Abstract
Expression recognition is a very important direction for computers to understand human emotions and human-computer interaction. However, for 3D data such as video sequences, the complex structure of traditional convolutional neural networks, which stretch the input 3D data into vectors, not only leads to a dimensional explosion, but also fails to retain structural information in 3D space, simultaneously leading to an increase in computational cost and a lower accuracy rate of expression recognition. This paper proposes a video sequence face expression recognition method based on Squeeze-and-Excitation and 3DPCA Network (SE-3DPCANet). The introduction of a 3DPCA algorithm in the convolution layer directly constructs tensor convolution kernels to extract the dynamic expression features of video sequences from the spatial and temporal dimensions, without weighting the convolution kernels of adjacent frames by shared weights. Squeeze-and-Excitation Network is introduced in the feature encoding layer, to automatically learn the weights of local channel features in the tensor features, thus increasing the representation capability of the model and further improving recognition accuracy. The proposed method is validated on three video face expression datasets. Comparisons were made with other common expression recognition methods, achieving higher recognition rates while significantly reducing the time required for training.
1. Introduction
With the rapid development of the internet, the visual information that can be seen in everyday life is taking on an increasingly rich form. Compared to traditional 2D static images, 3D image sequences contain more information, especially temporal information, such as behavioral actions. Facial information is one of the most common sources of information in everyday life, and the visual information it conveys is of great importance [1,2]. In recent years, facial expression recognition has gradually emerged in the field of face recognition and can be applied to psychological research, emotional computing, intelligent interaction, and the medical industry, playing an important role in maintaining social stability and promoting the development of society [3,4,5,6,7,8,9,10,11]. The difference between expression recognition, which is the study of individual differences between different faces, and face recognition, which interferes with information when expressions change; expression recognition is the study of the commonality of facial expressions, and the features extracted reflect the differences between faces in different expression patterns, and the differences in individual faces are interfering information. As a human face moves, there is a dynamic process of change, and its time-domain information has a critical impact on expression recognition.
Traditional research methods can be divided into two categories: feature extraction based on static images and feature extraction of video sequences. Among these, the static images-based feature extraction methods can be subdivided into holistic and local methods, as the static images of facial expressions visualize the changes in facial shape and texture produced by the movement of the muscles of the face as expressions occur. As a whole, this apparent deformation of the facial organs can have an impact on the global information of the face image, hence the emergence of facial expression recognition algorithms that consider expression features from a holistic perspective, such as principal component analysis (PCA), independent component analysis (ICA) and linear discriminant analysis (LDA) [12,13,14,15,16,17,18,19,20]. Yet, there are not only overall variations in facial expressions, but also local variations. The information contained in the local deformation of facial muscles, such as texture and folds, helps to determine the properties of expressions accurately. The classical methods of the local method are the Gabor wavelet [21,22,23,24,25,26] and the Local Binary Pattern (LBP) [27,28,29,30,31,32]. The literature [33] proposes a lightweight face classification method that uses polynomial and smith fuzzy sets set to obtain a new composite fuzzy space to extract different features of images and improve the recognition ability. Research [34] proposes a new face recognition architecture based on the fuzzy discrete wavelet transform (DWT) and two novel local graph descriptors. The proposed new graph-based image descriptors are used to extract salient features for face recognition, and the DWT-fuzzy set-based domain (FWD) method, created by DWT and fuzzy set theory, improves face recognition. As moving images reflect the process by which facial expressions occur, the expression characteristics of moving images are mainly characterized by the continuous deformation of the face and the movement of muscles in different areas of the face. Current dynamic image-based feature extraction methods are mainly divided into the optical flow, model, and geometric methods [35,36,37,38,39,40]. As a human face moves, there is a dynamic process of change, and its time-domain information has a critical impact on expression recognition. Therefore, the facial expression recognition method oriented to video image sequences can better extract the essential change features of expressions and further improve the accuracy of facial expression recognition. With the rise of deep learning, traditional manually designed feature extraction methods have been replaced by deep neural networks. The structure of such networks is often based on the extraction of expression features through several convolutional layers, followed by a non-linear transformation through a fully connected layer, and a Softmax transformation to obtain the probability distribution of samples belonging to each classification. This end-to-end training approach eliminates the tedium of manual feature extraction and, in practice, achieves better recognition results than traditional methods. For 3D data such as video sequences, most models built by convolutional neural networks cannot be processed efficiently. Stretching the input 3D data directly into vectors would not only lead to a dimensional explosion, but also fail to preserve the structural information of the 3D space. The three-dimensional convolutional neural network (3D-CNN) proposed in the literature [41] expands the dimensionality to three-dimensional space, using the same convolutional kernel to perform convolutional operations on three consecutive frames, which can effectively extract spatial and temporal feature information in videos. In the literature [42,43,44], a Long Short-Term Memory network (LSTM) was introduced and cascaded with convolutional neural networks such as CNN, ResNet, and VGG-16, respectively. LSTM has significant advantages in modeling temporal relationships and therefore achieved high recognition accuracy. However, all of these algorithms rely on large training samples and have large parameter computations.
In the field of image recognition, especially in the field based on deep learning, the training speed of the model and the recognition accuracy of the model are usually difficult to be achieve at the same time. Deep learning models are often complex in structure and the number of samples available for training has proliferated with digitalization; once new samples or labels are added, the entire model has to be trained all over again. Such low timeliness often does not meet the actual demand. Therefore, how to reduce the time required for model training while ensuring model accuracy as much as possible is a widespread concern among scholars in the field of deep learning today. This paper proposes a video sequence face expression recognition method based on Squeeze-and-Excitation and 3DPCA Network (SE-3DPCANet). 3DPCANet is a generalization of the lightweight convolutional neural network PCANet in 3D space. Thanks to the better feature extraction capability and lower computational complexity of PCA, 3DPCANet has a faster training speed compared to general deep networks and does not require a large number of training samples. 3DPCANet takes expression image sequences as input samples and introduces the 3DPCA algorithm in the convolution layer to directly construct tensor convolution kernels without weighting the convolution kernels of adjacent frames by shared weights, to extract dynamic expression features of video sequences from spatial and temporal dimensions. Then, to address the redundancy of local channel features, a Squeeze-and-Excitation Network (SENet) is introduced in the feature encoding layer, to automatically learn the weights of local channel features in the tensor features, thus increasing the representation capability of the model and further improving the recognition accuracy.
The main contributions are as follows:
(1) Since the complex information and great data volume of the facial expression data of video sequences and the extremely high training time cost using deep neural networks, this paper proposes use of the lightweight convolutional neural network 3DPCANet for feature extraction of the facial expression data of video sequences. Benefiting from the excellent feature extraction capability, low computational complexity, and simple mathematical mechanism of 3DPCANet, the facial expression features extracted by 3DPCANet greatly reduce the redundancy of the original information while retaining the key information.
(2) In response to the redundancy of local channels, this paper introduces SENet in the feature encoding layer to automatically learn the weights of local channel features in tensor features. The proposed method increases the representation capability of the model and, in combination with 3DPCANet, greatly reduces the time cost of model training while ensuring the accuracy of the model as much as possible. The proposed method is validated on three datasets, compared with a variety of mainstream deep learning models.
The rest of the paper is organized as follows. Section 2 explains tensor representation and arithmetic methods, and a short introduction to 3DPCA and SENet. A video sequence face expression recognition method based on SE-3DPCANet is proposed for expression classification in Section 3. We use three video face expression datasets in Section 4 to validate the superiority of the proposed method for face expression video sequences.
2. Preliminaries
2.1. Tensor Representations and Operations
This section begins with an introduction to the representations of tensors and the associated operations. Assume that the Nth-order tensor can be expressed as .
2.1.1. n-Mode Product
Define the n-mode product of the tensor and the matrix as , then its elements can be expressed as:
where denotes the Nth order index of the tensor. If , the n-mode product of a multidimensional tensor and a two-dimensional matrix can be dimensionally reduced, i.e., a higher-order tensor is mapped to a lower-order tensor space. In particular, the projection of the tensor to the real numbers can be achieved when the matrix is replaced by the vector .
2.1.2. Inner Product
The inner product of two Nth-order tensors of the same size can be expressed as:
Accordingly, its Frobenius norm is defined as:
2.1.3. Outer Product
Define the outer product of an Nth-order tensor and an Mth-order tensor as:
That is, the order of the tensor W is the sum of the orders of the two tensors.
2.1.4. Kronecker Product
The Kronecker product is the operation defined on the two matrices , i.e.,:
2.2. Three-Dimensional Principal Component Analysis (3DPCA)
Wang et al. [45] established a fast 3DPCA algorithm, which effectively solved the problem encountered when the feature information contained in each image is calculated separately in lung CT image lesion detection, which results in the correlation between individual scan layers will be ignored, thus affecting the detection accuracy. Inspired by 3DPCA, to extract the dynamic features of video face expression sequences and solve the problem of missing dynamic information representation of 2D images, the expression information in time and space dimensions can be represented as a third-order tensor, and the 3DPCA algorithm can be used for feature extraction, and the specific algorithm process is defined as follows:
Assuming a three-dimensional sequence , where denotes the spatial dimension of each video image frame and denotes the temporal dimension of the sequence. The average tensor of this 3D sequence is first calculated:
Define the 3D covariance matrix of the sample:
Equation (7) can then be transformed into a singular value decomposition (SVD) problem on the . However, the general SVD cannot effectively handle three-dimensional tensors. Therefore, the Higher Order tensor Singular Value Decomposition (HOSVD) is used to compute the singular value decomposition of the tensor A in three-dimensional space [46].
Firstly, the third-order tensor is defined to be expendable, represented as three two-dimensional matrices, , corresponding to the three directions in the 3D video sequence, as shown in Figure 1.
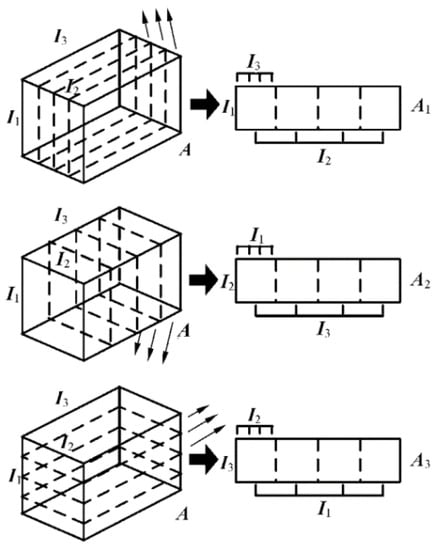
Figure 1.
Two-dimensional matrix expansion of a three-dimensional tensor. (The thinner arrow on the left side of the figure represents the direction of tensor expansion).
As can be seen from Figure 1, slicing and tiling as two-dimensional matrix along the direction of yields ; slicing and tiling as two-dimensional matrix along the direction of yields ; similarly, slicing and tiling as a two-dimensional matrix along the direction of yields .
Then, the two-dimensional matrix singular value decomposition of , respectively, can yield the corresponding unitary matrix , and all of these are orthogonal. Then, according to the Tucker decomposition of the tensor, the third-order tensor A can be decomposed into the following product form:
where is called the kernel tensor. The matrixed solution procedure for the third order SVD can be obtained from Equation (8) and the higher order tensor expansion is as follows:
where is the n-th expansion of the kernel tensor and the symbol denotes the Kronecker product. If any two sub-tensor of are orthogonal to each other, then the eigenvalues , is the corresponding eigenvector. Therefore, we can obtain the main eigenvalues by calculating the cumulative contribution, and then ignore the non-principal components to obtain the new eigen third-order tensor , thus extracting the main feature space of the 3D video image sequence.
2.3. Squeeze-and-Excitation Net (SENet)
The attention mechanism can be seen as a generic pooling method for adaptively assigning weights to inputs and has begun to be used extensively in convolutional neural networks in recent years, providing a huge performance boost in many tasks. Convolution operations can fuse spatial and channel features, and most research has focused on optimizing models for spatial features. The channel attention mechanism, on the other hand, addresses inter-channel relationships and proposes a new Squeeze-and-Excitation Net (SENet). Each feature of the convolution output can be seen as a channel, and the core of this lies in the fact that a constant weight can be predicted for each convolution output feature channel by automatic learning [47].
The basic structure of the SENet is shown in Figure 2.
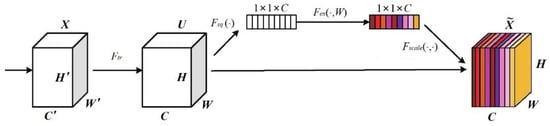
Figure 2.
Basic structure of SENet.
Assuming that the convolution outputs C -dimensional feature maps, which are considered as C channels, we get , then enter the SENet module. The first Squeeze step is performed as follows:
That is, the feature map of channel C, dimension , is compressed into a feature map of channel C, dimension , utilizing a global averaging pooling operation, and gets a feature descriptor that represents global information.
The second step then performs the Excitation operation as follows:
Equation (11) specifically contains two fully connected layers, and the first full connection is performed on the result Z (which can be considered as a C-dimensional vector) obtained after global pooling to obtain a -dimensional vector with ReLU activation. A full concatenation of the activation results was then performed, turning the -dimensional vector back into a C-dimensional vector and performing a Sigmoid activation (mapping the weights to between 0 and 1), resulting in a weight matrix.
Finally, the weights of the learned channels are multiplied by the initial features to output the attention-weighted feature map:
The attention-weighted corrected feature map allows for the retention of valuable features and the elimination of less valuable ones. SENet is generic and can therefore be added to existing network architectures, with only a small increase in computational consumption, but with a significant increase in network performance. The overall operation of the SENet is shown in Figure 3.
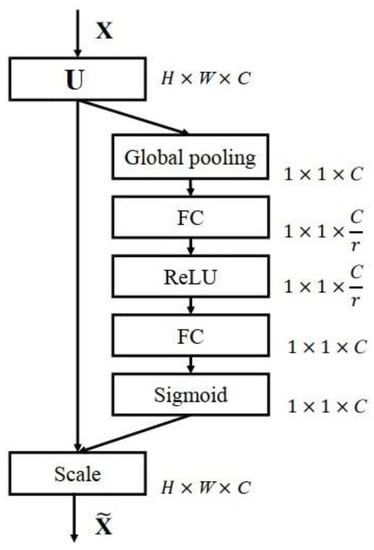
Figure 3.
The SENet algorithm process.
3. A Video Sequence Face Expression Recognition Method Based on SE-3DPCANet
In this paper, we propose a video sequence face expression recognition method based on SE-3DPCANet. As shown in Figure 4, the model input samples are video expression sequences, and the dynamic expression features are extracted in the convolutional layer using 3DPCA convolutional kernel; for the redundancy of local channel features, SENet is introduced in the feature encoding layer, to automatically learn the weights of local features in the tensor features.
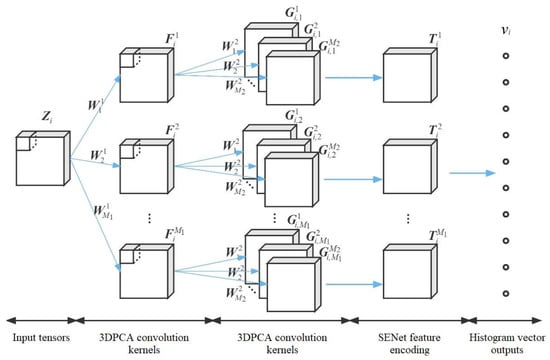
Figure 4.
Schematic diagram of the SE-3DPCANet structure.
3.1. Two-Order Convolutional Layers Based on 3DPCA
Suppose we take a video sequence of N sets of facial expressions , the size of each image frame in a single expression action sequence is , and the number of video frames is t, which is used as the sample input tensors.
Let the tensor sampling block size be , for the ith sample can slide sampling to get the tensor set , where denotes the jth tensor sampling block of sample in the first convolutional layer. Repeating the sliding sampling operation for N sets of samples yields . Then, 3DPCA is performed on . In all three SVDs, the first eigenvectors correspond to the largest eigenvalues, thus obtaining three 2D eigenmatrices:
Let , and then use the outer product of the tensor, is tensed into third-order eigentensor, i.e., the first layer of convolution kernel:
where , , . Then, sample is convoluted with convolution kernels for tensor convolution:
Then sample can output tensor feature maps after the first convolution layer.
Before inputting the second convolution layer, the edges of are first zero-complemented so that the tensor feature map has the same size as the initial tensor . Then, a similar operation to the first layer is performed on each tensor feature map to obtain second-order convolution kernels:
where . Similarly, convolving each with each of the convolution kernels yields a feature tensor map.
Then the second convolutional layer will eventually output feature tensors .
Remark.
This section extracts the temporal and spatial features of the video expression sequences based on the 3DPCA and uses this to construct the corresponding 3D convolution kernels for tensor convolution operations, effectively preserving the temporal information of expression changes. However, the feature tensors contain multiple local feature channels, which have some redundancy and are not conducive to the feature representation of the model if directly binarized hash encoding is performed. Therefore, the encoding of the tensor features is improved in the next subsection.
3.2. Feature Encoding Layer Based on the Channel Attention Mechanism
Local channel features at adjacent spatial locations in each tensor feature map output after 3DPCA convolution often have some correlation, due to the overlap of sensory fields. However, in the feature encoding process of a typical PCANet, for each feature map, only weight is usually assigned by contribution and all local features are weighted based on this weight, ignoring the relationship between local channel features and also failing to dynamically adjust the weights of each feature according to the input.
Therefore, this paper addresses the redundancy of local channel features and introduces the SENet to learn adaptive weights for local channel features in each tensor feature to improve the representation capability of the network. The specific steps are as follows.
First, the individual feature tensor maps are still binarized to obtain a feature tensor containing only 0 and 1 elements:
where is the binarization function. Omit the lower marker of as , then using each of the three directions of the tensor as a channel dimension yields , , , and enter the SENet one by one to calculate the weights in each of the three directions. First, the first step of the Squeeze operation is performed on to obtain a global description of the feature tensor , where:
After compressing the feature map to obtain a global description of the features, the Excitation operation is then used to calculate the weight matrix:
where , , are hyperparameters, denotes the ReLU activation function, and denotes the Sigmoid activation function.
Performing the same operation for and , the corresponding weight matrices and are obtained. The three weight matrices are then used to weight each element of the feature map tensor with the following weighting formula:
The final attention-weighted feature map tensor is obtained, i.e., . Next, the feature map tensors are weighted by the degree of contribution to obtain:
is then divided into C tensor blocks and the histograms of each tensor block are counted to obtain a histogram tandem feature for each feature map . The final cascade of histogram features into one feature vector output:
The samples can output a final video expression feature matrix after feature extraction using SE-3DPCANet, and then the SVM classifier is used to achieve expression recognition.
Remark.
This subsection uses SENet to learn adaptive weights for local feature channels on the tensor feature map after binarization, reducing feature redundancy. It also avoids the need to weigh all channels based on a single weight during hash coding, increasing the representational power of the model and contributing to subsequent classification accuracy.
4. Case Study
4.1. Introduction to the Data Set and Preprocessing
In this paper, three video face expression datasets, CK+ [48], AFEW [49] and CASME II [50], are selected for experimental validation of the algorithm performance.
The CK+ expression dataset consists of a total of 593 video sequences, including 327 tagged expression sequences consisting of seven expressions: anger, contempt, disgust, fear, happiness, sadness, and surprise, with the remaining sequences being neutral expressions. The expressions in each video sequence change from neutral to peak expressions, so 16 frames can be intercepted at appropriate intervals as the expression sequences for this experiment, and the sequences with less than 16 frames are copied from the last frame until 16 frames are made up. All expression frames are then aligned and cropped, with a uniform crop size of ; this gives the tensor size of each video sample as . Finally, the processed expression sequences in each class were divided 3:1 into the training and test sets.
The AFEW dataset is derived from film footage and is more realistic and challenging than the laboratory’s posed expressions. The parts of the film containing more expressions were selected for the interception, and a total of 1809 video expression sequences were obtained, containing seven expression labels: anger, disgust, fear, happiness, sadness, surprise, and neutral. For each video sequence, 16 frames at regular intervals were selected as the experimental sample sequence and then aligned and cropped according to the same criteria.
The CASME II micro-expressions dataset consists of 255 micro-expression video sequences from 26 filmmakers, containing a total of five basic expressions: boredom, happiness, surprise, sadness, and fear, as well as other expressions. Each video sequence changes from a neutral expression to a peak expression and finally back to a neutral expression. Therefore, for each video sequence, 16 frames are intercepted at regular intervals from the beginning of the neutral expression to the end of the peak, and the interval is used as a sample of the expression sequence. The same alignment and cropping operations are then performed with the CK+ dataset.
4.2. Experiment 1: Selection of Model Parameters
This subsection conducts experiments on the selection of parameters for the proposed SE-3DPCANet model. The optimal parameter values for the network can be selected by a combinatorial comparison. Uniformly set the number of filters to , the sampling block plane sliding size is chosen as , , separately, sample block sliding frame number increased from 8 to 16, the histogram window size is , and the corresponding overlap rate was set to 0.5. The same trained SVM classifier was used for expression classification recognition.
The SE-3DPCANet recognition rate curves for different parameters are shown in Figure 5. As can be seen from the parameter curves in Figure 5, the recognition accuracy of the model increases with the increase of the sampling size in the spatial dimension and the sampling size in the temporal dimension under all three datasets, and eventually stabilizes. The optimal combination of sampling block parameters for the CK+ and CASME II datasets is , . By comparison, the optimal combination of sampling block parameters for the AFEW dataset is , .
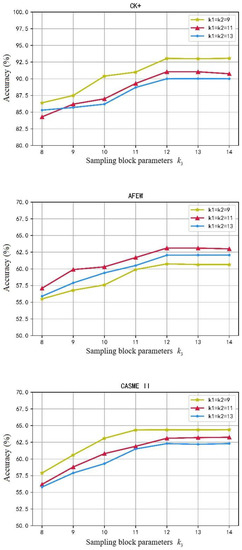
Figure 5.
Recognition rate curve for SE-3DPCANet with different parameters.
4.3. Experiment 2: Algorithm Performance Comparison and Analysis
This subsection tests the performance of SE-3DPCANet on three datasets: CK+, AFEW and CASME II, respectively. The confusion matrix for SE-3DPCANet on the CK+ dataset was first calculated, as shown in Figure 6. The confusion matrix provides a visual representation of the classification accuracy of the model, which indicates the proportion of each type of expression predicted by the model in the actual sample of each type of expression, as a way to assess the classification performance of the SE-3DPCANet model.
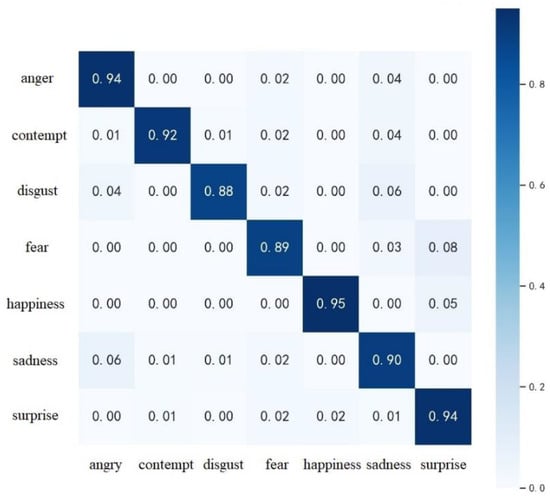
Figure 6.
Confusion matrix for CK+ dataset.
According to Figure 6, it can be seen that the recognition accuracy of all types of expressions in the CK+ dataset is relatively high. Thanks to the fact that the facial expressions in the CK+ dataset were all filmed in the laboratory, the video images are of better quality and the expression movements are in place, making them easier to distinguish and recognize. Among the seven expressions in the CK+ dataset, the recognition accuracy of happiness, surprise, and anger is relatively high. Of these, the happiness expression is the highest, as it is characterized by more intense emotions and larger movements. In addition to this, happiness has an advantage in terms of sample size. However, the recognition rate of disgust, fear, and sadness expressions is low compared to other expressions. The confusion matrix shows that disgust is easily misidentified as sadness; fear is easily confused with surprise; and a small number of sadness expressions are recognized as anger. The main reasons for this are the presence of similar facial movement features in some expressions and the unevenness of the samples, which affects the recognition rate.
The SE-3DPCANet algorithm proposed in this paper is then compared with existing expression recognition algorithms 3D-CNN, 3D Inception-ResNet, Spatio-temporal manifold, as well as PCANet, KPCANet-LDA, 3D-PCANet. A comparison of the recognition performance of each algorithm on the CK+ dataset is shown in Table 1.

Table 1.
Performance comparison of different algorithms on the CK+ dataset.
Table 1 shows that the recognition rate of the SE-3DPCANet model proposed in this paper is 93.15% on the CK+ dataset, which is higher than most of the algorithms in the table. The comparison between SE-3DPCANet and 3DPCANet illustrates that the introduction of the SENet facilitates the extraction of more effective features and maintains a shorter training time while improving the recognition rate. Compared with the 3D-ResNet algorithm, the training time of the proposed method is less than 1/21 of that of 3D-ResNet, although the correct recognition rate of the proposed method is reduced by 1.05%. The proposed method is more suitable for realistic needs, as it greatly reduces training costs while significantly preserving the accuracy of the model.
The confusion matrix for SE-3DPCANet on the AFEW dataset was calculated using the same method as shown in Figure 7. Compared with Figure 8, it can be seen that the overall recognition rate of the proposed algorithm on AFEW is smaller than that of CK+, which is mainly affected by the lack of resolution of the face video image and the fullness of the expression action, and there is also a certain gap in the number and quality of samples for each type of expression. The proposed algorithm achieves the highest recognition rate of 80% for happiness and more than 70% for anger, surprise and sadness, but the recognition rate for disgust and fear expressions is low. It can be seen from Figure 7 that some of the disgust expressions were identified as sadness and some of the fear expressions were identified as sadness and surprise. Both disgust and sadness are negative emotions, which inherently share two very similar sets of facial expressions. In addition, there are many similar expression frames in the video sequences of disgust and sadness expressions, resulting in greater misclassification of disgust and sadness on the AGEW dataset. When the negative stimulus source exceeds the test subject’s psychological expectations, the emotion of fear arises; when a bad result occurs, the test subject’s emotion changes from fear to sadness. Thus, there was a strong correlation between sadness and fear, resulting in some of the fearful expression samples being misclassified as sadness.
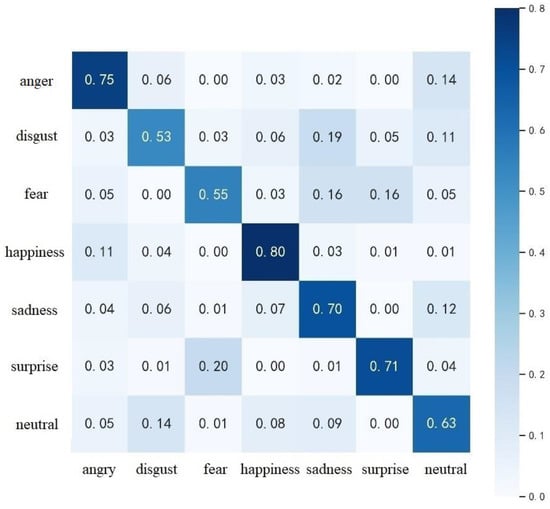
Figure 7.
Confusion matrix for the AFEW dataset.
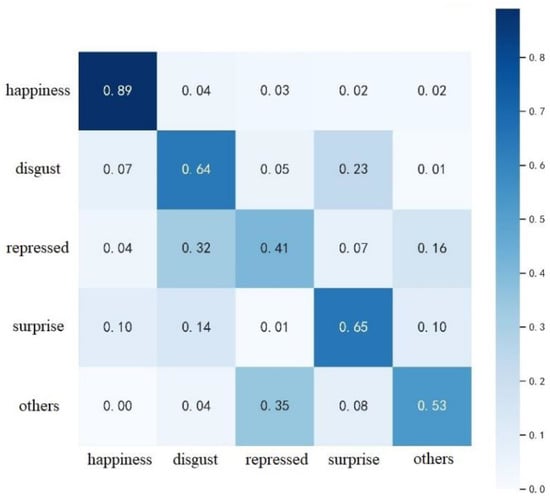
Figure 8.
Confusion matrix for the CASME II dataset.
The SE-3DPCANet algorithm was then compared with 3D-CNN, VGG-LSTM, VGG-LSTM-Attention, 3DCNN-Attention, PCANet, and 3D-PCANet on the AFEW dataset. A comparison of the performance of the various algorithms on the AFEW dataset is shown in Table 2.
Table 2.
Performance comparison of different algorithms on the AFEW dataset.
Comparing the recognition rates and training times of the algorithms in Table 2, it is clear that the SE-3DPCANet can also achieve recognition rates similar to or even higher than the deep convolutional network on the AFEW dataset, while having a lower training time. Compared with the highest recognition rate of 3DCNN-Attention, the recognition rate of the proposed method is only 0.45% lower; however, the training time required for 3DCNN-Attention is more than 1 day, while the training time required for the proposed method is only 3 h. The extremely long training time of 3DCNN-Attention is unacceptable for subsequent sample replenishment, parameter changes and model updates. The proposed method significantly reduces the time required for model training while substantially ensuring model accuracy compared to other methods. It is well-illustrated that the use of SE-3DPCANet can effectively extract feature information on expression sequences, especially preserving the temporal correlation between expression action frames.
The final calculation of the confusion matrix for SE-3DPCANet on the CASME II dataset is shown in Figure 8. As can be seen in Figure 8, the overall expression recognition rates of the algorithms proposed in this paper are all low on CASME II. The best recognition is achieved in happiness, with an accuracy of 89%, which is due to the fact that facial changes are more obvious when a subject is happy, which facilitates recognition. The lowest recognition rate was for repressed, which is because repressed faces have smaller movements and less distinctive features, making it easy to misidentify expressions. The recognition rate for all remaining expressions is low, with disgust and surprise easily confused and some of the other expressions being incorrectly categorized as depressed.
The SE-3DPCANet algorithm was then compared with the common expression recognition methods LBP-TOP, EVM+HIGO, CNN-LSTM, PCANet, and 3D-PCANet on the CASME II dataset. A comparison of the performance of each algorithm is shown in Table 3.
Table 3.
Performance comparison of different algorithms on the CASME II dataset.
Table 3 shows that SE-3DPCANet also achieves good recognition results on the CASME II dataset, and can achieve a final recognition rate of 64.17%. The recognition rate is 3.08% lower than that of the EVM + HIGO algorithm, but, with its lightweight network structure, it greatly reduces the time cost in model training, which is less than 1/17th of the training time required by EVM + HIGO. Most of the remaining methods not only have a longer training time, but the model accuracy is not as excellent as the method proposed in this paper. Although the training time is shorter using only PCANet models, the significantly lower model accuracy is not acceptable in practical situations.
5. Conclusions
In this paper, we propose a video sequence face expression recognition method based on Squeeze-and-Excitation and 3DPCA Network. The model input samples are video expression sequences, and a tensor convolution kernel is constructed in the convolution layer, using 3DPCA to extract the dynamic expression features of the 3D video sequences; then, for the redundancy of local channel features, the channel attention mechanism module SENet is introduced in the feature encoding layer, to automatically learn the weights of local features in the tensor features to further improve the recognition accuracy. Experimental validation was conducted on three datasets: CK+, AFEW, and CASME II, respectively. The recognition accuracy of the model was evaluated by calculating the confusion matrix for each type of expression and comparison with other common expression recognition algorithms for analysis. Experimental results show that the SE-3DPCANet algorithm proposed in this paper can effectively recognize various types of expressions and achieve close to or even higher correct recognition rates compared to most expression recognition methods. The proposed method has great advantages in terms of training time, and the overall performance of the model is superior.
We list the benefits and drawbacks as follows:
Benefits:
(1) The facial expression features extracted by 3DPCANet greatly reduce the redundancy of the original information while retaining the key information.
(2) SENet increases the representation capability of the model and, in combination with 3DPCANet, greatly reduces the time cost of model training while ensuring the accuracy of the model as much as possible.
Drawbacks:
(1) While the proposed method substantially reduces the time required for training, the model accuracy is also slightly reduced compared to deep neural networks. How to maintain or even surpass the accuracy of the original model while reducing the training time of the model, and significantly improve the comprehensive performance of the model, is a future research direction.
(2) How to apply the proposed method to micro-expression recognition and extract the small difference in features of human facial expression is a future research direction.
Author Contributions
Conceptualization, Y.Q.; data curation, Y.Q.; formal analysis, C.W.; funding acquisition, C.W.; methodology, Y.Q. and C.W.; project administration, Y.Q.; resources, C.W.; supervision, C.W.; validation, C.W.; writing—original draft, C.L.; writing—review and editing, C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China under Grants U19344221, 61733015 and 61933013; the State Key Laboratory of Rail Traffic Control and Safety (Contract NO. RCS2021K007), Beijing Jiaotong University.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sown, M. A preliminary note on pattern recognition of facial emotional expression. In Proceedings of the 4th International Joint Conferences on Pattern Recognition, Kyoto, Japan, 7–10 November 1978. [Google Scholar]
- Jain, A.K.; Li, S.Z. Handbook of Face Recognition; Springer: Berlin/Heidelberg, Germany, 2011; Volume 1. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Cohen, I.; Sebe, N.; Garg, A.; Chen, L.S.; Huang, T.S. Facial expression recognition from video sequences: Temporal and static modeling. Comput. Vis. Image Underst. 2003, 91, 160–187. [Google Scholar] [CrossRef]
- Chibelushi, C.C.; Bourel, F. Facial expression recognition: A brief tutorial overview. CVonline-Line Compend. Comput. Vis. 2003, 9. [Google Scholar]
- Rodger, H.; Vizioli, L.; Ouyang, X.; Caldara, R. Mapping the development of facial expression recognition. Dev. Sci. 2015, 18, 926–939. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6897–6906. [Google Scholar]
- Chen, X.-W.; Huang, T. Facial expression recognition: A clustering-based approach. Pattern Recognit. Lett. 2003, 24, 1295–1302. [Google Scholar] [CrossRef]
- Kimura, S.; Yachida, M. Facial expression recognition and its degree estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 295–300. [Google Scholar]
- Michel, P.; El Kaliouby, R. Real time facial expression recognition in video using support vector machines. In Proceedings of the 5th International Conference on Multimodal Interfaces, Vancouver, BC, Canada, 5–7 November 2003; pp. 258–264. [Google Scholar]
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A natural visible and infrared facial expression database for expression recognition and emotion inference. IEEE Trans. Multimed. 2010, 12, 682–691. [Google Scholar] [CrossRef]
- Mohammadi, M.R.; Fatemizadeh, E.; Mahoor, M.H. PCA-based dictionary building for accurate facial expression recognition via sparse representation. J. Vis. Commun. Image Represent. 2014, 25, 1082–1092. [Google Scholar] [CrossRef]
- Patil, M.N.; Iyer, B.; Arya, R. Performance evaluation of PCA and ICA algorithm for facial expression recognition application. In Proceedings of the Fifth International Conference on Soft Computing for Problem Solving; Springer: Singapore, 2016; pp. 965–976. [Google Scholar]
- Luo, Y.; Wu, C.-m.; Zhang, Y. Facial expression recognition based on fusion feature of PCA and LBP with SVM. Opt.-Int. J. Light Electron Opt. 2013, 124, 2767–2770. [Google Scholar] [CrossRef]
- Deng, H.-B.; Jin, L.-W.; Zhen, L.-X.; Huang, J.-C. A new facial expression recognition method based on local Gabor filter bank and PCA plus LDA. Int. J. Inf. Technol. 2005, 11, 86–96. [Google Scholar]
- Buciu, I.; Pitas, I. Application of non-negative and local non negative matrix factorization to facial expression recognition. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 26 August 2004; pp. 288–291. [Google Scholar]
- Lien, J.J.; Kanade, T.; Cohn, J.F.; Li, C.-C. Automated facial expression recognition based on FACS action units. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 390–395. [Google Scholar]
- Buciu, I.; Kotropoulos, C.; Pitas, I. Comparison of ICA approaches for facial expression recognition. Signal Image Video Process. 2009, 3, 345–361. [Google Scholar] [CrossRef]
- Guo, X.; Zhang, X.; Deng, C.; Wei, J. Facial Expression Recognition based on Independent Component Analysis. J. Multimed. 2013, 8, 402–409. [Google Scholar] [CrossRef]
- Varma, S.; Shinde, M.; Chavan, S.S. Analysis of PCA and LDA features for facial expression recognition using SVM and HMM classifiers. In Techno-Societal 2018; Springer: Berlin/Heidelberg, Germany, 2020; pp. 109–119. [Google Scholar]
- Wu, T.; Bartlett, M.S.; Movellan, J.R. Facial expression recognition using gabor motion energy filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 42–47. [Google Scholar]
- Gu, W.; Xiang, C.; Venkatesh, Y.; Huang, D.; Lin, H. Facial expression recognition using radial encoding of local Gabor features and classifier synthesis. Pattern Recognit. 2012, 45, 80–91. [Google Scholar] [CrossRef]
- Ou, J.; Bai, X.-B.; Pei, Y.; Ma, L.; Liu, W. Automatic facial expression recognition using Gabor filter and expression analysis. In Proceedings of the 2010 Second International Conference on Computer Modeling and Simulation, Sanya, China, 22–24 January 2010; pp. 215–218. [Google Scholar]
- Liu, W.; Wang, Z. Facial expression recognition based on fusion of multiple Gabor features. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 536–539. [Google Scholar]
- Almaev, T.R.; Valstar, M.F. Local gabor binary patterns from three orthogonal planes for automatic facial expression recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 356–361. [Google Scholar]
- Ahsan, T.; Jabid, T.; Chong, U.-P. Facial expression recognition using local transitional pattern on Gabor filtered facial images. IETE Tech. Rev. 2013, 30, 47–52. [Google Scholar] [CrossRef]
- Ding, Y.; Zhao, Q.; Li, B.; Yuan, X. Facial expression recognition from image sequence based on LBP and Taylor expansion. IEEE Access 2017, 5, 19409–19419. [Google Scholar] [CrossRef]
- Shan, C.; Gritti, T. Learning Discriminative LBP-Histogram Bins for Facial Expression Recognition. In Proceedings of the BMVC, Leeds, UK, 1–8 September 2008; pp. 1–10. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Robust facial expression recognition using local binary patterns. In Proceedings of the IEEE International Conference on Image Processing, Geneva, Switzerland, 11–14 September 2005. [Google Scholar]
- Huang, M.-W.; Wang, Z.-W.; Ying, Z.-L. A new method for facial expression recognition based on sparse representation plus LBP. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 1750–1754. [Google Scholar]
- He, L.; Zou, C.; Zhao, L.; Hu, D. An enhanced LBP feature based on facial expression recognition. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 3300–3303. [Google Scholar]
- Kong, F. Facial expression recognition method based on deep convolutional neural network combined with improved LBP features. Pers. Ubiquitous Comput. 2019, 23, 531–539. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Akbal, E. Discrete complex fuzzy transform based face image recognition method. Int. J. Image Graph. Signal Process 2019, 11, 1–7. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Abdar, M.; Ehsan Basiri, M.; Pławiak, P. Face recognition with triangular fuzzy set-based local cross patterns in wavelet domain. Symmetry 2019, 11, 787. [Google Scholar] [CrossRef]
- Tu, D.-W.; Jiang, J.-L. Improved algorithm for motion image analysis based on optical flow and its application. Guangxue Jingmi Gongcheng 2011, 19, 1159–1164. [Google Scholar]
- Song, X.; Seneviratne, L.D.; Althoefer, K. A Kalman filter-integrated optical flow method for velocity sensing of mobile robots. IEEE/ASME Trans. Mechatron. 2010, 16, 551–563. [Google Scholar] [CrossRef]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Brox, T.; Bruhn, A.; Papenberg, N.; Weickert, J. High accuracy optical flow estimation based on a theory for warping. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 25–36. [Google Scholar]
- Lei, Y.; Jinzong, L.; Dongdong, L. Discontinuity-preserving optical flow algorithm. J. Syst. Eng. Electron. 2007, 18, 347–354. [Google Scholar] [CrossRef]
- Bruhn, A.; Weickert, J.; Schnörr, C. Lucas/Kanade meets Horn/Schunck: Combining local and global optic flow methods. Int. J. Comput. Vis. 2005, 61, 211–231. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4489–4497. [Google Scholar]
- He, X.; Xu, J.; Shi, K.; Chen, W. Video face expression recognition based on attention mechanism. Inf. Technol. 2020, 44, 103–107. [Google Scholar] [CrossRef]
- Wang, Z.; Hou, T.; Heng, X. Fusing CNN and BLSTM neural networks for facial expression recognition. Comput. Digit. Eng. 2020, 48, 2978–2983. [Google Scholar]
- Vielzeuf, V.; Pateux, S.; Jurie, F. Temporal multimodal fusion for video emotion classification in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 569–576. [Google Scholar]
- Wang, Q.; Wang, K.; Li, Y.; Wang, X.; Wang, B. Fast 3D principal component analysis-based lung CT image detection. Opt. Precis. Eng. 2010, 18, 2695–2701. [Google Scholar]
- Lathauwer, L.D.; Moor, B.D.; Vandewalle, J. A Multilinear Singular Value Decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting Large, Richly Annotated Facial-Expression Databases from Movies. IEEE MultiMedia 2012, 19, 34–41. [Google Scholar] [CrossRef]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, X.; He, L.; Du, Q. Expression Recognition Based on KPCANet and Linear Discriminant Analysis. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2020, 48, 95–99. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Ma, A. Research on Video Oriented Dynamic Facial Expression Recognition Algorithm. Master’s Thesis, Jilin University, Changchun, China, 2021. [Google Scholar]
- Park, S.Y.; Lee, S.H.; Ro, Y.M. Subtle Facial Expression Recognition Using Adaptive Magnification of Discriminative Facial Motion. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 911–914. [Google Scholar]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikäinen, M. Towards Reading Hidden Emotions: A Comparative Study of Spontaneous Micro-Expression Spotting and Recognition Methods. IEEE Trans. Affect. Comput. 2018, 9, 563–577. [Google Scholar] [CrossRef]
- Kim, D.H.; Baddar, W.J.; Ro, Y.M. Micro-Expression Recognition with Expression-State Constrained Spatio-Temporal Feature Representations. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 382–386. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).