
Global–Local Facial Fusion Based GAN Generated Fake Face Detection


Abstract
1. Introduction
- (1)
- We establish a mechanism to identify forgery images by combining both physiological methods, such as iris color, pupil shape, etc., and deep learning methods.
- (2)
- We propose a novel deepfake detection framework, which includes a local region detection branch and a global detection branch. The two branches are trained end-to-end to generate comprehensive detection results.
- (3)
- Extensive experiments have demonstrated the effectiveness of our method in detection accuracy, generalization, and robustness when compared with other approaches.
2. Related Work
2.1. Physical Properties Detection Method
2.2. Deep Learning Detection Method
3. Proposed Method
3.1. Motivation
3.2. Local Region Detection Branch
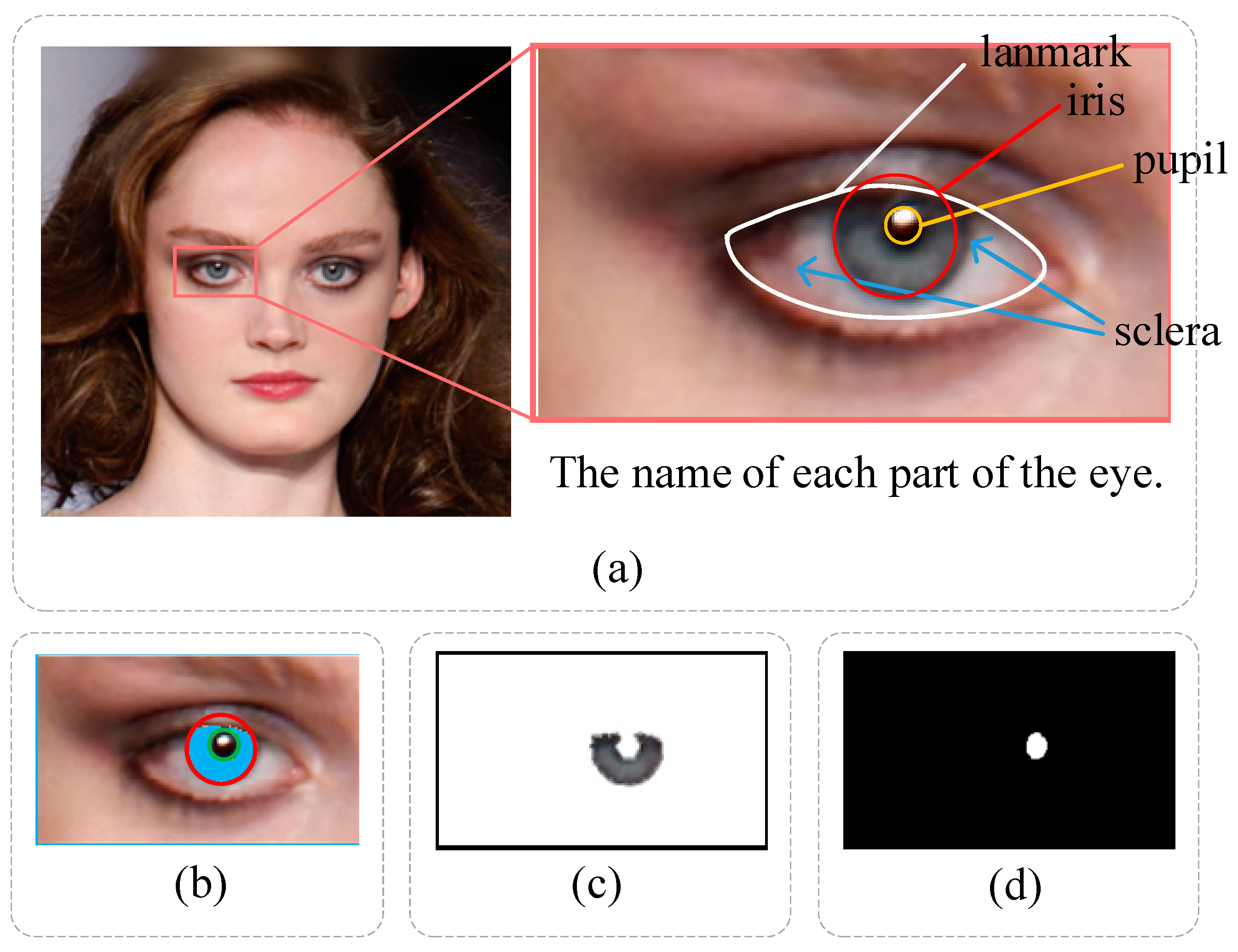
3.2.1. Iris and Pupil Segmentation
3.2.2. Iris Color Detection
3.2.3. Pupil Shape Estimation
| Algorithm 1 Pseudo-code of SSD |
| Input: ,, epochs Output:
|
3.3. Global Detection Branch
3.3.1. Downsample
3.3.2. Upsampling
3.3.3. Residual Features Extraction
3.4. Classifier
4. Experiments
4.1. Dataset
4.1.1. Real Person Data
4.1.2. GAN-Generated Methods
4.2. Implementation Details
4.3. Results and Analysis
4.3.1. Ablation Study
Ablation Study in Hyper-Parameter Analysis
Ablation Study in Local Detection Branch
Ablation Study in Two Branches
4.3.2. Noise Study
4.3.3. Comparison with the Physical Approaches
4.3.4. Comparison with the State-of-the-Arts
Comparative Experiment
Experiments with Post-Processing Operations
5. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3677–3685. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Theobalt, C.; Stamminger, M.; Nießner, M. Headon: Real-time reenactment of human portrait videos. ACM Trans. Graph. (TOG) 2018, 37, 164. [Google Scholar] [CrossRef]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. (TOG) 2018, 37, 163. [Google Scholar] [CrossRef]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 66. [Google Scholar] [CrossRef]
- Lample, G.; Zeghidour, N.; Usunier, N.; Bordes, A.; Denoyer, L.; Ranzato, M.A. Fader networks: Manipulating images by sliding attributes. Adv. Neural Inf. Process. Syst. 2017, 30, 5967–5976. [Google Scholar]
- Averbuch-Elor, H.; Cohen-Or, D.; Kopf, J.; Cohen, M.F. Bringing portraits to life. ACM Trans. Graph. (TOG) 2017, 36, 196. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face Manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Nirkin, Y.; Wolf, L.; Keller, Y.; Hassner, T. DeepFake detection based on discrepancies between faces and their context. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6111–6121. [Google Scholar] [CrossRef]
- Hu, S.; Li, Y.; Lyu, S. Exposing GAN-generated Faces Using Inconsistent Corneal Specular Highlights. In Proceedings of the ICASSP 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2500–2504. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.S.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A.K. Detecting GAN generated fake images using co-occurrence matrices. Electron. Imaging 2019, 2019, 532-1–532-7. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, H. Manipulated face detector: Joint spatial and frequency domain attention network. arXiv 2020, arXiv:2005.02958. [Google Scholar]
- Wang, J.; Wu, Z.; Chen, J.; Han, X.; Chen, J.; Jiang, Y.G.; Li, S.N. M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection. arXiv 2021, arXiv:2104.09770. [Google Scholar]
- Ju, Y.; Jia, S.; Ke, L.; Xue, H.; Nagano, K.; Lyu, S. Fusing Global and Local Features for Generalized AI-Synthesized Image Detection. arXiv 2022, arXiv:2203.13964. [Google Scholar]
- Chen, B.; Tan, W.; Wang, Y.; Zhao, G. Distinguishing between Natural and GAN-Generated Face Images by Combining Global and Local Features. Chin. J. Electron. 2022, 31, 59–67. [Google Scholar]
- Zhao, X.; Yu, Y.; Ni, R.; Zhao, Y. Exploring Complementarity of Global and Local Spatiotemporal Information for Fake Face Video Detection. In Proceedings of the ICASSP 2022, Singapore, 23–27 May 2022; pp. 2884–2888. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Li, X.; Ji, S.; Wu, C.; Liu, Z.; Deng, S.; Cheng, P.; Yang, M.; Kong, X. A Survey on Deepfakes and Detection Techniques. J. Softw. 2021, 32, 496–518. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef]
- Verdoliva, D.C.G.P.L. Extracting camera-based fingerprints for video forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Camera-based Image Forgery Localization using Convolutional Neural Networks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; El-Gaaly, T.; Lim, S.N. Detecting deep-fake videos from appearance and behavior. In Proceedings of the 2020 IEEE International Workshop on Information Forensics and Security (WIFS), New York City, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar]
- Peng, B.; Fan, H.; Wang, W.; Dong, J.; Lyu, S. A Unified Framework for High Fidelity Face Swap and Expression Reenactment. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3673–3684. [Google Scholar] [CrossRef]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2823–2832. [Google Scholar]
- Zhang, Y.; Goh, J.; Win, L.L.; Thing, V.L. Image Region Forgery Detection: A Deep Learning Approach. SG-CRC 2016, 2016, 1–11. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image splicing localization using a multi-task fully convolutional network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef]
- Xuan, X.; Peng, B.; Wang, W.; Dong, J. On the generalization of GAN image forensics. In Proceedings of the Chinese Conference on Biometric Recognition, Zhuzhou, China, 12–13 October 2019; Springer: Cham, Switzerland, 2019; pp. 134–141. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do gans leave artificial fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Barni, M.; Kallas, K.; Nowroozi, E.; Tondi, B. CNN detection of GAN-generated face images based on cross-band co-occurrences analysis. In Proceedings of the 2020 IEEE International Workshop on Information Forensics and Security (WIFS), New York, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Mi, Z.; Jiang, X.; Sun, T.; Xu, K. Gan-generated image detection with self-attention mechanism against gan generator defect. IEEE J. Sel. Top. Signal Process. 2020, 14, 969–981. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot… for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Hu, J.; Liao, X.; Wang, W.; Qin, Z. Detecting Compressed Deepfake Videos in Social Networks Using Frame-Temporality Two-Stream Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1089–1102. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zheng, Y.; Zhao, G.; Shi, Y.Q. A robust GAN-generated face detection method based on dual-color spaces and an improved Xception. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3527–3538. [Google Scholar] [CrossRef]
- He, Y.; Yu, N.; Keuper, M.; Fritz, M. Beyond the spectrum: Detecting deepfakes via re-synthesis. arXiv 2021, arXiv:2105.14376. [Google Scholar]
- Zhang, M.; Wang, H.; He, P.; Malik, A.; Liu, H. Improving GAN-generated image detection generalization using unsupervised domain adaptation. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing Face Forgery Detection with High-frequency Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16317–16326. [Google Scholar]
- Wang, C.; Wang, Y.; Zhang, K.; Muhammad, J.; Lu, T.; Zhang, Q.; Tian, Q.; He, Z.; Sun, Z.; Zhang, Y.; et al. NIR iris challenge evaluation in non-cooperative environments: Segmentation and localization. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–10. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International conference on machine learning, Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.C.; Lyu, S. Eyes tell all: Irregular pupil shapes reveal GAN-generated faces. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2904–2908. [Google Scholar]
- Wikipedia. Ellipse[EB/OL]. Available online: https:en.wikipedia.org/wiki/Ellipse#Parameters (accessed on 24 December 2022).
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Liu, Z.; Qi, X.; Torr, P.H.S. Global texture enhancement for fake face detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8060–8069. [Google Scholar]
- Wang, X.; Guo, H.; Hu, S.; Chang, M.C.; Lyu, S. Gan-generated faces detection: A survey and new perspectives. arXiv 2022, arXiv:2202.07145. [Google Scholar]
- Yang, X.; Li, Y.; Qi, H.; Lyu, S. Exposing GAN-synthesized faces using landmark locations. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019; pp. 113–118. [Google Scholar]
- Gragnaniello, D.; Cozzolino, D.; Marra, F.; Poggi, G.; Verdoliva, L. Are GAN generated images easy to detect? A critical analysis of the state-of-the-art. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 3 | 5 | 7 | 9 | |
|---|---|---|---|---|---|
| ProGAN | 78.9 | 83.3 | 93.4 | 81.4 | 62.9 |
| StyleGAN | 74.3 | 81.9 | 90.6 | 79.2 | 61.3 |
| Avg | 76.6 | 82.6 | 92.0 | 80.3 | 62.1 |
| 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | |
|---|---|---|---|---|---|
| ProGAN | 65.2 | 70.3 | 84.3 | 90.4 | 84.1 |
| StyleGAN | 77.6 | 80.9 | 81.2 | 87.5 | 79.6 |
| Avg | 71.4 | 75.6 | 82.8 | 89.0 | 81.9 |
| 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | |
|---|---|---|---|---|---|
| ProGAN | 62.1 | 84.1 | 91.9 | 80.4 | 75.1 |
| StyleGAN | 73.3 | 76.4 | 86.8 | 74.5 | 73.3 |
| Avg | 67.7 | 80.3 | 89.4 | 77.5 | 74.2 |
| ProGAN | ICD | PSE | LRD (All) | |||
| Num | ACC | Num | ACC | Num | ACC | |
| Raw | 2335 | 93.4 | 2298 | 91.9 | 2377 | 95.1 |
| +R | 2341 | 93.6 | 2219 | 88.8 | 2376 | 95.0 |
| +E | 2312 | 92.8 | 2276 | 91.0 | 2301 | 92.0 |
| +A | 2350 | 94.0 | 2197 | 87.9 | 2344 | 93.8 |
| +P | 2306 | 92.2 | 2284 | 91.4 | 2219 | 94.7 |
| StyleGAN | ICD | PSE | LRD (All) | |||
| Num | ACC | Num | ACC | Num | ACC | |
| Raw | 2266 | 90.6 | 2165 | 86.6 | 2316 | 92.6 |
| +R | 2288 | 91.5 | 2210 | 88.4 | 2341 | 93.6 |
| +E | 2212 | 88.5 | 2179 | 87.2 | 2237 | 89.5 |
| +A | 2238 | 89.5 | 2244 | 89.8 | 2167 | 86.7 |
| +P | 2178 | 87.1 | 2152 | 86.1 | 2210 | 88.4 |
| Branch | ProGAN-Raw | StyleGAN-Raw |
|---|---|---|
| LRD | 95.08% | 92.64% |
| GD | 99.29% | 99.97% |
| Dual | 100% | 100% |
| Method | ProGAN -> ProGAN | StyleGAN -> StyleGAN | ||||||||||
| Raw | +R | +E | +A | +P | Avg | Raw | +R | +E | +A | +P | Avg | |
| PRNU [16] | 78.3 | 57.1 | 63.5 | 53.2 | 51.3 | 60.7 | 76.5 | 68.8 | 75.2 | 63 | 61.9 | 69.1 |
| FFT-2d magnitude [50] | 99.9 | 95.9 | 81.8 | 99.9 | 59.8 | 87.5 | 100 | 90.8 | 72 | 99.4 | 57.7 | 84.0 |
| GramNet [51] | 100 | 77.1 | 100 | 77.7 | 69 | 84.8 | 100 | 96.3 | 100 | 96.3 | 73.3 | 93.2 |
| Re-Synthesis [37] | 100 | 100 | 100 | 99.7 | 64.5 | 92.8 | 100 | 98.7 | 100 | 99.9 | 66.7 | 93.1 |
| GLFNet (LRD) | 95.1 | 95.0 | 92.0 | 93.8 | 88.8 | 92.9 | 92.6 | 93.6 | 89.5 | 86.7 | 88.4 | 90.2 |
| GLFNet (GD) | 99.3 | 98.2 | 98.2 | 98.1 | 89.2 | 96.4 | 100 | 98.3 | 99.8 | 97.2 | 73.4 | 93.7 |
| GLFNet (Dual) | 100 | 100 | 100 | 99.9 | 86.1 | 97.2 | 100 | 99.1 | 100 | 100 | 82.3 | 96.3 |
| Method | ProGAN -> StyleGAN | StyleGAN -> ProGAN | ||||||||||
| Raw | +R | +E | +A | +P | Avg | Raw | +R | +E | +A | +P | Avg | |
| PRNU [16] | 47.4 | 44.8 | 45.3 | 44.2 | 48.9 | 46.1 | 48 | 55.1 | 53.6 | 51.1 | 53.6 | 52.3 |
| FFT-2d magnitude [50] | 98.9 | 99.8 | 63.2 | 61.1 | 56.8 | 76.0 | 77.5 | 54.6 | 56.5 | 76.5 | 55.5 | 64.1 |
| GramNet [51] | 64 | 57.3 | 63.7 | 50.9 | 57.1 | 58.6 | 63.1 | 56.4 | 63.8 | 66.8 | 56.2 | 61.3 |
| Re-Synthesis [37] | 100 | 97.8 | 99.9 | 99.8 | 67.0 | 92.9 | 99.5 | 99.9 | 99.8 | 100 | 66.1 | 93.1 |
| GLFNet (LRD) | 92.5 | 92.1 | 88.3 | 90.0 | 90.3 | 90.6 | 94.5 | 93.7 | 91.2 | 93.7 | 83.6 | 91.3 |
| GLFNet (GD) | 99 | 96.8 | 97.8 | 98.7 | 82.3 | 94.9 | 97.8 | 96.3 | 92.1 | 99.4 | 74.7 | 92.1 |
| GLFNet (Dual) | 100 | 98.0 | 100 | 99.8 | 88.9 | 97.3 | 99.6 | 99.7 | 100 | 100 | 83.7 | 96.6 |
| Method | Real Face | GAN Face | AUC | |
|---|---|---|---|---|
| Hu’s Method [14] | FFHQ (500) | StyleGAN2 (500) | 0.94 | |
| Guo’s Method [48] | FFHQ (1.6K) | StyleGAN2 (1.6K) | 0.91 | |
| Matern’s Method [12] | CelebA (1K) | ProGAN (1K) | 0.76–0.85 | |
| Yang’s Method [58] | CelebA (≥50K) | ProGAN (25K) | 0.91–0.94 | |
| GLFNet (Dual) | FFHQ (1K) | raw | StyleGAN2 (1K) | 0.96 |
| u-s | 0.88 | |||
| d-s | 0.82 | |||
| CelebA (1K) | raw | ProGAN (1K) | 0.88 | |
| u-s | 0.81 | |||
| d-s | 0.79 | |||
| CelebA (≥50K) | raw | ProGAN (25K) | 0.95 | |
| u-s | 0.90 | |||
| d-s | 0.87 | |||
| Methods | ProGAN | StyleGAN (FFHQ) | StyleGAN2 |
|---|---|---|---|
| Mi’s Method [37] | 99.7 | 50.4 | 50.1 |
| Chen’s Method [40] | 99.8 | 61.5 | 63.7 |
| Gragnaniello’s Method [59] | 97.1 | 96.6 | 96.9 |
| Zhang’s Method [42] | 99.8 | 97.4 | 97.7 |
| GLFNet (Dual) | 99.8 | 98.4 | 99.1 |
| Methods/ Variate | JPEG Compression/ Compression Quality | Gamma Correction/ Gamma | Median Blurring/ Kernel Size | ||||||
| 90 | 70 | 50 | 1.1 | 1.4 | 1.7 | 3 × 3 | 5 × 5 | 7 × 7 | |
| Xception [36] | 96.9 | 90.1 | 81.5 | 98.9 | 98.2 | 95.4 | 94.8 | 76.6 | 65.6 |
| GramNet [56] | 89.8 | 70.3 | 65.8 | 95.5 | 93.4 | 92.2 | 78.5 | 68.3 | 64.2 |
| Mi’s Method [37] | 97.8 | 90.2 | 83.2 | 99.9 | 99.5 | 98.3 | 80.1 | 73.2 | 63.2 |
| Chen’s Method [40] | 99.5 | 96.6 | 89.4 | 99.6 | 99.6 | 98.5 | 98.4 | 87.5 | 76.8 |
| GLFNet (Dual) | 99.6 | 96.8 | 91.4 | 99.5 | 99.8 | 98.6 | 98.5 | 87.6 | 79.1 |
| Methods/ Variate | Gaussian Blurring/ Kernel Size | Gaussian Noising/ Standard Deviation | Resizing/ Upscaling | ||||||
| 3 × 3 | 5 × 5 | 7 × 7 | 3 | 5 | 7 | 1% | 3% | 5% | |
| Xception [36] | 96.4 | 90.8 | 80.7 | 98.2 | 97.1 | 92.5 | 79.3 | 52.9 | 50.0 |
| GramNet [56] | 94.5 | 89.8 | 79.5 | 97.2 | 94.6 | 88.7 | 91.2 | 70.5 | 60.4 |
| Mi’s Method [37] | 95.2 | 90.1 | 80.9 | 99.1 | 80.1 | 68.7 | 89.3 | 65.2 | 56.7 |
| Chen’s Method [40] | 98.3 | 96.3 | 85.2 | 99.7 | 99.5 | 94.3 | 97.2 | 88.5 | 71.3 |
| GLFNet (Dual) | 99.2 | 96.9 | 88.3 | 99.9 | 99.4 | 95.4 | 98.1 | 89.2 | 72.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, Z.; Jiang, X.; Liu, Q.; Wei, Z. Global–Local Facial Fusion Based GAN Generated Fake Face Detection. Sensors 2023, 23, 616. https://doi.org/10.3390/s23020616
Xue Z, Jiang X, Liu Q, Wei Z. Global–Local Facial Fusion Based GAN Generated Fake Face Detection. Sensors. 2023; 23(2):616. https://doi.org/10.3390/s23020616
Chicago/Turabian StyleXue, Ziyu, Xiuhua Jiang, Qingtong Liu, and Zhaoshan Wei. 2023. "Global–Local Facial Fusion Based GAN Generated Fake Face Detection" Sensors 23, no. 2: 616. https://doi.org/10.3390/s23020616
APA StyleXue, Z., Jiang, X., Liu, Q., & Wei, Z. (2023). Global–Local Facial Fusion Based GAN Generated Fake Face Detection. Sensors, 23(2), 616. https://doi.org/10.3390/s23020616