
Graph Reinforcement Learning-Based Decision-Making Technology for Connected and Autonomous Vehicles: Framework, Review, and Future Trends


Abstract
:1. Introduction
- A systematic review of the GRL-based methods for decision-making is presented based on the technical structure of the proposed GRL framework. Related works are clearly summarized in tables for appropriate comparisons.
- A generic GRL framework for the decision-making technology of CAVs in mixed autonomy traffic is proposed. The corresponding elements and functions in the framework are explained in detail.
- Validation methods including evaluation metrics and simulation tools that can be used for the decision-making technology in autonomous vehicles are discussed and summarized for the validation of future related research.
- Challenges and future research topics of the GRL-based methods for decision-making of CAVs are discussed based on the current research status.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronyms | Description |
|---|---|
| CAV | Connected and Automated Vehicle |
| HV | Human Vehicle |
| RL | Reinforcement Learning |
| DRL | Deep Reinforcement Learning |
| GRL | Graph Reinforcement Learning |
| GNN | Graph Neural Network |
| GCN | Graph Convolutional Network |
| GAT | Graph Attention Network |
| ST-GCNN | Spatial–Temporal Graph Convolutional Nerual Network |
| LSTM | Long Short-Term Memory |
| GRU | Gate Recurrent Unit |
| TCN | Temporal Convolutional Network |
| MDP | Markov Decision Process |
| POMDP | Partially Observable Markov Decision Process |
| DQN | Deep Q-Network |
| D3QN | Double Dueling DQN |
| PER | Prioritized Experience Replay |
| AC | Actor Critic |
| A2C | Advantage Actor Critic |
| NAF | Normalized Advantage Function |
| DDPG | Deep Deterministic Policy Gradients |
| TD3 | Twin Delayed Deep Deterministic Policy Gradients |
| PPO | Proximal Policy Optimization |
| SAC | Soft Actor Critic |
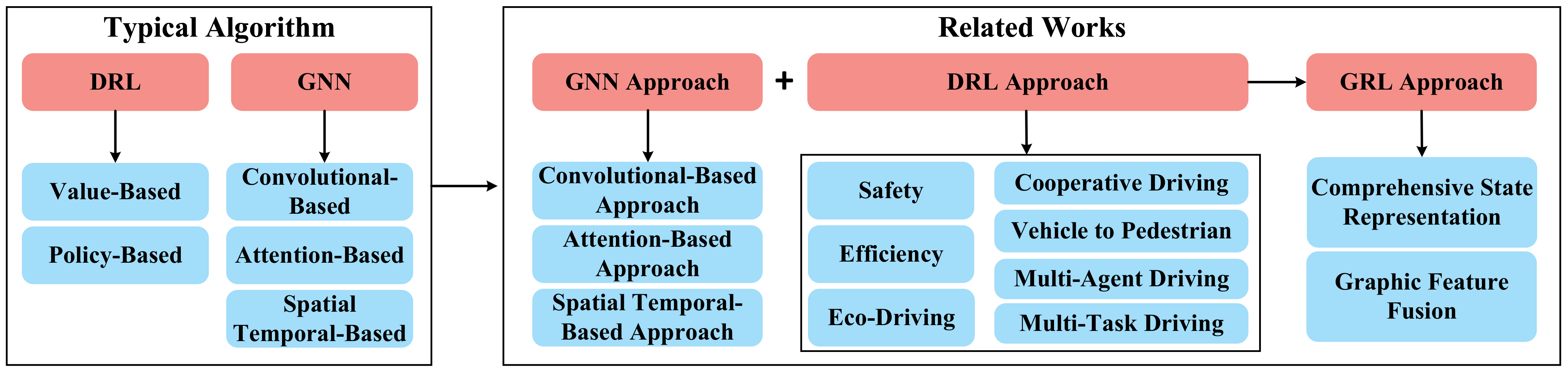
2. Related Works
3. Research Methods
3.1. Research Questions
- RQ1: What is the main application of the article?
- RQ2: Which GRL research point could this article potentially contribute to?
- RQ3: What methods does this article suggest around the above research point?
- RQ4: What are the evaluation metrics and simulation methods used by the article to validate the proposed methods?
- RQ5: What are the limitations of the article and the perspective of future research?
3.2. Literature Retrieval
3.3. Papers in Review
- Articles that can potentially contribute to GRL decision-making for CAVs in mixed autonomy traffic.
- Articles that have applied reinforcement learning methods.
- Articles that were published in 2018–2023.
- Articles that had no relevance related to decision-making technology in any way.
- Articles that did not utilize RL-based methods.
- Articles that had simple and inadequate simulation and validation processes.
4. Methods for Graph Representation
4.1. Basic Principle
4.1.1. Node Feature Matrix
4.1.2. Adjacency Matrix
4.1.3. Scenario Classification
4.1.4. Scenario Construction
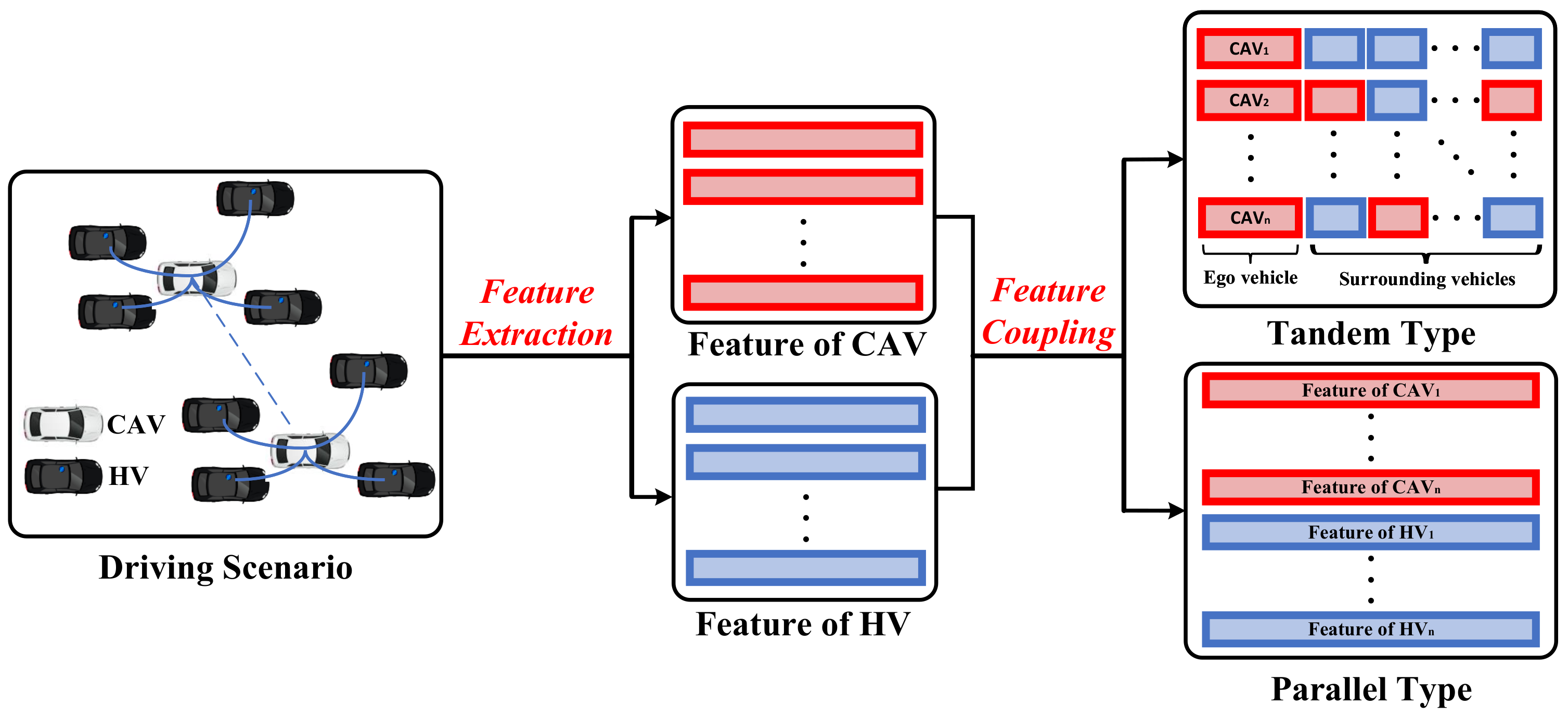
4.2. Methods for Node Feature Matrix
4.2.1. Tandem Type
4.2.2. Parallel Type
4.3. Methods for the Adjacency Matrix
| Coupling Type | Refs. | Scenario | Information | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Ego-Vehicle | Surrounding Vehicles | Relative Speed | Relative Position | Lane | Other | ||||||
| Speed | Acceleration | Position | Speed | Position | |||||||
| Tandem | [5] | Highway cruising | ✓ | ✓ | ✓ | ✓ | |||||
| [34] | Highway Merging | ✓ | ✓ | ||||||||
| [35] | Lane-changing | ✓ | ✓ | ||||||||
| [36] | Various scenarios | ✓ | ✓ | ✓ | ✓ | ||||||
| [37] | Lane-changing | ✓ | ✓ | ✓ | ✓ | ||||||
| [38] | Highway cruising | ✓ | ✓ | ✓ | Cooperation Level | ||||||
| [4] | Highway merging | ✓ | ✓ | ✓ | Traffic lights; warning | ||||||
| Parallel | [39] | Lane-changing | ✓ | ✓ | ✓ | ||||||
| [8] | Vehicle platoon | ✓ | ✓ | ✓ | Vehicle index | ||||||
| [14] | Traffic signal control | ✓ | ✓ | ||||||||
| [22] | Highway ramping | ✓ | ✓ | ✓ | Driving intention | ||||||
| [41] | Vehicle dispatching | ✓ | ✓ | Channel information | |||||||
| Refs. | Scenario | Interaction Model | Model Remarks |
|---|---|---|---|
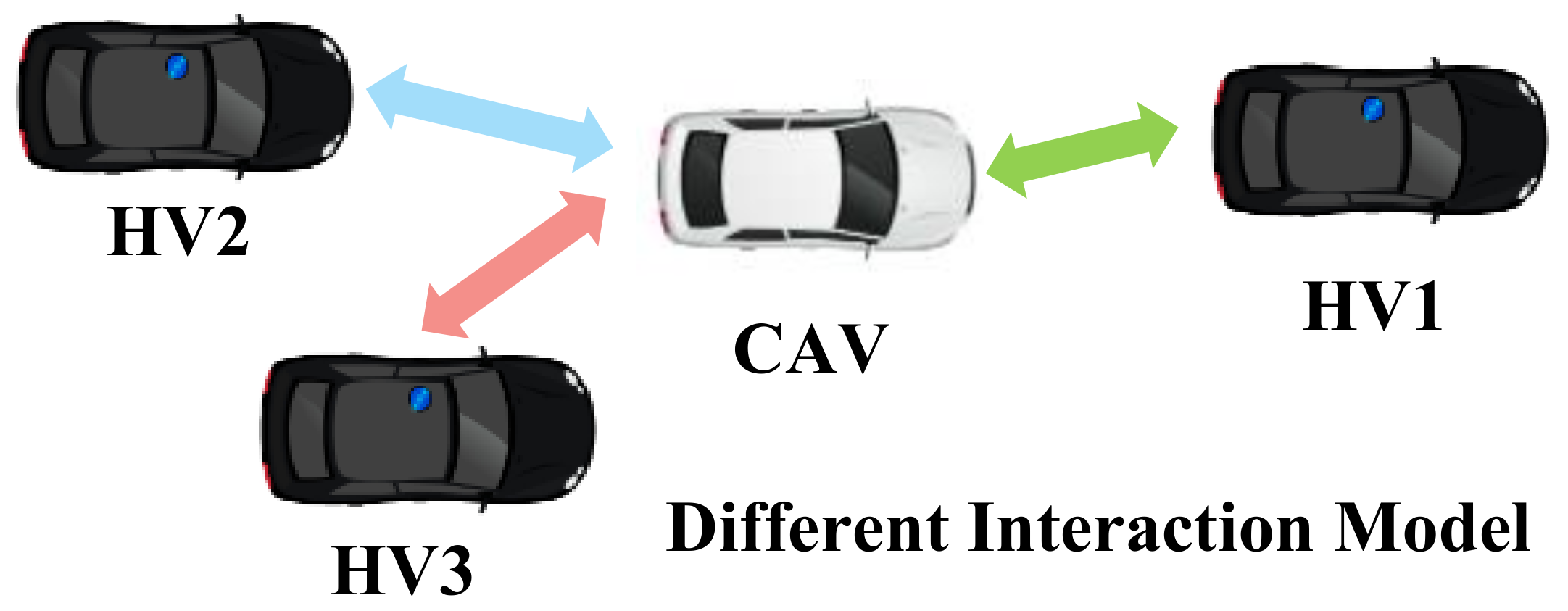
| [22] | Highway ramping | Information sharing between vehicles. | Interaction between vehicles are defined as 0 and 1 directly based on whether they are connected or not; diverse interaction models need to be considered in the future. |
| [36] | Various scenarios | Gaussian speed field using the Gaussian process regression (GPR) model. | Both relative distance and relative speed were fused into several kinematic matrices to generate the adjacency matrix. |
| [42] | Risk Recognition | Potential collision relationship between the ego-vehicle and the surrounding vehicles. | Safety constraints are considered to construct a more complete interaction model to achieve safe and efficient driving. |
| [43] | Trajectory prediction | Relative direction and relative speed of different vehicles. | Both relative distance and relative speed were taken into account to generate the adjacency matrix. |
| [44] | Urban bus-pooling | The one-hot representation of the index of the ego-bus and its one-hop neighbors. | The interaction between different vehicles is modeled by a multi-mode adjacency matrix |
5. Review of GRL Methods for Decision-Making
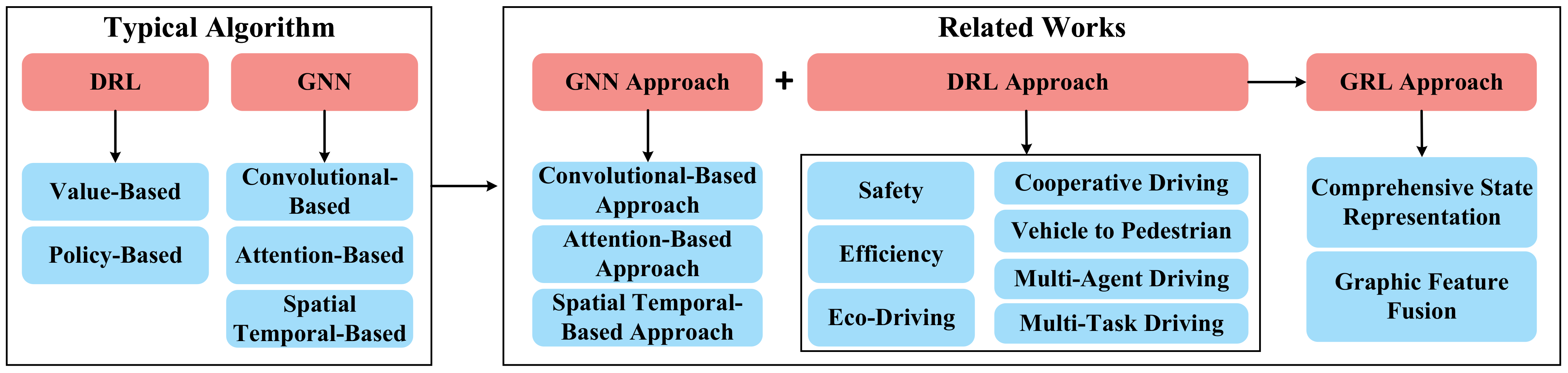
5.1. Typical GNN Algorithms
5.2. Review for GNN Methods
5.2.1. Convolutional-Based Methods
5.2.2. Attention-Based Methods
5.2.3. Spatial–Temporal-Based Methods
| Category | Refs. | Scenario | Models | Basic Modules | Simulator/Dataset |
|---|---|---|---|---|---|
| Convoluational- Based | [43] | Trajectory prediction | - | GCN, three directed graph | Stanford Drone Dataset. |
| [59] | Traffic speed forecasting | - | GraphSAGE | Urban area in Hangzhou, China. | |
| Attention- Based | [44] | Bus-pooling | DGACC | GAT, Hierarchical AC | Real-world datasets in Shenzhen, China. |
| [61] | Traffic signal control | - | GAT, AC | Real-world datasets from New York, Hangzhou, and Jinan. | |
| [60] | Slicing resource management | - | GAT+ DQN, GAT+A2C | Numerical analysis. | |
| Spatial–Temporal- Based | [62] | Traffic flow forecasting | T-MGCN | Multi-layer GCN, GRU | HZJTD, PEMSD10. |
| [63] | Traffic flow forecasting | KST-GCN | GCN, GRU | Dataset from Luohu District, Shenzhen, China. | |
| [64] | Traffic speed/flow forecasting | OGCRNN | GCN, GRU | D.C., Philadelphia, and PeMSD4. | |
| [19] | Traffic flow forecasting | LTT+STGC | GCN, LSTM | PeMSD7(M), PEMS-BAY, and Beijing Metro datasets. | |
| [65] | Traffic flow forecasting | HSTGCN | GCN, TCN | Traffic data from the Shenzhen Urban Traffic Planning Centre. | |
| [66] | Traffic flow forecasting | STGT | GCN, transformer model | PemsD8. | |
| [67] | Traffic flow forecasting | Traff-GGNN | Self-attention GNN, GRU | SZ-taxi, Los-loop, and PEMS-BAY Dataset. | |
| [17] | Traffic flow forecasting | STAtt | GAT, LSTM | Road section in Beijing, China. | |
| [10] | Trajectory prediction | EA-Net | GAT, LSTM | NGSIM, highD. | |
| [68] | Trajectory prediction | STG-DAT | Attention mechanism, GRU | ETH, UCY, SDD, ID, and Standford Drone Dataset. |
5.3. Typical DRL Algorithms
5.4. DRL-Based Methods for Decision-Making
5.4.1. Safety
5.4.2. Efficiency
5.4.3. Eco-Driving
5.4.4. Cooperative Driving
5.4.5. Vehicle-to-Pedestrian Interaction
5.4.6. Multi-Agent Driving
5.4.7. Multi-Task Driving
5.4.8. Other
5.5. Review for GRL Methods
5.5.1. Comprehensive State Representation
| Task Solved | Refs. | Methods | Scenario | Verification | Performance | Characteristics | |
|---|---|---|---|---|---|---|---|
| Main Solution | Remarks | ||||||
| Safety | [86] | Distribu- tional DQN | Intersection | Numerical simulation | Collision rate of less than 3%. | Safe policy | An online risk assessment mechanism is introduced to evaluate the probability distribution of different actions. |
| [89] | Risk-aware DQN | Intersection | Simulation in Carla | More than 95% success rate with steady performance. | Safe reward function | A stricter risk-based reward function is constructed to solve the model. | |
| [93] | SAC | Various scenarios | Simulation in Carla | Success rate of more than 87% with a low collision rate. | Attention mechanism | An attention-based spatial–temporal fusion driving policy is proposed. | |
| High efficiency solving | [96] | DQN | Intersection | Simulation in SUMO | Over 97% success rate with a small total number of finishing steps. | Hierarchical framework | Hierarchical Options MDP (HOMDP) is utilized to model the scenario. |
| [97] | Double DQN | Highway lane-changing | Numerical simulation | Over 90% success rate is achieved with only 100 training epochs. | Demonstration | Human demonstration with supervised loss is introduced. | |
| Eco- driving | [8] | PPO | Vehicle platoon | Simulation in SUMO | Fuel consumption is reduced by 11.6%. | Oscillation resuction | A predecessor–leader–follower typology is proposed. |
| [38] | Dueling DQN | Intersection | Unity Engine | Energy consumption is reduced by 12.70%. | Hybrid framework | The rule-based strategy and the DRL strategy are combined. | |
| Coopera- tive driving | [102] | DQN | Highway lane-changing | Numerical simulation | Mean vehicle flow rate of 6529 in congested conditions. | Behavior prediction | Individual efficiency with overall efficiency for harmony is combined. |
| [103] | Deep-Sets DQN | Highway merging | Numerical simulation | Low comfort cost is achieved under cooperative driving. | Behavior prediction | Cooperative drivers are identified from their vehicle state history. | |
| Vehicle to Pedestrian | [106] | DQN | Pedestrian crossing | Simulation in PreScan | Collision rate reaches zero when TTC is higher than 1.5 s. | Brake Control | An autonomous braking system is designed with different braking strengths. |
| [108] | Double DQN | Distracted pedestrian crossing | Simulation in OpenDS | Different safe speed ranges are verified under various pedestrian situations. | Behavior prediction | A risk assessment is performed to predict the behaviors of pedestrians. | |
| Multi-agent driving | [110] | DDPG | Highway merging | Numerical simulation | Collision-free performance is achieved at the merging ramp. | Parameter sharing | Collision avoidance is emphasized in the interaction between vehicles. |
| [34] | Improved A2C | Highway merging | Simulation in Highway-env | Zero collision rate is achieved in three tested modes. | Parameter sharing | A priority-based safety supervisor is developed to reduce collision. | |
| [5] | Tubular Q-learning | Highway cruising | Graphical simulation | High average reward with good lane-keeping behaviors. | Interaction modeling | A dynamic coordination graph is proposed to model the interactive topology. | |
| Multi-task driving | [113] | Multi- task DQN | Intersection | Simulation in SUMO | Success rate is higher than 87%. | multi-objective reward function | Multiple tasks are represented by a unified four-dimensional vector with a vectorized reward function. |
| [114] | DDPG | Highway merging | Simulation in SUMO | Vehicle jerk is reduced by 73% with nearly no collision. | multi-objective reward function | Collision avoidance for safety and jerk minimization for passenger comfort are both investigated. | |
| [119] | DQN\DDPG | Various scenarios | Simulation in Carla | 100% success rate with no traffic rule violations. | Tasks decoupling | Multiple agents are trained with different simple tasks under the hierarchical DRL framework. | |
5.5.2. Graphic Feature Fusion
| Refs. | Methods | Scenario | Verification | Performance | Characteristics | |
|---|---|---|---|---|---|---|
| Main Solution | Remarks | |||||
| [22] | GCN+DQN | Highway ramping | Simulation in SUMO | Better than those of the rule-based and LSTM at different traffic density values. | Graph modeling | The traffic scenario is modeled as an undirected graph. However, the generated behaviors do not correspond to the current vehicles. |
| [122] | GCN+DQN | Highway ramping | Simulation in SUMO | The network convergence and training efficiency are improved. | Graph modeling | A generalized single-agent GRL training method is proposed and extended to the multi-agent framework. |
| [123] | GCN+DQN | Highway ramping | Simulation in SUMO | High reward and average speed can be achieved. | Graph modeling | A multi-mode reward function with a decision-weighted coefficient matrix is derived to achieve the training of multiple decision-making modes. |
| [39] | Directed graph+PPO | Highway lane-changing | Numerical simulation | An 81.6% success rate is achieved at 11.1% collision rate. | Graph modeling | Graph representation is implemented based on the relative position between vehicles. |
| [124] | GCN+TD3 | Intersection | Simulation in Highway-env | Flow rate in the intersection is significantly improved. | Graph modeling | The varying number of vehicles in the scenario is handled by a flexible graph representation. |
| [36] | GAT+PPO | Various scenarios | Simulation in SUMO | Average reward is increased in all the tested scenarios. | Graph modeling | The attention mechanism is introduced to capture mutual interplay among vehicles to achieve better cooperative control. |
| [125] | DiGNet | Various scenarios | Simulation in Carla | Safe navigation in a complex driving environment while obeying traffic rules. | Graphical feature fusion | Graph representation is fused with bird’s-eye views of the driving scenario and route information. |
| [126] | GAT+D3QN | Various scenarios | Simulation in Carla | Over 96% success rate in the training scenarios. | Graphical feature fusion | Graph representation is fused with bird’s-eye views. The PID controller is implemented in the decision-making module. |
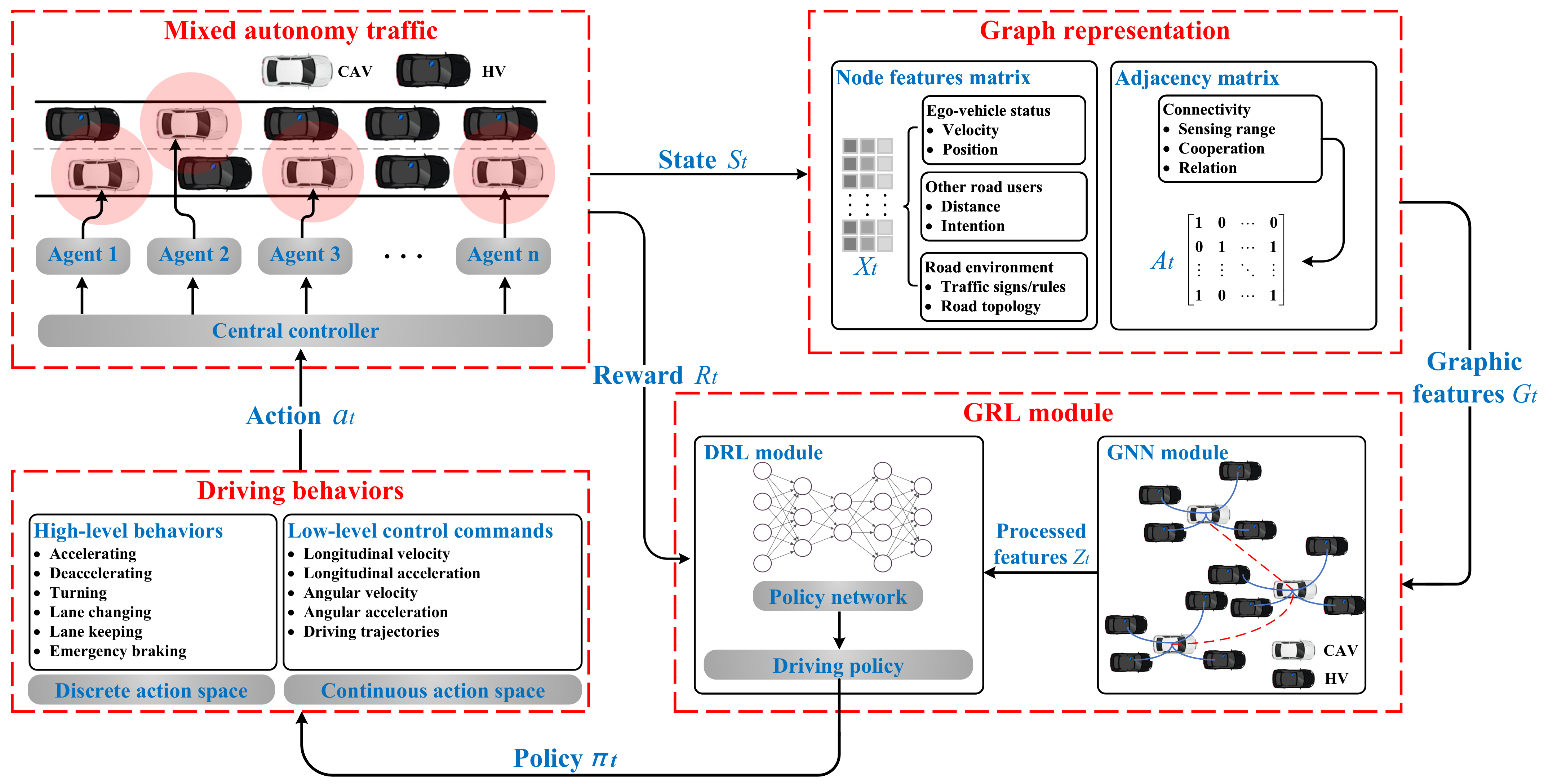
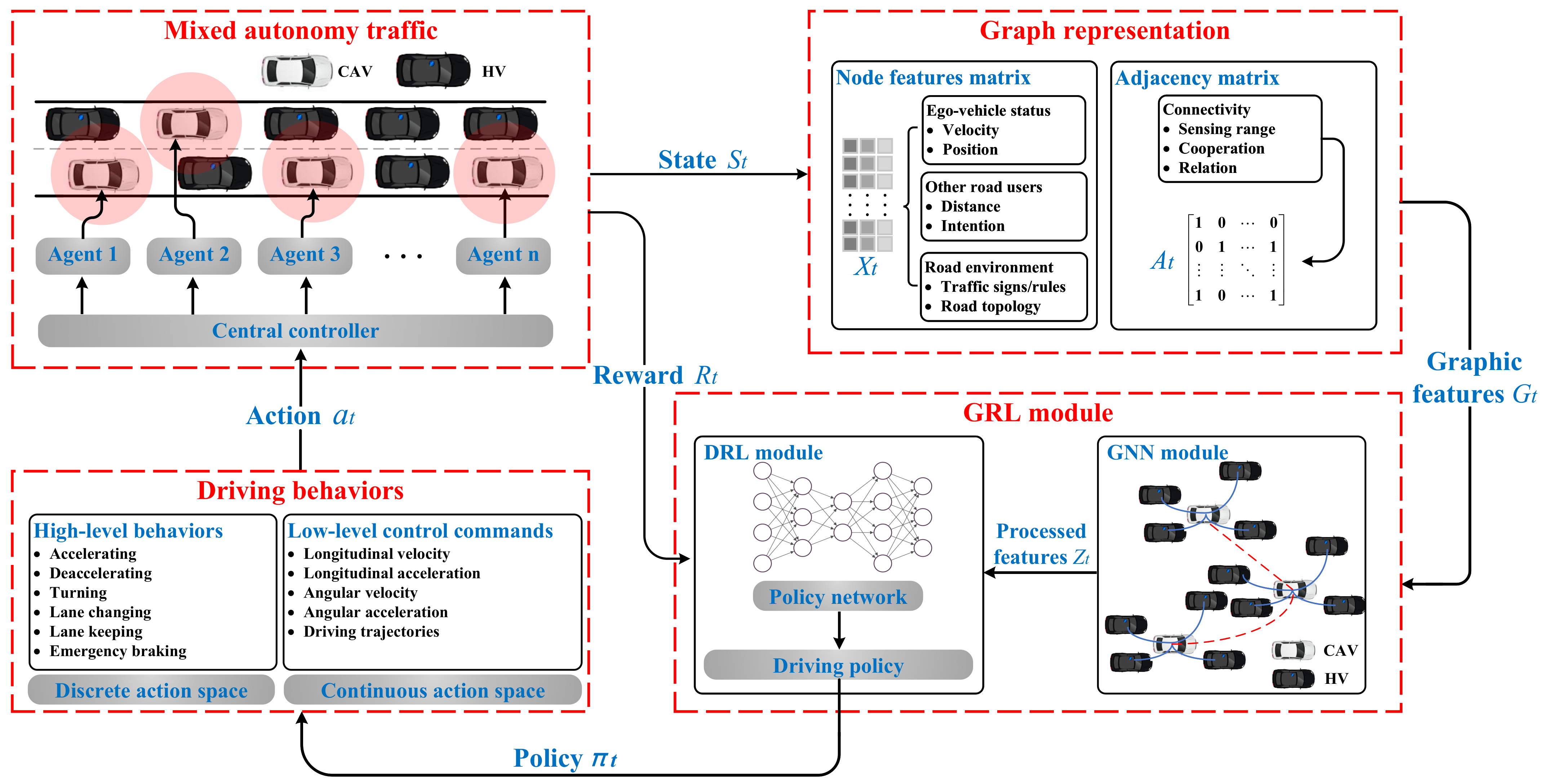
6. GRL Framework for the Decision-Making of CAVs
6.1. GRL Framework Architecture and Principle
6.2. Fundamental State Quantities and Data Flows of the GRL Framework
6.2.1. Temporal State Space
6.2.2. Temporal Graphic Feature
6.2.3. Driving Policy and Action Set
6.2.4. Reward Function R
6.2.5. Discount Factor
6.2.6. Data Flow
6.3. Optimization Principle of the GRL Framework
7. Validation for GRL-Based Decision-Making of CAVs
7.1. Evaluation Metrics
7.1.1. Overall Evaluation
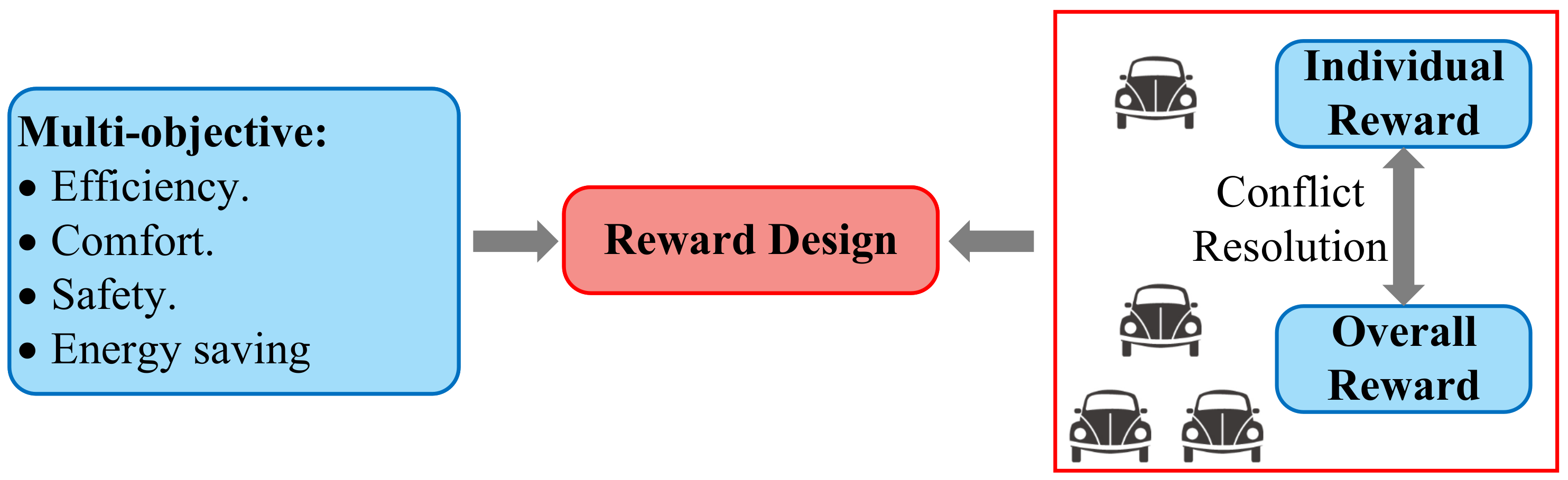
- Reward function: The reward function directly affects the training process of GRL-based methods as well as the overall performance of decision-making. The design of the reward function needs to consider multi-dimensional evaluation metrics, and a reasonably designed reward function is crucial to the efficiency of vehicle decision-making. For the operation of CAVs, the establishment of a reward function should not only assess the overall decision-making performance of all controlled vehicles in the environment but also consider the individual performance of each vehicle.
7.1.2. Dynamic Evaluation
- Speed: Speed is a direct way to assess the driving efficiency of the vehicle. In general, the maximum speed and average speed are usually chosen in related research [129].
- Acceleration: The maximum and average acceleration is typically selected to evaluate whether the vehicle can efficiently achieve high operating efficiency.
7.1.3. Task Evaluation
- Success rate: This refers to the percentage of the driving task that the vehicles complete during the numerous training or testing episodes [96].
- Finishing time: This indicates the time it would take for the vehicle to complete its driving task [130].
- Iterative steps: In some simulation platforms, the system returns the number of steps consumed when the vehicle completes the driving task. Therefore, the iteration step can be used as an indicator to assess the efficiency of task completion [40].
7.1.4. Safety Evaluation
- Number of collision: This refers to the collision number between vehicles in each training or testing episode [131].
- Time to collision: This refers to the time of collision between the ego-vehicle and the front vehicle, which can be calculated from the relative distance and relative speed [132].
- Number of lane changes: This implies a trade-off between safety and efficiency in vehicle operation. If lane changes are too frequent, vehicles are prone to accidents; conversely, high driving efficiency may not be guaranteed [133].
- Vehicle jerk: This represents the urgency of the longitudinal or lateral control of the vehicle [134].
- Traffic rules: Obeying traffic rules is an essential part of safe driving. This metric mainly refers to whether the vehicle violates traffic rules during operation and the frequency of violations. Compliance with traffic rules requires an assessment of whether the controlled vehicle has run a red light, invaded the lane mark, driven out of the road, driven on the wrong line, blocked the future path of other vehicles, etc. [96,135,136].
7.1.5. Economy Evaluation
7.2. Relevant Simulation Tools
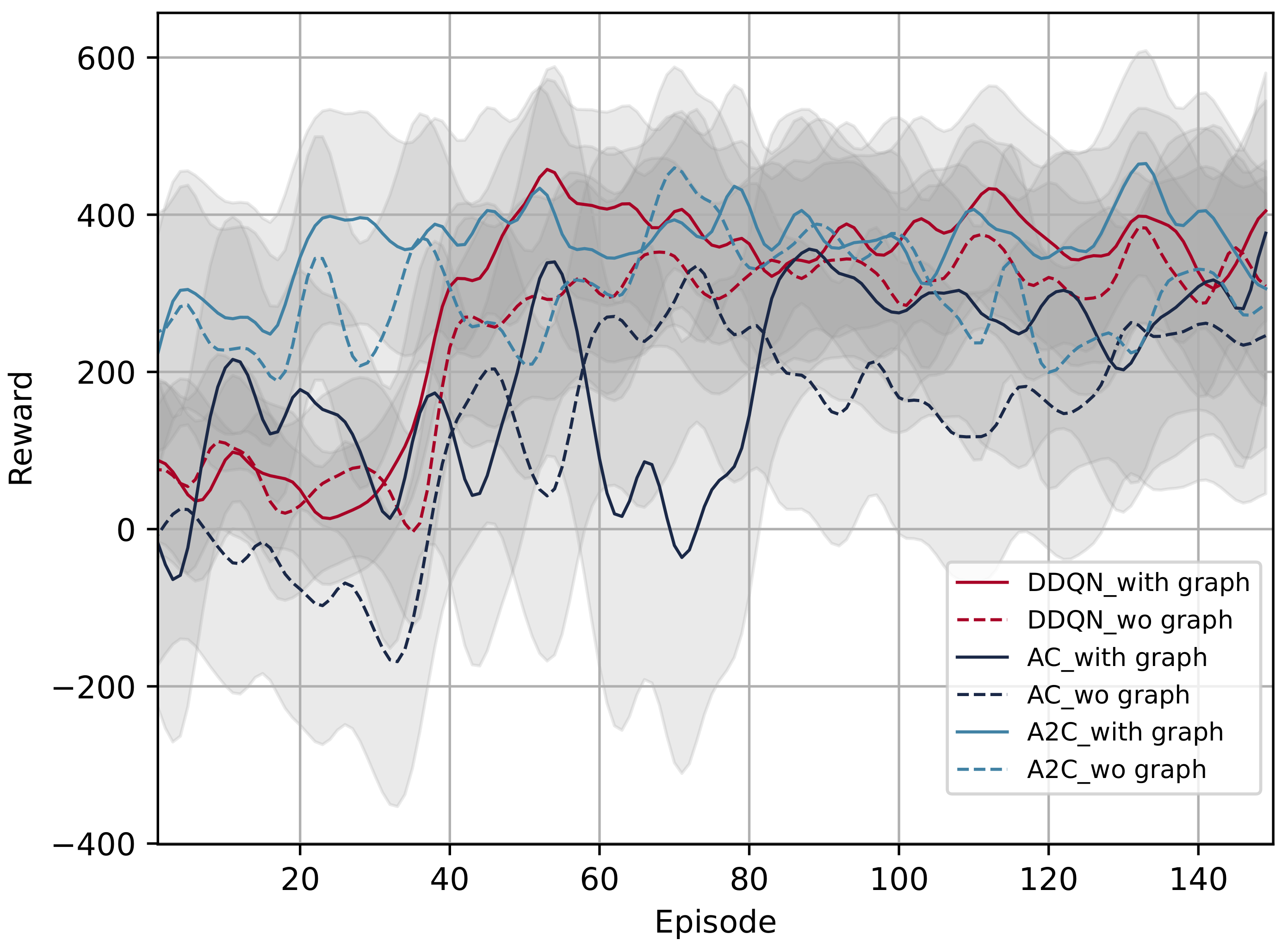
7.3. Initial Test of GRL-Based Methods
8. Challenges and Future Outlook
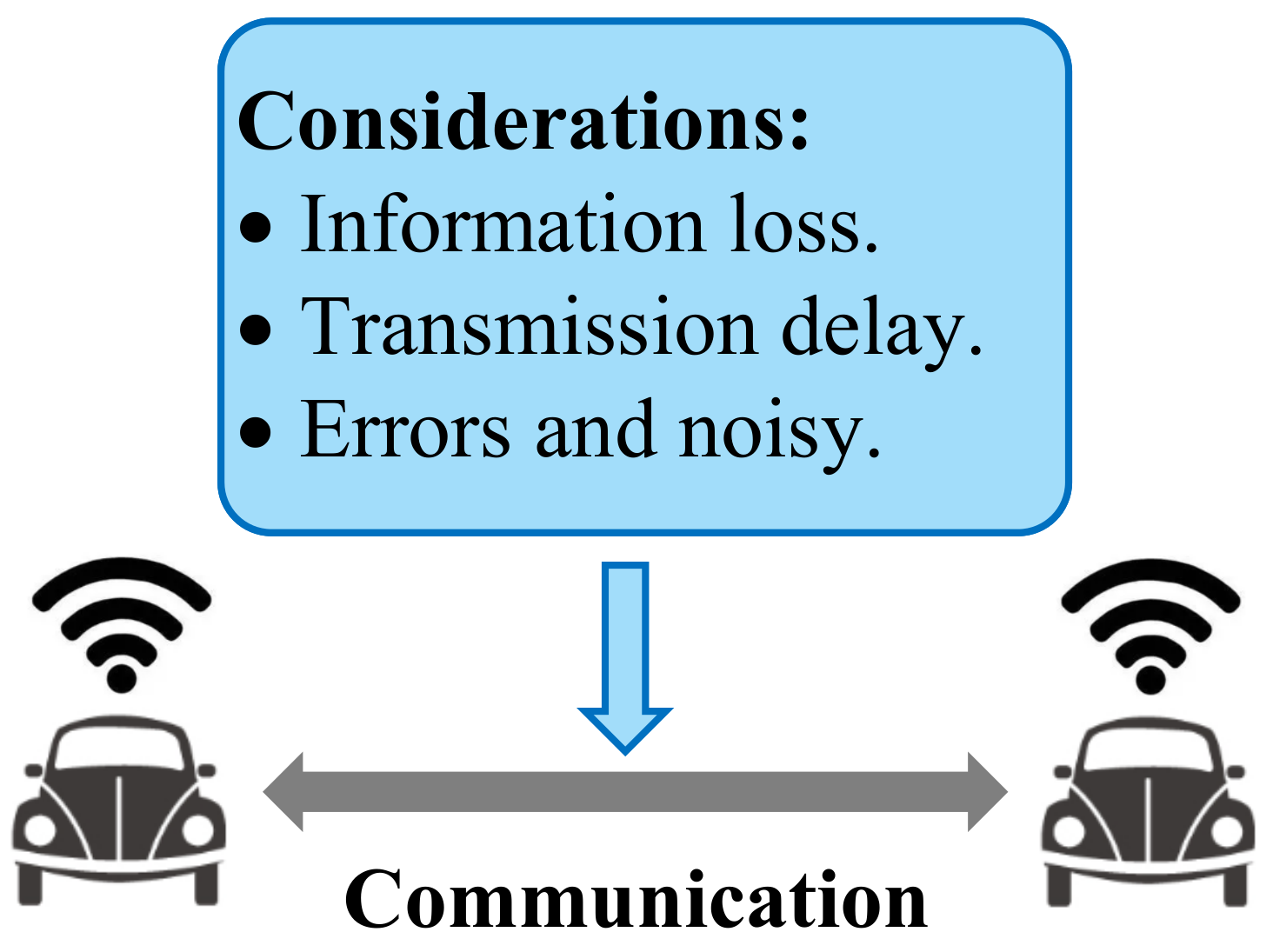
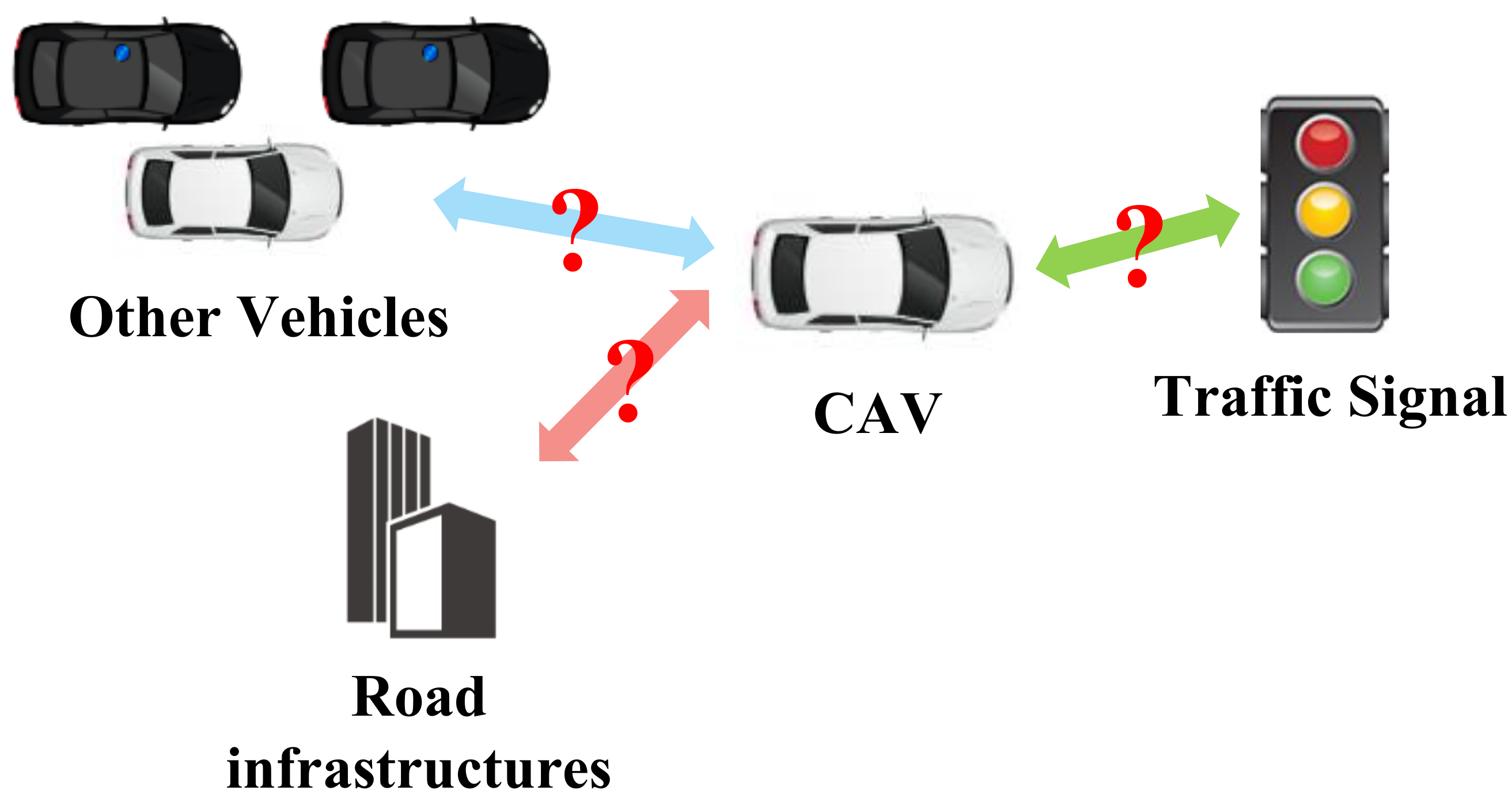
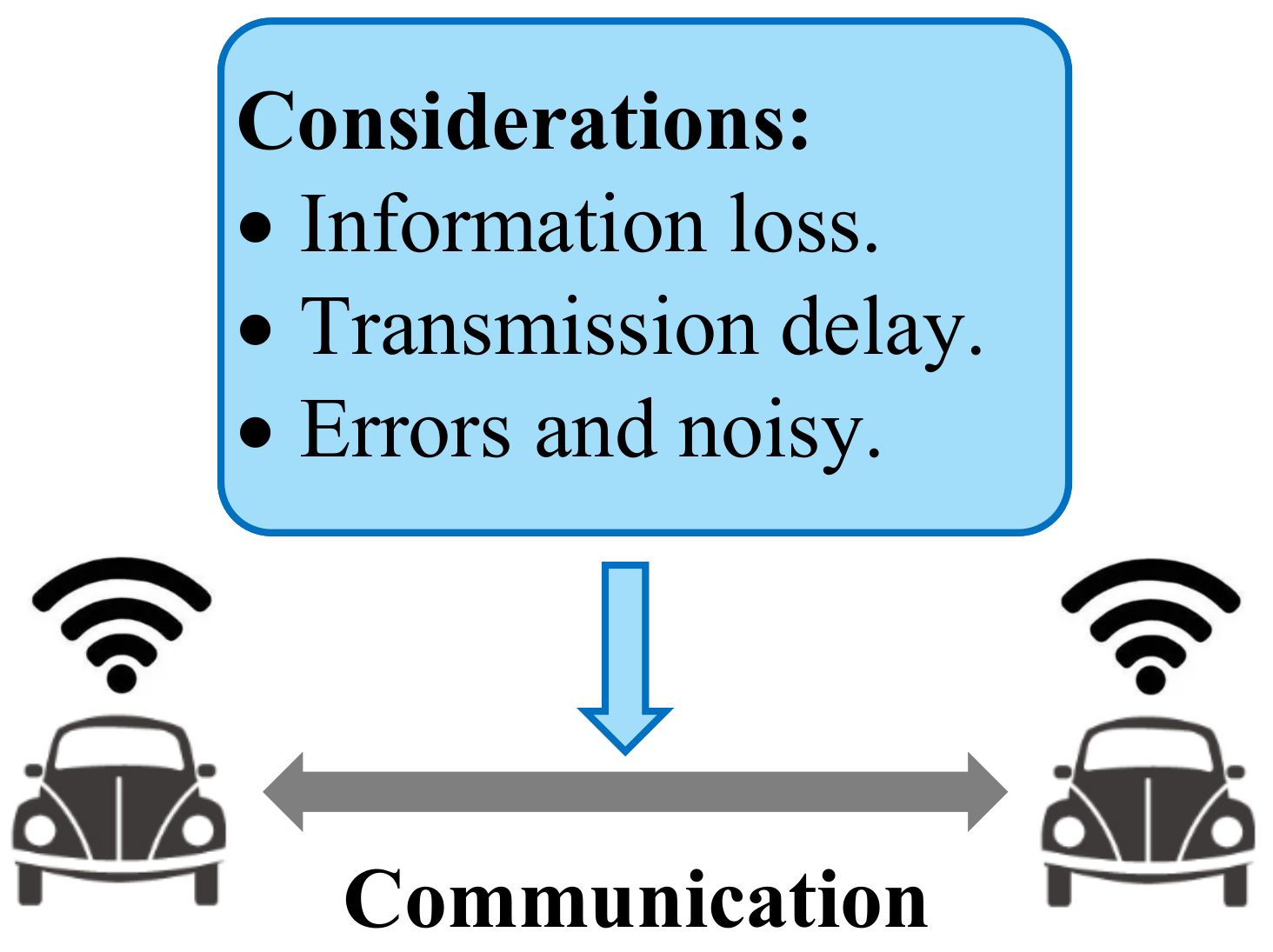
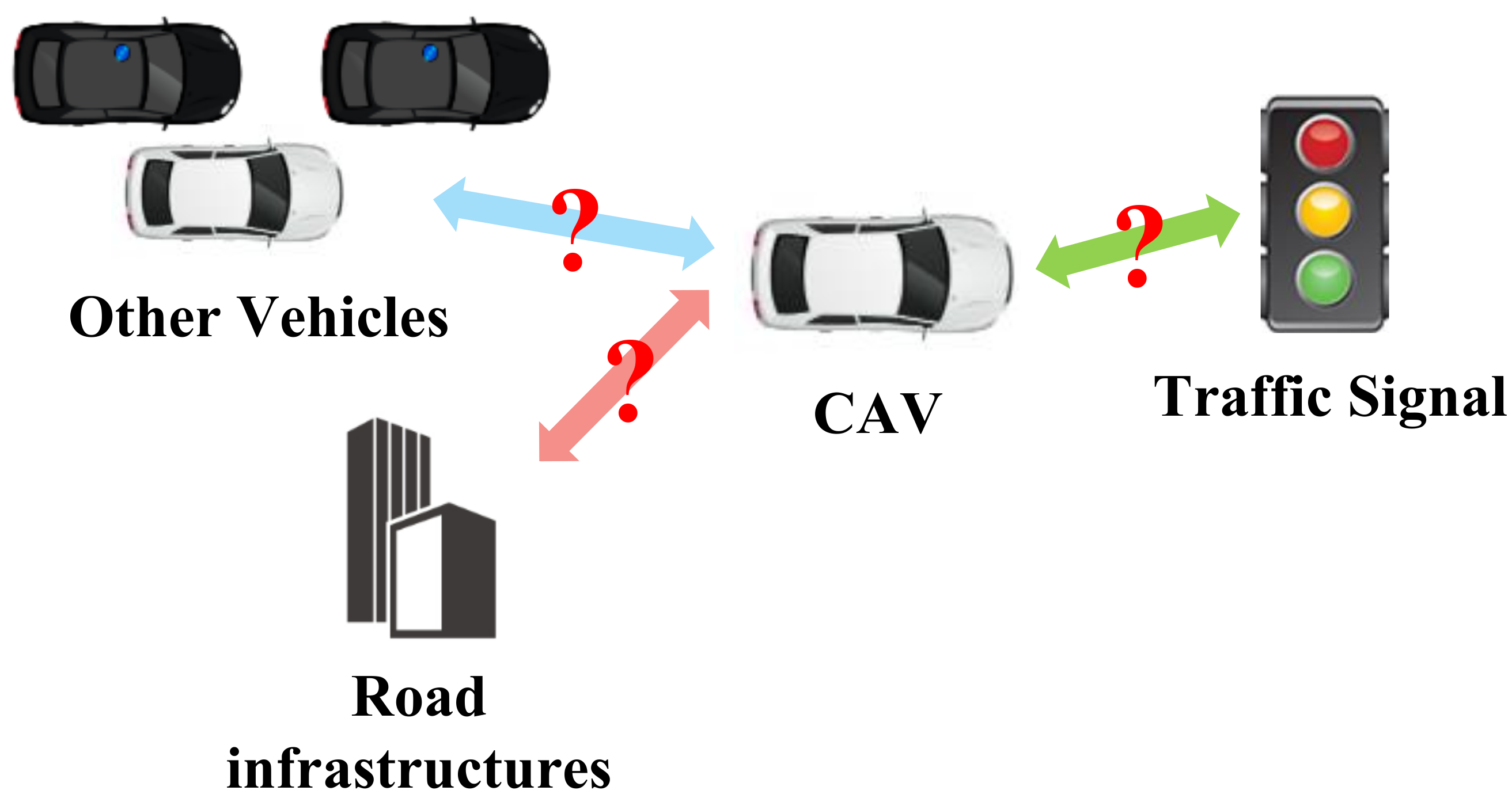
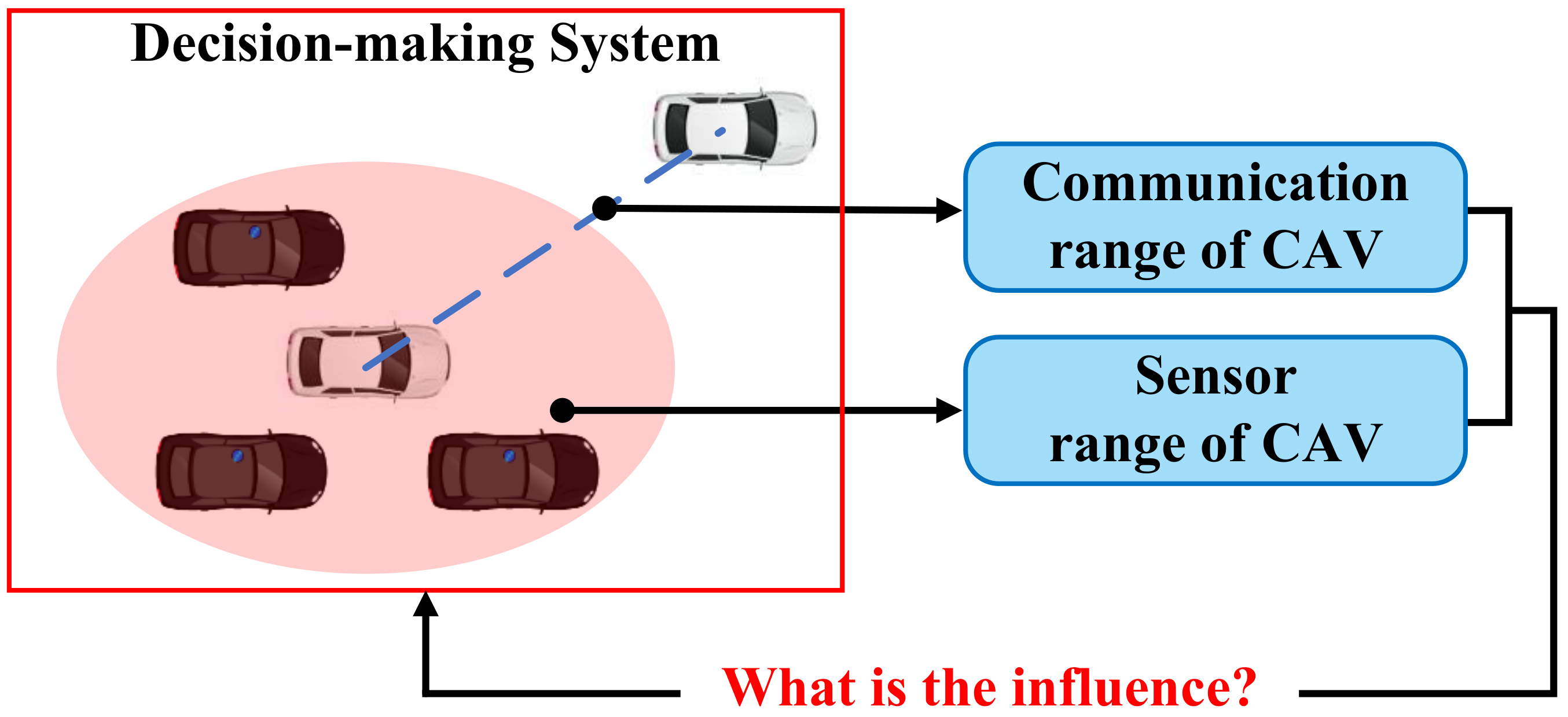
8.1. Communication
8.2. Reward Design
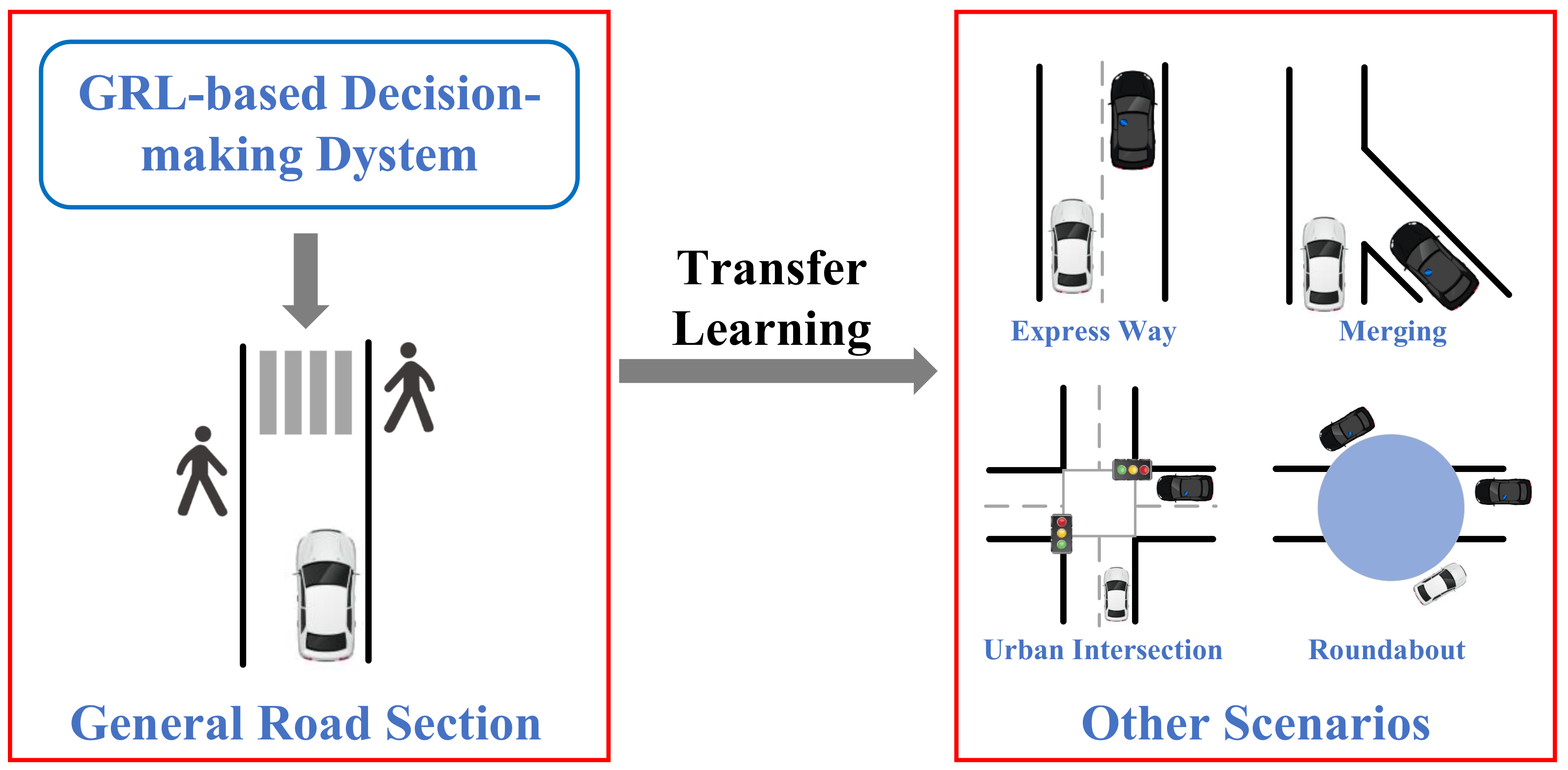
8.3. Transfer Learning
8.4. Human Factor
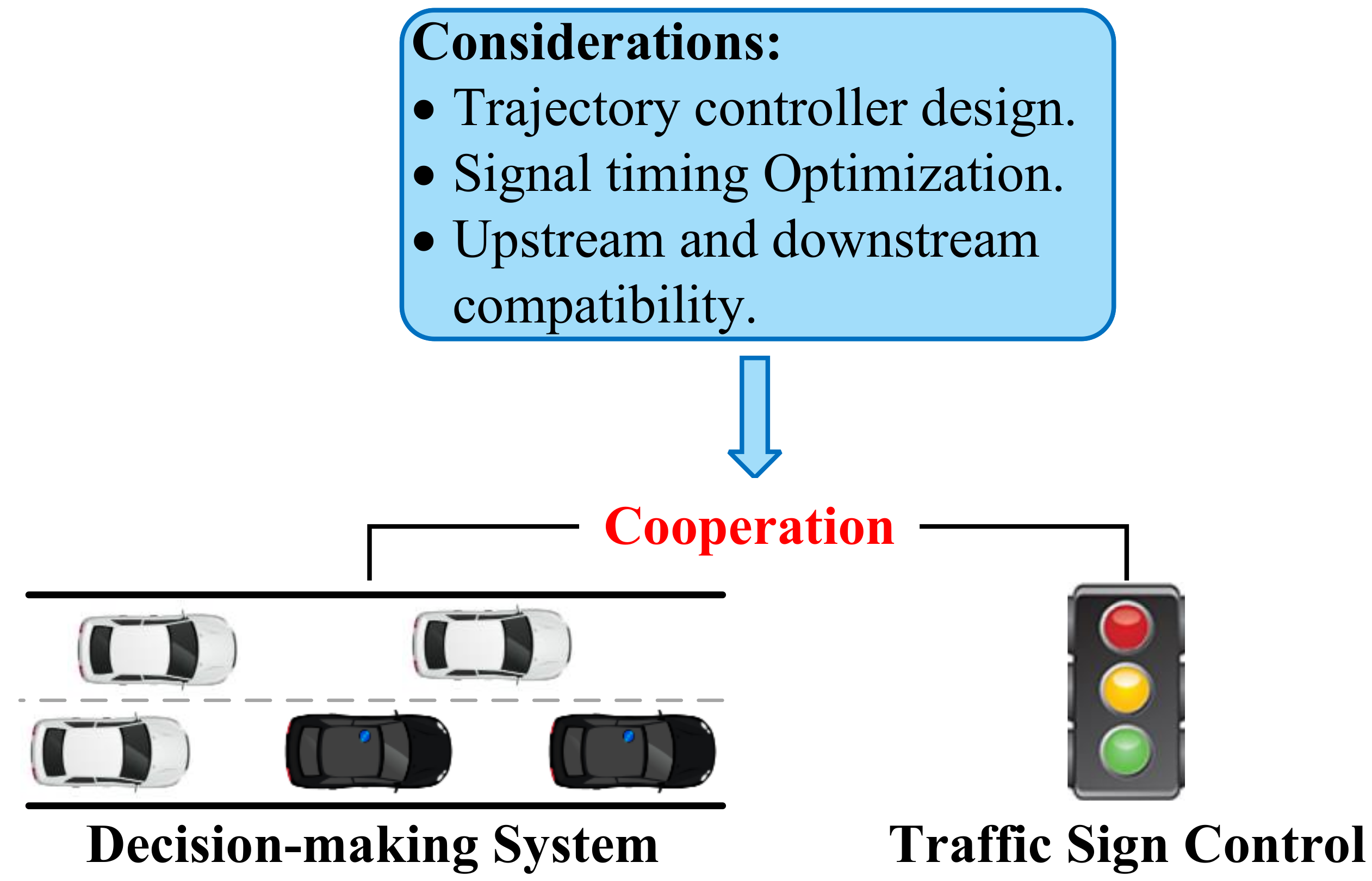
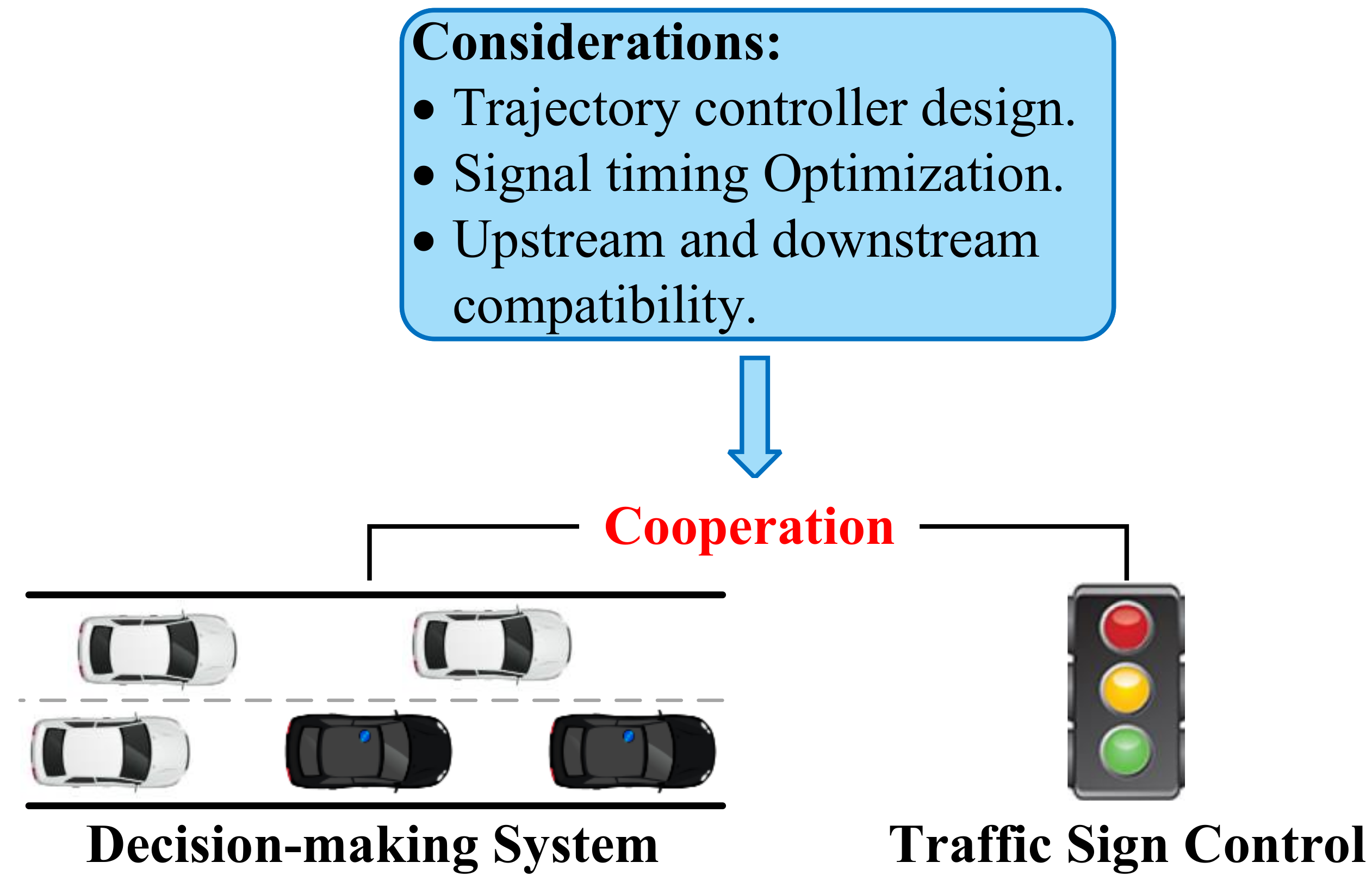
8.5. Traffic Control System Cooperative Feature
8.6. Uncertainty Problem
8.7. Coordination of Global and Local Information
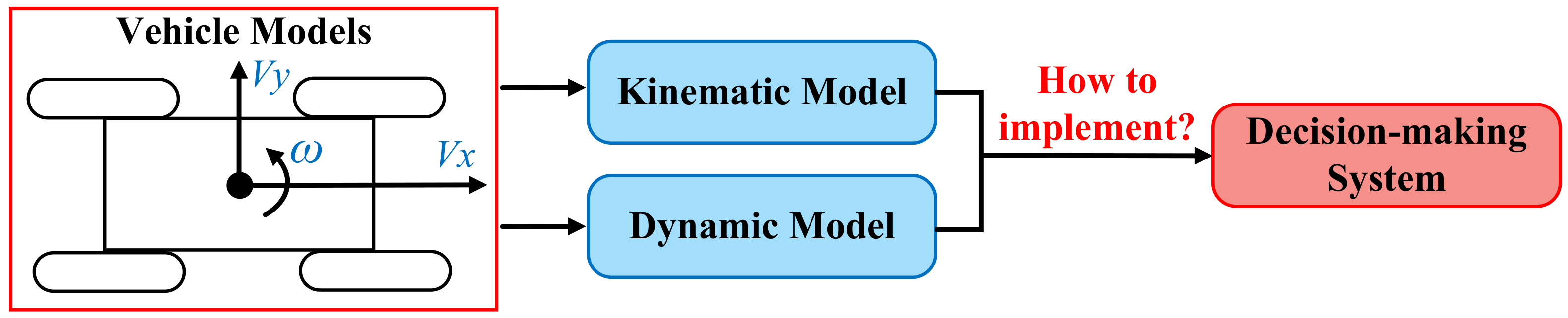
8.8. Vehicle Models
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Althoff, M.; Koschi, M.; Manzinger, S. CommonRoad: Composable benchmarks for motion planning on roads. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 719–726. [Google Scholar] [CrossRef]
- Zheng, F.; Liu, C.; Liu, X.; Jabari, S.E.; Lu, L. Analyzing the impact of automated vehicles on uncertainty and stability of the mixed traffic flow. Transp. Res. Part C Emerg. Technol. 2020, 112, 203–219. [Google Scholar] [CrossRef]
- Hang, P.; Lv, C.; Huang, C.; Xing, Y.; Hu, Z. Cooperative decision-making of connected automated vehicles at multi-lane merging zone: A coalitional game approach. IEEE Trans. Intell. Transp. Syst. 2021, 23, 3829–3841. [Google Scholar] [CrossRef]
- Bouton, M.; Nakhaei, A.; Fujimura, K.; Kochenderfer, M.J. Cooperation-aware reinforcement learning for merging in dense traffic. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3441–3447. [Google Scholar]
- Yu, C.; Wang, X.; Xu, X.; Zhang, M.; Ge, H.; Ren, J.; Sun, L.; Chen, B.; Tan, G. Distributed multiagent coordinated learning for autonomous driving in highways based on dynamic coordination graphs. IEEE Trans. Intell. Transp. Syst. 2019, 21, 735–748. [Google Scholar] [CrossRef]
- Palanisamy, P. Multi-agent connected autonomous driving using deep reinforcement learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Ha, P.Y.J.; Chen, S.; Dong, J.; Du, R.; Li, Y.; Labi, S. Leveraging the capabilities of connected and autonomous vehicles and multi-agent reinforcement learning to mitigate highway bottleneck congestion. arXiv 2020, arXiv:2010.05436. [Google Scholar]
- Li, M.; Cao, Z.; Li, Z. A reinforcement learning-based vehicle platoon control strategy for reducing energy consumption in traffic oscillations. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5309–5322. [Google Scholar] [CrossRef]
- Han, Y.; Wang, M.; Li, L.; Roncoli, C.; Gao, J.; Liu, P. A physics-informed reinforcement learning-based strategy for local and coordinated ramp metering. Transp. Res. Part C Emerg. Technol. 2022, 137, 103584. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, Z.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. Environment-attention network for vehicle trajectory prediction. IEEE Trans. Veh. Technol. 2021, 70, 11216–11227. [Google Scholar] [CrossRef]
- Li, Z.; Gong, J.; Lu, C.; Yi, Y. Interactive Behavior Prediction for Heterogeneous Traffic Participants in the Urban Road: A Graph-Neural-Network-Based Multitask Learning Framework. IEEE/ASME Trans. Mechatron. 2021, 26, 1339–1349. [Google Scholar] [CrossRef]
- Li, Z.; Lu, C.; Yi, Y.; Gong, J. A hierarchical framework for interactive behaviour prediction of heterogeneous traffic participants based on graph neural network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9102–9114. [Google Scholar] [CrossRef]
- Wang, Q. VARL: A variational autoencoder-based reinforcement learning Framework for vehicle routing problems. Appl. Intell. 2022, 52, 8910–8923. [Google Scholar] [CrossRef]
- Devailly, F.X.; Larocque, D.; Charlin, L. IG-RL: Inductive graph reinforcement learning for massive-scale traffic signal control. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7496–7507. [Google Scholar] [CrossRef]
- Yoon, J.; Ahn, K.; Park, J.; Yeo, H. Transferable traffic signal control: Reinforcement learning with graph centric state representation. Transp. Res. Part C Emerg. Technol. 2021, 130, 103321. [Google Scholar] [CrossRef]
- Yang, S.; Yang, B.; Kang, Z.; Deng, L. IHG-MA: Inductive heterogeneous graph multi-agent reinforcement learning for multi-intersection traffic signal control. Neural Netw. 2021, 139, 265–277. [Google Scholar] [CrossRef]
- Dong, H.; Zhu, P.; Gao, J.; Jia, L.; Qin, Y. A Short-term Traffic Flow Forecasting Model Based on Spatial-temporal Attention Neural Network. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 416–421. [Google Scholar]
- Duan, Y.; Chen, N.; Shen, S.; Zhang, P.; Qu, Y.; Yu, S. FDSA-STG: Fully dynamic self-attention spatio-temporal graph networks for intelligent traffic flow prediction. IEEE Trans. Veh. Technol. 2022, 71, 9250–9260. [Google Scholar] [CrossRef]
- Huo, G.; Zhang, Y.; Wang, B.; Gao, J.; Hu, Y.; Yin, B. Hierarchical Spatio–Temporal Graph Convolutional Networks and Transformer Network for Traffic Flow Forecasting. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3855–3867. [Google Scholar] [CrossRef]
- Jiang, J.; Dun, C.; Huang, T.; Lu, Z. Graph convolutional reinforcement learning. arXiv 2018, arXiv:1810.09202. [Google Scholar]
- Naderializadeh, N.; Hung, F.H.; Soleyman, S.; Khosla, D. Graph convolutional value decomposition in multi-agent reinforcement learning. arXiv 2020, arXiv:2010.04740. [Google Scholar]
- Chen, S.; Dong, J.; Ha, P.; Li, Y.; Labi, S. Graph neural network and reinforcement learning for multi-agent cooperative control of connected autonomous vehicles. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 838–857. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; Yuan, S.; Li, Z. Decision-making technology for autonomous vehicles: Learning-based methods, applications and future outlook. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 30–37. [Google Scholar]
- Haydari, A.; Yilmaz, Y. Deep reinforcement learning for intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2020, 23, 11–32. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Munikoti, S.; Agarwal, D.; Das, L.; Halappanavar, M.; Natarajan, B. Challenges and opportunities in deep reinforcement learning with graph neural networks: A comprehensive review of algorithms and applications. arXiv 2022, arXiv:2206.07922. [Google Scholar] [CrossRef]
- Xiong, L.; Kang, Y.c.; Zhang, P.z.; Zhu, C.; Yu, Z. Research on behavior decision-making system for unmanned vehicle. Automob. Technol. 2018, 515, 4–12. [Google Scholar]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous vehicles. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Xu, Q.; Li, K.; Wang, J.; Yuan, Q.; Yang, Y.; Chu, W. The status, challenges, and trends: An interpretation of technology roadmap of intelligent and connected vehicles in China (2020). J. Intell. Connect. Veh. 2022, 5, 1–7. [Google Scholar] [CrossRef]
- Leurent, E. An Environment for Autonomous Driving Decision-Making. 2018. Available online: https://github.com/eleurent/highway-env, (accessed on 4 May 2023).
- Wu, C.; Kreidieh, A.R.; Parvate, K.; Vinitsky, E.; Bayen, A.M. Flow: A modular learning framework for mixed autonomy traffic. IEEE Trans. Robot. 2021, 38, 1270–1286. [Google Scholar] [CrossRef]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic Traffic Simulation using SUMO. In Proceedings of the The 21st IEEE International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018; pp. 2575–2582. [Google Scholar]
- Aimsun. Aimsun Next 20 User’s Manual, 20.0.3 ed.; Aimsun Next: Barcelona, Spain, 2021. [Google Scholar]
- Chen, D.; Li, Z.; Wang, Y.; Jiang, L.; Wang, Y. Deep multi-agent reinforcement learning for highway on-ramp merging in mixed traffic. arXiv 2021, arXiv:2105.05701. [Google Scholar] [CrossRef]
- Zhou, W.; Chen, D.; Yan, J.; Li, Z.; Yin, H.; Ge, W. Multi-agent reinforcement learning for cooperative lane changing of connected and autonomous vehicles in mixed traffic. Auton. Intell. Syst. 2022, 2, 5. [Google Scholar] [CrossRef]
- Shi, T.; Wang, J.; Wu, Y.; Miranda-Moreno, L.; Sun, L. Efficient Connected and Automated Driving System with Multi-agent Graph Reinforcement Learning. arXiv 2020, arXiv:2007.02794. [Google Scholar]
- Xu, X.; Zuo, L.; Li, X.; Qian, L.; Ren, J.; Sun, Z. A reinforcement learning approach to autonomous decision-making of intelligent vehicles on highways. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 3884–3897. [Google Scholar] [CrossRef]
- Bai, Z.; Hao, P.; Shangguan, W.; Cai, B.; Barth, M.J. Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15850–15863. [Google Scholar] [CrossRef]
- Hart, P.; Knoll, A. Graph neural networks and reinforcement learning for behavior generation in semantic environments. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1589–1594. [Google Scholar]
- Liu, Q.; Li, Z.; Li, X.; Wu, J.; Yuan, S. Graph Convolution-Based Deep Reinforcement Learning for Multi-Agent Decision-Making in Interactive Traffic Scenarios. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 4074–4081. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, F.; Lyu, C.; Li, S.; Ye, J.; Qu, X. Deep dispatching: A deep reinforcement learning approach for vehicle dispatching on online ride-hailing platform. Transp. Res. Part E Logist. Transp. Rev. 2022, 161, 102694. [Google Scholar] [CrossRef]
- Li, J.; Lu, C.; Li, P.; Zhang, Z.; Gong, C.; Gong, J. Driver-Specific Risk Recognition in Interactive Driving Scenarios using Graph Representation. IEEE Trans. Veh. Technol. 2022, 72, 4453–4465. [Google Scholar] [CrossRef]
- Su, Y.; Du, J.; Li, Y.; Li, X.; Liang, R.; Hua, Z.; Zhou, J. Trajectory forecasting based on prior-aware directed graph convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16773–16785. [Google Scholar] [CrossRef]
- Wang, E.; Liu, B.; Lin, S.; Shen, F.; Bao, T.; Zhang, J.; Wang, J.; Sadek, A.W.; Qiao, C. Double graph attention actor-critic framework for urban bus-pooling system. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5313–5325. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- He, S.; Xiong, S.; Ou, Y.; Zhang, J.; Wang, J.; Huang, Y.; Zhang, Y. An overview on the application of graph neural networks in wireless networks. IEEE Open J. Commun. Soc. 2021, 2, 2547–2565. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Xu, B.; Shen, H.; Cao, Q.; Qiu, Y.; Cheng, X. Graph wavelet neural network. arXiv 2019, arXiv:1904.07785. [Google Scholar]
- Zou, D.; Hu, Z.; Wang, Y.; Jiang, S.; Sun, Y.; Gu, Q. Layer-dependent importance sampling for training deep and large graph convolutional networks. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10-48550. [Google Scholar]
- Zhang, R.; Zou, Y.; Ma, J. Hyper-SAGNN: A self-attention based graph neural network for hypergraphs. arXiv 2019, arXiv:1911.02613. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Phung, D. Universal graph transformer self-attention networks. In Proceedings of the Companion Proceedings of the Web Conference 2022, Virtual, 22–25 April 2022; pp. 193–196. [Google Scholar]
- Manessi, F.; Rozza, A.; Manzo, M. Dynamic graph convolutional networks. Pattern Recognit. 2020, 97, 107000. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2020; pp. 14424–14432. [Google Scholar]
- Liu, J.; Ong, G.P.; Chen, X. GraphSAGE-based traffic speed forecasting for segment network with sparse data. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1755–1766. [Google Scholar] [CrossRef]
- Shao, Y.; Li, R.; Hu, B.; Wu, Y.; Zhao, Z.; Zhang, H. Graph attention network-based multi-agent reinforcement learning for slicing resource management in dense cellular network. IEEE Trans. Veh. Technol. 2021, 70, 10792–10803. [Google Scholar] [CrossRef]
- Yi, C.; Wu, J.; Ren, Y.; Ran, Y.; Lou, Y. A Spatial-Temporal Deep Reinforcement Learning Model for Large-Scale Centralized Traffic Signal Control. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 275–280. [Google Scholar]
- Lv, M.; Hong, Z.; Chen, L.; Chen, T.; Zhu, T.; Ji, S. Temporal multi-graph convolutional network for traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3337–3348. [Google Scholar] [CrossRef]
- Zhu, J.; Han, X.; Deng, H.; Tao, C.; Zhao, L.; Wang, P.; Lin, T.; Li, H. KST-GCN: A knowledge-driven spatial-temporal graph convolutional network for traffic forecasting. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15055–15065. [Google Scholar] [CrossRef]
- Guo, K.; Hu, Y.; Qian, Z.; Liu, H.; Zhang, K.; Sun, Y.; Gao, J.; Yin, B. Optimized graph convolution recurrent neural network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1138–1149. [Google Scholar] [CrossRef]
- Chen, B.; Hu, K.; Li, Y.; Miao, L. Hybrid Spatio-Temporal Graph Convolution Network For Short-Term Traffic Forecasting. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 2128–2133. [Google Scholar]
- Wang, Q.; He, G.; Lu, P.; Chen, Q.; Chen, Y.; Huang, W. Spatial-Temporal Graph-Based Transformer Model for Traffic Flow Forecasting. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 2806–2811. [Google Scholar]
- Wang, Y.; Zheng, J.; Du, Y.; Huang, C.; Li, P. Traffic-GGNN: Predicting Traffic Flow via Attentional Spatial-Temporal Gated Graph Neural Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18423–18432. [Google Scholar] [CrossRef]
- Li, J.; Ma, H.; Zhang, Z.; Li, J.; Tomizuka, M. Spatio-temporal graph dual-attention network for multi-agent prediction and tracking. IEEE Trans. Intell. Transp. Syst. 2021, 23, 10556–10569. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1726–1744. [Google Scholar] [CrossRef] [PubMed]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Chengdu, China, 30 June–2 July 2016; pp. 1995–2003. [Google Scholar]
- Fortunato, M.; Azar, M.G.; Piot, B.; Menick, J.; Osb, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; Pietquin, O.; et al. Noisy networks for exploration. arXiv 2017, arXiv:1706.10295. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A distributional perspective on reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 449–458. [Google Scholar]
- Hessel, M.; Modayil, J.; van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. Adv. Neural Inf. Process. Syst. 1999, 12, 1008–1014. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Gu, S.; Lillicrap, T.; Sutskever, I.; Levine, S. Continuous deep q-learning with model-based acceleration. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 2829–2838. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 25–31 July 2018; pp. 1587–1596. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mirchevska, B.; Pek, C.; Werling, M.; Althoff, M.; Boedecker, J. High-level decision-making for safe and reasonable autonomous lane changing using reinforcement learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2156–2162. [Google Scholar]
- Bernhard, J.; Pollok, S.; Knoll, A. Addressing inherent uncertainty: Risk-sensitive behavior generation for automated driving using distributional reinforcement learning. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2148–2155. [Google Scholar]
- Bouton, M.; Nakhaei, A.; Fujimura, K.; Kochenderfer, M.J. Safe reinforcement learning with scene decomposition for navigating complex urban environments. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1469–1476. [Google Scholar]
- Schmidt, L.M.; Kontes, G.; Plinge, A.; Mutschler, C. Can you trust your autonomous car? Interpretable and verifiably safe reinforcement learning. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 171–178. [Google Scholar]
- Kamran, D.; Lopez, C.F.; Lauer, M.; Stiller, C. Risk-aware high-level decisions for automated driving at occluded intersections with reinforcement learning. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October 2020–13 November 2020; pp. 1205–1212. [Google Scholar]
- Hu, J.; Li, X.; Cen, Y.; Xu, Q.; Zhu, X.; Hu, W. A Roadside Decision-Making Methodology Based on Deep Reinforcement Learning to Simultaneously Improve the Safety and Efficiency of Merging Zone. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18620–18631. [Google Scholar] [CrossRef]
- Alizadeh, A.; Moghadam, M.; Bicer, Y.; Ure, N.K.; Yavas, U.; Kurtulus, C. Automated lane change decision-making using deep reinforcement learning in dynamic and uncertain highway environment. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1399–1404. [Google Scholar]
- Hoel, C.J.; Tram, T.; Sjöberg, J. Reinforcement learning with uncertainty estimation for tactical decision-making in intersections. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2020; pp. 1–7. [Google Scholar]
- Kuutti, S.; Fallah, S.; Bowden, R. ARC: Adversarially Robust Control Policies for Autonomous Vehicles. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 522–529. [Google Scholar]
- Seong, H.; Jung, C.; Lee, S.; Shim, D.H. Learning to drive at unsignalized intersections using attention-based deep reinforcement learning. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 559–566. [Google Scholar]
- Yavas, U.; Kumbasar, T.; Ure, N.K. A new approach for tactical decision-making in lane changing: Sample efficient deep Q learning with a safety feedback reward. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1156–1161. [Google Scholar]
- Qiao, Z.; Muelling, K.; Dolan, J.; Palanisamy, P.; Mudalige, P. Pomdp and hierarchical options mdp with continuous actions for autonomous driving at intersections. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2377–2382. [Google Scholar]
- Liu, D.; Brännstrom, M.; Backhouse, A.; Svensson, L. Learning faster to perform autonomous lane changes by constructing maneuvers from shielded semantic actions. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1838–1844. [Google Scholar]
- Prathiba, S.B.; Raja, G.; Dev, K.; Kumar, N.; Guizani, M. A hybrid deep reinforcement learning for autonomous vehicles smart-platooning. IEEE Trans. Veh. Technol. 2021, 70, 13340–13350. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, J.; Shi, X.; Cheng, J. Learning the policy for mixed electric platoon control of automated and human-driven vehicles at signalized intersection: A random search approach. arXiv 2022, arXiv:2206.12052. [Google Scholar] [CrossRef]
- Lichtlé, N.; Vinitsky, E.; Gunter, G.; Velu, A.; Bayen, A.M. Fuel Consumption Reduction of Multi-Lane Road Networks using Decentralized Mixed-Autonomy Control. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2068–2073. [Google Scholar]
- Liu, J.; Zhao, W.; Xu, C. An efficient on-ramp merging strategy for connected and automated vehicles in multi-lane traffic. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5056–5067. [Google Scholar] [CrossRef]
- Wang, G.; Hu, J.; Li, Z.; Li, L. Harmonious lane changing via deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4642–4650. [Google Scholar] [CrossRef]
- Kamran, D.; Ren, Y.; Lauer, M. High-level Decisions from a Safe Maneuver Catalog with Reinforcement Learning for Safe and Cooperative Automated Merging. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Bilbao, Spain, 24–28 September 2021; pp. 804–811. [Google Scholar]
- El abidine Kherroubi, Z.; Aknine, S.; Bacha, R. Novel decision-making strategy for connected and autonomous vehicles in highway on-ramp merging. IEEE Trans. Intell. Transp. Syst. 2021, 23, 12490–12502. [Google Scholar] [CrossRef]
- Lv, P.; Han, J.; Nie, J.; Zhang, Y.; Xu, J.; Cai, C.; Chen, Z. Cooperative Decision-Making of Connected and Autonomous Vehicles in an Emergency. IEEE Trans. Veh. Technol. 2022, 72, 1464–1477. [Google Scholar] [CrossRef]
- Chae, H.; Kang, C.M.; Kim, B.; Kim, J.; Chung, C.C.; Choi, J.W. Autonomous braking system via deep reinforcement learning. In Proceedings of the 2017 IEEE 20th International conference on intelligent transportation systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Deshpande, N.; Vaufreydaz, D.; Spalanzani, A. Navigation In Urban Environments Amongst Pedestrians Using Multi-Objective Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 923–928. [Google Scholar]
- Papini, G.P.R.; Plebe, A.; Da Lio, M.; Donà, R. A reinforcement learning approach for enacting cautious behaviours in autonomous driving system: Safe speed choice in the interaction with distracted pedestrians. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8805–8822. [Google Scholar] [CrossRef]
- Trumpp, R.; Bayerlein, H.; Gesbert, D. Modeling Interactions of Autonomous Vehicles and Pedestrians with Deep Multi-Agent Reinforcement Learning for Collision Avoidance. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2022; pp. 331–336. [Google Scholar]
- Schester, L.; Ortiz, L.E. Automated Driving Highway Traffic Merging using Deep Multi-Agent Reinforcement Learning in Continuous State-Action Spaces. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2021; pp. 280–287. [Google Scholar]
- Yan, Z.; Wu, C. Reinforcement Learning for Mixed Autonomy Intersections. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2089–2094. [Google Scholar] [CrossRef]
- Antonio, G.P.; Maria-Dolores, C. Multi-Agent Deep Reinforcement Learning to Manage Connected Autonomous Vehicles at Tomorrow’s Intersections. IEEE Trans. Veh. Technol. 2022, 71, 7033–7043. [Google Scholar] [CrossRef]
- Kai, S.; Wang, B.; Chen, D.; Hao, J.; Zhang, H.; Liu, W. A multi-task reinforcement learning approach for navigating unsignalized intersections. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1583–1588. [Google Scholar]
- Lin, Y.; McPhee, J.; Azad, N.L. Anti-Jerk On-Ramp Merging Using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 7–14. [Google Scholar] [CrossRef]
- Wang, T.; Luo, Y.; Liu, J.; Li, K. Multi-Objective End-to-End Self-Driving Based on Pareto-Optimal Actor-Critic Approach. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 473–478. [Google Scholar]
- He, X.; Fei, C.; Liu, Y.; Yang, K.; Ji, X. Multi-objective longitudinal decision-making for autonomous electric vehicle: A entropy-constrained reinforcement learning approach. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Ye, F.; Wang, P.; Chan, C.Y.; Zhang, J. Meta reinforcement learning-based lane change strategy for autonomous vehicles. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2021; pp. 223–230. [Google Scholar]
- Triest, S.; Villaflor, A.; Dolan, J.M. Learning highway ramp merging via reinforcement learning with temporally-extended actions. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1595–1600. [Google Scholar]
- Gangopadhyay, B.; Soora, H.; Dasgupta, P. Hierarchical program-triggered reinforcement learning agents for automated driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 10902–10911. [Google Scholar] [CrossRef]
- De Moura, N.; Chatila, R.; Evans, K.; Chauvier, S.; Dogan, E. Ethical decision-making for autonomous vehicles. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 2006–2013. [Google Scholar]
- Pusse, F.; Klusch, M. Hybrid online pomdp planning and deep reinforcement learning for safer self-driving cars. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1013–1020. [Google Scholar]
- Yang, F.; Li, X.; Liu, Q.; Li, Z.; Gao, X. Generalized Single-Vehicle-Based Graph Reinforcement Learning for Decision-Making in Autonomous Driving. Sensors 2022, 22, 4935. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Li, X.; Liu, Q.; Li, Z.; Yang, F.; Luan, T. Multi-Agent Decision-Making Modes in Uncertain Interactive Traffic Scenarios via Graph Convolution-Based Deep Reinforcement Learning. Sensors 2022, 22, 4586. [Google Scholar] [CrossRef] [PubMed]
- Klimke, M.; Völz, B.; Buchholz, M. Cooperative Behavioral Planning for Automated Driving using Graph Neural Networks. arXiv 2022, arXiv:2202.11376. [Google Scholar]
- Cai, P.; Wang, H.; Sun, Y.; Liu, M. DiGNet: Learning Scalable Self-Driving Policies for Generic Traffic Scenarios with Graph Neural Networks. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 October–1 November 2021; pp. 8979–8984. [Google Scholar]
- Cai, P.; Wang, H.; Sun, Y.; Liu, M. DQ-GAT: Towards Safe and Efficient Autonomous Driving with Deep Q-Learning and Graph Attention Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21102–21112. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 679–684. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Ivanov, R.; Jothimurugan, K.; Hsu, S.; Vaidya, S.; Alur, R.; Bastani, O. Compositional learning and verification of neural network controllers. ACM Trans. Embed. Comput. Syst. 2021, 20, 1–26. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, B.; Tomizuka, M. Model-free deep reinforcement learning for urban autonomous driving. In Proceedings of the 2019 IEEE intelligent transportation systems conference (ITSC), Indianapolis, IN, USA, 19–22 September 2019; pp. 2765–2771. [Google Scholar]
- Bhattacharyya, R.P.; Phillips, D.J.; Liu, C.; Gupta, J.K.; Driggs-Campbell, K.; Kochenderfer, M.J. Simulating emergent properties of human driving behavior using multi-agent reward augmented imitation learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 789–795. [Google Scholar]
- Deshpande, N.; Spalanzani, A. Deep reinforcement learning based vehicle navigation amongst pedestrians using a grid-based state representation. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2081–2086. [Google Scholar]
- Min, K.; Kim, H.; Huh, K. Deep Q learning based high level driving policy determination. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 226–231. [Google Scholar]
- Huang, Z.; Xu, X.; He, H.; Tan, J.; Sun, Z. Parameterized batch reinforcement learning for longitudinal control of autonomous land vehicles. IEEE Trans. Syst. Man, Cybern. Syst. 2017, 49, 730–741. [Google Scholar] [CrossRef]
- Paxton, C.; Raman, V.; Hager, G.D.; Kobilarov, M. Combining neural networks and tree search for task and motion planning in challenging environments. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6059–6066. [Google Scholar]
- Chen, L.; Chen, Y.; Yao, X.; Shan, Y.; Chen, L. An adaptive path tracking controller based on reinforcement learning with urban driving application. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2411–2416. [Google Scholar]
- Liu, J.; Wang, Z.; Zhang, L. Integrated Vehicle-Following Control for Four-Wheel-Independent-Drive Electric Vehicles Against Non-Ideal V2X Communication. IEEE Trans. Veh. Technol. 2022, 71, 3648–3659. [Google Scholar] [CrossRef]
- Zhou, H.; Aral, A.; Brandić, I.; Erol-Kantarci, M. Multiagent Bayesian Deep Reinforcement Learning for Microgrid Energy Management Under Communication Failures. IEEE Internet Things J. 2021, 9, 11685–11698. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Y.; Fortino, G.; Guan, Q.; Liu, J.; Song, J. Software escalation prediction based on deep learning in the cognitive internet of vehicles. IEEE Trans. Intell. Transp. Syst 2022, 23, 25408–25418. [Google Scholar] [CrossRef]
- Blumenkamp, J.; Morad, S.; Gielis, J.; Li, Q.; Prorok, A. A framework for real-world multi-robot systems running decentralized GNN-based policies. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 8772–8778. [Google Scholar]
- Chen, S.; Leng, Y.; Labi, S. A deep learning algorithm for simulating autonomous driving considering prior knowledge and temporal information. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 305–321. [Google Scholar] [CrossRef]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Lesort, T.; Lomonaco, V.; Stoian, A.; Maltoni, D.; Filliat, D.; Díaz-Rodríguez, N. Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges. Inf. Fusion 2020, 58, 52–68. [Google Scholar] [CrossRef]
- He, X.; Stapel, J.; Wang, M.; Happee, R. Modelling perceived risk and trust in driving automation reacting to merging and braking vehicles. Transp. Res. Part F Traffic Psychol. Behav. 2022, 86, 178–195. [Google Scholar] [CrossRef]
- Kolekar, S.; de Winter, J.; Abbink, D. Human-like driving behaviour emerges from a risk-based driver model. Nat. Commun. 2020, 11, 4850. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Zhao, J.; Hoogendoorn, S.; Wang, M. A single-layer approach for joint optimization of traffic signals and cooperative vehicle trajectories at isolated intersections. Transp. Res. Part C Emerg. Technol. 2022, 134, 103459. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. arXiv 2021, arXiv:2107.03342. [Google Scholar] [CrossRef]


| Refs. | Topic | Year | Range of Discussions | Characteristic | |||
|---|---|---|---|---|---|---|---|
| Framework | RL | DRL | GRL | ||||
| [27] | decision-making | 2018 | ✕ | ✕ | ✕ | ✕ | Rule-based methods and application were mainly discussed. |
| [28] | Planning; decision-making | 2018 | ✕ | ✓ | ✕ | ✕ | A wide range of categories of decision-making approaches were summarized. |
| [23] | decision-making | 2021 | ✓ | ✓ | ✓ | ✕ | A framework was proposed, and several categories of methods were summarized. |
| [24] | DRL in autonomous driving | 2020 | ✕ | ✓ | ✓ | ✕ | DRL-based applications in several research fields of autonomous vehicles were presented. |
| [25] | DRL in ITS | 2021 | ✕ | ✓ | ✓ | ✕ | DRL-based approaches for ITS, as well as the principle of DRL algorithm in ITC were mainly discussed. |
| [26] | GRL in different fields | 2022 | ✕ | ✕ | ✓ | ✓ | Typical GRL-based algorithms and applications in several fields were generally summarized. |
| [29] | GRL in different fields | 2022 | ✓ | ✕ | ✕ | ✕ | Basic knowledge and general technology roadmap of CAVs were mainly summarized. |
| Ours | GRL in decison-making | 2023 | ✓ | ✓ | ✓ | ✓ | A comprehensive review of GRL-based methods for decision-making systems of CAVs were presented, including framework, related research, and validation methods. |
| Category | Algorithm | Refs. | Characteristic | Pros and Cons |
|---|---|---|---|---|
| Convolutional- Based | GCN | [49] |
|
|
| GraphSAGE | [50] |
| ||
| GWNN | [51] |
| ||
| LADIES | [52] |
| ||
| Attention- Based | GAT | [53] |
|
|
| SAGNN | [54] |
| ||
| SpGAT | [55] |
| ||
| Spatial-Temporal- Based | DynamicGCN | [56] |
|
|
| ST-GCNN | [57] |
| ||
| Social- STGCNN | [58] |
|
| Category | Algorithm | Refs. | Available Scenario | Characteristic | Pros and Cons | |
|---|---|---|---|---|---|---|
| Discrete | Continuous | |||||
| Value-Based | DQN | [71] | ✓ | ✕ |
|
|
| Double DQN | [72] | ✓ | ✕ |
| ||
| Dueling DQN | [73] | ✓ | ✕ |
| ||
| Noisy DQN | [74] | ✓ | ✕ |
| ||
| DQN with PER | [75] | ✓ | ✕ |
| ||
| Distributional DQN | [76] | ✓ | ✕ |
| ||
| Rainbow DQN | [77] | ✓ | ✕ |
| ||
| Policy-Based | REINFORCE | [78] | ✓ | ✓ |
|
|
| AC | [79] | ✓ | ✓ |
| ||
| A2C | [80] | ✓ | ✓ |
| ||
| NAF | [81] | ✕ | ✓ |
| ||
| DDPG | [82] | ✕ | ✓ |
| ||
| TD3 | [83] | ✕ | ✓ |
| ||
| PPO | [84] | ✓ | ✓ |
| ||
| Categories | Driving Policy | Derivation of Driving Behaviors |
|---|---|---|
| Value-based | State-value function | Discrete: Value of each available action. |
| Policy-based | Deterministic policy | Continuous: Specific numerical instruction of each action. |
| Stochastic policy | Discrete: Probability of each available action. | |
| Continuous: Normal distribution of each available action. |
| Category | Name | Discription | Support Language | Link |
|---|---|---|---|---|
| Simulation platform | Carla | Realistic simulation scenarios with different sensor models; focus on simulation of environmental perception system; support for RL-based decision-making; support for complex vehicle control algorithms. | Python | https://github.com/carla-simulator/carla (accessed on 8 December 2022) |
| SUMO | Macro-scale modeling of traffic scenario; multi-agent decision-making is well supported; python interface is achieved by implemented TRACI. | Python/C++ | https://www.eclipse.org/sumo/ (accessed on 15 June 2023) | |
| FLOW | A DRL-based framework that provides integration with DRL library and traffic micro-simulation platform; several traffic control benchmarking are presented. | Python | https://flow-project.github.io/ (accessed on 18 March 2023) | |
| Open-CDA | Combining Carla and SUMO for Co-simulation; full-stack prototype cooperative driving system can be achieved. | Python | https://github.com/ucla-mobility/OpenCDA (accessed on 6 October 2022) | |
| Highway-env | A gym-based simulation environment for typical traffic scenario; good support for RL-based multi-agent decision-making | Python | https://github.com/Farama-Foundation/HighwayEnv (accessed on 19 March 2023) | |
| CommonRoad | Good simulation of planning and multi-agent decision-making of autonomous vehicles; comprehensive support for RL-based methods; provides numerous traffic scenarios for validation. | Python | https://commonroad.in.tum.de/ (accessed on 20 February 2023) | |
| Program library | Pytorch | A popular machine learning tools with fast updating and comprehensive documentation. | Python/C++ /Java | https://pytorch.org/ (accessed on 9 July 2023) |
| Tensorflow | A stable machine learning library with highly visualized and easy debugging. | Python/C++ /Java | https://www.tensorflow.org/ (accessed on 8 January 2023) | |
| Pytorch geometric | An easily write and train GNN library based on Pytorch for a wide range of applications. | Python | https://pytorch-geometric.readthedocs.io/en/latest/index.html (accessed on 5 June 2023) | |
| Tensorflow geometric | An efficient GNN library based on Tensorflow. | Python | https://github.com/CrawlScript/tf_geometric (accessed on 16 September 2022) | |
| RLlib | A production-level and highly distributed RL-based framework supporting both Pytorch and Tensorflow; unified and simple APIs for a large variety of industrial applications. | Python | https://docs.ray.io/en/latest/rllib/index.html (accessed on 12 January 2023) | |
| Stable Baseline3 | A set of reliable implementations of RL-based algorithms in PyTorch; high frequency of continuous updates. | Python | https://github.com/DLR-RM/stable-baselines3 (accessed on 25 October 2022) | |
| Pfrl library | A library that implements various state-of-the-art DRL-based algorithms. | Python | https://github.com/pfnet/pfrl (accessed on 7 May 2023) |
| Method | Average Reward of DRL | Average Reward of GRL | Optimization Rate (%) |
|---|---|---|---|
| Double DQN | 337.79 | 374.51 | 10.87 |
| AC | 132.40 | 192.63 | 45.49 |
| A2C | 298.61 | 363.93 | 21.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Li, X.; Tang, Y.; Gao, X.; Yang, F.; Li, Z. Graph Reinforcement Learning-Based Decision-Making Technology for Connected and Autonomous Vehicles: Framework, Review, and Future Trends. Sensors 2023, 23, 8229. https://doi.org/10.3390/s23198229
Liu Q, Li X, Tang Y, Gao X, Yang F, Li Z. Graph Reinforcement Learning-Based Decision-Making Technology for Connected and Autonomous Vehicles: Framework, Review, and Future Trends. Sensors. 2023; 23(19):8229. https://doi.org/10.3390/s23198229
Chicago/Turabian StyleLiu, Qi, Xueyuan Li, Yujie Tang, Xin Gao, Fan Yang, and Zirui Li. 2023. "Graph Reinforcement Learning-Based Decision-Making Technology for Connected and Autonomous Vehicles: Framework, Review, and Future Trends" Sensors 23, no. 19: 8229. https://doi.org/10.3390/s23198229
APA StyleLiu, Q., Li, X., Tang, Y., Gao, X., Yang, F., & Li, Z. (2023). Graph Reinforcement Learning-Based Decision-Making Technology for Connected and Autonomous Vehicles: Framework, Review, and Future Trends. Sensors, 23(19), 8229. https://doi.org/10.3390/s23198229