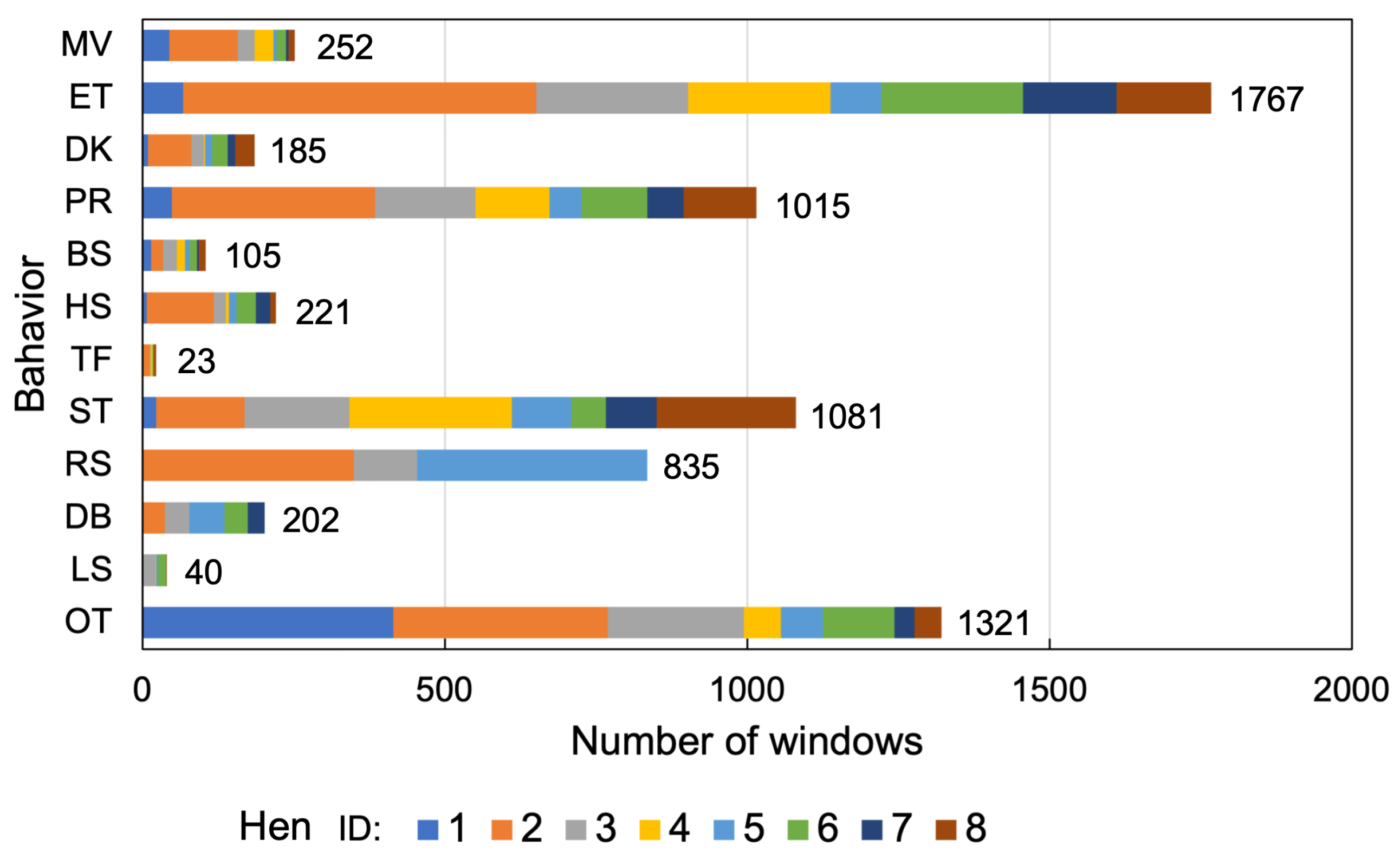
5.5. Effective Sensor Modalities and Importance of Magnitude of Acceleration
Section 4.5 explains that, regardless of the classifier, GYR had lower F1-scores than ACC in the 10-fold-CV due to increased mutual confusion between ET, DK, PR, and OT and between ST and RS in GYR compared to ACC. The increase in confusion between ET and OT in GYR may be because OT includes the action of pecking sensors of other individuals. Although feeding and pecking are similar because they produce short impulse-like bursts, the direction of head movement differs between feeding in the bait box and pecking at another individual’s sensor due to the different positions of the target. An angular velocity sensor measures the relative change in angle, whereas the force applied to the sensor, including the acceleration of gravity, is obtained by an accelerometer, and an accelerometer could therefore discriminate these differences in the direction of movement. Similarly, the increased confusion in the GYR between ET, DK, and PR may have resulted from their inability to discriminate between different target locations for beak use but a commonality in the act of beak use.
As for ST and RS, ST is primarily a stationary behavior compared to the other behaviors, although hens occasionally move their heads when standing. In RS, the body may tilt when lying on the ground, resulting in a variation in sensor posture compared to standing firmly on both legs. Therefore, we believe an accelerometer is more effective than an angular velocity sensor because an accelerometer can capture postural information from the gravitational acceleration component and the force associated with the movement. Moreover, TF was the only behavior with a higher value in GYR than in ACC. An angular velocity sensor may have been more effective because tail wagging was mostly in a horizontal plane. Thus, although an accelerometer demonstrated a high overall classification performance, the combination with the angular velocity sensor (i.e., ALL) resulted in classification that is more accurate. Although an angular velocity sensor generally has a higher power consumption than an accelerometer [
55], we suggest the combination of the gyro sensor with an accelerometer if there is no battery limitation.
Similar to the above, in
Section 4.5, more than half of the comparisons between wo_M and ALL in
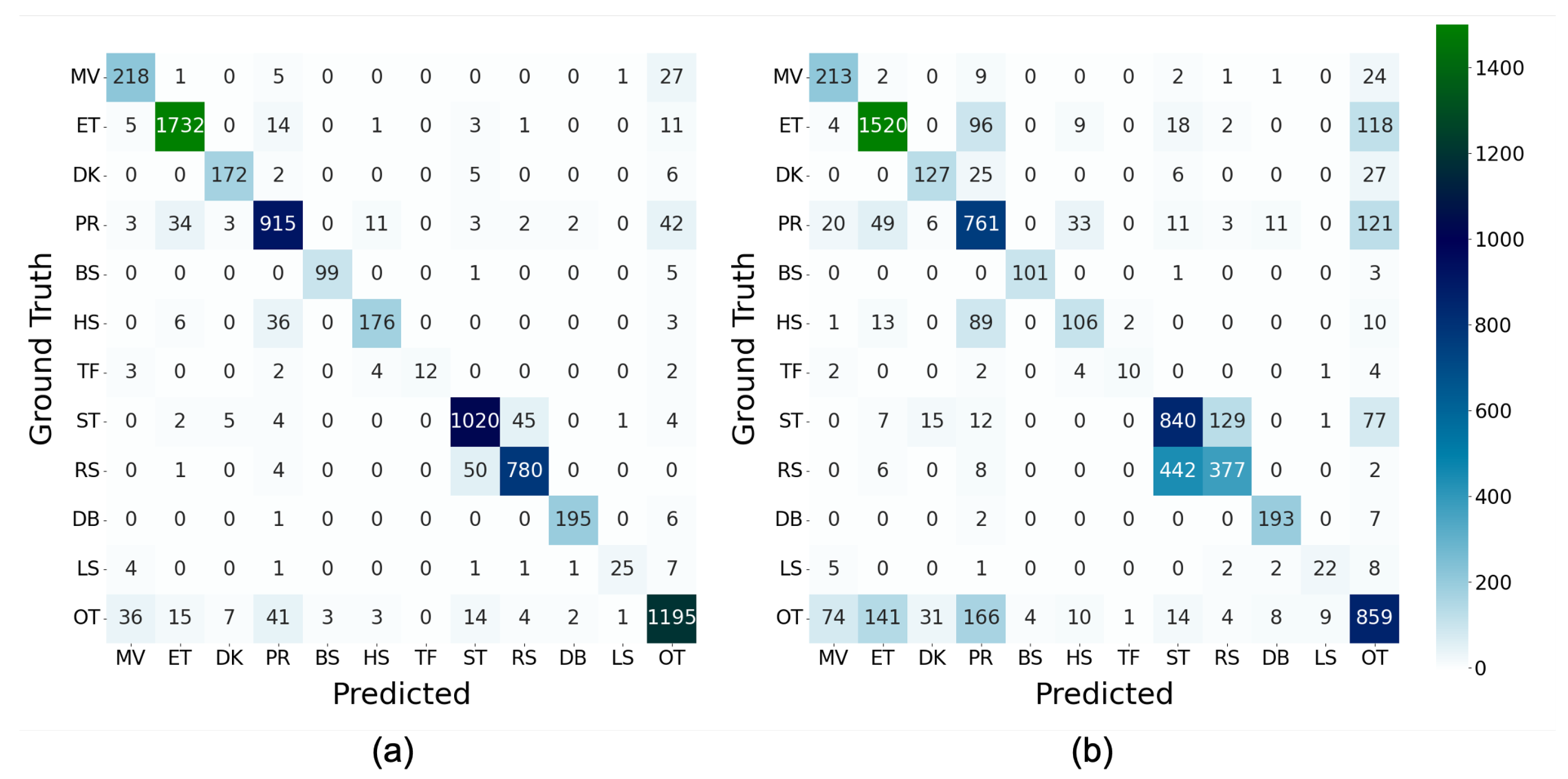
Figure 14 depict that wo_M had higher F1-scores. Particularly, in TF with a value of 0.143 higher, it might be the primary reason why the macro average of wo_M was higher than that of ALL. The detail of classification in TF is depicted in
Figure 6a with four, three, two, and two misclassifications out of 23 instances of TF for HS, MV, PR, and OT, respectively. In addition, they were reduced by four, zero, one, and one by excluding the magnitude of acceleration. Moreover, the number of misclassifications to LS increased by one; however, the number of correct classifications into TF increased by five. HS is a rapid head-scratching behavior with one foot; therefore, the force applied to the body might be similar to that of TF, even if the direction of movement was different from that of TF that wags the tail at high speed. Therefore, we believe that the misclassification was suppressed by extracting the magnitude value and emphasizing the directional component; however, further experiments with a larger sample are required to determine the misclassification source because the number of instances is only 23.
Figure 15b exhibits that the number of correct classifications into LS decreased by one, whereas the number of misclassifications to LS increased by one in MV, TF, and DB and decreased by one in ST. This resulted in a 0.039 lower F1-score for LS, compared to ALL, as depicted in
Figure 14; however, it is challenging to generalize the cause of this difference because the individual differences were only plus or minus one.
5.6. Existing Work on Chicken Behavior Recognition
We discuss the results compared with other work related to chicken behavior recognition.
Table 11 summarizes relevant parameters discovered in each work: the number and type of behaviors, sensor modality, number of axes, sampling frequency, window length, classification method, and condition of data.
The present study addressed 11 types of behaviors belonging to categories such as migration, feeding, self-defense, grooming, resting, and searching and is characterized by its aims to quantify various daily behaviors of chickens compared to other studies. In the works of Abdoli et al. [
10,
11] and Quwaider et al. [
13], a class PK was among the classification targets we did not address. However, because Abdoli et al. used the term “pecking” along with “feeding” in their study, it can be noted that our method also covered what they called pecking. In Quwaider et al.’s study, the target of PK appears to be the ground, sensors, etc. In the data collected in this study, we also discovered some behaviors of pecking at other individuals’ sensors as strange objects; however, we included these behaviors in OT. Note that the introduction of OT was unique to our study. In a classification task in machine learning, the input data are classified into one of the learned classes. Thus, miscellaneous data obtained in the automatic processing of long-term data, expected in practical applications, would be incorrectly classified into a behavior class with similar characteristics. In this study, the behaviors included in OT contain pecking at the sensor and various movements such as balance breaking, beak scratching, and looking around, as listed in
Table 1. We believe the introduction of OT would improve the discrimination accuracy of the 11 types of behaviors other than OT. However, there are still movements that are not included in OT. Therefore, the reliability of the classification results would be further improved by post-processing the classifier output, such as using the rejection option. The research group of Derakhshani and Shahbazi classified various behaviors into three classes based on their intensity [
26,
27], which was intended to be used to control the amount of fine dust produced by hens’ activity or to assess the health and welfare status of hens. We focused on the recognition of individual behaviors because we intend to use the frequency and transitions of the behaviors and the locations where the behaviors occur in our attempts to improve hen’s welfare.
Regarding the sensor modality, all existing work except Li et al. [
24], Shahbazi et al. [
26], and ours used only an accelerometer for behavior classification. Li et al. performed feature selection by integrating acceleration and angular velocity-derived features and did not investigate the classification performance for each sensor. However, we generated a subset of features for each modality (ACC and GYR) and compared the performance with the combined set (ALL). Our results demonstrated that the accelerometer is more beneficial than the angular velocity sensor as a single sensor and that the combination of the two is excellent. The results showed an overall trend and a trend for each action. This outcome provides information to decide whether to adopt or reject the angular velocity sensor, considering the power constraints of the measurement system and the type of behavior to emphasize. Shahbazi et al. further combined a magnetic field sensor and confirmed that it was more accurate than using the combination of accelerometer and angular velocity sensor in an artificially generated high-level noise environment. We consider it an interesting finding, and the applicability is worth considering while taking into account the influence of metals present in the actual rearing environment on the magnetic field sensor.
For sampling frequency, we down-sampled data collected at 1000 Hz to generate data sampled at five different frequencies for comparison, whereas other studies used a single value. Although the optimal frequency varied with the classifier, we concluded that 100 Hz was suitable from an individual-independent perspective. The results showed a trend in classification accuracy at frequencies lower and higher than this value, which will be beneficial in determining sampling frequency in future research.
Similar comparisons were made for window length; Banerjee et al. [
12], Yang et al. [
25], and Derakhshani et al. [
27] also compared two, six, and two different window lengths, showing 4 s, 1 s, and 4 s as better window length than the other candidates, respectively. For datasets collected in finite time, decreasing the window length increases the number of data instances, which increases the training data. Therefore, the number of instances required standardization to investigate the effect of the window length. Contrary to other studies, we compared a window of 1.28 s and 0.64 s with and without standardizing the number of instances based on these ideas. We demonstrated that 1.28 s is more effective regarding informativeness even when the number of training instances is approximately doubled in 0.64 s. We did not compare the results over 3 s in these studies because we utilized an upper limit of about 1 s based on the duration of the target behaviors. Therefore, it is challenging to generalize the results. Nevertheless, we could show a lower bound of about 1 s.
We compared traditional classifiers, such as
kNN and NB, and newer ones, such as LGBM, and discovered that LGBM, SVM, and MLP were superior regarding F1-scores in 10-fold-CV and IIR. The 10-fold-CV approach assumes identical data distribution during training and testing, and IIR acts as an indicator of the independence of individual differences. The superiority of these classifiers was also found to be beneficial by Banerjee et al. [
12], Yang et al. [
25], and Li et al [
24]. In the literature above, only [
26] utilizes a deep learning (DL)-based approach (i.e., convoluational neural networks (CNNs)). As described in
Section 3.1, we did not take DL-based approaches due to relatively poor classification performance in a preliminary evaluation, which we consider because of the small number of data. We are currently developing an interactive labeling tool using the present behavior recognition pipeline to accelerate making a large dataset. The evaluation with DL-based approaches remains for future work.
To address the imbalance in the training data, we compared the classification performance using training data balanced by over-sampling and training data that remained imbalanced. The results demonstrated that the training with imbalanced data was satisfactory. Collecting labeled data in animal behavior recognition is more challenging than in human behavior recognition because cooperation from the target (i.e., animals) is more demanding to obtain, and imbalance is more likely to occur [
10]. We consider the comparison significant: it demonstrated that balancing training data did not necessarily positively influence classification performance. However, data balancing should be implemented per new datasets because the result depended on data distribution.
To understand the applicability of features used in existing work to our recognition task and dataset, the features used in the work of Banerjee et al. [
12] and Derakhshani et al. [
27] were evaluated. The reasons for the choice of these studies are that they took a feature engineering-based approach using fixed-size windows and they had sufficient information for reproduction. In the work of Banerjee et al. [
12], ENTR and MEAN were calculated from each of the
x and
y axes of an accelerometer; these four features were included in our feature set. A total of 31 features calculated from the acceleration signal were taken from Derakhshani et al.’s work: SKEW, KURT, MEAN, SD, variance (VAR), MIN, MAX, ENTR, ENGY, and covariance (COV) for each of three axes and the average signal magnitude (ASM), in which all but VAR, COV, and ASM were a subset of our feature set.
Figure 16 shows the F1-scores per behavior, in which the result of our features with the highest score (i.e., ALL) are also presented as a comparison. Compared to the results of Derakhshani et al., our feature set (ALL) showed higher F1 scores for all behaviors but BS, including the mean, particularly MV, TF, and LS, and the scores of their ET, ST, RS, and OT were comparable to ALL. On the other hand, most scores using Banerjee et al.’s features were considerably lower than ALL, but comparable for stable states such as ST and RS.
To summarize, we increased the number of target behaviors, compared different parameters that should be considered when designing a hen behavior recognition system using wearable sensors, and demonstrated the superiority or inferiority of the candidate parameters. We also showed that the sensor modality and features used in existing work were insufficient to successfully classify the target behaviors. Considering this, we assume it would contribute beneficial information for designing similar systems.
5.7. General Discussion
The generality of the results of this study to hen behavior recognition is discussed. In this study, we collected data from Boris Brown layers. However, we believe the results apply to other breeds of layers and roosters, as there are almost no differences in their behavioral patterns. However, there may be differences depending on the age in weeks. When using the same acceleration sensor device, it may be challenging to distinguish the behavior of a newborn hen because the sensor is large and heavy for its body size. In addition, its movements are limited and different from the learned patterns; however, we consider that there will be no problem when the hens are approximately three months old or later when they begin to lay eggs.
In addition, although we collected data in an area of 100 cm × 76 cm, we assume our results are applicable even if the hens are kept in a larger space because their basic behaviors, such as dust bathing and feeding, do not change. Because the hens’ movements are expected to be more dynamic in a larger space due to their long strides, it may be possible to detect them accurately by retraining the classifier through data collection. Similarly, the extra space will enable the hens to jump upwards; thus, we expect to notice movements that could not be collected. As noted above, we believe that we can redirect data from multiple behaviors; therefore, additional data collection limited to new behaviors will allow us to include many behaviors in the recognition target.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}