

Adaptation of YOLOv7 and YOLOv7_tiny for Soccer-Ball Multi-Detection with DeepSORT for Tracking by Semi-Supervised System
 , and
, and
Abstract
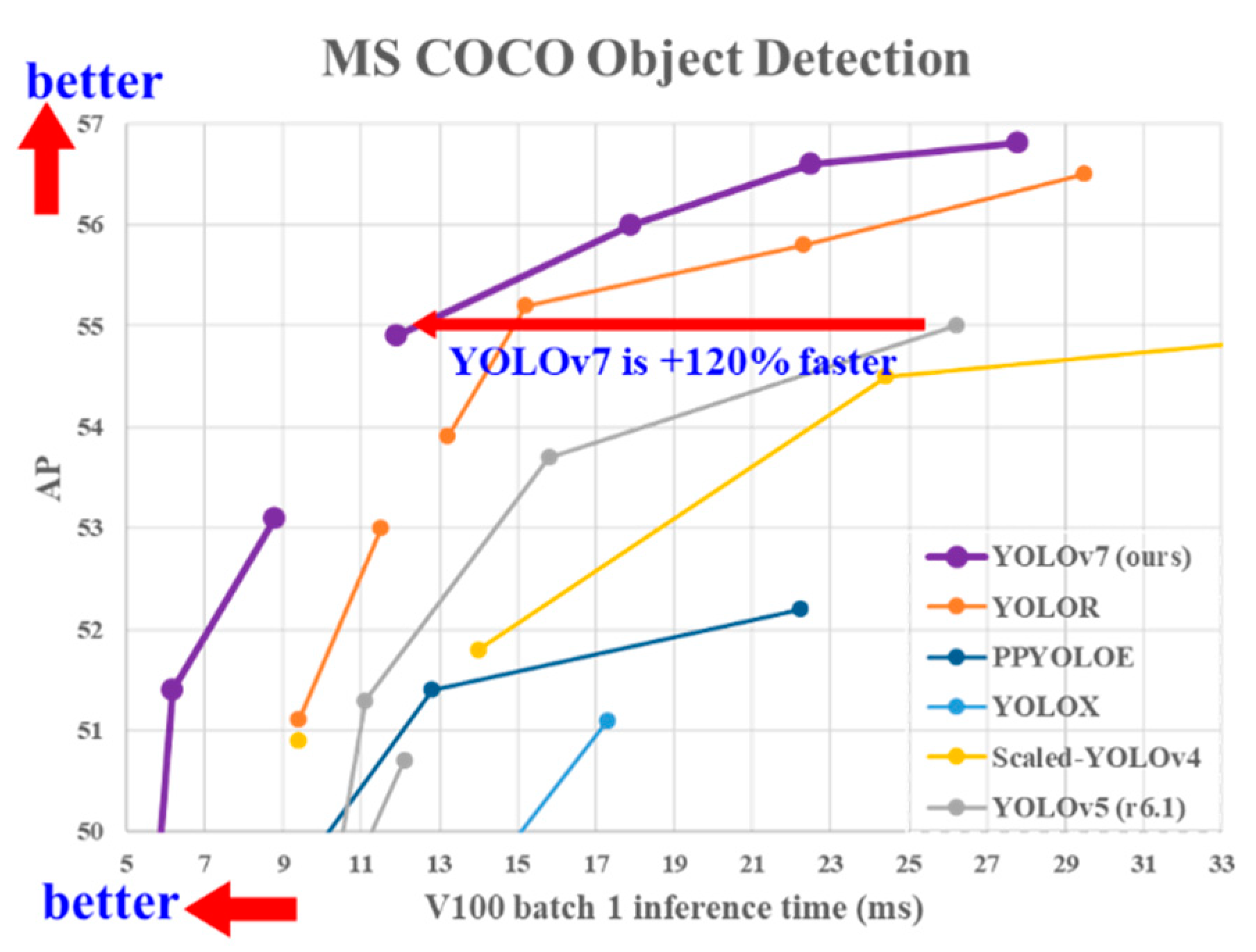
:1. Introduction
Introduction Background and Scope of This Study
2. Materials and Methods
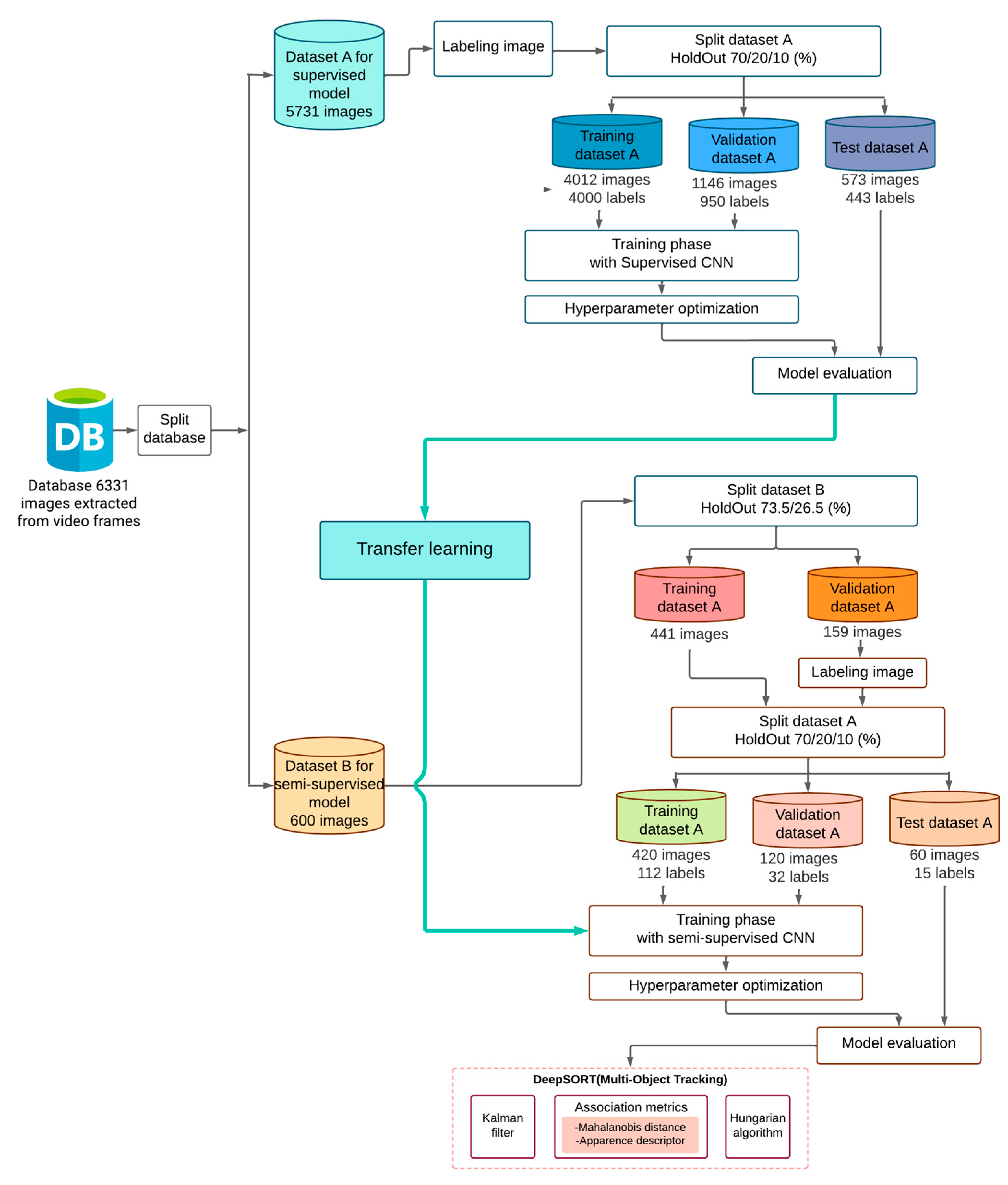
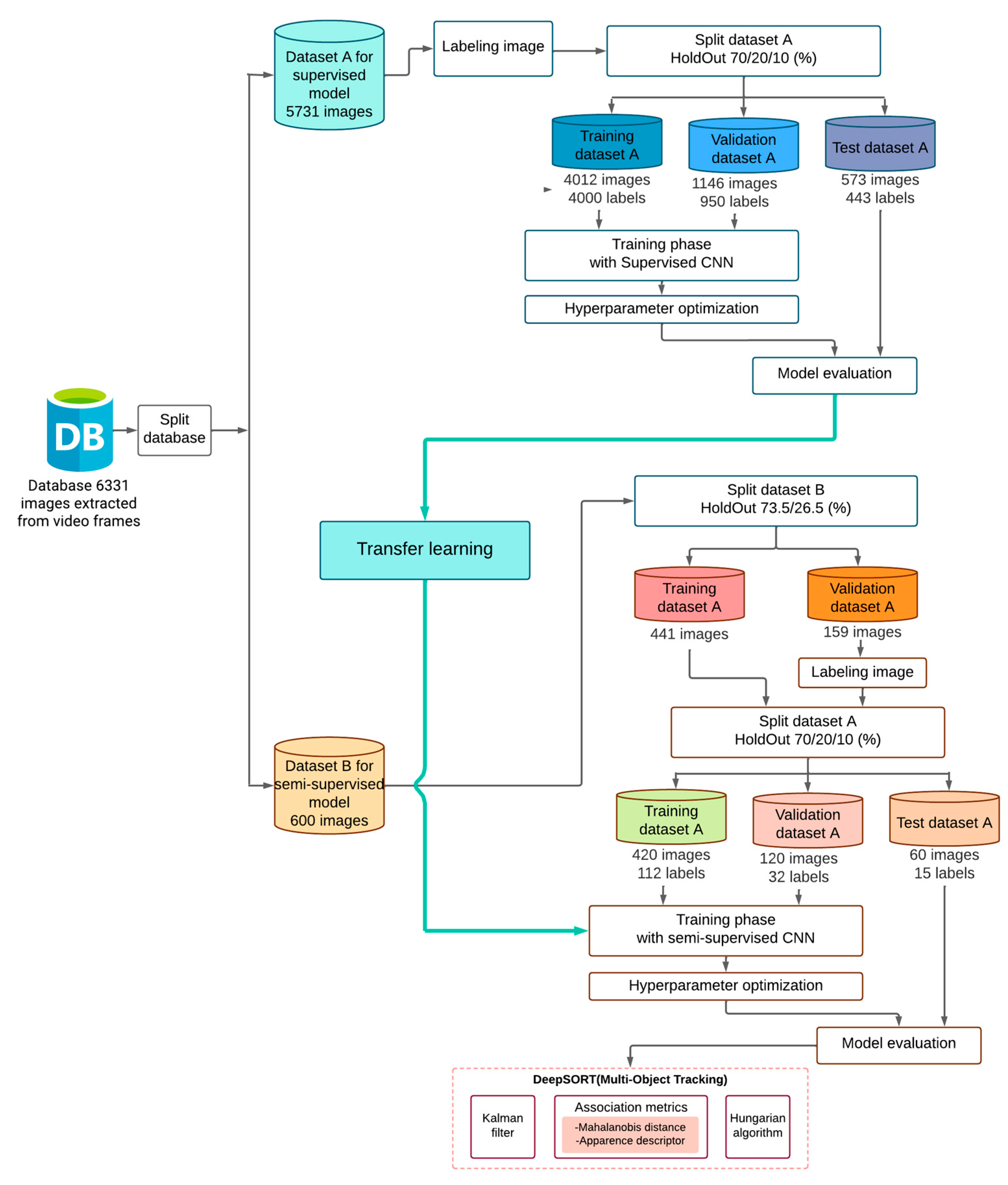
2.1. Dataset
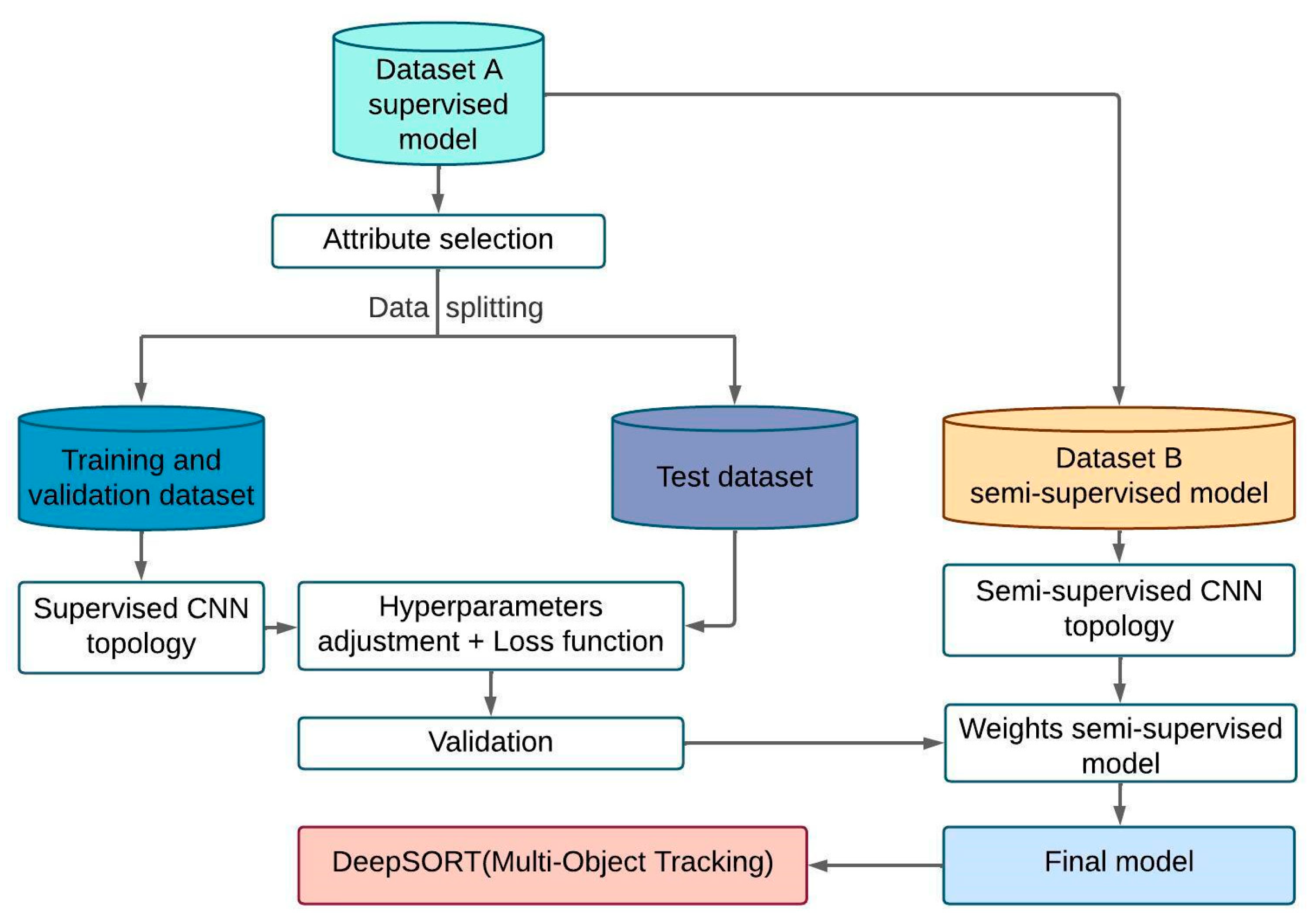
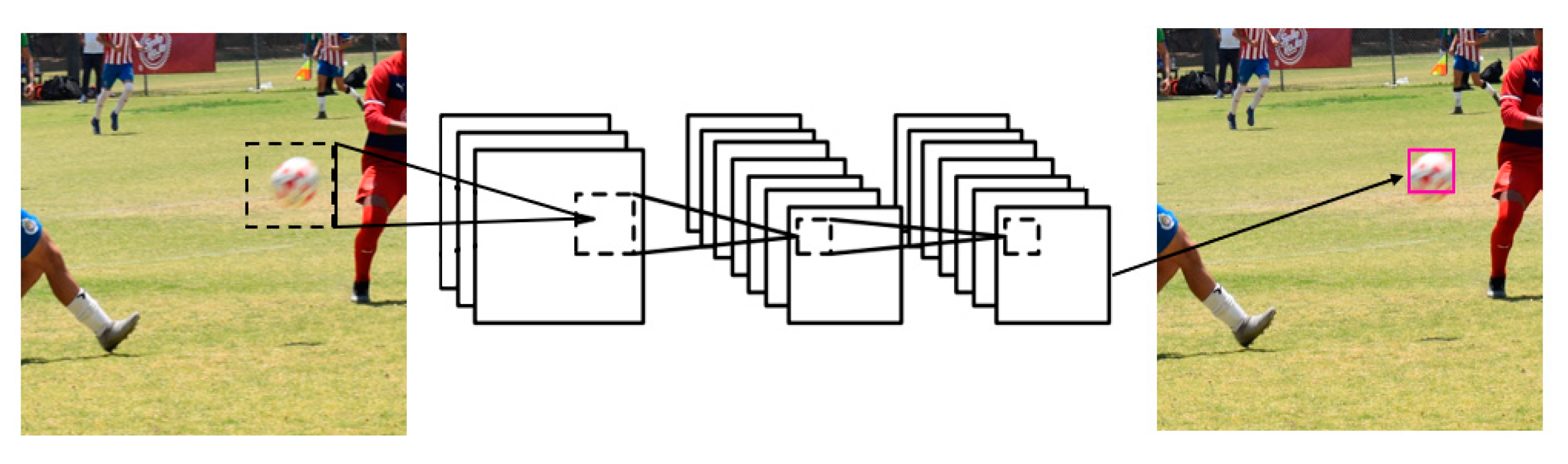
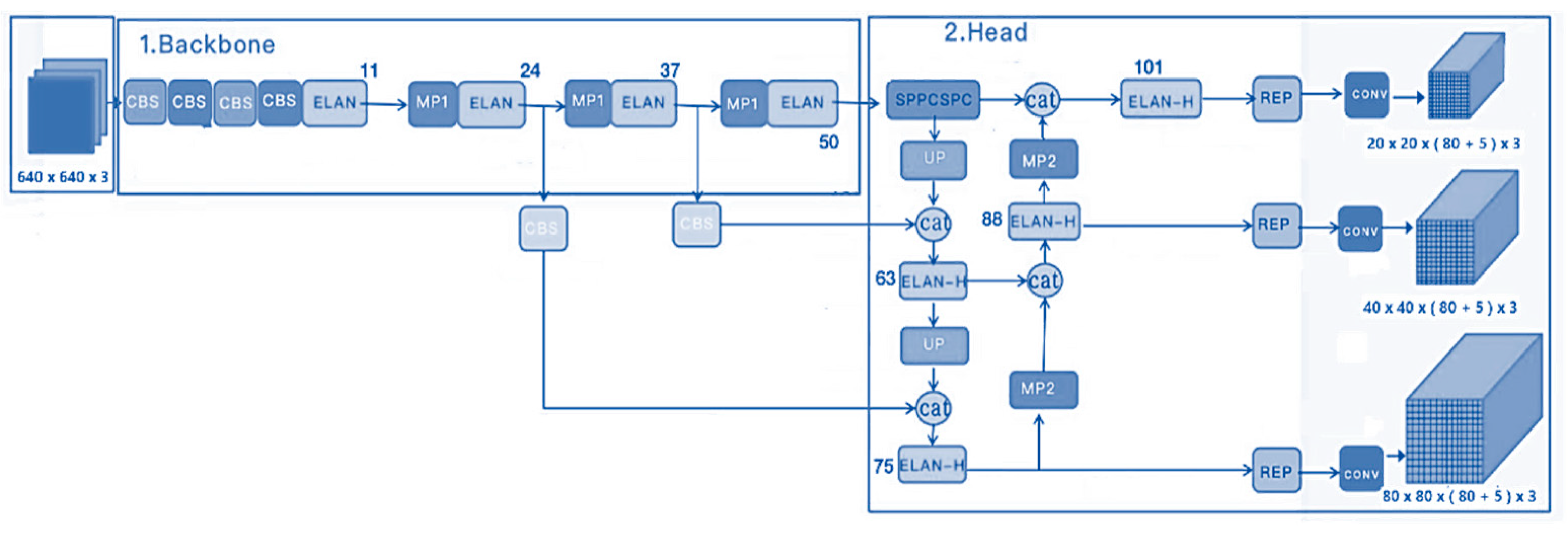
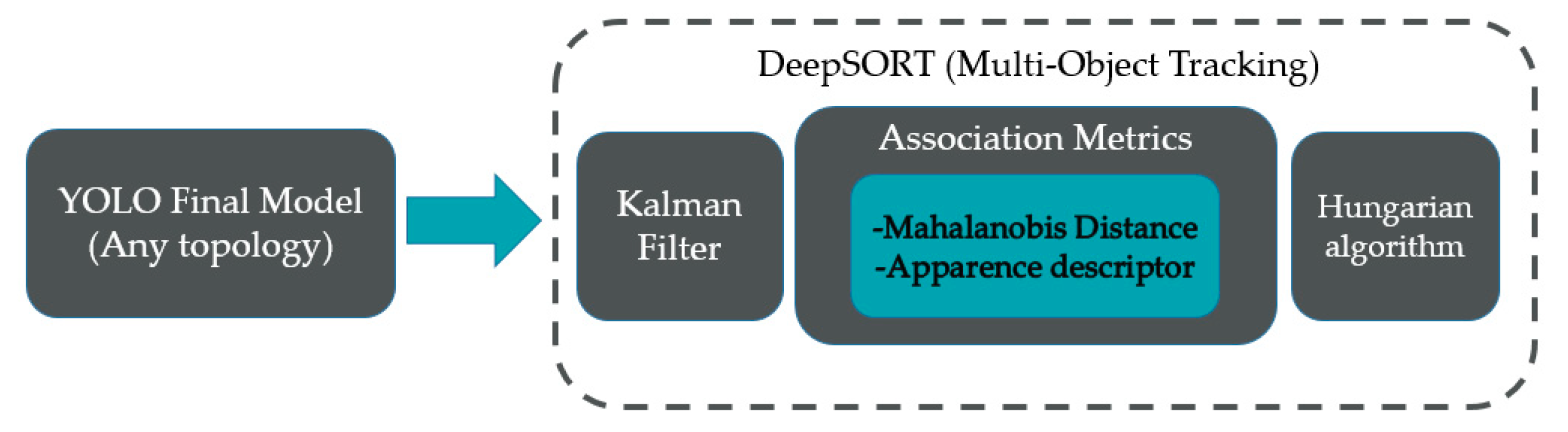
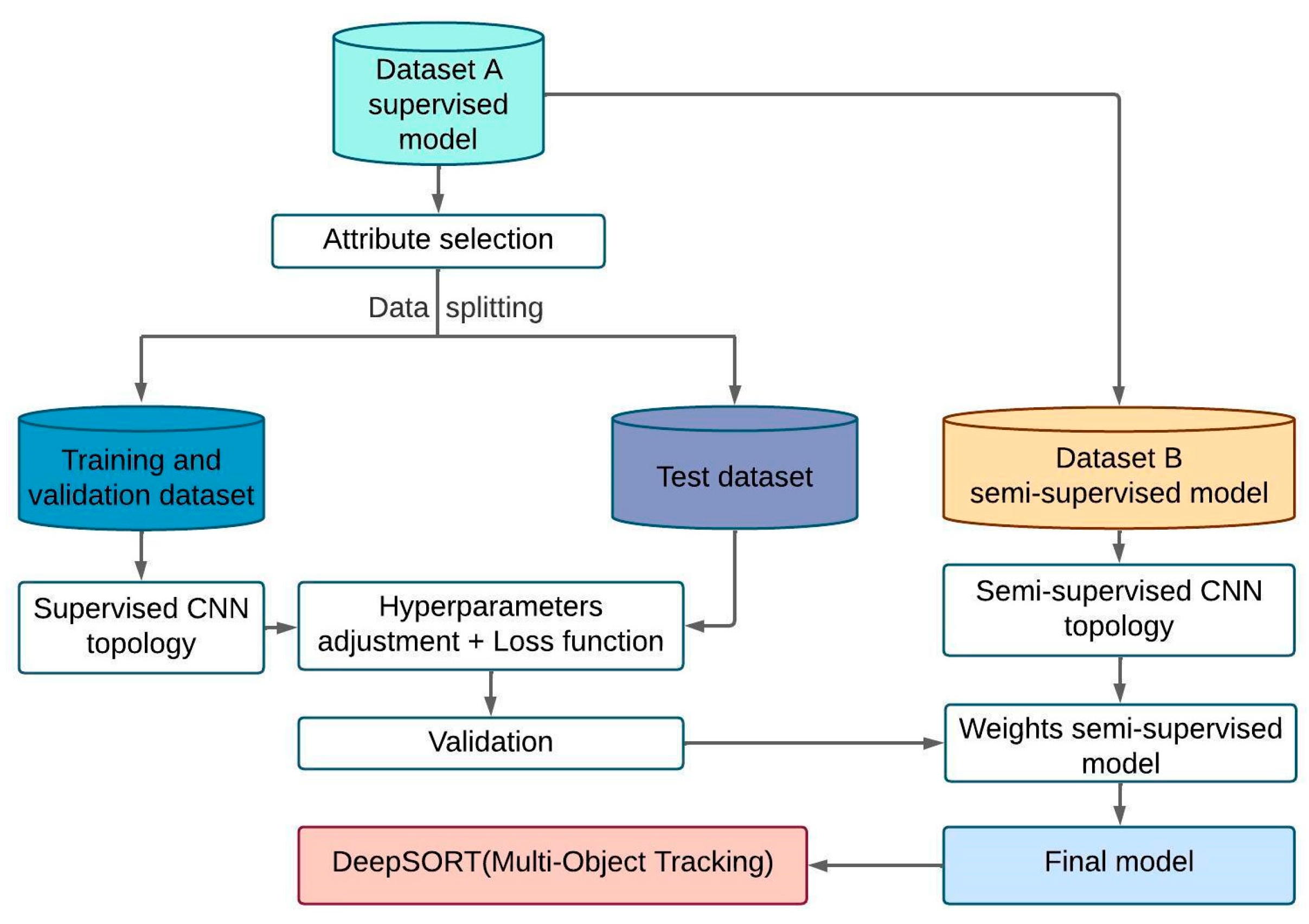
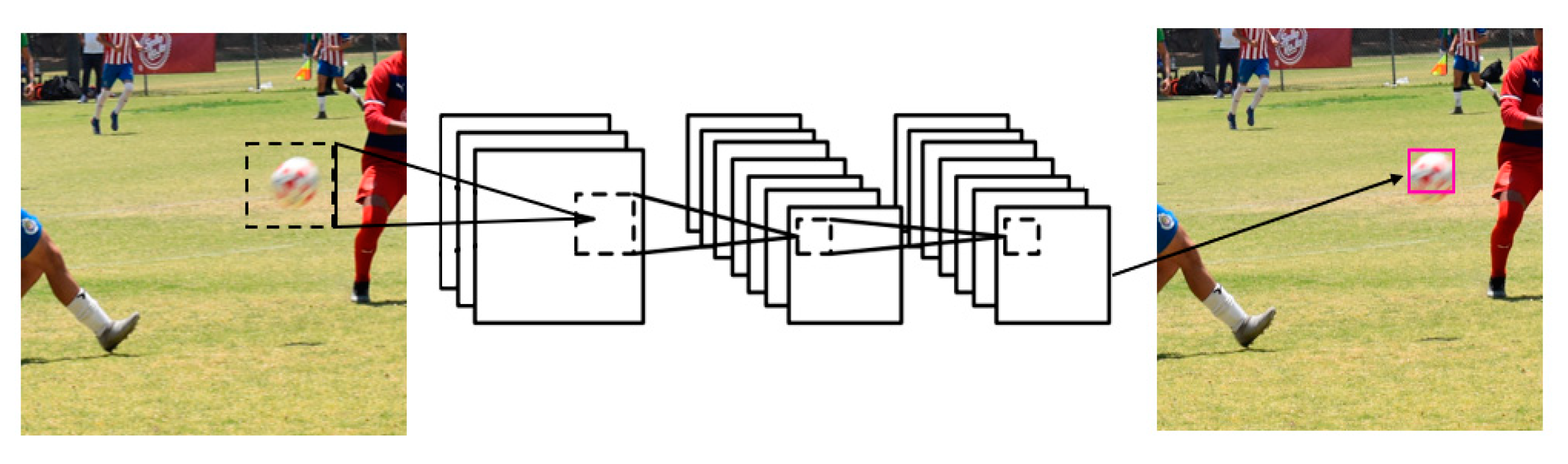
2.2. Proposed Methodology
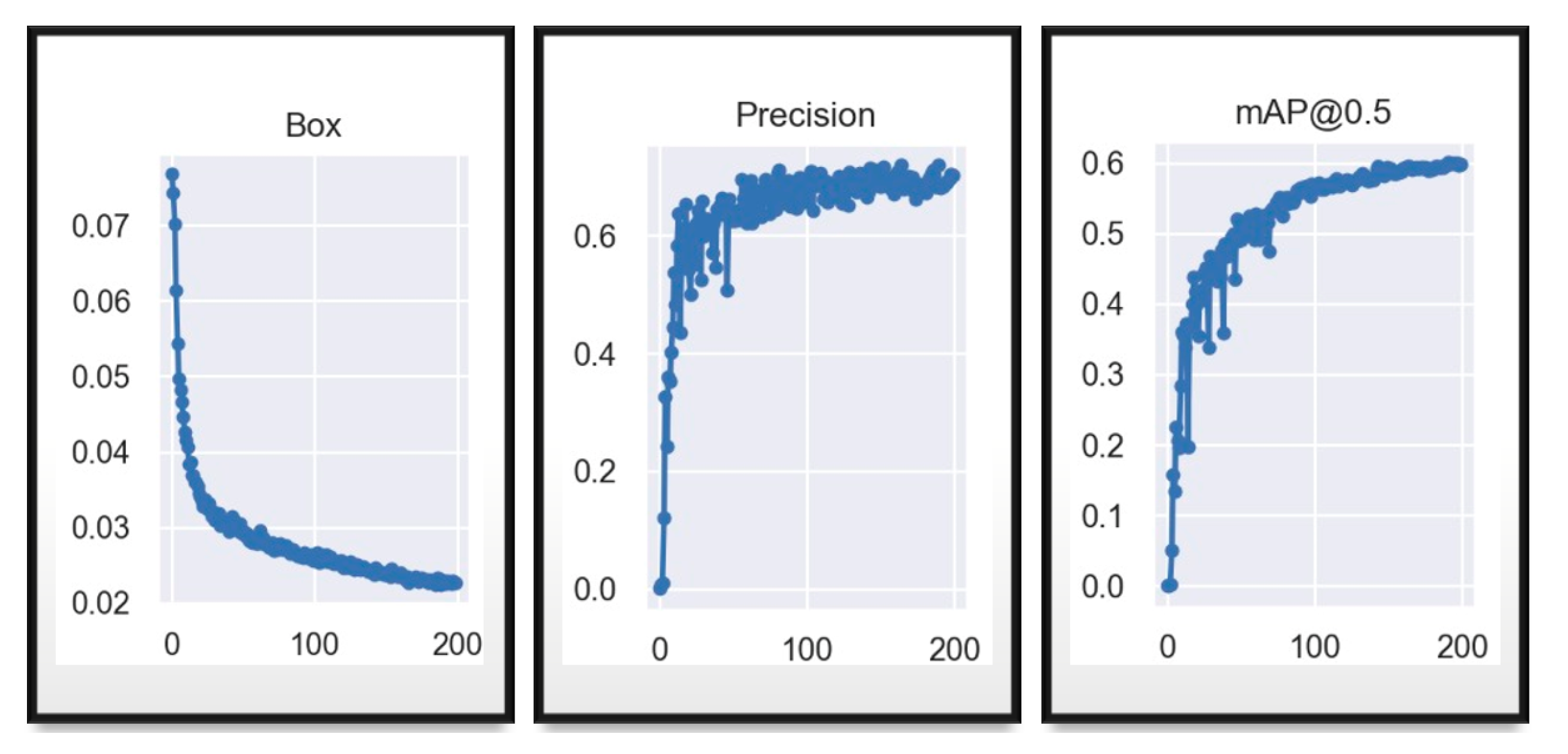
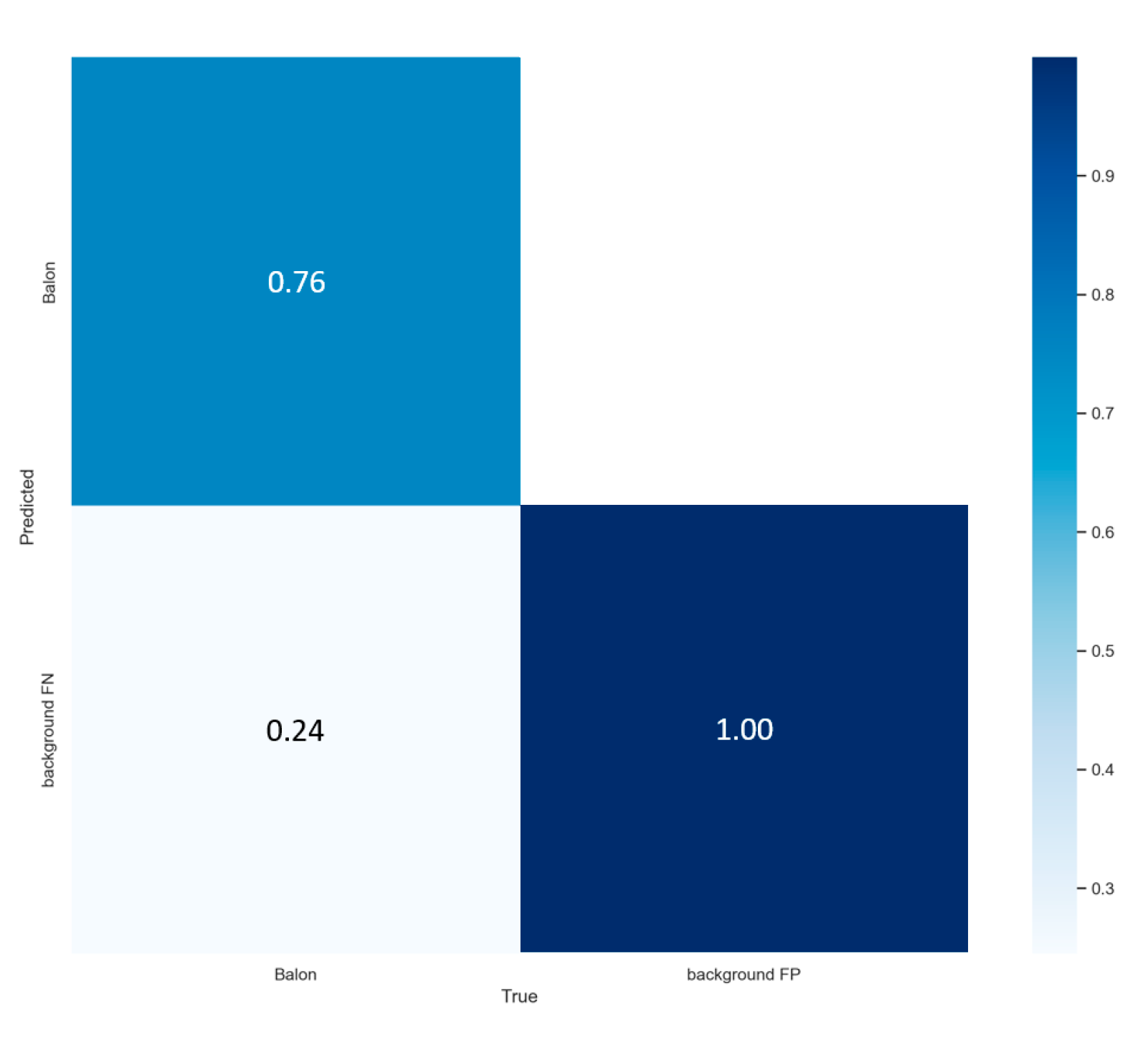
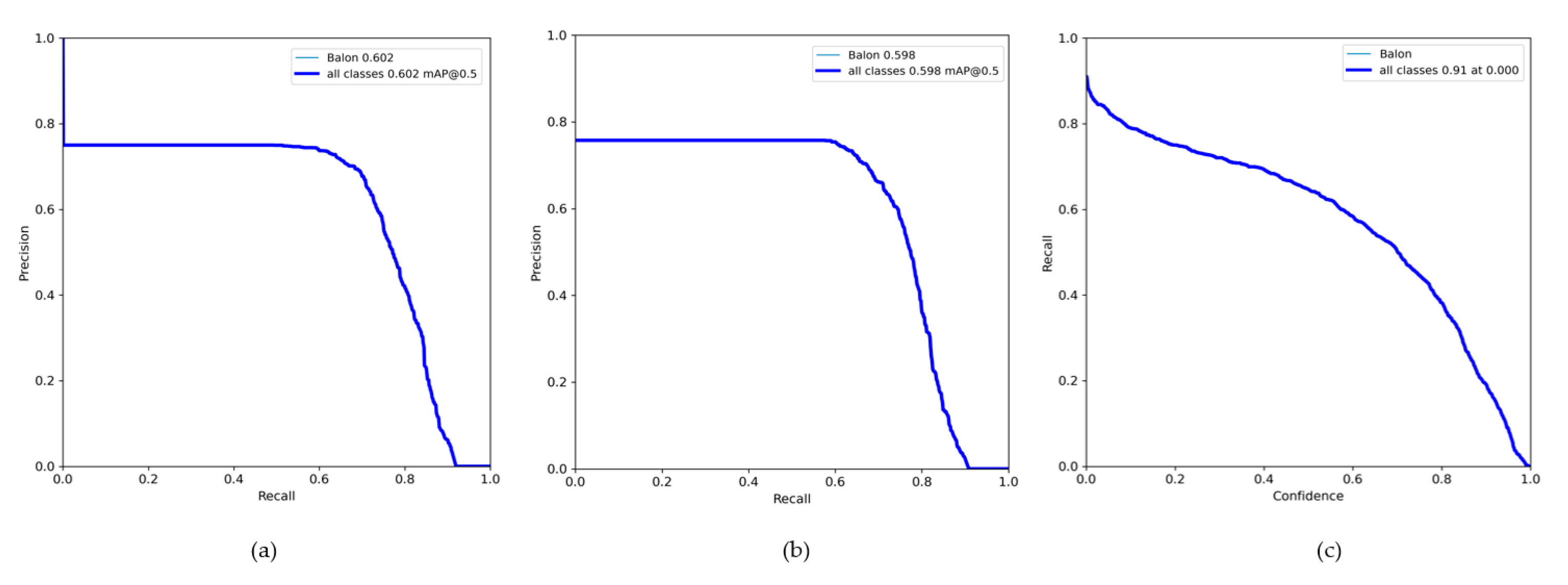
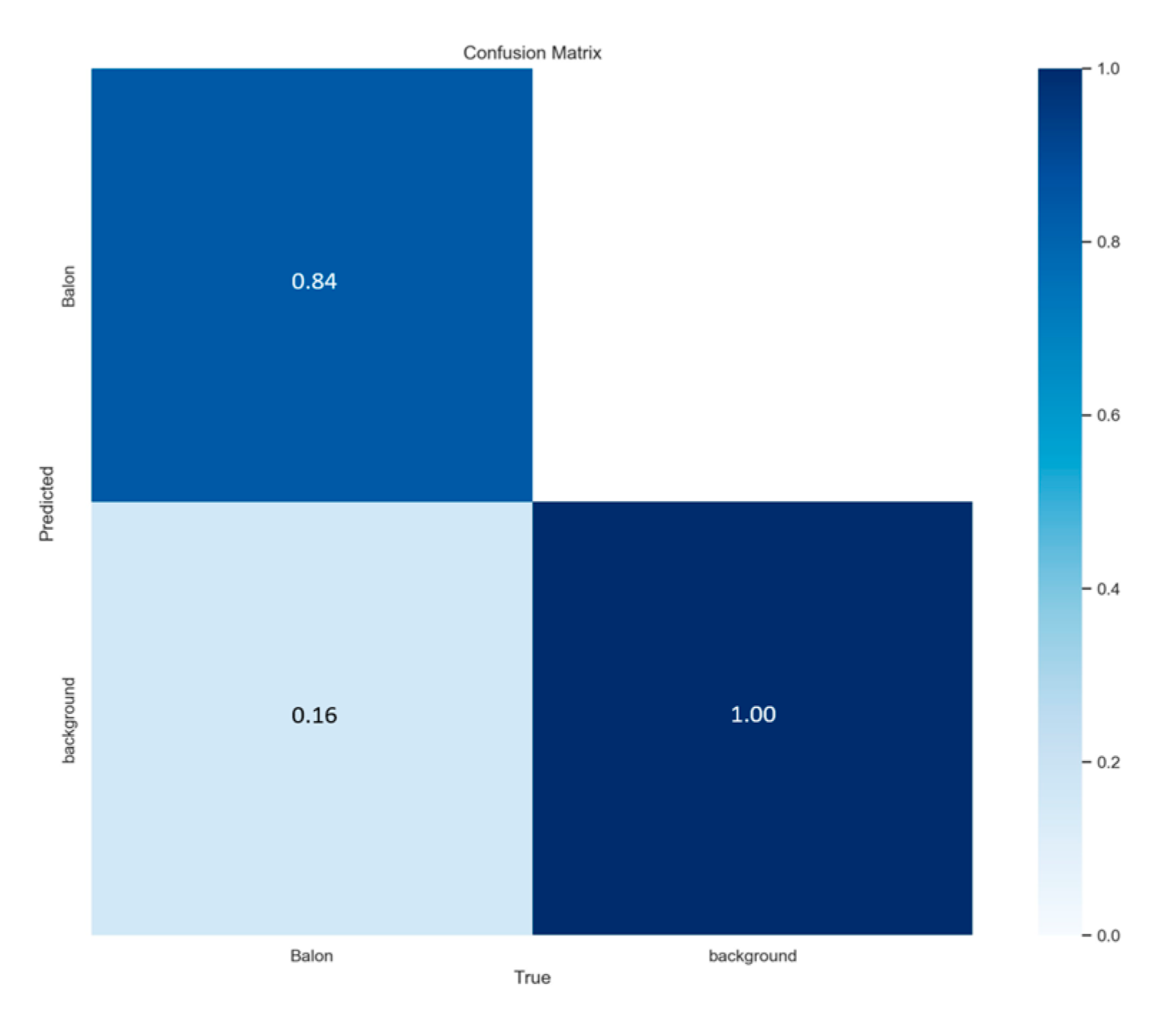
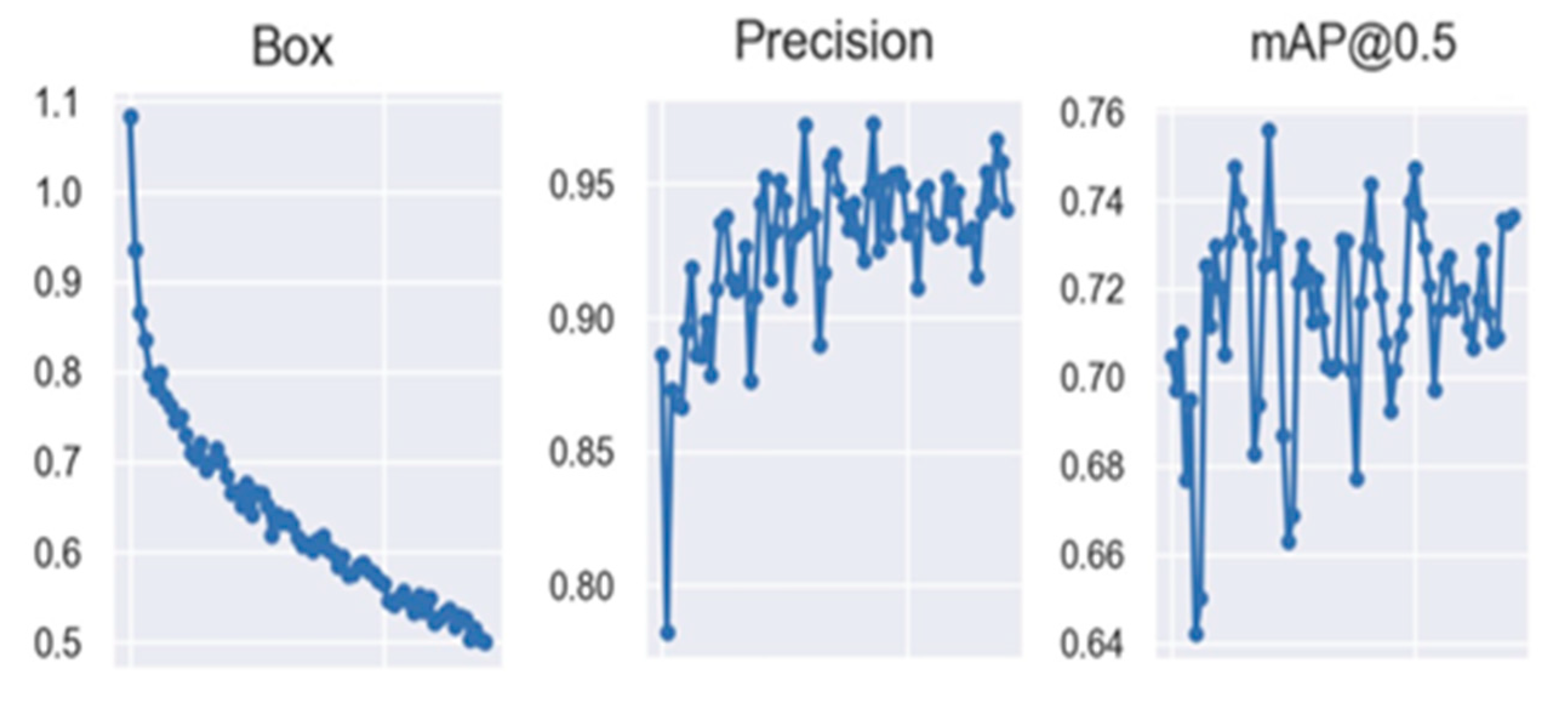
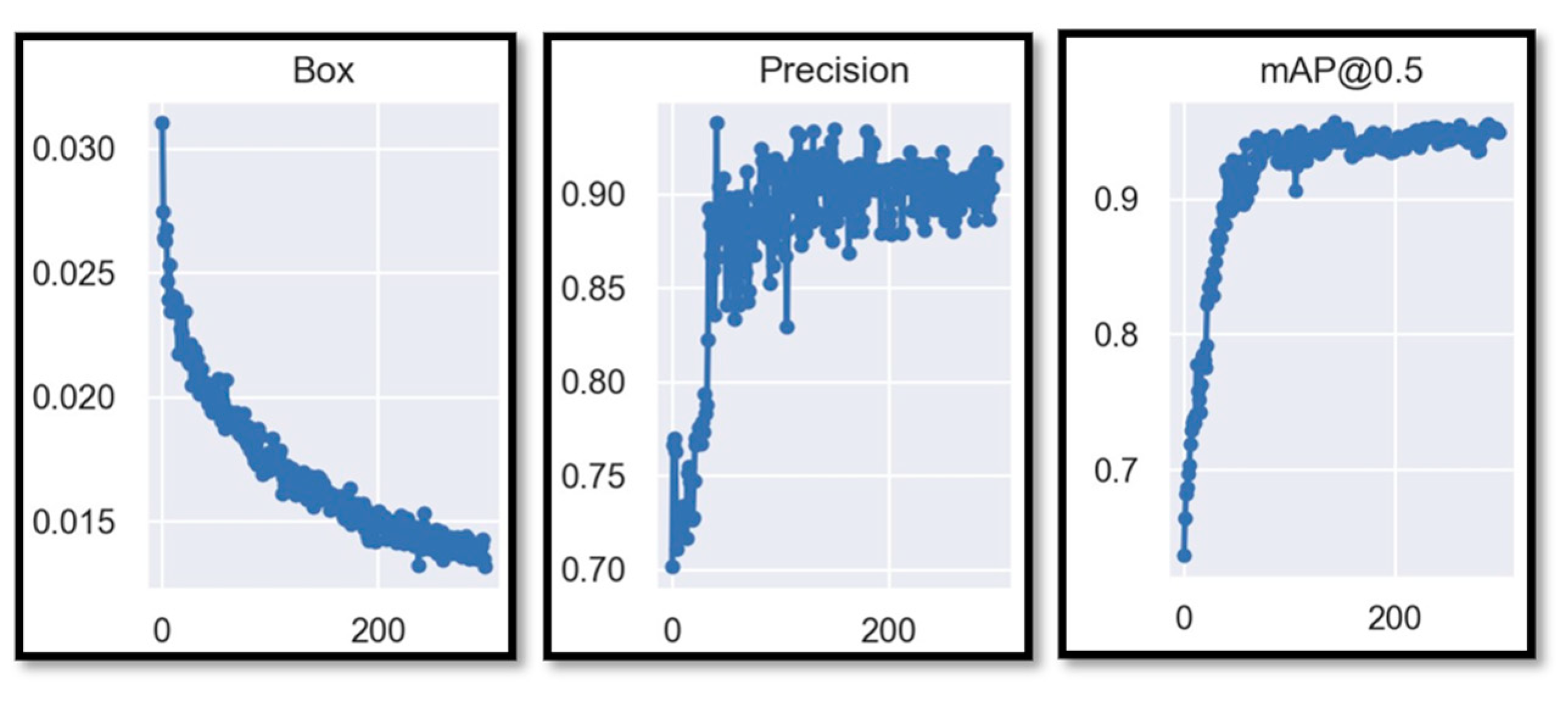
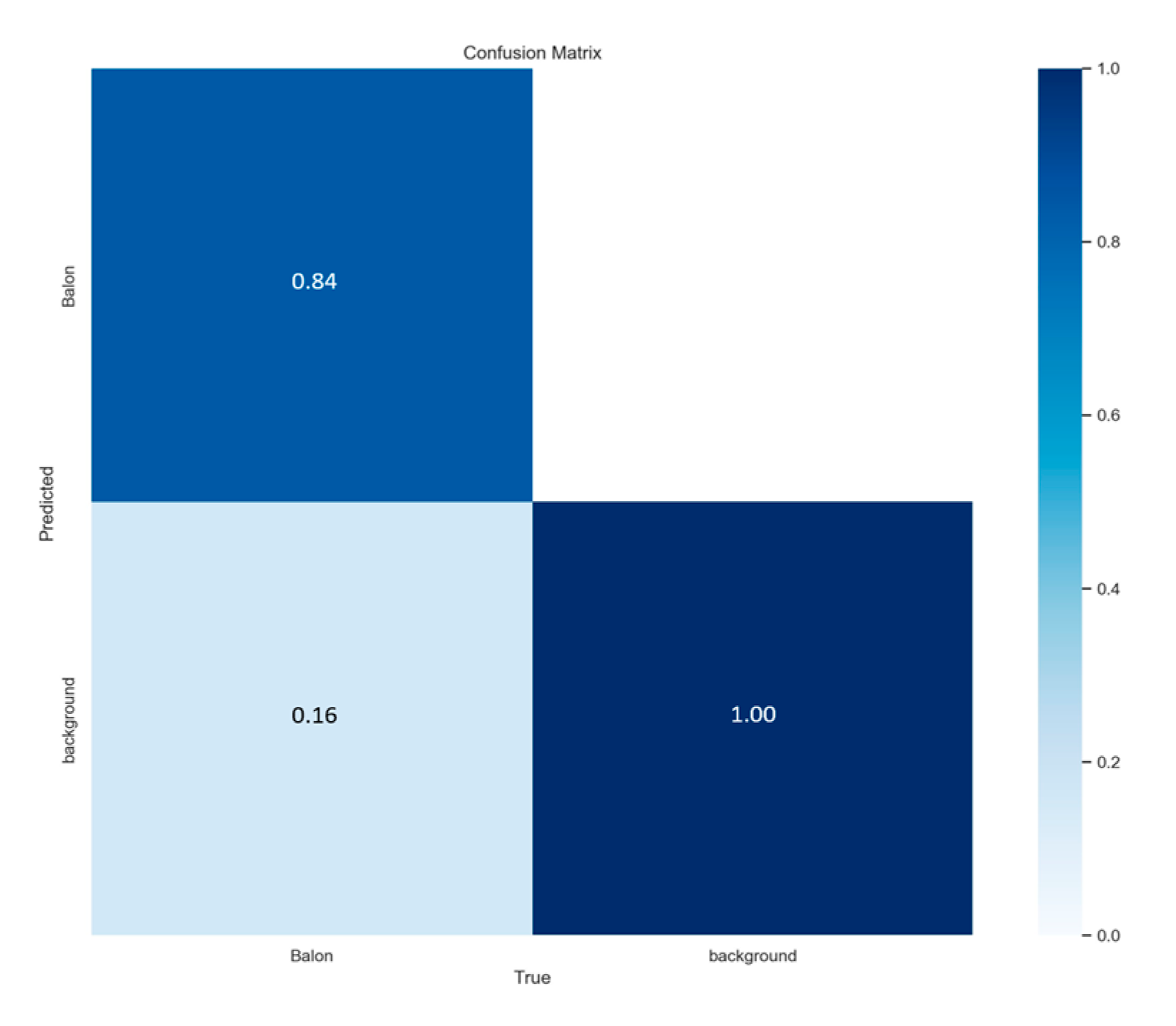
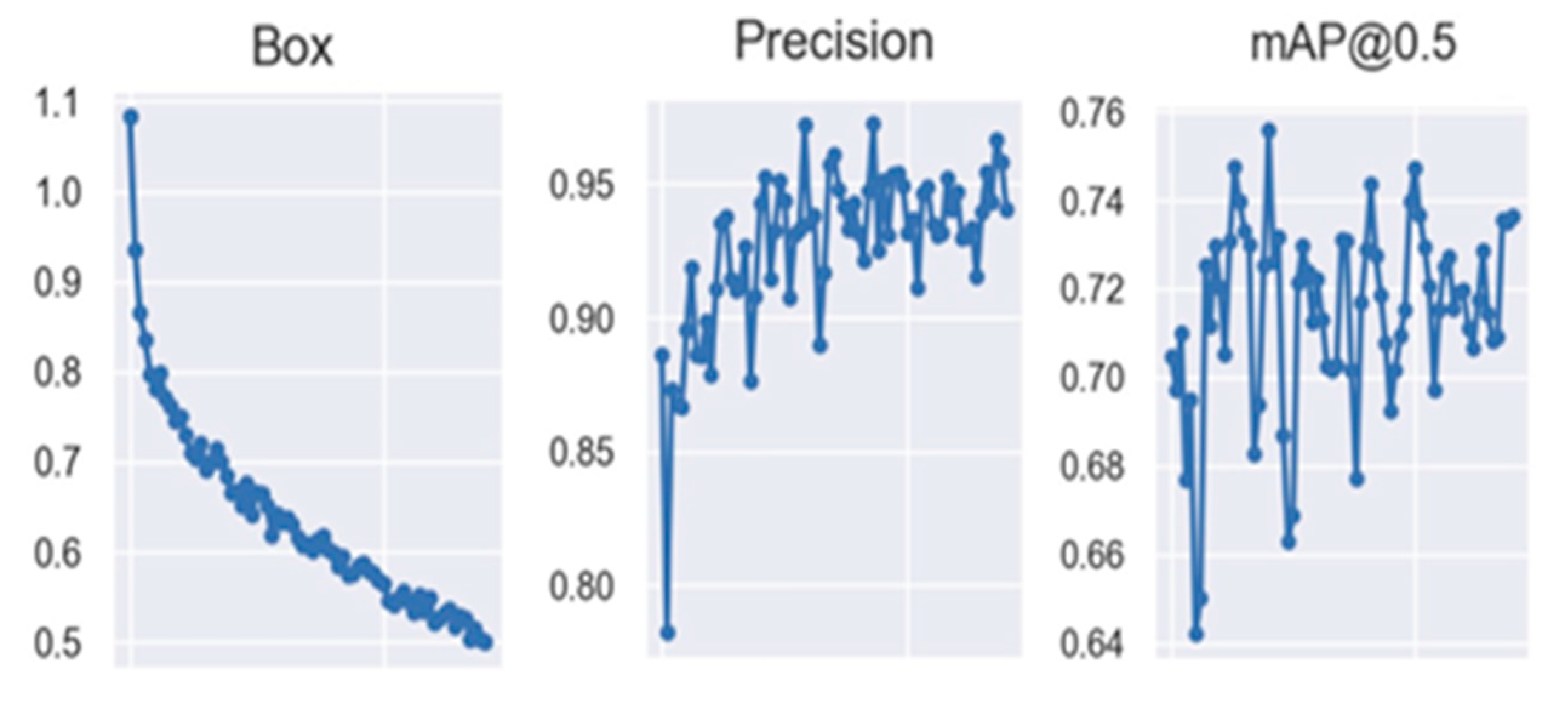
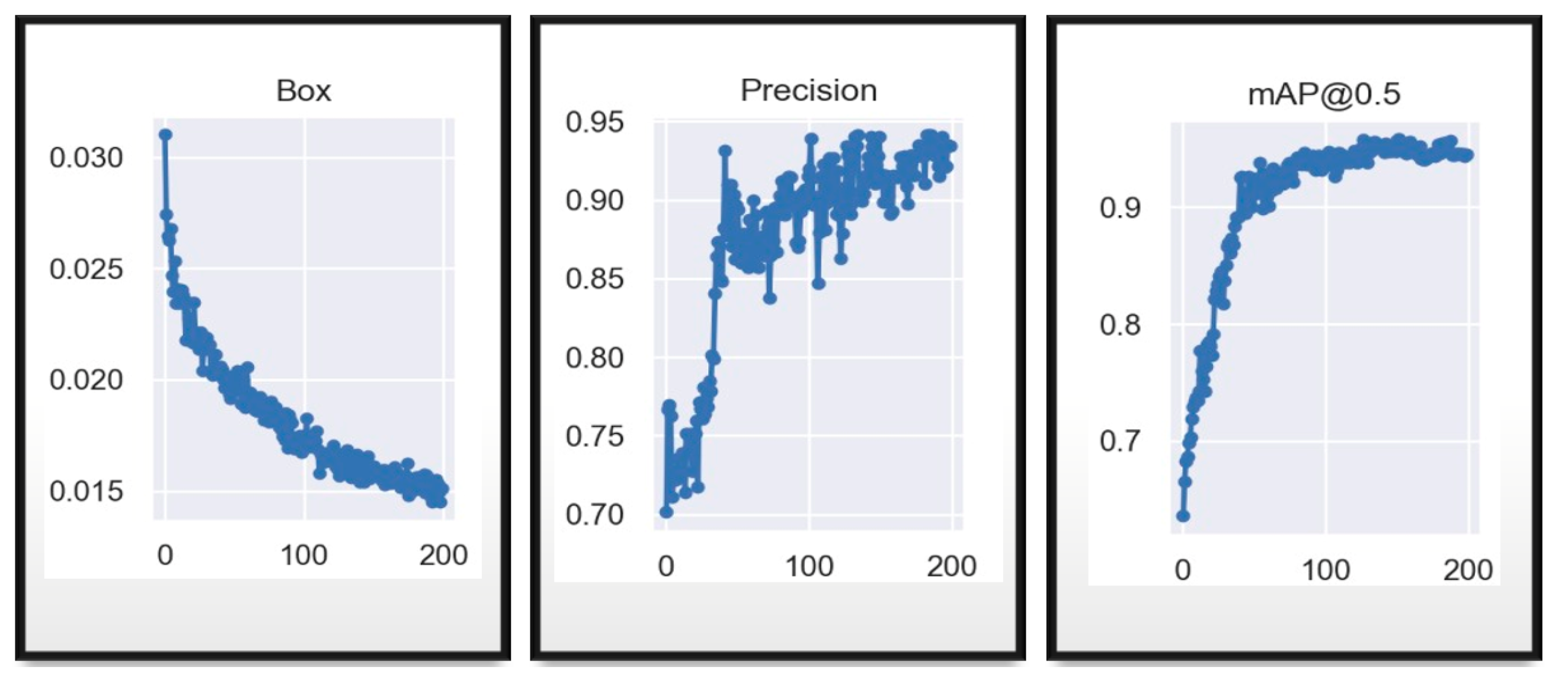
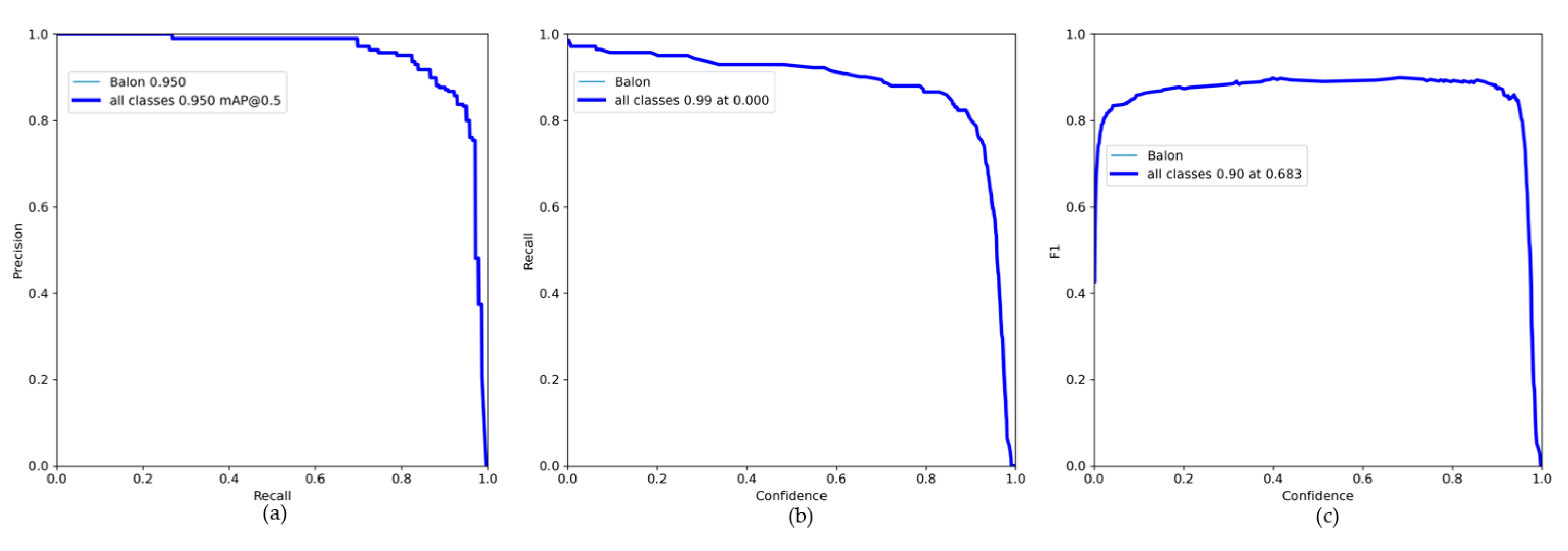
3. Results
4. Discussion
5. Conclusions
6. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nielsen Sports. World Football Report; The Nielsen Company: New York, NY, USA, 2018. [Google Scholar]
- García-Lago Cañas, Á. Impacto de La Liga Profesional de Fútbol En El Conjunto de La Economía Española. 2020. Available online: http://hdl.handle.net/10902/20577 (accessed on 31 March 2023).
- Ali, A. Measuring Soccer Skill Performance: A Review. Scand. J. Med. Sci. Sports 2011, 21, 170–183. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Wright, C.; Carling, C.; Lawlor, C.; Collins, D. Elite Football Player Engagement with Performance Analysis. Int. J. Perform. Anal. Sport 2016, 16, 1007–1032. [Google Scholar] [CrossRef]
- Goes, F.; Meerhoff, L.; Bueno, M.; Rodrigues, D.; Moura, F.; Brink, M.; Elferink-Gemser, M.; Knobbe, A.; Cunha, S.; Torres, R. Unlocking the Potential of Big Data to Support Tactical Performance Analysis in Professional Soccer: A Systematic Review. Eur. J. Sport Sci. 2021, 21, 481–496. [Google Scholar] [CrossRef]
- Stübinger, J.; Mangold, B.; Knoll, J. Machine Learning in Football Betting: Prediction of Match Results Based on Player Characteristics. Appl. Sci. 2019, 10, 46. [Google Scholar] [CrossRef]
- García-Aliaga, A.; Marquina, M.; Coteron, J.; Rodriguez-Gonzalez, A.; Luengo-Sanchez, S. In-Game Behaviour Analysis of Football Players Using Machine Learning Techniques Based on Player Statistics. Int. J. Sports Sci. Coach. 2021, 16, 148–157. [Google Scholar] [CrossRef]
- Knoll, J.; Stübinger, J. Machine-Learning-Based Statistical Arbitrage Football Betting. KI-Künstliche Intell. 2020, 34, 69–80. [Google Scholar] [CrossRef]
- Paolo, D.; Zaffagnini, S.; Pizza, N.; Grassi, A.; Bragonzoni, L. Poor Motor Coordination Elicits Altered Lower Limb Biomechanics in Young Football (Soccer) Players: Implications for Injury Prevention through Wearable Sensors. Sensors 2021, 21, 4371. [Google Scholar] [CrossRef] [PubMed]
- Kondo, Y.; Ishii, S.; Aoyagi, H.; Hossain, T.; Yokokubo, A.; Lopez, G. FootbSense: Soccer Moves Identification Using a Single IMU; Springer: Berlin/Heidelberg, Germany, 2022; pp. 115–131. [Google Scholar]
- Yu, C.; Huang, T.-Y.; Ma, H.-P. Motion Analysis of Football Kick Based on an IMU Sensor. Sensors 2022, 22, 6244. [Google Scholar] [CrossRef] [PubMed]
- Wadsworth, N.; Charnock, L.; Russell, J.; Littlewood, M. Use of Video-Analysis Feedback within a Six-Month Coach Education Program at a Professional Football Club. J. Sport Psychol. Action 2020, 11, 73–91. [Google Scholar] [CrossRef]
- Kinnerk, P.; Kearney, P.E.; Harvey, S.; Lyons, M. High Performance Team Sport Coaches’ Perspectives of Their Use of In-Session Core Coaching Practices to Stimulate Player Learning; Taylor & Francis: Oxfordshire, UK, 2023; pp. 1–14. [Google Scholar] [CrossRef]
- Modric, T.; Versic, S.; Sekulic, D.; Liposek, S. Analysis of the Association between Running Performance and Game Performance Indicators in Professional Soccer Players. Int. J. Environ. Res. Public Health 2019, 16, 4032. [Google Scholar] [CrossRef] [PubMed]
- Andersen, L.W.; Francis, J.W.; Bateman, M. Danish Association Football Coaches’ Perception of Performance Analysis; Taylor & Francis: Oxfordshire, UK, 2021. [Google Scholar] [CrossRef]
- Brümmer, K. Coordination in Sports Teams–Ethnographic Insights into Practices of Video Analysis in Football. Eur. J. Sport Soc. 2019, 16, 27–43. [Google Scholar] [CrossRef]
- He, X. Application of Deep Learning in Video Target Tracking of Soccer Players. Soft Comput. 2022, 26, 10971–10979. [Google Scholar] [CrossRef]
- Wang, T.; Li, T. Deep Learning-Based Football Player Detection in Videos. Comput. Intell. Neurosci. 2022, 2022, 3540642. [Google Scholar] [CrossRef] [PubMed]
- Ayala Beltrán, H.F.; Duarte Valero, E.A. Rol Del Video-Análisis En La Enseñanza Del Giro En Los Porteros de Fútbol de 9 a 11 Años; Universidad de Ciencias Aplicadas y Ambientales: Bogotá, Colombia, 2023; Available online: https://repository.udca.edu.co/handle/11158/5035 (accessed on 31 May 2023).
- Akan, S.; Varlı, S. Use of Deep Learning in Soccer Videos Analysis: Survey. Multimed. Syst. 2023, 29, 897–915. [Google Scholar] [CrossRef]
- D’Orazio, T.; Guaragnella, C.; Leo, M.; Distante, A. A New Algorithm for Ball Recognition Using Circle Hough Transform and Neural Classifier. Pattern Recognit. 2004, 37, 393–408. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- González, S. Estudio Comparativo de Modelos de Clasificación Automática de Señales de Tráfico. 2020. Available online: https://academica-e.unavarra.es/xmlui/handle/2454/37479 (accessed on 31 May 2023).
- Rozada Raneros, S. Estudio de la Arquitectura YOLO para la Detección de Objetos Mediante Deep Learning. Master’s Thesis, Universidad de Valladolid, Valladolid, Spain, 2021. [Google Scholar]
- Thomas, G.; Gade, R.; Moeslund, T.B.; Carr, P.; Hilton, A. Computer Vision for Sports: Current Applications and Research Topics. Comput. Vis. Image Underst. 2017, 159, 3–18. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting Objects as Paired Keypoints. In Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany; Springer: Cham, Switzerland, 2018; Volume 11218, pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects Points. arXiv 2019, arXiv:1904.07850. [Google Scholar] [CrossRef]
- Moreira. Aplicación de un Modelo de Reconocimiento de Objetos Utilizando YOLO (You Only Look Once). 2021. Available online: https://repositorio.upse.edu.ec/handle/46000/5755 (accessed on 18 August 2023).
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Chandan, G.; Jain, A.; Jain, H. Real Time Object Detection and Tracking Using Deep Learning and OpenCV. In Proceedings of the 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11–12 July 2018; pp. 1305–1308. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- Feng, Q.; Xu, X.; Wang, Z. Deep Learning-Based Small Object Detection: A Survey. Math. Biosci. Eng. 2023, 20, 6551–6590. [Google Scholar] [CrossRef]
- Pham, M.-T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-Stage Detector of Small Objects under Various Backgrounds in Remote Sensing Images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A Survey and Performance Evaluation of Deep Learning Methods for Small Object Detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small Object Detection Based on Deep Learning for Remote Sensing: A Comprehensive Review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Yang, Y.; Wang, Z.; Wang, G. Efficient Golf Ball Detection and Tracking Based on Convolutional Neural Networks and Kalman Filter. arXiv 2020, arXiv:2012.09393. [Google Scholar]
- Keča, D.; Kunović, I.; Matić, J.; Sovic Krzic, A. Ball Detection Using Deep Learning Implemented on an Educational Robot Based on Raspberry Pi. Sensors 2023, 23, 4071. [Google Scholar] [CrossRef]
- Kukleva, A.; Khan, M.A.; Farazi, H.; Behnke, S. Utilizing Temporal Information in Deep Convolutional Network for Efficient Soccer Ball Detection and Tracking; Springer: Berlin/Heidelberg, Germany, 2019; pp. 112–125. [Google Scholar]
- O’Keeffe, S.; Villing, R. A Benchmark Data Set and Evaluation of Deep Learning Architectures for Ball Detection in the RoboCup SPL; Springer: Berlin/Heidelberg, Germany, 2018; pp. 398–409. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-The-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Kamble, P.R.; Keskar, A.G.; Bhurchandi, K.M. A Deep Learning Ball Tracking System in Soccer Videos. Opto-Electron. Rev. 2019, 27, 58–69. [Google Scholar] [CrossRef]
- Komorowski, J.; Kurzejamski, G.; Sarwas, G. Deepball: Deep Neural-Network Ball Detector. arXiv 2019, arXiv:1902.07304. [Google Scholar]
- Hiemann, A.; Kautz, T.; Zottmann, T.; Hlawitschka, M. Enhancement of Speed and Accuracy Trade-off for Sports Ball Detection in Videos—Finding Fast Moving, Small Objects in Real Time. Sensors 2021, 21, 3214. [Google Scholar] [CrossRef]
- Cao, L.; Zheng, X.; Fang, L. The Semantic Segmentation of Standing Tree Images Based on the Yolo v7 Deep Learning Algorithm. Electronics 2023, 12, 929. [Google Scholar] [CrossRef]
- Broström, M. Real-Time Multi-Camera Multi-Object Tracker Using Yolov5 and Strongsort with Osnet. 2022. Available online: github.com/zenjieli/YOLOv5StrongSORT (accessed on 31 May 2023).
- Martínez Martínez, A. Estudio Práctico de Técnicas AI Para Reconocimiento de Objetos. Cartagena/Murcia/España. 2020. Available online: http://hdl.handle.net/10317/8864 (accessed on 31 May 2023).
- Reno, V.; Mosca, N.; Marani, R.; Nitti, M.; D’Orazio, T.; Stella, E. Convolutional Neural Networks Based Ball Detection in Tennis Games. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1758–1764. [Google Scholar]
- Komorowski, J.; Kurzejamski, G.; Sarwas, G. Footandball: Integrated Player and Ball Detector. arXiv 2019, arXiv:1912.05445. [Google Scholar]
- Prodan, C.-V.; Scurtu, I.-L. Aerodynamics Study of the Soccer Ball. J. Ind. Des. Eng. Graph. 2022, 17, 5–10. [Google Scholar]
- Santos-García, D.J.; Valdivielso, F.N. Análisis de La Velocidad Del Balón En El Golpeo En Jugadores de Fútbol Sala En Función Del Sistema de Medición, La Intención En La Precisión Del Tiro, Y Su Relación Con Otras Acciones Explosivas. Eur. J. Hum. Mov. 2006, 15. [Google Scholar]
- Burić, M.; Pobar, M.; Ivašić-Kos, M. Adapting YOLO Network for Ball and Player Detection. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods, Prague, Czech Republic, 19–21 February 2019; Volume 1, pp. 845–851. [Google Scholar]
- Thulasya, N.B.; Hashmi, M.F. YOLOv3-SORT: Detection and Tracking Player/Ball in Soccer Sport. J. Electron. Imaging 2023, 32, 011003. [Google Scholar] [CrossRef]
- Kelly, A.; Wilson, M.R.; Jackson, D.T.; Williams, C.A. Technical Testing and Match Analysis Statistics as Part of the Talent Development Process in an English Football Academy. Int. J. Perform. Anal. Sport 2020, 20, 1035–1051. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Addressed Problem | Dataset | Model | Precision (%) | Observations |
|---|---|---|---|---|---|
| D’Orazio et al. [22] (2004) | Ball recognition soccer on real images | Image sequences taken by a camera connected to an S-VHS video:
| Adaptation of the Atherton algorithm | 96.46 | Includes evaluation with ball occlusion obtaining 92% accuracy |
| Zhang et al. [39] (2022) | Golf ball detection and tracking with CNN and Kalman filter | 2169 high resolution golf images from online tournaments of which 17,436 golf ball labels are generated. |
| Tracking with Faster R-CNN: 81.3 YOLOv3 tiny: 82.1 | Addresses small object detection issues |
| Kamble et al. [44] (2019) | Deep learning approach for 2D ball detection and tracking (DLBT) in soccer videos | Own dataset 1500 images for each class: ball, player, and background | CNN architecture designed by modifying the Visual Geometry Group (VGG) at University of Oxford, named VGG-M | 93.25 | Soccer videos are used |
| Komorowski [45] (2019) | Soccer ball detection in long take videos | ISSIA-CNR Soccer Dataset (20,000 frames)
|
| 87 | The hypercolumn concept is implemented with convolutional feature maps |
| Hiemann [46] (2021) | Volleyball ball detection | 12,555 images
| YOLOv3 | 73.2 | Time inference metrics are presented in frames per second (FPS). |
| Design Parameter | Values |
|---|---|
| Convolutional Layers | |
| Kernel Size | 1 × 1, 3 × 3 or 5 × 5 |
| Kernel dilatation | 1 or 2 |
| Stride | 4 |
| Output channels | 512 |
| Pooling | Max Pooling |
| Activation | Mish, Sigmoid or ReLU |
| Batch normalization | No |
| Full Connected Layers | |
| Layers outputs | 16 |
| Hyperparameter | Adjust Value |
|---|---|
| Initial Learning Rate | 0.01 |
| Final Learning Rate | 0.1 |
| Momentum | 0.937 |
| Weight_decay | 0.0005 |
| Warmup_epoch | 3.0 |
| Warmup_bias_learning rate | 0.1 |
| Box Loss Factor | 0.05 |
| Classification Loss Factor | 0.3 |
| Classification Loss Weight | 1.0 |
| Objectness Loss Factor | 0.7 |
| Intersection Over UnionThreshold | 0.2 |
| Anchor Threshold | 4.0 |
| Focal Loss Gamma | 1.0 |
| Mosaic Scale | 0.5 |
| Mosaic Augmentation | 1.0 |
| Name | Patch Size/Stride | Output Size |
|---|---|---|
| Conv1 | 3 × 3/1 | 32 × 128 × 64 |
| Conv2 | 3 × 3/1 | 32 × 128 × 64 |
| Max Pool 3 | 3 × 3/2 | 32 × 64 × 32 |
| Residual 4 | 3 × 3/1 | 32 × 64 × 32 |
| Residual 5 | 3 × 3/1 | 32 × 64 × 32 |
| Residual 6 | 3 × 3/2 | 64 × 32 × 16 |
| Residual 7 | 3 × 3/1 | 64 × 32 × 16 |
| Residual 8 | 3 × 3/2 | 128 × 16 × 8 |
| Residual 9 | 3 × 3/1 | 128 × 16 × 8 |
| Dense 10 | 128 | |
| Batch | 128 | |
| l2 normalization | 128 |
| Model | Range Precision | Way to Train CNN |
|---|---|---|
| YOLOv7_tiny | 70–75% | Transfer Learning |
| YOLOv7 | 70–77% | Transfer Learning |
| YOLOv7_tiny Focal Loss | 50–60% | Transfer Learning |
| YOLOv7 Focal Loss | 65–70% | Transfer Learning |
| YOLOv7_tiny semi-supervised with Focal Loss | 90–94.5% | Inherited weights |
| YOLOv7 semi-supervised with Focal Loss | 90–95% | Inherited weights |
| Model | Model Size | Backbone | Loss Function | mAP | APtest |
|---|---|---|---|---|---|
| YOLOv7_tiny | 640 | E-ELAN | SigmoidBin | 74.88 | 38.7% |
| YOLOv7 | 640 | E-ELAN | SigmoidBin | 76.15 | 51.4% |
| YOLOv7_tiny | 640 | RCSP-ELAN | Focal Loss | 53.7 | 43.1% |
| YOLOv7 | 640 | RCSP-ELAN | Focal Loss | 60.2 | 56.0% |
| YOLOv7_tiny_semisupervised | 640 | RCSP-ELAN | Focal Loss | 94.5 | 59.2% |
| YOLOv7_semisupervised | 640 | RCSP-ELAN | Focal Loss | 95 | 67.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vicente-Martínez, J.A.; Márquez-Olivera, M.; García-Aliaga, A.; Hernández-Herrera, V. Adaptation of YOLOv7 and YOLOv7_tiny for Soccer-Ball Multi-Detection with DeepSORT for Tracking by Semi-Supervised System. Sensors 2023, 23, 8693. https://doi.org/10.3390/s23218693
Vicente-Martínez JA, Márquez-Olivera M, García-Aliaga A, Hernández-Herrera V. Adaptation of YOLOv7 and YOLOv7_tiny for Soccer-Ball Multi-Detection with DeepSORT for Tracking by Semi-Supervised System. Sensors. 2023; 23(21):8693. https://doi.org/10.3390/s23218693
Chicago/Turabian StyleVicente-Martínez, Jorge Armando, Moisés Márquez-Olivera, Abraham García-Aliaga, and Viridiana Hernández-Herrera. 2023. "Adaptation of YOLOv7 and YOLOv7_tiny for Soccer-Ball Multi-Detection with DeepSORT for Tracking by Semi-Supervised System" Sensors 23, no. 21: 8693. https://doi.org/10.3390/s23218693
APA StyleVicente-Martínez, J. A., Márquez-Olivera, M., García-Aliaga, A., & Hernández-Herrera, V. (2023). Adaptation of YOLOv7 and YOLOv7_tiny for Soccer-Ball Multi-Detection with DeepSORT for Tracking by Semi-Supervised System. Sensors, 23(21), 8693. https://doi.org/10.3390/s23218693