
Optimal Resource Provisioning and Task Offloading for Network-Aware and Federated Edge Computing



Abstract
:1. Introduction
- In contrast to previous optimization approaches that focused on each individual component of the MEC architecture, we propose a comprehensive optimal approach that optimizes a chain of components in the MEC as well as network resources. In this study, the proposed approach optimizes BS-user association, federated-user assignment, resource provisioning, and task offloading.
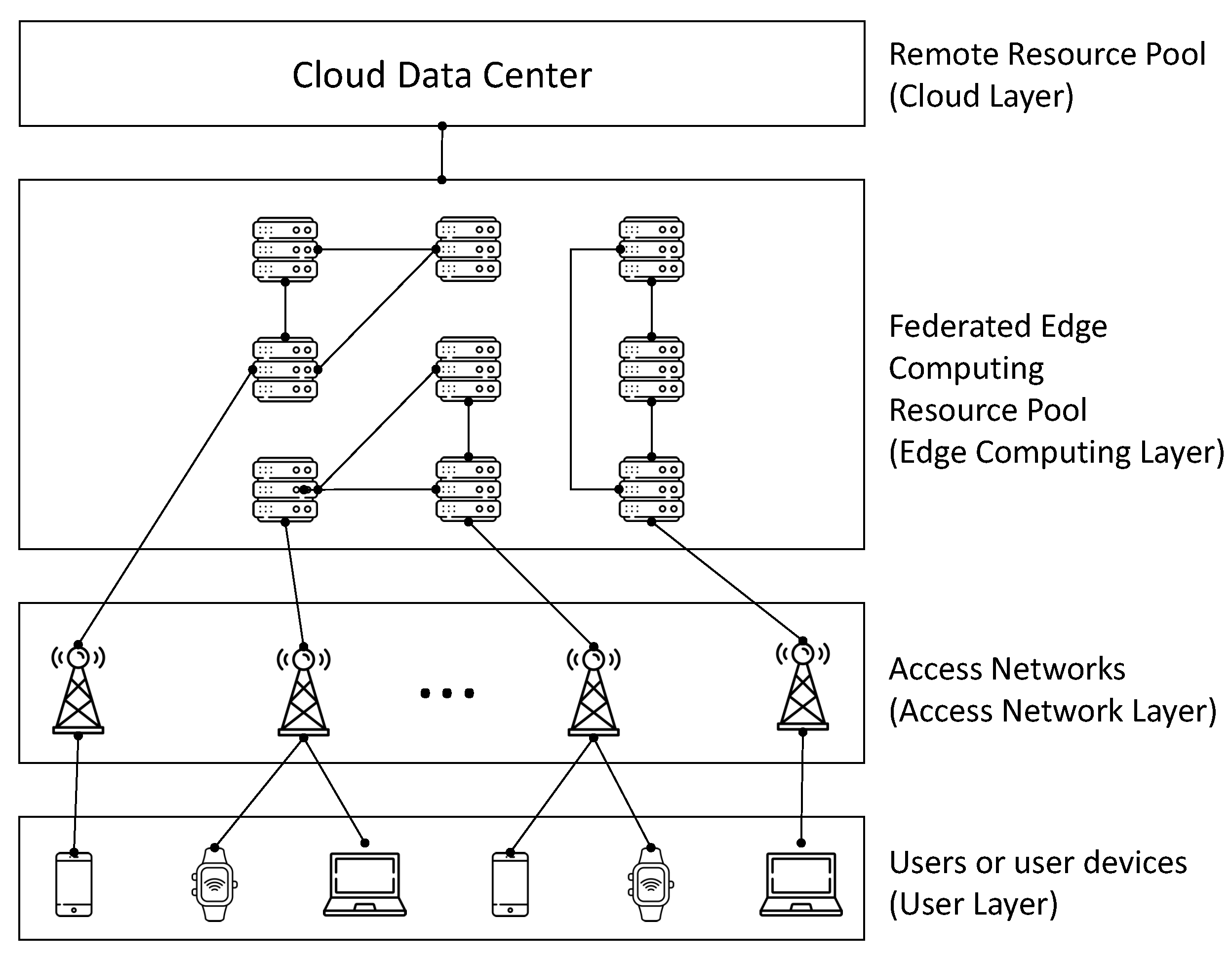
- We propose a federated edge server-based MEC architecture, where a user assigned to a particular federation can utilize only the edge servers in the same federation. This is practical and essential when some edge servers are operated by different service provider, or when some edge servers are owned by a third-party organization that is not trustworthy.
- In contrast to the previous MEC optimization approaches that focused on either VS or HS for provisioning virtualized resources, we propose to enable both to further enhance resource utilization and users’ QoS.
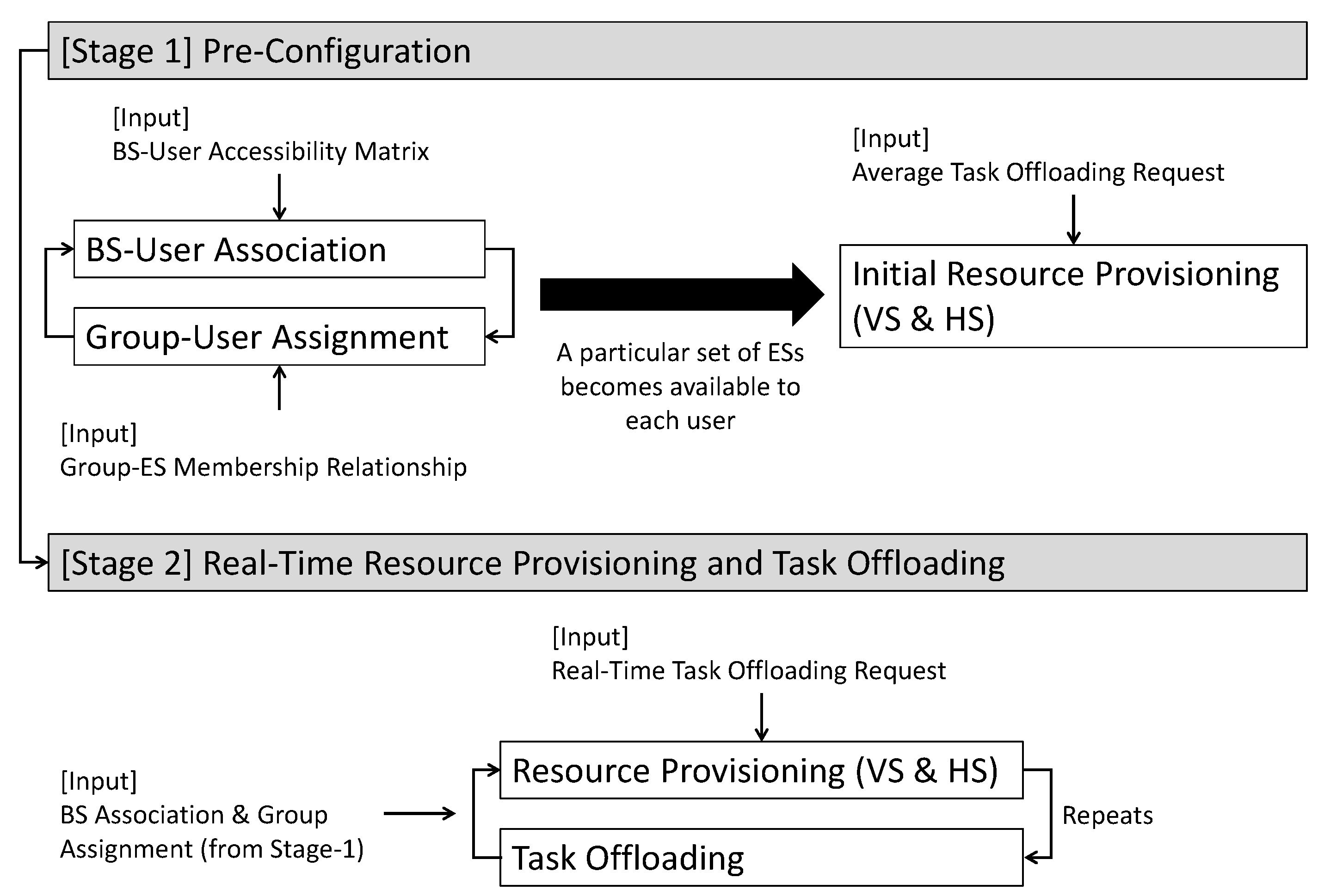
- We refer to our proposed approach as NAFEOS, which stands for Network-Aware Federated Edge Computing Optimal Scheduling. The NAFEOS approach presented in this study is formulated as a two-stage algorithm, considering the execution interval and complexity. The Stage-1 problem, which runs at long intervals, includes binary variables, resulting in relatively higher complexity. However, due to the efficient algorithms, such as branch-and-bound and branch-and-cut, leveraged in the computer solver we used in this study, the mixed integer (binary) linear program we propose in this study can be computed efficiently. On the other hand, the Stage-2 problem that iteratively optimizes both ES resources and task offloading at short intervals is formulated as linear programming so that it can run at low complexity. The proposed problem formulation aims to minimize battery consumption and service delay from the users’ perspective. At the same time, it maximizes the fair load distribution among federations by having a multi-objective optimization solution.
- We have carried out extensive evaluations and validated the effectiveness of the proposed optimal approach. Also, we have performed a comparison study with the common approaches. To do so, we implemented the proposed method along with its variants.
2. Related Work
3. Proposed Idea
3.1. Proposed System Architecture
3.2. Assumptions
3.3. Proposed Optimal MEC Management Method
4. Evaluation
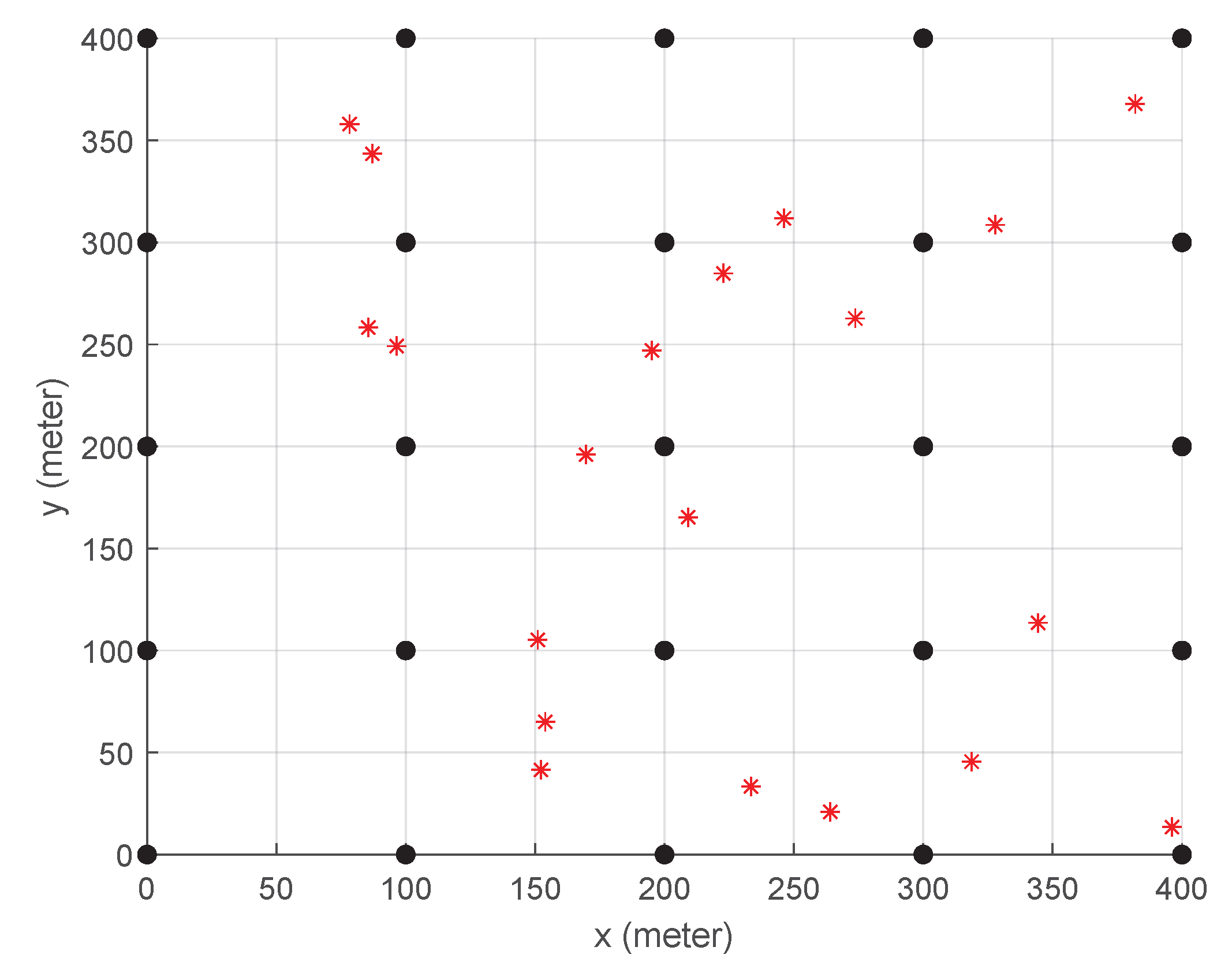
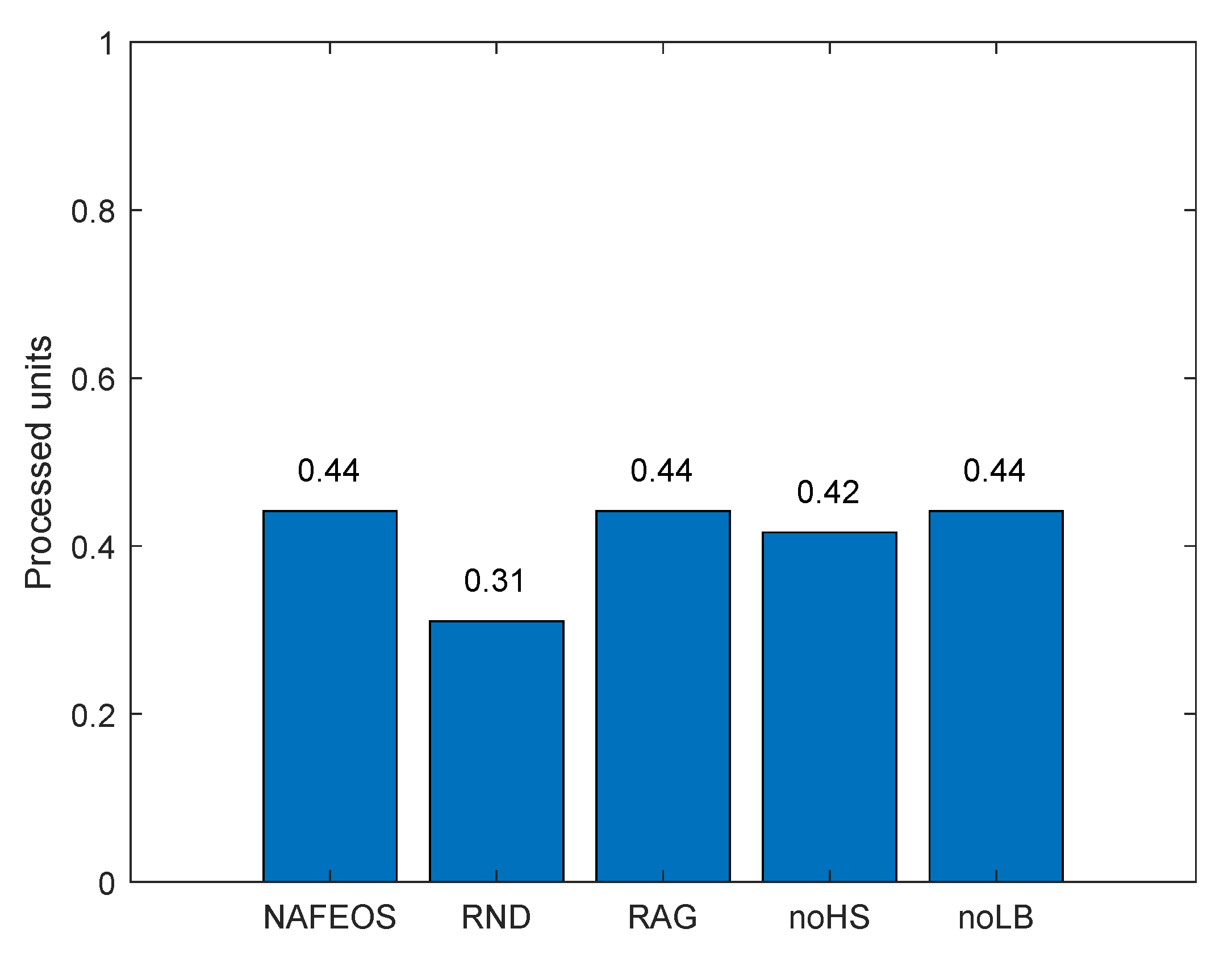
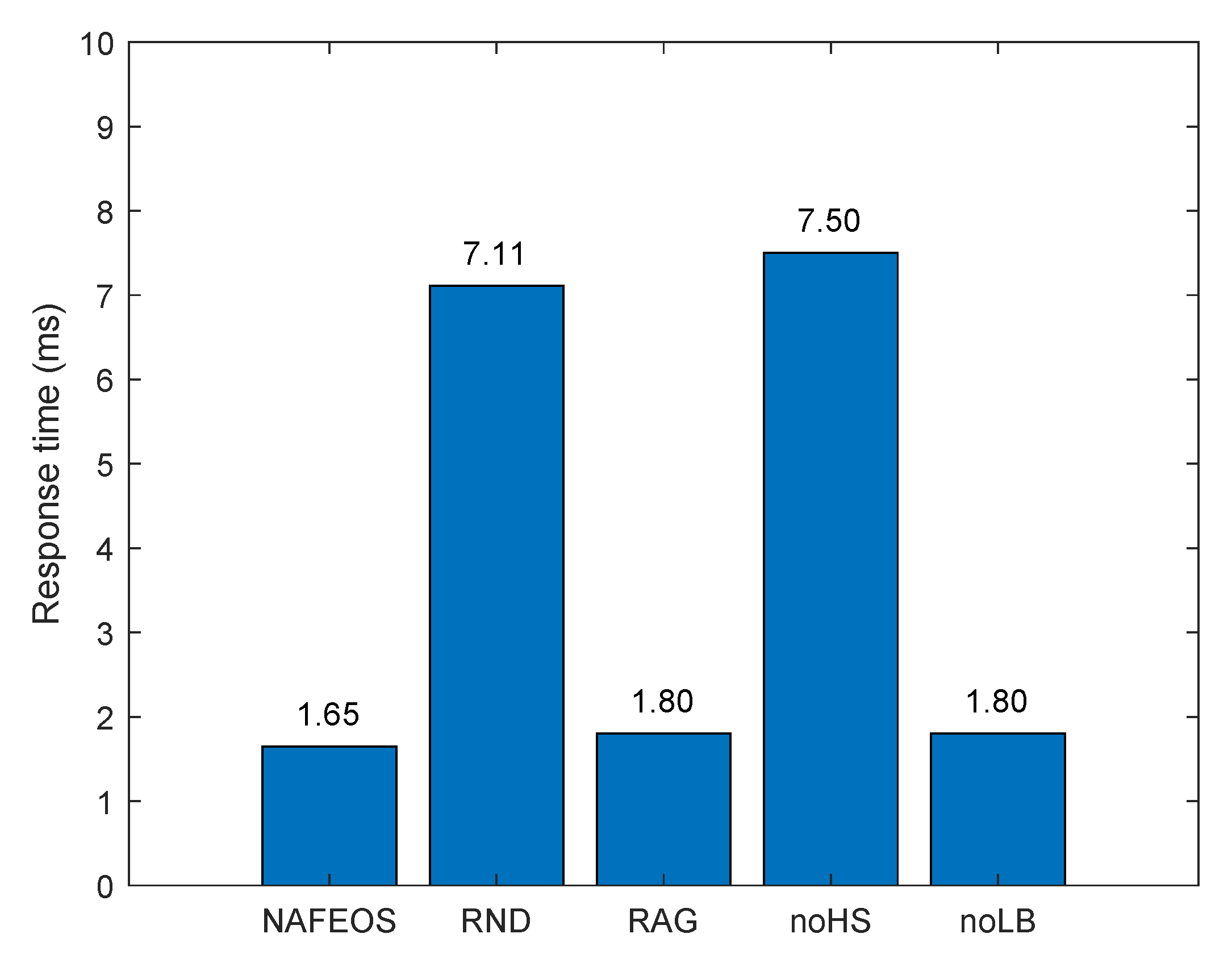
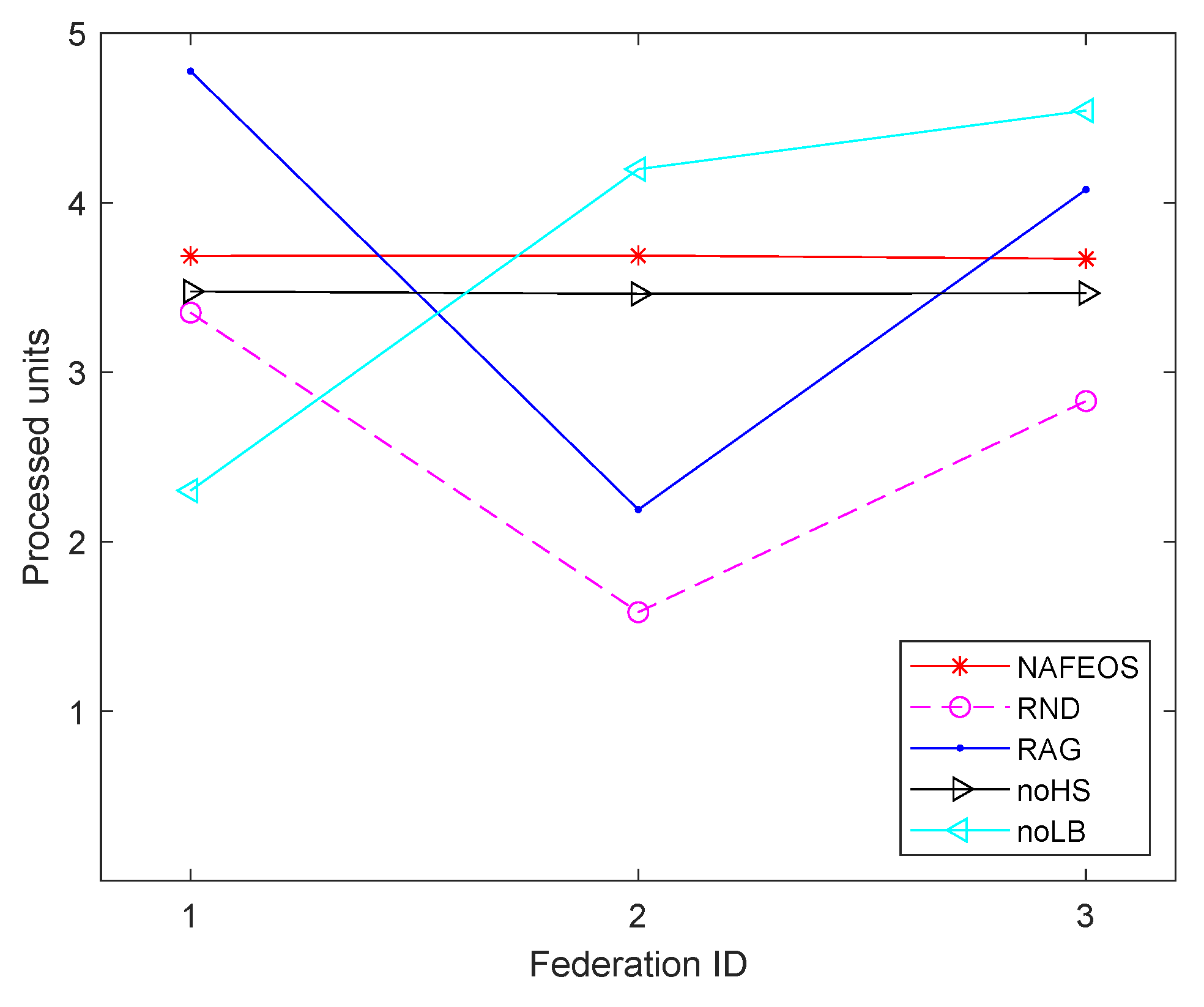
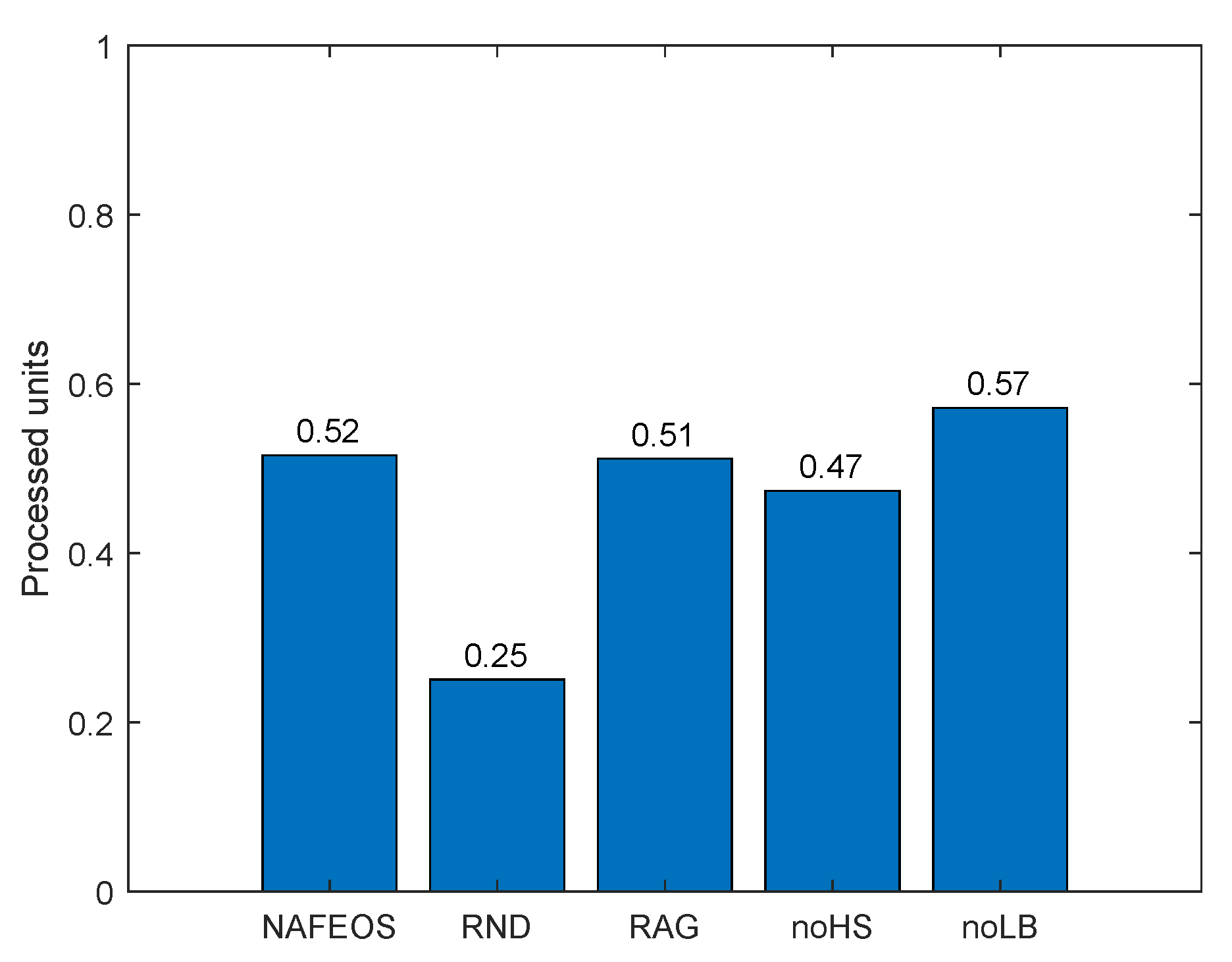
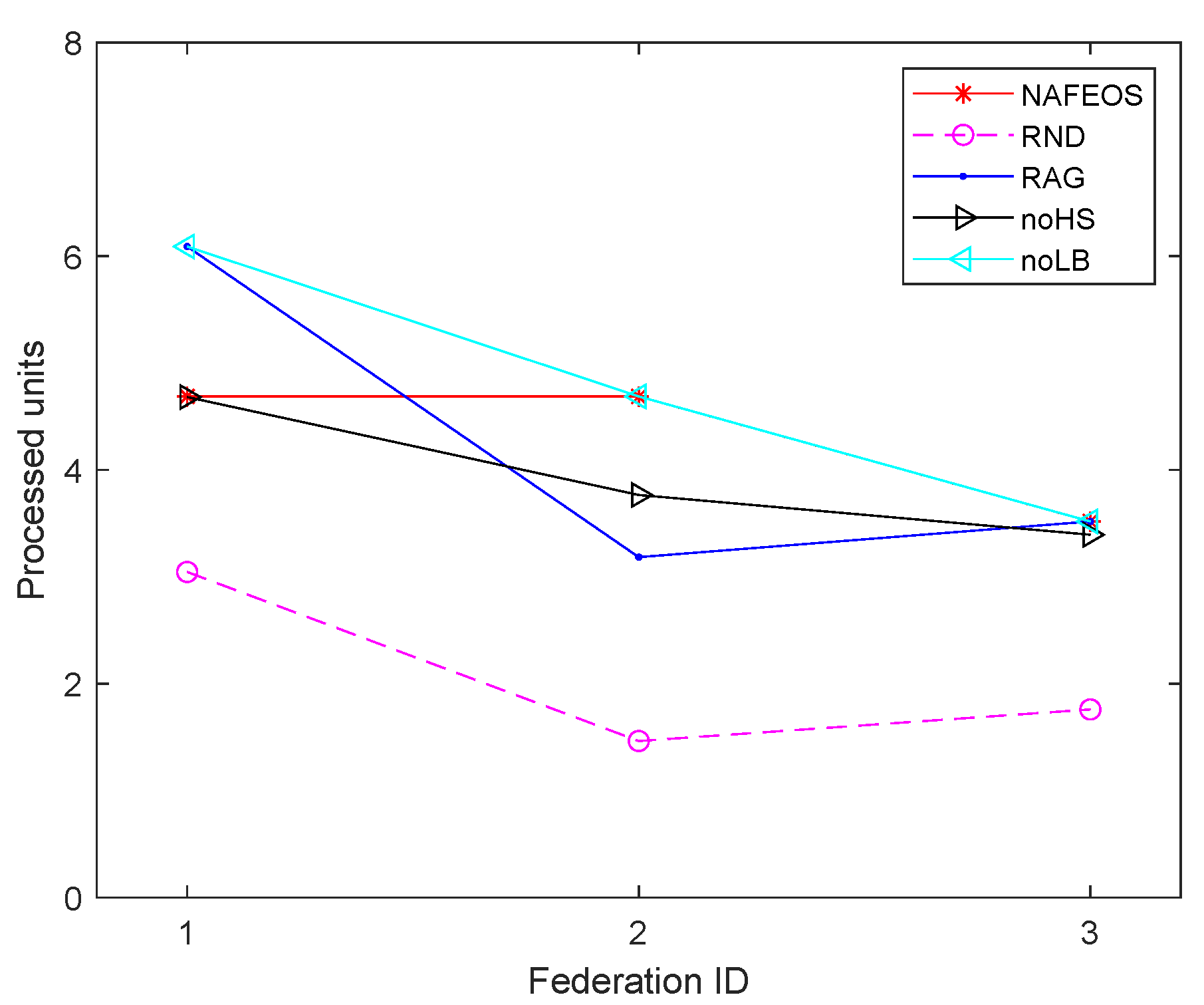
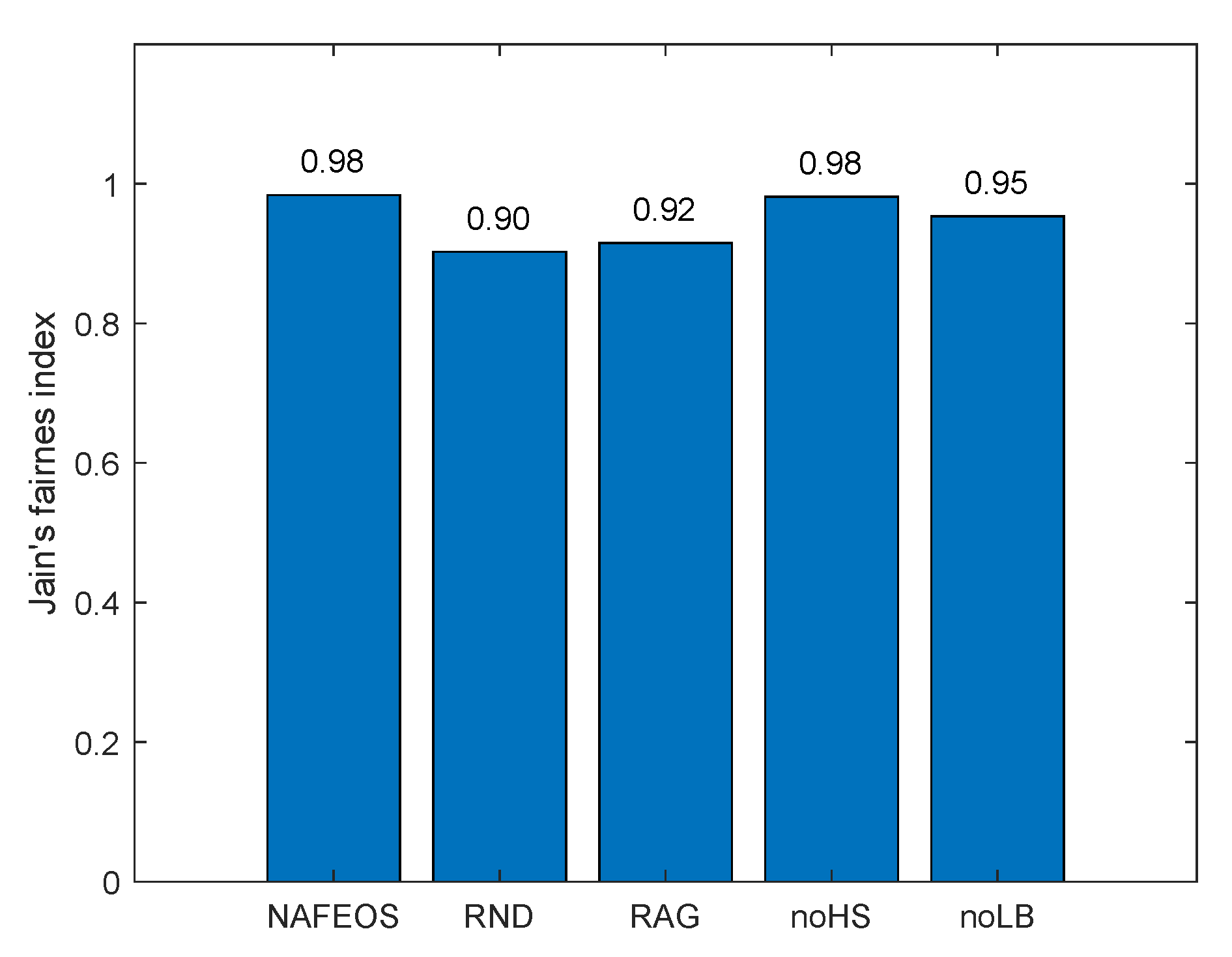
4.1. Even Distribution of Base Stations
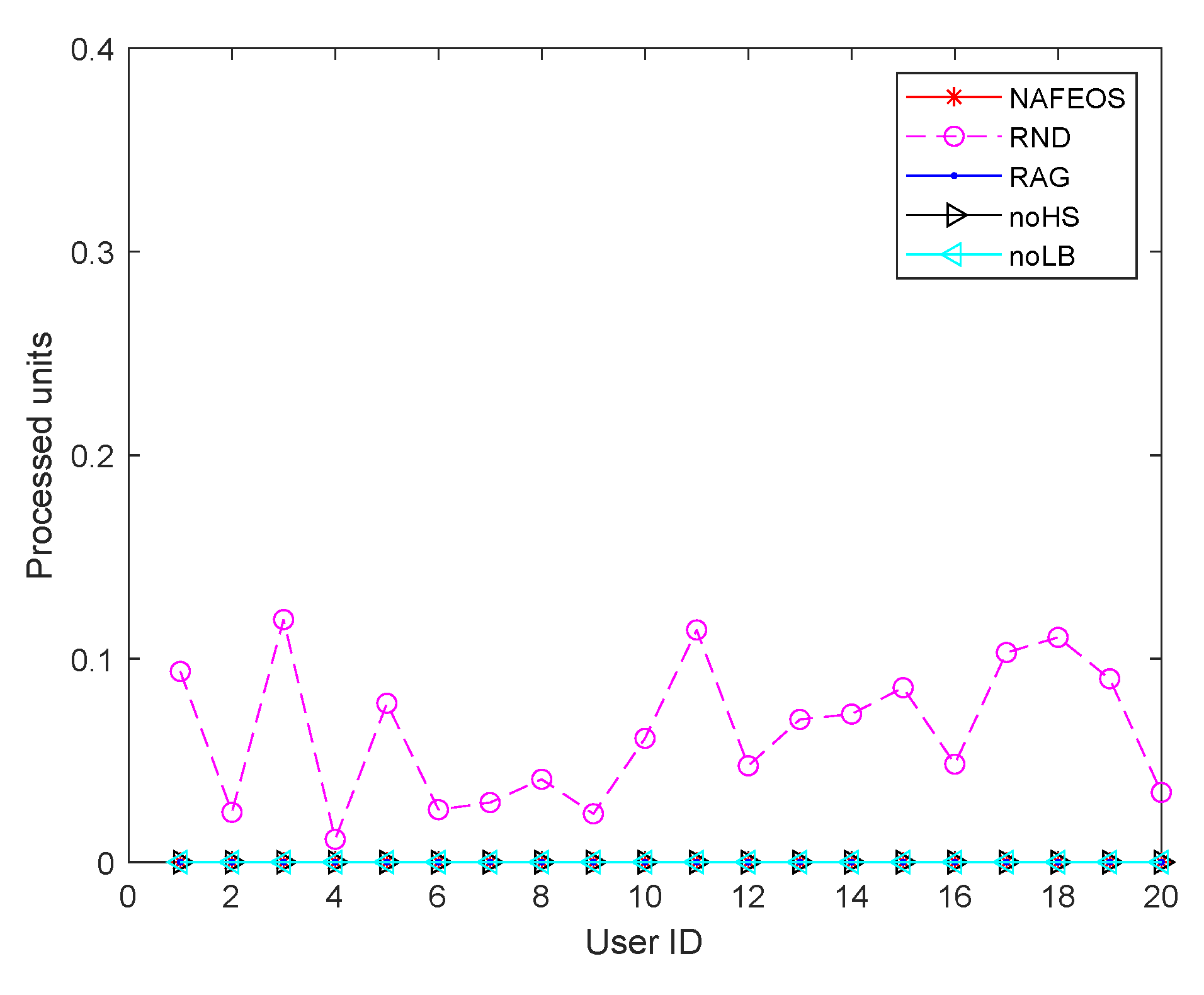
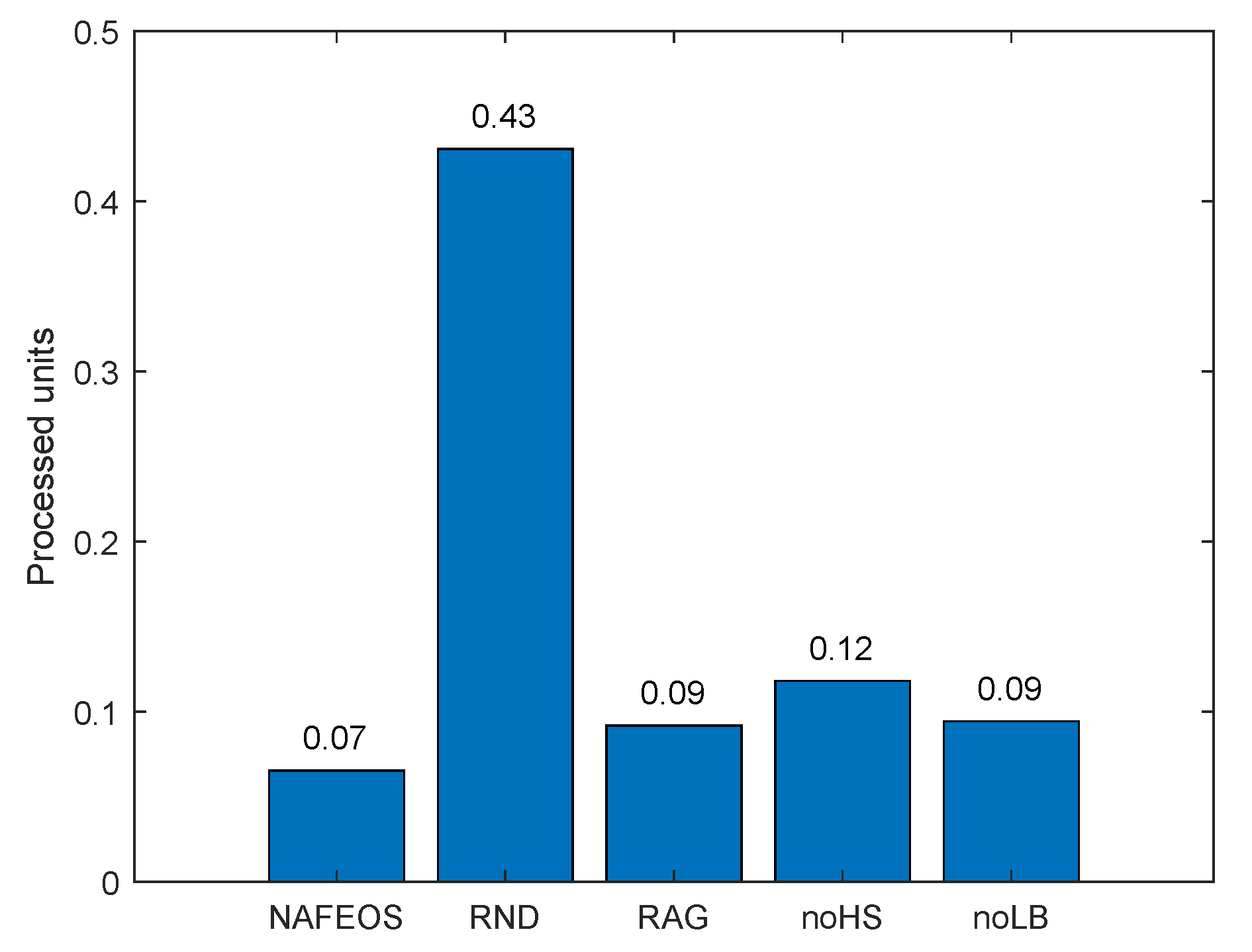
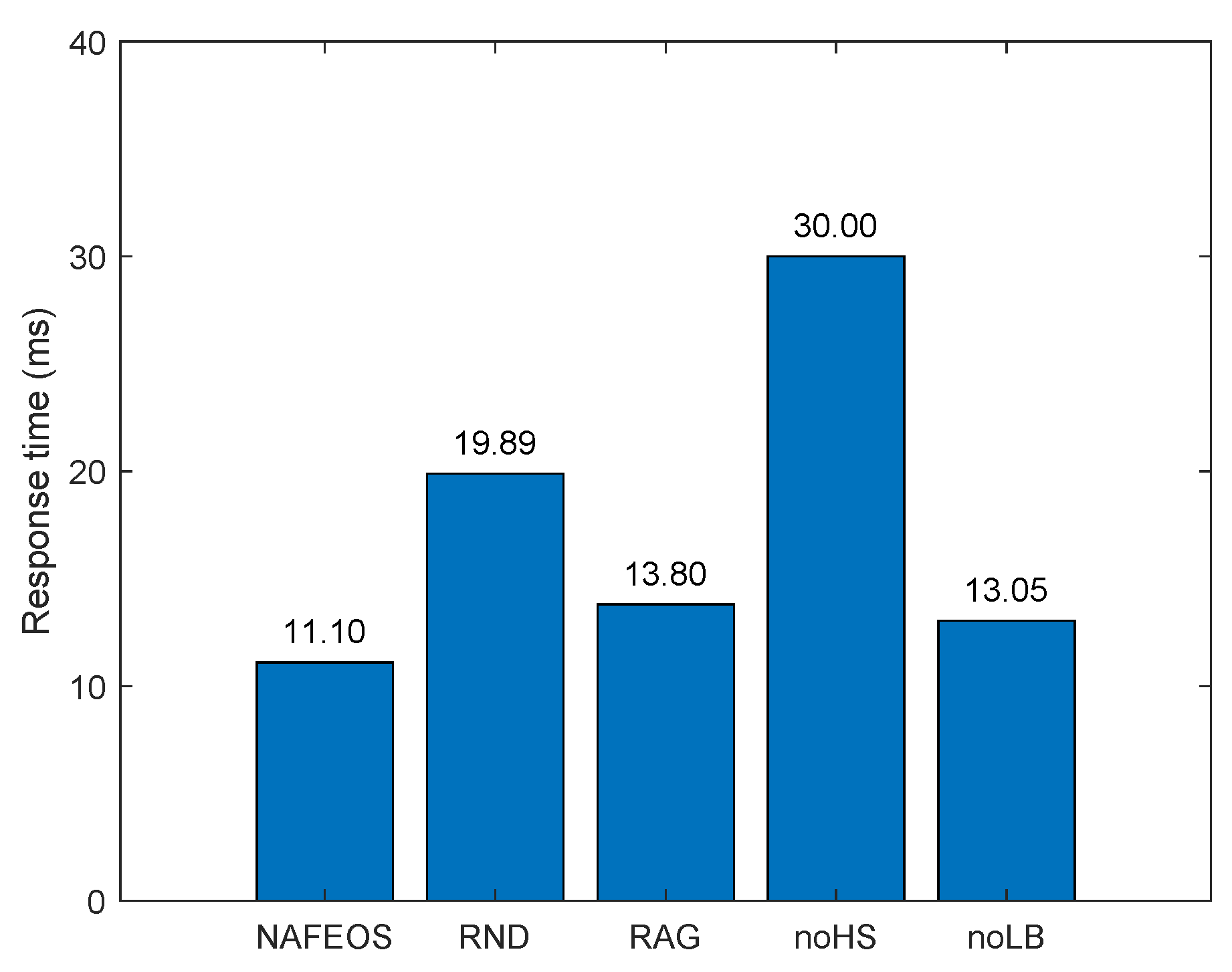
- NAFEOS: the optimal method proposed in this paper.
- RND (Random): random approach that makes decisions at random.
- RAG (Random Association and Grouping): same as NAFEOS, except that RAG randomly makes association and user-federation mapping (also called grouping).
- noHS (no Horizontal Scaling): same as NAFEOS, except that HS is not supported.
- noLB (no Load Balancing): same as NAFEOS, except that load balancing among federations is not supported.
- self-offloading yields zero response time
- offloading to ES without HS yields
- offloading to ES with HS yields
- offloading to the cloud yields
- offloading to ES without HS and to the cloud yields
- offloading to ES with HS and to the cloud yields .
4.2. Random Distribution of Base Stations with Higher Task Generation Rate
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Ma, X.; Zhang, J.; Hossain, M.S.; Muhammad, G.; Amin, S.U. Edge Intelligence in the Cognitive Internet of Things: Improving Sensitivity and Interactivity. IEEE Netw. 2019, 33, 58–64. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Choi, P.; Kwak, J. A Survey on Mobile Edge Computing for Deep Learning. In Proceedings of the International Conference on Information Networking (ICOIN), Bangkok, Thailand, 11–14 January 2023; pp. 652–655. [Google Scholar]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef]
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A. A survey on the computation offloading approaches in mobile edge computing: A machine learning-based perspective. Comput. Netw. 2020, 182, 107496. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutorials 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Jeong, H.J.; Lee, H.J.; Shin, K.Y.; Yoo, Y.H.; Moon, S.M. PerDNN: Offloading deep neural network computations to pervasive edge servers. In Proceedings of the IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 1055–1066. [Google Scholar]
- Chen, M.; Hao, Y. Task Offloading for Mobile Edge Computing in Software Defined Ultra-Dense Network. IEEE J. Sel. Areas Commun. 2018, 36, 587–597. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Q. Offloading Schemes in Mobile Edge Computing for Ultra-Reliable Low Latency Communications. IEEE Access 2018, 6, 12825–12837. [Google Scholar] [CrossRef]
- Jiang, C.; Cheng, X.; Gao, H.; Zhou, X.; Wan, J. Toward Computation Offloading in Edge Computing: A Survey. IEEE Access 2019, 7, 131543–131558. [Google Scholar] [CrossRef]
- Li, Q.; Wang, S.; Zhou, A.; Ma, X.; Yang, F.; Liu, A.X. QoS Driven Task Offloading with Statistical Guarantee in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022, 21, 278–290. [Google Scholar] [CrossRef]
- Sardellitti, S.; Merluzzi, M.; Barbarossa, S. Optimal Association of Mobile Users to Multi-Access Edge Computing Resources. In Proceedings of the IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, A.; Xu, G. Optimized task distribution based on task requirements and time delay in edge computing environments. Eng. Appl. Artif. Intell. 2020, 94, 103774. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, T.; Liu, Y.; Yang, D.; Xiao, L.; Tao, M. Cellular-Connected Multi-UAV MEC Networks: An Online Stochastic Optimization Approach. IEEE Trans. Commun. 2022, 70, 6630–6647. [Google Scholar] [CrossRef]
- Haibeh, L.A.; Yagoub, M.C.E.; Jarray, A. A Survey on Mobile Edge Computing Infrastructure: Design, Resource Management, and Optimization Approaches. IEEE Access 2022, 10, 27591–27610. [Google Scholar] [CrossRef]
- Yang, J.; Shah, A.A.; Pezaros, D. A Survey of Energy Optimization Approaches for Computational Task Offloading and Resource Allocation in MEC Networks. Electronics 2023, 12, 3548. [Google Scholar] [CrossRef]
- Chu, W.; Jia, X.; Yu, Z.; Lui, J.C.; Lin, Y. Joint Service Caching, Resource Allocation and Task Offloading for MEC-based Networks: A Multi-Layer Optimization Approach. IEEE Trans. Mob. Comput. 2023, 1–17. [Google Scholar] [CrossRef]
- Kim, T.; Lin, J.W.; Hsieh, C.T. Delay and QoS aware low complex optimal service provisioning for edge computing. IEEE Trans. Veh. Technol. 2023, 72, 1169–1183. [Google Scholar] [CrossRef]
- Yahya, W.; Oki, E.; Lin, Y.D.; Lai, Y.C. Scaling and offloading optimization in pre-CORD and post-CORD multi-access edge computing. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4503–4516. [Google Scholar] [CrossRef]
- Wang, N.; Matthaiou, M.; Nikolopoulos, D.S.; Varghese, B. DYVERSE: Dynamic vertical scaling in multi-tenant edge environments. Future Gener. Comput. Syst. 2020, 108, 598–612. [Google Scholar] [CrossRef]
- da Silva, T.P.; Neto, A.F.R.; Batista, T.V.; Lopes, F.A.; Delicato, F.C.; Pires, P.F. Horizontal auto-scaling in edge computing environment using online machine learning. In Proceedings of the IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), AB, Canada, 25–28 October 2021; pp. 161–168. [Google Scholar]
- Cañete, A.; Djemame, K.; Amor, M.; Fuentes, L.; Aljulayfi, A. A proactive energy-aware auto-scaling solution for edge-based infrastructures. In Proceedings of the IEEE/ACM 15th International Conference on Utility and Cloud Computing (UCC), Vancouver, WA, USA, 6–9 December 2022; pp. 240–247. [Google Scholar]
- Zhang, L.; Zou, Y.; Wang, W.; Jin, Z.; Su, Y.; Chen, H. Resource allocation and trust computing for blockchain-enabled edge computing system. Comput. Secur. 2021, 105, 102249. [Google Scholar] [CrossRef]
- Kim, T.; Al-Tarazi, M.; Lin, J.W.; Choi, W. Optimal container migration for mobile edge computing: Algorithm, system design and implementation. IEEE Access 2021, 9, 158074–158090. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Sun, R.; Su, R.; Liu, B. Joint user association and power allocation for minimizing multi-bitrate video transmission delay in mobile-edge computing networks. In Proceedings of the 12th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS-2018), Sydney, NSW, Australia, 3–5 July 2019; pp. 467–478. [Google Scholar]
- Dai, Y.; Xu, D.; Maharjan, S.; Zhang, Y. Joint computation offloading and user association in multi-task mobile edge computing. IEEE Trans. Veh. Technol. 2018, 67, 12313–12325. [Google Scholar] [CrossRef]
- Tang, X.; Wen, Z.; Chen, J.; Li, Y.; Li, W. Joint optimization task offloading strategy for mobile edge computing. In Proceedings of the IEEE 2nd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 17–19 December 2021; Volume 2, pp. 515–518. [Google Scholar]
- Bi, S.; Huang, L.; Zhang, Y.J.A. Joint optimization of service caching placement and computation offloading in mobile edge computing systems. IEEE Trans. Wirel. Commun. 2020, 19, 4947–4963. [Google Scholar] [CrossRef]
- Kherraf, N.; Alameddine, H.A.; Sharafeddine, S.; Assi, C.M.; Ghrayeb, A. Optimized provisioning of edge computing resources with heterogeneous workload in IoT networks. IEEE Trans. Netw. Serv. Manag. 2019, 16, 459–474. [Google Scholar] [CrossRef]
- Xiang, Z.; Deng, S.; Jiang, F.; Gao, H.; Tehari, J.; Yin, J. Computing power allocation and traffic scheduling for edge service provisioning. In Proceedings of the IEEE International Conference on Web Services (ICWS), Beijing, China, 19–23 October 2020; pp. 394–403. [Google Scholar]
- Abouaomar, A.; Cherkaoui, S.; Mlika, Z.; Kobbane, A. Resource provisioning in edge computing for latency-sensitive applications. IEEE Internet Things J. 2021, 8, 11088–11099. [Google Scholar] [CrossRef]
- Hussain, R.F.; Salehi, M.A.; Kovalenko, A.; Feng, Y.; Semiari, O. Federated edge computing for disaster management in remote smart oil fields. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 929–936. [Google Scholar]
- Chi, H.R.; Radwan, A. Fully-Decentralized Fairness-Aware Federated MEC Small-Cell Peer-Offloading for Enterprise Management Networks. IEEE Trans. Ind. Informatics 2022, 19, 644–652. [Google Scholar] [CrossRef]
- Karakoç, N.; Scaglione, A.; Reisslein, M.; Wu, R. Federated edge network utility maximization for a multi-server system: Algorithm and convergence. IEEE/Acm Trans. Netw. 2022, 30, 2002–2017. [Google Scholar] [CrossRef]
- Li, C.; Tang, J.; Luo, Y. Elastic edge cloud resource management based on horizontal and vertical scaling. J. Supercomput. 2020, 76, 7707–7732. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, T.; Li, A.; Zhang, W. Adaptive auto-scaling of delay-sensitive serverless services with reinforcement learning. In Proceedings of the IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 866–871. [Google Scholar]
- Daraje, M.; Shaikh, J. Hybrid resource scaling for dynamic workload in cloud computing. In Proceedings of the IEEE International Conference on Mobile Networks and Wireless Communications (ICMNWC), Tumkur, India, 3–4 December 2021; pp. 1–6. [Google Scholar]
- Maia, A.M.; Ghamri-Doudane, Y.; Vieira, D.; de Castro, M.F. Optimized Placement of Scalable IoT Services in Edge Computing. In Proceedings of the IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Arlington, VA, USA, 8–12 April 2019; pp. 189–197. [Google Scholar]
- Li, C.; Qianqian, C.; Luo, Y. Low-latency edge cooperation caching based on base station cooperation in SDN based MEC. Expert Syst. Appl. 2022, 191, 116252. [Google Scholar] [CrossRef]
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- Mitchell, J.E. Branch-and-cut algorithms for combinatorial optimization problems. Handb. Appl. Optim. 2002, 1, 65–77. [Google Scholar]
- Cplex, IBM ILOG. V12. 1: User’s Manual for CPLEX. Int. Bus. Mach. Corp. 2009, 46, 157. [Google Scholar]
- Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual; Gurobi Optimization, LLC: Beaverton, OR, USA, 2023. [Google Scholar]
- Karmarkar, N. A new polynomial-time algorithm for linear programming. In Proceedings of the Sixteenth Annual ACM Symposium on Theory of Computing, Washington, DC, USA, 30 April–2 May 1984; pp. 302–311. [Google Scholar]
- Morrison, D.R.; Jacobson, S.H.; Sauppe, J.J.; Sewell, E.C. Branch-and-bound algorithms: A survey of recent advances in searching, branching, and pruning. Discret. Optim. 2016, 19, 79–102. [Google Scholar] [CrossRef]
- MATLAB. Version 7.10.0 (R2010a); The MathWorks Inc.: Natick, MA, USA, 2010. [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1, 2014.
- Kelechi, A.H.; Alsharif, M.H.; Ramly, A.M.; Abdullah, N.F.; Nordin, R. The four-C framework for high capacity ultra-low latency in 5G networks: A review. Energies 2019, 12, 3449. [Google Scholar] [CrossRef]
- Guo, M.; Li, L.; Guan, Q. Energy-efficient and delay-guaranteed workload allocation in IoT-edge-cloud computing systems. IEEE Access 2019, 7, 78685–78697. [Google Scholar] [CrossRef]
- Jain, R.K.; Chiu, D.M.W.; Hawe, W.R. A Quantitative Measure of Fairness and Discrimination; Eastern Research Laboratory, Digital Equipment Corporation: Hudson, MA, USA, 1984; Volume 21. [Google Scholar]
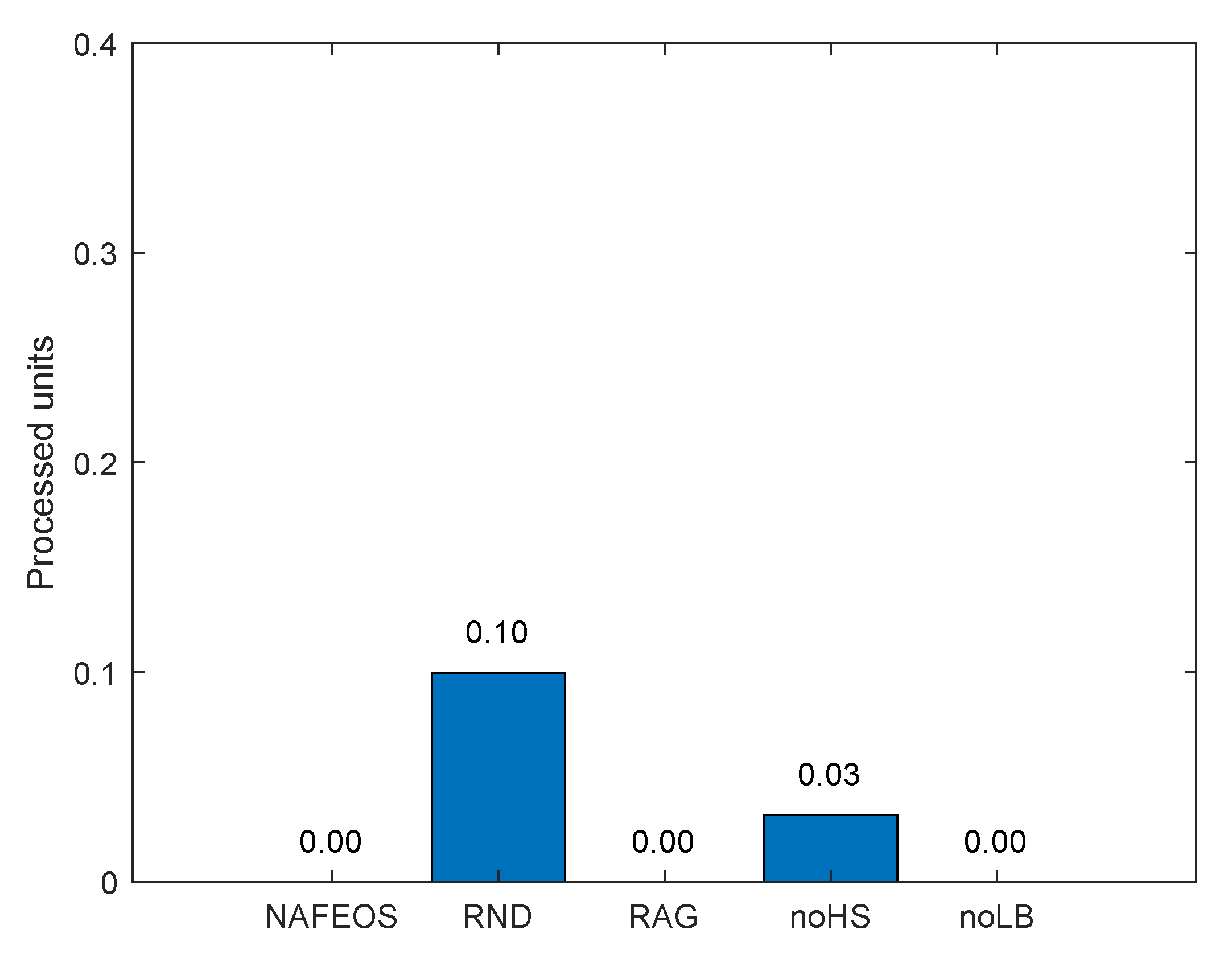



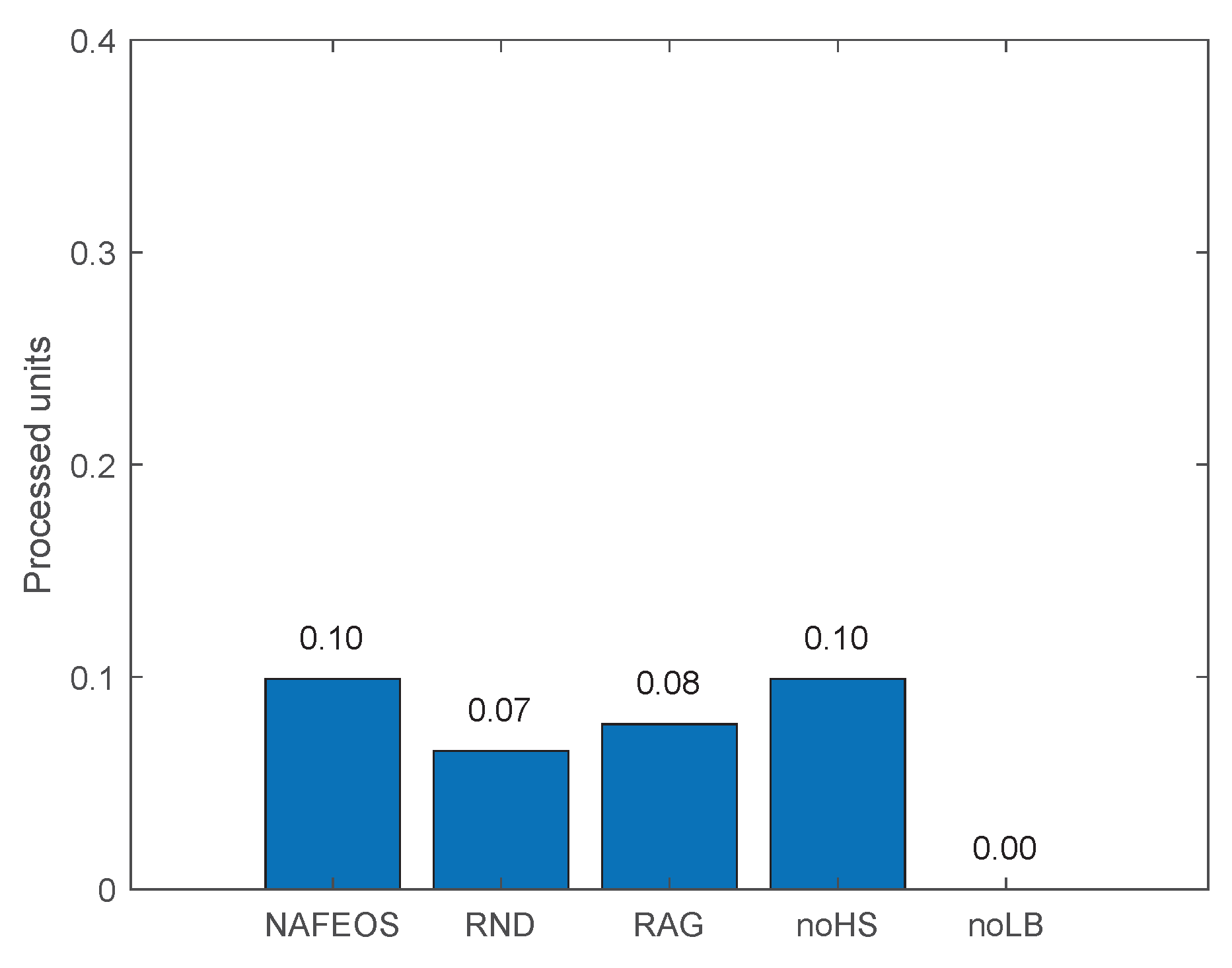


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of users | 20, distributed randomly |
| Number of BS/ES | 25, distributed evenly |
| BS transmission range | 150 m |
| Number of orthogonal channels | 5 |
| Number of federations | 3 |
| Offloading request rate | Uniform[0.20,1.00] per user |
| Resource budget | Uniform[0.05,0.20] per user |
| Uniform[0.40,0.80] per ES | |
| h | 0.05 (container operating overhead) |
| weights |
| Parameter | Value |
|---|---|
| Number of BS/ES | 25, randomly distributed |
| Offloading request rate | per user |
| weights |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nugroho, A.K.; Shioda, S.; Kim, T. Optimal Resource Provisioning and Task Offloading for Network-Aware and Federated Edge Computing. Sensors 2023, 23, 9200. https://doi.org/10.3390/s23229200
Nugroho AK, Shioda S, Kim T. Optimal Resource Provisioning and Task Offloading for Network-Aware and Federated Edge Computing. Sensors. 2023; 23(22):9200. https://doi.org/10.3390/s23229200
Chicago/Turabian StyleNugroho, Avilia Kusumaputeri, Shigeo Shioda, and Taewoon Kim. 2023. "Optimal Resource Provisioning and Task Offloading for Network-Aware and Federated Edge Computing" Sensors 23, no. 22: 9200. https://doi.org/10.3390/s23229200
APA StyleNugroho, A. K., Shioda, S., & Kim, T. (2023). Optimal Resource Provisioning and Task Offloading for Network-Aware and Federated Edge Computing. Sensors, 23(22), 9200. https://doi.org/10.3390/s23229200