
Enhancing Feature Detection and Matching in Low-Pixel-Resolution Hyperspectral Images Using 3D Convolution-Based Siamese Networks


Abstract
:1. Introduction
- A feature match generation method using phase stretch transformation-based edge maps.
- Training, evaluation, and application of a Siamese network based on a 3D convolution neural network for feature filtering.
- Evaluation of the proposed method with the state-of-the-art methods.
2. Related Work
2.1. Hyperspectral Imaging in Remote Sensing
2.2. Dimensionality Reduction of Hyperspectral Images
2.3. Siamese Networks
2.4. Feature Matching for Hyperspectral Imaging
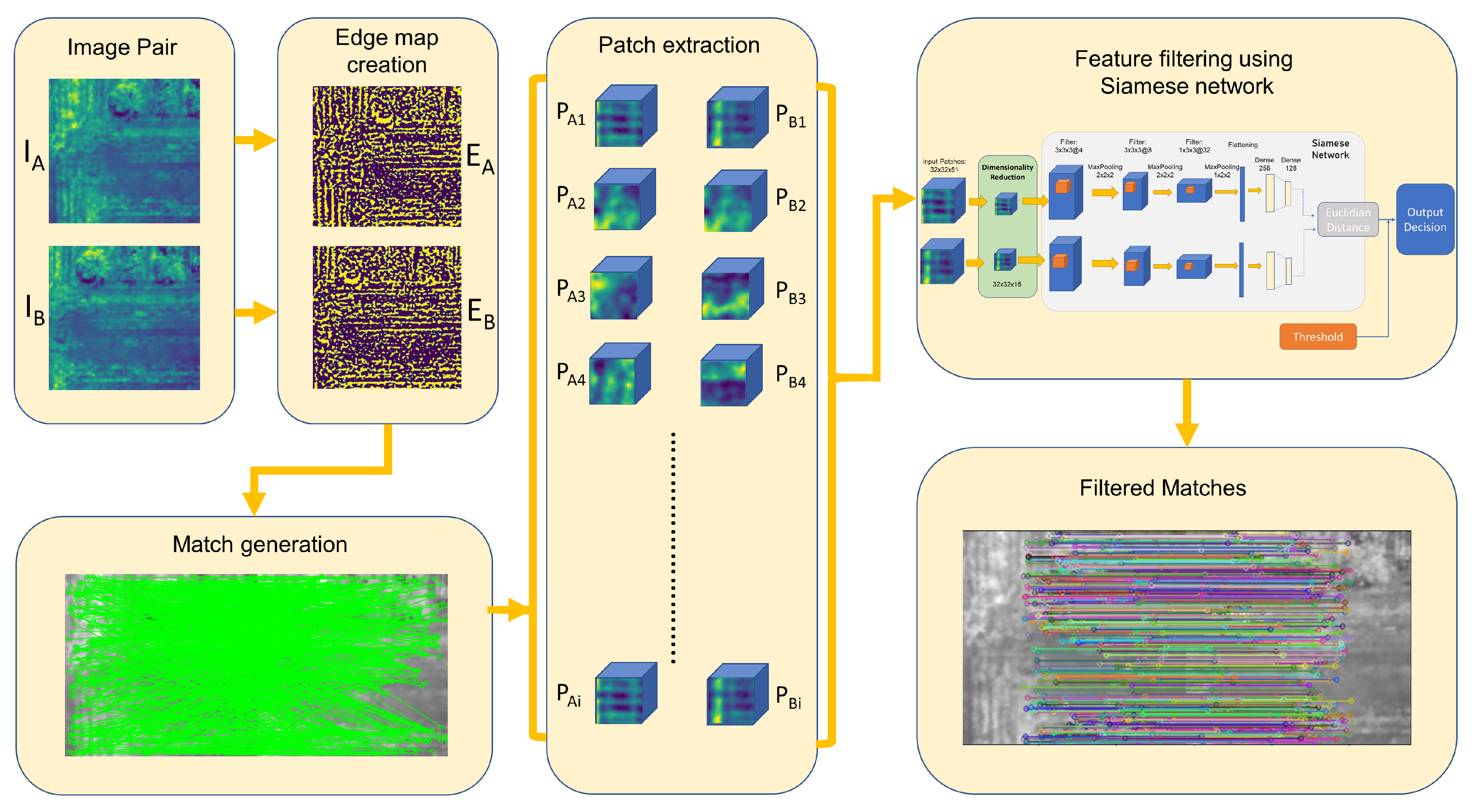
3. Methodology
3.1. Data Acquisition and Preprocessing
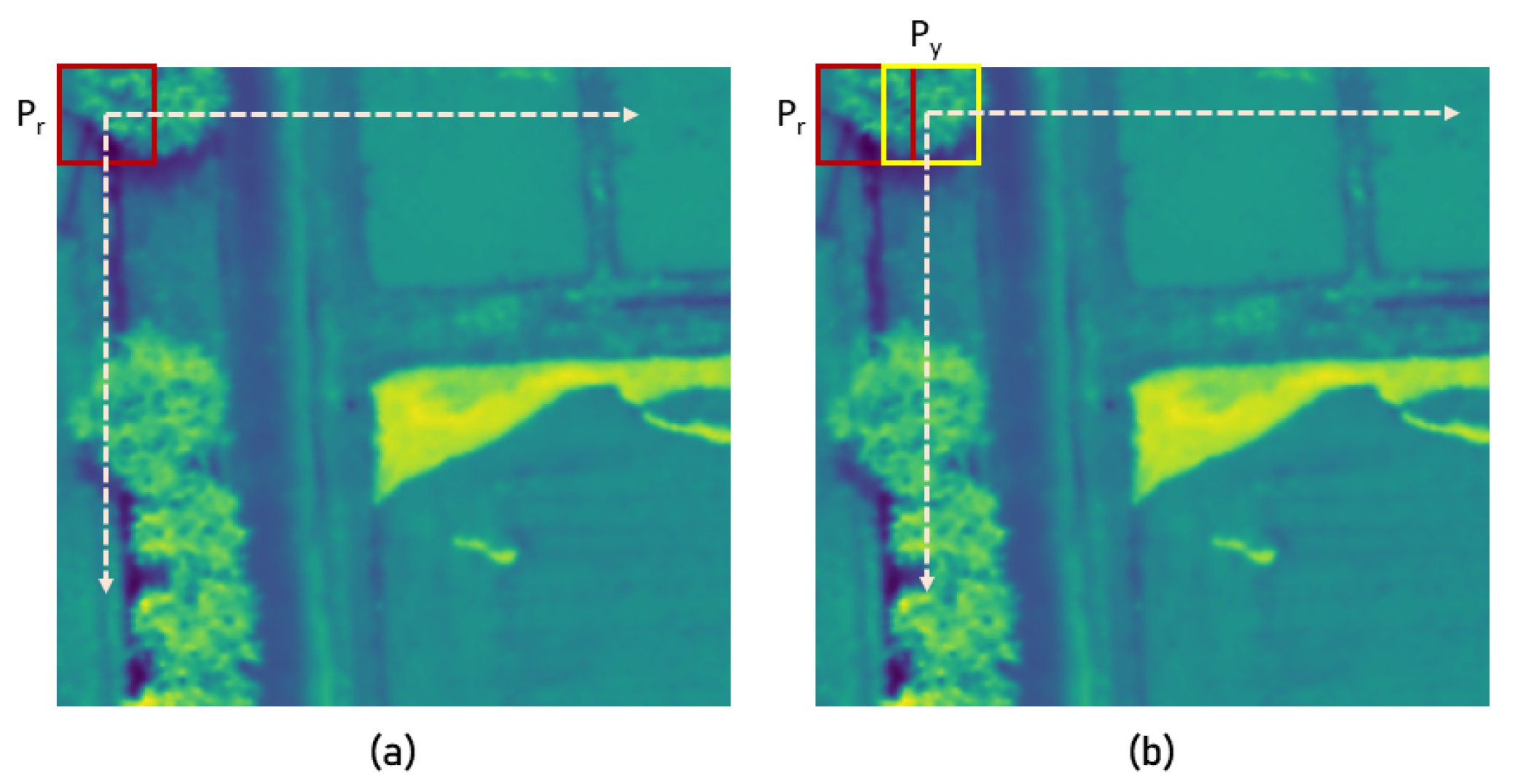
3.2. PST-Based Feature Match Generation
3.3. Dimensionality Reduction Using Autoencoder
3.4. Feature Filtering Using a 3D Convolutional Siamese Network
3.4.1. Network Architecture
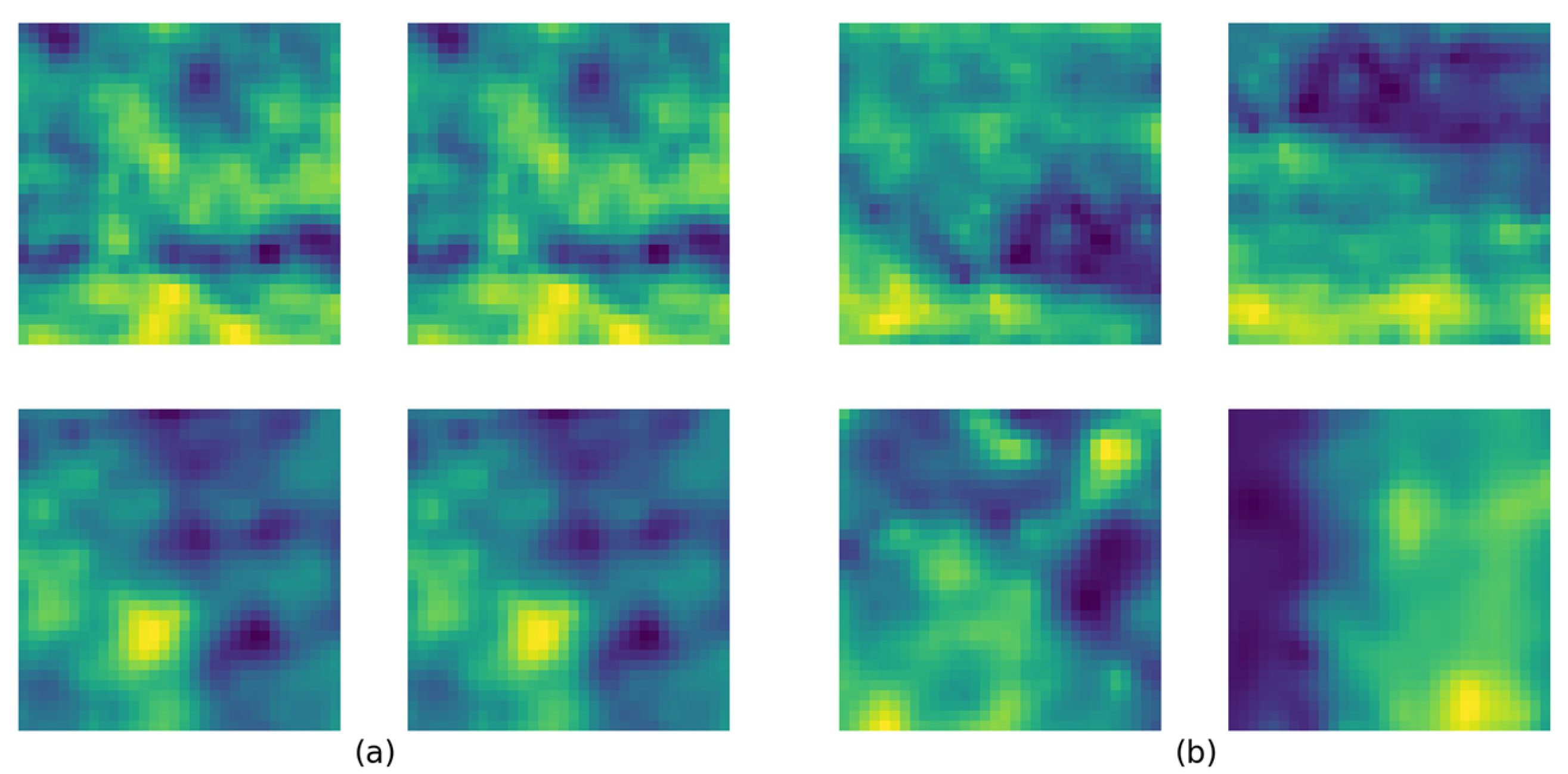
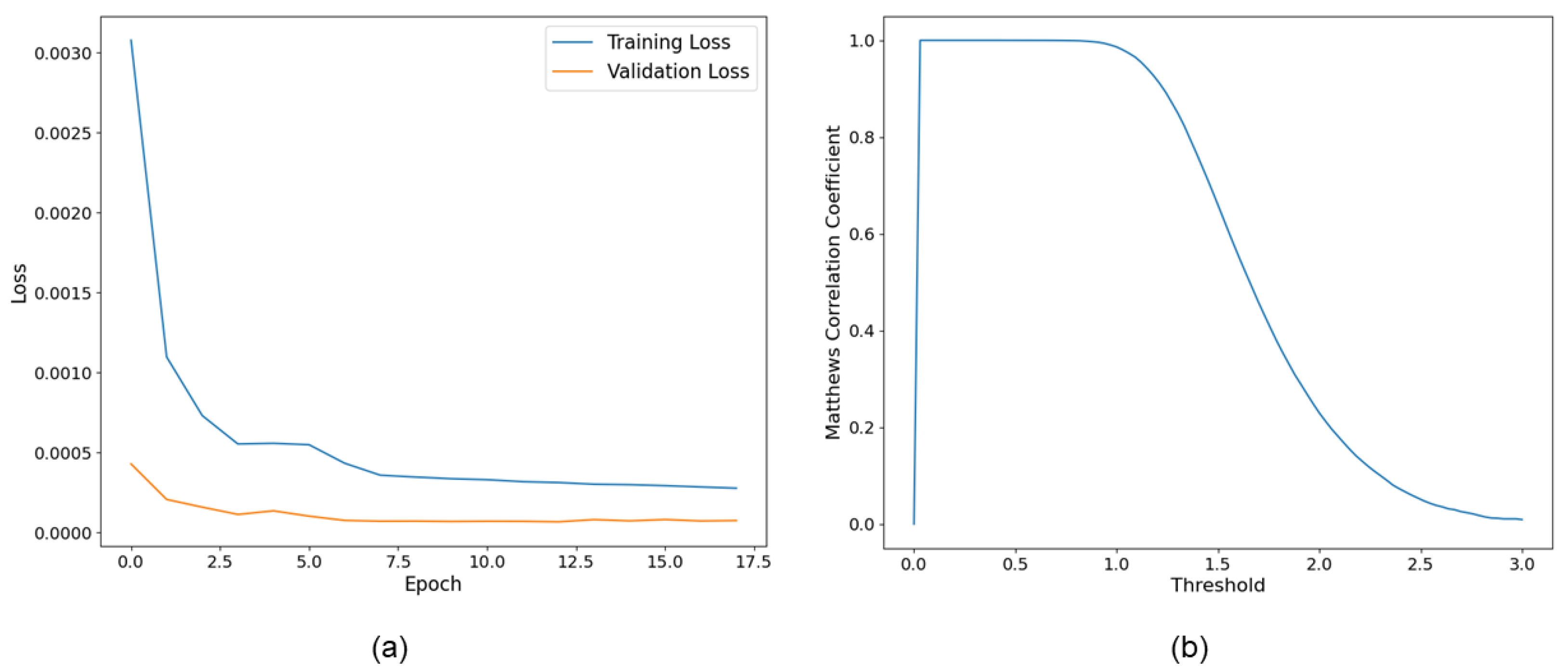
3.4.2. Training Dataset Creation and Training Process
3.5. Evaluation Procedure
4. Results and Discussion
4.1. Selection of the Spectral Band
4.2. Evaluation of the Proposed Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hasanlou, M.; Seydi, S.T. Hyperspectral change detection: An experimental comparative study. Int. J. Remote Sens. 2018, 39, 7029–7083. [Google Scholar] [CrossRef]
- Uzkent, B.; Rangnekar, A.; Hoffman, M. Aerial vehicle tracking by adaptive fusion of hyperspectral likelihood maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 39–48. [Google Scholar]
- Perera, C.J.; Premachandra, C.; Kawanaka, H. Feature Detection and Matching for Low-Resolution Hyperspectral Images. In Proceedings of the 2023 IEEE International Conference on Consumer Electronics (ICCE) Taiwan, Pingtung, Taiwan, 17–19 July 2023; pp. 1–3. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Goetz, A.F.; Vane, G.; Solomon, J.E.; Rock, B.N. Imaging spectrometry for earth remote sensing. Science 1985, 228, 1147–1153. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Wang, X.; Xu, Y.; Jia, T.; Cui, S.; Wei, L.; Ma, A.; Zhang, L. MINI-UAV borne hyperspectral remote sensing: A review. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 3–28 July 2017; pp. 5908–5911. [Google Scholar]
- Govender, M.; Chetty, K.; Bulcock, H. A review of hyperspectral remote sensing and its application in vegetation and water resource studies. Water SA 2007, 33, 145–151. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Yu, H.; Kong, B.; Hou, Y.; Xu, X.; Chen, T.; Liu, X. A critical review on applications of hyperspectral remote sensing in crop monitoring. Exp. Agric. 2022, 58, E26. [Google Scholar] [CrossRef]
- Ghiyamat, A.; Shafri, H.Z. A review on hyperspectral remote sensing for homogeneous and heterogeneous forest biodiversity assessment. Int. J. Remote Sens. 2010, 31, 1837–1856. [Google Scholar] [CrossRef]
- Wu, J.; Peng, D.L. Advances in researches on hyperspectral remote sensing forestry information-extracting technology. Spectrosc. Spectr. Anal. 2011, 31, 2305–2312. [Google Scholar]
- Adam, E.; Mutanga, O.; Rugege, D. Multispectral and hyperspectral remote sensing for identification and mapping of wetland vegetation: A review. Wetl. Ecol. Manag. 2010, 18, 281–296. [Google Scholar] [CrossRef]
- Veraverbeke, S.; Dennison, P.; Gitas, I.; Hulley, G.; Kalashnikova, O.; Katagis, T.; Kuai, L.; Meng, R.; Roberts, D.; Stavros, N. Hyperspectral remote sensing of fire: State-of-the-art and future perspectives. Remote Sens. Environ. 2018, 216, 105–121. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Ramakrishnan, D.; Bharti, R. Hyperspectral remote sensing and geological applications. Curr. Sci. 2015, 108, 879–891. [Google Scholar]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral imaging: A review on UAV-based sensors, data processing and applications for agriculture and forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- “GmbH—Real-Time Spectral Imaging”, Cubert. Available online: https://www.cubert-hyperspectral.com/products/ultris-5 (accessed on 15 November 2022).
- XIMEA—Hyperspectral Cameras Based on USB3—xiSpec—ximea.com. Available online: https://www.ximea.com/en/products/xilab-application-specific-oem-custom/hyperspectral-cameras-based-on-usb3-xispec (accessed on 9 August 2023).
- Datta, A.; Ghosh, S.; Ghosh, A. PCA, Kernel PCA and Dimensionality Reduction in Hyperspectral Images. In Advances in Principal Component Analysis: Research and Development; Springer: Singapore, 2018; pp. 19–46. [Google Scholar]
- Fabiyi, S.D.; Murray, P.; Zabalza, J.; Ren, J. Folded LDA: Extending the linear discriminant analysis algorithm for feature extraction and data reduction in hyperspectral remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12312–12331. [Google Scholar] [CrossRef]
- Lennon, M.; Mercier, G.; Mouchot, M.; Hubert-Moy, L. Independent component analysis as a tool for the dimensionality reduction and the representation of hyperspectral images. In Proceedings of the IGARSS 2001. Scanning the Present and Resolving the Future. IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No. 01CH37217), Sydney, Australia, 9–13 July 2001; Volume 6, pp. 2893–2895. [Google Scholar]
- Fang, Y.; Li, H.; Ma, Y.; Liang, K.; Hu, Y.; Zhang, S.; Wang, H. Dimensionality reduction of hyperspectral images based on robust spatial information using locally linear embedding. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1712–1716. [Google Scholar] [CrossRef]
- Yan, L.; Niu, X. Spectral-angle-based Laplacian eigenmaps for nonlinear dimensionality reduction of hyperspectral imagery. Photogramm. Eng. Remote Sens. 2014, 80, 849–861. [Google Scholar] [CrossRef]
- Ramamurthy, M.; Robinson, Y.H.; Vimal, S.; Suresh, A. Auto encoder based dimensionality reduction and classification using convolutional neural networks for hyperspectral images. Microprocess. Microsyst. 2020, 79, 103280. [Google Scholar] [CrossRef]
- Ayma, V.; Ayma, V.; Gutierrez, J. Dimensionality reduction via an orthogonal autoencoder approach for hyperspectral image classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 357–362. [Google Scholar] [CrossRef]
- Pande, S.; Banerjee, B. Dimensionality reduction using 3d residual autoencoder for hyperspectral image classification. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2029–2032. [Google Scholar]
- Pande, S.; Banerjee, B. Feedback Convolution Based Autoencoder for Dimensionality Reduction in Hyperspectral Images. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 147–150. [Google Scholar]
- Petersson, H.; Gustafsson, D.; Bergstrom, D. Hyperspectral image analysis using deep learning—A review. In Proceedings of the 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA), Oulu, Finland, 12–15 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kuester, J.; Gross, W.; Middelmann, W. 1D-convolutional autoencoder based hyperspectral data compression. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 43, 15–21. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6, 737–744. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.P.; Zhang, T. A survey on siamese network: Methodologies, applications, and opportunities. IEEE Trans. Artif. Intell. 2022, 3, 994–1014. [Google Scholar] [CrossRef]
- Fu, C.; Lu, K.; Zheng, G.; Ye, J.; Cao, Z.; Li, B.; Lu, G. Siamese object tracking for unmanned aerial vehicle: A review and comprehensive analysis. arXiv 2022, arXiv:2205.04281. [Google Scholar] [CrossRef]
- Wu, H.; Xu, Z.; Zhang, J.; Yan, W.; Ma, X. Face recognition based on convolution siamese networks. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–5. [Google Scholar]
- Xiao, W.; Ding, Y. A two-stage siamese network model for offline handwritten signature verification. Symmetry 2022, 14, 1216. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Lin, Z.; Xu, M.; Sun, W.; Huang, Q.; Zhu, J.; Jia, X. A semisupervised Siamese network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5516417. [Google Scholar] [CrossRef]
- Rao, W.; Gao, L.; Qu, Y.; Sun, X.; Zhang, B.; Chanussot, J. Siamese transformer network for hyperspectral image target detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5526419. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Shu, M.; Li, G.; Sun, C.; Liu, Z.; Zhong, Y. An anchor-free Siamese target tracking network for hyperspectral video. In Proceedings of the 2021 11th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 14–16 January 2021; pp. 1–5. [Google Scholar]
- Li, Y.; Wang, J.; Yao, K. Modified phase correlation algorithm for image registration based on pyramid. Alex. Eng. J. 2022, 61, 709–718. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lee, H.; Lee, S.; Choi, O. Improved method on image stitching based on optical flow algorithm. Int. J. Eng. Bus. Manag. 2020, 12, 1847979020980928. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Rosten, E.; Drummond, T. Fusing points and lines for high performance tracking. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–20 October 2005; Volume 2, pp. 1508–1515. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 467–483. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Toward geometric deep slam. arXiv 2017, arXiv:1707.07410. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Rocco, I.; Cimpoi, M.; Arandjelović, R.; Torii, A.; Pajdla, T.; Sivic, J. Ncnet: Neighbourhood consensus networks for estimating image correspondences. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1020–1034. [Google Scholar] [CrossRef]
- Rocco, I.; Arandjelović, R.; Sivic, J. Efficient neighbourhood consensus networks via submanifold sparse convolutions. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 605–621. [Google Scholar]
- Li, X.; Han, K.; Li, S.; Prisacariu, V. Dual-resolution correspondence networks. Adv. Neural Inf. Process. Syst. 2020, 33, 17346–17357. [Google Scholar]
- Lindenberger, P.; Sarlin, P.E.; Pollefeys, M. LightGlue: Local Feature Matching at Light Speed. arXiv 2023, arXiv:2306.13643. [Google Scholar]
- Yi, L.; Chen, J.M.; Zhang, G.; Xu, X.; Ming, X.; Guo, W. Seamless mosaicking of uav-based push-broom hyperspectral images for environment monitoring. Remote Sens. 2021, 13, 4720. [Google Scholar] [CrossRef]
- Peng, Z.; Ma, Y.; Mei, X.; Huang, J.; Fan, F. Hyperspectral image stitching via optimal seamline detection. IEEE Geosci. Remote Sens. Lett. 2021, 19, 5507805. [Google Scholar] [CrossRef]
- Mo, Y.; Kang, X.; Duan, P.; Li, S. A robust UAV hyperspectral image stitching method based on deep feature matching. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5517514. [Google Scholar] [CrossRef]
- Zhang, Y.; Mei, X.; Ma, Y.; Jiang, X.; Peng, Z.; Huang, J. Hyperspectral Panoramic Image Stitching Using Robust Matching and Adaptive Bundle Adjustment. Remote Sens. 2022, 14, 4038. [Google Scholar] [CrossRef]
- Fang, J.; Wang, X.; Zhu, T.; Liu, X.; Zhang, X.; Zhao, D. A novel mosaic method for UAV-based hyperspectral images. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9220–9223. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Ordóñez, Á.; Argüello, F.; Heras, D.B. Alignment of hyperspectral images using KAZE features. Remote Sens. 2018, 10, 756. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Liu, Y.; Xie, W. A spatial-spectral SIFT for hyperspectral image matching and classification. Pattern Recognit. Lett. 2019, 127, 18–26. [Google Scholar] [CrossRef]
- Perera, C.J.; Premachandra, C.; Kawanaka, H. Comparison of Light Weight Hyperspectral Camera Spectral Signatures with Field Spectral Signatures for Agricultural Applications. In Proceedings of the 2023 IEEE International Conference on Consumer Electronics (ICCE), Pingtung, Taiwan, 17–19 July 2023; pp. 1–3. [Google Scholar] [CrossRef]
- Asghari, M.H.; Jalali, B. Physics-inspired image edge detection. In Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Atlanta, GA, USA, 3–5 December 2014; pp. 293–296. [Google Scholar]
- Asghari, M.H.; Jalali, B. Edge detection in digital images using dispersive phase stretch transform. J. Biomed. Imaging 2015, 2015, 687819. [Google Scholar] [CrossRef]
- Coppinger, F.; Bhushan, A.; Jalali, B. Photonic time stretch and its application to analog-to-digital conversion. IEEE Trans. Microw. Theory Tech. 1999, 47, 1309–1314. [Google Scholar] [CrossRef]
- Zhou, Y.; MacPhee, C.; Suthar, M.; Jalali, B. PhyCV: The first physics-inspired computer vision library. arXiv 2023, arXiv:2301.12531. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar]
- Sobel, I. History and Definition of the So-Called “Sobel Operator”, More Appropriately Named the Sobel-Feldman Operator. 2014. Available online: https://www.researchgate.net/publication/239398674_An_Isotropic_3x3_Image_Gradient_Operator.FirstpresentedattheStanfordArtificialIntelligenceProject(SAIL) (accessed on 5 May 2022).
- Marr, D.; Hildreth, E. Theory of edge detection. Proc. R. Soc. Lond. Ser. B. Biol. Sci. 1980, 207, 187–217. [Google Scholar]
- Köppen, M. The curse of dimensionality. In Proceedings of the 5th Online World Conference on Soft Computing in Industrial Applications (WSC5), Online, 4–18 September 2000; Volume 1, pp. 4–8. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization methods for large-scale machine learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Takase, T. Dynamic batch size tuning based on stopping criterion for neural network training. Neurocomputing 2021, 429, 1–11. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Tyszkiewicz, M.; Fua, P.; Trulls, E. DISK: Learning local features with policy gradient. Adv. Neural Inf. Process. Syst. 2020, 33, 14254–14265. [Google Scholar]
- Shi, J. Good features to track. In Proceedings of the 1994 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Viniavskyi, O.; Dobko, M.; Mishkin, D.; Dobosevych, O. OpenGlue: Open source graph neural net based pipeline for image matching. arXiv 2022, arXiv:2204.08870. [Google Scholar]
- Barroso-Laguna, A.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Key.Net: Keypoint Detection by Handcrafted and Learned CNN Filters. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
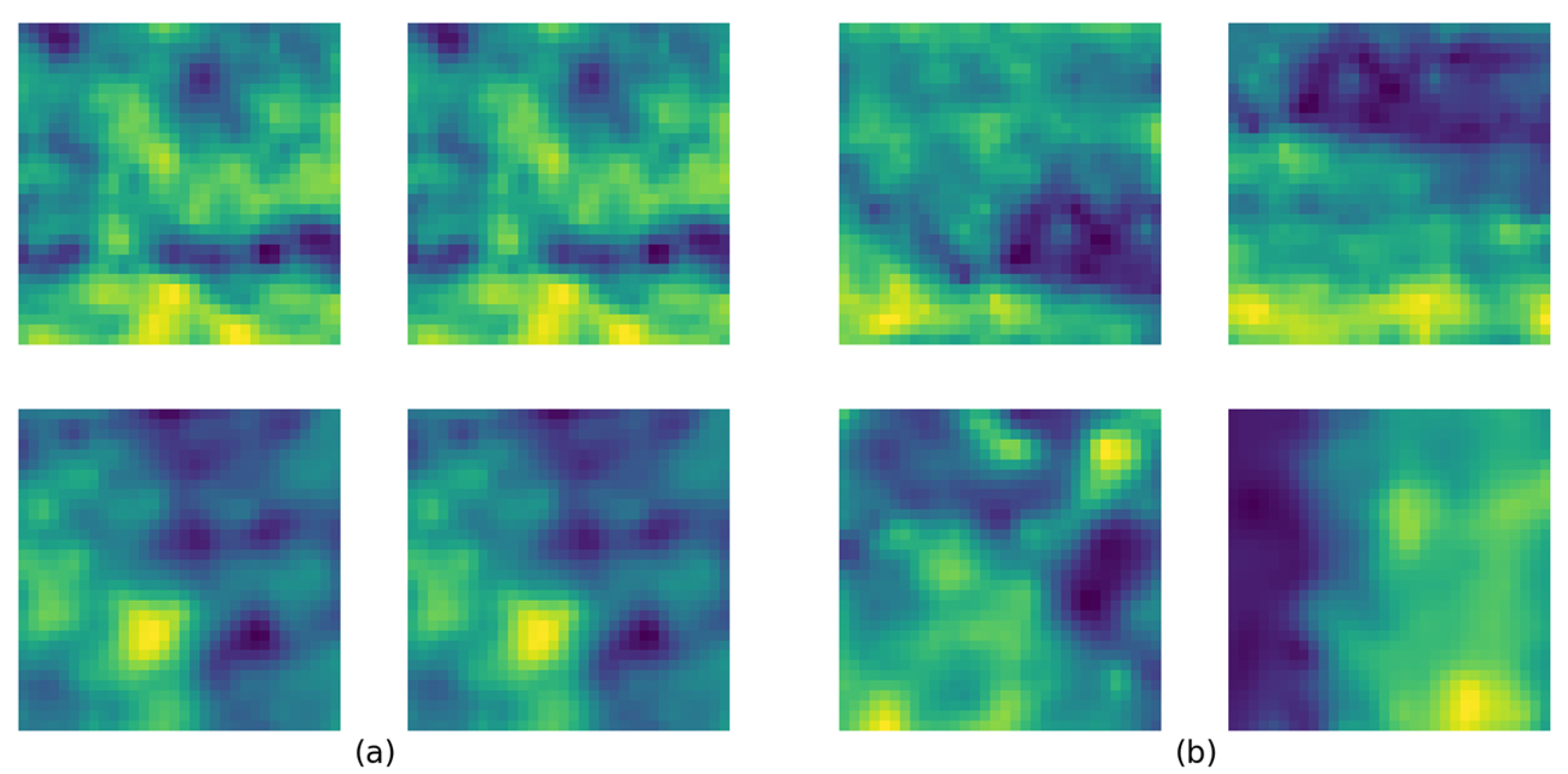{kind=link}
{kind=link}
{kind=link}
{kind=link}
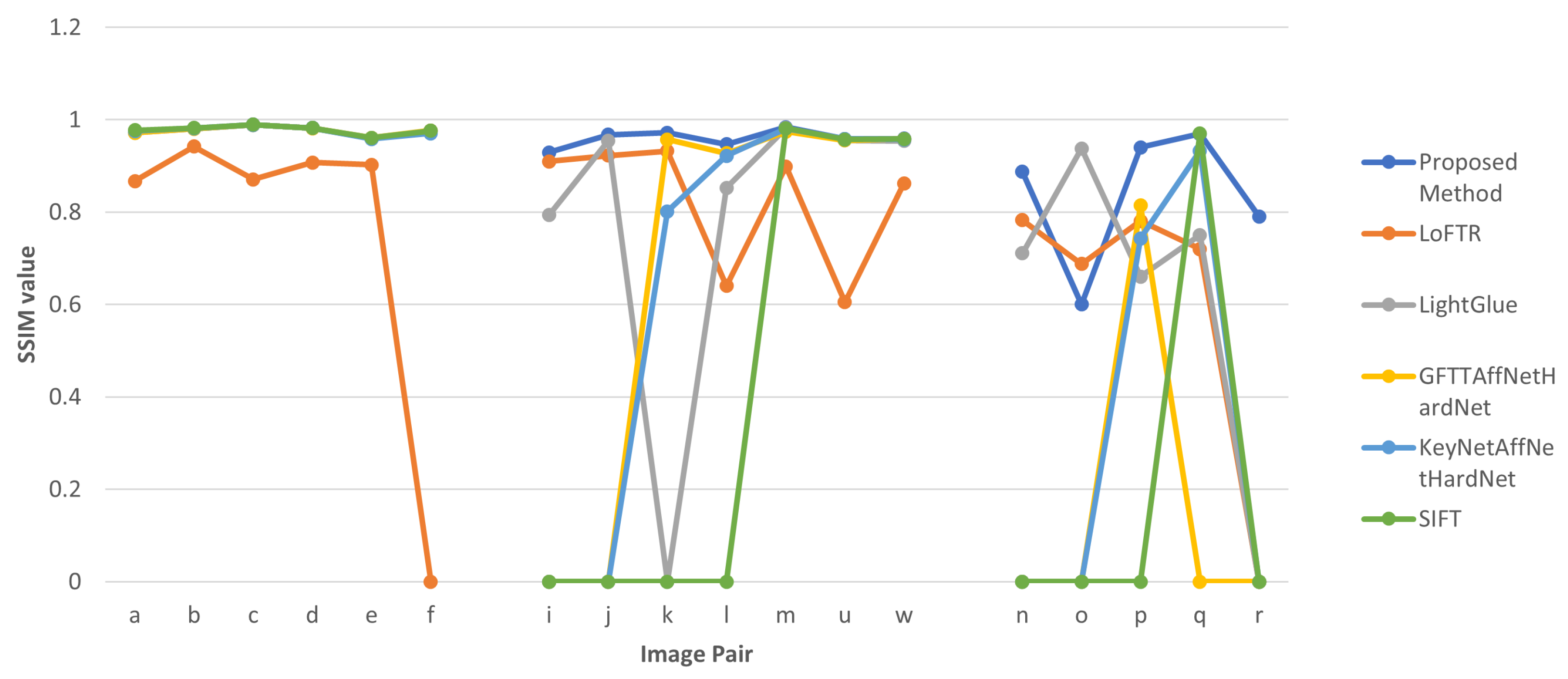{kind=link}
{kind=link}
| Proposed Method | LoFTR | LightGlue + DISK | |||||||||||
| DS | IP | Matches | SSIM | Corr | Inliers | Matches | SSIM | Corr | Inliers | Matches | SSIM | Corr | Inliers |
| 1 | a | 282 | 0.973 | 0.935 | 94.68 | 13 | 0.867 | 0.851 | 92.30 | 677 | 0.971 | 0.999 | 93.83 |
| b | 254 | 0.980 | 0.992 | 91.73 | 719 | 0.942 | 0.978 | 80.80 | 834 | 0.980 | 0.992 | 84.77 | |
| c | 412 | 0.989 | 0.997 | 95.63 | 499 | 0.870 | 0.964 | 77.35 | 838 | 0.989 | 0.997 | 98.56 | |
| d | 394 | 0.982 | 0.998 | 96.70 | 63 | 0.907 | 0.979 | 85.71 | 873 | 0.981 | 0.998 | 96.44 | |
| e | 132 | 0.959 | 0.974 | 77.20 | 42 | 0.902 | 0.926 | 92.85 | 334 | 0.960 | 0.974 | 84.43 | |
| f | 231 | 0.975 | 0.980 | 81.38 | 5 | Fail | 438 | 0.973 | 0.977 | 98.18 | |||
| 2 | i | 74 | 0.929 | 0.622 | 89.18 | 240 | 0.909 | 0.717 | 87.08 | 97 | 0.793 | −0.025 | 82.47 |
| j | 88 | 0.967 | 0.896 | 87.50 | 287 | 0.922 | 0.833 | 75.95 | 387 | 0.954 | 0.943 | 76.74 | |
| k | 36 | 0.971 | 0.941 | 72.22 | 91 | 0.932 | 0.925 | 69.23 | Fail | ||||
| l | 107 | 0.946 | 0.983 | 85.04 | 7 | 0.640 | 0.578 | 85.71 | 241 | 0.853 | 0.911 | 68.87 | |
| m | 215 | 0.983 | 0.968 | 86.04 | 143 | 0.899 | 0.880 | 74.12 | 212 | 0.982 | 0.965 | 88.21 | |
| u | 753 | 0.958 | 0.978 | 92.69 | 58 | 0.605 | 0.712 | 93.10 | 960 | 0.955 | 0.976 | 98.43 | |
| w | 1057 | 0.959 | 0.980 | 99.81 | 841 | 0.862 | 0.929 | 93.10 | 1042 | 0.954 | 0.977 | 91.26 | |
| 3 | n | 14 | 0.887 | 0.874 | 100.0 | 410 | 0.782 | 0.747 | 71.21 | 6 | Fail | ||
| o | 52 | 0.600 | 0.693 | 94.23 | 234 | 0.687 | 0.931 | 75.21 | 285 | 0.710 | 0.958 | 92.63 | |
| p | 131 | 0.940 | 0.947 | 94.02 | 32 | 0.780 | 0.514 | 65.62 | 507 | 0.937 | 0.819 | 81.65 | |
| q | 36 | 0.969 | 0.980 | 75.00 | 45 | 0.720 | 0.805 | 66.66 | 118 | 0.660 | 0.497 | 33.89 | |
| r | 23 | 0.790 | 0.761 | 91.30 | Fail | 41 | 0.750 | 0.657 | 60.97 | ||||
| DS | IP | GFTTAffNetHardNet + snn | KeyNetAffNetHardNet + snn | SIFT | |||||||||
| Matches | SSIM | Corr | Inlirs | Matches | SSIM | Corr | Inliers | Matches | SSIM | Corr | Inliers | ||
| 1 | a | 51 | 0.971 | 0.927 | 98.11 | 125 | 0.975 | 0.982 | 83.20 | 38 | 0.977 | 0.956 | 13.47 |
| b | 52 | 0.979 | 0.992 | 100.0 | 126 | 0.981 | 0.992 | 88.09 | 29 | 0.981 | 0.993 | 11.41 | |
| c | 87 | 0.988 | 0.997 | 87.35 | 143 | 0.989 | 0.997 | 95.10 | 44 | 0.989 | 0.997 | 10.67 | |
| d | 88 | 0.981 | 0.998 | 95.45 | 150 | 0.981 | 0.998 | 86.66 | 38 | 0.981 | 0.998 | 8.12 | |
| e | 23 | 0.960 | 0.974 | 86.95 | 88 | 0.958 | 0.974 | 96.59 | 33 | 0.961 | 0.974 | 18.18 | |
| f | 41 | 0.976 | 0.970 | 97.56 | 58 | 0.970 | 0.967 | 89.65 | 16 | 0.975 | 0.980 | 6.49 | |
| 2 | i | Fail | Fail | 34 | Fail | ||||||||
| j | Fail | Fail | Fail | ||||||||||
| k | 7 | 0.957 | 0.932 | 100 | 10 | 0.801 | 0.774 | 80.00 | Fail | ||||
| l | 4 | 0.927 | 0.971 | 100 | 18 | 0.922 | 0.968 | 88.88 | 12 | Fail | |||
| m | 27 | 0.973 | 0.958 | 92.59 | 73 | 0.981 | 0.964 | 84.93 | 66 | 0.981 | 0.963 | 8.37 | |
| u | 192 | 0.955 | 0.976 | 24.70 | 131 | 0.958 | 0.978 | 87.78 | 357 | 0.957 | 0.977 | 83.75 | |
| w | 259 | 0.958 | 0.980 | 24.50 | 131 | 0.957 | 0.979 | 83.21 | 456 | 0.958 | 0.979 | 96.49 | |
| 3 | n | Fail | 5 | Fail | 26 | Fail | |||||||
| o | 8 | Fail | 8 | Fail | Fail | ||||||||
| p | 14 | 0.814 | 0.510 | 78.57 | 41 | 0.742 | 0.452 | 75.60 | 19 | Fail | |||
| q | 1 | Fail | 26 | 0.932 | 0.956 | 69.23 | 7 | 0.970 | 0.978 | 19.44 | |||
| r | 1 | Fail | 6 | Fail | Fail | ||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perera, C.J.; Premachandra, C.; Kawanaka, H. Enhancing Feature Detection and Matching in Low-Pixel-Resolution Hyperspectral Images Using 3D Convolution-Based Siamese Networks. Sensors 2023, 23, 8004. https://doi.org/10.3390/s23188004
Perera CJ, Premachandra C, Kawanaka H. Enhancing Feature Detection and Matching in Low-Pixel-Resolution Hyperspectral Images Using 3D Convolution-Based Siamese Networks. Sensors. 2023; 23(18):8004. https://doi.org/10.3390/s23188004
Chicago/Turabian StylePerera, Chamika Janith, Chinthaka Premachandra, and Hiroharu Kawanaka. 2023. "Enhancing Feature Detection and Matching in Low-Pixel-Resolution Hyperspectral Images Using 3D Convolution-Based Siamese Networks" Sensors 23, no. 18: 8004. https://doi.org/10.3390/s23188004
APA StylePerera, C. J., Premachandra, C., & Kawanaka, H. (2023). Enhancing Feature Detection and Matching in Low-Pixel-Resolution Hyperspectral Images Using 3D Convolution-Based Siamese Networks. Sensors, 23(18), 8004. https://doi.org/10.3390/s23188004