
Exploiting Light Polarization for Deep HDR Imaging from a Single Exposure †

Abstract
1. Introduction
2. Related Work
2.1. Multiple LDR to HDR
2.1.1. Classical Approaches
2.1.2. Learning-Based Techniques
2.2. Single LDR to HDR
2.2.1. Classical
2.2.2. Learning Based
2.3. Novel Sensors for HDR
2.4. PFA Camera-Based HDR
3. HDR with Stereo PFA Cameras
- It requires two PFA cameras mounted on a rigid structure, which is expensive.
- The stereo setup is complicated to manage and not easy to use (e.g., shutter synchronization or the calibration of the camera’s response function).
- Although two cameras have a minimum baseline, there is still a need to align the responses of both cameras, and mapping can be erroneous, especially for objects near the cameras.
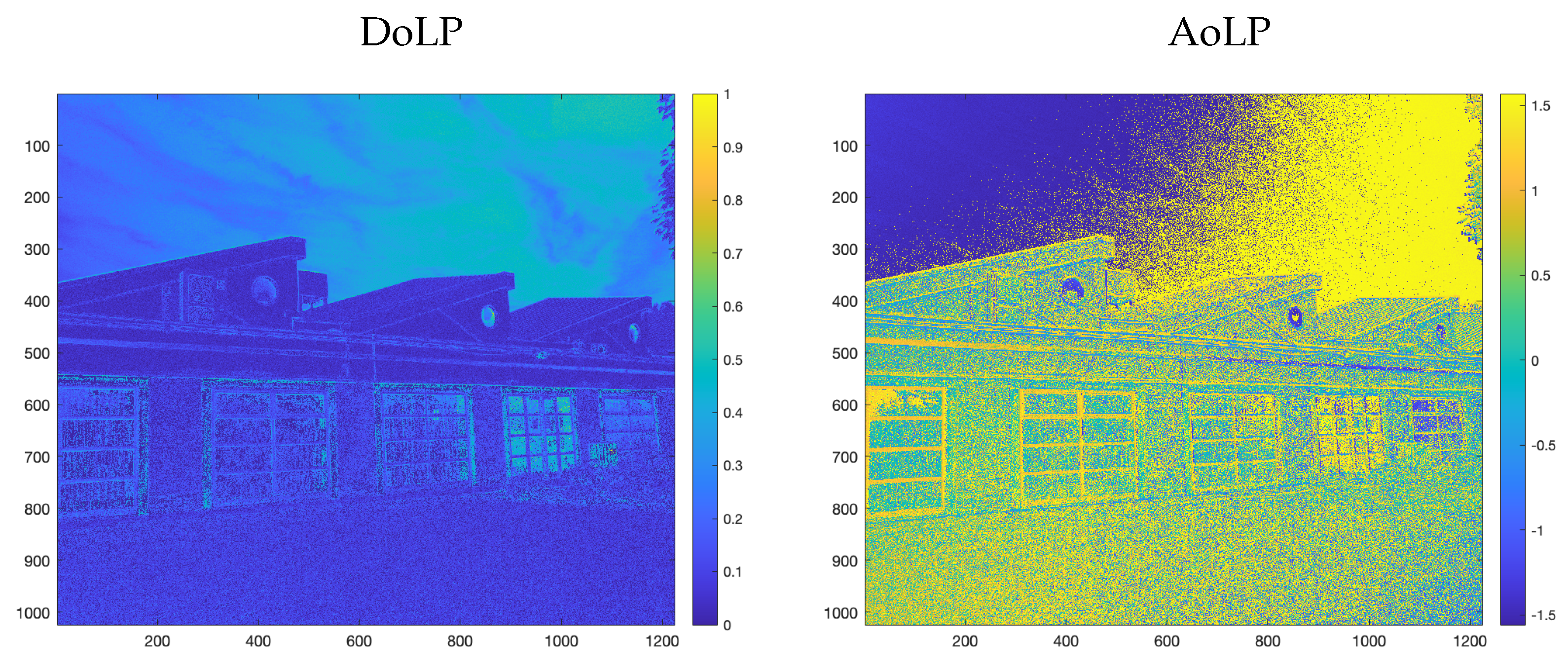
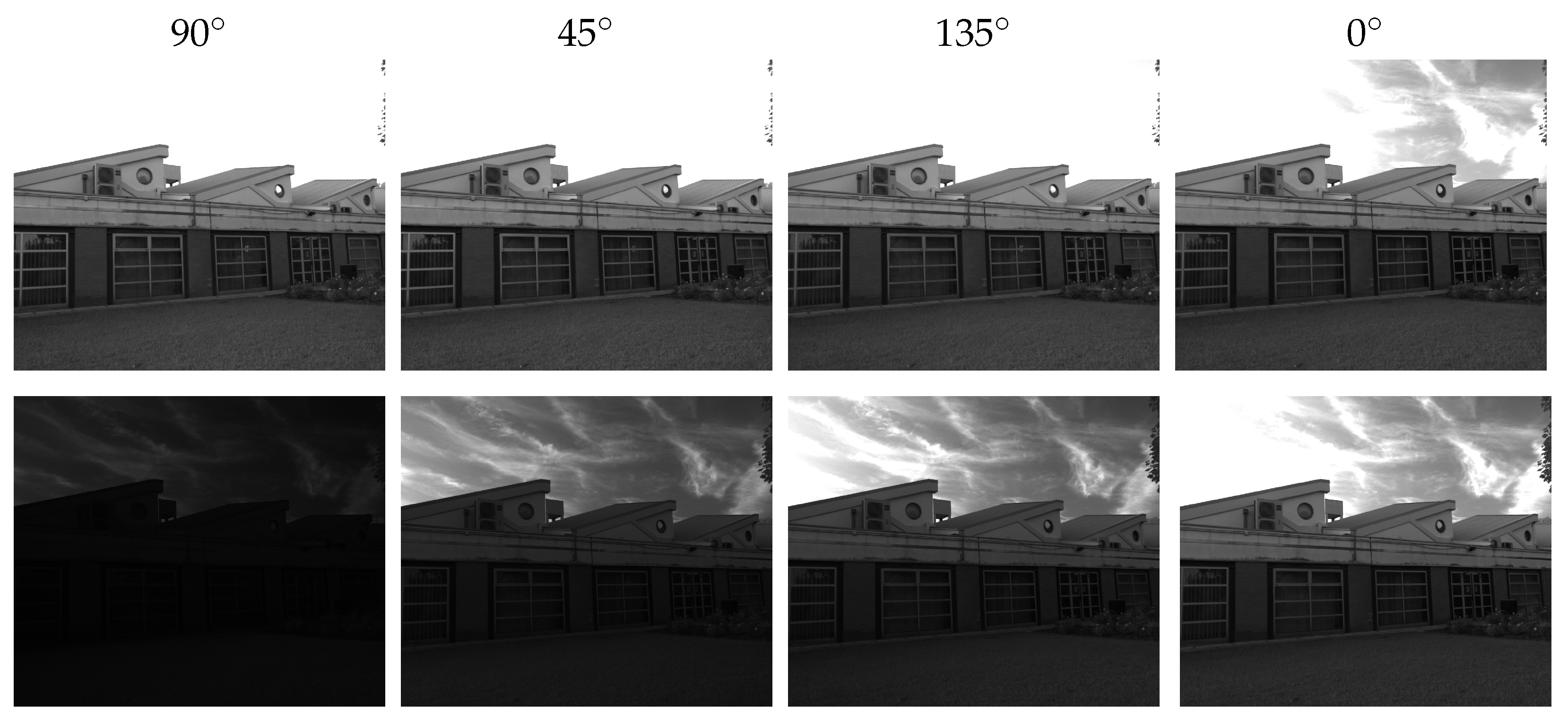
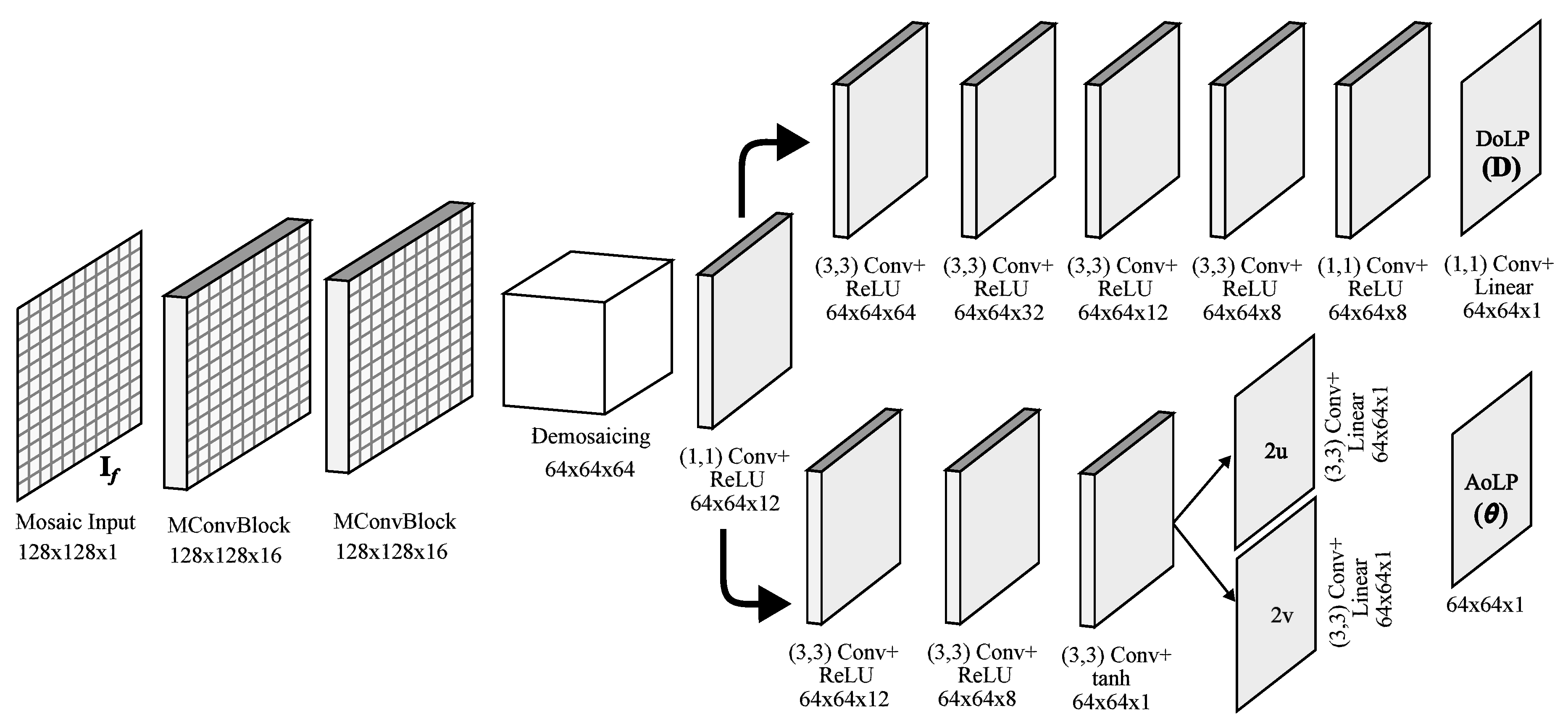
4. Single-Shot HDR with the PFA Camera
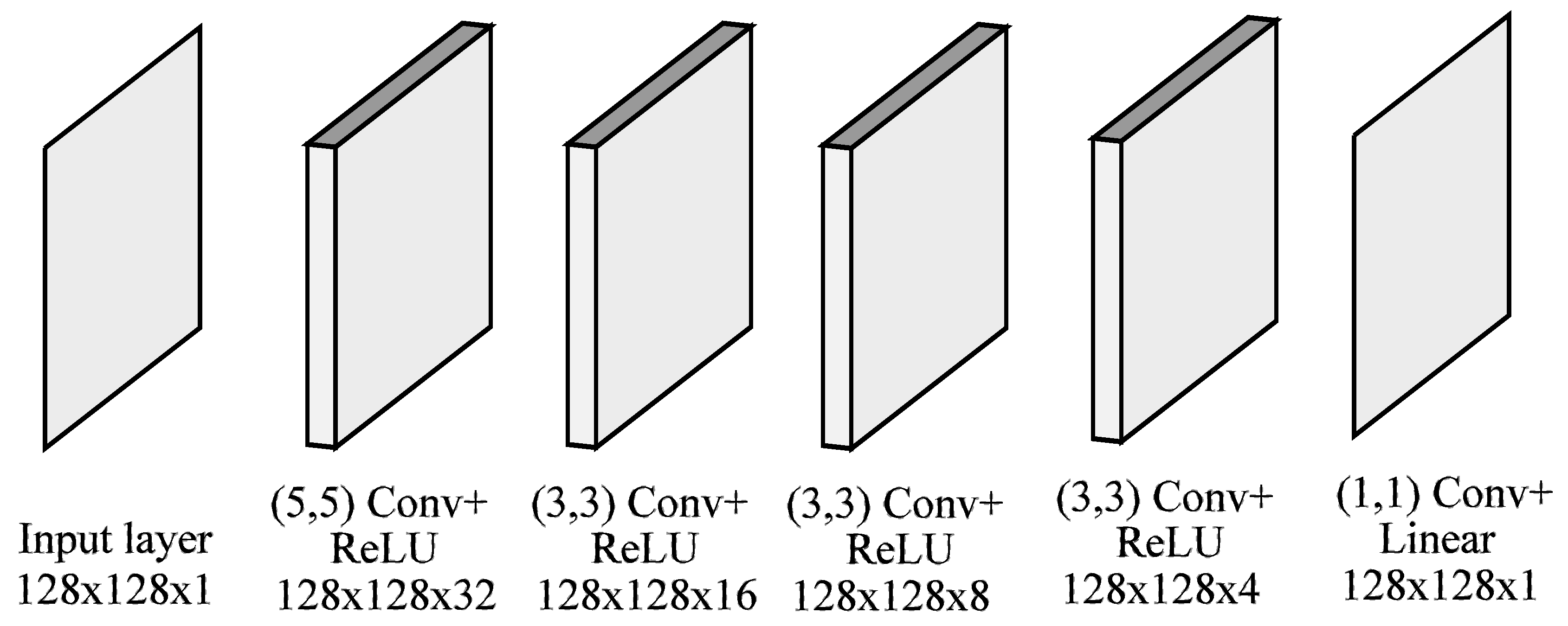
- The recovery network is in charge of synthesizing the response of a regular PFA camera (in terms of AoLP and DoLP) from an image taken with an additional external linear polarizer. The network architecture includes some components, referred to as mosaiced convolutions from the PFA demosaicing network (PFADN) [72]; these components have been shown to be effective for demosaicing the PFA raw camera images to obtain a full-resolution intensity image and AoLP.
- The image acquired via the PFA camera with the additional filter is merged with the recovery network output using the camera model presented in [15] to produce an HDR image. Note that this step is deterministic and not learning-based since it is a direct application of the theory presented in the previous section.
- Finally, the tone mapping network takes as input the computed HDR image and is designed to make the output perceptually similar to the ground truth.
4.1. Recovery Network
4.2. HDR Generation
4.3. Tone Mapping Network
5. Experimental Section
5.1. Dataset Acquisition
5.2. Training Procedure
5.3. Quantitative Analysis
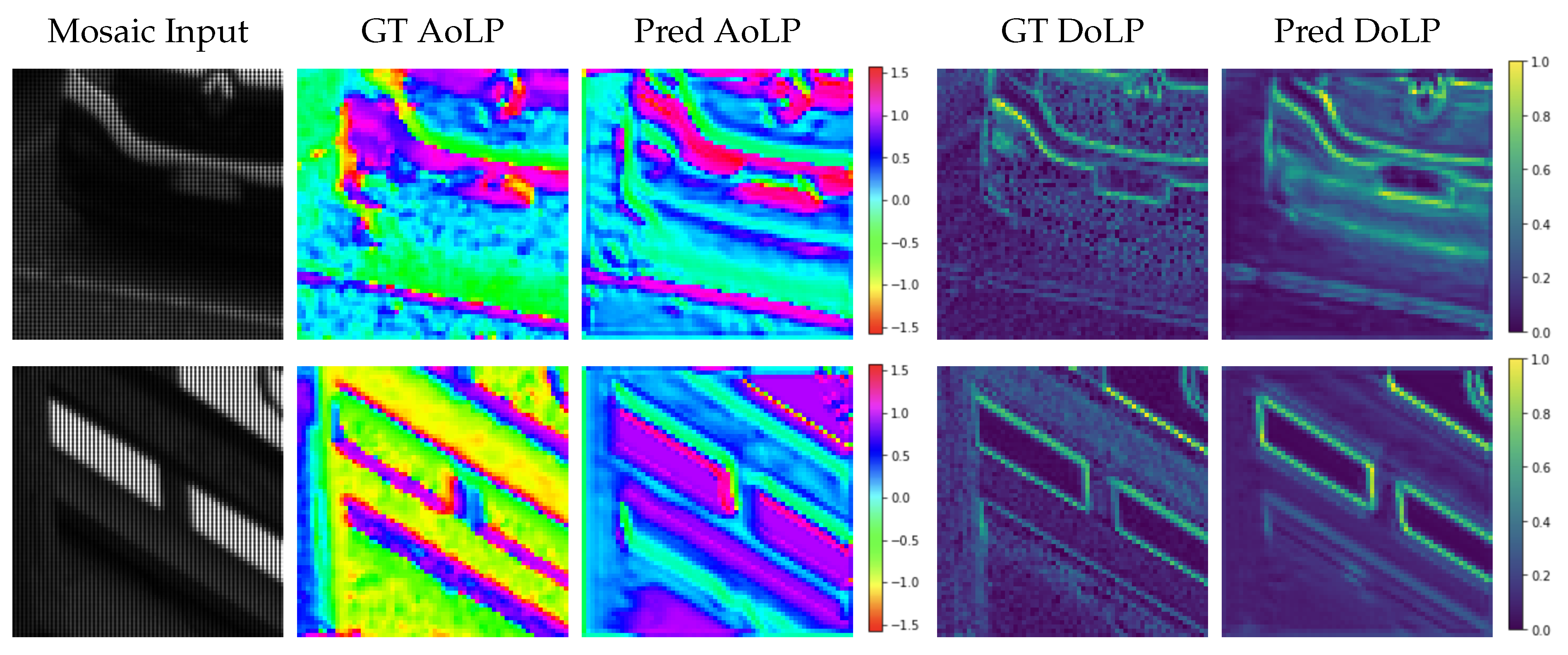
5.4. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure fusion: A simple and practical alternative to high dynamic range photography. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2009; Volume 28, pp. 161–171. [Google Scholar]
- Ladas, N.; Chrysanthou, Y.; Loscos, C. Improving tracking accuracy using illumination neutralization and high dynamic range imaging. In High Dynamic Range Video; Elsevier: Amsterdam, The Netherlands, 2017; pp. 203–213. [Google Scholar]
- Wu, X.; Zhang, H.; Hu, X.; Shakeri, M.; Fan, C.; Ting, J. HDR reconstruction based on the polarization camera. IEEE Robot. Autom. Lett. 2020, 5, 5113–5119. [Google Scholar] [CrossRef]
- Seger, U. Hdr imaging in automotive applications. In High Dynamic Range Video; Elsevier: Amsterdam, The Netherlands, 2016; pp. 477–498. [Google Scholar]
- Ramponi, G.; Badano, A.; Bonfiglio, S.; Albani, L.; Guarnieri, G. An Application of HDR in Medical Imaging. In High Dynamic Range Video; Elsevier: Amsterdam, The Netherlands, 2016; pp. 499–518. [Google Scholar]
- Wu, J.C.H.; Lin, G.S.; Hsu, H.T.; Liao, Y.P.; Liu, K.C.; Lie, W.N. Quality enhancement based on retinex and pseudo-HDR synthesis algorithms for endoscopic images. In Proceedings of the 2013 Visual Communications and Image Processing (VCIP), Kuching, Malaysia, 17–20 November 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Suh, H.K.; Hofstee, J.W.; Van Henten, E.J. Improved vegetation segmentation with ground shadow removal using an HDR camera. Precis. Agric. 2018, 19, 218–237. [Google Scholar] [CrossRef]
- Karr, B.; Chalmers, A.; Debattista, K. High dynamic range digital imaging of spacecraft. In High Dynamic Range Video; Elsevier: Amsterdam, The Netherlands, 2016; pp. 519–547. [Google Scholar]
- Khan, E.A.; Akyuz, A.O.; Reinhard, E. Ghost removal in high dynamic range images. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 2005–2008. [Google Scholar]
- Banterle, F.; Ledda, P.; Debattista, K.; Chalmers, A. Inverse tone mapping. In Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia, Kuala Lumpur, Malaysia, 29 November–2 December 2006; pp. 349–356. [Google Scholar]
- Marnerides, D.; Bashford-Rogers, T.; Hatchett, J.; Debattista, K. Expandnet: A deep convolutional neural network for high dynamic range expansion from low dynamic range content. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2018; Volume 37, pp. 37–49. [Google Scholar]
- Khan, Z.; Khanna, M.; Raman, S. Fhdr: Hdr image reconstruction from a single ldr image using feedback network. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019; pp. 1–5. [Google Scholar]
- Ting, J.; Wu, X.; Hu, K.; Zhang, H. Deep snapshot HDR reconstruction based on the polarization camera. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1769–1773. [Google Scholar]
- Ting, J.; Shakeri, M.; Zhang, H. Deep Polarimetric HDR Reconstruction. arXiv 2022, arXiv:2203.14190. [Google Scholar]
- Fatima, T.; Pistellato, M.; Torsello, A.; Bergamasco, F. One-Shot HDR Imaging via Stereo PFA Cameras. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 467–478. [Google Scholar]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Proceedings of the ACM SIGGRAPH 2008 Classes, Los Angeles, CA, USA, 11–15 August 2008; pp. 1–10. [Google Scholar]
- Lu, P.Y.; Huang, T.H.; Wu, M.S.; Cheng, Y.T.; Chuang, Y.Y. High dynamic range image reconstruction from hand-held cameras. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 509–516. [Google Scholar]
- Hasinoff, S.W.; Sharlet, D.; Geiss, R.; Adams, A.; Barron, J.T.; Kainz, F.; Chen, J.; Levoy, M. Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Trans. Graph. (ToG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Zhang, W.; Cham, W.K. Gradient-directed composition of multi-exposure images. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 530–536. [Google Scholar] [CrossRef]
- Sun, N.; Mansour, H.; Ward, R. HDR image construction from multi-exposed stereo LDR images. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, 26–29 September 2010; pp. 2973–2976. [Google Scholar] [CrossRef]
- Mann, S.; Picard, R. On being “undigital” with digital cameras: Extending dynamic range by combining differently exposed pictures. In Proceedings of the IS&T 48th Annual Conference Society for Imaging Science and Technology Annual Conference, Washington, DC, USA, 7–11 May 1995. [Google Scholar]
- Kirk, K.; Andersen, H.J. Noise Characterization of Weighting Schemes for Combination of Multiple Exposures. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006; Volume 3, pp. 1129–1138. [Google Scholar]
- Granados, M.; Ajdin, B.; Wand, M.; Theobalt, C.; Seidel, H.P.; Lensch, H.P. Optimal HDR reconstruction with linear digital cameras. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 215–222. [Google Scholar]
- Pistellato, M.; Cosmo, L.; Bergamasco, F.; Gasparetto, A.; Albarelli, A. Adaptive Albedo Compensation for Accurate Phase-Shift Coding. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2450–2455. [Google Scholar] [CrossRef]
- Umair, M.B.; Iqbal, Z.; Faraz, M.A.; Khan, M.A.; Zhang, Y.D.; Razmjooy, N.; Kadry, S. A Network Intrusion Detection System Using Hybrid Multilayer Deep Learning Model. In Big Data; Mary Ann Liebert, Inc.: New Rochelle, NY, USA, 2022. [Google Scholar]
- Huang, Q.; Ding, H.; Razmjooy, N. Optimal deep learning neural network using ISSA for diagnosing the oral cancer. Biomed. Signal Process. Control 2023, 84, 104749. [Google Scholar] [CrossRef]
- Gasparetto, A.; Ressi, D.; Bergamasco, F.; Pistellato, M.; Cosmo, L.; Boschetti, M.; Ursella, E.; Albarelli, A. Cross-Dataset Data Augmentation for Convolutional Neural Networks Training. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 910–915. [Google Scholar] [CrossRef]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Xu, H.; Ma, J.; Zhang, X.P. MEF-GAN: Multi-exposure image fusion via generative adversarial networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar] [CrossRef]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144. [Google Scholar] [CrossRef]
- KS, G.R.; Biswas, A.; Patel, M.S.; Prasad, B.P. Deep multi-stage learning for hdr with large object motions. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4714–4718. [Google Scholar]
- Yan, Q.; Gong, D.; Shi, Q.; Hengel, A.v.d.; Shen, C.; Reid, I.; Zhang, Y. Attention-guided network for ghost-free high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1751–1760. [Google Scholar]
- Pu, Z.; Guo, P.; Asif, M.S.; Ma, Z. Robust high dynamic range (hdr) imaging with complex motion and parallax. In Proceedings of the Asian Conference on Computer Vision, Virtual, 30 November–4 December 2020. [Google Scholar]
- Nazarczuk, M.; Catley-Chandar, S.; Leonardis, A.; Pellitero, E.P. Self-supervised HDR Imaging from Motion and Exposure Cues. arXiv 2022, arXiv:2203.12311. [Google Scholar]
- Catley-Chandar, S.; Tanay, T.; Vandroux, L.; Leonardis, A.; Slabaugh, G.; Pérez-Pellitero, E. FlexHDR: Modeling Alignment and Exposure Uncertainties for Flexible HDR Imaging. IEEE Trans. Image Process. 2022, 31, 5923–5935. [Google Scholar] [CrossRef]
- Nejati, M.; Karimi, M.; Soroushmehr, S.R.; Karimi, N.; Samavi, S.; Najarian, K. Fast exposure fusion using exposedness function. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2234–2238. [Google Scholar]
- Li, Z.; Wei, Z.; Wen, C.; Zheng, J. Detail-enhanced multi-scale exposure fusion. IEEE Trans. Image Process. 2017, 26, 1243–1252. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Zhu, H.; Fang, Y.; Wang, Z. Deep guided learning for fast multi-exposure image fusion. IEEE Trans. Image Process. 2019, 29, 2808–2819. [Google Scholar] [CrossRef] [PubMed]
- Lecouat, B.; Eboli, T.; Ponce, J.; Mairal, J. High dynamic range and super-resolution from raw image bursts. arXiv 2022, arXiv:2207.14671. [Google Scholar] [CrossRef]
- Shaw, R.; Catley-Chandar, S.; Leonardis, A.; Pérez-Pellitero, E. HDR Reconstruction from Bracketed Exposures and Events. arXiv 2022, arXiv:2203.14825. [Google Scholar]
- Yoon, H.; Uddin, S.N.; Jung, Y.J. Multi-Scale Attention-Guided Non-Local Network for HDR Image Reconstruction. Sensors 2022, 22, 7044. [Google Scholar] [CrossRef] [PubMed]
- Song, M.; Tao, D.; Chen, C.; Bu, J.; Luo, J.; Zhang, C. Probabilistic exposure fusion. IEEE Trans. Image Process. 2011, 21, 341–357. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.G.; Zheng, J.H.; Rahardja, S. Detail-enhanced exposure fusion. IEEE Trans. Image Process. 2012, 21, 4672–4676. [Google Scholar] [PubMed]
- Tico, M.; Gelfand, N.; Pulli, K. Motion-blur-free exposure fusion. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3321–3324. [Google Scholar]
- Zhang, W.; Cham, W.K. Reference-guided exposure fusion in dynamic scenes. J. Vis. Commun. Image Represent. 2012, 23, 467–475. [Google Scholar] [CrossRef]
- Kuo, P.H.; Tang, C.S.; Chien, S.Y. Content-adaptive inverse tone mapping. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar]
- Kovaleski, R.P.; Oliveira, M.M. High-quality brightness enhancement functions for real-time reverse tone mapping. Vis. Comput. 2009, 25, 539–547. [Google Scholar] [CrossRef]
- Kovaleski, R.P.; Oliveira, M.M. High-quality reverse tone mapping for a wide range of exposures. In Proceedings of the 2014 27th SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 26–30 August 2014; pp. 49–56. [Google Scholar]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR image reconstruction from a single exposure using deep CNNs. ACM Trans. Graph. (TOG) 2017, 36, 1–15. [Google Scholar] [CrossRef]
- Endo, Y.; Kanamori, Y.; Mitani, J. Deep reverse tone mapping. ACM Trans. Graph. 2017, 36, 177. [Google Scholar] [CrossRef]
- Kinoshita, Y.; Kiya, H. ITM-Net: Deep inverse tone mapping using novel loss function considering tone mapping operator. IEEE Access 2019, 7, 73555–73563. [Google Scholar] [CrossRef]
- Lee, M.J.; Rhee, C.h.; Lee, C.H. HSVNet: Reconstructing HDR Image from a Single Exposure LDR Image with CNN. Appl. Sci. 2022, 12, 2370. [Google Scholar] [CrossRef]
- Le, P.H.; Le, Q.; Nguyen, R.; Hua, B.S. Single-Image HDR Reconstruction by Multi-Exposure Generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4063–4072. [Google Scholar]
- Gharbi, M.; Chen, J.; Barron, J.T.; Hasinoff, S.W.; Durand, F. Deep bilateral learning for real-time image enhancement. ACM Trans. Graph. (TOG) 2017, 36, 1–12. [Google Scholar] [CrossRef]
- Moriwaki, K.; Yoshihashi, R.; Kawakami, R.; You, S.; Naemura, T. Hybrid loss for learning single-image-based HDR reconstruction. arXiv 2018, arXiv:1812.07134. [Google Scholar]
- Wu, G.; Song, R.; Zhang, M.; Li, X.; Rosin, P.L. LiTMNet: A deep CNN for efficient HDR image reconstruction from a single LDR image. Pattern Recognit. 2022, 127, 108620. [Google Scholar] [CrossRef]
- Cao, G.; Zhou, F.; Liu, K.; Wang, A.; Fan, L. A decoupled kernel prediction network guided by soft mask for single image HDR reconstruction. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–23. [Google Scholar] [CrossRef]
- Nayar, S.K.; Mitsunaga, T. High dynamic range imaging: Spatially varying pixel exposures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000, Hilton Head Island, SC, USA, 15 June 2000; Volume 1, pp. 472–479. [Google Scholar]
- Cho, H.; Kim, S.J.; Lee, S. Single-shot High Dynamic Range Imaging Using Coded Electronic Shutter. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2014; Volume 33, pp. 329–338. [Google Scholar]
- Gu, J.; Hitomi, Y.; Mitsunaga, T.; Nayar, S. Coded rolling shutter photography: Flexible space-time sampling. In Proceedings of the 2010 IEEE International Conference on Computational Photography (ICCP), Cambridge, MA, USA, 29–30 March 2010; pp. 1–8. [Google Scholar]
- Banterle, F.; Artusi, A.; Debattista, K.; Chalmers, A. Advanced High Dynamic Range Imaging; AK Peters/CRC Press: Wellesley, MA, USA, 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Collett, E. Field Guide to Polarization; SPIE: Bellingham, WA, USA, 2005. [Google Scholar]
- Ferraton, M.; Stolz, C.; Morel, O.; Meriaudeau, F. Quality control of transparent objects with polarization imaging. In Proceedings of the Eighth International Conference on Quality Control by Artificial Vision, 2007, Napoli, Italy, 29 May 2007; Volume 6356, pp. 54–61. [Google Scholar]
- Wolff, L.B. Polarization-based material classification from specular reflection. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 1059–1071. [Google Scholar] [CrossRef]
- Morel, O.; Meriaudeau, F.; Stolz, C.; Gorria, P. Polarization imaging applied to 3D reconstruction of specular metallic surfaces. In Proceedings of the Machine Vision Applications in Industrial Inspection XIII; SPIE: Napoli, Italy, 2005; Volume 5679, pp. 178–186. [Google Scholar]
- Pistellato, M.; Albarelli, A.; Bergamasco, F.; Torsello, A. Robust joint selection of camera orientations and feature projections over multiple views. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 3703–3708. [Google Scholar] [CrossRef]
- Pistellato, M.; Bergamasco, F.; Albarelli, A.; Torsello, A. Dynamic optimal path selection for 3D Triangulation with multiple cameras. In Proceedings of the Image Analysis and Processing—ICIAP 2015: 18th International Conference, Genova, Italy, 7–11 September 2015; Volume 9279, pp. 468–479. [Google Scholar] [CrossRef]
- Zappa, C.J.; Banner, M.L.; Schultz, H.; Corrada-Emmanuel, A.; Wolff, L.B.; Yalcin, J. Retrieval of short ocean wave slope using polarimetric imaging. Meas. Sci. Technol. 2008, 19, 055503. [Google Scholar] [CrossRef]
- Pistellato, M.; Bergamasco, F.; Torsello, A.; Barbariol, F.; Yoo, J.; Jeong, J.Y.; Benetazzo, A. A physics-driven CNN model for real-time sea waves 3D reconstruction. Remote Sens. 2021, 13, 3780. [Google Scholar] [CrossRef]
- Cronin, T.W.; Marshall, J. Patterns and properties of polarized light in air and water. Philos. Trans. R. Soc. B Biol. Sci. 2011, 366, 619–626. [Google Scholar] [CrossRef]
- Pistellato, M.; Bergamasco, F.; Fatima, T.; Torsello, A. Deep Demosaicing for Polarimetric Filter Array Cameras. IEEE Trans. Image Process. 2022, 31, 2017–2026. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Mitsunaga, T.; Nayar, S.K. Radiometric self calibration. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 1, pp. 374–380. [Google Scholar]
- Ba, Y.; Gilbert, A.; Wang, F.; Yang, J.; Chen, R.; Wang, Y.; Yan, L.; Shi, B.; Kadambi, A. Deep shape from polarization. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 554–571. [Google Scholar]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, San Antonio, TX, USA, 23–26 July 2002; pp. 267–276. [Google Scholar]
- A Sharif, S.M.; Naqvi, R.A.; Biswas, M.; Kim, S. A two-stage deep network for high dynamic range image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 550–559. [Google Scholar]
- Santos, M.S.; Ren, T.I.; Kalantari, N.K. Single image HDR reconstruction using a CNN with masked features and perceptual loss. arXiv 2020, arXiv:2005.07335. [Google Scholar] [CrossRef]
- Reinhard, E.; Heidrich, W.; Debevec, P.; Pattanaik, S.; Ward, G.; Myszkowski, K. High Dynamic Range Imaging: Acquisition, Display, and Image-Based Lighting; Morgan Kaufmann: San Francisco, CA, USA, 2010. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR (dB) | MS-SSIM |
|---|---|---|
| Ours | 23.0670 ± 2.1362 | 0.9756 ± 0.0145 |
| Ours w/o TMnet | 20.5114 ± 3.7150 | 0.9741 ± 0.0121 |
| Wu et al. [3] | 18.9489 ± 4.1196 | 0.9706 ± 0.0188 |
| KO [48] | 12.9069 ± 1.6990 | 0.5067 ± 0.1880 |
| DPHDR [13] | 12.5211 ± 2.4826 | 0.6465 ± 0.0786 |
| Two-stage HDR [78] | 19.5877 ± 3.1949 | 0.9658 ± 0.0230 |
| Deep-HDR [79] | 16.6983 ± 1.8659 | 0.7840 ± 0.1401 |
| ExpandNet [11] | 14.6473 ± 2.5156 | 0.8113 ± 0.0788 |
| HDRCNN [49] | 14.8472 ± 2.8604 | 0.7202 ± 0.1661 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pistellato, M.; Fatima, T.; Wimmer, M. Exploiting Light Polarization for Deep HDR Imaging from a Single Exposure. Sensors 2023, 23, 5370. https://doi.org/10.3390/s23125370
Pistellato M, Fatima T, Wimmer M. Exploiting Light Polarization for Deep HDR Imaging from a Single Exposure. Sensors. 2023; 23(12):5370. https://doi.org/10.3390/s23125370
Chicago/Turabian StylePistellato, Mara, Tehreem Fatima, and Michael Wimmer. 2023. "Exploiting Light Polarization for Deep HDR Imaging from a Single Exposure" Sensors 23, no. 12: 5370. https://doi.org/10.3390/s23125370
APA StylePistellato, M., Fatima, T., & Wimmer, M. (2023). Exploiting Light Polarization for Deep HDR Imaging from a Single Exposure. Sensors, 23(12), 5370. https://doi.org/10.3390/s23125370