
Research on Fatigued-Driving Detection Method by Integrating Lightweight YOLOv5s and Facial 3D Keypoints

Abstract
:1. Introduction
2. Design of Face-Feature Detection Network
2.1. The Basic Architecture of YOLOv5s
- (1)
- Input: Adopting Mosaic data augmentation, adaptive image scaling, and anchor box computation to enhance model training speed and reduce redundant information.
- (2)
- Backbone Network: By introducing the CBS convolutional structure and C3 module, the backbone network can perform targeted downsampling, selectively preserving detailed information of the target features, and effectively preventing degradation of network performance.
- (3)
- Feature Fusion Network (Neck): The FPN [23] and PAN [24] structures can enhance the network’s feature-fusion capability, reduce information loss during downsampling, and achieve effective fusion of information at different scales, enriching the texture information of shallow features and the semantic structure of deep features.
- (4)
- Prediction: The CIoU [25] loss function is used, which considers the area overlap, aspect ratio, and center point distance between the ground truth box and the predicted box. This ensures a good fit for width and height even when the center points of the ground truth and predicted boxes overlap or are very close. The predicted redundant information is then filtered using NMS (non-maximum suppression) to enhance the effective detection of the target region.
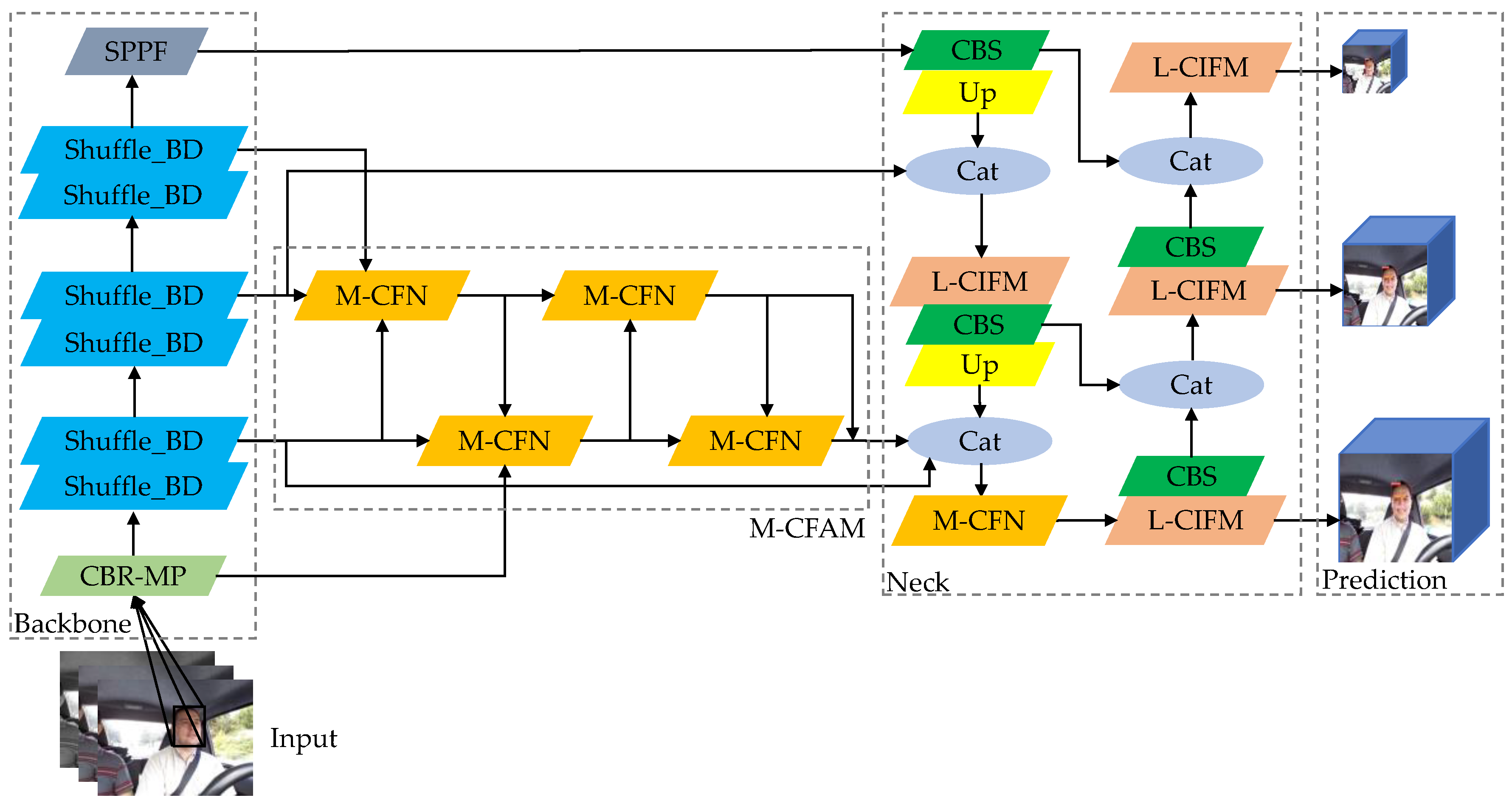
2.2. Face Feature Extraction Network of Improved YOLOv5s
2.2.1. Feature Extraction Backbone
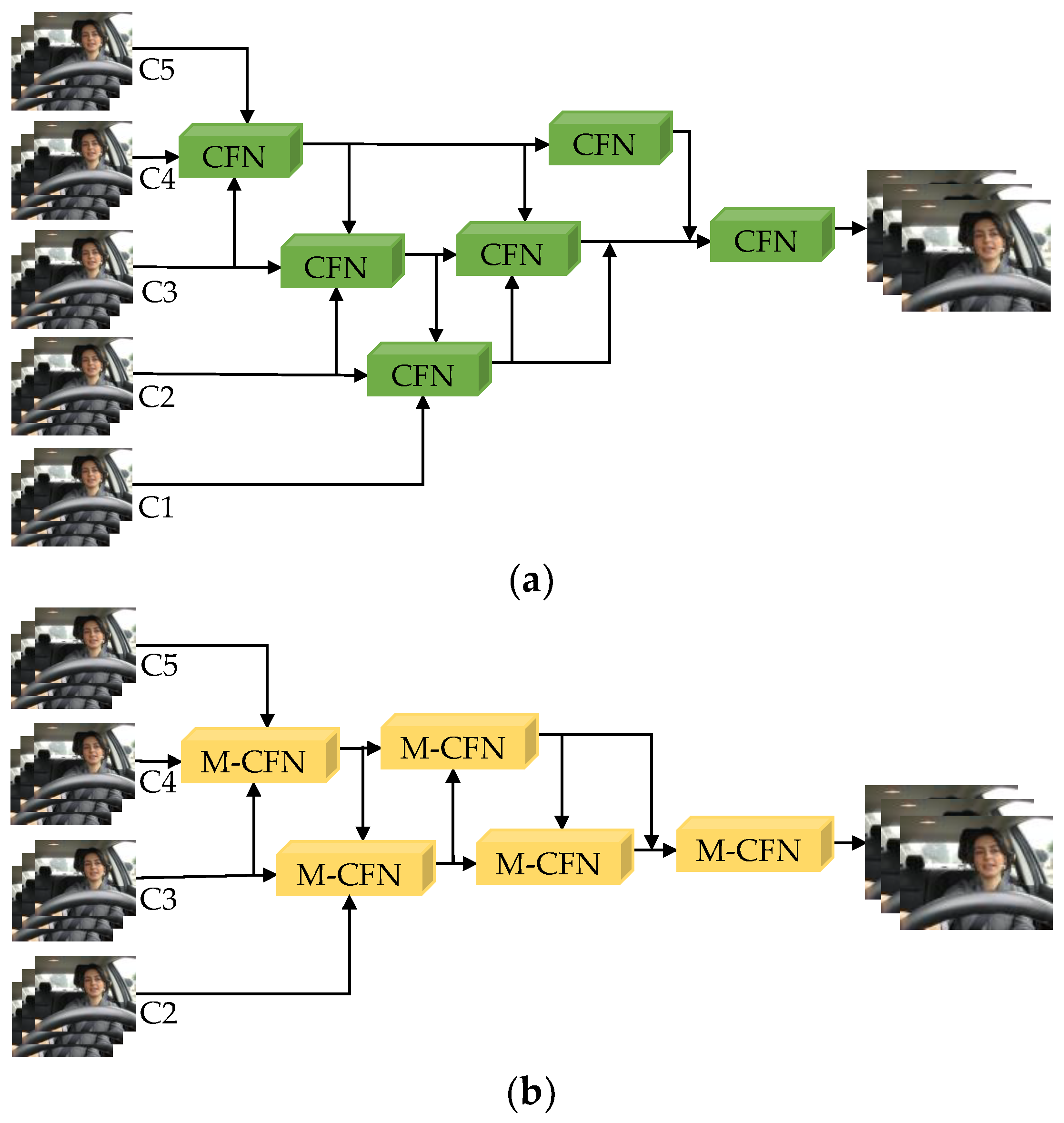
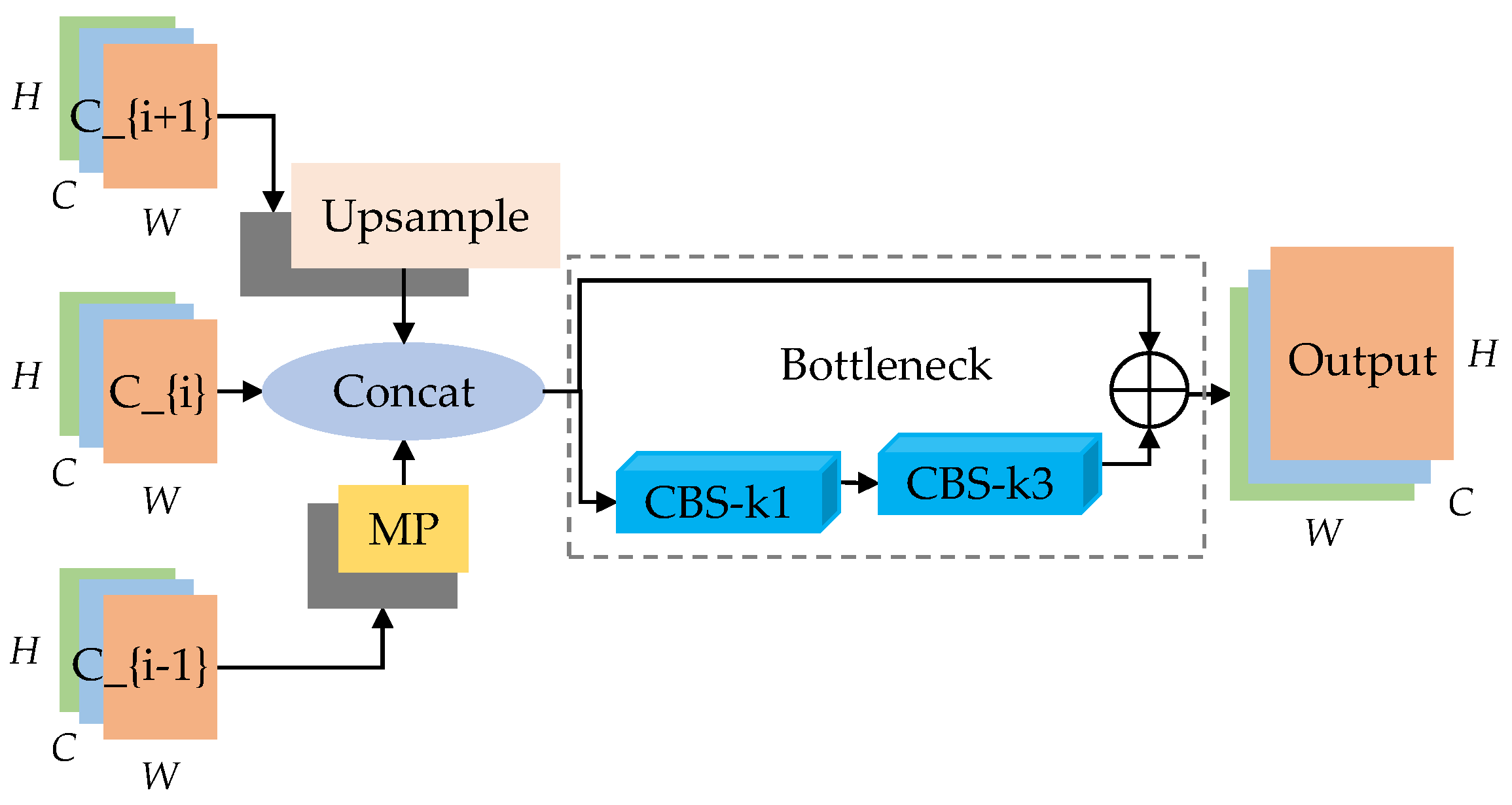
2.2.2. Maxpool Cross-Scale Feature Aggregation
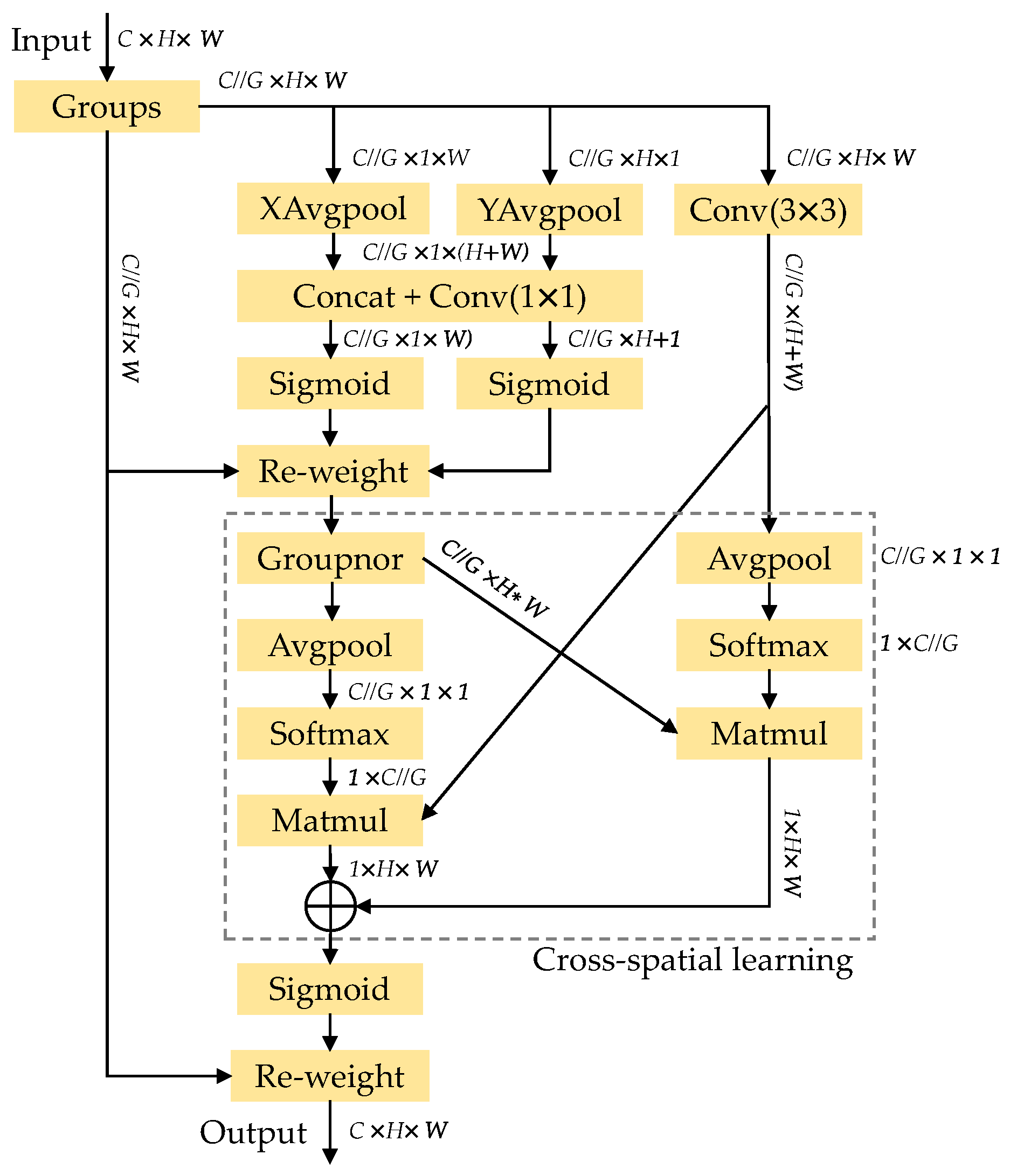
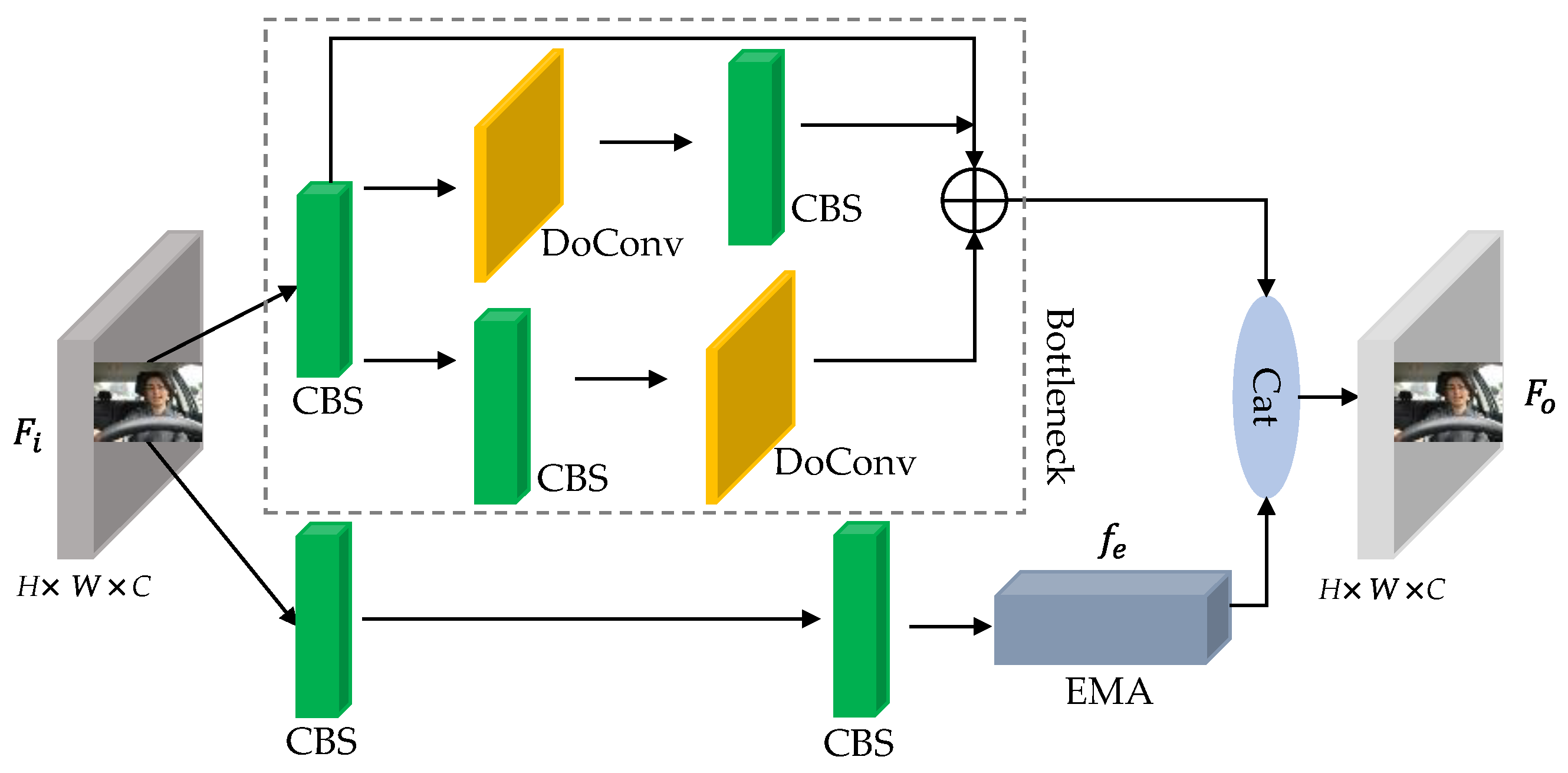
2.2.3. Lightweight Contextual Information Fusion Module
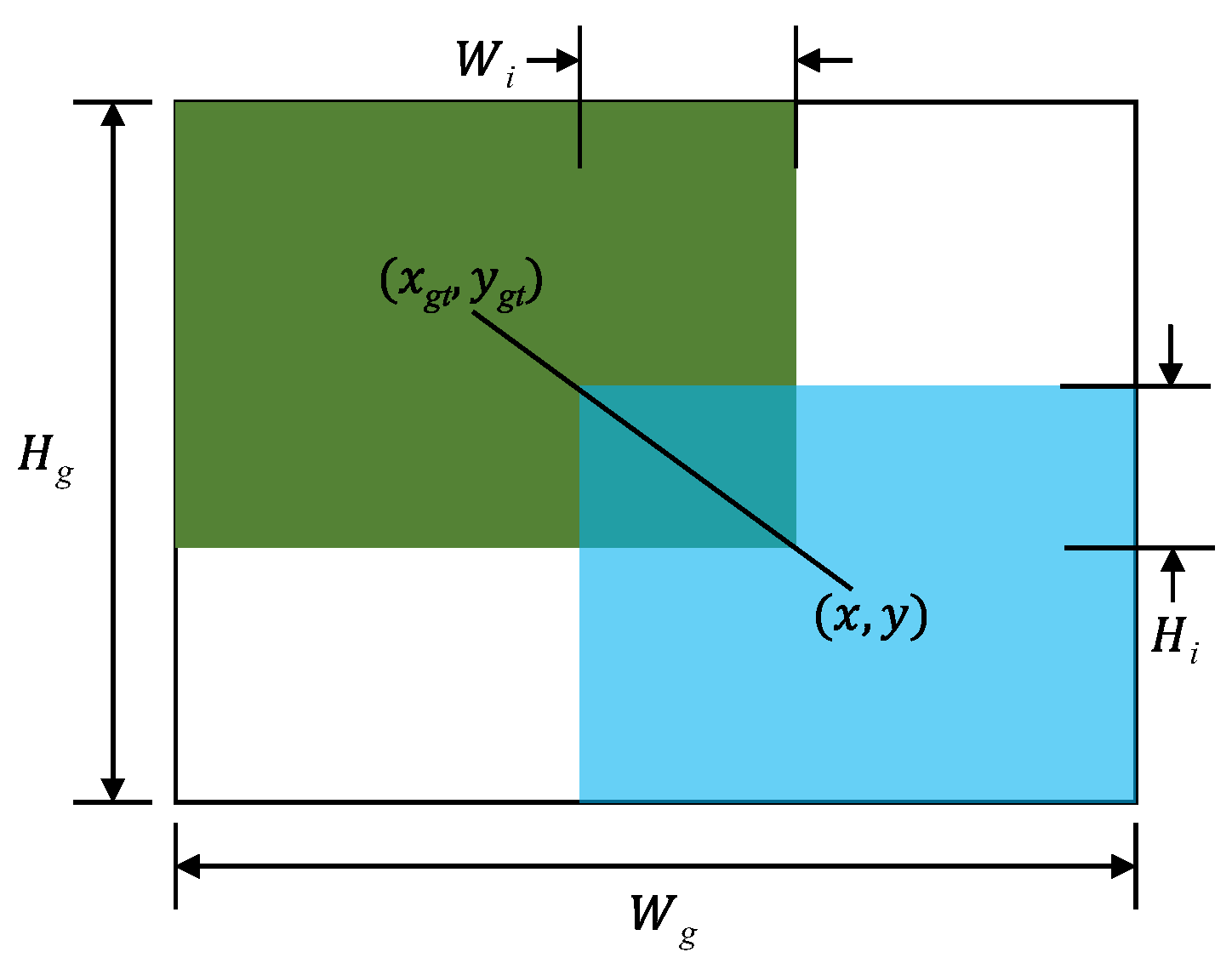
2.2.4. Improvement of Loss Function
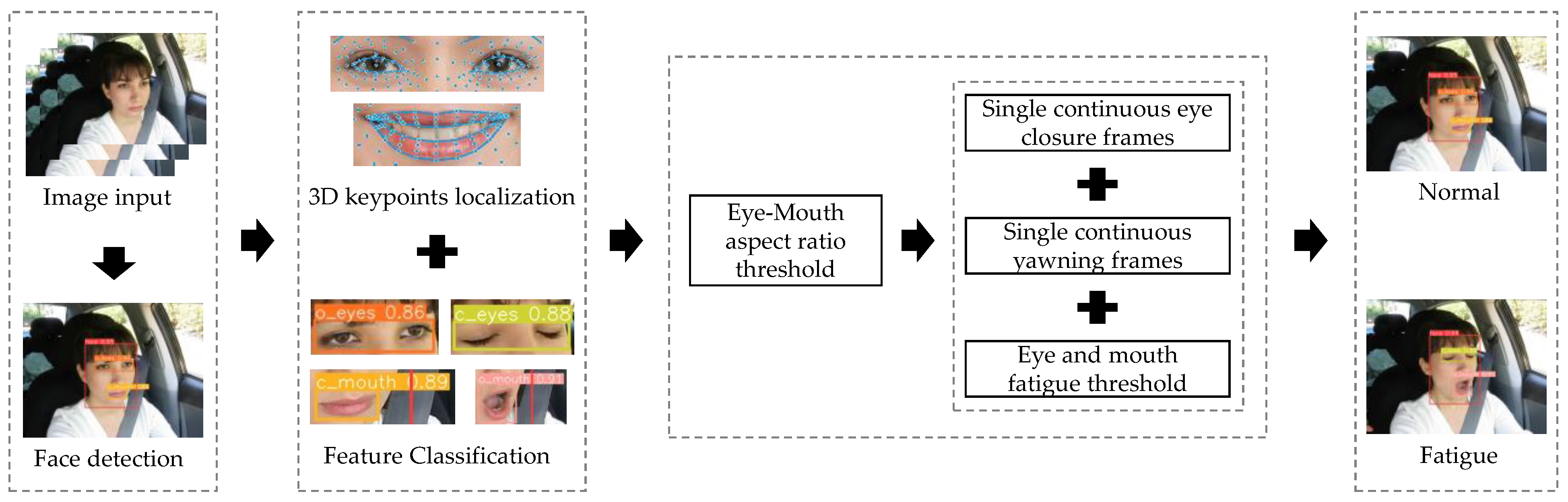
3. Keypoints Extraction and Fatigue-Judgment Model Construction
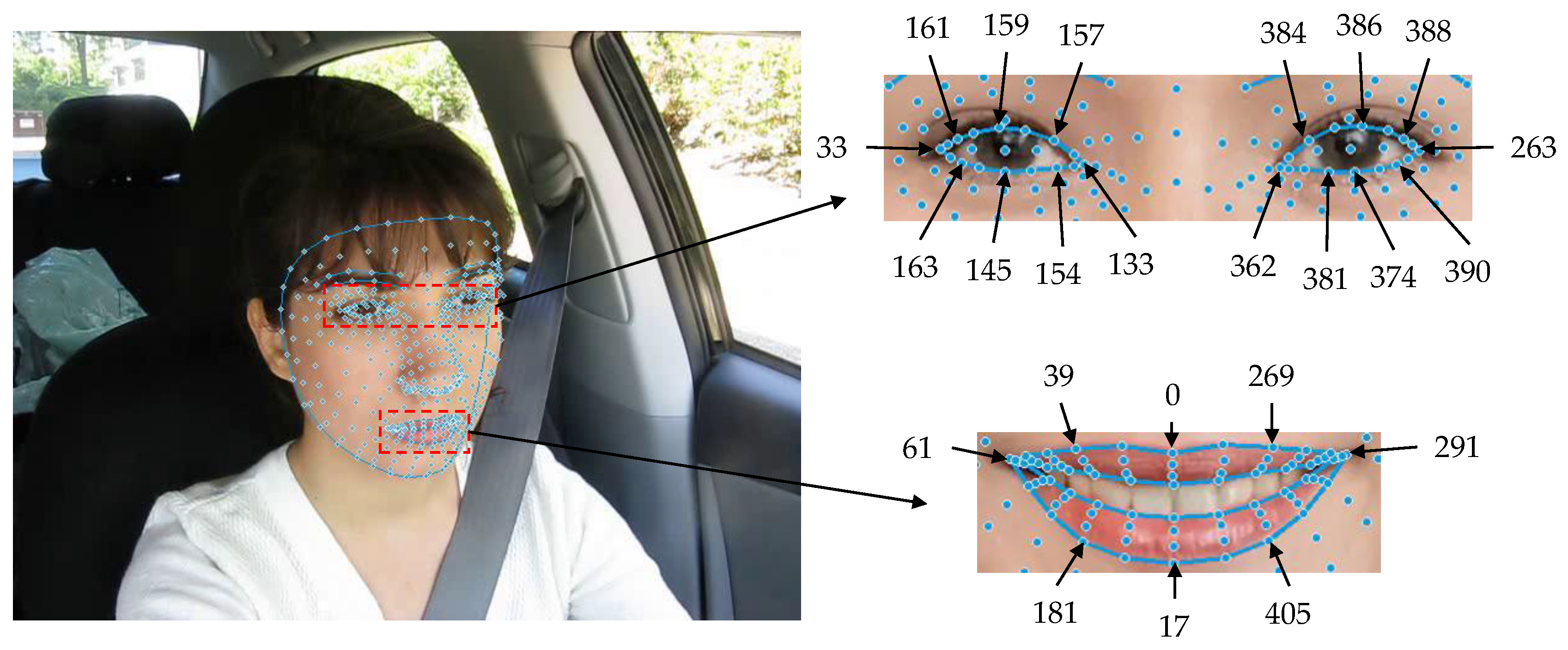
3.1. Extraction of 3D Facial Keypoints
3.2. Fatigued-Driving Detection Model with Feature Fusion
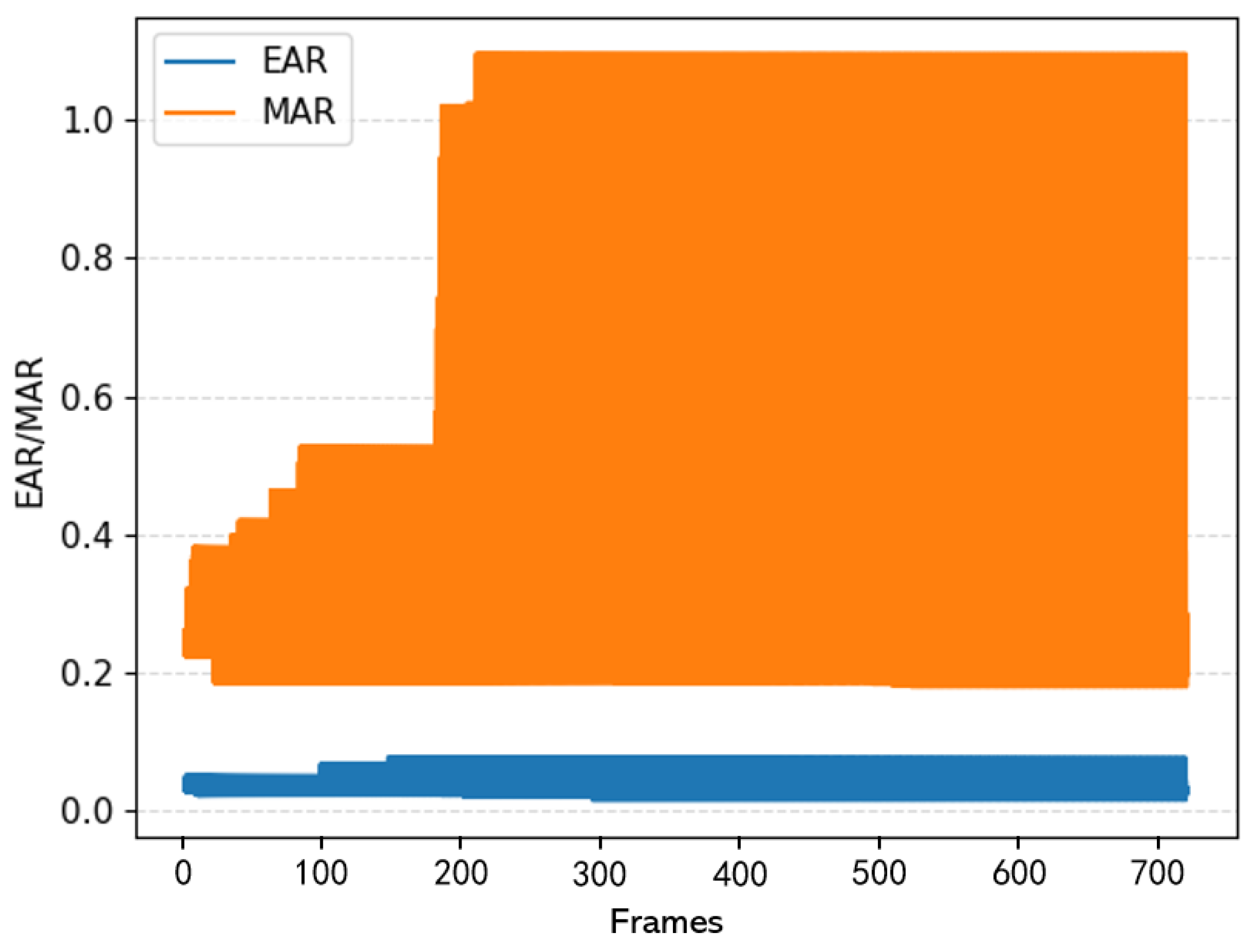
3.2.1. Eye-Mouth Aspect Ratio and the Determination of Its Threshold
3.2.2. The Number of Frames of Continuous Eye Closure and Yawning in a Single Instance
3.2.3. PERCLOS Criteria and the Determination of Its Threshold
4. Analysis of Experimental Results
4.1. Dataset and Experimental Conditions
4.2. Face-Feature Detection Experimental Analysis
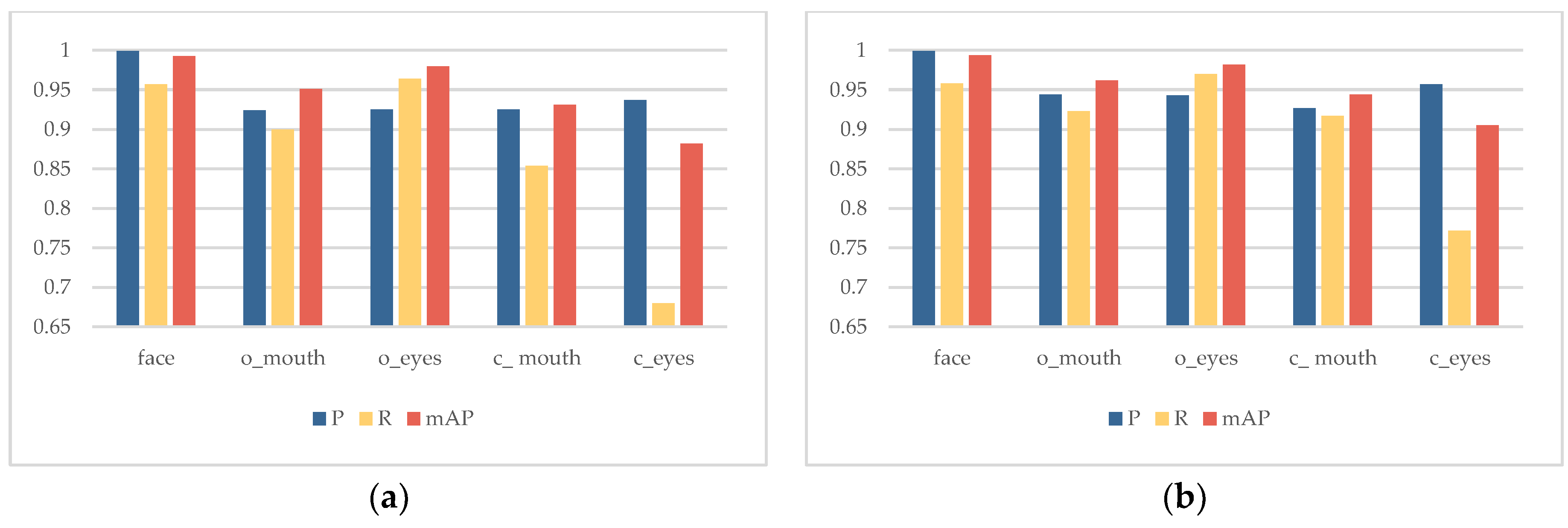
4.2.1. Evaluation Indicators
4.2.2. Comparison of Main Branch Refactoring Experiment
4.2.3. Ablation Experiment
4.2.4. Horizontal Network Comparison Experiment
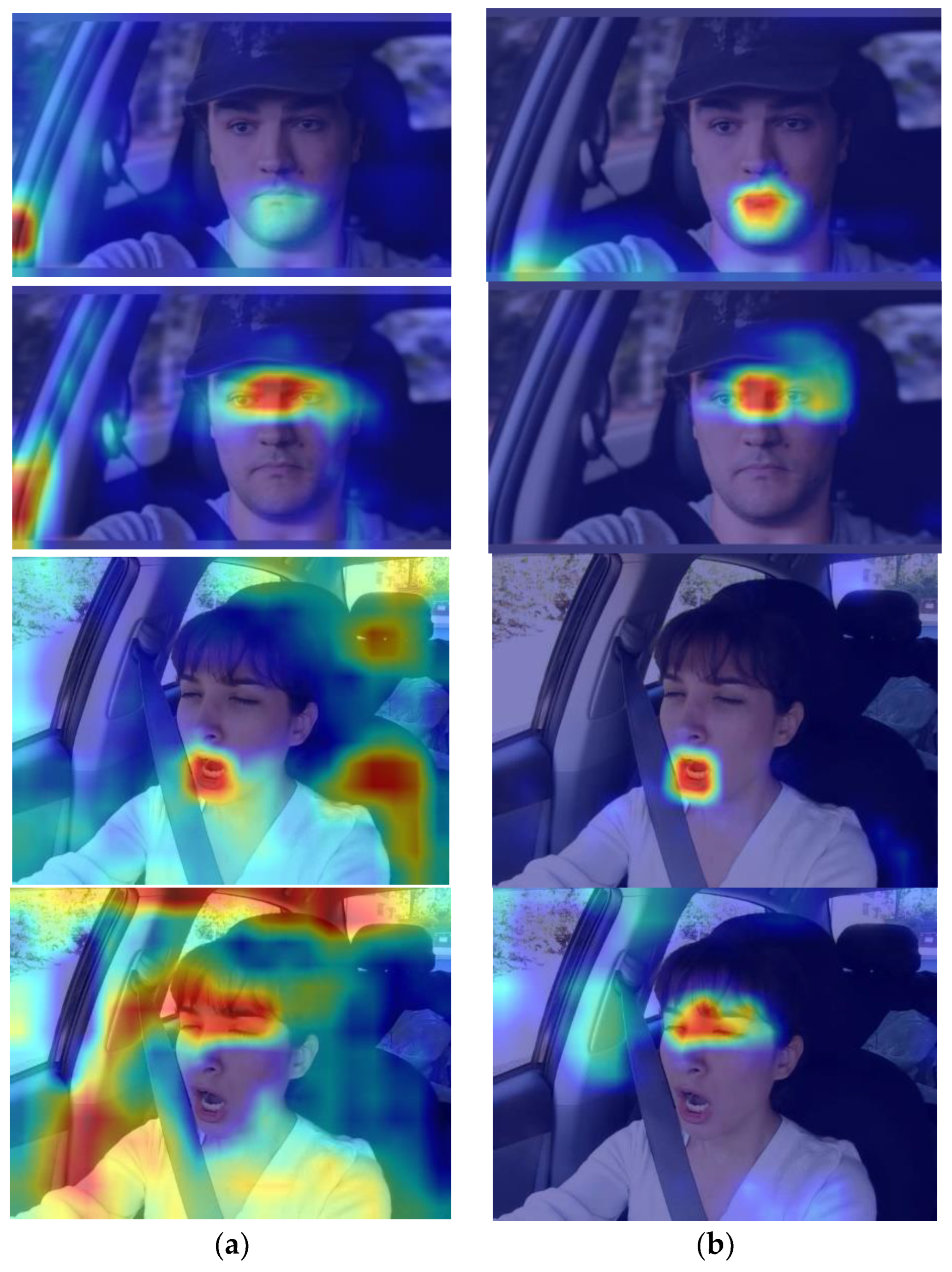
4.3. Fatigue Sample Test Result Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amodio, A.; Ermidoro, M.; Maggi, D.; Formentin, S.; Savaresi, S.M. Automatic detection of driver impairment based on pupillary light reflex. IEEE Trans. Intell. Transp. 2018, 20, 3038–3048. [Google Scholar] [CrossRef]
- Sikander, G.; Anwar, S. Driver fatigue detection systems: A review. IEEE Trans. Intell. Transp. 2018, 20, 2339–2352. [Google Scholar] [CrossRef]
- Chai, M. Drowsiness monitoring based on steering wheel status. Transp. Res. D Trans. Environ. 2019, 66, 95–103. [Google Scholar] [CrossRef]
- Jeon, Y.; Kim, B.; Baek, Y. Ensemble CNN to detect drowsy driving with in-vehicle sensor data. Sensors 2021, 21, 2372. [Google Scholar] [CrossRef]
- Xi, J.; Wang, S.; Ding, T.; Tian, J.; Shao, H.; Miao, X. Detection Model on Fatigue Driving Behaviors Based on the Operating Parameters of Freight Vehicles. Appl. Sci. 2021, 11, 7132. [Google Scholar] [CrossRef]
- Zhang, G.; Etemad, A. Capsule attention for multimodal EEG-EOG representation learning with application to driver vigilance estimation. IEEE Trans. Neural System. Rehabil. 2021, 29, 1138–1149. [Google Scholar] [CrossRef]
- Satti, A.T.; Kim, J.; Yi, E.; Cho, H.Y.; Cho, S. Microneedle array electrode-based wearable EMG system for detection of driver drowsiness through steering wheel grip. Sensors 2021, 21, 5091. [Google Scholar] [CrossRef]
- Qiu, X.; Tian, F.; Shi, Q.; Zhao, Q.; Hu, B. Designing and application of wearable fatigue detection system based on multimodal physiological signals. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 716–722. [Google Scholar]
- Dinges, D.F.; Grace, R. PERCLOS: A Valid Psychophysiological Measure of Alertness as Assessed by Psychomotor Vigilance; USA Department of Transportation Federal Highway Administration: Washington, DC, USA, 1998. [Google Scholar]
- Dziuda, Ł.; Baran, P.; Zieliński, P.; Murawski, K.; Dziwosz, M.; Krej, M.; Piotrowski, M.; Stablewski, R.; Wojdas, A.; Strus, W.; et al. Evaluation of a fatigue detector using eye closure-associated indicators acquired from truck drivers in a simulator study. Sensors 2021, 21, 6449. [Google Scholar] [CrossRef]
- Alioua, N.; Amine, A.; Rziza, M. Driver’s fatigue detection based on yawning extraction. Int. J. Veh. Technol. 2014, 2014, 678786. [Google Scholar] [CrossRef]
- Zhang, W.; Su, J. Driver yawning detection based on long short term memory networks. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–5. [Google Scholar]
- Knapik, M.; Cyganek, B. Driver’s fatigue recognition based on yawn detection in thermal images. Neurocomputing 2019, 338, 274–292. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal. Proc. Let. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Deng, W.; Zhan, Z.; Yu, Y.; Wang, W. Fatigue Driving Detection Based on Multi Feature Fusion. In Proceedings of the IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 407–411. [Google Scholar]
- Liu, W.; Tang, M.; Wang, C.; Zhang, K.; Wang, Q.; Xu, X. Attention-guided Dual Enhancement Train Driver Fatigue Detection Based on MTCNN. In Proceedings of the International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 10–12 December 2021; pp. 1324–1329. [Google Scholar]
- Liu, Z.; Peng, Y.; Hu, W. Driver fatigue detection based on deeply-learned facial expression representation. J. Vis. Commun. Image R. 2020, 71, 102723. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, H.; Huang, J. Driver fatigue state detection based on facial key points. In Proceedings of the International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 144–149. [Google Scholar]
- Li, K.; Gong, Y.; Ren, Z. A fatigue driving detection algorithm based on facial multi-feature fusion. IEEE Access. 2020, 8, 101244–101259. [Google Scholar] [CrossRef]
- Babu, A.; Nair, S.; Sreekumar, K. Driver’s drowsiness detection system using Dlib HOG. In Ubiquitous Intelligent Systems; Karuppusamy, P., Perikos, I., García Márquez, F.P., Eds.; Springer: Singapore, 2022; Volume 243, pp. 219–229. [Google Scholar]
- Cai, J.; Liao, X.; Bai, J.; Luo, Z.; Li, L.; Bai, J. Face Fatigue Feature Detection Based on Improved D-S Model in Complex Scenes. IEEE Access. 2023, 11, 101790–101798. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the Computer Vision-ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Springer-Verlag: Berlin/Heidelberg, Germany, 2018; pp. 122–138. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Cao, J.; Li, Y.; Sun, M.; Chen, Y.; Lischinski, D.; Cohen-Or, D.; Chen, B.; Tu, C. Do-conv: Depthwise over-parameterized convolutional layer. IEEE Trans. Image Process. 2022, 31, 3726–3736. [Google Scholar] [CrossRef] [PubMed]
- Guo, X. A novel Multi to Single Module for small object detection. arXiv 2023, arXiv:2303.14977. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the Computer Vision-ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 404–419. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Grishchenko, I.; Ablavatski, A.; Kartynnik, Y.; Raveendran, K.; Grundmann, M. Attention mesh: High-fidelity face mesh prediction in real-time. arXiv 2020, arXiv:2006.10962. [Google Scholar]
- Soukupova, T.; Cech, J. Real-time eye blink detection using facial landmarks. In Proceedings of the 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia, 3–5 February 2016; pp. 1–8. [Google Scholar]
- Abtahi, S.; Omidyeganeh, M.; Shirmohammadi, S.; Hariri, B. YawDD: A yawning detection dataset. In Proceedings of the 5th ACM Multimedia Systems Conference, Singapore, 19–21 March 2014; pp. 24–28. [Google Scholar]
- Gallup, A.C.; Church, A.M.; Pelegrino, A.J. Yawn duration predicts brain weight and cortical neuron number in mammals. Biol. Lett. 2016, 12, 20160545. [Google Scholar] [CrossRef] [PubMed]
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver drowsiness detection via a hierarchical temporal deep belief network. In Proceedings of the Computer Vision-ACCV 2016 Workshops: ACCV 2016 International Workshops, Taipei, China, 20–24 November 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 117–133. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Ji, Y.; Wang, S.; Zhao, Y.; Wei, J.; Lu, Y. Fatigue state detection based on multi-index fusion and state recognition network. IEEE Access. 2019, 7, 64136–64147. [Google Scholar] [CrossRef]
- Liu, W.; Qian, J.; Yao, Z.; Jiao, X.; Pan, J. Convolutional Two-Stream Network Using Multi-Facial Feature Fusion for Driver Fatigue Detection. Future Internet 2019, 11, 115. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Details |
|---|---|
| CPU | Xeon (R) Platinum 8255C |
| GPU | RTX 2080Ti (11 GB) |
| Memory | 40 GB |
| Deep learning framework | Pytorch 1.11.0 |
| Programming language | Python 3.8 |
| GPU acceleration tool | CUDA 11.3 |
| Method | mAP | FLOPs/G | Params | Size [MB] |
|---|---|---|---|---|
| YOLOv5s | 0.947 | 15.8 | 7.02 M | 14.4 |
| Shufflenetv2 | 0.918 | 5.9 | 3.24 M | 6.8 |
| Shufflenetv2_BD | 0.927 | 5.9 | 3.36 M | 7.0 |
| YOLOv5s+Shufflenetv2_BD | L-CAM | L-CIFM | WIoU | AP50 | mAP | FLOPs/G | Params | Size [MB] |
|---|---|---|---|---|---|---|---|---|
| 0.938 | 0.947 | 15.8 | 7.02 M | 14.4 | ||||
| √ | 0.940 | 0.927 | 5.9 | 3.36 M | 7.0 | |||
| √ | √ | 0.958 | 0.953 | 7.5 | 3.44 M | 7.2 | ||
| √ | √ | 0.943 | 0.948 | 4.3 | 2.74 M | 5.9 | ||
| √ | √ | 0.946 | 0.932 | 5.9 | 3.36 M | 7.0 | ||
| √ | √ | √ | 0.953 | 0.950 | 5.9 | 2.95 M | 6.3 | |
| √ | √ | √ | √ | 0.955 | 0.957 | 5.9 | 2.95 M | 6.3 |
| Classes | Quantity | Correctly Identify the Number | Accuracy |
|---|---|---|---|
| face | 50,000 | 49,850 | 0.997 |
| o_mouth | 22,383 | 22,025 | 0.984 |
| o_eyes | 28,850 | 28,590 | 0.991 |
| c_mouth | 26,899 | 26,280 | 0.977 |
| c_eyes | 19,517 | 18,834 | 0.965 |
| Comprehensive | 147,649 | 145,579 | 0.986 |
| Method | mAP | FLOPs/G | Params | Size [MB] |
|---|---|---|---|---|
| SDD | 0.774 | 28.4 | 20.52 M | 105.1 |
| YOLOv3-Tiny | 0.876 | 13.1 | 8.72 M | 51.4 |
| YOLOv4-Tiny | 0.881 | 3.4 | 6.06 M | 22.4 |
| YOLOv5n | 0.928 | 4.1 | 1.77 M | 3.8 |
| YOLOv7-Tiny | 0.956 | 13.1 | 6.02 M | 12.3 |
| YOLOv8s | 0.977 | 28.8 | 11.20 M | 23.7 |
| YOLOv5s | 0.949 | 15.8 | 7.02 M | 14.4 |
| Ours | 0.957 | 5.9 | 2.95 M | 6.3 |
| Method | Category | Quantity | Correctly Identify the Number | Error Category | Accuracy |
|---|---|---|---|---|---|
| Normal | 45 | 45 | - | 1 | |
| Speaking | 45 | 43 | Tired eyes + yawning | 0.956 | |
| Ours | Eye fatigue | 15 | 13 | Normal | 0.867 |
| Yawning fatigue | 30 | 29 | Normal | 0.967 | |
| Comprehensive | 135 | 130 | - | 0.963 | |
| Normal | 110 | 67 | Tired eyes + yawning | 0.609 | |
| Speaking | 100 | 97 | Tired eyes + yawning | 0.970 | |
| Reference [39] | Eye fatigue | 33 | 23 | Normal | 0.696 |
| Yawning fatigue | 82 | 19 | Normal | 0.231 | |
| Comprehensive | 325 | 206 | - | 0.634 | |
| Normal | 10,291 | 9643 | Tired yawning | 0.937 | |
| Speaking | 12,904 | 12,614 | Tired yawning | 0.978 | |
| Reference [40] | Eye fatigue | - | - | - | - |
| Yawning fatigue | 21,643 | 21,234 | Normal | 0.981 | |
| Comprehensive | 44,838 | 43,491 | - | 0.970 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, X.; He, S.; Li, R. Research on Fatigued-Driving Detection Method by Integrating Lightweight YOLOv5s and Facial 3D Keypoints. Sensors 2023, 23, 8267. https://doi.org/10.3390/s23198267
Ran X, He S, Li R. Research on Fatigued-Driving Detection Method by Integrating Lightweight YOLOv5s and Facial 3D Keypoints. Sensors. 2023; 23(19):8267. https://doi.org/10.3390/s23198267
Chicago/Turabian StyleRan, Xiansheng, Shuai He, and Rui Li. 2023. "Research on Fatigued-Driving Detection Method by Integrating Lightweight YOLOv5s and Facial 3D Keypoints" Sensors 23, no. 19: 8267. https://doi.org/10.3390/s23198267
APA StyleRan, X., He, S., & Li, R. (2023). Research on Fatigued-Driving Detection Method by Integrating Lightweight YOLOv5s and Facial 3D Keypoints. Sensors, 23(19), 8267. https://doi.org/10.3390/s23198267