
AMFF-Net: An Effective 3D Object Detector Based on Attention and Multi-Scale Feature Fusion


Abstract
:1. Introduction
- We designed a Dual-Attention Voxel Feature Extractor (DA-VFE) to integrate the Dual-Attention mechanism into the voxel-feature-extraction process, extract more-representative point cloud features, and reduce the information loss in the process of extracting the voxel features.
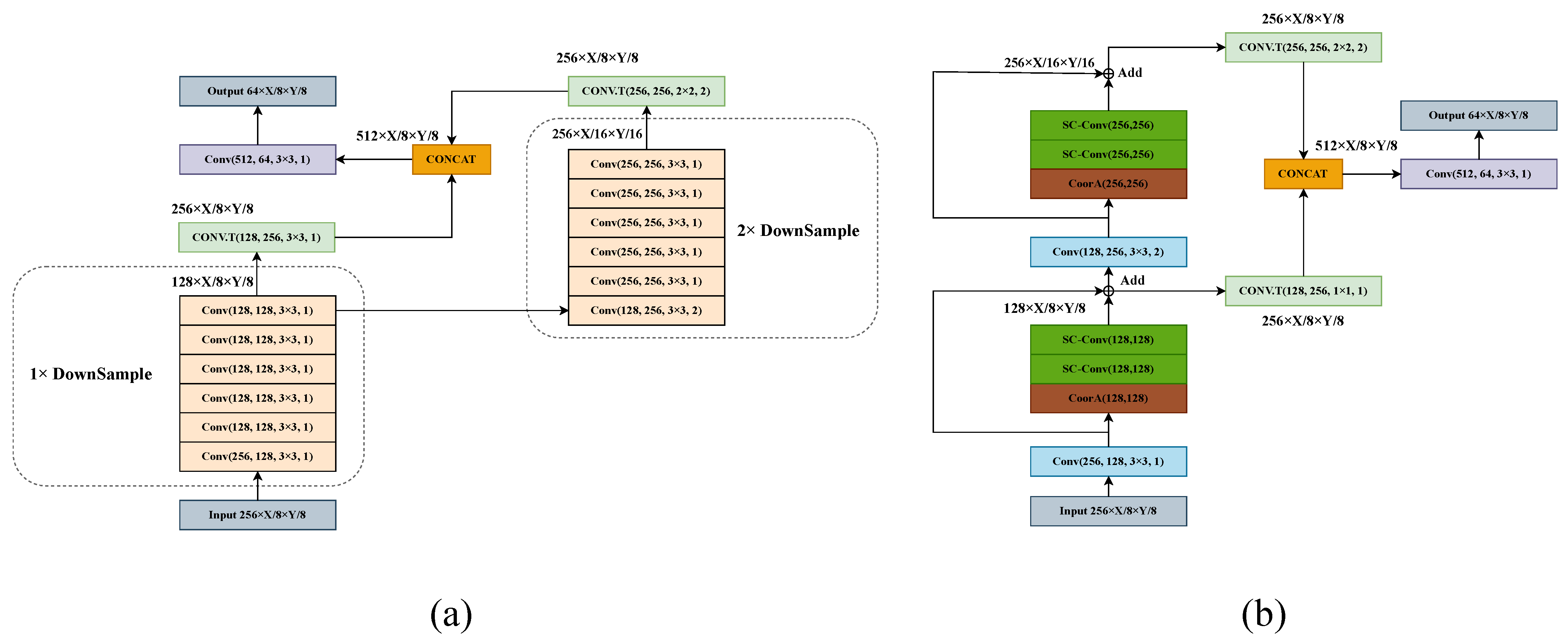
- We propose a novel 2D Backbone named the MFF Module, which extends the perceptual field of the 2D Backbone and can capture more contextual information to extract richer information with higher accuracy and robustness.
- The proposed network can achieve performance gains while reducing the computational overhead.
2. Related Work
3. Method
3.1. Voxelization
3.2. Dual-Attention Voxel Feature Extractor
3.2.1. Pointwise Attention
3.2.2. Channelwise Attention
3.3. Multi-Scale Feature Fusion Module
3.4. Loss Function
4. Experiments
4.1. Experiment Details
4.1.1. Dataset
4.1.2. Data Augmentation
4.1.3. Parameter Settings
4.1.4. Training Details
4.2. Experimental Results
4.3. Ablation Studies
4.3.1. DA-VFE
4.3.2. MFF Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Cai, Y.; Wang, H.; Chen, L.; Gao, H.; Jia, Y.; Li, Y. Robust target recognition and tracking of self-driving cars with radar and camera information fusion under severe weather conditions. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6640–6653. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3D object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Y.; Zhang, S.; Ogai, H. Deep 3D object detection networks using LiDAR data: A review. IEEE Sens. J. 2020, 21, 1152–1171. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3D point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Chen, Q.; Sun, L.; Wang, Z.; Jia, K.; Yuille, A. Object as hotspots: An anchor-free 3D object detection approach via firing of hotspots. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 68–84. [Google Scholar]
- Kuang, H.; Wang, B.; An, J.; Zhang, M.; Zhang, Z. Voxel-FPN: Multi-scale voxel feature aggregation for 3D object detection from LIDAR point clouds. Sensors 2020, 20, 704. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, H.; Chen, Z.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. Voxel-RCNN-complex: An effective 3-D point cloud object detector for complex traffic conditions. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10096–10105. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 11784–11793. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and PATTERN Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local pointwise features for amodal 3D object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3D object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3D object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1951–1960. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar]
- Zhang, Y.; Hu, Q.; Xu, G.; Ma, Y.; Wan, J.; Guo, Y. Not all points are equal: Learning highly efficient point-based detectors for 3D lidar point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18953–18962. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3D object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11677–11684. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Xu, Q.; Zhong, Y.; Neumann, U. Behind the curtain: Learning occluded shapes for 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 2893–2901. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; Yu, G. Class-balanced grouping and sampling for point cloud 3D object detection. arXiv 2019, arXiv:1908.09492. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Hu, P.; Ziglar, J.; Held, D.; Ramanan, D. What you see is what you get: Exploiting visibility for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11001–11009. [Google Scholar]
- Qin, P.; Zhang, C.; Dang, M. GVnet: Gaussian model with voxel-based 3D detection network for autonomous driving. Neural Comput. Appl. 2022, 34, 6637–6645. [Google Scholar] [CrossRef]
- Liu, S.; Huang, W.; Cao, Y.; Li, D.; Chen, S. SMS-Net: Sparse multi-scale voxel feature aggregation network for LiDAR-based 3D object detection. Neurocomputing 2022, 501, 555–565. [Google Scholar] [CrossRef]
- Yin, J.; Shen, J.; Guan, C.; Zhou, D.; Yang, R. Lidar-based online 3D video object detection with graph-based message passing and spatiotemporal transformer attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11495–11504. [Google Scholar]
- Zhu, X.; Ma, Y.; Wang, T.; Xu, Y.; Shi, J.; Lin, D. Ssn: Shape signature networks for multi-class object detection from point clouds. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 581–597. [Google Scholar]
- Zhai, Z.; Wang, Q.; Pan, Z.; Gao, Z.; Hu, W. Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection. Sensors 2022, 22, 7473. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Ma, J.; Zheng, Q.; Liu, Y.; Shi, G. 3D Object Detection Based on Attention and Multi-Scale Feature Fusion. Sensors 2022, 22, 3935. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP | NDS | Car | Truck | Bus | Trailer | CV | Ped | Motor | Bicycle | TC | Barrier |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointPillars [7] | 30.5 | 45.3 | 68.4 | 23.0 | 28.2 | 23.4 | 4.1 | 59.7 | 27.4 | 1.1 | 30.8 | 38.9 |
| WYSIWYG [41] | 35.0 | 41.9 | 79.1 | 30.4 | 46.6 | 40.1 | 7.1 | 65.0 | 18.2 | 0.1 | 28.8 | 34.7 |
| GVNet [42] | 35.4 | / | 76.2 | 29.7 | 42.3 | 22.1 | / | 59.2 | 20.7 | 0.8 | / | 32.0 |
| SMS-Net [43] | 43.7 | 57.6 | 80.3 | 49.5 | 61.3 | 35.1 | 12.1 | 71.2 | 28.9 | 4.6 | 46.0 | 34.7 |
| PMPNet [44] | 45.4 | 53.1 | 79.7 | 36.6 | 47.1 | 43.1 | 18.1 | 76.5 | 40.7 | 7.9 | 58.8 | 48.8 |
| PointPainting [40] | 46.4 | 58.1 | 77.9 | 35.8 | 36.2 | 37.3 | 15.8 | 73.3 | 41.5 | 24.1 | 62.4 | 60.2 |
| SSN [45] | 46.4 | 58.1 | 80.7 | 37.5 | 39.9 | 43.9 | 14.6 | 72.3 | 43.7 | 20.1 | 54.2 | 56.3 |
| MFFFNet-CP [46] | 46.6 | / | 79.7 | 46.8 | 64.9 | 32.5 | 8.9 | 74.1 | 36.5 | 14.1 | 51.6 | 56.5 |
| CBGS [37] | 52.8 | 63.3 | 81.1 | 48.5 | 54.9 | 42.9 | 10.5 | 80.1 | 51.5 | 22.3 | 70.9 | 65.7 |
| CenterPoint [19] | 58.0 | 65.5 | 84.6 | 51.0 | 60.2 | 53.2 | 17.5 | 83.4 | 53.7 | 28.7 | 76.7 | 70.9 |
| CenterPoint [19] | 60.3 | 67.3 | 85.3 | 53.5 | 63.6 | 56.1 | 20.0 | 84.6 | 59.4 | 30.7 | 78.4 | 71.1 |
| AMFF-Net (Ours) | 60.8 | 67.7 | 85.9 | 53.7 | 64.9 | 56.2 | 18.7 | 85.8 | 60.4 | 32.1 | 79.9 | 70.1 |
| AMFF-Net (Ours) | 62.8 | 69.2 | 86.5 | 55.9 | 66.8 | 58.5 | 21.3 | 86.6 | 63.6 | 35.6 | 82.0 | 71.0 |
| Methods | mAP↑ | NDS↑ | mATE↓ | mASE↓ | mAOE↓ | mAVE↓ | mAAE↓ | FPS↑ | Parameters↓ |
|---|---|---|---|---|---|---|---|---|---|
| CenterPoint (Baseline) | 58.3 | 66.1 | 29.4 | 25.7 | 30.2 | 26.4 | 19.1 | 13.1 | 8.94 M |
| AMFF-Net (Ours) | 60.4 | 67.3 | 29.3 | 25.5 | 30.1 | 25.1 | 18.7 | 13.3 | 6.91 M |
| CenterPoint (Baseline) | 60.7 | 67.9 | 27.8 | 25.0 | 28.2 | 24.4 | 19.2 | 4.2 | 8.94 M |
| AMFF-Net (Ours) | 62.5 | 68.9 | 27.7 | 25.0 | 29.4 | 23.0 | 18.8 | 4.2 | 6.91 M |
| Methods | Cars | Cyclists | Pedestrians | 3D mAP | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | ||
| VoxelNet | 81.97 | 65.46 | 62.85 | 67.17 | 47.65 | 45.11 | 57.86 | 53.42 | 48.87 | 58.93 |
| PointPillars | 87.50 | 77.01 | 74.77 | 83.65 | 63.40 | 59.71 | 66.73 | 61.06 | 56.50 | 70.03 |
| SECOND | 89.05 | 79.94 | 77.09 | 82.96 | 61.43 | 59.15 | 55.94 | 51.14 | 46.17 | 66.99 |
| PointRCNN | 88.26 | 77.73 | 76.67 | 82.76 | 62.83 | 59.62 | 65.62 | 58.57 | 51.48 | 69.28 |
| Part-A2 | 89.47 | 79.47 | 78.54 | 88.31 | 70.14 | 66.93 | 66.89 | 59.68 | 54.62 | 72.67 |
| PV-RCNN | 92.10 | 84.36 | 82.48 | 88.88 | 71.95 | 66.78 | 64.26 | 56.67 | 51.91 | 73.26 |
| TANet | 88.21 | 77.85 | 75.62 | 85.98 | 64.95 | 60.40 | 70.80 | 63.45 | 58.22 | 71.72 |
| Voxel R-CNN | 92.64 | 85.10 | 82.84 | 92.93 | 75.03 | 70.81 | 69.21 | 61.98 | 56.33 | 76.31 |
| BtcDet | 93.15 | 86.28 | 83.86 | 91.45 | 74.70 | 70.08 | 69.39 | 61.19 | 55.86 | 76.21 |
| MA-MFFC | 92.60 | 84.98 | 83.21 | 94.78 | 75.72 | 72.28 | 71.33 | 63.84 | 58.63 | 77.48 |
| AMFF-Net (Ours) | 92.67 | 85.79 | 84.17 | 92.56 | 76.97 | 72.74 | 73.80 | 64.93 | 61.52 | 78.35 |
| Methods | Ped | Motor | Bicycle | TC | mAP | NDS |
|---|---|---|---|---|---|---|
| Baseline | 84.4 | 58.7 | 39.7 | 68.4 | 58.3 | 66.1 |
| +DA-VFE | 85.3 | 60.1 | 42.4 | 71.0 | 59.7 | 67.0 |
| +MFF | 85.7 | 59.7 | 44.0 | 71.6 | 60.1 | 66.9 |
| Ours | 85.8 | 60.7 | 45.3 | 72.7 | 60.4 | 67.3 |
| Methods | Ped | Motor | Bicycle | TC | mAP | NDS |
|---|---|---|---|---|---|---|
| Baseline | 84.4 | 58.7 | 39.7 | 68.4 | 58.3 | 66.1 |
| PA | 85.3 | 59.8 | 40.8 | 68.9 | 58.7 | 66.5 |
| CA | 85.0 | 57.8 | 40.5 | 70.6 | 58.8 | 66.4 |
| DA | 85.3 | 60.1 | 42.4 | 71.0 | 59.7 | 67.0 |
| Baseline | SC-Conv | CA | Res | Ped | Motor | Bicycle | TC | mAP | NDS |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | 84.4 | 58.7 | 39.7 | 68.4 | 58.3 | 66.1 | |||
| ✓ | ✓ | 85.4 | 57.9 | 40.9 | 70.1 | 59.0 | 66.3 | ||
| ✓ | ✓ | ✓ | 85.7 | 59.7 | 40.4 | 70.6 | 59.7 | 66.9 | |
| ✓ | ✓ | ✓ | ✓ | 85.7 | 59.7 | 44.0 | 71.6 | 60.1 | 66.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Mo, Z.; Ling, B.W.-K. AMFF-Net: An Effective 3D Object Detector Based on Attention and Multi-Scale Feature Fusion. Sensors 2023, 23, 9319. https://doi.org/10.3390/s23239319
Li G, Mo Z, Ling BW-K. AMFF-Net: An Effective 3D Object Detector Based on Attention and Multi-Scale Feature Fusion. Sensors. 2023; 23(23):9319. https://doi.org/10.3390/s23239319
Chicago/Turabian StyleLi, Guangping, Zuanfang Mo, and Bingo Wing-Kuen Ling. 2023. "AMFF-Net: An Effective 3D Object Detector Based on Attention and Multi-Scale Feature Fusion" Sensors 23, no. 23: 9319. https://doi.org/10.3390/s23239319
APA StyleLi, G., Mo, Z., & Ling, B. W.-K. (2023). AMFF-Net: An Effective 3D Object Detector Based on Attention and Multi-Scale Feature Fusion. Sensors, 23(23), 9319. https://doi.org/10.3390/s23239319