
GammaGAN: Gamma-Scaled Class Embeddings for Conditional Video Generation


Abstract
:1. Introduction
- We propose GammaGAN, an enhanced video discriminator network for conditional video generation that incorporates two novel techniques: scaling class embeddings and normalizing outputs.
- Scaled class embeddings emphasize class conditional information, thereby enhancing the distinction between different classes.
- Our technique for normalizing outputs balances the outputs of the model. This enables the prioritization between feature vectors and class embeddings during training, leading to improved video quality.
2. Related Work
2.1. Video Generation
2.2. Conditional Generative Adversarial Networks
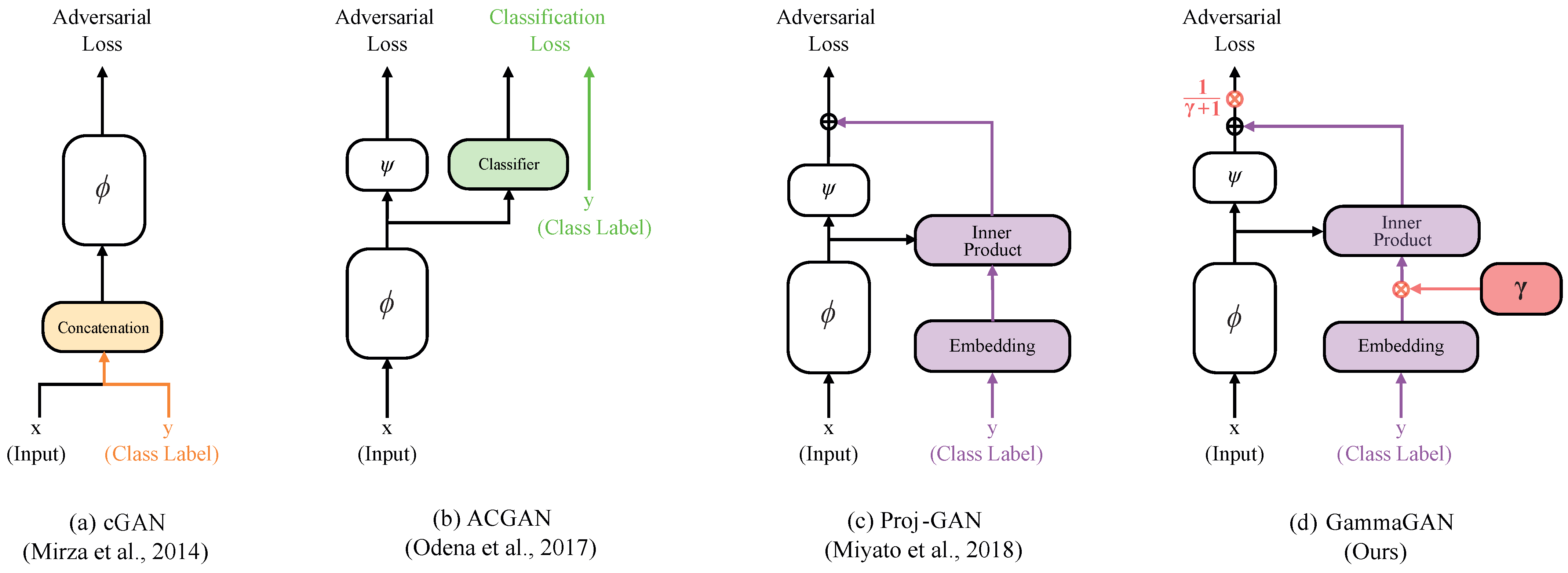
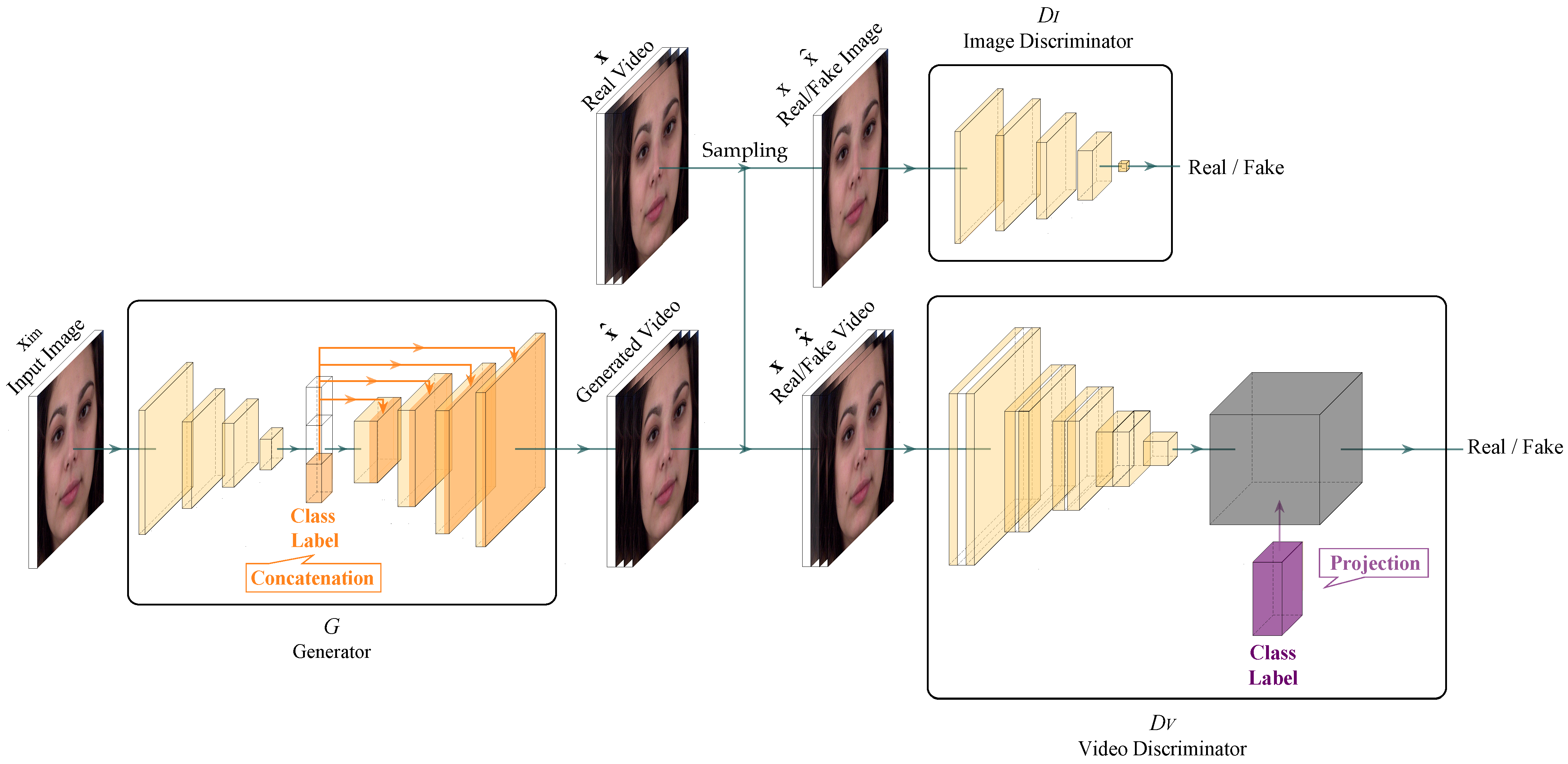
3. Method
3.1. GammaGAN Video Discriminator
3.1.1. Mathematical Description
3.1.2. Architecture
3.2. Objective Function
3.2.1. Full Objective Function
3.2.2. Generator Loss
3.2.3. Image Discriminator Loss
3.2.4. Video Discriminator Loss
4. Experimental Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.1.4. Evaluation Method
4.2. Ablation Study
4.2.1. Effectiveness of Normalization
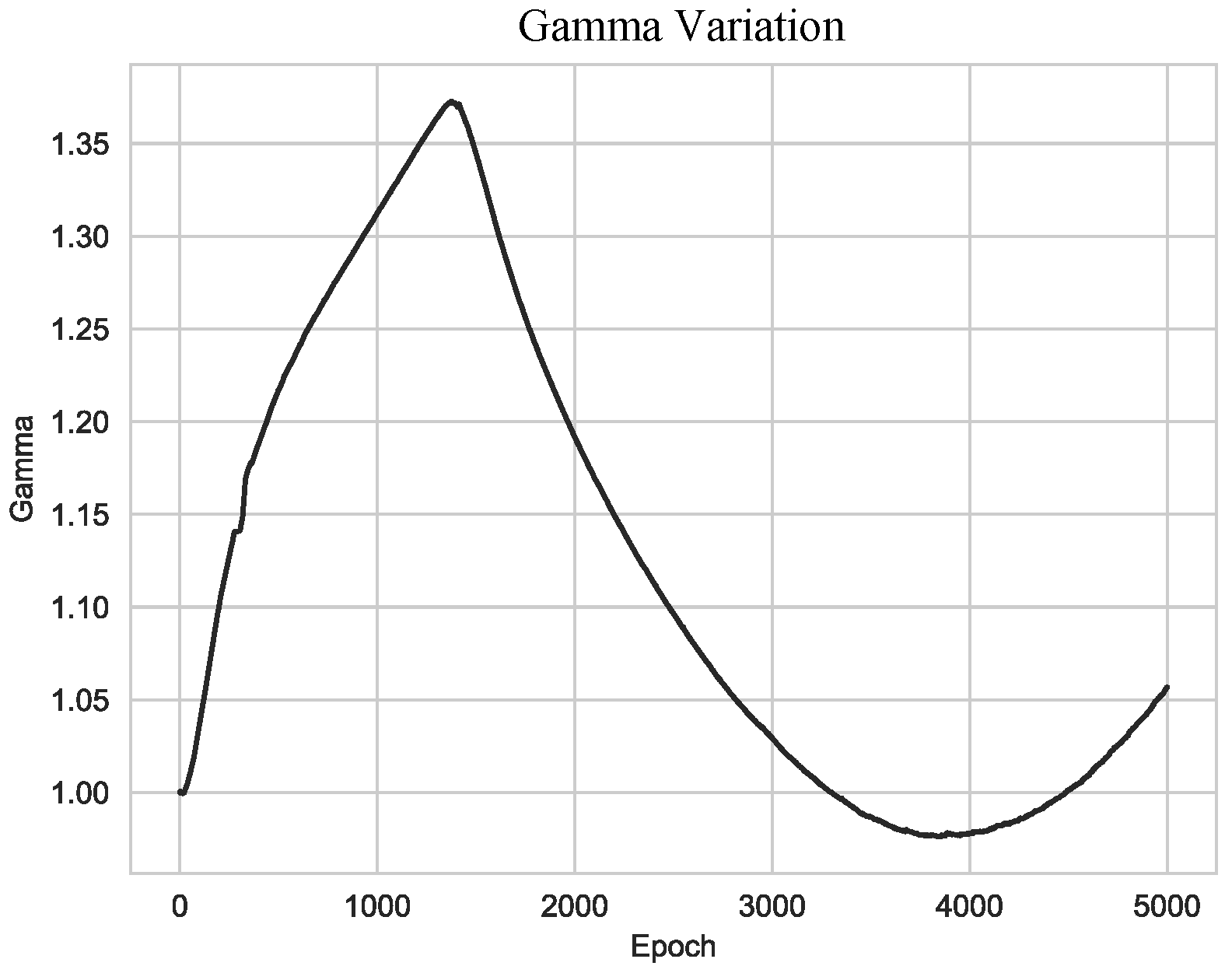
4.2.2. Effectiveness of Scaling Class Embeddings
4.3. Comparative Results
4.3.1. Quantitative Evaluation
4.3.2. Qualitative Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GANs | Generative Adversarial Networks |
| cGANs | Conditional Generative Adversarial Networks |
| MUG | Multimedia Understanding Group |
| VGG | Visual Geometry Group |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
| LPIPS | Learned Perceptual Image Patch Similarity |
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; pp. 1–21. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling up Capacity and Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–23 June 2022; pp. 12009–12019. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 1–12. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; pp. 1–20. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat GANs on image synthesis. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–14 December 2021; pp. 8780–8794. [Google Scholar]
- Lee, K.; Chang, H.; Jiang, L.; Zhang, H.; Tu, Z.; Liu, C. ViTGAN: Training GANs with Vision Transformers. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022; pp. 1–18. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Miyato, T.; Koyama, M. cGANs with Projection Discriminator. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–21. [Google Scholar]
- Denton, E.L.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 1486–1494. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1060–1069. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Perarnau, G.; van de Weijer, J.; Raducanu, B.; Álvarez, J.M. Invertible Conditional GANs for image editing. arXiv 2016, arXiv:1611.06355. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Lamb, A.; Arjovsky, M.; Mastropietro, O.; Courville, A. Adversarially Learned Inference. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–18. [Google Scholar]
- Sricharan, K.; Bala, R.; Shreve, M.; Ding, H.; Saketh, K.; Sun, J. Semi-supervised Conditional GANs. arXiv 2017, arXiv:1708.05789. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–26. [Google Scholar]
- Han, L.; Min, M.R.; Stathopoulos, A.; Tian, Y.; Gao, R.; Kadav, A.; Metaxas, D.N. Dual Projection Generative Adversarial Networks for Conditional Image Generation. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14438–14447. [Google Scholar]
- Han, S.; Lee, T.B.; Heo, Y.S. Semantic-Aware Face Deblurring with Pixel-Wise Projection Discriminator. IEEE Access 2023, 11, 11587–11600. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Nguyen, A.; Clune, J.; Bengio, Y.; Dosovitskiy, A.; Yosinski, J. Plug & play generative networks: Conditional iterative generation of images in latent space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 3510–3520. [Google Scholar]
- Gong, M.; Xu, Y.; Li, C.; Zhang, K.; Batmanghelich, K. Twin Auxilary Classifiers GAN. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1328–1337. [Google Scholar]
- Kang, M.; Shim, W.; Cho, M.; Park, J. Rebooting ACGAN: Auxiliary Classifier GANs with Stable Training. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; pp. 23505–23518. [Google Scholar]
- Hou, L.; Cao, Q.; Shen, H.; Pan, S.; Li, X.; Cheng, X. Conditional GANs with Auxiliary Discriminative Classifier. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 8888–8902. [Google Scholar]
- Clark, A.; Donahue, J.; Simonyan, K. Adversarial Video Generation on Complex Datasets. arXiv 2019, arXiv:1907.06571. [Google Scholar]
- Kang, M.; Park, J. ContraGAN: Contrastive Learning for Conditional Image Generation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 1–13. [Google Scholar]
- Ding, X.; Wang, Y.; Xu, Z.; Welch, W.J.; Wang, Z.J. CcGAN: Continuous Conditional Generative Adversarial Networks for Image Generation. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; pp. 1–30. [Google Scholar]
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG facial expression database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Desenzano, Italy, 12–14 April 2010; pp. 1–4. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating videos with scene dynamics. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 613–621. [Google Scholar]
- Tulyakov, S.; Liu, M.Y.; Yang, X.; Kautz, J. MoCoGAN: Decomposing Motion and Content for Video Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1526–1535. [Google Scholar]
- WANG, Y.; Bilinski, P.; Bremond, F.; Dantcheva, A. ImaGINator: Conditional spatio-temporal GAN for video generation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1160–1169. [Google Scholar]
- Haim, H.; Feinstein, B.; Granot, N.; Shocher, A.; Bagon, S.; Dekel, T.; Irani, M. Diverse generation from a single video made possible. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 491–509. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2226–2234. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 105–114. [Google Scholar]
- Zhu, J.Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative Visual Manipulation on the Natural Image Manifold. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 597–613. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2018, arXiv:1812.04948. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Shaham, T.R.; Dekel, T.; Michaeli, T. SinGAN: Learning a Generative Model from a Single Natural Image. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Schonfeld, E.; Schiele, B.; Khoreva, A. A U-Net Based Discriminator for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8207–8216. [Google Scholar]
- Saito, M.; Matsumoto, E.; Saito, S. Temporal Generative Adversarial Nets with Singular Value Clipping. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2830–2839. [Google Scholar]
- Saito, M.; Saito, S. TGANv2: Efficient Training of Large Models for Video Generation with Multiple Subsampling Layers. arXiv 2018, arXiv:1811.09245. [Google Scholar]
- Voleti, V.; Jolicoeur-Martineau, A.; Pal, C. MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 1–25. [Google Scholar]
- Ni, H.; Shi, C.; Li, K.; Huang, S.X.; Min, M.R. Conditional Image-to-Video Generation with Latent Flow Diffusion Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18444–18455. [Google Scholar]
- Yu, L.; Cheng, Y.; Sohn, K.; Lezama, J.; Zhang, H.; Chang, H.; Hauptmann, A.G.; Yang, M.H.; Hao, Y.; Essa, I.; et al. MAGVIT: Masked Generative Video Transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10459–10469. [Google Scholar]
- Weissenborn, D.; Täckström, O.; Uszkoreit, J. Scaling Autoregressive Video Models. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–24. [Google Scholar]
- Ge, S.; Hayes, T.; Yang, H.; Yin, X.; Pang, G.; Jacobs, D.; Huang, J.B.; Parikh, D. Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 102–118. [Google Scholar]
- Iqbal, H. HarisIqbal88/PlotNeuralNet v1.0.0, (v1.0.0); Zenodo: Genève, Switzerland, 8 June 2023. [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June–23 June 2018; pp. 586–595. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Method | Metric | ||||
|---|---|---|---|---|---|---|
| Projection | Scaling | Normalization | PSNR↑ | SSIM↑ | LPIPS↓ | |
| ImaGINator [33] 1 | 24.8779 | 0.8214 | 0.1119 | |||
| Proj-GAN [12] | ✓ | 25.2851 | 0.8344 | 0.1070 | ||
| GammaGAN w/o normalization | ✓ | ✓ | 25.1176 | 0.8288 | 0.1179 | |
| GammaGAN w/normalization (Ours) | ✓ | ✓ | ✓ | 25.2917 | 0.8346 | 0.1112 |
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| VGAN [31] | 14.54 | 0.28 | - |
| MoCoGAN [32] | 18.16 | 0.58 | - |
| ImaGINator [33] | 22.63 | 0.75 | - |
| ImaGINator [33] 1 | 24.8779 | 0.8214 | 0.1119 |
| GammaGAN (Ours) | 25.2917 | 0.8346 | 0.1112 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, M.; Heo, Y.S. GammaGAN: Gamma-Scaled Class Embeddings for Conditional Video Generation. Sensors 2023, 23, 8103. https://doi.org/10.3390/s23198103
Kang M, Heo YS. GammaGAN: Gamma-Scaled Class Embeddings for Conditional Video Generation. Sensors. 2023; 23(19):8103. https://doi.org/10.3390/s23198103
Chicago/Turabian StyleKang, Minjae, and Yong Seok Heo. 2023. "GammaGAN: Gamma-Scaled Class Embeddings for Conditional Video Generation" Sensors 23, no. 19: 8103. https://doi.org/10.3390/s23198103
APA StyleKang, M., & Heo, Y. S. (2023). GammaGAN: Gamma-Scaled Class Embeddings for Conditional Video Generation. Sensors, 23(19), 8103. https://doi.org/10.3390/s23198103