
Path Planning for Unmanned Surface Vehicles with Strong Generalization Ability Based on Improved Proximal Policy Optimization

Abstract
:1. Introduction
- To reflect realistic maritime environments, a grid-based environment model is constructed based on real-world electronic charts to map the dynamic states of a ship and static obstacles in the sea.
- Integration of planning and obstacle avoidance is achieved based on the proposed PPO algorithm, with the consideration of the sensing range of on-board sensors.
- To address the unpredictable situations, e.g., unknown maps or moving ships in the area, we use convolutional neural networks (CNNs) for state-feature extraction in PPO. Our simulation results show that this method greatly improves the adaptability of USV in path planning in uncharted marine environments.
2. Modeling and Problem Formulation
2.1. Building a Marine Environment Map Based on Electronic Charts
2.2. Problem Formulation
3. USV Path Planning Based on PPO
3.1. State Space
3.2. Action Space
3.3. Reward Function
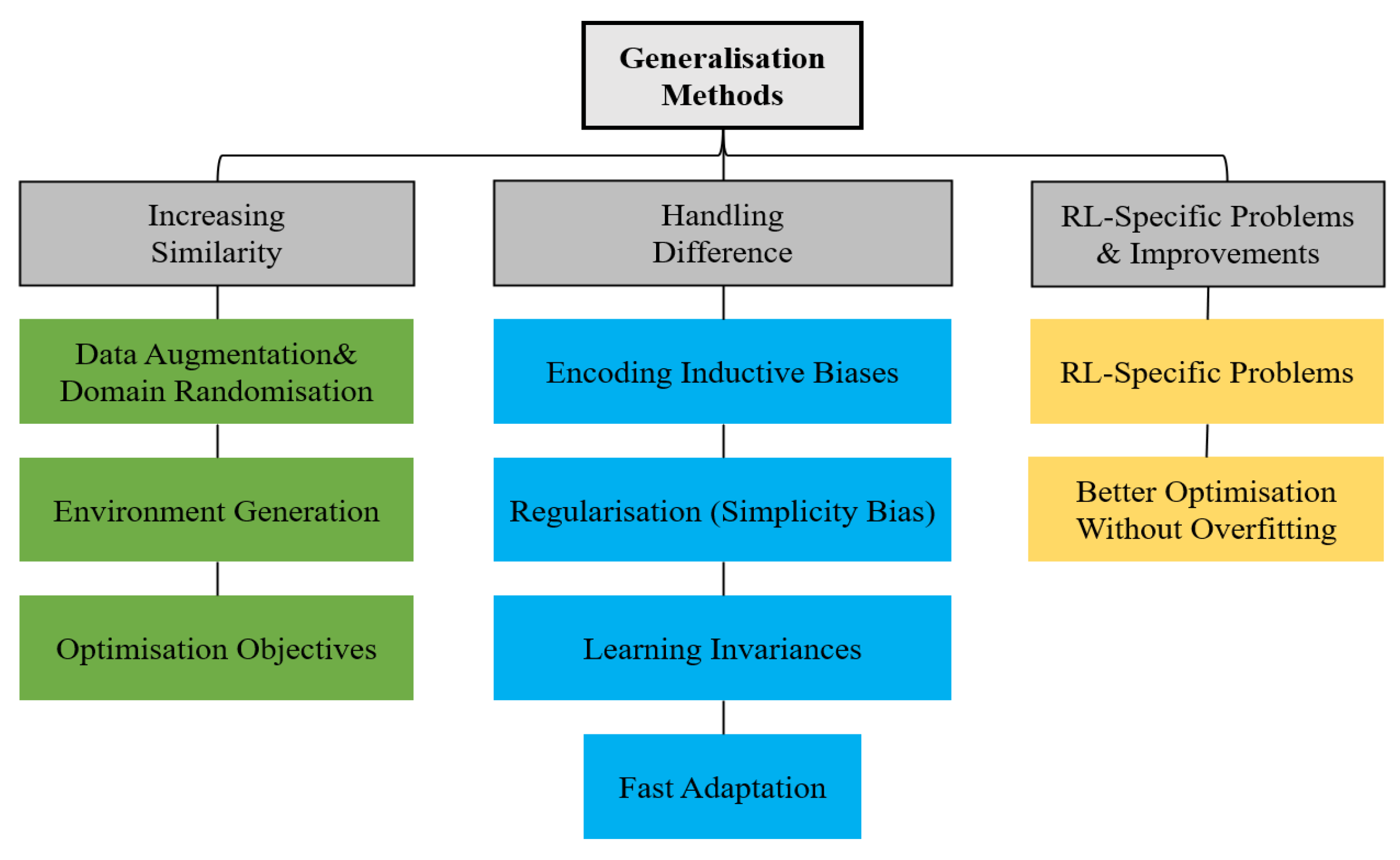
3.4. Improved PPO with Better Generalization Capability
3.4.1. Neural Network Design with Convolutional Layers
3.4.2. PPO Algorithm
| Algorithm 1: Pseudo code of the PPO–Clip algorithm |
|
4. Experiments
4.1. Generalization Definition and Modeling
4.2. Simulation Experiment
4.2.1. Experimental Platform Description and Training Parameters
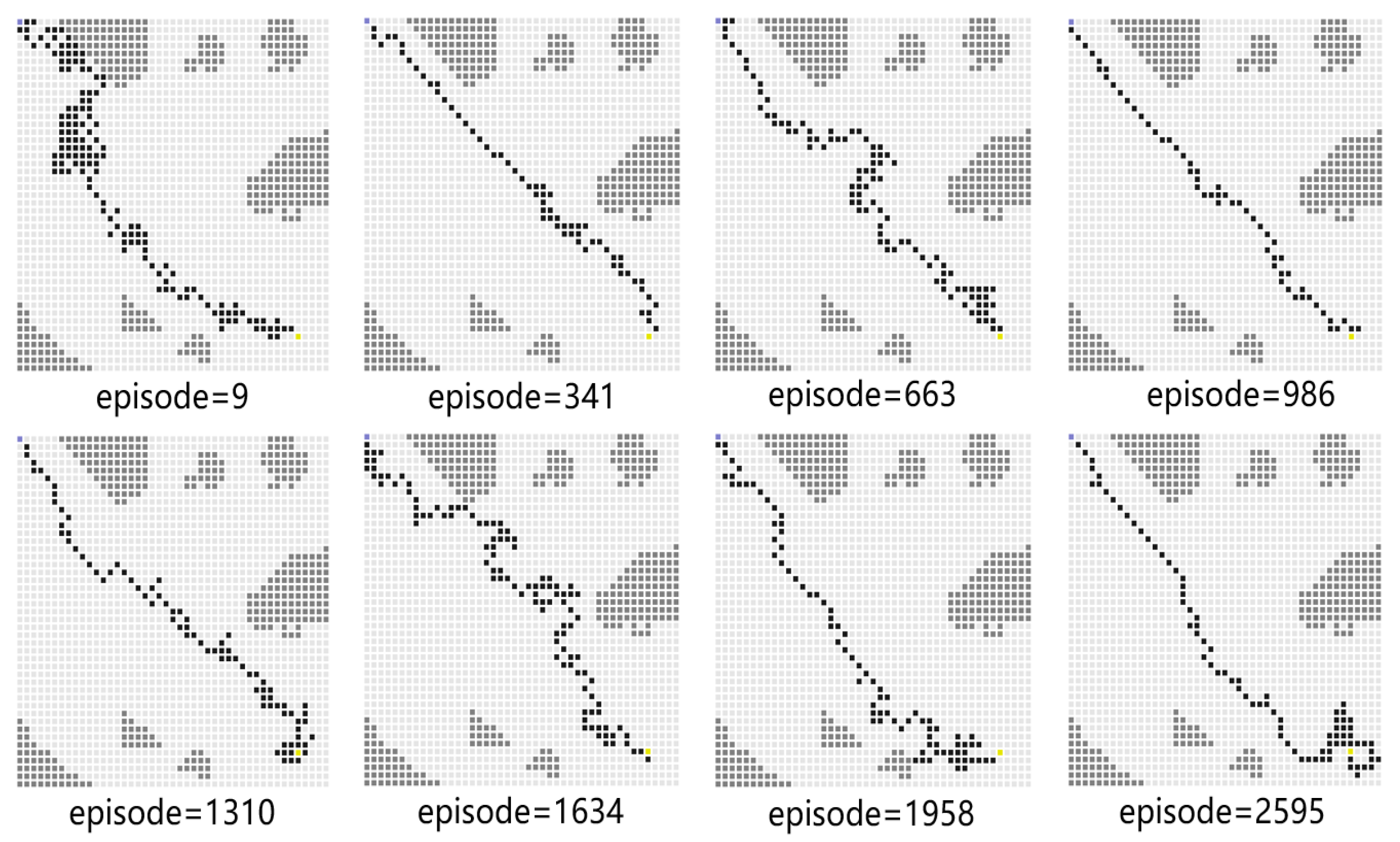
4.2.2. Experimental Results and Analysis
4.2.3. Comparative Experiment
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kurowski, M.; Thal, J.; Damerius, R.; Korte, H.; Jeinsch, T. Automated Survey in Very Shallow Water using an Unmanned Surface Vehicle. IFAC Pap. Online 2019, 52, 146–151. [Google Scholar] [CrossRef]
- Jin, J.; Zhang, J.; Shao, F.; Lyu, Z.; Wang, D. A novel ocean bathymetry technology based on an unmanned surface vehicle. Acta Oceanol. Sin. 2018, 37, 99–106. [Google Scholar] [CrossRef]
- Schofield, R.T.; Wilde, G.A.; Murphy, R.R. Potential field implementation for move-to-victim behavior for a lifeguard assistant unmanned surface vehicle. In Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–2. [Google Scholar]
- Liu, X.; Li, Y.; Zhang, J.; Zheng, J.; Yang, C. Self-adaptive dynamic obstacle avoidance and path planning for USV under complex maritime environment. IEEE Access 2019, 7, 114945–114954. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, L.; Chen, P.; Negenborn, R.R. Ship collision avoidance methods: State-of-the-art. Saf. Sci. 2020, 121, 451–473. [Google Scholar] [CrossRef]
- Patle, B.K.; Pandey, A.; Parhi, D.R.K.; Jagadeesh, A. A review: On path planning strategies for navigation of mobile robot. Def. Technol. 2019, 15, 582–606. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, J.; Jin, J.; Mao, X. Local collision avoidance algorithm for a unmanned surface vehicle based on steering maneuver considering colregs. IEEE Access 2021, 9, 49233–49248. [Google Scholar] [CrossRef]
- Choset, H.; Lynch, K.M.; Hutchinson, S.; Kantor, G.A.; Burgard, W. Principles of Robot Motion: Theory, Algorithms, and Implementations; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Iijima, Y.; Hagiwara, H.; Kasai, H. Results of collision avoidance manoeuvre experiments using a knowledge-based autonomous piloting system. J. Navig. 1991, 44, 194–204. [Google Scholar] [CrossRef]
- Churkin, V.I.; Zhukov, Y.I. Procedures for ship collision avoidance. In Proceedings of the IEEE Oceanic Engineering Society. OCEANS’98. Conference Proceedings (Cat. No. 98CH36259), Nice, France, 28 September–1 October 1998; Volume 2, pp. 857–860. [Google Scholar]
- Hwang, C.N. The integrated design of fuzzy collision-avoidance and H[infty infinity]-autopilots on ships. J. Navig. 2002, 55, 117–136. [Google Scholar] [CrossRef]
- Chang, K.Y.; Jan, G.E.; Parberry, I. A method for searching optimal routes with collision avoidance on raster charts. J. Navig. 2003, 56, 371–384. [Google Scholar] [CrossRef]
- Szlapczynski, R. A new method of ship routing on raster grids, with turn penalties and collision avoidance. J. Navig. 2005, 59, 27–42. [Google Scholar] [CrossRef]
- Niu, H.; Savvaris, A.; Tsourdos, A.; Ji, Z. Voronoi-visibility roadmap-based path planning algorithm for unmanned surface vehicles. J. Navig. 2019, 72, 850–874. [Google Scholar] [CrossRef]
- Nie, Z.; Zhao, H. Research on robot path planning based on Dijkstra and Ant colony optimization. In Proceedings of the 2019 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Shanghai, China, 21–24 November 2019; pp. 222–226. [Google Scholar]
- Kuwata, Y.; Wolf, M.T.; Zarzhitsky, D.; Huntsberger, T.L. Safe maritime autonomous navigation with COLREGS, using velocity obstacles. IEEE J. Ocean. Eng. 2013, 39, 110–119. [Google Scholar] [CrossRef]
- Yao, P.; Zhao, R.; Zhu, Q. A hierarchical architecture using biased min-consensus for USV path planning. IEEE Trans. Veh. Technol. 2020, 69, 9518–9527. [Google Scholar] [CrossRef]
- Wu, J.; Xue, Y.; Qiu, E. Research on Unmanned Surface Vehicle Path Planning Based on Improved Intelligent Water Drops Algorithm. In Proceedings of the 2020 4th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 6–8 November 2020; pp. 637–641. [Google Scholar]
- Wei, A.; Yue, L.; Yanfeng, W.; Yong, H.; Guoqing, C.; Genwang, H. Design and Research of Intelligent Navigation System for Unmanned Surface Vehicle. In Proceedings of the 2020 3rd International Conference on Unmanned Systems (ICUS), Harbin, China, 27–28 November 2020; pp. 1102–1107. [Google Scholar]
- Woo, J.; Kim, N. Collision avoidance for an unmanned surface vehicle using deep reinforcement learning. Ocean. Eng. 2020, 199, 107001. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, C.; Liu, Y.; Chen, X. Decision-making for the autonomous navigation of maritime autonomous surface ships based on scene division and deep reinforcement learning. Sensors 2019, 19, 4055. [Google Scholar] [CrossRef] [PubMed]
- Jaradat, M.A.K.; Al-Rousan, M.; Quadan, L. Reinforcement based mobile robot navigation in dynamic environment. Robot. Comput. Integr. Manuf. 2011, 27, 135–149. [Google Scholar] [CrossRef]
- Guan, W.; Cui, Z.; Zhang, X. Intelligent Smart Marine Autonomous Surface Ship Decision System Based on Improved PPO Algorithm. Sensors 2022, 22, 5732. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, X.; Du, Y.; Zheng, Y.; Cao, Z. Path planning of coastal ships based on optimized DQN reward function. J. Mar. Sci. Eng. 2021, 9, 210. [Google Scholar] [CrossRef]
- Prianto, E.; Kim, M.; Park, J.H.; Bae, J.H.; Kim, J.S. Path planning for multi-arm manipulators using deep reinforcement learning: Soft actor–critic with hindsight experience replay. Sensors 2020, 20, 5911. [Google Scholar] [CrossRef]
- Habib, G.; Qureshi, S. Optimization and acceleration of convolutional neural networks: A survey. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 4244–4268. [Google Scholar] [CrossRef]
- Lebedev, V.; Lempitsky, V. Speeding-up convolutional neural networks: A survey. Bull. Pol. Acad. Sci. Tech. Sci. 2018, 66, 799–811. [Google Scholar]
- Krichen, M. Convolutional neural networks: A survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Tang, P.; Zhang, R.; Liu, D.; Huang, L.; Liu, G.; Deng, T. Local reactive obstacle avoidance approach for high-speed unmanned surface vehicle. Ocean. Eng. 2015, 106, 128–140. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kirk, R.; Zhang, A.; Grefenstette, E.; Rocktäschel, T. A survey of generalisation in deep reinforcement learning. arXiv 2021, arXiv:2111.09794. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Network | Input | Kernel-Size | Fc | Activation Function | Output |
|---|---|---|---|---|---|
| Actor | state-dim | Relu | action-dim | ||
| Critic | state-dim | Relu | status-value |
| Parameters | Value |
|---|---|
| Actor learning rate | |
| Critic learning rate | |
| Discount factor | |
| Batch size | 1500 |
| Time steps | |
| Clip range |
| Comparative Experiment | Average Reward | Convergence Time Steps |
|---|---|---|
| PPO with sensing range | ||
| PPO | ||
| DQN | ||
| SAC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, P.; Yang, C.; Zhou, X.; Wang, W. Path Planning for Unmanned Surface Vehicles with Strong Generalization Ability Based on Improved Proximal Policy Optimization. Sensors 2023, 23, 8864. https://doi.org/10.3390/s23218864
Sun P, Yang C, Zhou X, Wang W. Path Planning for Unmanned Surface Vehicles with Strong Generalization Ability Based on Improved Proximal Policy Optimization. Sensors. 2023; 23(21):8864. https://doi.org/10.3390/s23218864
Chicago/Turabian StyleSun, Pengqi, Chunxi Yang, Xiaojie Zhou, and Wenbo Wang. 2023. "Path Planning for Unmanned Surface Vehicles with Strong Generalization Ability Based on Improved Proximal Policy Optimization" Sensors 23, no. 21: 8864. https://doi.org/10.3390/s23218864
APA StyleSun, P., Yang, C., Zhou, X., & Wang, W. (2023). Path Planning for Unmanned Surface Vehicles with Strong Generalization Ability Based on Improved Proximal Policy Optimization. Sensors, 23(21), 8864. https://doi.org/10.3390/s23218864