1. Introduction
Durian (
Durio zibethinus) is a tropical fruit grown in Southeast Asia and is highly appreciated by consumers throughout Asia [
1]. Thailand is the leading exporter of durian fruit in terms of volume and exports them to different countries [
2]. The exports of Thai durian have been consistently growing each year [
3]. There are three main varieties of durian, namely Monthong, Chanee, and Kanyao. Among these three varieties of durian, Monthong is the most well-known exported variety of durian [
4].
Dry matter content (DMC) and soluble solid content (SSC) are two major parameters used in the evaluation of the quality of durian pulp. The DMC is an indication of the fruit’s maturity [
5], and the SSC is an indication of its ripeness [
6]. Durian fruit at different stages of maturity have different sensory qualities. When the fruit become mature, they start to ripen. When the immature durian is ripe, it has a reduced flavor and taste, while, if it is overripe, it will decay rapidly after harvest. When fruit growth starts to slow down, the formation of sugars, starch, lipids, DMC, and carbohydrates takes place. The DMC of durian is mainly due to the accumulation of starch, while the SSC is created by reducing and non-reducing sugars [
7]. The maturity and the DMC and SSC of durian pulp show a linear relationship; when the maturity increases, the DMC and SSC increase [
8].
The measurement of these parameters is very important for commercial purposes. The price of durian varies according to these two parameters. In addition, the classification of durian on the basis of these two parameters is essential for commercial purposes because it allows them to be classified into different groups on the basis of these parameters, as they represent the quality of the fruit. The traditional method of measuring these two parameters is destructive, so it cannot be used for commercial purposes. According to the Thai Agricultural Standard (TAS) 3-2013, the harvesting time of Monthong durian fruit is between 105 and 110 days after anthesis (DAA) [
9]. Fruits harvested at different DAA have different maturity levels, which is directly related to the quality of the fruit. Traditionally, durian maturity is assessed using a combination of methods, such as counting the DAA, evaluating the sound of the pitch after tapping, checking the stem flexibility, and observing the spike tip color [
10,
11]. However, these traditional methods of classification have several limitations that make them unsuitable for modern durian production. One major issue is the subjective nature of the classification, which relies on the experience and judgement of individual classifiers, leading to inconsistent classifications. This subjectivity can be influenced by various factors, such as personal biases, environmental conditions, and cultural preferences, which can compromise the accuracy of classification. Furthermore, the traditional methods can be time-consuming and labor-intensive as they require a close examination of each fruit, which is problematic for large-scale durian production, where time and efficiency are critical. This can result in delays and inefficiencies that impact the overall productivity and profitability of durian production.
Recently, research has been conducted on the topic of improving the non-destructive maturity classification model for durian fruit using near-infrared spectroscopy. Authors have investigated the use of near-infrared spectroscopy (NIRS) and machine learning algorithms to improve the non-destructive maturity classification of durian fruit. In a study, two NIRS spectrometers were used to scan durian fruit at different maturity stages, and three supervised machine learning algorithms were tested. The results showed that the use of both rind and stem spectra provided the greatest efficiency, with the LDA model exhibiting the highest accuracy (training accuracy = 97.28%, test accuracy = 96.25%). The authors suggested that NIR spectroscopy has the potential to be used for the non-destructive estimation of durian maturity and could be used for quality control in the durian export industry [
12].
Due to its real-time monitoring capability, cost-effectiveness, and time efficiency, the inline measurement of fruit constituents and classification using NIR spectra has gained significance. Extensive research has been conducted on the measurement of fruit properties and classifying fruit based on such properties. A Vis–SWNIR spectrometer was integrated into a conveyor system to measure the inline DMC and SSC of durian pulp [
6]. The spectra of the samples were acquired in two orientations, scanning upright pulps from 2018 and stable pulps from 2019, and the optimal model showed
values of 0.88 for DMC calibration, 0.83 for DMC prediction, 0.70 for SSC calibration, and 0.70 for SSC prediction, with an RMSEP of 4.32% and 4.0%, respectively, and a RPIQ of 3.52 for DMC and 2.2 for SSC prediction [
6]. Several other studies have explored the application of the inline measurement of NIR spectra for the analysis of different fruit, such as apple, orange, pear, strawberry, and mango, including the classification and prediction of specific constituents [
13,
14,
15,
16,
17]. The results obtained from these studies provide clear evidence that the utilization of the inline measurement of NIR spectra is effective in achieving accurate classification and the precise prediction of specific constituents.
In the study titled “Hyperspectral Images-Based Crop Classification Scheme for Agricultural Remote Sensing”, a pixel-based approach utilizing Principal Component Analysis-Based Edge-Preserving Features (PCA-EPF) and an SVM classifier was introduced. This approach successfully improved the crop classification accuracy in hyperspectral remote sensing, achieving results of over 90% in the performance metrics measured across nine different crop types [
18].
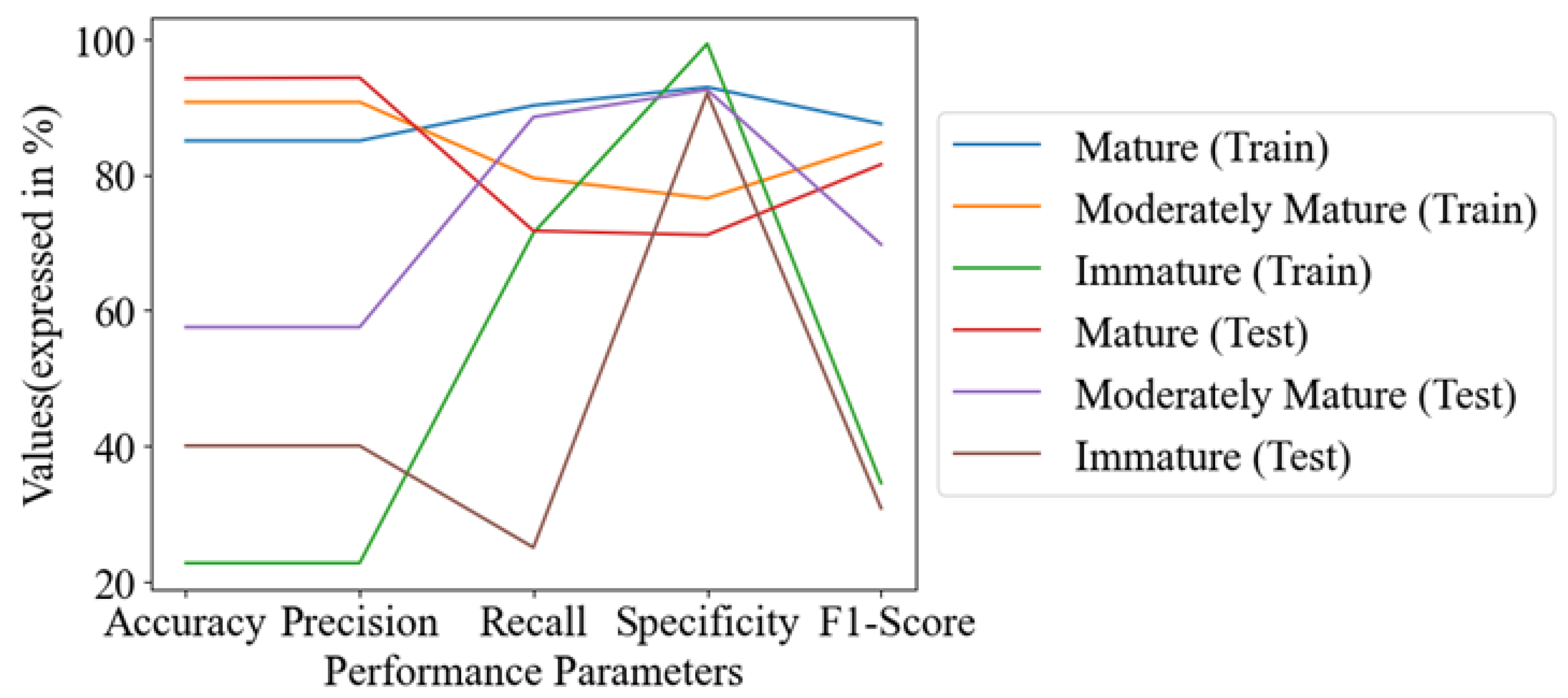
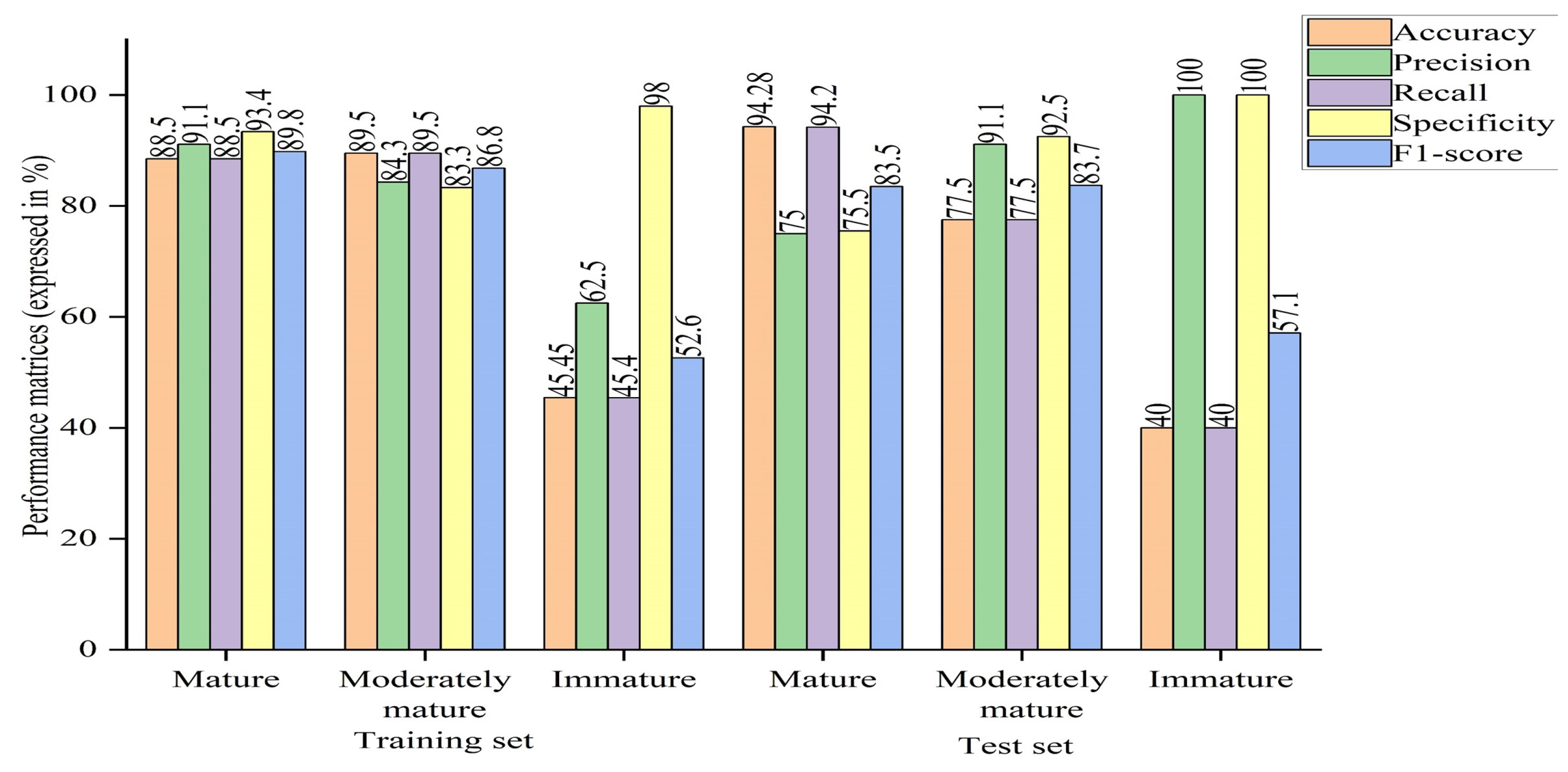
Previous research presented promising results in determining the quality parameters (DMC and SSC) of durian pulp through inline measurement. This study aimed to classify durian pulp based on DMC and SSC into three classes (mature, moderately mature, and immature) in real time, using an inline spectrometer and a conveyor system for efficient and accurate results. The models were built using five spectral preprocessing techniques: Savitzky–Golay and Standard Normal Variate (SG+SNV), Moving Average and Standard Normal Variate (MA+SNV), Savitzky–Golay and Mean Normalization (SG+MN), Savitzky–Golay and Baseline Correction (SG+BC), and Savitzky–Golay and Multiplicative Scatter Correction (SG+MSC). Both PLSDA and optimizable machine learning algorithms were applied in the Classification Learner app of MATLAB, including neural networks, ensembles, k-nearest neighbors, support vector machines, Naive Bayes, discriminants, and trees. The classification results from each algorithm were compared. This model can accurately classify durian into different maturity stages, ensuring consistent quality and reducing the risk of selling underripe or overripe fruit. Additionally, it helps to increase the production capacity, meet the market demand, and expand durian businesses.
Partial Least Squares (PLS) was originally developed as a latent variable modeling technique, primarily used for linear regression analysis [
19]. PLS was later extended to include PLS Discriminant Analysis (PLS-DA) for classification purposes [
20], which is capable of analyzing small sample sizes and handling multicollinearity in data, particularly in cases such as chemical spectroscopy data. These types of data are often high-dimensional and exhibit strong correlations among neighboring independent variables. PLS addresses the issue of high-dimensional data by employing latent projections before modeling, thereby mitigating the challenges associated with the curse of dimensionality [
21]. PLSDA has limitations with regard to effectively capturing and modeling complex data and nonlinear relationships [
22,
23]. Machine learning has attracted extensive interest due to its capability to effectively model complex nonlinear data patterns [
24,
25,
26]. Numerous studies have been conducted comparing PLSDA with machine learning algorithms for classification tasks [
27,
28,
29,
30]. In the majority of these studies, machine learning algorithms have demonstrated superior performance compared to PLSDA.
The objective of this research is to identify and select machine learning algorithms that outperform others. The method is compared with the PLSDA algorithm in terms of performance parameters such as accuracy, precision, recall, specificity, F1-score, area under the receiver operating curve, kappa, and Matthews correlation coefficient. By evaluating and comparing these performance measures, this study aims to determine the most effective algorithm for the classification of durian pulp. Furthermore, another objective is to explore the feasibility of classifying durian pulp based on DMC and SSC using inline measurement. By investigating this possibility, the study aims to contribute the knowledge of durian pulp classification techniques, particularly in the context of inline measurement. The findings of this research can potentially be utilized to auto-grade durian pulp into three stages of maturity: mature, moderately mature, and immature.
2. Materials and Methods
2.1. Sampling
The study utilized a total of 415 Monthong durian pulp samples, which were sourced from a factory and subsequently sent to the NIRS Research Center for Agricultural Products and Food within the Department of Agricultural Engineering, School of Engineering, King Mongkut’s Institute of Technology Ladkrabang. Four distinct experiments were conducted on these samples, with data collection taking place on 31 May 2021, 16 August 2021, 31 August 2021, 15 October 2021, and 15–16 June 2022. The samples were collected at 110 DAA and were visually classified by experienced gardeners, based on their levels of maturity. The classification system used in this study consisted of three levels of maturity, designated as A, B, and C, and three stages of ripening, designated as 1, 2, and 3. Specifically, “A” corresponded to full maturity, “B” corresponded to moderate maturity, and “C” corresponded to immature samples. Additionally, “1” corresponded to full ripening, “2” corresponded to moderate ripening, and “3” corresponded to unripe samples. Prior to transportation to the laboratory, the samples were prepared overnight and packaged in food-grade plastic to reduce moisture loss. Spectral data were collected at the NIR Spectroscopy Research Center for Agricultural Products and Food within the Department of Agricultural Engineering at King Mongkut’s Institute of Technology Ladkrabang in Bangkok, Thailand, where the ambient temperature was approximately 25 ± 2 °C in the morning. The samples were also measured for DMC and SSC after scanning.
Figure 1 illustrates the flowchart representing the classification modeling process used in this study.
2.2. Inline NIR Scanning
The inline near-infrared (NIR) scanning process involved collecting spectra through inline measurement using an AvaSpec-2048-USB2 standard fiber-optic spectrometer (Avantes, Apeldoorn, The Netherlands) with a wavelength range of 300–1160 nm and a spectral resolution of 2.4 nm. The optical bench utilized a 75 mm focal length and the detector used was a CCD linear array with 2048 pixels. The AD converter had a 16-bit length with a 2 MHz sampling frequency and a sample speed with onboard averaging of 1.1 ms/scan. The light source was an Ava Light-HAL Standard 10 W tungsten halogen lamp, and a compact stabilized halogen fan-cooled light source was used in the visible and NIR range, having a wavelength range of 350–2500 nm. A fiber-optic reflection probe (FCR7IR200-2-BX) consisting of seven fibers with a 200 µm core, six light fibers, and one read fiber in two separate legs enclosed in a silicon inner tube was used, as well as a flexible stainless-steel connector with an SMA connected to the light source and spectrometer to obtain the spectral information of the sample. Each pulp was kept in an upright position in a black plastic tray for stability and placed on a chain conveyor with a speed of 0.17 m/s. The tray speed was adjusted using a speed controller unit with power of 60 watts. To sort the trays according to the grade of the pulp, an oil-free air compressor was used, with a maximum pressure of 0.8 MPa and a fan speed of 1480 r/min. The light source was activated 15–30 min before collecting the white and dark spectra, to allow it to warm up. To correct for the influence of the unstable intensity of the light source on the spectra and to eliminate the background noise within the detector, the Teflon reference material spectrum, or a white reference, was acquired. To obtain the dark and reference scans in one run, the time required for the detector to capture the radiation, also known as the integration time, was set at 4.5 ms, such that the maximum value of reflectance from the reference material (Teflon) was taken over the wavelength range of around 90 of the full analog-to-digital converter (ADC) scale. The optimum focal distance, i.e., the distance between the sensor and the sample surface, was approximately 2.5 cm. However, as the sample size varied, the focal length was altered. As the sample approached the black box, the proximity sensor was placed along the same vertical plane, and when the sample reached the sensor boundary in the black box, consisting of the spectrometer and light source, the sensor sent a signal to the spectrometer to start scanning as shown in
Figure 2. Each spectrum was obtained from an average of 200 scans throughout the longitudinal top surface of the durian pulp.
2.3. Reference Analysis
2.3.1. Soluble Solid Content (SSC) Measurement
After the completion of inline near-infrared (NIR) spectra collection, the SSC of the samples was determined using a refractometer (PAL-1, S/No L218454, Atago, Tokyo, Japan) with the technical specifications listed in
Table 1.
The SSC of each sample was measured in longitudinal sections throughout the scanning area, with the measurements reported in terms of percent Brix. To ensure accurate results, the refractometer was cleaned with distilled water prior to each measurement. Three measurements were taken at the head, middle, and bottom positions of each durian sample, and the refractometer was cleaned with distilled water and dried with tissue paper after each measurement. The average SSC value was then calculated from the measurements taken at the head, middle, and bottom sections of each durian sample.
2.3.2. Dry Matter Content (DMC) Measurement
The dry matter content (DMC) of the pulp samples was determined by homogenizing a portion of the scanned pulp that had undergone soluble solid content (SSC) measurement. The homogenized samples were then placed in aluminum moisture cans with a 5 cm diameter and 3 cm height. Approximately 5 g of the durian sample was taken and placed in the aluminum moisture can. The initial weight of the sample was determined using a high-precision electronic balance (Mettler Toledo Model- JS1203C, Columbus, OH, USA). The samples were then placed in a controlled-environment oven (Memmert GmbH, Model-30-1060, Schwabach, Germany). The temperature of the oven was set at 60 °C for 24 h. The weight of the sample was measured at 3 h intervals until a constant weight was obtained. The DMC of the sample was calculated by subtracting the moisture content, determined by the weight loss during the drying process, from the initial weight of the sample and reported as a percentage of the sample’s dry weight (% wb).
2.4. Separation into Classes Using Classification Criteria
The durian pulps were separated into three classes, namely mature, moderately mature, and immature, based on the classification criteria established by the Durian Meat Export Company. These criteria were determined from the DMC and TSS values, as outlined in
Table 2. As discussed earlier, the samples were evaluated using an electronic balance (Mettler Toledo Model JS1203C) and refractometer (Atago PAL-1, Japan) to determine their DMC and TSS values, respectively. The classification criteria were applied by comparing the measured DMC and SSC values of the samples against the established standards. The samples that met the established standards for DMC and SSC were classified as mature, moderately mature, or immature accordingly.
2.5. Dataset Information
The dataset used in this study consists of near-infrared (NIR) spectra obtained from a spectrometer, along with reference values for dry matter content (DMC) and total soluble solids (TSS), obtained using an electronic balance and refractometer, respectively. The data were transferred to Microsoft Excel for further analysis.
Data Structure in the Excel Spreadsheet: The first row contains the titles “DMC” and “SSC” in the first and second columns, respectively. The third column represents the categorical variable showing the group to which each sample belongs. Starting from the fourth column, each column corresponds to a wavelength ranging from 450 nm to 1000 nm. Each subsequent row, from the second row to the 416th row, represents a sample, where the first column contains the DMC value for the respective sample, the second column contains the TSS value for the respective sample, the third column represents the categorical variable for the respective sample, and the remaining columns contain the absorbance values of the NIR spectra for each sample at their respective wavelengths.
2.6. Different Algorithms for Classification
2.6.1. Partial Least Squares Discriminant Analysis
Partial Least Squares Discriminant Analysis (PLS-DA) is a supervised classification algorithm that uses the PLS regression method and linear discriminate method to discriminate a dataset into different classes [
31]. PLS establishes the relationship between the predictor variables and response variables using a reduced number of latent variables. Latent variables maximize the covariance between predictor variables and response variables. Then, LDA takes the latent variable as the input to make class predictions. For binary classification, PLS1 is used, where the response variable is either 0 or 1, depending on whether it belongs to the given class or not [
32,
33]. For the PLS2 method, if there are G number of classes and N number of samples, then we set the response variable as (N × G) with a dummy variable [
34,
35]. There are several PLS-DA methods used for different purposes. They include Standard PLS-DA, Orthogonal Partial Least Squares Discriminant Analysis (OPLS), Sequential Inner–Outer Model PLS Discriminant Analysis (SIMPLS-DA), Robust Partial Least Square Discriminant Analysis (Robust PLS-DA), and Multivariate Curve Resolution–Partial Least Squares Discriminant Analysis (MCR-PLS-DA). The mathematical steps needed to perform PLSDA can be summarized as follows. First, the partial least squares regression method is used to identify the set of latent variables (LVs) that explain the maximum amount of variation in both
X and
Y. The mathematical expression for PLS regression can be represented as
where
T is a matrix of
X scores,
P is a matrix of
X loadings,
U is a matrix of
Y scores,
Q is a matrix of
Y loadings,
E is a matrix of
X residuals, and
F is a matrix of
Y residuals. The
LVs are extracted from the PLS regression model by multiplying
X by the normalized loading matrix
.
The extracted
LVs are then used as input to a linear discriminant analysis (LDA) model, which separates the samples into different classes based on their class membership. The mathematical expression for LDA can be represented as
where
is the predicted class membership,
is the weight vector and is obtained by constrained optimization, and
B is the bias term.
2.6.2. Artificial Neural Network (ANN)
Artificial neural networks are a specific type of machine learning algorithm that are inspired by the structure and function of the human brain [
36,
37,
38,
39]. The human nervous system can learn from the past, and, in a similar way, ANNs are able to learn from the data and provide responses in the form of predictions or classifications. An ANN consists of an input layer, output layer, and hidden layer. The purpose of the input layer is to receive the input data, the hidden layer processes the input data, and the output layer computes the final prediction. The number of neurons in the input nodes is equal to the number of explanatory variables in the input data. Each neuron in the input layer corresponds to the explanatory variable. It does not perform any computation; it passes the input data to another layer. The value of each neuron is set to the corresponding value of each explanatory variable in the input data. There may be one or more hidden layers located between the input layer and output layer. Each neuron in the hidden layer receives input from the neurons in the previous layer, processes it using a nonlinear activation function, and sends it to the neurons in the next layer. Values entered in hidden node are multiplied by weights, and then weighted inputs are summed to produce a single number [
40,
41]. Increasing the number of hidden layers and the number of neurons in the hidden layer increases the performance of the model. However, too many hidden layers and neurons in the hidden layer may cause overfitting, where the model shows good performance with training data and poor performance with new data. The different activation functions used include Sigmoid, Rectified Linear Unit (ReLU), hyperbolic tangent (Tanh), Leaky ReLU, Exponential Linear Unit ELU), and Softmax. ReLU is a commonly used activation function [
42,
43]. The output layer is the final layer of the artificial neural network (ANN) and computes the final prediction. In supervised learning, the output layer has one neuron for each class, while, in regression, it has one neuron. The activation function used for classification in the output layer is Softmax, and, for regression, the linear activation function is used. A wide neural network consists of only one hidden layer with a large number of neurons in a single layer. In deep neural networks, there are multiple hidden layers. The mathematical computation inside hidden layers can be summarized as the output of the activation function in the hidden layer:
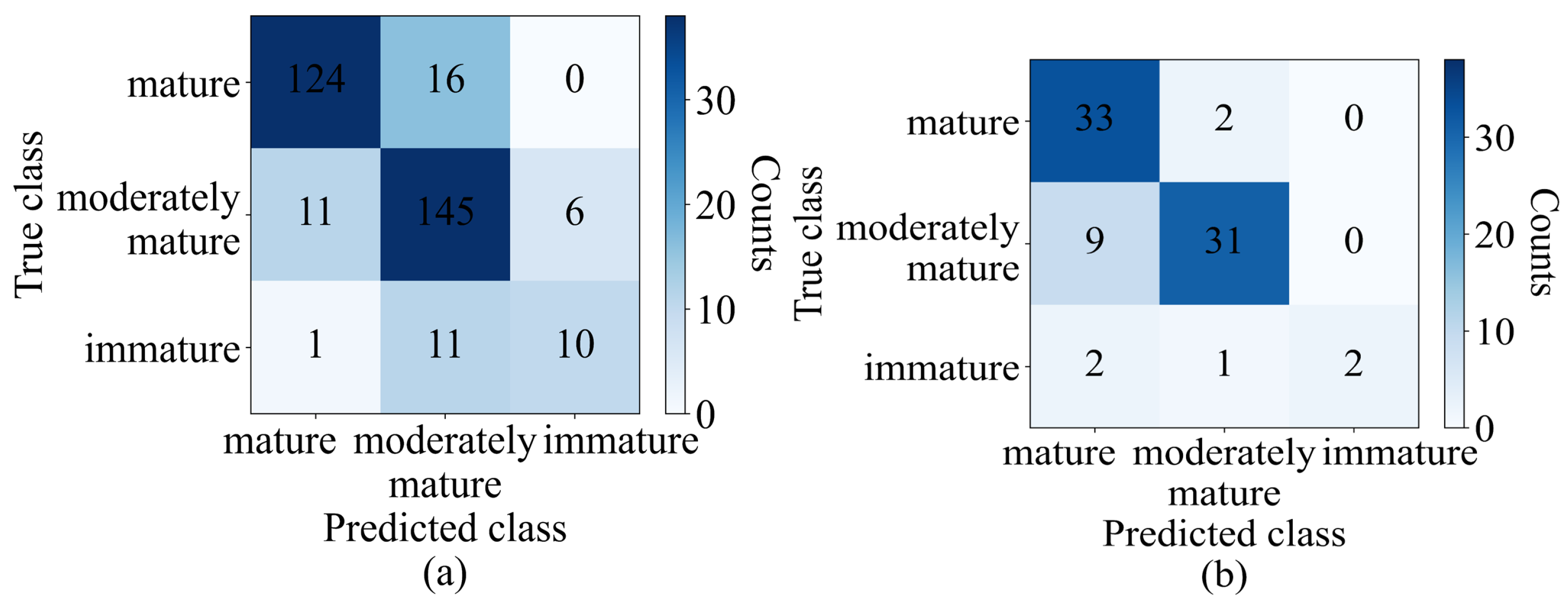
The model identified the hyperparameter where the model was optimized. Then, the model was trained on the optimized hyperparameter. The results of the trained model were obtained, and then the model was tested to evaluate its performance on a new dataset. Results from the application were obtained in terms of confusion matrices and the receiver operating curve (shown in
Table 3).
2.7. Software Used for Classification
The classification modeling was performed using a licensed MATLAB R2021b version from MathWorks [
44], obtained through KMITL. The machine learning algorithm employed for this purpose was run using the Classification Learner, a built-in application in MATLAB. Additionally, Partial Least Squares Discriminant Analysis (PLS-DA) was performed using the PLS-Toolbox from Eigenvector Research Incorporated [
45].
2.8. Classification Modeling
After acquiring spectral data, DMC, and SSC from an experiment, they were then transferred to an Excel file. The samples were then sorted into different classes, with a total of 415 durian samples being analyzed. Outliers were identified using Q residuals reduced and Hotelling’s T-squared reduced plots at a significance level of
p = 0.950. Samples outside the boundary line (critical value) were considered outliers, with 11 samples being identified as such. The remaining 404 samples were used for modeling, with the data being imbalanced in terms of the distribution of samples among the mature (43.31%), moderately mature (50%), and immature (6.68%) classes. Due to the low number of samples belonging to the immature category, our dataset is imbalanced, which may negatively impact the performance of model developed from these data, as the model may struggle to correctly classify samples in the under-populated immature category as it does not have sufficient data to learn from. The samples were divided into an 80% training set and a 20% test set via the holdout method, with 324 and 80 samples being used in each set, respectively. Classification was performed using the PLSDA algorithm, which was implemented using Version 9.1 of the PLS-Toolbox and Solo in MATLAB. Additionally, machine learning algorithms were employed, with the Classification Learner application being used to build the model. A five-fold cross-validation technique was employed in both PLSDA and machine learning, with the sample being divided into five subsets or folds. In this cross-validation procedure, each subset was utilized as a validation set once, while the remaining four subsets served as the calibration set. This process was repeated five times, with different subsets being used for evaluation each time, and the results were averaged to estimate the model’s performance. The dataset was trained using seven different optimizable machine learning algorithms, namely optimizable neural networks, optimizable ensembles, optimizable k-nearest neighbors, optimizable support vector machines, optimizable Naive Bayes, optimizable discriminants, and optimizable trees. Each optimizable algorithm searched for the optimal hyperparameters within a specified range, and the hyperparameters that resulted in the best performance of the model were selected.
Table 4 presents the search ranges of the hyperparameters used by each algorithm.







 and
and 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}