
A Multiarmed Bandit Approach for LTE-U/Wi-Fi Coexistence in a Multicell Scenario
 , ,
, ,  , ,
, ,  , and
, and
Abstract
1. Introduction
2. Related Works
- An LTE operator is the best neighbor for a Wi-Fi operator in terms of interference and capacity, even if compared with the coexistence of two Wi-Fi networks.
- The mechanism for accessing the LTE environment in the unlicensed spectrum must be dynamically adjusted to ensure that no additional configuration is required from the user. The first conclusion is only true if this condition is satisfied.
- Due to the dynamic aspect of traffic load demand, interference, and usage of different technologies, machine learning techniques are strong candidates for the coexistence problem.
- A simple, adaptive DC selection strategy with better performance and enhanced fairness compared with the Q-Learning-based strategy proposed in [10];
- A flexible solution for the coexistence that does not require the definition of state-action pairs, allowing a higher number of available DC values to choose from;
- An adaptive solution that combines low complexity and lower number of parameters to configure;
- We show that in environments where the rate changes dynamically, the sequential decision-making approach can result in a base model that is applicable for a wide range of reinforcement learning algorithms, whether they are simple or complex;
- A key comparison of reinforcement learning strategies applied to the adaptive multicell data rate environment for coexistence. To the best of our knowledge, this kind of comparison has not yet been done using the approach presented in this work.
3. Evaluation Scenario and Reference Results
- The DC value that results in maximum system throughput depends on the offered data rate and changes every time that the offered data rates change;
- If the offered data rate for each operator is unbalanced, the best DC value, resulting in maximum system throughput, is the one that is proportional to the imbalance. For example, if we offer 4 Mbps for LTE-U users and 500 kbps for Wi-Fi users, the optimal DC value is approximately , because it gives 80% of the channel usage time for LTE-U and 20% for Wi-Fi, matching the demand;
- A fixed DC value is not enough to achieve maximum throughput in a dynamic system where the data rates are constantly changing. In order to reach maximum throughput in such scenarios, a dynamic algorithm is needed to automatically and dynamically change the DC value based on the system’s current state.
- Choosing the best DC value for the current state guarantees that the system will always be as close to its maximum throughput as possible, since there is an optimal DC value for each combination of offered data rates;
- Q-Learning is highly dependent on how the state-action pair is modeled, and this has a great impact on convergence. If the number of state-action pairs is high, the algorithm may not converge before it is time to begin calculating again. On the other hand, if the number of state-action pairs is low, the algorithm may converge to a locally optimal point, or it may not explore all possibilities provided by the environment. Therefore, fine-tuning is necessary when using this approach for optimal decision making.
4. Adaptive Duty Cycle Selection with Reinforcement Learning
5. MAB-ADC: Multiarmed Bandit for Adaptive Duty Cycle Selection
- The actions that the agent can choose from are the duty cycle values in the set . Each value represents how much channel air time, during the ABS time, is given to each access technology. For example, a DC value of means that 40% of the ABS time is reserved for LTE-U and 60% is reserved for Wi-Fi;
- The reward is defined as the aggregated throughput: , where is the LTE-U operator throughput over the ABS time, and represents the throughput of the Wi-Fi operator;
- The decision-making process happens for each duty cycle duration of 40 ms (ABS time);
- To balance the exploration vs. exploitation trade-off in the -greedy algorithm, the value of is initially defined as , which corresponds to a 30% exploring probability. Then, this value decays with a factor of . This configuration ensures more exploration at the beginning and more exploitation after learning the best action. Besides, these values result in an exploring probability of % after 200 random selections.
| Algorithm 1: MAB-ADC: MAB application for adaptive DC selection |
 |
6. Performance Evaluation of MAB-ADC
- It has 40 s of duration, and the offered data rate changes after 20 s;
- The offered data rate is initially 4 Mbps for LTE-U users and 500 kbps for Wi-Fi users. At 20 s, the data rates are inverted. This approach comprises two different unbalanced scenarios regarding the system’s demand. When LTE-U users have a much higher offered data rate, the optimal DC value is the one that gives more channel time to LTE-U, that is, a DC value closer to 1. However, if Wi-Fi users have a higher offered data rate, the optimal DC value is the one that gives more channel time to Wi-Fi, closer to 0;
- The algorithms always operate at the end of the current ABS time (40 ms windows). At that time, they select the DC value for the next ABS interval;
- For comparison, we use the Q-Learning framework proposed in [10]. It has the same centralized and coordinated operation as one of our proposed MAB operation modes. The QL is defined with four actions and four states. Since QL also requires the state’s definition, we established only four actions. If the number of actions were to be increased, the convergence time would be affected.
- The simulation has a duration of 250 s, and the offered data rate changes at specific timestamps throughout the simulation;
- The offered data rate is uniformly sampled from the set = { 500 kbps, 1 Mbps, 2 Mbps, 4 Mbps};
- The specific timestamps where the offered data rate changes occur are uniformly sampled from an interval between 10 and 15 s. These timestamps are added to the current simulation time until it reaches the 250 s limit. As a result, during the 250 s simulation, there will be from 16 to 25 changes in the offered data rate (calculated by dividing the total duration by the minimum and maximum intervals);
- The algorithms always operate at the end of the current ABS time (40 ms windows). At that time, they select the DC value for the next ABS interval;
- To ensure statistical confidence, the 250 s simulation was repeated 100 times. In each simulation run (snapshot), the stations are uniformly distributed across the multicell scenario, resulting in different interference profiles, since the stations are in different positions at each snapshot;
- For comparison, we also use the Q-Learning framework defined in [10]. It has the same centralized and coordinated operations as one of our proposed MAB operation modes.
7. Final Comments and Future Investigation
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ericsson. Ericsson Mobility Report—2020; Technical Report; Ericsson: Stockholm, Sweden, 2020. [Google Scholar]
- Roslee, M.; Alhammadi, A.; Alias, M.Y.; Anuar, K.; Nmenme, P.U. Efficient handoff spectrum scheme using fuzzy decision making in cognitive radio system. In Proceedings of the 2017 3rd International Conference on Frontiers of Signal Processing (ICFSP), Paris, France, 6–8 September 2017. [Google Scholar] [CrossRef]
- TR 36.889; Feasibility Study on Licensed-Assisted Access to Unlicensed Spectrum (Release 13). 3GPP: Sophia Antipolis, France, 2015.
- LTE-U Forum; LTE-U Technical Report—Coexistence Study for LTE-U SDL v1.0 Technical Report, Alcatel-Lucent, Ericsson, Qualcomm Technologies. 2015. Available online: https://studylib.net/doc/18297695/lte-u-technical-report—lte (accessed on 16 June 2023).
- TR 38.889; Technical Specification Group Radio Access Network; Study on NR-Based Access to Unlicensed Spectrum (Release 16). Technical Report; 3GPP: Sophia Antipolis, France, 2018.
- De Santana, P.M.; de Lima Melo, V.D.; de Sousa, V.A. Performance of License Assisted Access Solutions Using ns-3. In Proceedings of the International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016. [Google Scholar] [CrossRef]
- De Santana, P.M.; Neto, J.M.d.C.; de Sousa, V.A. Evaluation of LTE Unlicensed Solutions Using ns-3. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 674–679. [Google Scholar] [CrossRef]
- De Santana, P.M.; de Sousa, V.A., Jr.; Abinader, F.M.; de C. Neto, J.M. DM-CSAT: A LTE-U/Wi-Fi coexistence solution based on reinforcement learning. Telecommun. Syst. 2019, 71, 615–626. [Google Scholar] [CrossRef]
- De Santana, P.; Castro Neto, J.; Abinader, F., Jr.; de Sousa, V.A. GTDM-CSAT: An LTE-U self Coexistence Solution based on Game Theory and Reinforcement Learning. J. Commun. Inf. Syst. 2019, 34, 169–177. [Google Scholar] [CrossRef][Green Version]
- Neto, J.M.C.; Neto, S.F.; de Santana, P.M.; de Sousa, V.A. Multi-cell LTE-U/Wi-Fi coexistence evaluation using a reinforcement learning framework. Sensors 2020, 20, 1855. [Google Scholar] [CrossRef] [PubMed]
- Qualcomm; Ericsson; Alcatel-Lucent. Qualcomm Research LTE in Unlicensed Spectrum: Harmonious Coexistence with Wi-Fi; Technical Report; Qualcomm: San Diego, CA, USA, 2014. [Google Scholar]
- Qualcomm. HSPA Supplemental Downlink; Technical Report; Qualcomm: San Diego, CA, USA, 2014. [Google Scholar]
- TR 36.300; LTE; Evolved Universal Terrestrial Radio Access (E-UTRA) and Evolved Universal Terrestrial Radio Access Network (E-UTRAN); Overall Description; Stage 2 (Release 13). 3GPP: Sophia Antipolis, France, 2016.
- Koorapaty, H. RP-151866: Work Item on Licensed-Assisted Access to Unlicensed Spectrum (TSG RAN Meeting 70); Technical Report; 3GPP: Sophia Antipolis, France, 2015. [Google Scholar]
- Corporation, I. LTE-WLAN Aggregation (LWA): Benefits and Deployment Considerations. Available online: https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/lte-wlan-aggregation-deployment-paper.pdf (accessed on 1 January 2023).
- Qualcomm. Multefire: LTE-Like Performance with Wi-Fi-Like Deployment Simplicity. Available online: https://www.qualcomm.com/invention/technologies/lte/multefire (accessed on 1 January 2023).
- Alliance, M. About MulteFire Release 1.1 Specification. Available online: https://www.multefire.org/technology/specifications/ (accessed on 1 January 2023).
- Zhang, J.; Liu, S.; Yin, R.; Yu, G.; Jin, X. Coexistence algorithms for LTE and WiFi networks in unlicensed spectrum: Performance optimization and comparison. Wirel. Netw. 2021, 27, 1875–1885. [Google Scholar] [CrossRef]
- Shinde, B.E.; Vijayabaskar, V. An Opportunistic Coexistence Analysis of LTE and Wi-Fi in Unlicensed 5 GHz Frequency Band. Wirel. Pers. Commun. 2023, 130, 269–280. [Google Scholar] [CrossRef]
- Dama, S.; Kumar, A.; Kuchi, K. Performance Evaluation of LAA-LBT based LTE and WLANs Co-existence in Unlicensed Spectrum. In Proceedings of the 2015 IEEE Globecom Workshops (GC Wkshps), San Diego, CA, USA, 6–10 December 2015. [Google Scholar] [CrossRef]
- Rupasinghe, N.; Guvenc, I. Licensed-Assisted Access for WiFi-LTE Coexistence in the Unlicensed Spectrum. In Proceedings of the 2014 IEEE Globecom Workshops (GC Wkshps), Austin, TX, USA, 8–12 December 2014. [Google Scholar] [CrossRef]
- Chen, B.; Chen, J.; Gao, Y.; Zhang, J. Coexistence of LTE-LAA and Wi-Fi on 5 GHz with Corresponding Deployment Scenarios: A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 7–32. [Google Scholar] [CrossRef]
- Girmay, M.; Maglogiannis, V.; Naudts, D.; Shahid, A.; Moerman, I. Coexistence Scheme for Uncoordinated LTE and WiFi Networks Using Experience Replay Based Q-Learning. Sensors 2021, 21, 6977. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Sun, X.; Gao, Y.; Zhan, W.; Li, Y. Spectrum sharing mechanisms in the unlicensed band: Performance limit and comparison. IET Commun. 2023, 17, 999–1011. [Google Scholar] [CrossRef]
- Zinno, S.; Di Stasi, G.; Avallone, S.; Ventre, G. On a fair coexistence of LTE and Wi-Fi in the unlicensed spectrum: A Survey. Comput. Commun. 2018, 115, 35–50. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, T.; Liew, S.C. Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar] [CrossRef]
- Naveen, K.P.; Amballa, C. Coexistence of LTE-Unlicensed and WiFi: A Reinforcement Learning Framework. In Proceedings of the 13th International Conference on Communication Systems & Networks (COMSNETS), Bangalore, India, 5–9 January 2021. [Google Scholar] [CrossRef]
- Maglogiannis, V.; Naudts, D.; Shahid, A.; Moerman, I. A Q-Learning Scheme for Fair Coexistence between LTE and Wi-Fi in Unlicensed Spectrum. IEEE Access 2018, 6, 27278–27293. [Google Scholar] [CrossRef]
- Bajracharya, R.; Shrestha, R.; Kim, S.W. Q-Learning Based Fair and Efficient Coexistence of LTE in Unlicensed Band. Sensors 2019, 19, 2875. [Google Scholar] [CrossRef] [PubMed]
- Pei, E.; Huang, Y.; Li, Y. A Deep Reinforcement Learning Based Spectrum Access Scheme in Unlicensed Bands. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021. [Google Scholar] [CrossRef]
- Pei, E.; Huang, Y.; Zhang, L.; Li, Y.; Zhang, J. Intelligent Access to Unlicensed Spectrum: A Mean Field Based Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2023, 22, 2325–2337. [Google Scholar] [CrossRef]
- Lai, L.; Jiang, H.; Poor, H.V. Medium Access in Cognitive Radio Networks: A Competitive Multi-armed Bandit Framework. In Proceedings of the 2008 42nd Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 26–29 October 2008; pp. 98–102. [Google Scholar] [CrossRef]
- Sriyananda, M.G.; Parvez, I.; Guvene, I.; Bennis, M.; Sarwat, A.I. Multi-Armed bandit for LTE-U and WiFi coexistence in unlicensed bands. In Proceedings of the IEEE Wireless Communications and Networking Conference, WCNC, Doha, Qatar, 3–6 April 2016. [Google Scholar] [CrossRef]
- Parvez, I.; Sriyananda, M.G.; Güvenç, I.; Bennis, M.; Sarwat, A. CBRS Spectrum Sharing between LTE-U and WiFi: A Multiarmed Bandit Approach. Mob. Inf. Syst. 2016, 2016, 5909801. [Google Scholar] [CrossRef]
- Zhou, K.; Li, A.; Dong, C.; Zhang, L.; Qin, Z. MABOM: A MAB-based Opportunistic MAC Protocol for WiFi/M2M Coexistence. In Proceedings of the 5th International Conference on Big Data Computing and Communications, BIGCOM 2019, QingDao, China, 9–11 August 2019; pp. 278–282. [Google Scholar] [CrossRef]
- ns-3. ns-3 Repositories. Available online: http://code.nsnam.org/ (accessed on 1 January 2023).
- ns-3. LTE LBT Wi-Fi Coexistence Module Documentation (Release ns-3-lbt rev. b48bfc33132b). 2016. Available online: https://www.nsnam.org/~tomh/ns-3-lbt-documents/html/lbt-wifi-coexistence.html (accessed on 1 January 2023).
- Almeida, E.; Cavalcante, A.M.; Paiva, R.C.D.; Chaves, F.S.; Abinader, F.M.; Vieira, R.D.; Choudhury, S.; Tuomaala, E.; Doppler, K. Enabling LTE/WiFi coexistence by LTE blank subframe allocation. In Proceedings of the 2013 IEEE International Conference on Communications (ICC), Budapest, Hungary, 9–13 June 2013. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; Cambridge University Press: London, UK, 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wi-Fi parameter (802.11n-HT PHY/MAC) | |
|---|---|
| Bandwidth | 20 MHz |
| CCA-Energy Detection threshold | −62 dBm |
| CCA-Carrier sense threshold | −82 dBm |
| Bit Error Rate (BER) target | |
| LTE parameters | |
| Bandwidth | 20 MHz |
| Packet scheduler | Proportional fair |
| ABS pattern duration | 40 ms |
| Duty Cycle (DC) values | {0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9} |
| Common parameters | |
| Tx power | −18 dBm |
| Traffic model | UDP full buffer |
| Mobility | Constant position |
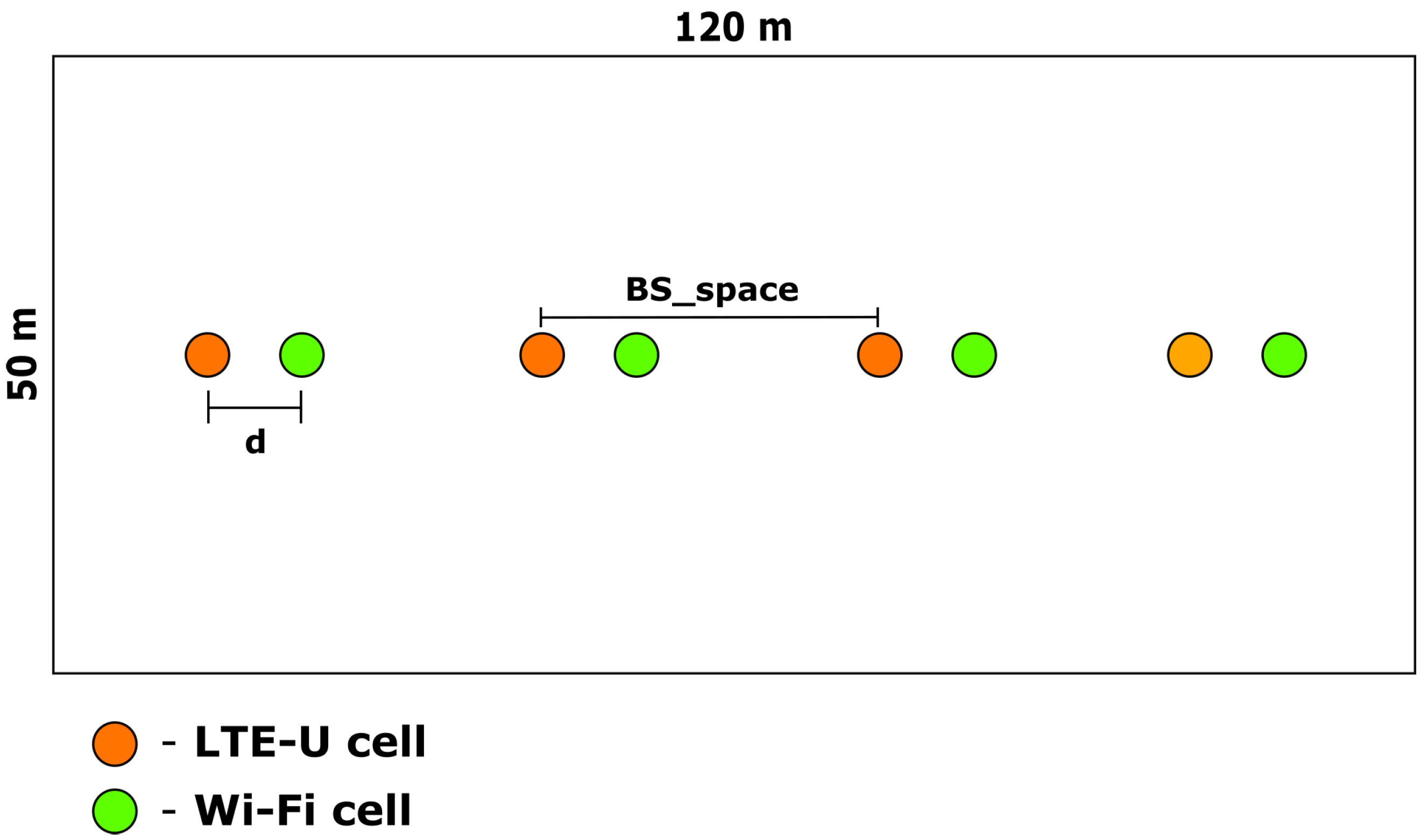
| Scenario | |
| d (distance between APs of different RATs) | 5 m |
| (distance between APs of same RAT) | 25 m |
| Number of LTE-U APs | 4 |
| Number of LTE-U stations | 20 |
| Number of Wi-Fi APs | 4 |
| Number of Wi-Fi stations | 20 |
| Path loss and Shadowing | ITU InH |
| Cell selection criteria | For Wi-Fi, AP with strongest RSS. |
| For LTE-U, cell with the strongest RSRP. | |
| UDPRate | {0.5, 1, 2 Mbps, 4 Mbps}. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diógenes do Rego, I.; de Castro Neto, J.M.; Neto, S.F.G.; de Santana, P.M.; de Sousa, V.A., Jr.; Vieira, D.; Venâncio Neto, A. A Multiarmed Bandit Approach for LTE-U/Wi-Fi Coexistence in a Multicell Scenario. Sensors 2023, 23, 6718. https://doi.org/10.3390/s23156718
Diógenes do Rego I, de Castro Neto JM, Neto SFG, de Santana PM, de Sousa VA Jr., Vieira D, Venâncio Neto A. A Multiarmed Bandit Approach for LTE-U/Wi-Fi Coexistence in a Multicell Scenario. Sensors. 2023; 23(15):6718. https://doi.org/10.3390/s23156718
Chicago/Turabian StyleDiógenes do Rego, Iago, José M. de Castro Neto, Sildolfo F. G. Neto, Pedro M. de Santana, Vicente A. de Sousa, Jr., Dario Vieira, and Augusto Venâncio Neto. 2023. "A Multiarmed Bandit Approach for LTE-U/Wi-Fi Coexistence in a Multicell Scenario" Sensors 23, no. 15: 6718. https://doi.org/10.3390/s23156718
APA StyleDiógenes do Rego, I., de Castro Neto, J. M., Neto, S. F. G., de Santana, P. M., de Sousa, V. A., Jr., Vieira, D., & Venâncio Neto, A. (2023). A Multiarmed Bandit Approach for LTE-U/Wi-Fi Coexistence in a Multicell Scenario. Sensors, 23(15), 6718. https://doi.org/10.3390/s23156718