

Fine-Tuned Temporal Dense Sampling with 1D Convolutional Neural Network for Human Action Recognition


Abstract
1. Introduction
- A fine-tuned temporal dense sampling strategy that captures the significant spatial information and long-term dynamics of the human action video in a fixed-length representation.
- A single-stream 1DConvNet with FTDS that effectively represents the spatial information and temporal information of the human action video. In addition, FTDS-1DConvNet also reduces the possible temporal information loss of single-stream RGB-based ConvNet methods and the high computational requirements of LSTM methods.
2. Related Work
2.1. Hand-Crafted Methods
2.2. Representation Learning Methods
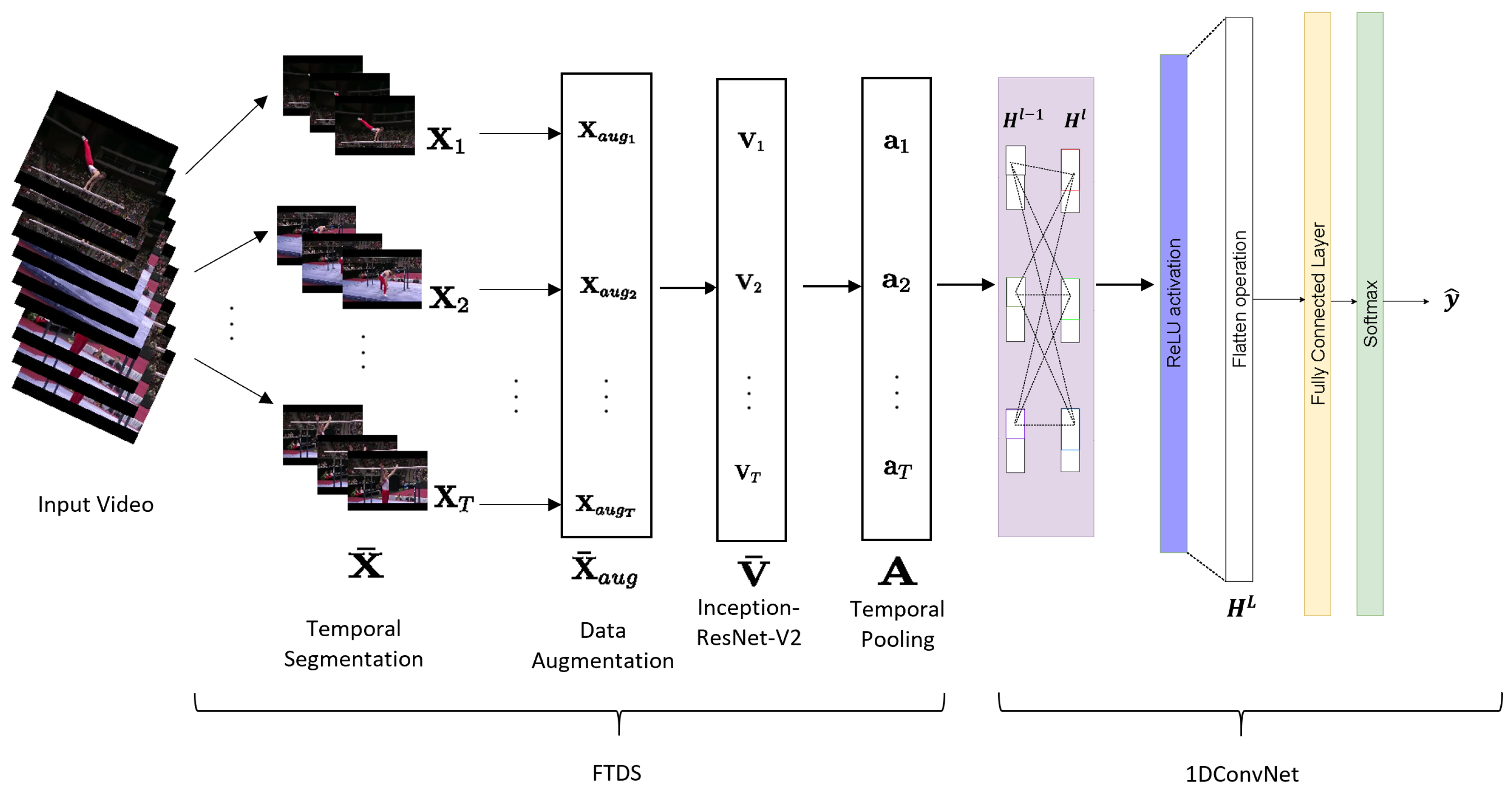
3. Fine-Tuned Temporal Dense Sampling with 1D Convolutional Neural Network (FTDS-1DConvNet)
3.1. Preprocessing with Temporal Segmentation and Data Augmentation
3.2. Transfer Learning with Inception-ResNet-V2
3.3. 1D Convolutional Neural Network (1DConvNet)
| Algorithm 1 Training in the proposed FTDS-1DConvNet Framework |
|
4. Experiments and Analysis
4.1. Datasets
4.2. Experimental Settings
4.3. Experimental Results
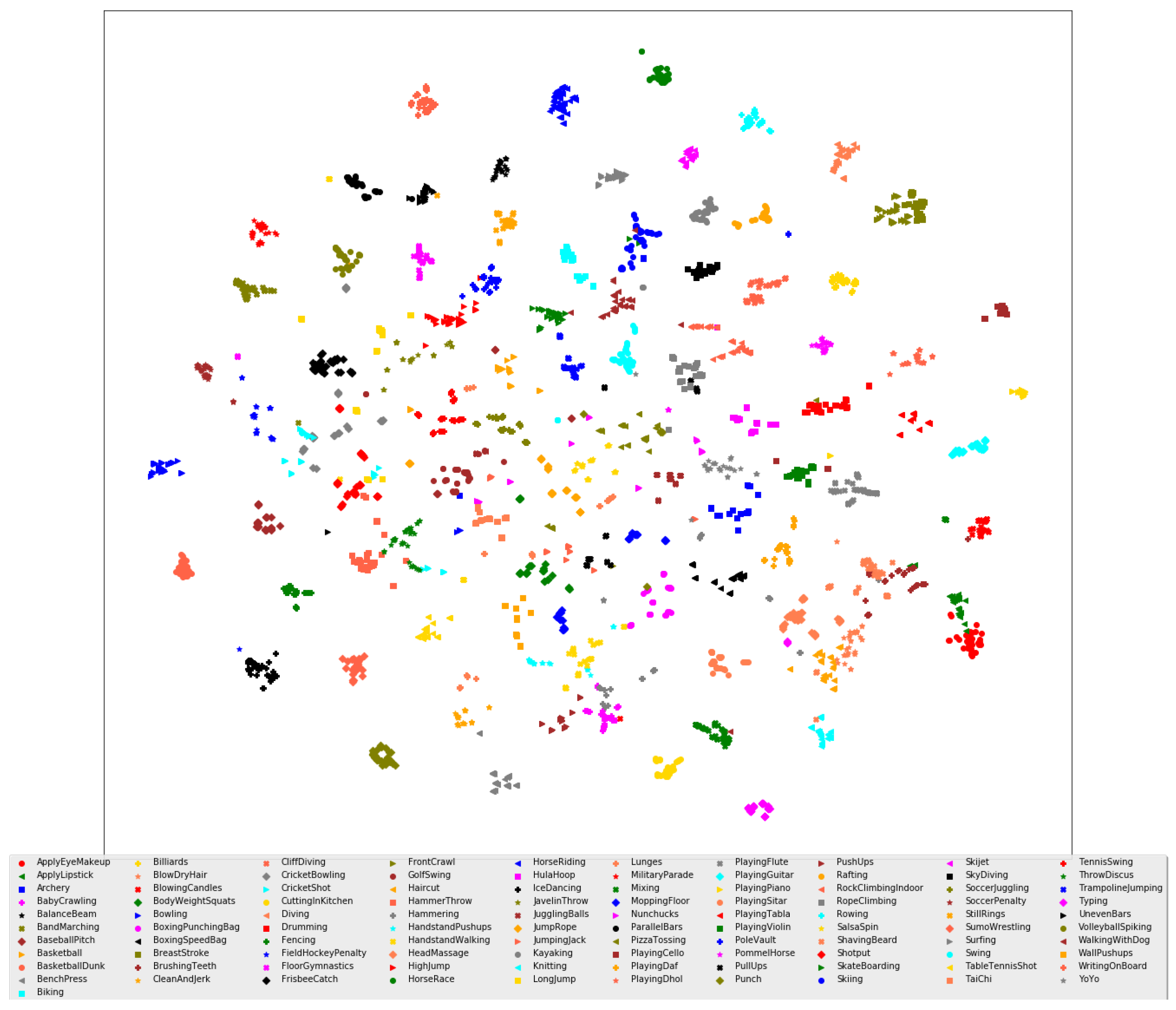
4.4. Visualization of the Proposed FTDS-1DConvNet
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Kim, W.; Lee, J.; Kim, M.; Oh, D.; Kim, C. Human action recognition using ordinal measure of accumulated motion. EURASIP J. Adv. Signal Process. 2010, 2010, 219190. [Google Scholar] [CrossRef]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402. [Google Scholar]
- Gorelick, L.; Galun, M.; Sharon, E.; Basri, R.; Brandt, A. Shape Representation and Classification Using the Poisson Equation. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 61–67. [Google Scholar]
- Yilmaz, A.; Shah, M. Actions sketch: A novel action representation. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 984–989. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Klaeser, A.; Marszalek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of the British Machine Vision Conference, Leeds, UK, 1–4 September 2008; BMVA Press: Durham, UK, 2008; pp. 99.1–99.10. [Google Scholar] [CrossRef]
- Oneata, D.; Verbeek, J.; Schmid, C. Action and event recognition with fisher vectors on a compact feature set. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1817–1824. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Peng, X.; Wang, L.; Wang, X.; Qiao, Y. Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. Comput. Vis. Image Underst. 2016, 150, 109–125. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Shi, Y.; Tian, Y.; Wang, Y.; Huang, T. Joint Network based Attention for Action Recognition. arXiv 2016, arXiv:1611.05215. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 23–27 October 2016; pp. 20–36. [Google Scholar]
- Ma, C.Y.; Chen, M.H.; Kira, Z.; AlRegib, G. TS-LSTM and Temporal-Inception: Exploiting Spatiotemporal Dynamics for Activity Recognition. arXiv 2017, arXiv:1703.10667. [Google Scholar] [CrossRef]
- Pan, B.; Sun, J.; Lin, W.; Wang, L.; Lin, W. Cross-Stream Selective Networks for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tan, K.S.; Lim, K.M.; Lee, C.P.; Kwek, L.C. Bidirectional Long Short-Term Memory with Temporal Dense Sampling for human action recognition. Expert Syst. Appl. 2022, 210, 118484. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhu, C.; Li, X.; Li, J.; Ding, G.; Tong, W. Spatial-temporal knowledge integration: Robust self-supervised facial landmark tracking. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4135–4143. [Google Scholar]
- He, D.; Zhou, Z.; Gan, C.; Li, F.; Liu, X.; Li, Y.; Wang, L.; Wen, S. Stnet: Local and global spatial-temporal modeling for action recognition. In Proceedings of the AAAI Conference On Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8401–8408. [Google Scholar]
- Yao, H.; Tang, X.; Wei, H.; Zheng, G.; Li, Z. Revisiting spatial-temporal similarity: A deep learning framework for traffic prediction. In Proceedings of the AAAI Conference On Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5668–5675. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards Good Practices for Very Deep Two-Stream ConvNets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Yifan, W.; Jie, S.; Limin, W.; Luc Van, G.; Otmar, H. Two-Stream SR-CNNs for Action Recognition in Videos. In Proceedings of the British Machine Vision Conference; Richard, C., Wilson, E.R.H., Smith, W.A.P., Eds.; BMVA Press: Durham, UK, 2016; pp. 108.1–108.12. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Residual Networks for Video Action Recognition. arXiv 2016, arXiv:1611.02155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Banjarey, K.; Sahu, S.P.; Dewangan, D.K. Human activity recognition using 1D convolutional neural network. In Proceedings of the Sentimental Analysis and Deep Learning: Proceedings of ICSADL 2021, Songkhla, Thailand, 18–19 June 2021; pp. 691–702. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human action classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Stiefelhagen, R.; Serre, T. HMDB51: A large video database for human motion recognition. In High Performance Computing in Science and Engineering ‘12; Springer: Berlin/Heidelberg, Germany, 2013; pp. 571–582. [Google Scholar]
- Ranasinghe, K.; Naseer, M.; Khan, S.; Khan, F.S.; Ryoo, M.S. Self-supervised video transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2874–2884. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Wang, X.; Farhadi, A.; Gupta, A. Actions~transformations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2658–2667. [Google Scholar]
- Girdhar, R.; Ramanan, D.; Gupta, A.; Sivic, J.; Russell, B. Actionvlad: Learning spatio-temporal aggregation for action classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 971–980. [Google Scholar]
- Sharma, S.; Kiros, R.; Salakhutdinov, R. Action Recognition using Visual Attention. In Proceedings of the International Conference on Learning Representations (ICLR) Workshop, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 843–852. [Google Scholar]
- Li, Z.; Gavrilyuk, K.; Gavves, E.; Jain, M.; Snoek, C.G. Videolstm convolves, attends and flows for action recognition. Comput. Vis. Image Underst. 2018, 166, 41–50. [Google Scholar] [CrossRef]
- Shi, Y.; Tian, Y.; Wang, Y.; Zeng, W.; Huang, T. Learning long-term dependencies for action recognition with a biologically-inspired deep network. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 716–725. [Google Scholar]
- Han, T.; Xie, W.; Zisserman, A. Video representation learning by dense predictive coding. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, South of Korea, 27–28 October 2019. [Google Scholar]
- Wang, J.; Jiao, J.; Bao, L.; He, S.; Liu, Y.; Liu, W. Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4006–4015. [Google Scholar]
- Xu, D.; Xiao, J.; Zhao, Z.; Shao, J.; Xie, D.; Zhuang, Y. Self-supervised spatiotemporal learning via video clip order prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10334–10343. [Google Scholar]
- Jenni, S.; Meishvili, G.; Favaro, P. Video representation learning by recognizing temporal transformations. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 425–442. [Google Scholar]
- Pan, T.; Song, Y.; Yang, T.; Jiang, W.; Liu, W. Videomoco: Contrastive video representation learning with temporally adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11205–11214. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network(s) | No. of Trainable Parameters | UCF101 | HMDB51 |
|---|---|---|---|
| Multi-resolution ConvNet [25] | 62 M | 65.40% | - |
| Two-stream ConvNet [44] | 17 M | 73.00% | 40.50% |
| Very Deep Two-streams ConvNet [30] | 138 M | 78.40% | - |
| C3D [45] | 17.5 M | 85.20% | - |
| Two-stream SR-ConvNet [33] | 138 M | 78.32% | - |
| Actions Transformation [46] | 276 M | 80.80% | 44.10% |
| TSN [20] | 11.29 M | 85.10% | 51.00% |
| ActionVLAD [47] | 138 M | - | 49.80% |
| LTC [37] | 56 M | 82.40% | - |
| Visual Attention [48] | 14.31 M | - | 41.31% |
| Unsupervised LSTM [49] | 117 M | 75.80% | 44.10% |
| Long-term Recurrent ConvNet [16] | 80.87 M | 68.20% | - |
| Conv ALSTM [50] | 222 M | 79.60% | 43.30% |
| Long-term LSTM [17] | 15 M | 82.60% | - |
| shuttleNet [51] | 66.32 M | 87.30% | 54.20% |
| DPC [52] | 32.6 M | 75.70% | 35.70% |
| Spatio-Temp [53] | 58.3 M | 61.20% | 33.40% |
| VCOP [54] | 58.3 M | 65.60% | 28.40% |
| RTT [55] | 58.3 M | 69.90% | 39.60% |
| VideoMoCo [56] | 14.4 M | 78.70% | 49.20% |
| SVT [43] | 86 M | 90.80% | 57.80% |
| FTDS-1DConvNet (Ours) | 56.23 M | 88.43% | 56.23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, K.M.; Lee, C.P.; Tan, K.S.; Alqahtani, A.; Ali, M. Fine-Tuned Temporal Dense Sampling with 1D Convolutional Neural Network for Human Action Recognition. Sensors 2023, 23, 5276. https://doi.org/10.3390/s23115276
Lim KM, Lee CP, Tan KS, Alqahtani A, Ali M. Fine-Tuned Temporal Dense Sampling with 1D Convolutional Neural Network for Human Action Recognition. Sensors. 2023; 23(11):5276. https://doi.org/10.3390/s23115276
Chicago/Turabian StyleLim, Kian Ming, Chin Poo Lee, Kok Seang Tan, Ali Alqahtani, and Mohammed Ali. 2023. "Fine-Tuned Temporal Dense Sampling with 1D Convolutional Neural Network for Human Action Recognition" Sensors 23, no. 11: 5276. https://doi.org/10.3390/s23115276
APA StyleLim, K. M., Lee, C. P., Tan, K. S., Alqahtani, A., & Ali, M. (2023). Fine-Tuned Temporal Dense Sampling with 1D Convolutional Neural Network for Human Action Recognition. Sensors, 23(11), 5276. https://doi.org/10.3390/s23115276