
Polygon Simplification for the Efficient Approximate Analytics of Georeferenced Big Data




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
2.1. Spatial Approximate Query Processing
2.2. Line Generalization Algorithms
2.3. Applications of Line Simplification in Approximate Geospatial Analysis
3. Theoretical Background
3.1. Spatial Sampling in Dynamic Scenarios
3.2. Representative On-the-Fly Geospatial Sampling
3.3. Problem Formulation
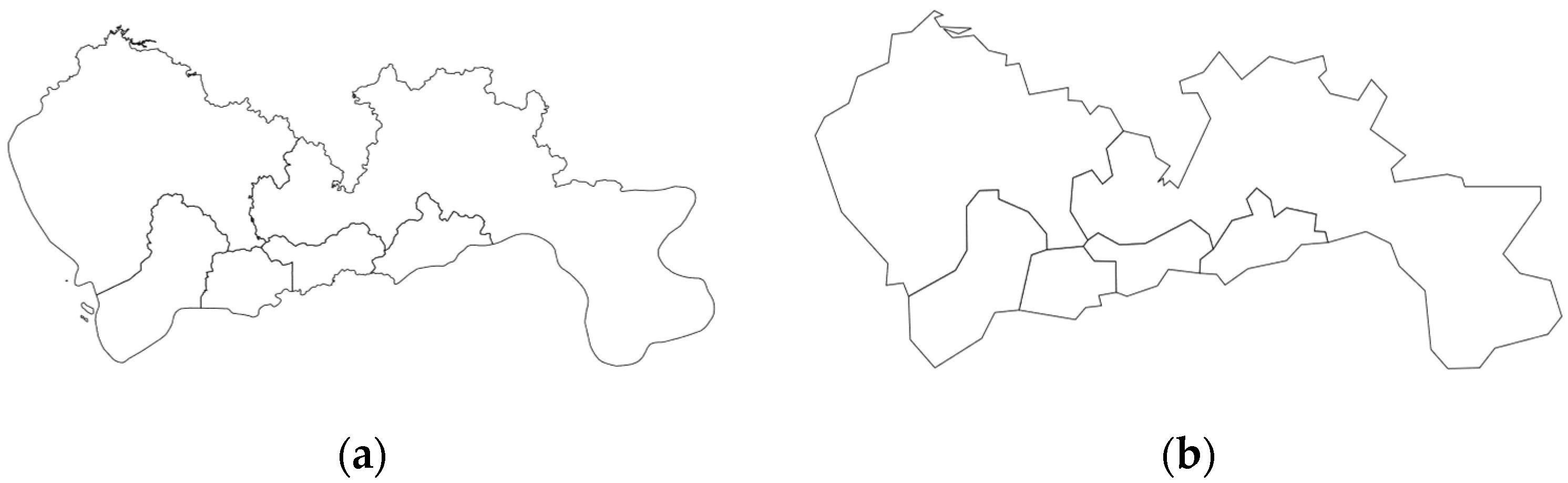
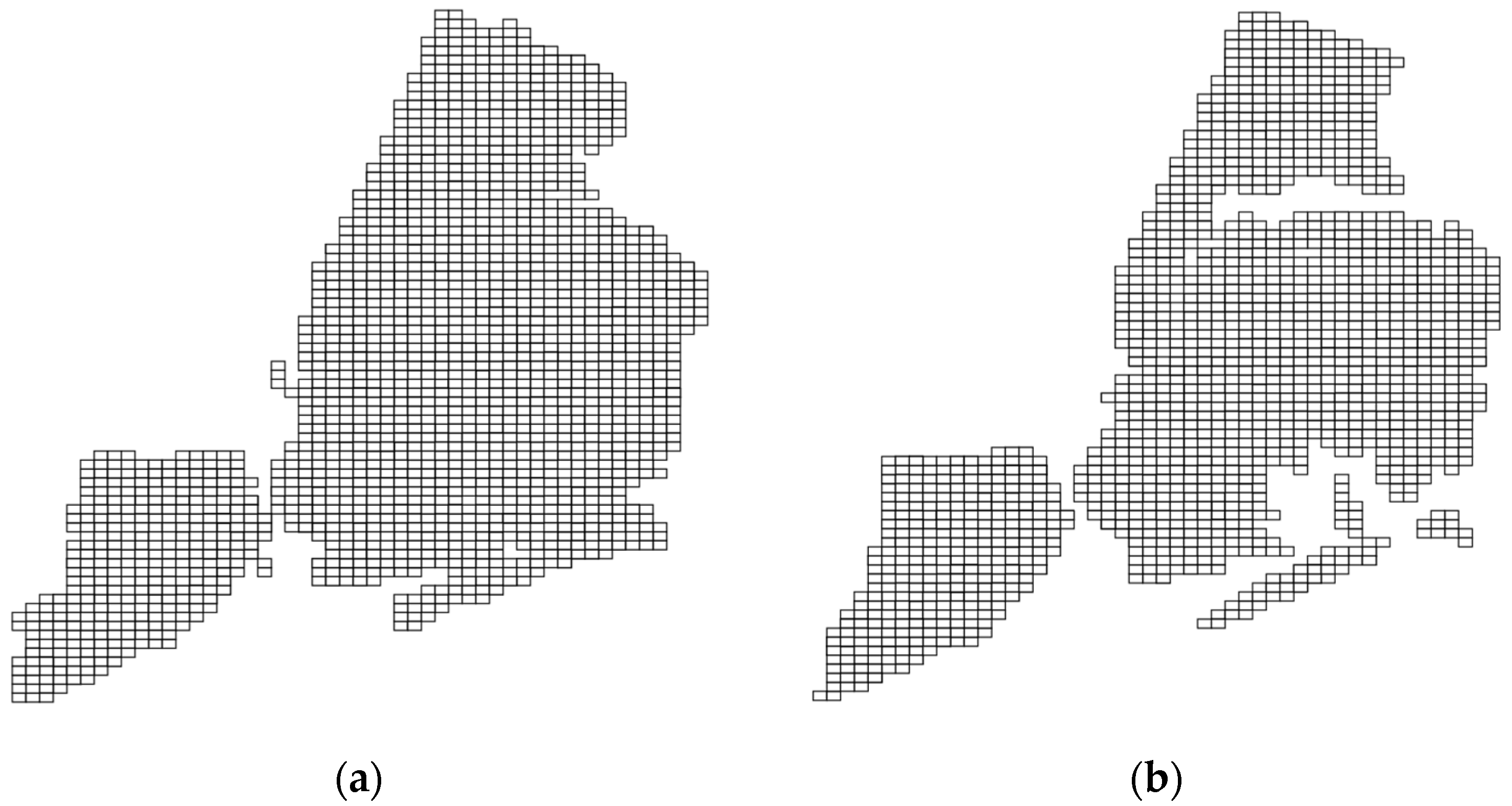
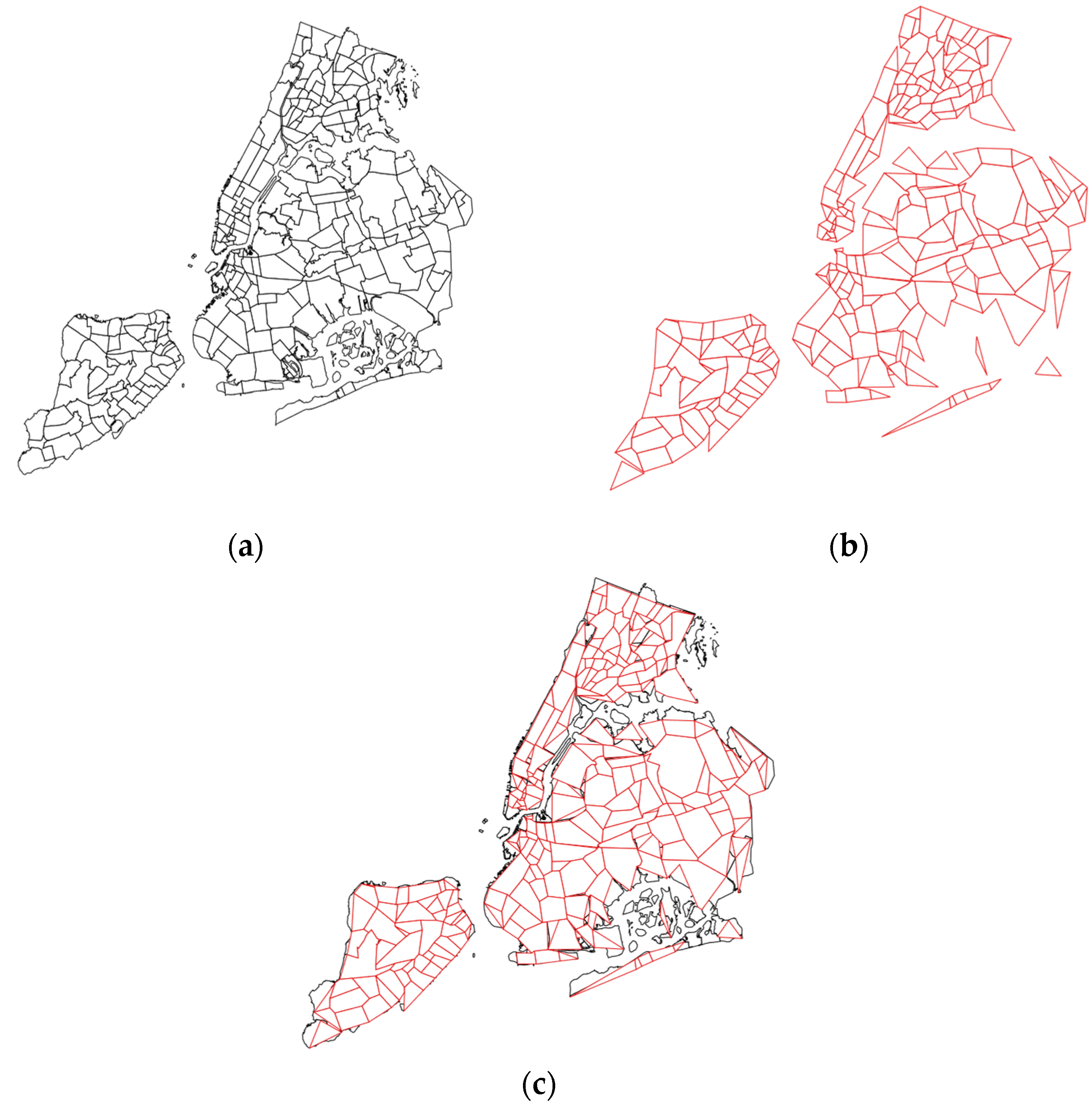
3.4. Geometric Generalization
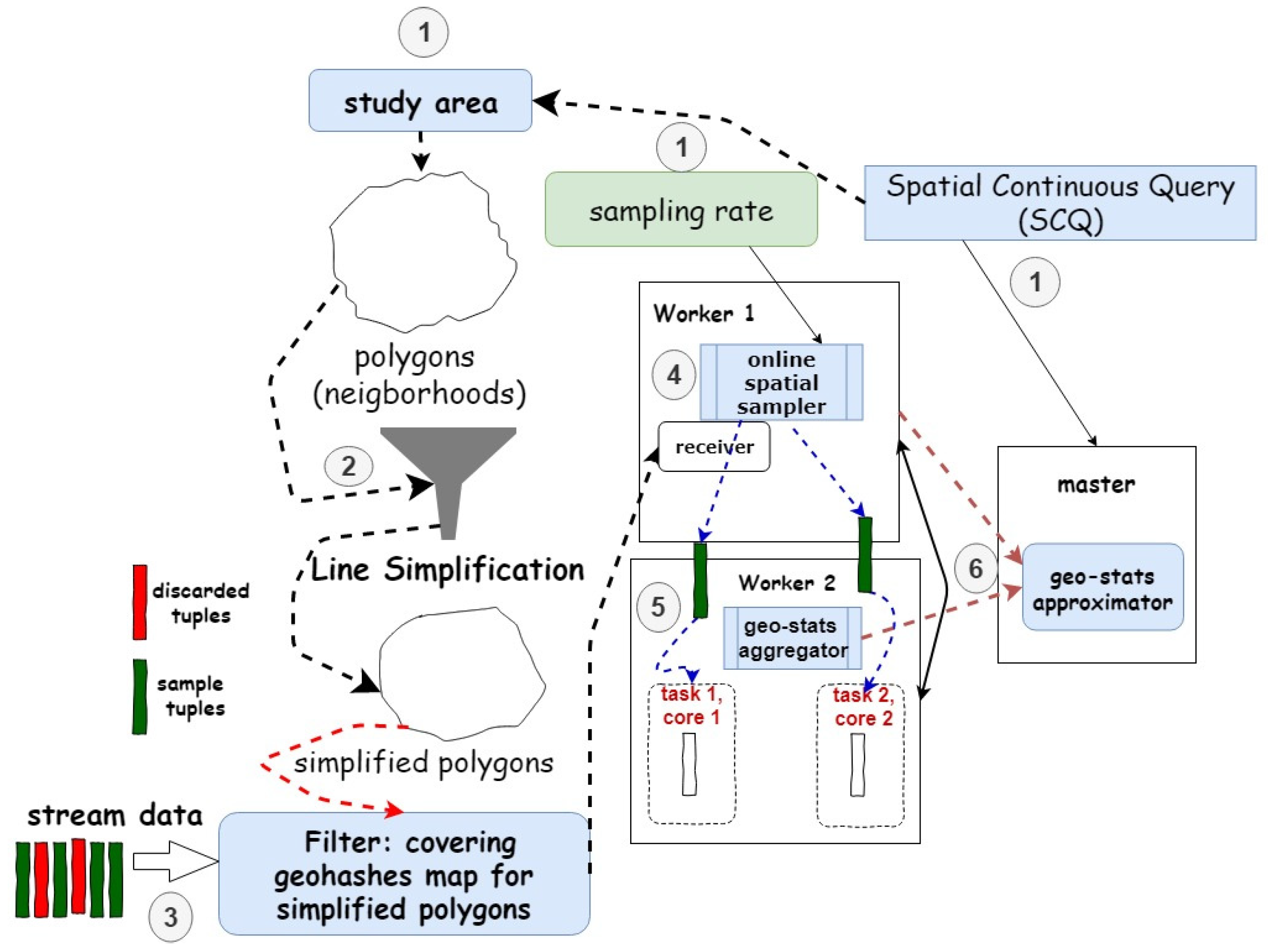
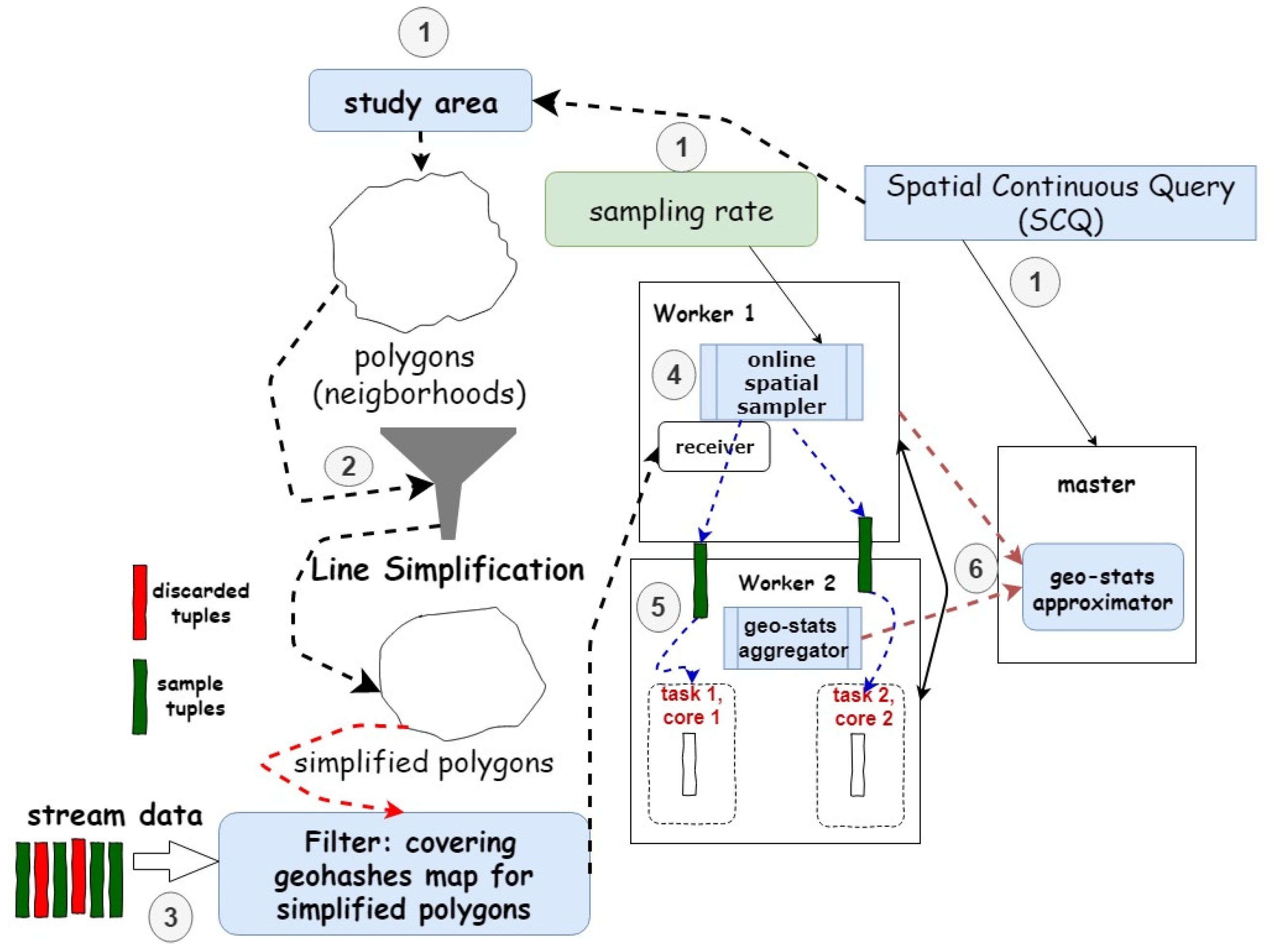
4. Representative Geo-Sampling for Dynamic Application Scenarios: An Overview of the GeoRAP Solution
4.1. Case Scenario and Baseline Systems
4.2. GeoRAP Design and Operation
| Algorithm 1: GeoRAP Workflow |
| /* geohashSize: geohash size, lsa: line simplification algorithm*/ Input: geo-stream, SpatialQuery (SQ), samplingRate, polygons, geohashSize, lsa |
| //lsa: Ramer-Douglas-Peucker simplifiedPolygons = lineSimplification(polygons, lsa) |
| geoCover ← computeGeoCover (simplifiedPolygons, geohashSize) |
| strata = stratify (geoCover) |
| Foreach query window time interval do |
| repSample = //tuples sampled in current time window |
| Foreach stratum in strata do |
| stratumSample = sample (stratum, samplingRate) |
| repSample.add(stratumSample) |
| End |
| //Calculate and feed incremental result every time window |
| stepwiseOutput ← execute (SQ, repSample) |
| return stepwiseOutput w/rigorous error bounds (i.e., standard error, distance, correlation coefficient, EMD) |
| End |
4.3. Spatial Queries Supported
4.4. Error Bounds Calculation
4.4.1. Batch Mode Error Bounds Calculation
4.4.2. Online Mode Error Bounds Calculation
4.5. Some Primary Implementation Insights
5. Experimental Evaluation Work and Performance Results
5.1. Deployment Settings and Benchmarking
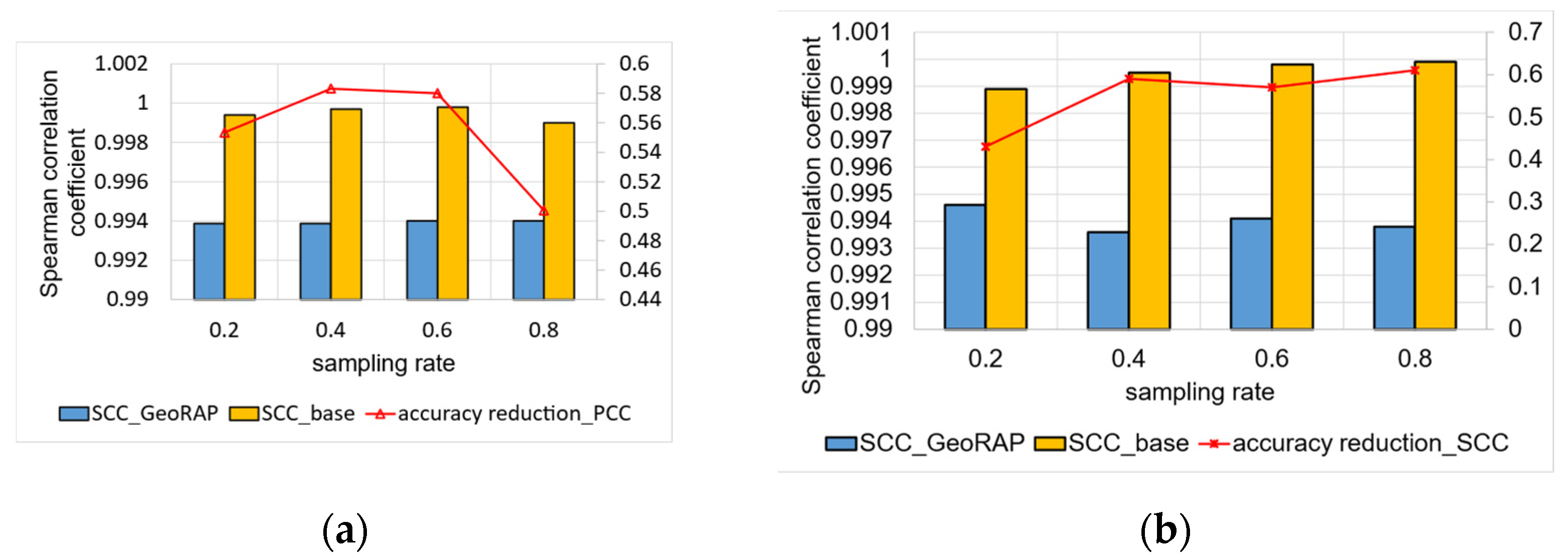
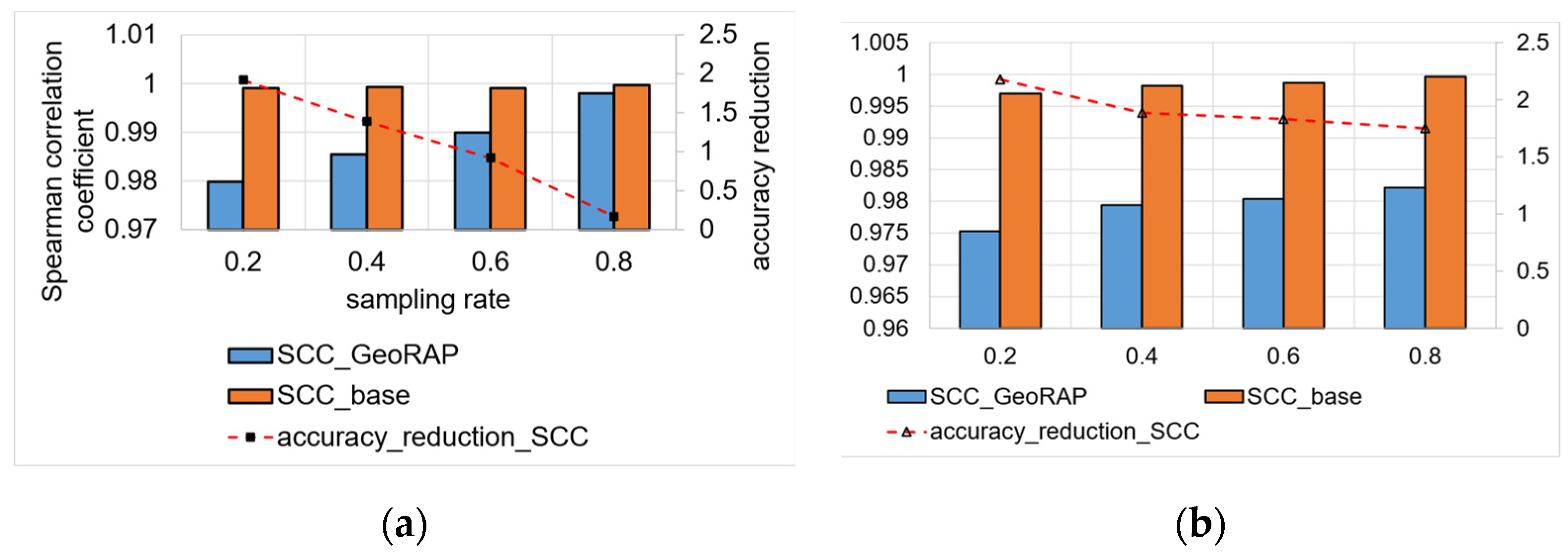
5.2. Performance Testing and Results Discussion
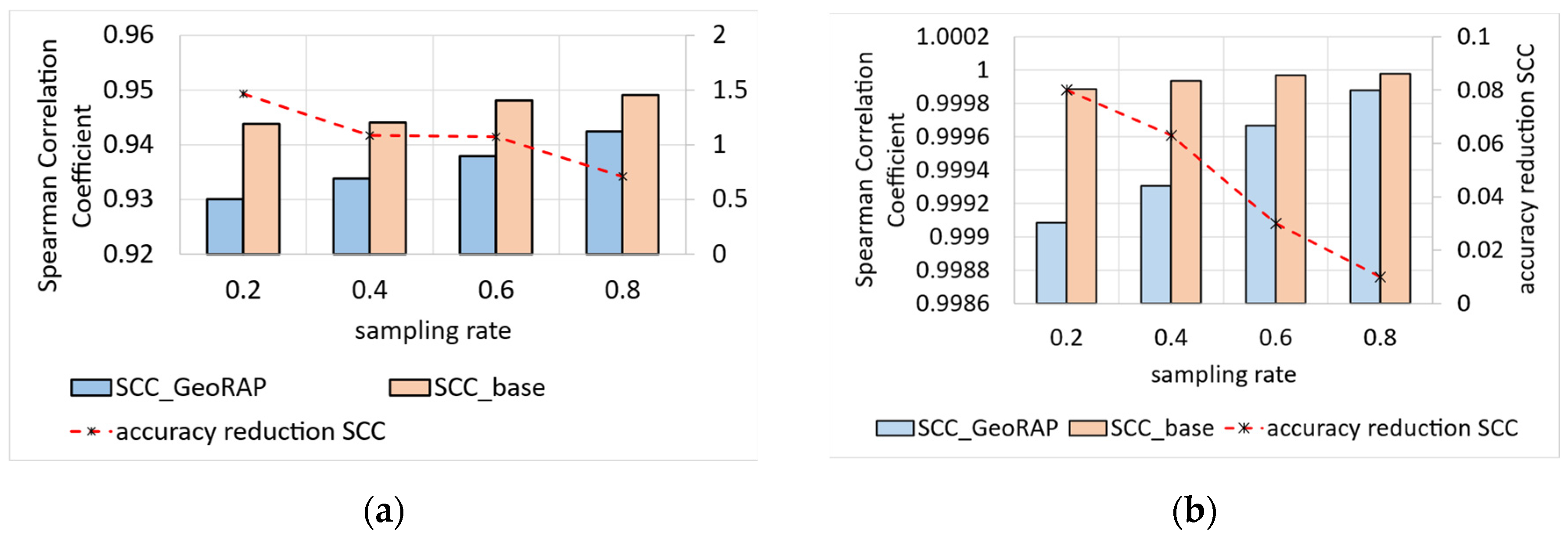
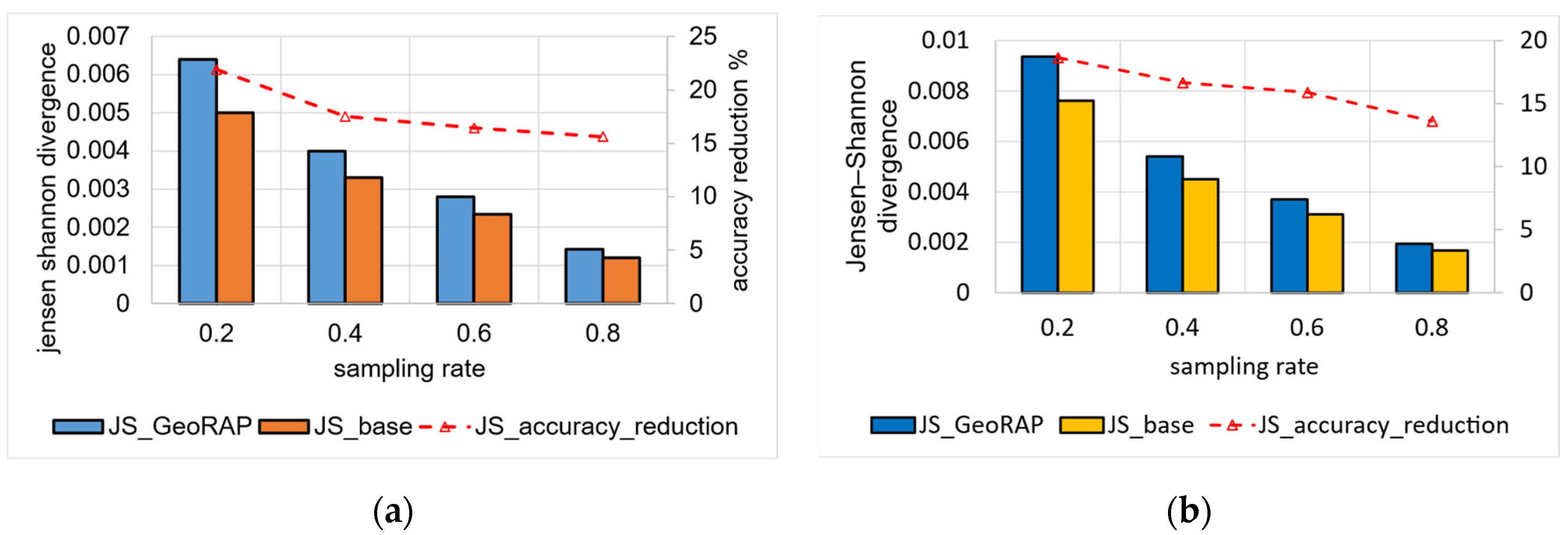
5.2.1. Top-N Queries (Batch Mode)
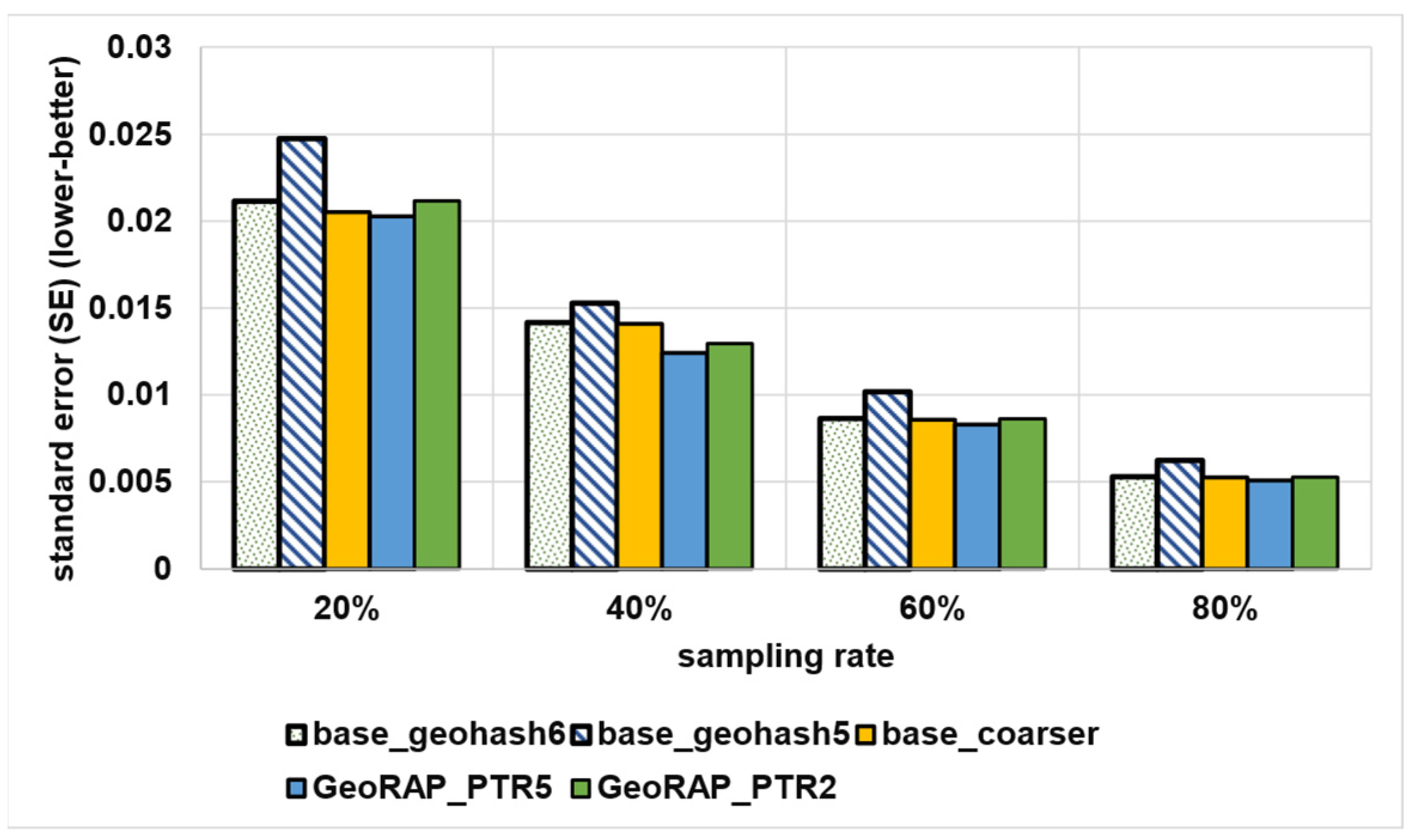
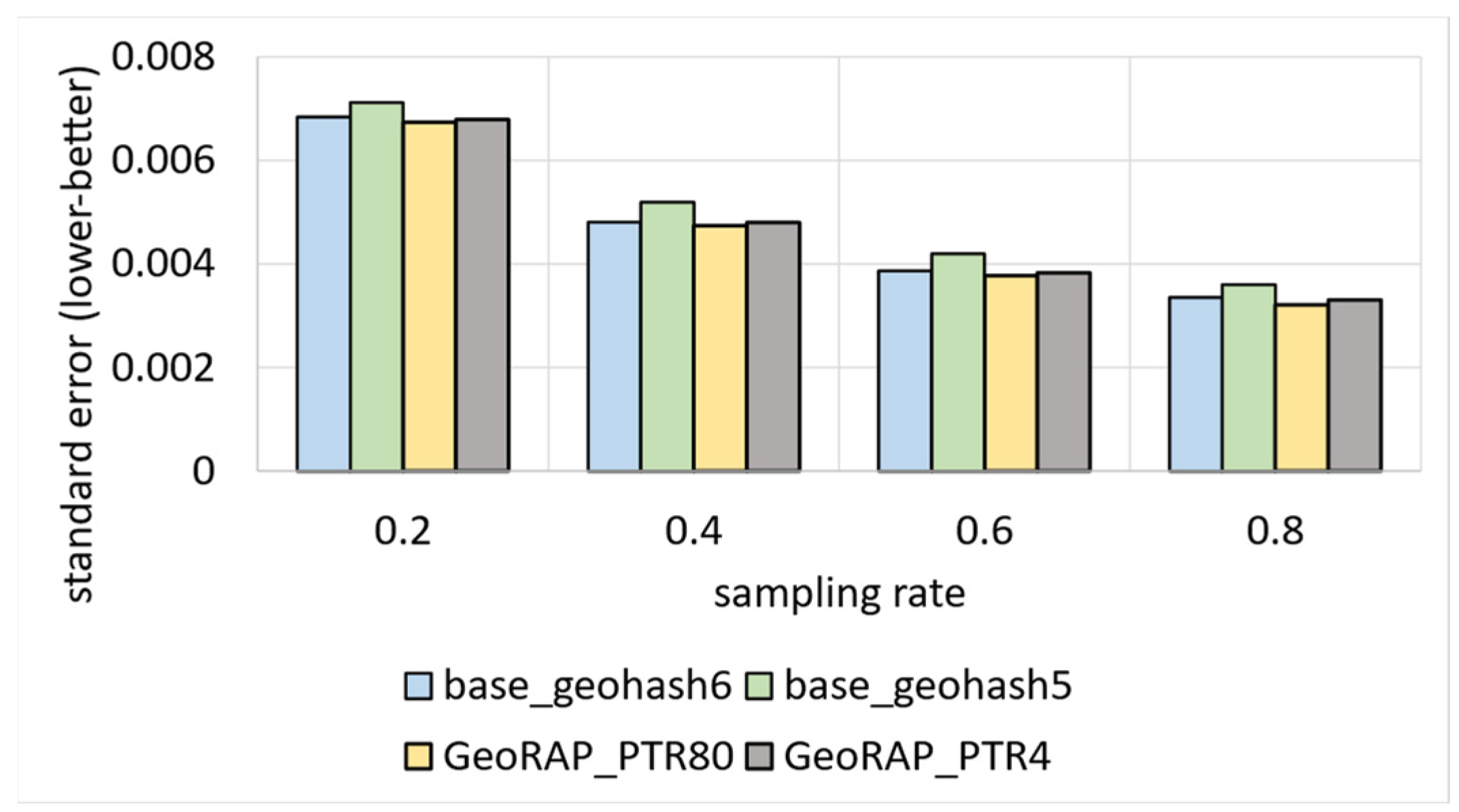
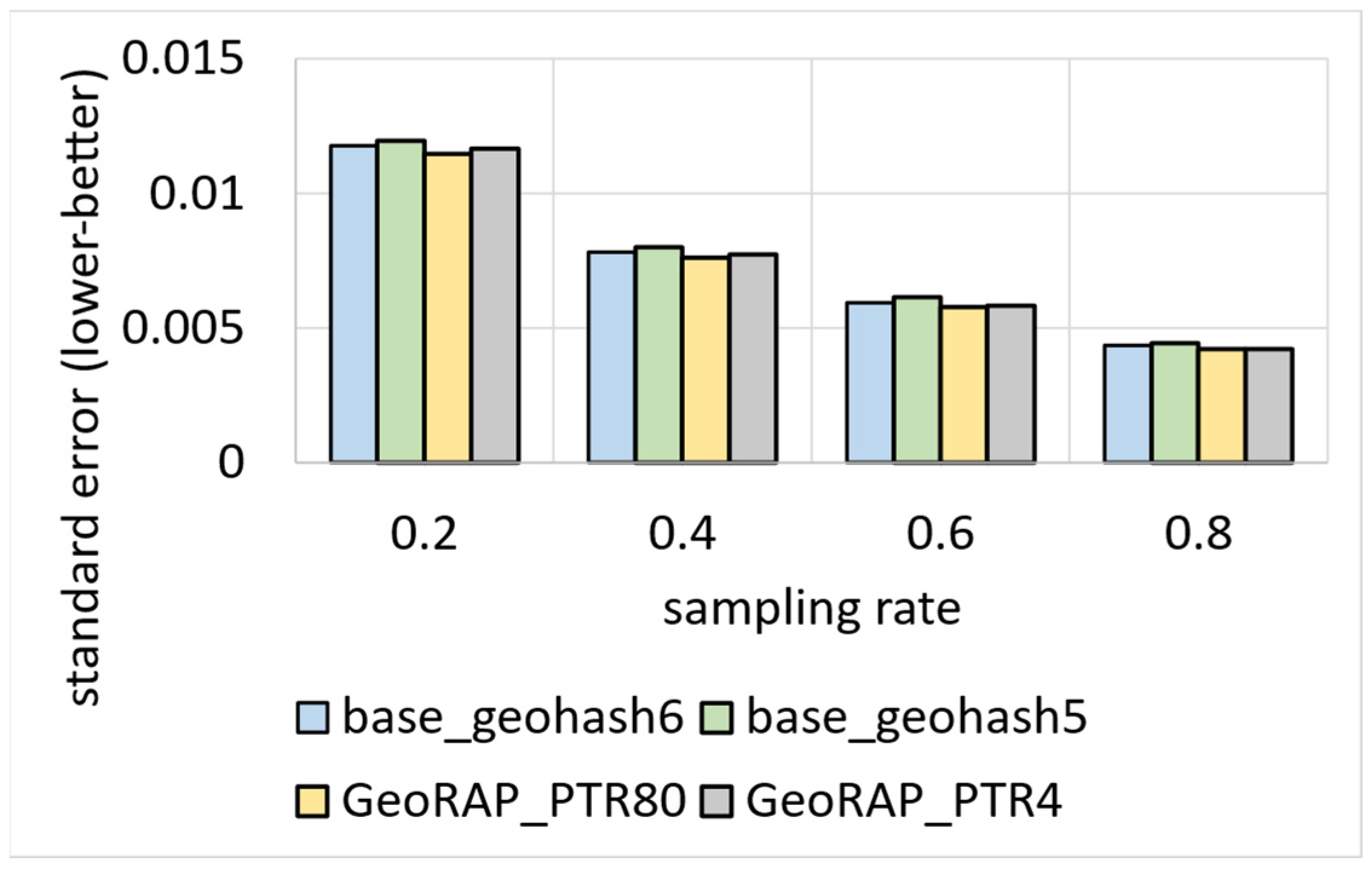
5.2.2. Geo-Stats (Count Queries)—Batch Mode
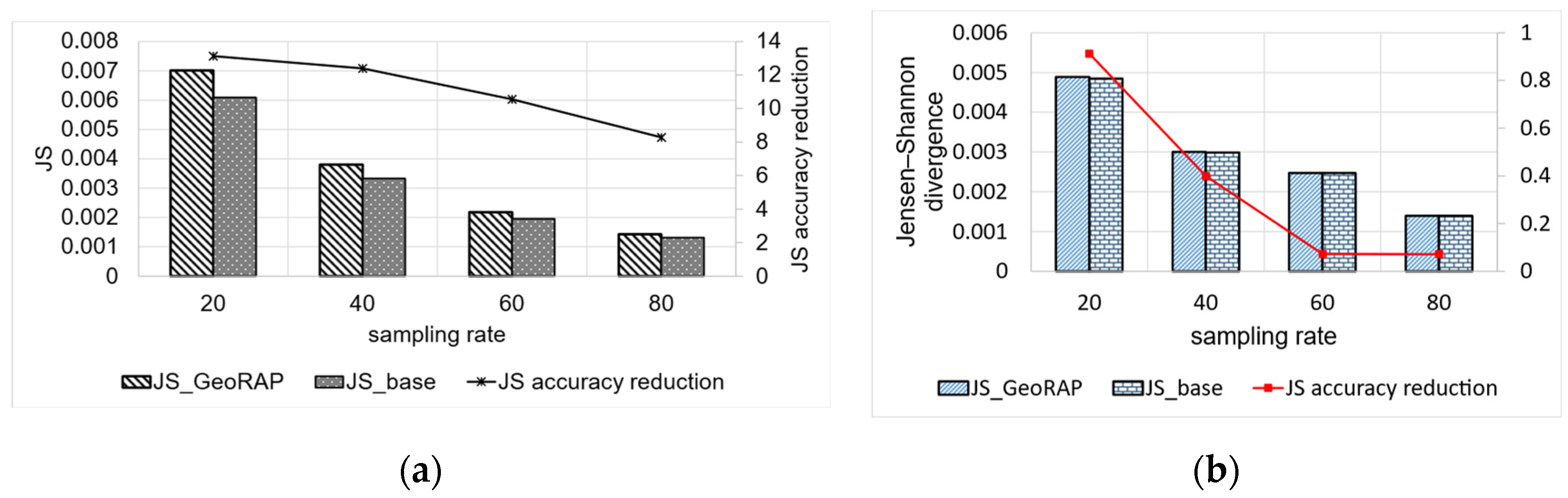
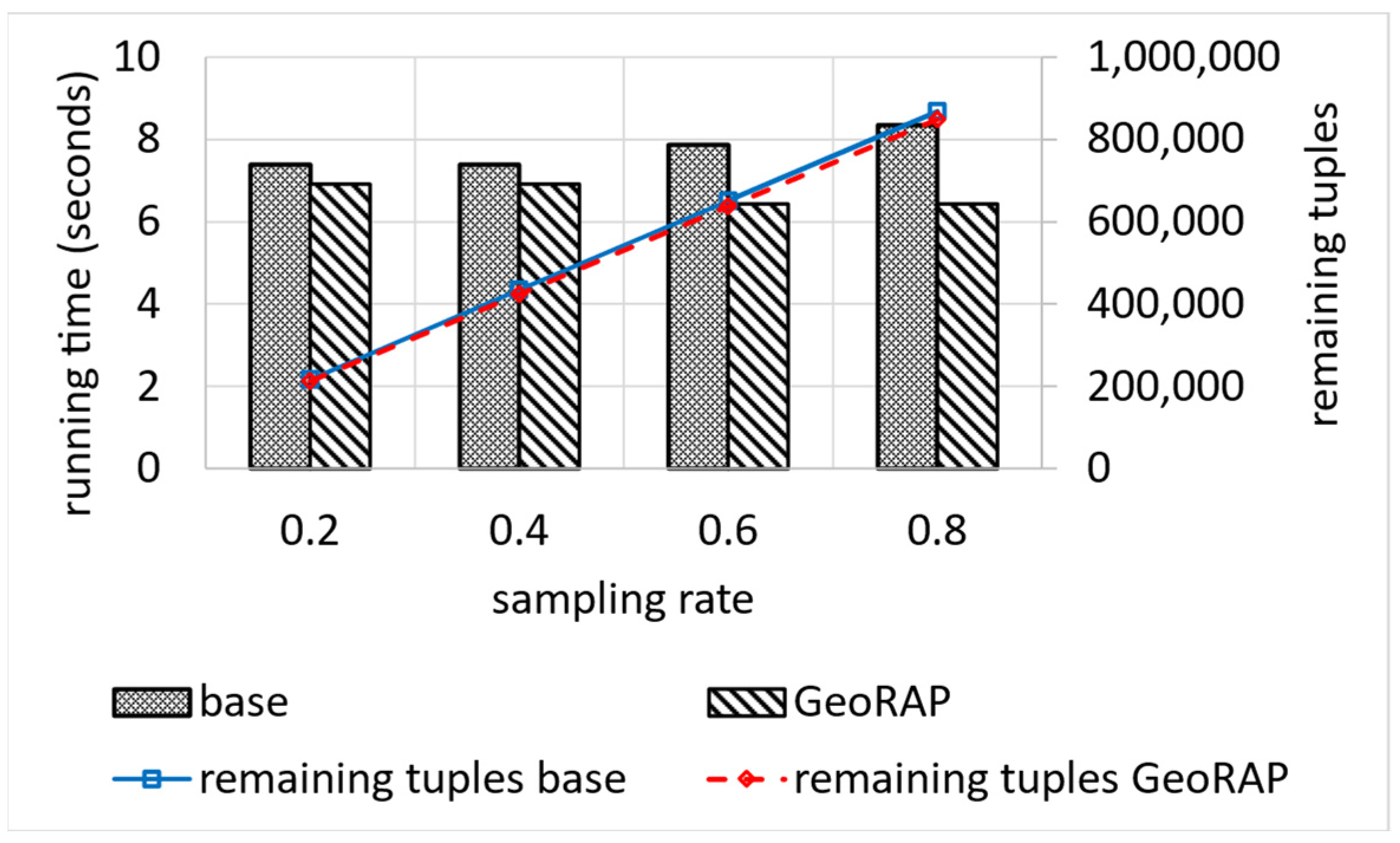
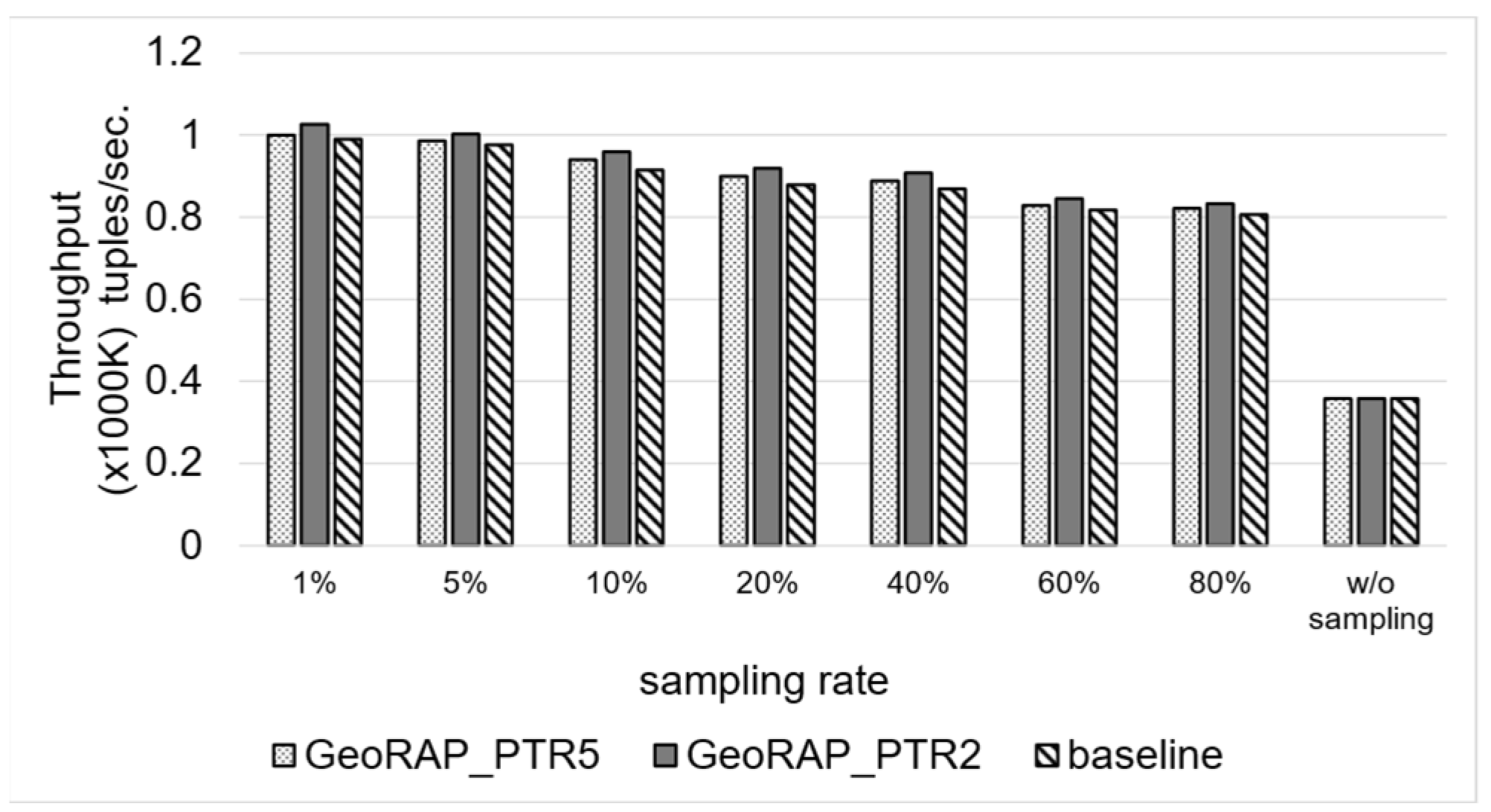
5.2.3. Testing Performance of Dynamic Operation Mode
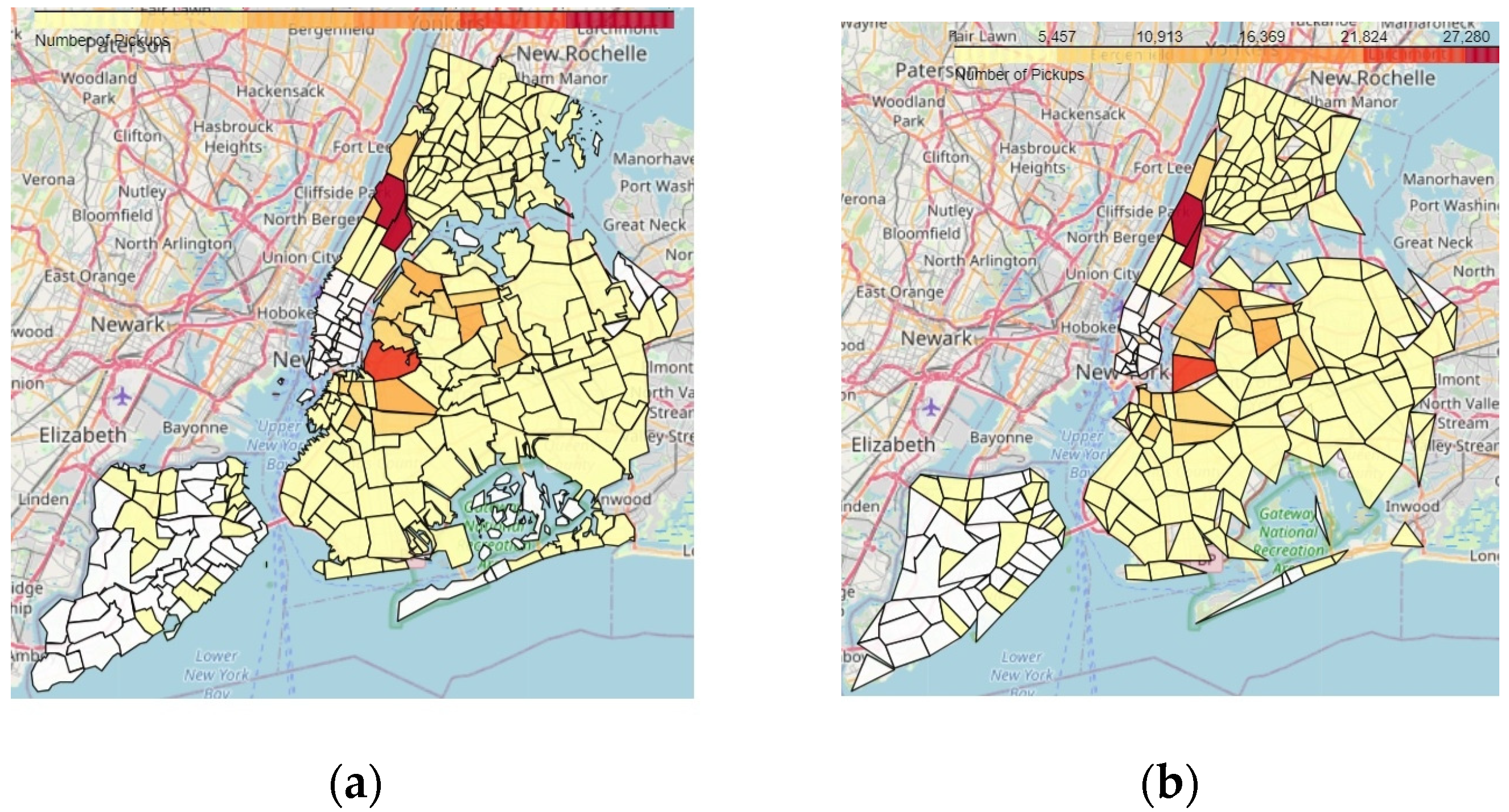
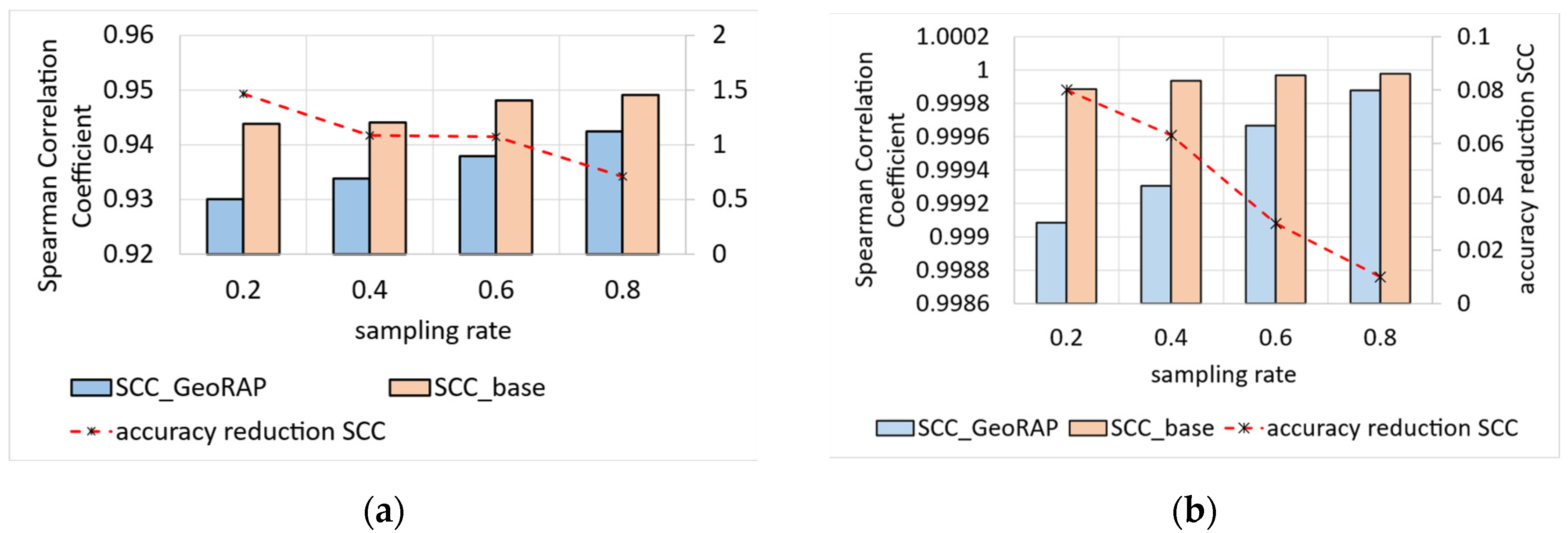
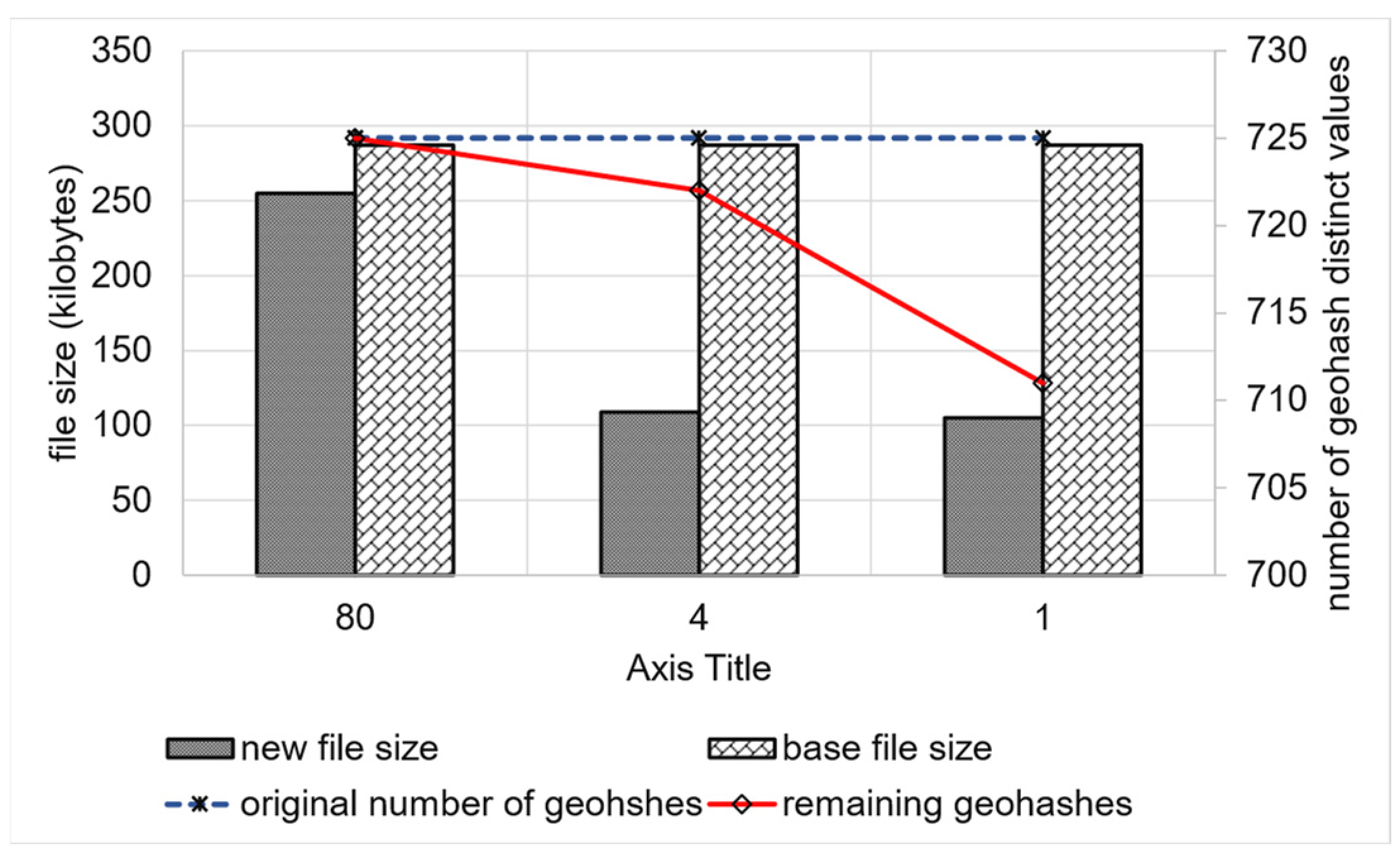
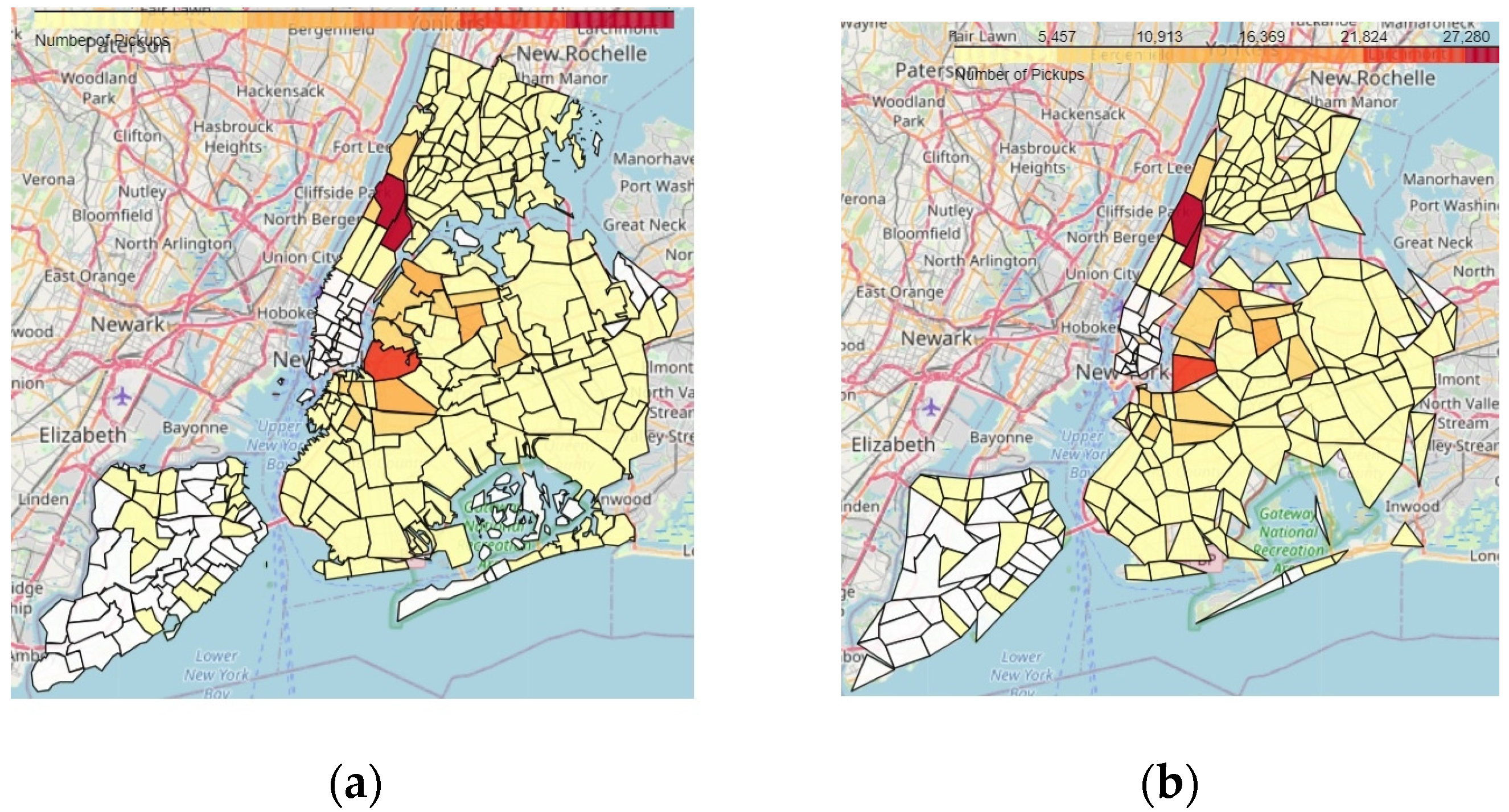
5.2.4. Testing the Ability to Generate Region-Based Aggregate Geo-Maps
6. Conclusive Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, D. The construction of smart city information system based on the Internet of Things and cloud computing. Comput. Commun. 2020, 150, 158–166. [Google Scholar] [CrossRef]
- Chen, G.; Zou, W.; Jing, W.; Wei, W.; Scherer, R. Improving the Efficiency of the EMS-Based Smart City: A Novel Distributed Framework for Spatial Data. IEEE Trans. Ind. Inform. 2022, 19, 594–604. [Google Scholar] [CrossRef]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Spatially Representative Online Big Data Sampling for Smart Cities. In Proceedings of the 2020 IEEE 25th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Pisa, Italy, 14–16 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams. Sensors 2021, 21, 4160. [Google Scholar] [CrossRef] [PubMed]
- Armbrust, M.; Das, T.; Torres, J.; Yavuz, B.; Zhu, S.; Xin, R.; Ghodsi, A.; Stoica, I.; Zaharia, M. Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Foschini, L.; Montanari, R. Spatial-Aware Approximate Big Data Stream Processing. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Wei, X.; Liu, Y.; Wang, X.; Gao, S.; Chen, L. Online adaptive approximate stream processing with customized error control. IEEE Access 2019, 7, 25123–25137. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Shi, W.; Cheung, C. Performance evaluation of line simplification algorithms for vector generalization. Cartogr. J. 2006, 43, 27–44. [Google Scholar] [CrossRef]
- Reumann, K.; Witkam, A. Optimizing Curve Segmentation in Computer Graphics; International Computing Symposium: Amsterdam, The Netherlands, 1974. [Google Scholar]
- Zhao, Z.; Saalfeld, A. Linear-time sleeve-fitting polyline simplification algorithms. Proc. AutoCarto 1997, 13, 214–223. [Google Scholar]
- Lang, T. Rules for the robot draughtsmen. Geogr. Mag. 1969, 42, 50–51. [Google Scholar]
- Visvalingam, M.; Whyatt, J.D. Line generalization by repeated elimination of points. In Landmarks in Mapping; Routledge: Oxfordshire, UK, 2017; pp. 144–155. [Google Scholar]
- Herbst, N.R.; Kounev, S.; Reussner, R. Elasticity in cloud computing: What it is, and what it is not. In Proceedings of the 10th International Conference on Autonomic Computing (ICAC 13), San Jose, CA, USA, 26–28 June 2013; pp. 23–27. [Google Scholar]
- Ramnarayan, J.; Mozafari, B.; Wale, S.; Menon, S.; Kumar, N.; Bhanawat, H.; Chakraborty, S.; Mahajan, Y.; Mishra, R.; Bachhav, K. Snappydata: A hybrid transactional analytical store built on spark. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 2153–2156. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Olma, M.; Papapetrou, O.; Appuswamy, R.; Ailamaki, A. Taster: Self-tuning, elastic and online approximate query processing. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 482–493. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Casimiro, F.; Corradi, A.; Foschini, L. Cost-effective strategies for provisioning NoSQL storage services in support for industry 4.0. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC), Natal, Brazil, 25–28 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 01227–01232. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Efficient QoS-Aware Spatial Join Processing for Scalable NoSQL Storage Frameworks. IEEE Trans. Netw. Serv. Manag. 2020, 18, 2437–2449. [Google Scholar] [CrossRef]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Big Spatial Data Management for the Internet of Things: A Survey. J. Netw. Syst. Manag. 2020, 28, 990–1035. [Google Scholar] [CrossRef]
- Goiri, I.; Bianchini, R.; Nagarakatte, S.; Nguyen, T.D. Approxhadoop: Bringing approximations to mapreduce frameworks. In Proceedings of the Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems, Istanbul, Turkey, 14–18 March 2015; pp. 383–397. [Google Scholar]
- Xie, D.; Li, F.; Yao, B.; Li, G.; Zhou, L.; Guo, M. Simba: Efficient in-memory spatial analytics. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1071–1085. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. Spatialhadoop: A mapreduce framework for spatial data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1352–1363. [Google Scholar]
- Ordonez-Ante, L.; Van Seghbroeck, G.; Wauters, T.; Volckaert, B.; De Turck, F. EXPLORA: Interactive Querying of Multidimensional Data in the Context of Smart Cities. Sensors 2020, 20, 2737. [Google Scholar] [CrossRef] [PubMed]
- Al Jawarneh, I.M.; Foschini, L.; Bellavista, P. Efficient Integration of Heterogeneous Mobility-Pollution Big Data for Joint Analytics at Scale with QoS Guarantees. Future Internet 2023, 15, 263. [Google Scholar] [CrossRef]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Efficient Geospatial Analytics on Time Series Big Data. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3002–3008. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Efficiently Integrating Mobility and Environment Data for Climate Change Analytics. In Proceedings of the 2021 IEEE 26th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Porto, Portugal, 25–27 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Xiong, W.; Wang, X.; Li, H. Efficient Large-Scale GPS Trajectory Compression on Spark: A Pipeline-Based Approach. Electronics 2023, 12, 3569. [Google Scholar] [CrossRef]
- Gao, S.; Li, M.; Rao, J.; Mai, G.; Prestby, T.; Marks, J.; Hu, Y. Automatic urban road network extraction from massive GPS trajectories of taxis. In Handbook of Big Geospatial Data; Springer: Berlin/Heidelberg, Germany, 2021; pp. 261–283. [Google Scholar]
- Qian, H.; Lu, Y. Simplifying GPS Trajectory Data with Enhanced Spatial-Temporal Constraints. ISPRS Int. J. Geo-Inf. 2017, 6, 329. [Google Scholar] [CrossRef]
- Zheng, L.; Feng, Q.; Liu, W.; Zhao, X. Discovering trip hot routes using large scale taxi trajectory data. In Advanced Data Mining and Applications, Proceedings of the 12th International Conference, ADMA 2016, Gold Coast, QLD, Australia, 12–15 December 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 534–546. [Google Scholar]
- Lin, C.-Y.; Hung, C.-C.; Lei, P.-R. A velocity-preserving trajectory simplification approach. In Proceedings of the 2016 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Hsinchu, Taiwan, 25–27 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 58–65. [Google Scholar]
- Liu, J.; Li, H.; Yang, Z.; Wu, K.; Liu, Y.; Liu, R.W. Adaptive douglas-peucker algorithm with automatic thresholding for AIS-based vessel trajectory compression. IEEE Access 2019, 7, 150677–150692. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, Y.; Yuan, X.; Wang, H. Compressing AIS Trajectory Data Based on the Multi-Objective Peak Douglas–Peucker Algorithm. IEEE Access 2023, 11, 6802–6821. [Google Scholar] [CrossRef]
- Tang, C.; Wang, H.; Zhao, J.; Tang, Y.; Yan, H.; Xiao, Y. A method for compressing AIS trajectory data based on the adaptive-threshold Douglas-Peucker algorithm. Ocean Eng. 2021, 232, 109041. [Google Scholar] [CrossRef]
- Lee, W.; Cho, S.-W. AIS Trajectories Simplification Algorithm Considering Topographic Information. Sensors 2022, 22, 7036. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G. A method for simplifying ship trajectory based on improved Douglas–Peucker algorithm. Ocean Eng. 2018, 166, 37–46. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, S. Map vector tile construction for arable land spatial connectivity analysis based on the Hadoop cloud platform. Front. Earth Sci. 2023, 11, 1234732. [Google Scholar] [CrossRef]
- Amiraghdam, A.; Diehl, A.; Pajarola, R. LOCALIS: Locally-adaptive Line Simplification for GPU-based Geographic Vector Data Visualization. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 443–453. [Google Scholar]
- Wu, M.; Chen, T.; Zhang, K.; Jing, Z.; Han, Y.; Chen, M.; Wang, H.; Lv, G. An Efficient Visualization Method for Polygonal Data with Dynamic Simplification. ISPRS Int. J. Geo-Inf. 2018, 7, 138. [Google Scholar] [CrossRef]
- Sasaki, I.; Arikawa, M.; Lu, M.; Sato, R. Thematic Geo-Density Heatmapping for Walking Tourism Analytics using Semi-Ready GPS Trajectories. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4944–4951. [Google Scholar]
- Sasaki, I.; Arikawa, M.; Lu, M.; Sato, R. Mobile Collaborative Heatmapping to Infer Self-Guided Walking Tourists’ Preferences for Geomedia. ISPRS Int. J. Geo-Inf. 2023, 12, 283. [Google Scholar] [CrossRef]
- Sun, G.; Zhai, S.; Li, S.; Liang, R. RectMap: A Boundary-Reserved Map Deformation Approach for Visualizing Geographical Map. Chin. J. Electron. 2018, 27, 927–933. [Google Scholar] [CrossRef]
- Lohr, S.L. Sampling: Design and Analysis; Nelson Education: Toronto, ON, Canada, 2009. [Google Scholar]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46 (Suppl. 1), 234–240. [Google Scholar] [CrossRef]
- Visvalingam, M.; Whyatt, J.D. The Douglas-Peucker algorithm for line simplification: Re-evaluation through visualization. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 1990; Volume 9, pp. 213–225. [Google Scholar]
- Lehman, A.; O’Rourke, N.; Hatcher, L.; Stepanski, E. JMP for Basic Univariate and Multivariate Statistics: Methods for Researchers and Social Scientists; Sas Institute: Minato, Japan, 2013. [Google Scholar]
- Wang, G.; Chen, X.; Zhang, F.; Wang, Y.; Zhang, D. Experience: Understanding long-term evolving patterns of shared electric vehicle networks. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–12. [Google Scholar]
- Wang, A.; Machida, Y.; de Souza, P.; Mora, S.; Duhl, T.; Hudda, N.; Durant, J.L.; Duarte, F.; Ratti, C. Leveraging machine learning algorithms to advance low-cost air sensor calibration in stationary and mobile settings. Atmos. Environ. 2023, 301, 119692. [Google Scholar] [CrossRef]
- Aljawarneh, I.M.; Bellavista, P.; De Rolt, C.R.; Foschini, L. Dynamic Identification of Participatory Mobile Health Communities. In Cloud Infrastructures, Services, and IoT Systems for Smart Cities; Springer: Berlin/Heidelberg, Germany, 2017; pp. 208–217. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Jawarneh, I.M.; Foschini, L.; Bellavista, P. Polygon Simplification for the Efficient Approximate Analytics of Georeferenced Big Data. Sensors 2023, 23, 8178. https://doi.org/10.3390/s23198178
Al Jawarneh IM, Foschini L, Bellavista P. Polygon Simplification for the Efficient Approximate Analytics of Georeferenced Big Data. Sensors. 2023; 23(19):8178. https://doi.org/10.3390/s23198178
Chicago/Turabian StyleAl Jawarneh, Isam Mashhour, Luca Foschini, and Paolo Bellavista. 2023. "Polygon Simplification for the Efficient Approximate Analytics of Georeferenced Big Data" Sensors 23, no. 19: 8178. https://doi.org/10.3390/s23198178
APA StyleAl Jawarneh, I. M., Foschini, L., & Bellavista, P. (2023). Polygon Simplification for the Efficient Approximate Analytics of Georeferenced Big Data. Sensors, 23(19), 8178. https://doi.org/10.3390/s23198178