
FILNet: Fast Image-Based Indoor Localization Using an Anchor Control Network


Abstract
:1. Introduction
- (1)
- An efficient anchor feature fingerprint database construction scheme is designed based on an anchor control network. The proposed scheme has low requirements for equipment and environment and high matching efficiency and is concise;
- (2)
- A multi-angle features supplementary algorithm based on the main-direction image, similar to the ASIFT algorithm, is proposed. This algorithm is based on the image POS and cuts images from multiple views to enrich a single feature point and improve the recall rate of feature matching even when the perspective changes significantly;
- (3)
- A fast spatial indexing algorithm is designed to improve feature matching efficiency to decrease time consumption, and a homography matrix is introduced to verify the correctness of matching using the projection error rate and delete the error matching points.
2. Related Work
2.1. Feature Matching
2.2. Indoor Localization
3. Proposed Model
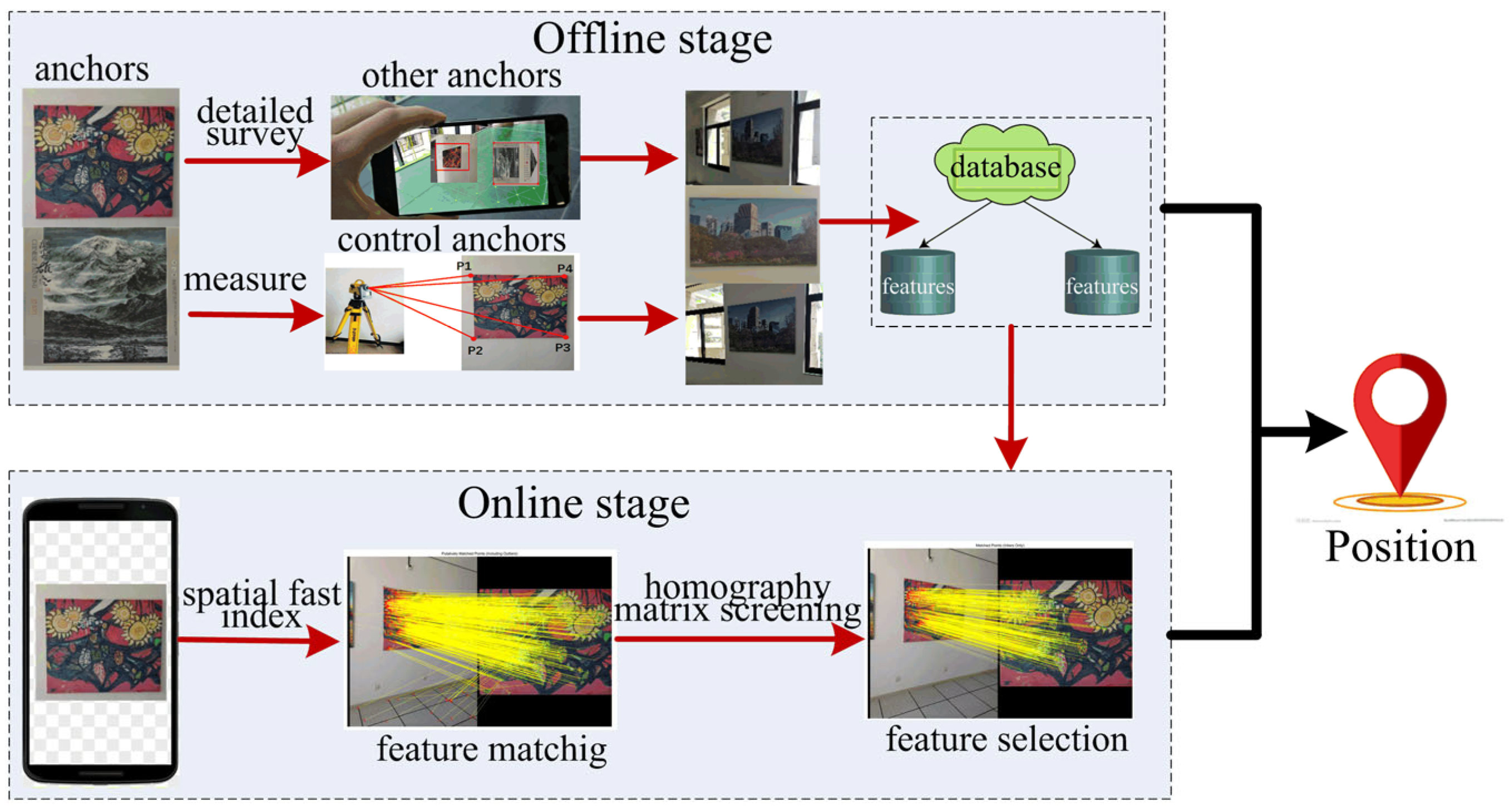
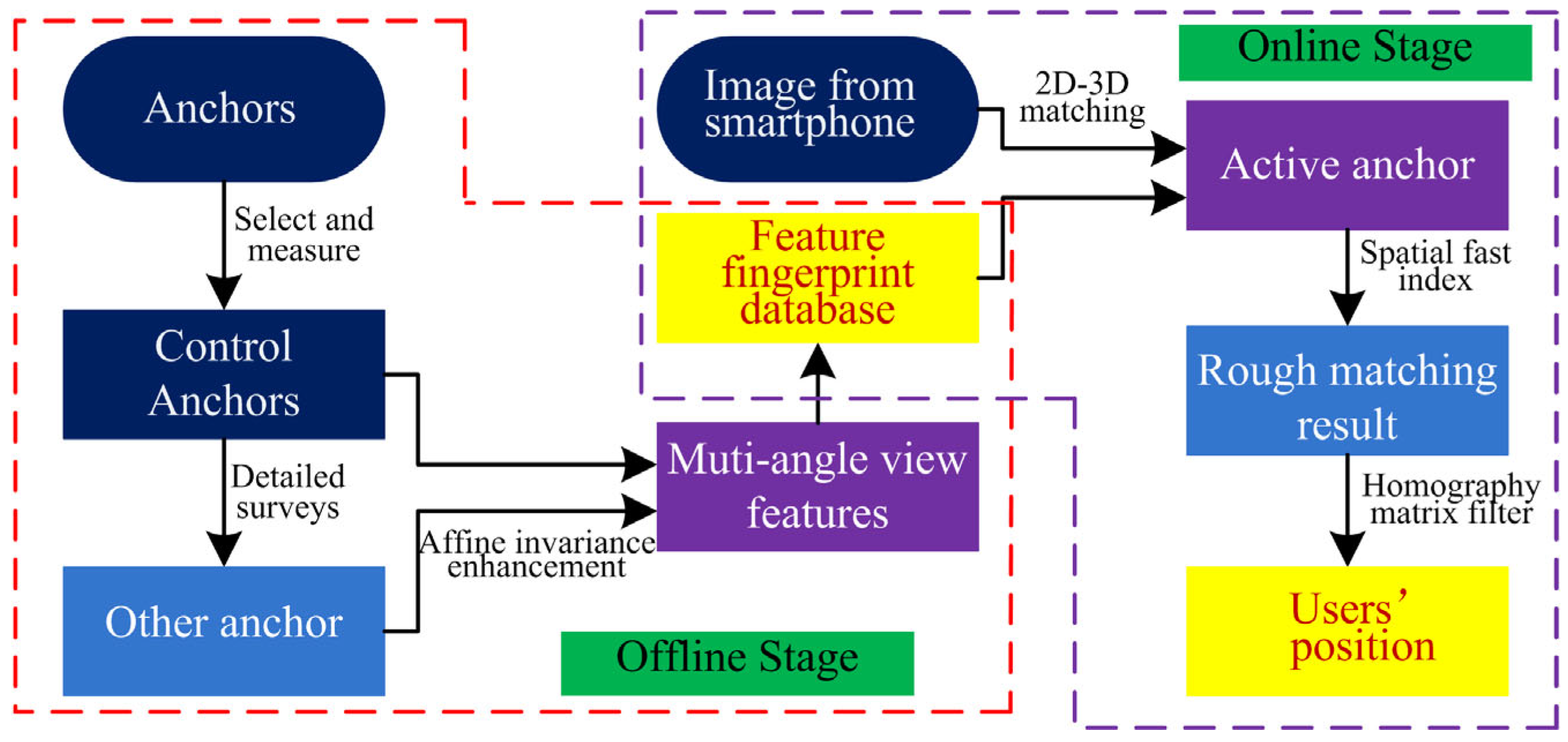
3.1. The Overview of the Proposed Approach
3.2. Feature Selection and Extraction
- (1)
- Scale-space interest point detection: The SURF uses a Hessian matrix to detect feature points. The Hessian matrix is a square matrix composed of the second partial derivative of a multivariate function, which describes the local curvature of the function. Equation (1) defines the Hessian matrix of the image I(x,y), where H denotes the Hessian matrix with image feature point coordinates I(x,y).
- (2)
- Interest point position: The non-maximum suppression is used to localize interest points in an image and over scales. The interpolation algorithm proposed by Brown and Lowe [36] is employed to interpolate the maxima of the determinant of the Hessian matrix into scale and image space;
- (3)
- Interest point orientation assignment: A vector is constructed by summing the transform values in the x-and y-direction inside an angle interval of the x–y plane and computing the Hal wavelet transform of the pixels surrounding the feature point in the x- and y-direction. The direction of the feature point is the longest vector, which is the vector with the largest x and y components;
- (4)
- Feature descriptor calculation: In the descriptor extraction process, the first step is to construct a square region centered around the interest point and oriented along the direction selected in the previous section. Further, a 5 pixel × 5 pixel region is set as a sub-region, and 20 × 20 pixels around the feature points are extracted, which is a total of 16 sub-regions. Then, the sum of the Hal wavelet transforms and its vector length in the x- and y-direction is obtained. At this time, the direction of parallel feature points is the x-direction, and the direction of vertical feature points is the y-direction within the sub-region: Σdx, Σdy, Σ|dx|, and Σ|dy|, which can generate a 64-dimensional descriptor.
3.3. Anchor Fingerprint Database Construction
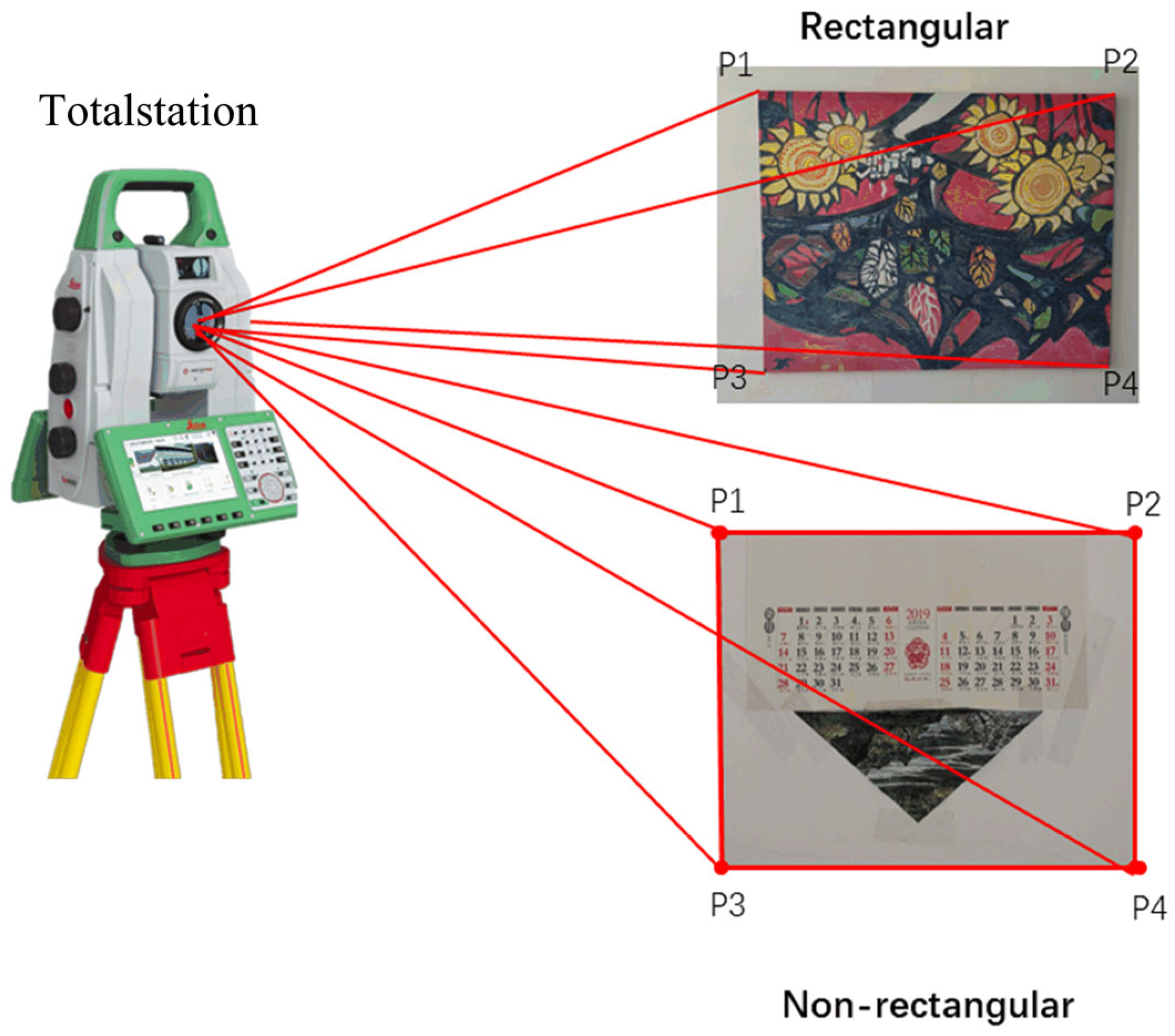
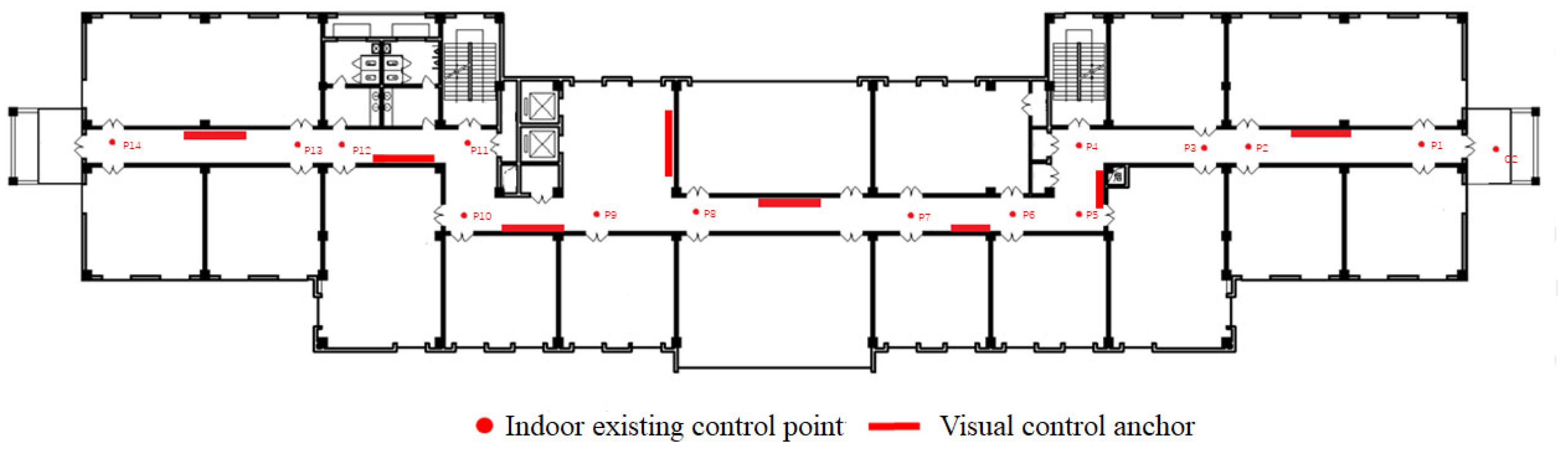
3.3.1. Control Anchor Measurement
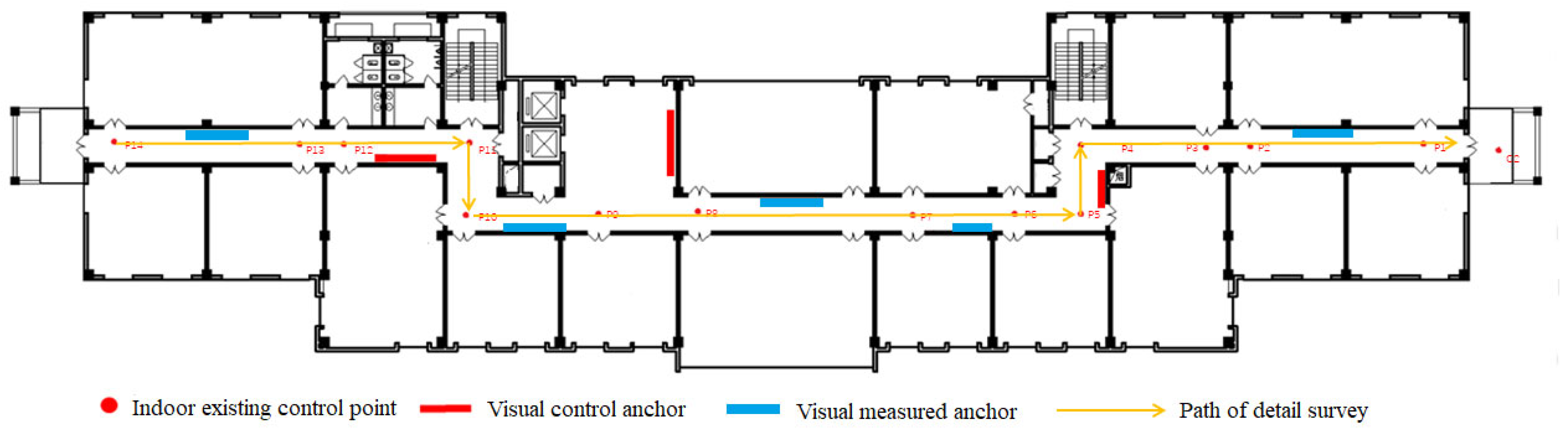
3.3.2. Anchor Detailed Survey
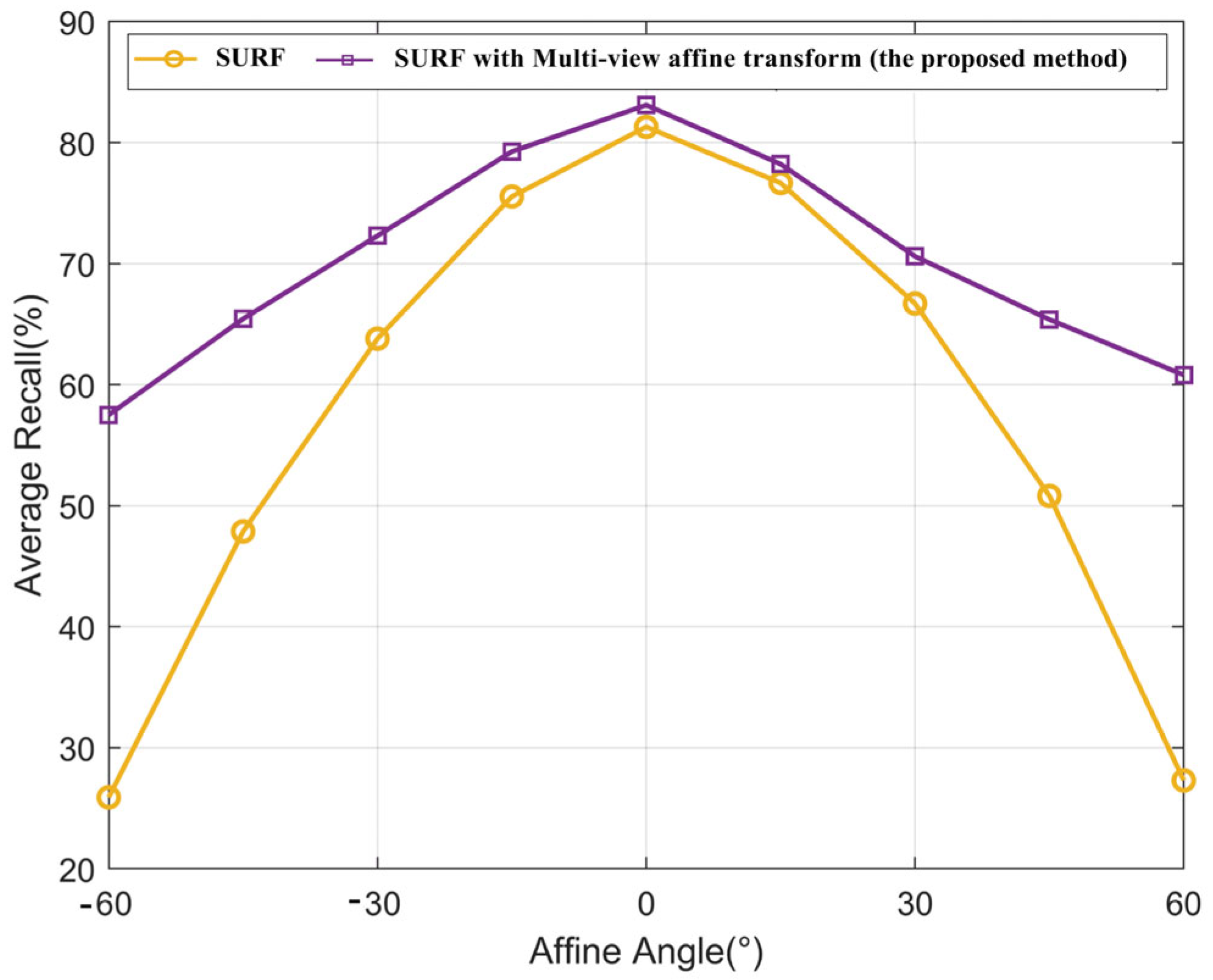
3.3.3. Feature Multi-View Affine Transformation
- (1)
- The corresponding path of a video stream is planned according to the location distribution that may appear when a user takes images. Different from the detailed survey planning path, the goal of this process is to obtain the frontal image of anchors and then infer the coordinates of the four corners of the circumscribed rectangle of the detailed anchors. The main goal of the affine simulation planning path is to obtain images from various perspectives to complement the features of the corresponding anchor;
- (2)
- A video is obtained along the planned path, and the POS information of an image is recorded at the same time.
- (3)
- The image of each anchor is filtered according to the POS. The POS information obtained by the ARcore is recorded in the form of a quaternion q (w, x, y, z), and the corresponding rotation matrix R is defined by:
3.4. Feature Matching
3.4.1. Active Anchors Fast Spatial Indexing
| Algorithm 1: Fast Spatial Indexing |
| Input: positioning image P, feature fingerprint database D, random k, threshold r |
| Output: best-matched anchor and |
| 1: extract M features points from P |
| 2: while do |
| 3: decrease k |
| 4: select m feature points from M according to rate k |
| 5: match m features with D using the k-d tree algorithm |
| 6: count the number of feature points from different anchors and record |
| 7: if > r |
| 8: record the ID of this anchor and the corresponding |
| 9: end if |
| 10: rank , take the first n |
| 11: extract anchors near n and narrow D into α |
| 12: match (m − n) feature with d, record |
| 13: end while |
3.4.2. Feature Screening
4. Experiment and Results
4.1. Experiment Setup
4.1.1. Anchor Deployment Environment
4.1.2. Localization Test Site
4.2. Result Analysis
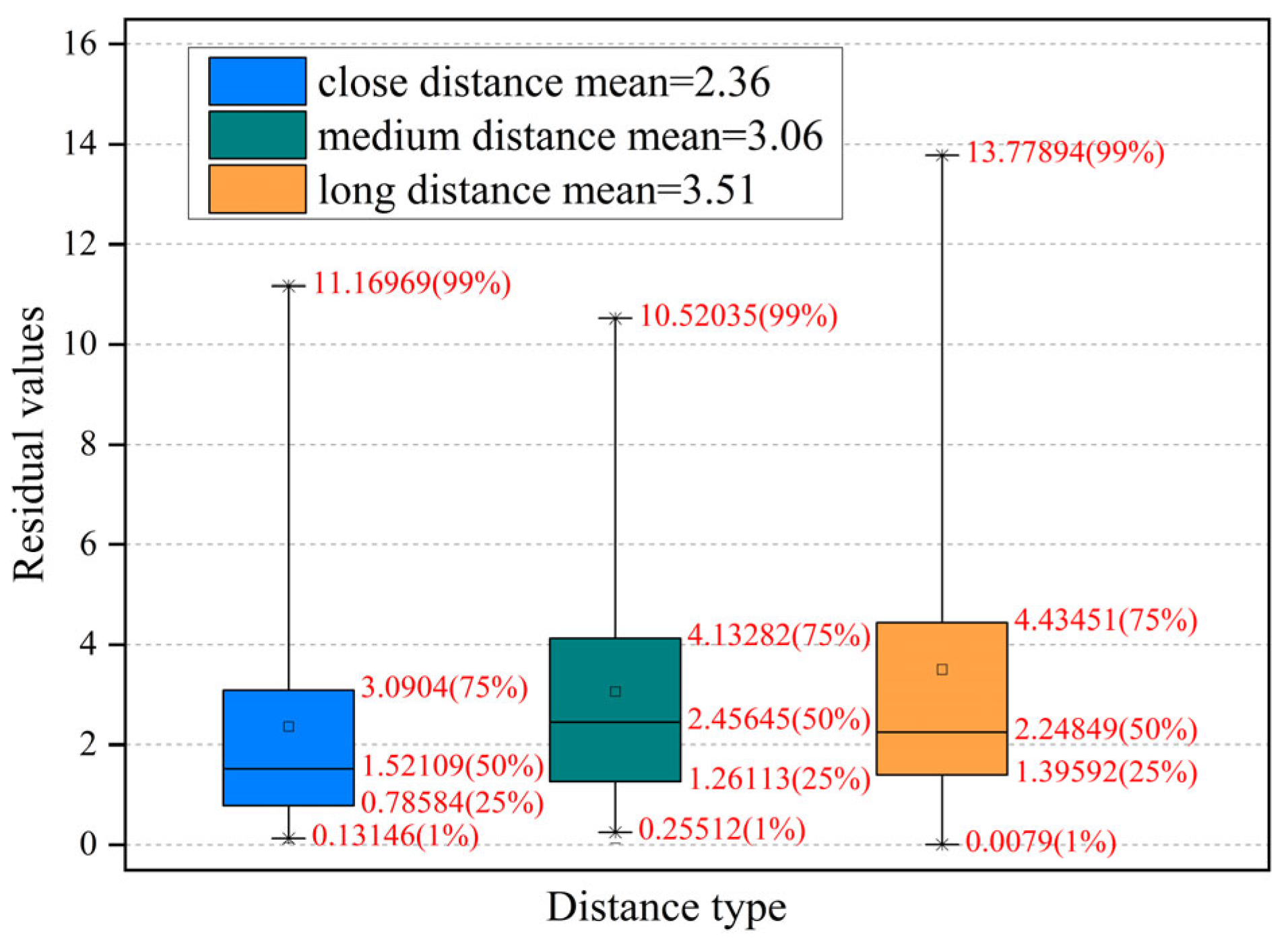
4.2.1. Performance Analysis of Feature Fingerprint Database
4.2.2. Anchor Fast Spatial Indexing Analysis
4.2.3. Feature Screening Analysis
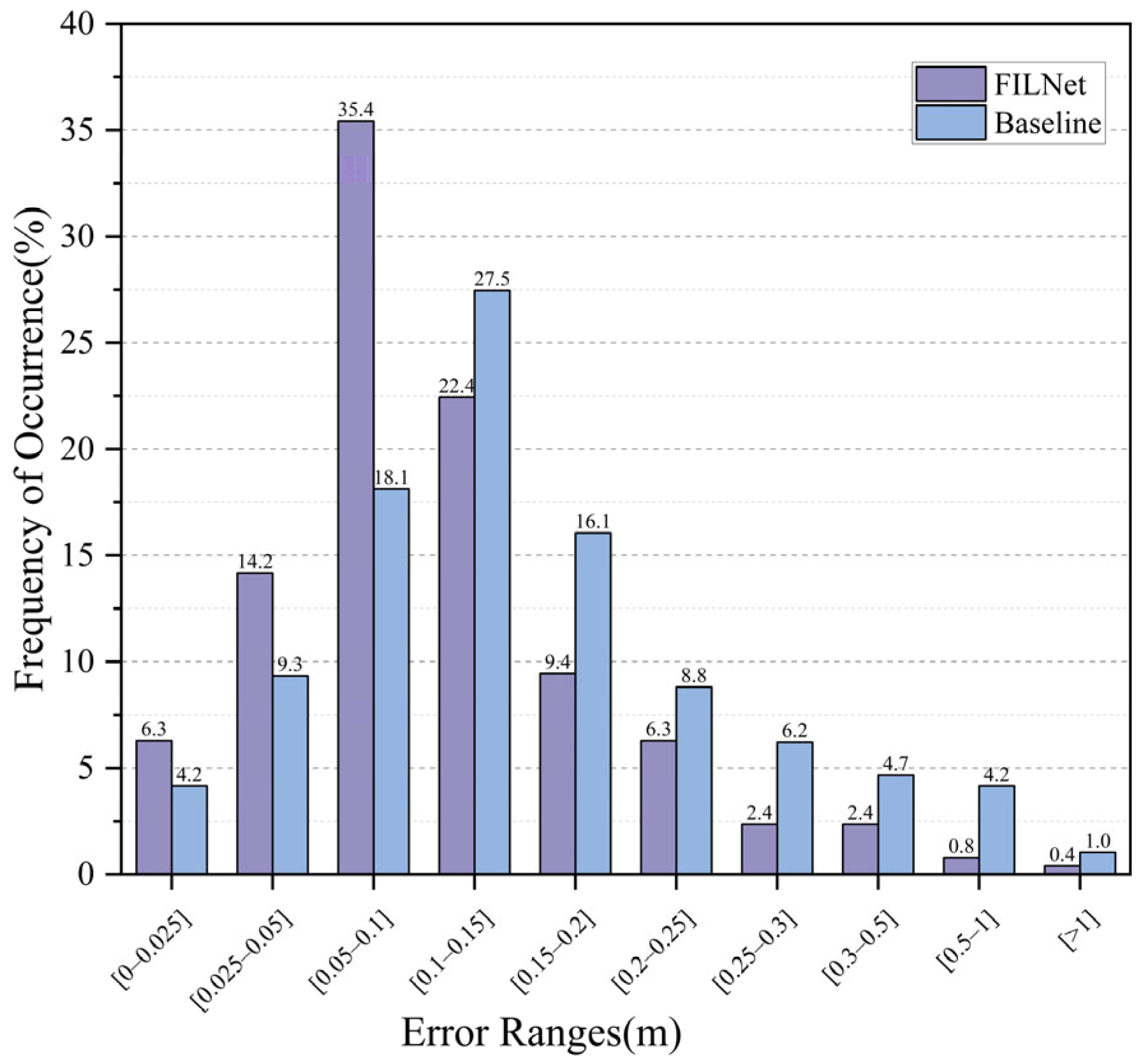
4.2.4. Localization Performance
4.3. Discussion of Limitations
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Zou, Y.; Chang, Y.; Liu, J.; Lin, B.; Zhu, Z. Multi-level scene modeling and matching for smartphone-based indoor localization. In Proceedings of the 2019 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Beijing, China, 10–18 October 2019; pp. 311–316. [Google Scholar]
- Filippoupolitis, A.; Oliff, W.; Loukas, G. Bluetooth low energy based occupancy detection for emergency management. In Proceedings of the 2016 15th International Conference on Ubiquitous Computing and Communications and 2016 International Symposium on Cyberspace and Security (IUCC-CSS) IEEE, Granada, Spain, 14–16 December 2016; pp. 31–38. [Google Scholar]
- Tekler, Z.D.; Chong, A. Occupancy prediction using deep learning approaches across multiple space types: A minimum sensing strategy. Build. Environ. 2022, 226, 109689. [Google Scholar] [CrossRef]
- Tekler, Z.D.; Low, R.; Yuen, C.; Blessing, L. Plug-Mate: An IoT-based occupancy-driven plug load management system in smart buildings. Build. Environ. 2022, 223, 109472. [Google Scholar] [CrossRef]
- Balaji, B.; Xu, J.; Nwokafor, A.; Gupta, R.; Agarwal, Y. Sentinel: Occupancy based HVAC actuation using existing WiFi infrastructure within commercial buildings. In Proceedings of the 11th ACM Conference on Embedded Networked Sensor Systems, Roma, Italy, 11–15 November 2013; pp. 1–14. [Google Scholar]
- Low, R.; Tekler, Z.D.; Cheah, L. An End-to-End Point of Interest (POI) Conflation Framework. ISPRS Int. J. Geo-Inf. 2021, 10, 779. [Google Scholar] [CrossRef]
- Alsmadi, L.; Kong, X.; Sandrasegaran, K.; Fang, G. An Improved Indoor Positioning Accuracy Using Filtered RSSI and Beacon Weight. IEEE Sens. J. 2021, 21, 18205–18213. [Google Scholar] [CrossRef]
- Dinh, T.-M.T.; Duong, N.-S.; Sandrasegaran, K. Smartphone-Based Indoor Positioning Using BLE iBeacon and Reliable Lightweight Fingerprint Map. IEEE Sens. J. 2020, 20, 10283–10294. [Google Scholar] [CrossRef]
- Zhou, M.; Li, Y.; Tahir, M.J.; Geng, X.; Wang, Y.; He, W. Integrated Statistical Test of Signal Distributions and Access Point Contributions for Wi-Fi Indoor Localization. IEEE Trans. Veh. Technol. 2021, 70, 5057–5070. [Google Scholar] [CrossRef]
- Xue, W.; Qiu, W.; Hua, X.; Yu, K. Improved Wi-Fi RSSI Measurement for Indoor Localization. IEEE Sens. J. 2017, 17, 2224–2230. [Google Scholar] [CrossRef]
- Wu, H.; Mo, Z.; Tan, J.; He, S.; Chan, S.-H.G. Efficient Indoor Localization Based on Geomagnetism. ACM Trans. Sens. Netw. (TOSN) 2019, 15, 1–25. [Google Scholar] [CrossRef]
- Liu, J.; Chen, C.; Ma, Y. Modeling Neighbor Discovery in Bluetooth Low Energy Networks. IEEE Commun. Lett. 2012, 16, 1439–1441. [Google Scholar] [CrossRef]
- Aravindan, M.; Yamuna, G.; Vikram, R.R. Indoor Localization Based on Wireless Local Area Network Fingerprint Technique. J. Comput. Theor. Nanosci. 2019, 16, 1498–1501. [Google Scholar] [CrossRef]
- Yang, Z.; Wu, C.; Liu, Y. Locating in fingerprint space: Wireless indoor localization with little human intervention. In Proceedings of the 18th Annual International Conference on Mobile Computing and Networking, Istanbul, Turkey, 22–26 August 2012; pp. 269–280. [Google Scholar]
- Li, L.; Guo, X.; Ansari, N.; Li, H. A Hybrid Fingerprint Quality Evaluation Model for WiFi Localization. IEEE Internet Things J. 2019, 6, 9829–9840. [Google Scholar] [CrossRef]
- Niu, Q.; Li, M.; He, S.; Gao, C.; Gary Chan, S.H.; Luo, X. Resource-efficient and automated image-based indoor localization. ACM Trans. Sens. Netw. (TOSN) 2019, 15, 1–31. [Google Scholar] [CrossRef]
- Park, S.; Carriquiry, A. An algorithm to compare two-dimensional footwear outsole images using maximum cliques and speeded-up robust feature. Stat. Anal. Data Min. ASA Data Sci. J. 2020, 13, 188–199. [Google Scholar] [CrossRef]
- Dong, J.; Yu, X.; Noreikis, M.; Ou, Z.; Ylä-Jääski, A. iMoon: Using smartphones for image-based indoor navigation. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Republic of Korea, 1–4 November 2015; pp. 85–97. [Google Scholar]
- Jiang, X.; Ma, J.; Jiang, J.; Guo, X. Robust Feature Matching Using Spatial Clustering with Heavy Outliers. IEEE Trans. Image Process. 2019, 29, 736–746. [Google Scholar] [CrossRef]
- Ma, J.; Li, Z.; Zhang, K.; Shao, Z.; Xiao, G. Robust feature matching via neighborhood manifold representation consensus. ISPRS J. Photogramm. Remote Sens. 2022, 183, 196–209. [Google Scholar] [CrossRef]
- Li, X.; Hu, Z. Rejecting Mismatches by Correspondence Function. Int. J. Comput. Vis. 2010, 89, 1–17. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust Point Matching via Vector Field Consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; Zheng, X. Gaussian field consensus: A robust nonparametric matching method for outlier rejection. Pattern Recognit. 2018, 74, 305–316. [Google Scholar] [CrossRef]
- Sarlin, P.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jiang, B.; Sun, P.; Tang, J.; Luo, B. Glmnet: Graph learning-matching networks for feature matching. arXiv 2019, arXiv:1911.07681. [Google Scholar] [CrossRef]
- Qian, J.; Ma, J.; Ying, R.; Liu, P.; Pei, L. An improved indoor localization method using smartphone inertial sensors. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, Montbeliard, France, 28–31 October 2013; pp. 1–8. [Google Scholar]
- Wang, X.; Yu, Z.; Mao, S. DeepML: Deep LSTM for Indoor Localization with Smartphone Magnetic and Light Sensors. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Murata, M.; Ahmetovic, D.; Sato, D.; Takagi, H.; Kitani, K.M.; Asakawa, C. Smartphone-based indoor localization for blind navigation across building complexes. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), Athens, Greece, 19–23 March 2018. [Google Scholar]
- Ashraf, I.; Hur, S.; Park, S.; Park, Y. DeepLocate: Smartphone Based Indoor Localization with a Deep Neural Network Ensemble Classifier. Sensors 2019, 20, 133. [Google Scholar] [CrossRef]
- Shu, M.; Chen, G.; Zhang, Z. Efficient image-based indoor localization with MEMS aid on the mobile device. ISPRS J. Photogramm. Remote Sens. 2022, 185, 85–110. [Google Scholar] [CrossRef]
- Anoosheh, A.; Sattler, T.; Timofte, R.; Pollefeys, M.; Van Gool, L. Night-to-day image translation for retrieval-based localization. In Proceedings of the 2019 Inter-National Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5958–5964. [Google Scholar] [CrossRef]
- Baek, F.; Ha, I.; Kim, H. Augmented reality system for facility management using image-based indoor localization. Autom. Constr. 2019, 99, 18–26. [Google Scholar] [CrossRef]
- Al-Khafaji, S.L.; Zhou, J.; Zia, A.; Liew, A.W.C. Spectral-spatial scale invariant feature transform for hyperspectral images. IEEE Trans. Image Process. 2017, 27, 837–850. [Google Scholar] [CrossRef]
- Aglave, P.; Kolkure, V. Implementation of High-Performance Feature Extraction Method Using Oriented Fast and Rotated Brief Algorithm. Int. J. Res. Eng. Technol. 2015, 4, 394–397. [Google Scholar]
- Radha, R.; Pushpa, M. A comparative analysis of SIFT, SURF and ORB on sketch and paint-based images. Int. J. Forensic Eng. 2021, 5, 102–110. [Google Scholar] [CrossRef]
- Lee, Y.H.; Bang, S.I. Improved image retrieval and classification with combined invariant features and color descriptor. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2255–2264. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. LAM: Locality affine-invariant feature matching. ISPRS J. Photogramm. Remote Sens. 2019, 154, 28–40. [Google Scholar] [CrossRef]
- Vijayan, V.; Kp, P. FLANN based matching with SIFT descriptors for drowsy features extraction. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), IEEE, Shimla, India, 15–17 November 2019; pp. 600–605. [Google Scholar]
- Muñoz, J.V.; Gonçalves, M.A.; Dias, Z.; Torres, R.d.S. Hierarchical Clustering-Based Graphs for Large Scale Approximate Nearest Neighbor Search. Pattern Recognit. 2019, 96, 106970. [Google Scholar] [CrossRef]
- Fernandes, N.; Kawamoto, Y.; Murakami, T. Locality sensitive hashing with extended differential privacy. In Proceedings of the European Symposium on Research in Computer Security, Darmstadt, Germany, 4–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 563–583. [Google Scholar]
- Sattler, T.; Leibe, B.; Kobbelt, L. Fast image-based localization using direct 2d-to-3d matching. In Proceedings of the 2011 In-ternational Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 667–674. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Speed | Robustness | ||
|---|---|---|---|---|
| Rotation | Angle | Scale | ||
| SIFT | low | better | better | better |
| SURF | faster | best | best | best |
| ORB | fastest | better | better | / |
| Parameter | Value |
|---|---|
| Feature descriptor | 64 dimensions |
| 2D plane coordinate | a (u, v) |
| 3D object coordinate | A (x, y, z) |
| Anchor ID | 001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Huang, Z.; Li, J.; Li, A.; Huang, X. FILNet: Fast Image-Based Indoor Localization Using an Anchor Control Network. Sensors 2023, 23, 8140. https://doi.org/10.3390/s23198140
Liu S, Huang Z, Li J, Li A, Huang X. FILNet: Fast Image-Based Indoor Localization Using an Anchor Control Network. Sensors. 2023; 23(19):8140. https://doi.org/10.3390/s23198140
Chicago/Turabian StyleLiu, Sikang, Zhao Huang, Jiafeng Li, Anna Li, and Xingru Huang. 2023. "FILNet: Fast Image-Based Indoor Localization Using an Anchor Control Network" Sensors 23, no. 19: 8140. https://doi.org/10.3390/s23198140
APA StyleLiu, S., Huang, Z., Li, J., Li, A., & Huang, X. (2023). FILNet: Fast Image-Based Indoor Localization Using an Anchor Control Network. Sensors, 23(19), 8140. https://doi.org/10.3390/s23198140