
Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data?

 ,
,  , ,
, ,  , ,
, , 
Abstract
1. Introduction
2. Convolutional Neural Networks, Review
2.1. CNN Mechanism
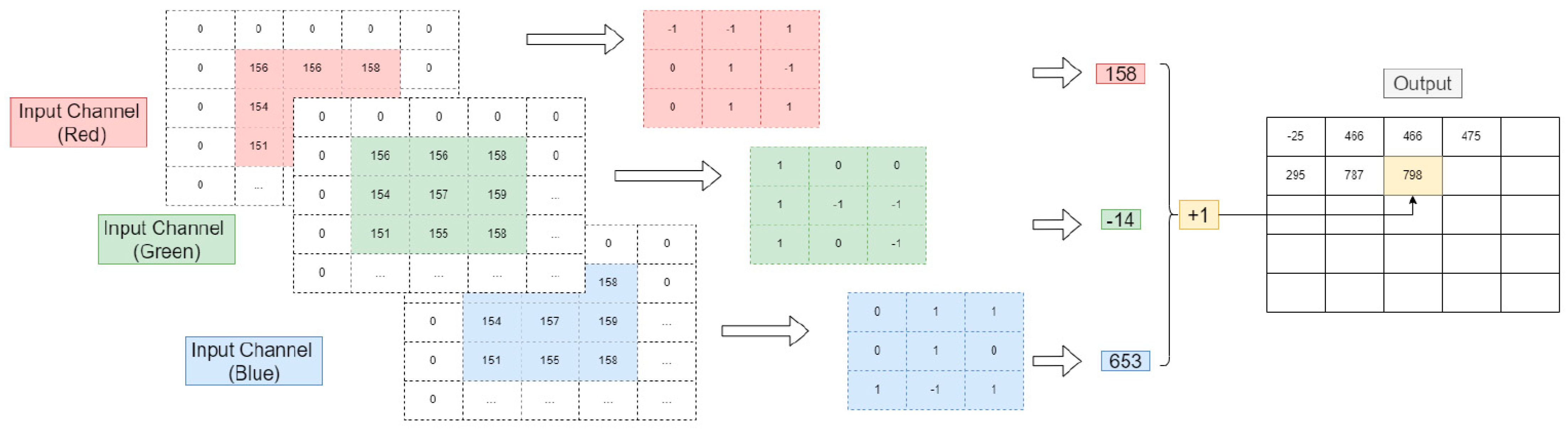
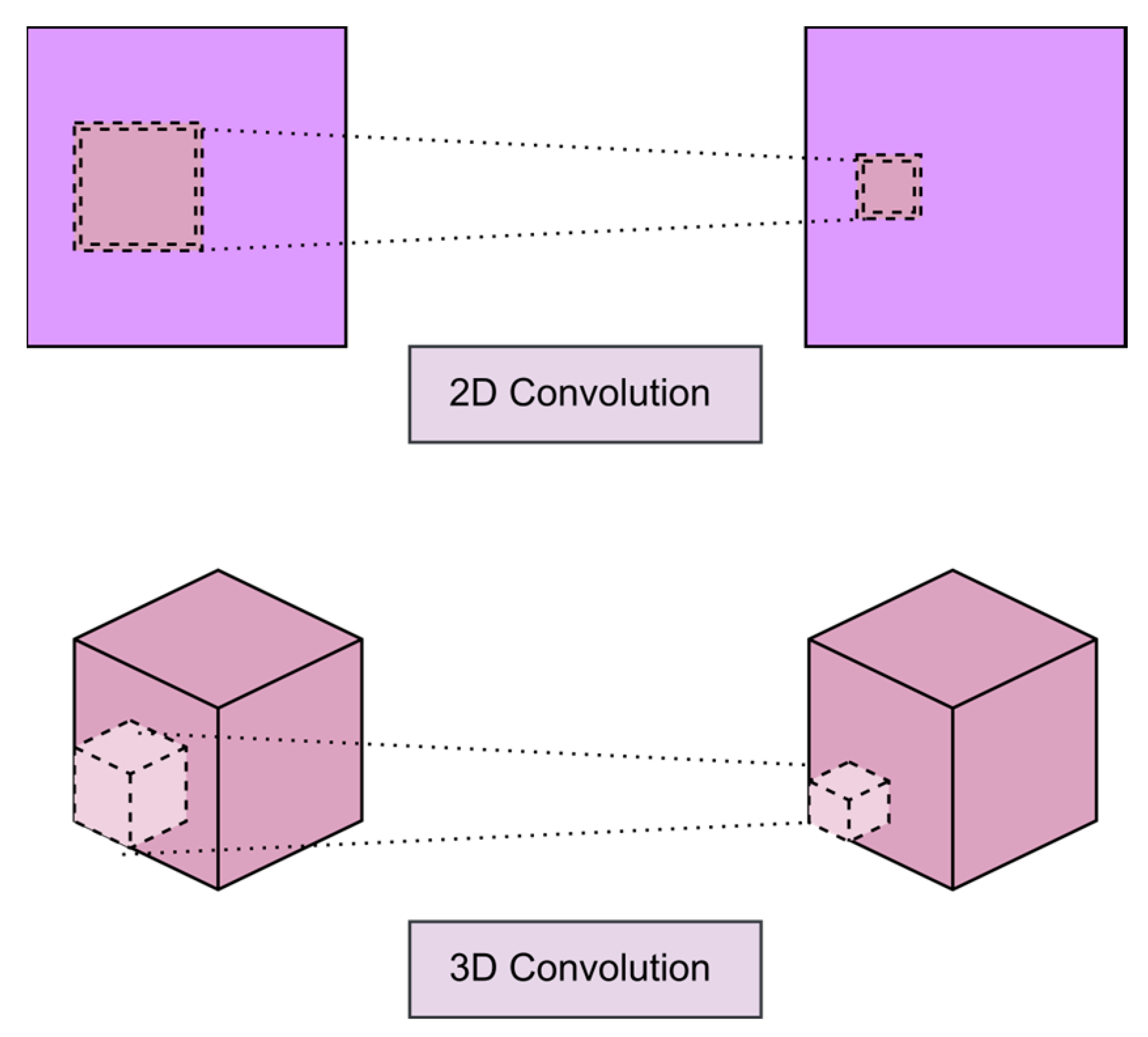
2.2. Convolution Layer
2.3. Nonlinearity Layer
2.4. Pooling Layer
2.5. Fully Connected Layer
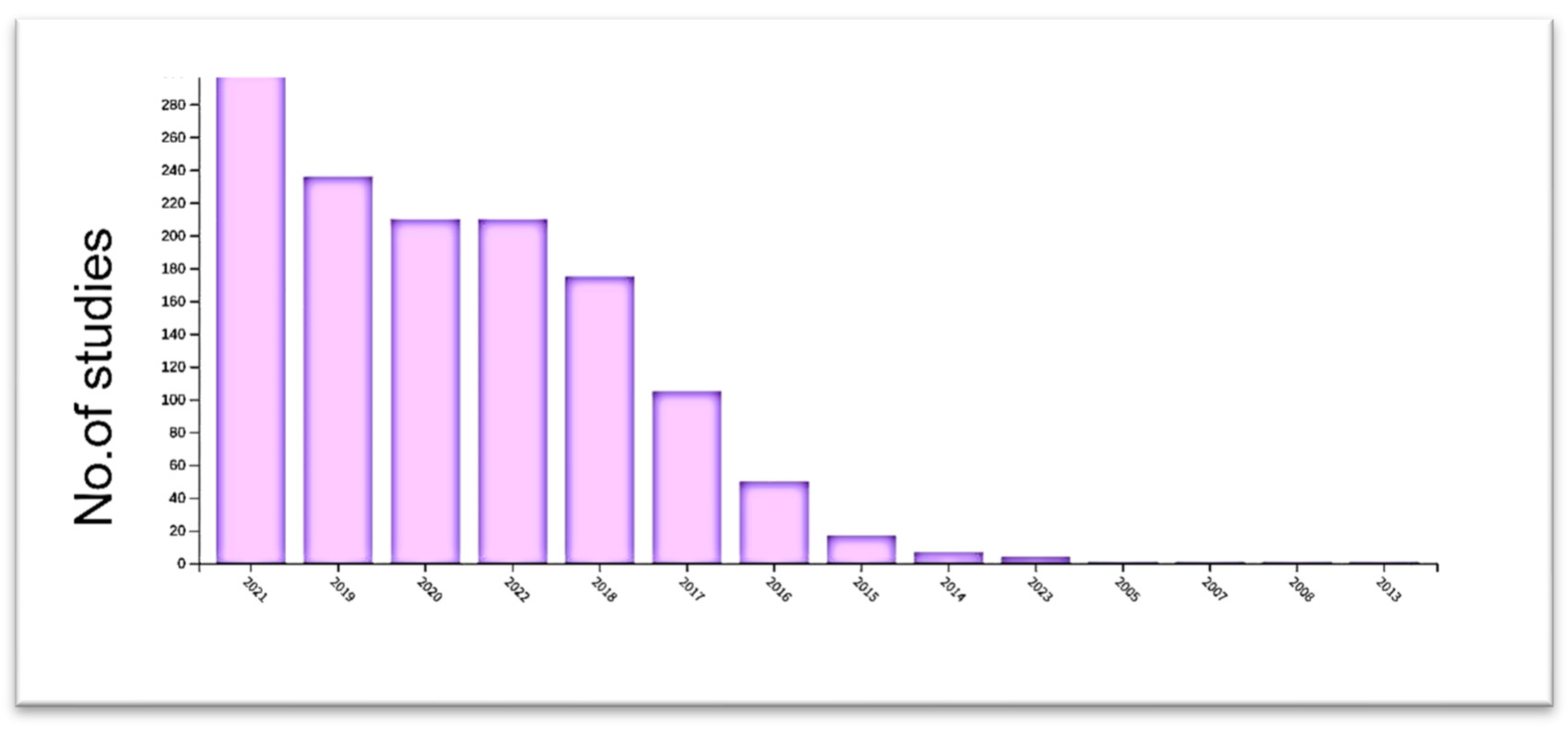
3. CNN-Related Work
4. CNN for Action Recognition
5. Vision Transformer
5.1. The standard Vision Transformer
5.1.1. Patch Embedding
5.1.2. Transformer Encoder
5.1.3. Pure Transformer
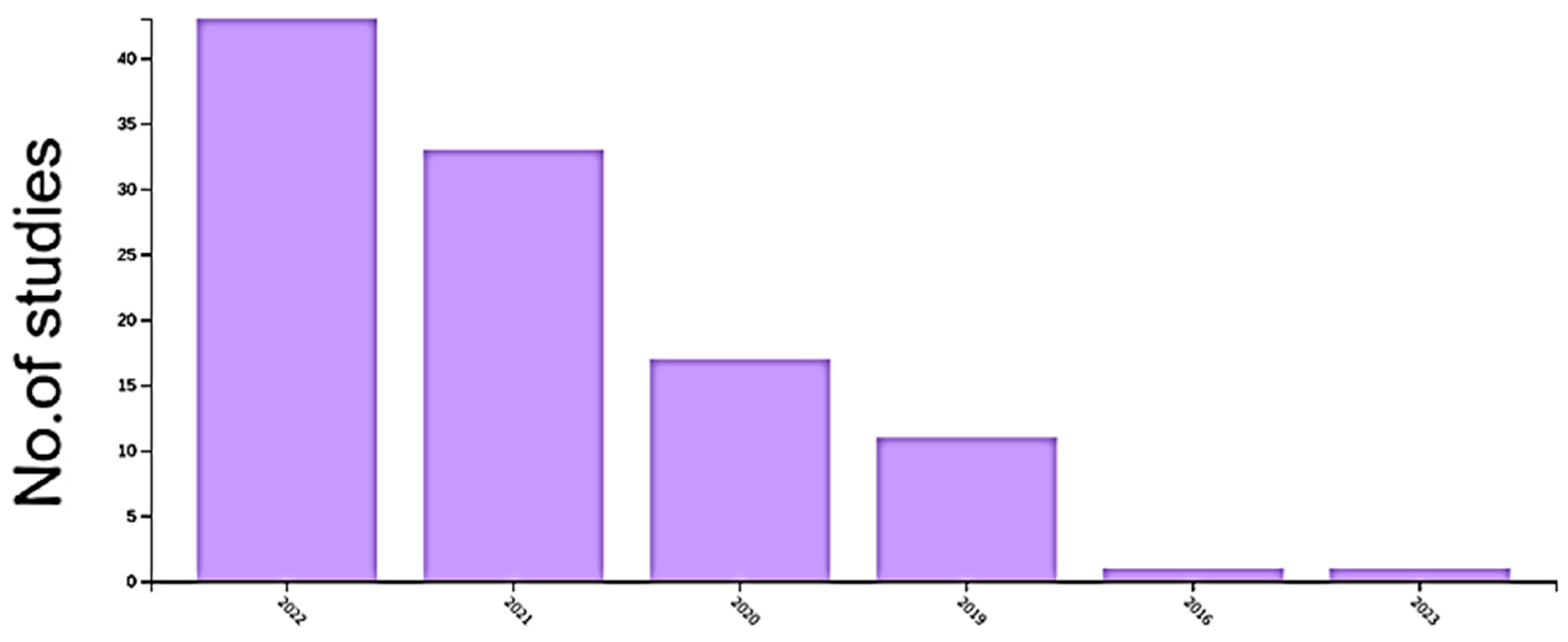
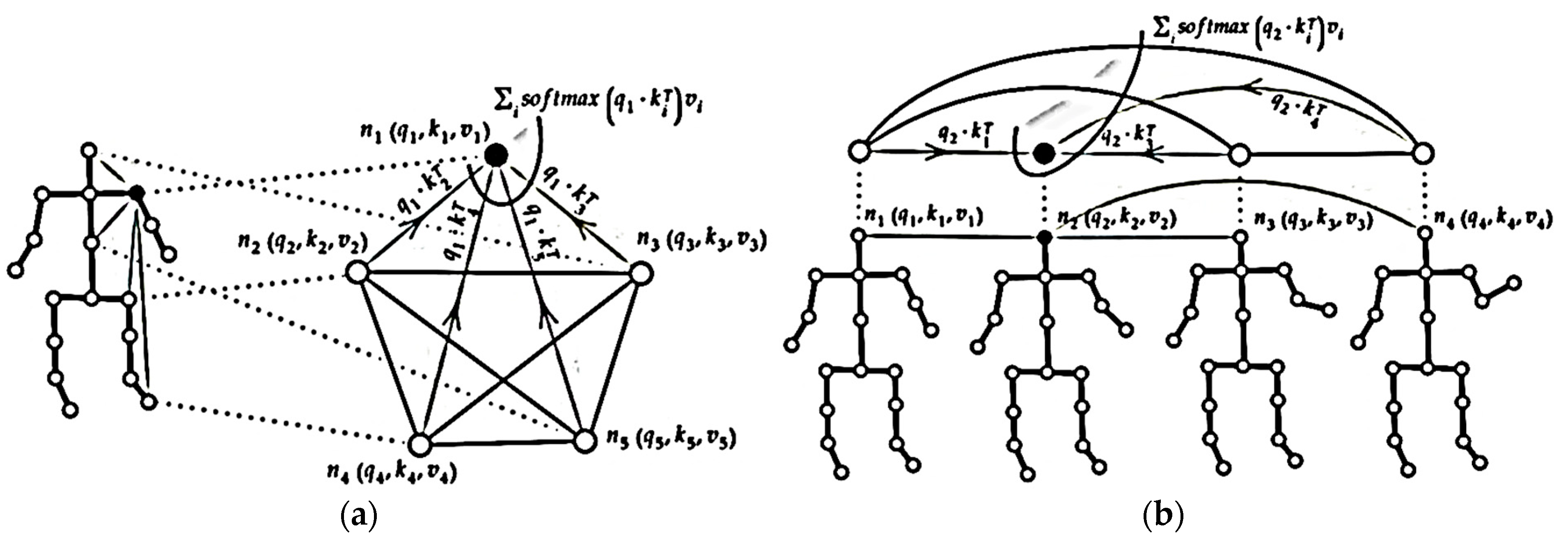
6. Transformers for Action Recognition
7. Comparative Study between CNN, Vision Transformer, and Hybrid Models
7.1. Pros and cons of CNN and Transformer
7.2. Modality Comparative Literature

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Year | The Idea of the Model | Datasets (Accuracy) | ||||
|---|---|---|---|---|---|---|---|
| NTU RGB+D | NTU RGB+D 120 | ||||||
| CS | CV | CS | CV | ||||
| CNN | Yan et al. [112] | 2018 | The authors developed the first strategy for collecting spatial and temporal data from skeleton data by encoding the skeleton data with GCN. | 85.7 | 92.7 | ||
| Banerjee et al. [113] | 2020 | The author developed a CNN-based classifier for each feature vector, combining Choquet fuzzy integral, Kullback–Leibler, and Jensen–Shannon divergences to verify that the feature vectors are complementary. | 84.2 | 89.7 | 74.8 | 76.9 | |
| Chen et al. [114] | 2021 | The authors employed a GCN-based method to model dynamic channel-by-channel topologies employing a refining technique. | 93.0 | 97.1 | 89.8 | 91.2 | |
| Chi et al. [115] | 2022 | The authors developed a novel method that combines a learning objective and an encoding strategy. A learning objective based on the information bottleneck instructs the model to acquire informative, yet condensed, latent representations. To provide discriminative information, a multi-modal representation of the skeleton based on the relative positions of joints, an attention-based graph convolution that captures the context-dependent underlying topology of human activity and complementing spatial information for joints. | 92.1 | 96.1 | 88.7 | 88.9 | |
| Song et al. [116] | 2022 | The authors developed a strategy based on a collection of GCN baselines to synchronously extend the width and depth of the model in order to extract discriminative features from all skeletal joints using a minimal number of trainable parameters. | 92.1 | 96.1 | 88.7 | 88.9 | |
| Transformer | Shi et al. [117] | 2021 | The authors designed a pure transformer model for peripheral platforms or real-time applications. Segmented linear self-attention module that records temporal correlations of dynamic joint motions and sparse self-attention module that performs sparse matrix multiplications to record spatial correlations between human skeletal joints. | 83.4 | 84.2 | 78.3 | 78.5 |
| Plizzari et al. [82] | 2021 | The authors proposed a novel method to the modelling challenge posed by joint dependencies. A spatial self-attention (SSA) module is used to comprehend intra-frame interactions between various body parts, while a temporal self-attention (TSA) module is used to describe inter-frame correlations. | 89.9 | 96.1 | 81.9 | 84.1 | |
| Helei et al. [80] | 2022 | The authors propose two different modules. The first module records the interaction between multiple joints in consecutive frames, while the second module integrates the characteristics of various sub-action segments to record information about multiple joints between frames. | 92.3 | 96.5 | 88.3 | 89.2 | |
| Hybrid models | Wang et al. [111] | 2021 | The authors investigated employing a Transformer method to decrease the noise caused by operating joints. They suggested simultaneously encoding joint and body part interactions. | 92.3 | 96.4 | 88.4 | 89.7 |
| Qin et al. [118] | 2022 | The authors proposed a strategy for concatenating the representation of joints and bones to the input layer using a single flow network in order to lower the computational cost. | 90.5 | 96.1 | 85.7 | 86.8 | |
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Freeman, W.T.; Anderson, D.B.; Beardsley, P.A.; Dodge, C.N.; Roth, M.; Weissman, C.D.; Yerazunis, W.S.; Tanaka, K. Computer Vision for Interactive. IEEE Comput. Graph. Appl. 1998, 18, 42–53. [Google Scholar] [CrossRef]
- Ayache, N. Medical computer vision, virtual reality and robotics. Image Vis. Comput. 1995, 13, 295–313. [Google Scholar] [CrossRef]
- Che, E.; Jung, J.; Olsen, M. Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review. Sensors 2019, 19, 810. [Google Scholar] [CrossRef]
- Volden, Ø.; Stahl, A.; Fossen, T.I. Vision-based positioning system for auto-docking of unmanned surface vehicles (USVs). Int. J. Intell. Robot. Appl. 2022, 6, 86–103. [Google Scholar] [CrossRef]
- Minaee, S.; Luo, P.; Lin, Z.; Bowyer, K. Going Deeper into Face Detection: A Survey. arXiv 2021, arXiv:2103.14983. [Google Scholar]
- Militello, C.; Rundo, L.; Vitabile, S.; Conti, V. Fingerprint Classification Based on Deep Learning Approaches: Experimental Findings and Comparisons. Symmetry 2021, 13, 750. [Google Scholar] [CrossRef]
- Hou, Y.; Li, Q.; Zhang, C.; Lu, G.; Ye, Z.; Chen, Y.; Wang, L.; Cao, D. The State-of-the-Art Review on Applications of Intrusive Sensing, Image Processing Techniques, and Machine Learning Methods in Pavement Monitoring and Analysis. Engineering 2021, 7, 845–856. [Google Scholar] [CrossRef]
- Deng, G.; Luo, J.; Sun, C.; Pan, D.; Peng, L.; Ding, N.; Zhang, A. Vision-based Navigation for a Small-scale Quadruped Robot Pegasus-Mini. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 893–900. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 6 January 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Degardin, B.; Proença, H. Human Behavior Analysis: A Survey on Action Recognition. Appl. Sci. 2021, 11, 8324. [Google Scholar] [CrossRef]
- Ravanbakhsh, M.; Nabi, M.; Mousavi, H.; Sangineto, E.; Sebe, N. Plug-and-Play CNN for Crowd Motion Analysis: An Application in Abnormal Event Detection. arXiv 2018, arXiv:1610.00307. [Google Scholar]
- Gabeur, V.; Sun, C.; Alahari, K.; Schmid, C. Multi-modal Transformer for Video Retrieval. arXiv 2020, arXiv:2007.10639. [Google Scholar]
- James, S.; Davison, A.J. Q-attention: Enabling Efficient Learning for Vision-based Robotic Manipulation. arXiv 2022, arXiv:2105.14829. [Google Scholar] [CrossRef]
- Sharma, R.; Sungheetha, A. An Efficient Dimension Reduction based Fusion of CNN and SVM Model for Detection of Abnormal Incident in Video Surveillance. J. Soft Comput. Paradig. 2021, 3, 55–69. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Huang, T.S. Computer Vision: Evolution and Promise; CERN School of Computing: Geneva, Switzerland, 1996; pp. 21–25. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten Digit Recognition with a Back-Propagation Network. Adv. Neural Inf. Process. Syst. 1990, 2, 396–404. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. ISBN 978-3-319-10589-5. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. arXiv 2020, arXiv:1908.07919. [Google Scholar] [CrossRef]
- Anwar, S.M.; Majid, M.; Qayyum, A.; Awais, M.; Alnowami, M.; Khan, M.K. Medical Image Analysis using Convolutional Neural Networks: A Review. J. Med. Syst. 2018, 42, 226. [Google Scholar] [CrossRef] [PubMed]
- Valiente, R.; Zaman, M.; Ozer, S.; Fallah, Y.P. Controlling Steering Angle for Cooperative Self-driving Vehicles utilizing CNN and LSTM-based Deep Networks. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2423–2428. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. arXiv 2019, arXiv:1808.01244. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2020, arXiv:1904.08900. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Du, H.; Shi, H.; Zeng, D.; Zhang, X.-P.; Mei, T. The Elements of End-to-end Deep Face Recognition: A Survey of Recent Advances. arXiv 2021, arXiv:2009.13290. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation from Predicting 10,000 Classes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. arXiv 2017, arXiv:1612.02295. [Google Scholar]
- Chen, C.-F.; Panda, R.; Ramakrishnan, K.; Feris, R.; Cohn, J.; Oliva, A.; Fan, Q. Deep Analysis of CNN-based Spatio-temporal Representations for Action Recognition. arXiv 2021, arXiv:2010.11757. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9912, pp. 20–36. ISBN 978-3-319-46483-1. [Google Scholar]
- Fan, Q. More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation. arXiv 2019, arXiv:1912.00869. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7082–7092. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? In A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 7–11 July 2017; pp. 4724–4733. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 10–14 June 2018; pp. 6546–6555. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- Luo, C.; Yuille, A. Grouped Spatial-Temporal Aggregation for Efficient Action Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5511–5520. [Google Scholar]
- Sudhakaran, S.; Escalera, S.; Lanz, O. Gate-Shift Networks for Video Action Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1099–1108. [Google Scholar]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video Transformer Network. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11 October–17 October 2021; pp. 3156–3165. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199v2. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Columbus, OH), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal Relational Reasoning in Videos. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11205, pp. 831–846. ISBN 978-3-030-01245-8. [Google Scholar]
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October–29 October 2017; pp. 5843–5851. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. YouTube-8M: A Large-Scale Video Classification Benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2020, arXiv:1910.03771. [Google Scholar]
- Fang, W.; Luo, H.; Xu, S.; Love, P.E.D.; Lu, Z.; Ye, C. Automated text classification of near-misses from safety reports: An improved deep learning approach. Adv. Eng. Inform. 2020, 44, 101060. [Google Scholar] [CrossRef]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.-Y. Incorporating BERT into Neural Machine Translation. arXiv 2020, arXiv:2002.06823. [Google Scholar]
- Wang, Z.; Ng, P.; Ma, X.; Nallapati, R.; Xiang, B. Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering. arXiv 2019, arXiv:1908.08167. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv 2022, arXiv:2101.03961. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv 2019, arXiv:1804.07461. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Ye, L.; Rochan, M.; Liu, Z.; Wang, Y. Cross-Modal Self-Attention Network for Referring Image Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10494–10503. [Google Scholar]
- Zellers, R.; Bisk, Y.; Schwartz, R.; Choi, Y. SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference. arXiv 2018, arXiv:1808.05326. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. arXiv 2021, arXiv:2103.00112. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. arXiv 2021, arXiv:2104.13840. [Google Scholar]
- Huang, Z.; Ben, Y.; Luo, G.; Cheng, P.; Yu, G.; Fu, B. Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer. arXiv 2021, arXiv:2106.03650. [Google Scholar]
- Chen, C.-F.; Panda, R.; Fan, Q. RegionViT: Regional-to-Local Attention for Vision Transformers. arXiv 2022, arXiv:2106.02689. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.H.; Feng, J.; Yan, S. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11 October–17 October 2021; pp. 538–547. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. DeepViT: Towards Deeper Vision Transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Wang, P.; Wang, X.; Wang, F.; Lin, M.; Chang, S.; Li, H.; Jin, R. KVT: K-NN Attention for Boosting Vision Transformers. arXiv 2022, arXiv:2106.00515. [Google Scholar]
- El-Nouby, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J.; et al. XCiT: Cross-Covariance Image Transformers. arXiv 2021, arXiv:2106.09681. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Girdhar, R.; Joao Carreira, J.; Doersch, C.; Zisserman, A. Video Action Transformer Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 244–253. [Google Scholar]
- Zhang, Y.; Wu, B.; Li, W.; Duan, L.; Gan, C. STST: Spatial-Temporal Specialized Transformer for Skeleton-based Action Recognition. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China; 2021; pp. 3229–3237. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lucic, M.; Schmid, C. ViViT: A Video Vision Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11 October–17 October 2021; pp. 6816–6826. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial Temporal Transformer Network for Skeleton-based Action Recognition. In International Conference on Pattern Recognition; Springer: Cham, Switzerland, 2021; Volume 12663, pp. 694–701. [Google Scholar]
- Manipur, I.; Manzo, M.; Granata, I.; Giordano, M.; Maddalena, L.; Guarracino, M.R. Netpro2vec: A Graph Embedding Framework for Biomedical Applications. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 19, 729–740. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. NTU RGB+D: A Large-Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.-Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2684–2701. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Directed Graph Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16-20 June 2019; pp. 7904–7913. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12018–12027. [Google Scholar] [CrossRef]
- Koot, R.; Hennerbichler, M.; Lu, H. Evaluating Transformers for Lightweight Action Recognition. arXiv 2021, arXiv:2111.09641. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Ulhaq, A.; Akhtar, N.; Pogrebna, G.; Mian, A. Vision Transformers for Action Recognition: A Survey. arXiv 2022, arXiv:2209.05700. [Google Scholar]
- Xu, Y.; Wei, H.; Lin, M.; Deng, Y.; Sheng, K.; Zhang, M.; Tang, F.; Dong, W.; Huang, F.; Xu, C. Transformers in computational visual media: A survey. Comput. Vis. Media 2022, 8, 33–62. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Wang, G.; Tang, C.; Luo, C.; Zeng, W.; Zha, Z.-J. A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP. arXiv 2021, arXiv:2108.13002. [Google Scholar]
- Omi, K.; Kimata, J.; Tamaki, T. Model-agnostic Multi-Domain Learning with Domain-Specific Adapters for Action Recognition. IEICE Trans. Inf. Syst. 2022, E105.D, 2119–2126. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, D.; Wang, Y.; Wang, L.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Lu, T. TEINet: Towards an Efficient Architecture for Video Recognition. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11669–11676. [Google Scholar] [CrossRef]
- Li, X.; Shuai, B.; Tighe, J. Directional Temporal Modeling for Action Recognition. arXiv 2020, arXiv:2007.11040. [Google Scholar]
- Tran, D.; Wang, H.; Feiszli, M.; Torresani, L. Video Classification with Channel-Separated Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5551–5560. [Google Scholar]
- Wang, J.; Torresani, L. Deformable Video Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14033–14042. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video Swin Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3192–3201. [Google Scholar]
- Yang, J.; Dong, X.; Liu, L.; Zhang, C.; Shen, J.; Yu, D. Recurring the Transformer for Video Action Recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14043–14053. [Google Scholar]
- Yan, S.; Xiong, X.; Arnab, A.; Lu, Z.; Zhang, M.; Sun, C.; Schmid, C. Multiview Transformers for Video Recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA; 2022; pp. 3323–3333. [Google Scholar]
- Zha, X.; Zhu, W.; Lv, T.; Yang, S.; Liu, J. Shifted Chunk Transformer for Spatio-Temporal Representational Learning. arXiv 2021, arXiv:2108.11575. [Google Scholar]
- Zhang, Y.; Li, X.; Liu, C.; Shuai, B.; Zhu, Y.; Brattoli, B.; Chen, H.; Marsic, I.; Tighe, J. VidTr: Video Transformer Without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 13557–13567. [Google Scholar]
- Kalfaoglu, M.E.; Kalkan, S.; Alatan, A.A. Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition. arXiv 2020, arXiv:2008.01232. [Google Scholar]
- Li, B.; Xiong, P.; Han, C.; Guo, T. Shrinking Temporal Attention in Transformers for Video Action Recognition. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1263–1271. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef]
- Imran, J.; Raman, B. Evaluating fusion of RGB-D and inertial sensors for multimodal human action recognition. J. Ambient Intell. Humaniz. Comput. 2020, 11, 189–208. [Google Scholar] [CrossRef]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human Action Recognition from Various Data Modalities: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–20. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef]
- Wang, Q.; Peng, J.; Shi, S.; Liu, T.; He, J.; Weng, R. IIP-Transformer: Intra-Inter-Part Transformer for Skeleton-Based Action Recognition. arXiv 2021, arXiv:2110.13385. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2018, arXiv:1212.0402. [Google Scholar] [CrossRef]
- Banerjee, A.; Singh, P.K.; Sarkar, R. Fuzzy Integral-Based CNN Classifier Fusion for 3D Skeleton Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2206–2216. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. arXiv 2021, arXiv:2107.12213. [Google Scholar]
- Chi, H.-G.; Ha, M.H.; Chi, S.; Lee, S.W.; Huang, Q.; Ramani, K. InfoGCN: Representation Learning for Human Skeleton-based Action Recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 20154–20164. [Google Scholar]
- Song, Y.-F.; Zhang, Z.; Shan, C.; Wang, L. Constructing Stronger and Faster Baselines for Skeleton-based Action Recognition. arXiv 2022, arXiv:2106.15125. [Google Scholar] [CrossRef]
- Shi, F.; Lee, C.; Qiu, L.; Zhao, Y.; Shen, T.; Muralidhar, S.; Han, T.; Zhu, S.-C.; Narayanan, V. STAR: Sparse Transformer-based Action Recognition. arXiv 2021, arXiv:2107.07089. [Google Scholar]
- Qin, X.; Cai, R.; Yu, J.; He, C.; Zhang, X. An efficient self-attention network for skeleton-based action recognition. Sci. Rep. 2022, 12, 4111. [Google Scholar] [CrossRef] [PubMed]








| Properties | CNN | Transformer | Hybrid Model |
|---|---|---|---|
| Sparse connectivity | ✓ | - | ✓ |
| Weight sharing | ✓ | - | ✓ |
| Best at Latency accuracy on small datasets | ✓ | - | ✓ |
| Inductive bias | ✓ | - | ✓ |
| Capture local information | ✓ | - | ✓ |
| Dynamic weight | - | ✓ | ✓ |
| Capture global information | - | ✓ | ✓ |
| Learn from different angles | - | ✓ | ✓ |
| Best at Spatio-temporal Model long-distance interactions | - | ✓ | ✓ |
| Model + (Citation) | The Idea of the Model | Parameters | Flops | Year | Datasets (Accuracy) | |||
|---|---|---|---|---|---|---|---|---|
| UCF | HDM | Kin | ||||||
| CNN | Omi et al. [94] | Present a 3D CNN multi-domain-learning using adapters between layers. The results showed with ResNet backbone. | 183.34 | 2022 | 63.33 | 93.29 | 67.80 | |
| TEINet [95] | A technique for temporal modeling that enhances motion-related properties and adjusts the temporal contextual information channel-wise (backbone ResNet-50). | 0.06 | 2020 | 96.7 | 72.1 | 76.2 | ||
| Xinyu Li [96] | Introduced a 3D CNN network that learns video clip-level temporal features from different spatial and temporal scales. | 103 | 0.12 | 2020 | 97.9 | 75.2 | ||
| SlowFast Networks [48] | A single-stream design that operates at two separate frame rates. SlowPath captures spatial semantics, but FastPath combines temporal semantics via the side connection. We displayed the outcomes using a 3D Resnet backbone. | 32.88 | 0.36 | 2019 | 75.6 | |||
| Du Tran et al. [97] | Suggested factorizing 3D convolutions by separating channel interactions and spatiotemporal interactions in order to obtain greater precision at a lower computing cost. | 32.8 | 1.08 | 2019 | 82.5 | |||
| Transformer | Jue Wang et al. [98] | Dynamically predicts a subset of video patches to attend for each query location based on motion information. | 73.9M | 1.28 | 2022 | 79.0 | ||
| Arnab et al. [81] | Presented multiple models which factorize different components of the spatial-temporal transformer encoder. A solution to regularize the transformer model during training small datasets. | 4.77 | 2021 | 84.9 | ||||
| Liu et al. [99] | A pure transformer backbone model addressed the inductive bias of locality by utilizing the advantage of the intrinsic spatiotemporal locality in videos. | 2022 | 84.9 | |||||
| Yang et al. [100] | Fix the issue with videos’ needed set length. A strategy that uses the attention date to repeatedly construct interaction between the current frame input and the prior hidden state. | 107.7 | 0.11 | 2022 | 81.5 | |||
| Xiong et al. [101] | A multi-view transformer is composed of multiple individuals, each of which focuses on a certain depiction. Through a lateral link between individual encoders, information from several visual representations is successfully merged. | 2022 | 89.1 | |||||
| Zha et al. [102] | The components of the Shifted Chunk Transformer are a frame encoder and a clip encoder. The frame encoder uses the picture chunk and the shifting multi-head self-attention elements to capture intra-frame representation and inter-frame motion, respectively. | 59.89 | 0.34 | 2021 | 98.7 | 84.6 | 83.0 | |
| Zhang et al. [103] | Using the proposed standard deviation, an approach that aggregates Spatial-temporal data with stacking attention and an attention-pooling strategy to reduce processing costs. | 0.392 | 0.39 | 2021 | 96.7 | 74.7 | 80.5 | |
| Hybrid- Model | Kalfaoglu et al. [104] | Combining 3D convolution with late temporal modeling is a great way to improve the performance of 3D convolution designs. | 94.74 | 0.07 | 2020 | 98.69 | 85.10 | |
| Bonan Li et al. [105] | The issue of time-length videos was solved by implementing two attention modules: a short-term attention module and a long-term attention module, each of which provided a distinct temporal token attention. | 2.17 | 2022 | 81.3 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moutik, O.; Sekkat, H.; Tigani, S.; Chehri, A.; Saadane, R.; Tchakoucht, T.A.; Paul, A. Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data? Sensors 2023, 23, 734. https://doi.org/10.3390/s23020734
Moutik O, Sekkat H, Tigani S, Chehri A, Saadane R, Tchakoucht TA, Paul A. Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data? Sensors. 2023; 23(2):734. https://doi.org/10.3390/s23020734
Chicago/Turabian StyleMoutik, Oumaima, Hiba Sekkat, Smail Tigani, Abdellah Chehri, Rachid Saadane, Taha Ait Tchakoucht, and Anand Paul. 2023. "Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data?" Sensors 23, no. 2: 734. https://doi.org/10.3390/s23020734
APA StyleMoutik, O., Sekkat, H., Tigani, S., Chehri, A., Saadane, R., Tchakoucht, T. A., & Paul, A. (2023). Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data? Sensors, 23(2), 734. https://doi.org/10.3390/s23020734