
Dark-Channel Soft-Constrained and Object-Perception-Enhanced Deep Dehazing Networks Used for Road Inspection Images


Abstract
:1. Introduction
- (1)
- To realize compelling image dehazing under different complex road situations, the DCSC-OPE-Net is proposed for the haze removal of road inspection images. The proposed networks embed the dark-channel soft-constrained priori to recover the feature of different colors of objects contained in the road and learn the atmosphere transmission function to effectively recover haze-free images, which makes the results not only satisfy the physical priori but also the shortcomings of traditional DCP to adapt to white vehicles and lane lines, so as to obtain a better dehazing effect.
- (2)
- To recover and enhance the feature-discriminative ability of the road disease object, the OPE module is proposed and embedded into the proposed dehazing network. The OPE module can effectively avoid the loss of image resolution caused by patch-based DCP processing. Not only that, the OPE module can absorb the information of the scene transmission map and transform it into depth information so as to perceive and enhance the discriminative features of the near-view object of the road inspection, which ensures the effective execution of road inspection.
- (3)
- To verify the performance of the proposed DCSC-OPE-Net for road inspection images, the experiments are conducted on public datasets and road inspection images. The experimental results demonstrate that the proposed DCSC-OPE-Net outperforms typical DCP methods and state-of-the-art (SOTA) deep learning-based dehazing methods using the mainstream evaluation metrics. More importantly, the proposed DCSC-OPE-Net not only improves the visibility of the resulting image, but also enhances the discriminative ability of the objects contained in the road, which indicates better road object detection results.
2. Related Work
2.1. Shallow Dehazing Method
2.2. Deep Dehazing Networks
3. Deep Dehazing Network for Road Inspection Images with Dark-Channel Weak Constraints and Object Perception Enhancement
3.1. Dehazing Backbone Network
3.1.1. DCSC Module
3.1.2. DCSC Embedding
3.2. OPE Module
3.2.1. OPE Backbone
3.2.2. Near-View Object Perception and Feature Enhancement
4. Experimentation and Analysis
- Details of the datasets
- Evaluation metrics
4.1. Details of the Training Implementation of the Proposed Methodology
4.2. Performance Analysis of Ablation Experiments with Different Modules of the Proposed Methodology
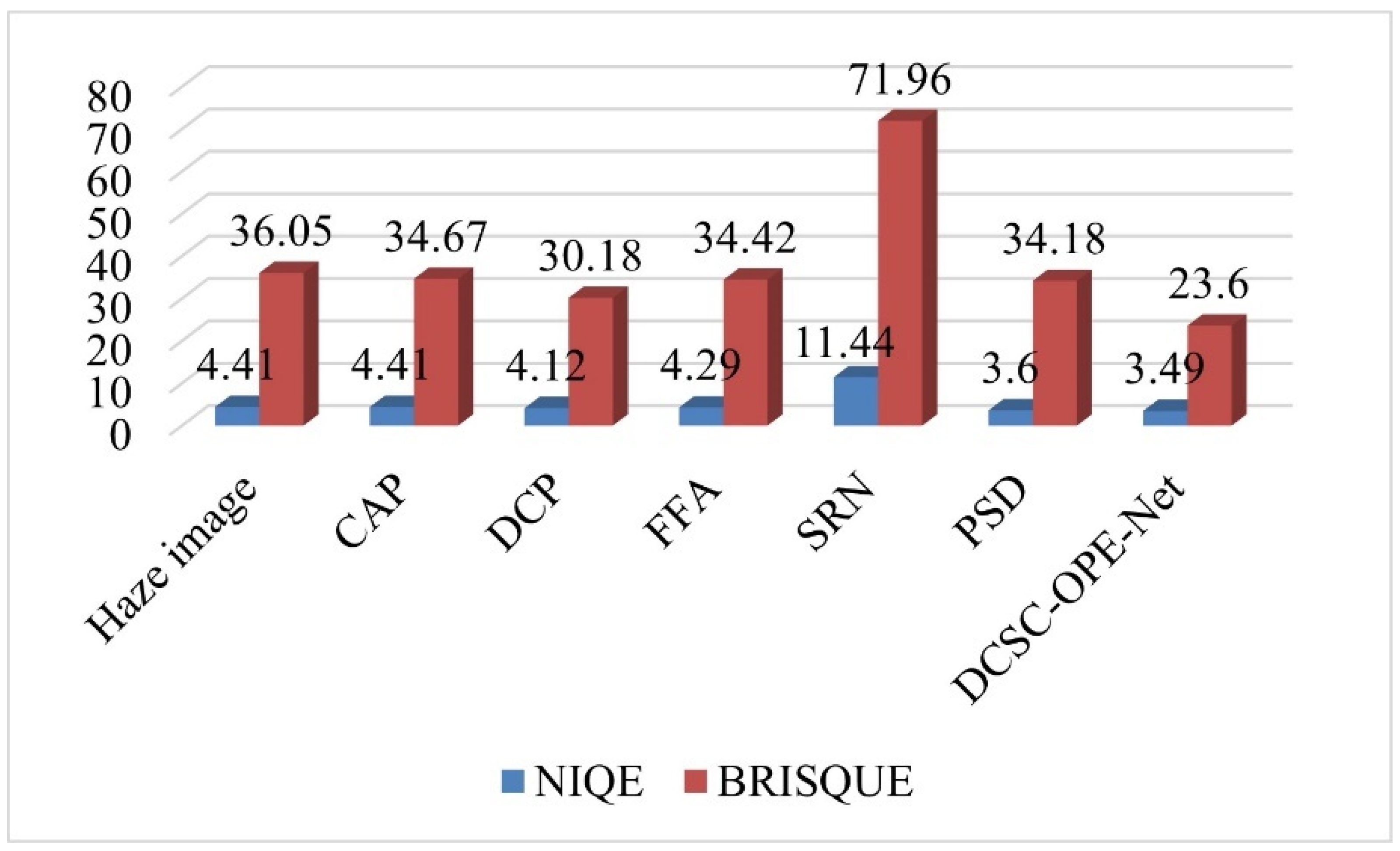
4.3. Evaluating the Performance of the Proposed Method Compared to SOTA Methods
- The color attention prior method (CAP): The CAP method is the classical haze-removal algorithm using a color attention prior. This method uses a linear model of colors to predict the scene depth so as to recover the haze-free image.
- The DCP: the DCP method is the classical dark-channel method, which serves as a representative physical modeling method for evaluating the performance of the proposed method.
- The Structure Representation Network (SRN) [40]: this method is a dehazing network model built in recent years, which utilizes uncertain feedback learning, thereby improving haze occlusion images with dense and non-uniform particle distributions to generate effective dehazing results.
- The Feature Fusion Attention Network (FFA-Net): the FFA-Net is a typical end-to-end dehazing network for the direct acquisition of haze-free images.
- The Principled Synthetic-to-Real Dehazing Network (PSD): the PSD network utilizes synthetic data to train real data fine-tuning to obtain effective dehazing results.
4.4. Evaluating the Performance of the Proposed Method for Feature Enhancement of Road Objects
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benedetto, A.; Tosti, F.; Ciampoli, L.B.; D’Amico, F. An overview of ground-penetrating radar signal processing techniques for road inspections. Signal Process. 2017, 132, 201–209. [Google Scholar] [CrossRef]
- Pereira, V.; Tamura, S.; Hayamizu, S.; Fukai, H. Classification of Paved and Unpaved Road Image Using Convolutional Neural Network for Road Condition Inspection System. In Proceedings of the 2018 5th International Conference on Advanced Informatics: Concept Theory and Applications (ICAICTA), Krabi, Thailand, 14–17 August 2018; pp. 165–169. [Google Scholar]
- Karballaeezadeh, N.; Zaremotekhases, F.; Shamshirband, S.; Mosavi, A.; Nabipour, N.; Csiba, P.; Várkonyi-Kóczy, A.R. Intelligent Road Inspection with Advanced Machine Learning; Hybrid Prediction Models for Smart Mobility and Transportation Maintenance Systems. Energies 2020, 13, 1718. [Google Scholar] [CrossRef]
- McCartney, E.J.; Hall, F.F. Optics of the atmosphere: Scattering by molecules and particles. Phys. Today 1977, 30, 76–77. [Google Scholar] [CrossRef]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Shi, S.; Zhang, Y.; Zhou, X.; Cheng, J. A novel thin cloud removal method based on multiscale dark channel prior (MDCP). IEEE Geosci. Remote Sens. Lett. 2021, 19, 1001905. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, T.; Tang, G.; Zhao, L.; Xu, Y.; Maybank, S. Single image haze removal based on a simple additive model with haze smoothness prior. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3490–3499. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8160–8168. [Google Scholar]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-dehaze: Enhanced cyclegan for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Zhang, C.; Wu, C. Multi-Scale Attentive Feature Fusion Network for Single Image Dehazing. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Liu, Z.; Xiao, B.; Alrabeiah, M.; Wang, K.; Chen, J. Single image dehazing with a generic model-agnostic convolutional neural network. IEEE Signal Process. Lett. 2019, 26, 833–837. [Google Scholar] [CrossRef]
- Li, R.; Pan, J.; Li, Z.; Tang, J. Single image dehazing via conditional generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8202–8211. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Li, R.; Pan, J.; He, M.; Li, Z.; Tang, J. Task-oriented network for image dehazing. IEEE Trans. Image Process. 2020, 29, 6523–6534. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.-H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 154–169. [Google Scholar]
- Chen, Z.; Wang, Y.; Yang, Y.; Liu, D. PSD: Principled synthetic-to-real dehazing guided by physical priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7180–7189. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. A closed-form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 228–242. [Google Scholar] [CrossRef]
- Fattal, R. Single image dehazing. ACM Trans. Graph. (TOG) 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Zhu, M.; He, B.; Wu, Q. Single image dehazing based on dark channel prior and energy minimization. IEEE Signal Process. Lett. 2017, 25, 174–178. [Google Scholar] [CrossRef]
- Park, Y.; Kim, T.-H. Fast execution schemes for dark-channel-prior-based outdoor video dehazing. IEEE Access 2018, 6, 10003–10014. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Park, J.; Han, D.K.; Ko, H. Fusion of heterogeneous adversarial networks for single image dehazing. IEEE Trans. Image Process. 2020, 29, 4721–4732. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, Y.; Cui, Y. An attention encoder-decoder network based on generative adversarial network for remote sensing image dehazing. IEEE Sens. J. 2022, 22, 10890–10900. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Y.; Yan, Q.; Zhang, K. Deep dehazing network with latent ensembling architecture and adversarial learning. IEEE Trans. Image Process. 2020, 30, 1354–1368. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Fang, T.; Fan, Y.; Wu, W.; She, Q.; Gan, H. Image-dehazing method based on the fusion coding of contours and colors. IEEE Access 2019, 7, 147857–147871. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, J.; Li, B.; Ni, X.; Mei, J. Nighttime Image Dehazing based on Bright and Dark Channel Prior and Gaussian Mixture Model. In Proceedings of the 2023 6th International Conference on Image and Graphics Processing, Chongqing, China, 6–8 January 2023; pp. 44–50. [Google Scholar]
- Li, C.; Guo, C.; Guo, J.; Han, P.; Fu, H.; Cong, R. PDR-Net: Perception-inspired single image dehazing network with refinement. IEEE Trans. Multimed. 2019, 22, 704–716. [Google Scholar] [CrossRef]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.-H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Qin, X.; Wu, C.; Chang, H.; Lu, H.; Zhang, X. Match Feature U-Net: Dynamic receptive field networks for biomedical image segmentation. Symmetry 2020, 12, 1230. [Google Scholar] [CrossRef]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 349–356. [Google Scholar]
- Farsiu, S.; Robinson, M.D.; Elad, M.; Milanfar, P. Fast and Robust Multiframe Super Resolution. IEEE Trans. Image Process. 2004, 13, 1327–1344. [Google Scholar] [CrossRef] [PubMed]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. May 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Kanade, S.B.T. Limits on super-resolution and how to break them. IEEE Trans. Pattern Anal. Mach. Intell. Sept. 2002, 24, 1167–1183. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Jin, Y.; Yan, W.; Yang, W.; Tan, R.T. Structure representation network and uncertainty feedback learning for dense non-uniform fog removal. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 155–172. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Gao, T.; Chen, H.; Chen, W. Adaptive heterogeneous support tensor machine: An extended STM for object recognition using an arbitrary combination of multisource heterogeneous remote sensing data. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5611222. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Haze Image | MSBDN | DCSC-MSBDN | MSBDN-OPE | DCSC-OPE-Net | |
|---|---|---|---|---|---|
| NIQE | 4.41 | 4.38 | 3.62 | 3.77 | 3.49 |
| BRISQUE | 36.05 | 34.19 | 34.2 | 23.4 | 23.1 |
| Haze Image | CAP | DPC | FFA | SRN | PSD | DCSC-OPE-Net | |
|---|---|---|---|---|---|---|---|
| AG | 22.64 | 34.51 | 25.96 | 22.16 | 22.1 | 60.09 | 95.81 |
| BRISQUE | 8.64 | 8.61 | 8.19 | 8.73 | 19.7 | 6.79 | 4.5 |
| NIQE | 25.56 | 26.40 | 25.07 | 28.15 | 67.97 | 20.84 | 18.67 |
| Haze Image | CAP | DCP | FFA | SRN | PSD | DCSC-OPE-Net | |
|---|---|---|---|---|---|---|---|
| recognition rate | 57.0% | 67.25% | 55.25% | 69.33% | 59.17% | 71.42% | 83.67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Gao, T.; Ji, Z.; Song, M.; Zhang, L.; Kong, D. Dark-Channel Soft-Constrained and Object-Perception-Enhanced Deep Dehazing Networks Used for Road Inspection Images. Sensors 2023, 23, 8932. https://doi.org/10.3390/s23218932
Wu H, Gao T, Ji Z, Song M, Zhang L, Kong D. Dark-Channel Soft-Constrained and Object-Perception-Enhanced Deep Dehazing Networks Used for Road Inspection Images. Sensors. 2023; 23(21):8932. https://doi.org/10.3390/s23218932
Chicago/Turabian StyleWu, Honglin, Tong Gao, Zhenming Ji, Mou Song, Lianzhen Zhang, and Dezhi Kong. 2023. "Dark-Channel Soft-Constrained and Object-Perception-Enhanced Deep Dehazing Networks Used for Road Inspection Images" Sensors 23, no. 21: 8932. https://doi.org/10.3390/s23218932
APA StyleWu, H., Gao, T., Ji, Z., Song, M., Zhang, L., & Kong, D. (2023). Dark-Channel Soft-Constrained and Object-Perception-Enhanced Deep Dehazing Networks Used for Road Inspection Images. Sensors, 23(21), 8932. https://doi.org/10.3390/s23218932