
Incremental Learning for Online Data Using QR Factorization on Convolutional Neural Networks


Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Incremental QR Factorization for Weight Shape Derivation
3.2. Center and Boundary of Feature Distribution
3.3. Bias Selection and Magnitude Derivation
| Algorithm 1 Datum-wise online incremental learning. |
|
4. Experiments and Results
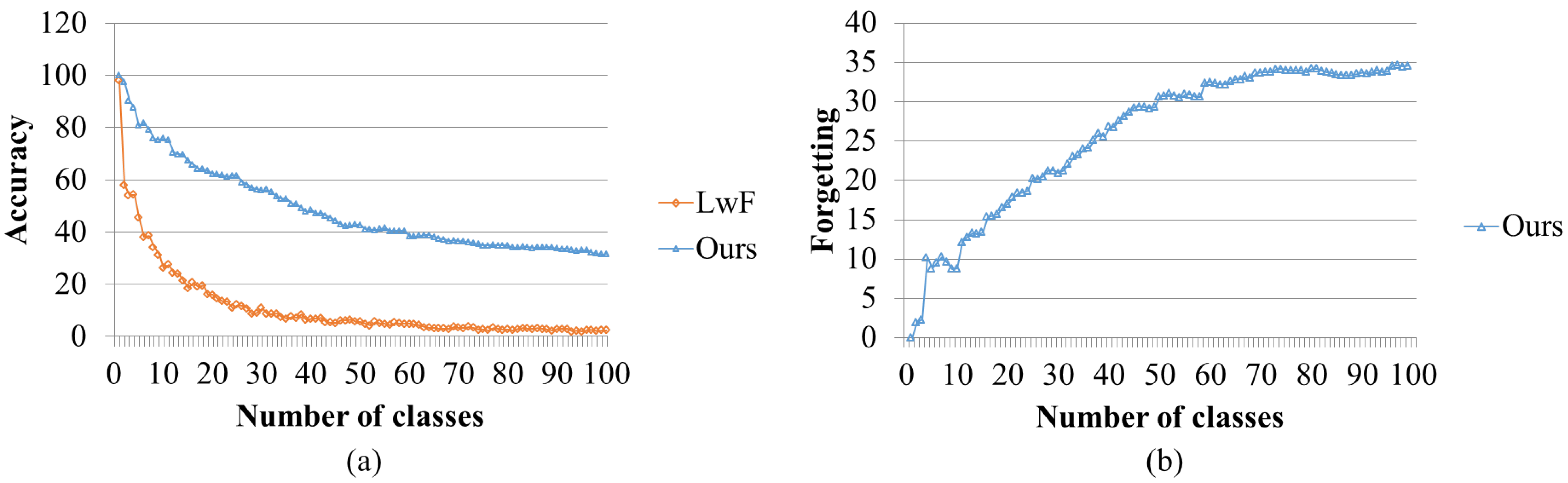
4.1. Comparison with Class-Wise Incremental Backpropagation
4.2. Random Input Comparison with One Epoch Backpropagation
4.3. Comparison with Replay Memory-Based Methods
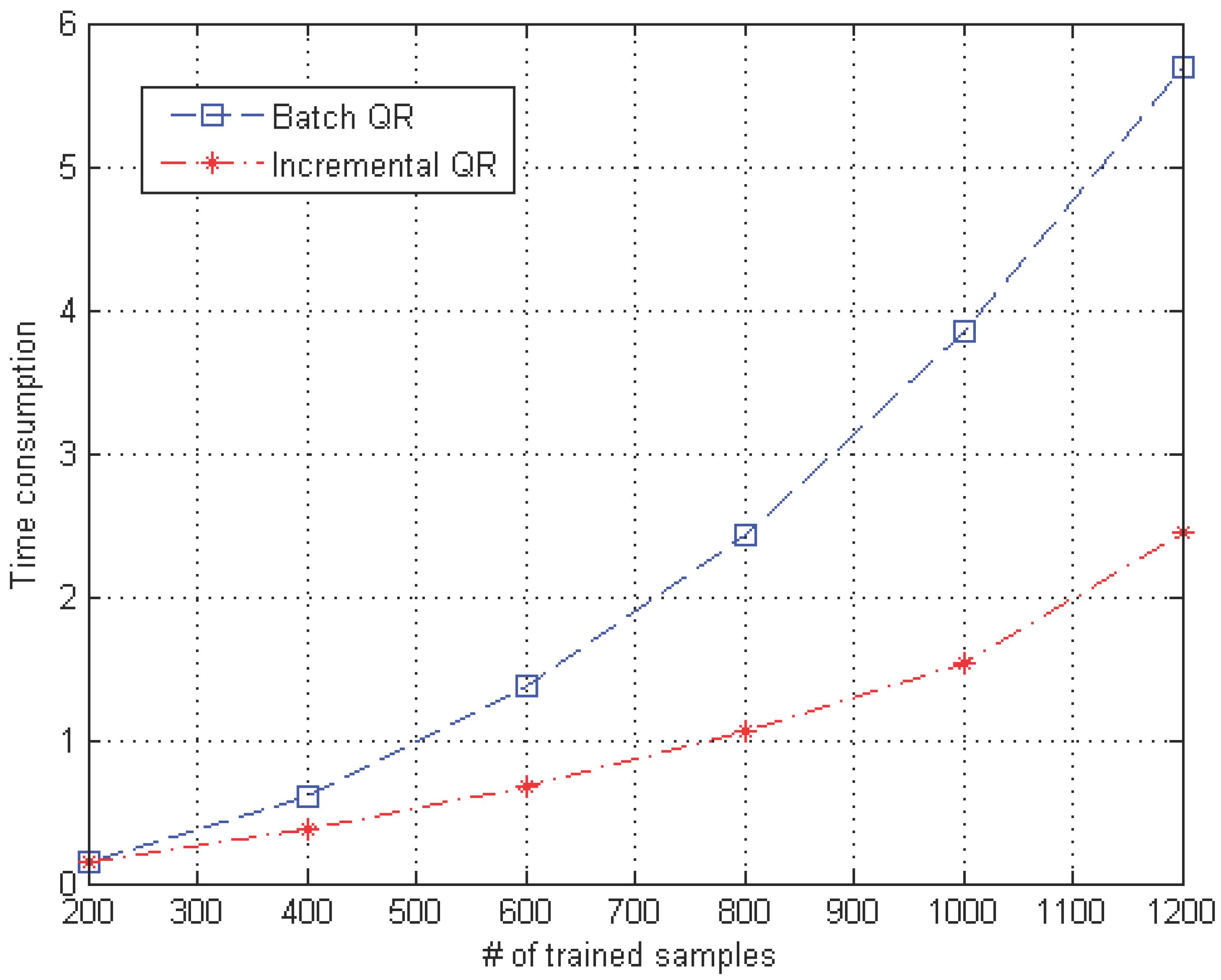
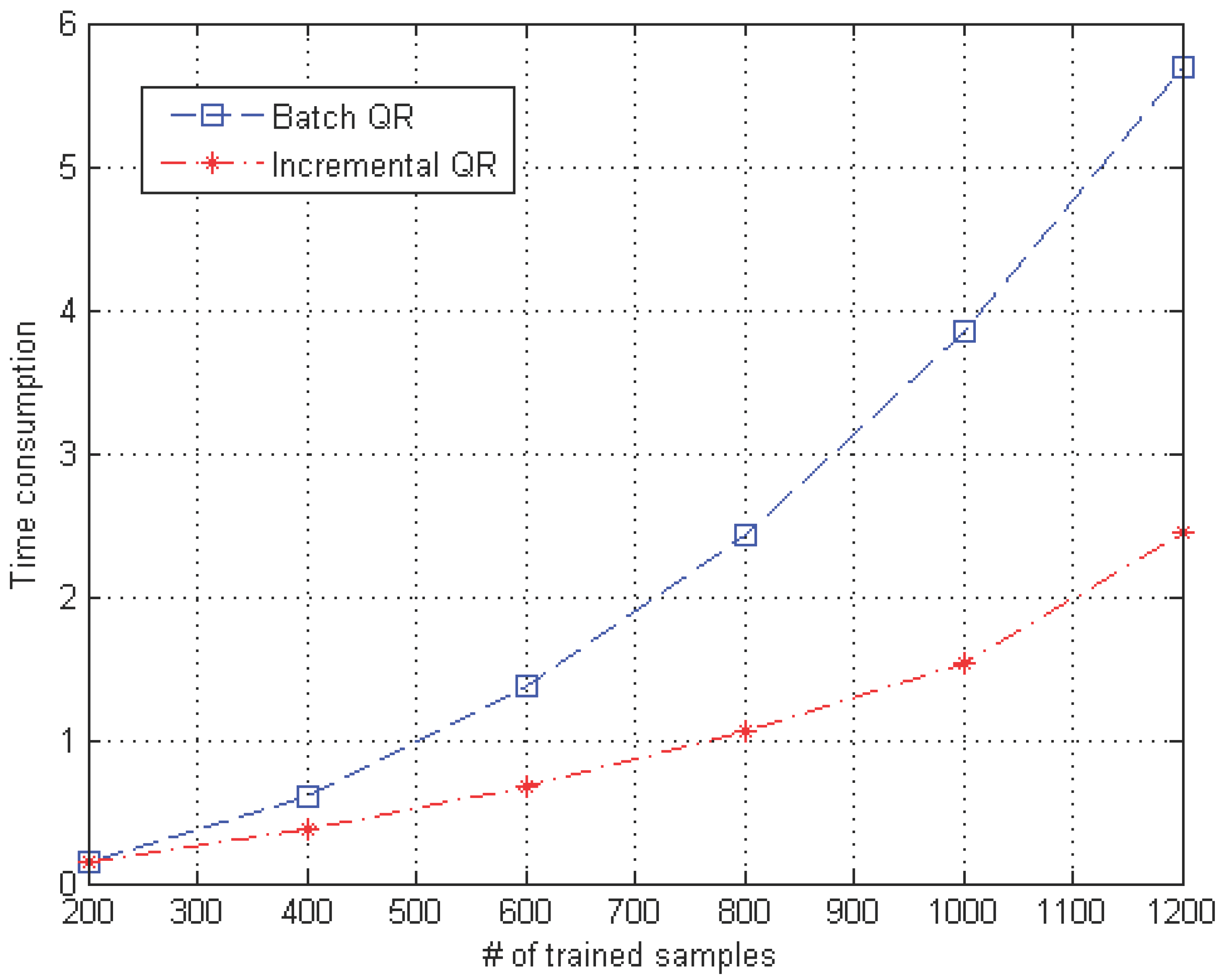
4.4. Computational Efficiency of the Proposed Incremental QR Factorization Compared with That of Batch
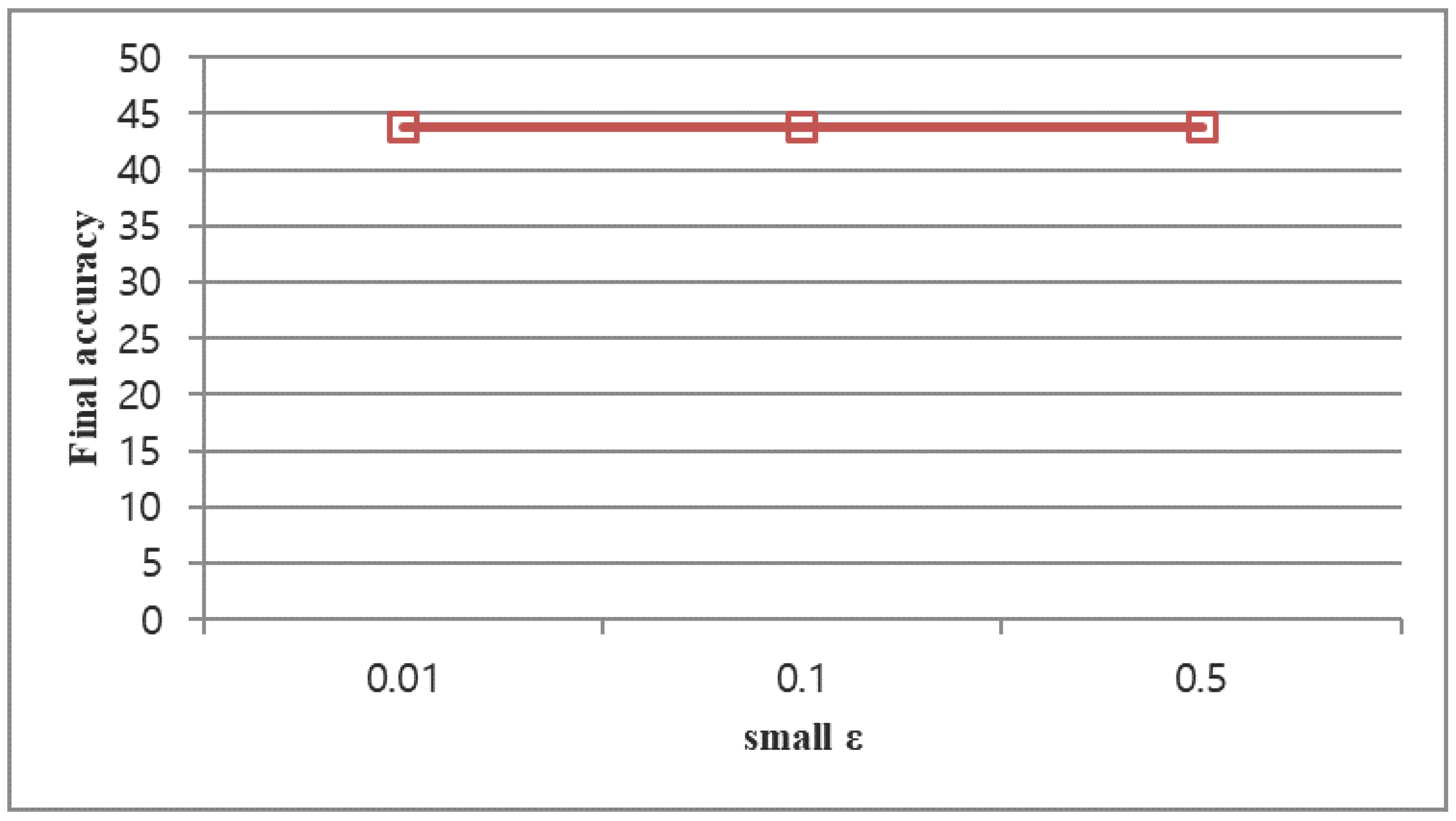
4.5. Hyper-Parameter Effect Analysis
4.5.1. Small
4.5.2. Bias Selection Parameter r
5. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hung, C.Y.; Tu, C.H.; Wu, C.E.; Chen, C.H.; Chan, Y.M.; Chen, C.S. Compacting, Picking and Growing for Unforgetting Continual Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13647–13657. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; Zhang, Z.; Fu, Y. Incremental classifier learning with generative adversarial networks. arXiv 2018, arXiv:1802.00853. [Google Scholar]
- Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; Fu, Y. Large scale incremental learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 374–382. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Liu, B. Learning on the job: Online lifelong and continual learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13544–13549. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- Gepperth, A.; Hammer, B. Incremental learning algorithms and applications. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Xue, J.; Zhao, Y.; Huang, S.; Liao, W.; Chan, J.C.W.; Kong, S.G. Multilayer sparsity-based tensor decomposition for low-rank tensor completion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6916–6930. [Google Scholar] [CrossRef]
- Zeng, H.; Xue, J.; Luong, H.Q.; Philips, W. Multimodal core tensor factorization and its applications to low-rank tensor completion. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Fu, Y.H. Reconstruction of compressive sensing and semi-QR factorization. J. Comput. Appl. 2008, 28, 2300–2302. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- French, R.M. Semi-distributed representations and catastrophic forgetting in connectionist networks. Connect. Sci. 1992, 4, 365–377. [Google Scholar] [CrossRef]
- Ratcliff, R. Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions. Psychol. Rev. 1990, 97, 285. [Google Scholar] [CrossRef]
- Grossberg, S. Competitive learning: From interactive activation to adaptive resonance. Cogn. Sci. 1987, 11, 23–63. [Google Scholar] [CrossRef]
- Mermillod, M.; Bugaiska, A.; Bonin, P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects. Front. Psychol. 2013, 4, 504. [Google Scholar] [CrossRef]
- Carpenter, G.A.; Grossberg, S.; Rosen, D.B. Fuzzy ART: Fast stable learning and categorization of analog patterns by an adaptive resonance system. Neural Netw. 1991, 4, 759–771. [Google Scholar] [CrossRef]
- Kim, B.; Ban, S.W.; Lee, M. Growing fuzzy topology adaptive resonance theory models with a push–pull learning algorithm. Neurocomputing 2011, 74, 646–655. [Google Scholar] [CrossRef]
- Jung, H.; Ju, J.; Jung, M.; Kim, J. Less-forgetting learning in deep neural networks. arXiv 2016, arXiv:1607.00122. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental learning of object detectors without catastrophic forgetting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3400–3409. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.W.; Kim, J.H.; Jun, J.; Ha, J.W.; Zhang, B.T. Overcoming catastrophic forgetting by incremental moment matching. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4652–4662. [Google Scholar]
- Aljundi, R.; Belilovsky, E.; Tuytelaars, T.; Charlin, L.; Caccia, M.; Lin, M.; Page-Caccia, L. Online continual learning with maximal interfered retrieval. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 11849–11860. [Google Scholar]
- Jin, X.; Sadhu, A.; Du, J.; Ren, X. Gradient-based editing of memory examples for online task-free continual learning. Adv. Neural Inf. Process. Syst. 2021, 34, 29193–29205. [Google Scholar]
- Gao, Q.; Zhao, C.; Ghanem, B.; Zhang, J. R-dfcil: Relation-guided representation learning for data-free class incremental learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 423–439. [Google Scholar]
- Sun, Q.; Lyu, F.; Shang, F.; Feng, W.; Wan, L. Exploring example influence in continual learning. Adv. Neural Inf. Process. Syst. 2022, 35, 27075–27086. [Google Scholar]
- Roy, A.; Verma, V.K.; Voonna, S.; Ghosh, K.; Ghosh, S.; Das, A. Exemplar-Free Continual Transformer with Convolutions. arXiv 2023, arXiv:2308.11357. [Google Scholar]
- Zhang, J.; Chen, C.; Zhuang, W.; Lv, L. Addressing Catastrophic Forgetting in Federated Class-Continual Learning. arXiv 2023, arXiv:2303.06937. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Shi, Q.; Eriksson, A.; Van Den Hengel, A.; Shen, C. Is face recognition really a compressive sensing problem? In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 553–560. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef]
- Yang, A.Y.; Wright, J.; Ma, Y.; Sastry, S.S. Feature selection in face recognition: A sparse representation perspective. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 2. Available online: https://people.eecs.berkeley.edu/~yima/recognition/Files/PAMI_Feature.pdf (accessed on 8 August 2023).
- Wang, L.; Zhang, H.; Wang, Z.; Li, J. A New Compressive Sensing Method for Face Recognition. In Proceedings of the 2014 Seventh International Symposium on Computational Intelligence and Design, Hangzhou, China, 13–14 December 2014; Volume 1, pp. 529–532. [Google Scholar]
- Axelsson, O. Iterative Solution Methods; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Higham, N.J. Iterative refinement enhances the stability ofQR factorization methods for solving linear equations. BIT Numer. Math. 1991, 31, 447–468. [Google Scholar] [CrossRef]
- Kim, J.; Sangjun, O.; Kim, Y.; Lee, M. Convolutional neural network with biologically inspired retinal structure. Procedia Comput. Sci. 2016, 88, 145–154. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 8 August 2023).
- Chaudhry, A.; Rohrbach, M.; Elhoseiny, M.; Ajanthan, T.; Dokania, P.K.; Torr, P.H.; Ranzato, M. Continual learning with tiny episodic memories. arXiv 2019, arXiv:1902.10486. [Google Scholar]
- Lopez-Paz, D.; Ranzato, M. Gradient episodic memory for continual learning. In Proceedings of the Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6467–6476. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Forgetting | |||||
|---|---|---|---|---|---|---|
| Methods | M = 20 | M = 50 | M = 100 | M = 20 | M = 50 | M = 100 |
| GEM [40] | 16.8 | 17.1 | 17.5 | 73.5 | 70.7 | 71.7 |
| iCarl [5] (5 iter) | 28.6 | 33.7 | 32.4 | 49 | 40.6 | 40 |
| ER-MIR [23] | 29.8 | 40.0 | 47.6 | 50.2 | 30.2 | 17.4 |
| DOI (Ours) | 50.4 (M = 0) | 48.9 (M = 0) | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Lee, W.; Baek, S.; Hong, J.-H.; Lee, M. Incremental Learning for Online Data Using QR Factorization on Convolutional Neural Networks. Sensors 2023, 23, 8117. https://doi.org/10.3390/s23198117
Kim J, Lee W, Baek S, Hong J-H, Lee M. Incremental Learning for Online Data Using QR Factorization on Convolutional Neural Networks. Sensors. 2023; 23(19):8117. https://doi.org/10.3390/s23198117
Chicago/Turabian StyleKim, Jonghong, WonHee Lee, Sungdae Baek, Jeong-Ho Hong, and Minho Lee. 2023. "Incremental Learning for Online Data Using QR Factorization on Convolutional Neural Networks" Sensors 23, no. 19: 8117. https://doi.org/10.3390/s23198117
APA StyleKim, J., Lee, W., Baek, S., Hong, J.-H., & Lee, M. (2023). Incremental Learning for Online Data Using QR Factorization on Convolutional Neural Networks. Sensors, 23(19), 8117. https://doi.org/10.3390/s23198117