CrossRef]
- Wang, T.; Yang, G.; Chen, P.; Xu, Z.; Jiang, M.; Ye, Q. A Survey of Applications of Deep Learning in Radio Signal Modulation Recognition. Appl. Sci. 2022, 12, 12052. [Google Scholar] [CrossRef]
- Tunze, G.B.; Huynh-The, T.; Lee, J.-M.; Kim, D.-S. Sparsely Connected CNN for Efficient Automatic Modulation Recognition. IEEE Trans. Veh. Technol. 2020, 69, 15557–15568. [Google Scholar] [CrossRef]
- Kim, S.-H.; Kim, J.-W.; Doan, V.-S.; Kim, D.-S. Lightweight Deep Learning Model for Automatic Modulation Classification in Cognitive Radio Networks. IEEE Access 2020, 8, 197532–197541. [Google Scholar] [CrossRef]
- Mumtaz, M.Z.; Khurram, M.; Adnan, M.; Fazil, A. Autonomous Modulation Classification Using Single Inception Module Based Convolutional Neural Network. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Srinivasan, S.; Kavitha, M.; Rani, G.V.; Manoharan, L.; Terence, E.; Siva, A.V. Implementation of Digital Modulation Techniques in High-Speed FPGA Board. In Proceedings of the 2023 Second International Conference on Electronics and Renewable Systems (ICEARS), Tuticorin, India, 2–4 March 2023; pp. 21–26. [Google Scholar] [CrossRef]
- Husnain, M.; Missen, M.M.S.; Mumtaz, S.; Luqman, M.M.; Coustaty, M.; Ogier, J.-M. Visualization of High-Dimensional Data by Pairwise Fusion Matrices Using t-SNE. Symmetry 2019, 11, 107. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Test | Modulation(s) | SNR Range | PCC % at the Lowest SNR | PCC % at the Highest SNR |
|---|---|---|---|---|---|
| [4] | ML | BPSK, QPSK,8PSK, 4QAM,16QAM,64QAM | From 0 to 20 dB | 80% | 100% |
| [4] | GLRT | BPSK, QPSK,8PSK, 4QAM,16QAM,64QAM | From 0 to 20 dB | 55% | 100% |
| [5] | ALRT | BPSK, QPSK | From −7 to 10 dB | 80% | 100% |
| [6] | HLRT | BPSK, QPSK,8PSK,16QAM | From −15 to 15 dB | 31% | 100% |
| Ref. | Technique | Dataset | Performance Evaluation |
|---|---|---|---|
| [15] | Modulation Classification based on long short-term memory (LSTM) | Modified RadioML2016.10a dataset | Accuracy of 90% at high SNRs |
| [16] | A hybrid model for AMC based on ResNet and LSTM | RadioML2016.10b dataset | Accuracy of 92% at 18 dB SNR |
| [22] | Modulation classification based on Inception network and ResNet | RadioML2016.10b dataset | Accuracy of 93.76% at 14 dB SNR |
| [23] | Dense layer dropout-based CNN architecture for automatic modulation classification | Generated dataset with eight modulation schemes | Accuracy of 97% above 2 dB SNR |
| [24] | Modulation classification based on convolutional neural network (CNN) | RadioML2016.04c dataset | Accuracy of 98.47% at 18 dB SNR |
| [25] | Three kinds of modules using grouped and separable convolutional layers | RadioML2018.01A dataset | Accuracy of 94.4% at 20 dB SNR |
| [26] | A bottleneck and asymmetric convolutional structure | RadioML2018.01A dataset | Accuracy of 94.97% at 20 dB SNR |
| [27] | CNN model with four stacked convolutional blocks and Inception module | Generated dataset with eleven modulation schemes | Accuracy of 90% at 10 dB SNR |
| Parameter | Value |
|---|---|
| Center frequency fc | 902 MHz for digital modulation and 100 MHz for an analog one |
| Samples per frame | 1024 |
| Symbols per frame | 128 |
| Sampling rate fs | 200 kHz |
| Kfactor | 4 |
| Max Doppler shift | 4 Hz |
| Max clock offset | 5 ppm |
| Path delays τk | [0, 1.8, 3.4]/fs |
| Average path gains ak | [0, −2, −10] dB |
| Carrier frequency offset | Δf |
| Phase offset | Δθ |
| Symbol period | T |
| The received signal | S(t) |
| AWGN | n(t) |
| In-phase components of received signal | Ai |
| quadrature components of received signal | Aq |
| Layer | Output Size | Remarks |
|---|---|---|
| Input | 2 × 1024 × 1 | |
| Conv Block 1 | 2 × 512 × 32 | 32 × (1 × 8), stride (1,1) Max-pooling (1,2), stride (1,2) |
| Block2 | 2 × 256 × 96 | 32 × (1 × 1), 32 × (1 × 3), 32 × (3 × 1) 96 × (1 × 1), stride (1,2) |
| Feature map concatenation | ||
| Addition | 2 × 256 × 96 | Addition layer |
| Block 2 | 2 × 128 × 96 | 32 × (1 × 1), 32 × (1 × 3), 32 × (3 × 1) 96 × (1 × 1), stride (1,2) |
| Feature map concatenation | ||
| Addition | 2 × 128 × 96 | Addition layer |
| Block 2 | 2 × 64 × 96 | 32 × (1 × 1), 32 × (1 × 3), 32 × (3 × 1) 96 × (1 × 1), stride (1,2) |
| Feature map concatenation | ||
| Addition | 2 × 64 × 96 | Addition layer |
| Block 2 | 2 × 32 × 96 | 32 × (1 × 1), 32 × (1 × 3), 32 × (3 × 1) 96 × (1 × 1), stride (1,2) |
| Feature map concatenation | ||
| Pool | 1 × 1 × 96 | Average pooling (2,32) |
| FC | 1 × 1 × 9 | Fully connected layer |
| Softmax | 9 |
| Hyperparameter | Value |
|---|---|
| Optimizer | SGDM |
| InitialLearnRate | 0.02 |
| MaxEpochs | 30 |
| MiniBatchSize | 128 |
| LearnRateDropPeriod | 9 |
| LearnRateDropFactor | 0.1 |
| Model | Total Parameters | Inference Time (ms) |
|---|---|---|
| Proposed model. | 106 k | 0.721 |
| Model [26] | 46 k | 0.698 |
| Model [27] | 200 k | 0.786 |
| Kernel Size | Total Parameters | Average Accuracy |
|---|---|---|
| 1 × 3 and 3 × 1 | 106 k | 74.65% |
| 1 × 5 and 5 × 1 | 147 k | 74.06% |
| 1 × 7 and 7 × 1 | 188 k | 73.96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abd-Elaziz, O.F.; Abdalla, M.; Elsayed, R.A. Deep Learning-Based Automatic Modulation Classification Using Robust CNN Architecture for Cognitive Radio Networks. Sensors 2023, 23, 9467. https://doi.org/10.3390/s23239467
Abd-Elaziz OF, Abdalla M, Elsayed RA. Deep Learning-Based Automatic Modulation Classification Using Robust CNN Architecture for Cognitive Radio Networks. Sensors. 2023; 23(23):9467. https://doi.org/10.3390/s23239467
Chicago/Turabian StyleAbd-Elaziz, Ola Fekry, Mahmoud Abdalla, and Rania A. Elsayed. 2023. "Deep Learning-Based Automatic Modulation Classification Using Robust CNN Architecture for Cognitive Radio Networks" Sensors 23, no. 23: 9467. https://doi.org/10.3390/s23239467
APA StyleAbd-Elaziz, O. F., Abdalla, M., & Elsayed, R. A. (2023). Deep Learning-Based Automatic Modulation Classification Using Robust CNN Architecture for Cognitive Radio Networks. Sensors, 23(23), 9467. https://doi.org/10.3390/s23239467