
Recent Advanced Deep Learning Architectures for Retinal Fluid Segmentation on Optical Coherence Tomography Images



Abstract
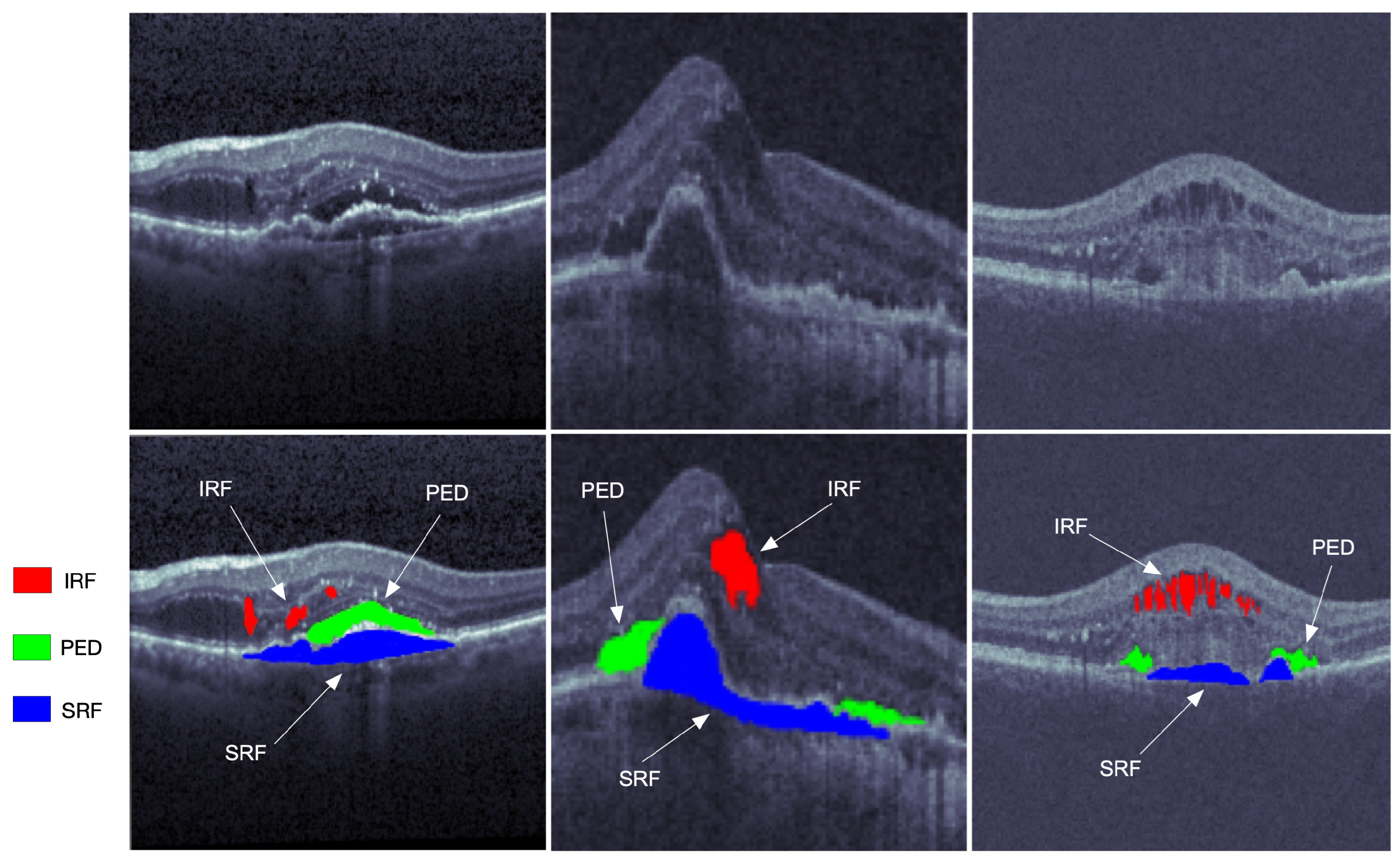
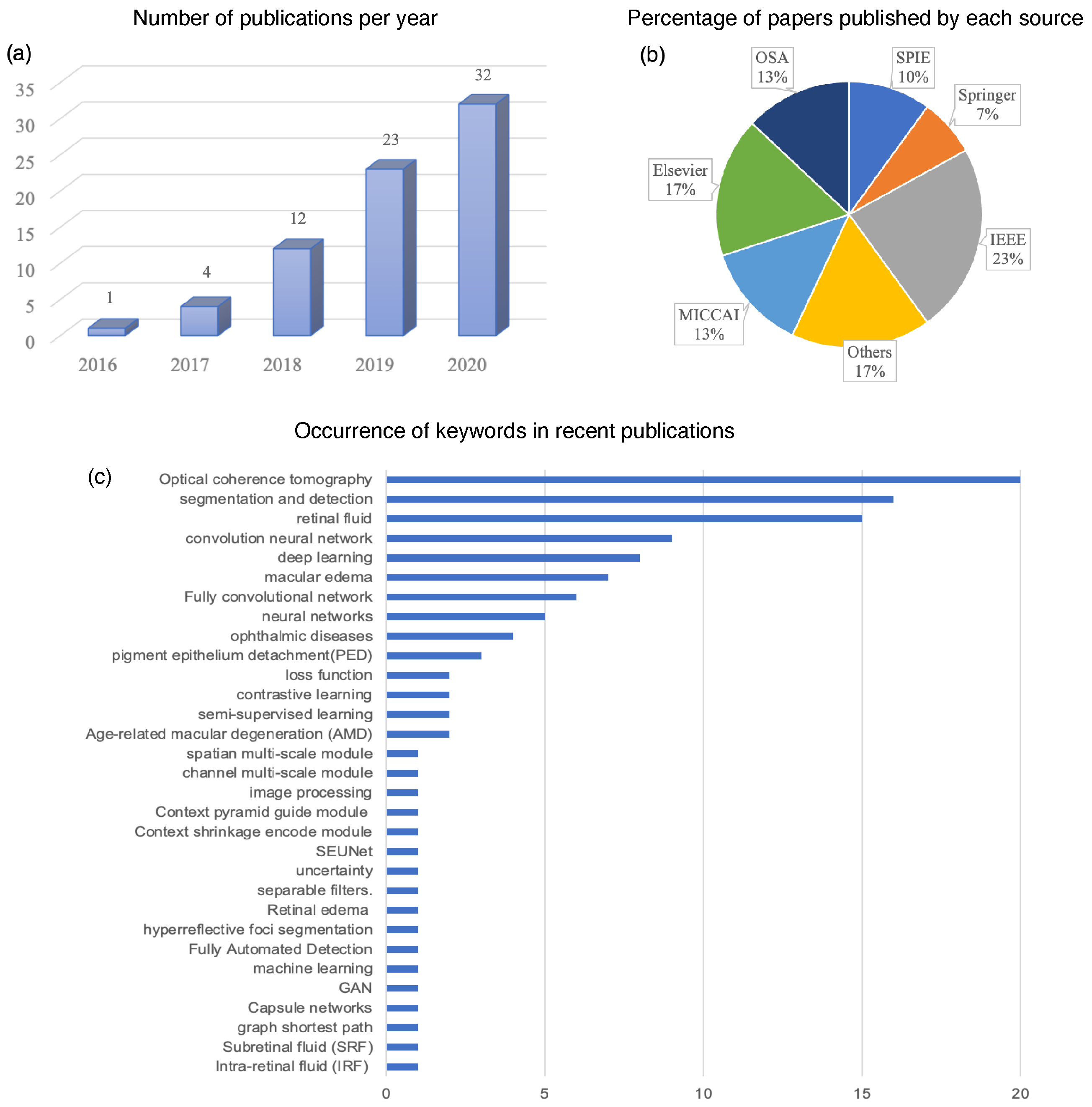
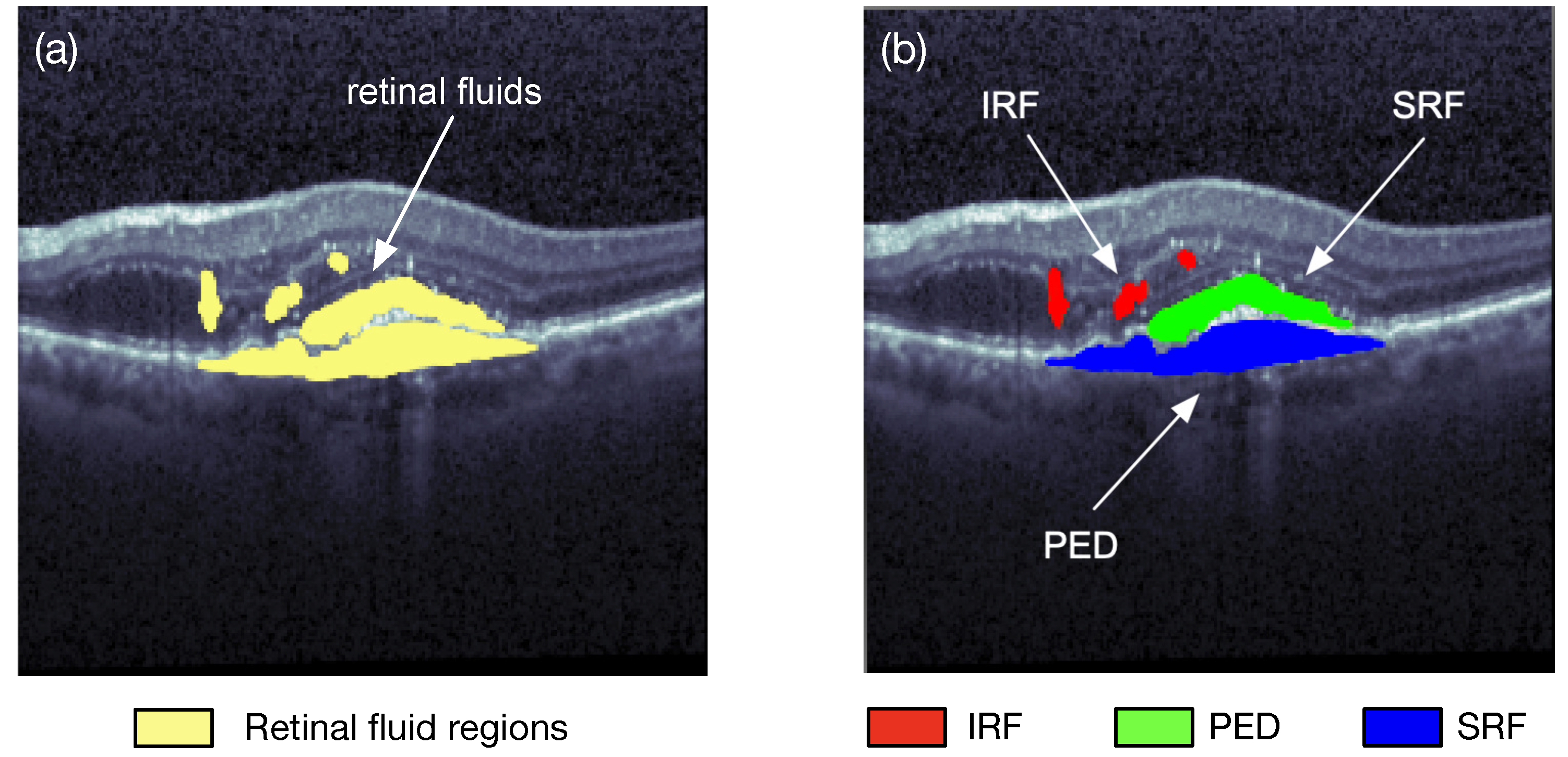
:1. Introduction
2. Deep Learning Applications for OCT Image Segmentation
2.1. Fully Convolutional Networks (FCNs)
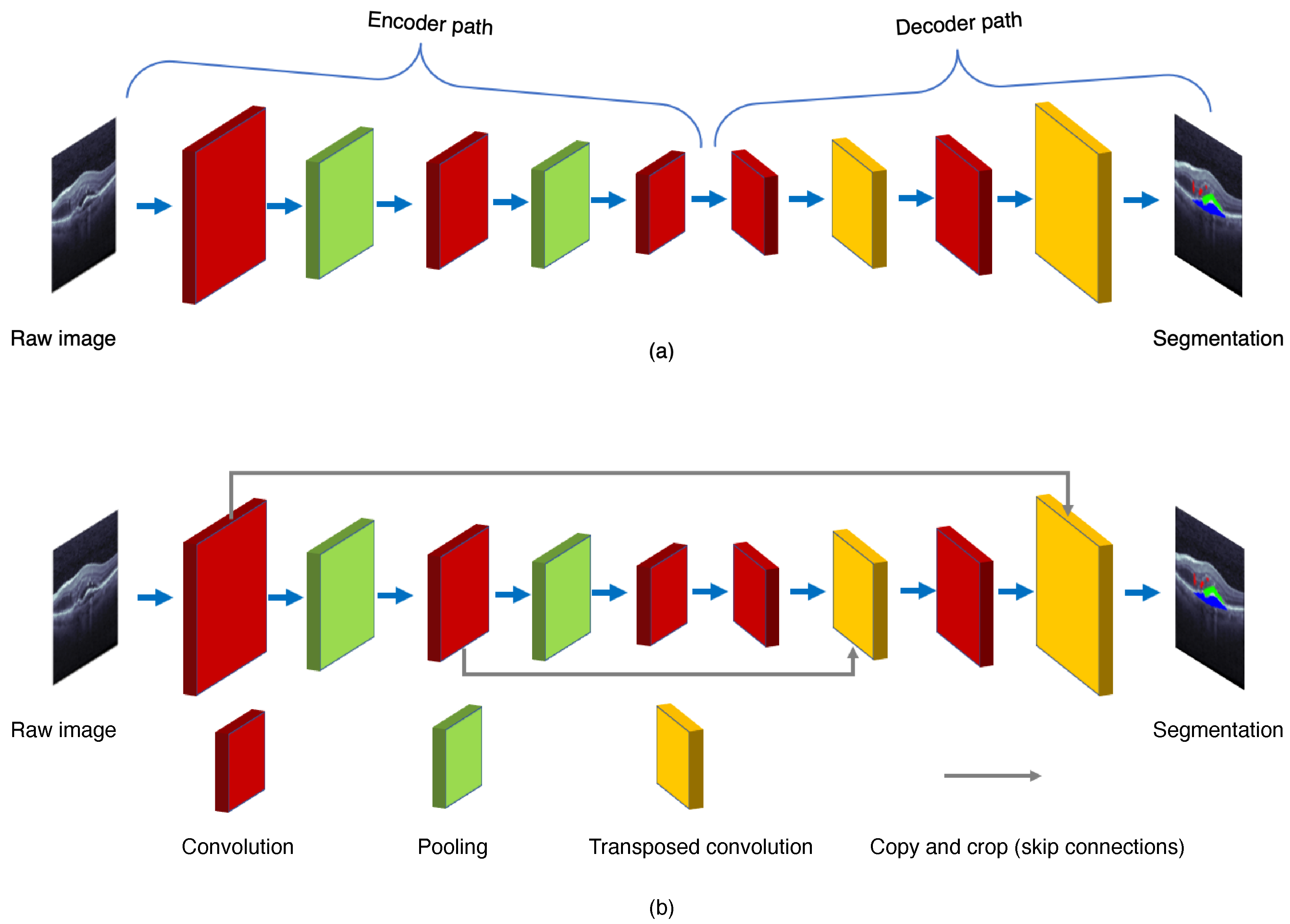
2.2. U-Net
2.3. SegNet
2.4. DeepLab
2.5. Evaluation Indicators
- Region-based indicators;
- Distance-based indicators (e.g., Hausdorff distance, pixel distance);
- Entire image-based statistical indicators.
3. Benchmark OCT Datasets
3.1. RETOUCH Dataset
3.2. UMN Dataset
3.3. OPTIMA Dataset
3.4. Duke Dataset
3.5. HCMS Dataset
3.6. Kermany Dataset
3.7. Other Private Datasets
4. Retinal Fluid Segmentation Based on Deep Learning
4.1. Deep Learning Paradigms Based on CNN or FCN
Modified CNN or FCN Architectures
4.2. Deep Learning Paradigms with U-Net Backbone
4.2.1. Fine-Tuning on the U-Net Backbone
4.2.2. Loss Function Innovations
4.2.3. U-Net with New Modules
4.2.4. 3D U-Net Model
4.3. Hybrid Computational Segmentation Methods
4.3.1. Shortest-Path Methods
4.3.2. Graph-Based Methods
4.3.3. Unsupervised Learning Methods
5. Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| AMD | Age-related Macular Degeneration |
| ASPP | Atrous Spatial Pyramid Pooling |
| BM | Bruch’s Membrane |
| BN | Batch Normalization |
| CNN | Convolutional Neural Network |
| CNV | Choroidal NeoVascularization |
| CPG | Context Pyramid Guide |
| CRF | Conditional Random Field |
| DAC | Dense Atrous Convolution |
| DME | Diabetic Macular Edema |
| FCN | Fully Convolutional Network |
| GPU | Graphics Processing Unit |
| GRU | Gated Recurrent Unit |
| ILM | Internal Limiting Membrane |
| IRF | Intraretinal Fluid |
| OCT | Optical Coherence Tomography |
| PED | Pigment Epithelial Detachment |
| RPE | Retinal Pigment Epithelium |
| RVO | Retinal Vein Occlusion |
| SE-block | Squeeze-and-Excitation block |
| SRF | Subretinal Fluid |
References
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [Green Version]
- Bogunovic, H.; Venhuizen, F.; Klimscha, S.; Apostolopoulos, S.; Bab-Hadiashar, A.; Bagci, U.; Beg, M.F.; Bekalo, L.; Chen, Q.; Ciller, C.; et al. RETOUCH: The retinal OCT fluid detection and segmentation benchmark and challenge. IEEE Trans. Med. Imaging 2019, 38, 1858–1874. [Google Scholar] [CrossRef]
- de Bruijne, M.; van Ginneken, B.; Viergever, M.A.; Niessen, W.J. Interactive segmentation of abdominal aortic aneurysms in CTA images. Med. Image Anal. 2004, 8, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Silveira, M.; Nascimento, J.C.; Marques, J.S.; Marcal, A.; Mendonca, T.; Yamauchi, S.; Maeda, J.; Rozeira, J. Comparison of segmentation methods for melanoma diagnosis in dermoscopy images. IEEE J. Sel. Top. Signal Process. 2009, 3, 35–45. [Google Scholar] [CrossRef]
- Fu, H.; Xu, Y.; Lin, S.; Wong, D.W.K.; Liu, J. DeepVessel: Retinal vessel segmentation via deep learning and conditional random field. In Proceedings of the 2016 International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2016), Athens, Greece, 17–21 October 2016; pp. 132–139. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Hassan, B.; Qin, S.; Ahmed, R. SEADNet: Deep learning driven segmentation and extraction of macular fluids in 3D retinal OCT scans. In Proceedings of the 2020 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT 2020), Louisville, KY, USA, 9–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ye, Y.; Chen, X.; Shi, F.; Xiang, D.; Pan, L.; Zhu, W. Context attention-and-fusion network for multiclass retinal fluid segmentation in OCT images. In Proceedings of the SPIE, Medical Imaging 2021: Image Processing, San Diego, CA, USA, 14–18 February 2021; Volume 11596, p. 1159622. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Lin, X.; Sanchez-Escobedo, D.; Casas, J.R.; Pardas, M. Depth estimation and semantic segmentation from a single RGB image using a hybrid convolutional neural network. Sensors 2019, 19, 1795. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chang, H.H.; Zhuang, A.H.; Valentino, D.J.; Chu, W.C. Performance measure characterization for evaluating neuroimage segmentation algorithms. NeuroImage 2009, 47, 122–135. [Google Scholar] [CrossRef]
- Rashno, A.; Nazari, B.; Koozekanani, D.D.; Drayna, P.M.; Sadri, S.; Rabbani, H.; Parhi, K.K. Fully-automated segmentation of fluid regions in exudative age-related macular degeneration subjects: Kernel graph cut in neutrosophic domain. PLoS ONE 2017, 12, e0186949. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Philip, A.M.; Podkowinski, D.; Gerendas, B.S.; Langs, G.; Simader, C.; Waldstein, S.M.; Schmidt-Erfurth, U.M. Multivendor spectral-domain optical coherence tomography dataset, observer annotation performance evaluation, and standardized evaluation framework for intraretinal cystoid fluid segmentation. J. Ophthalmol. 2016, 2016, 3898750. [Google Scholar] [CrossRef] [Green Version]
- Chiu, S.J.; Allingham, M.J.; Mettu, P.S.; Cousins, S.W.; Izatt, J.A.; Farsiu, S. Kernel regression based segmentation of optical coherence tomography images with diabetic macular edema. Biomed. Opt. Express 2015, 6, 1172–1194. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Carass, A.; Solomon, S.D.; Saidha, S.; Calabresi, P.A.; Prince, J.L. Retinal layer parcellation of optical coherence tomography images: Data resource for multiple sclerosis and healthy controls. Data Brief 2019, 22, 601–604. [Google Scholar] [CrossRef]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef]
- Schlegl, T.; Waldstein, S.M.; Bogunovic, H.; Endstraßer, F.; Sadeghipour, A.; Philip, A.M.; Podkowinski, D.; Gerendas, B.S.; Langs, G.; Schmidt-Erfurth, U. Fully automated detection and quantification of macular fluid in OCT using deep learning. Ophthalmology 2018, 125, 549–558. [Google Scholar] [CrossRef] [Green Version]
- Gao, K.; Niu, S.; Ji, Z.; Wu, M.; Chen, Q.; Xu, R.; Yuan, S.; Fan, W.; Chen, Y.; Dong, J. Double-branched and area-constraint fully convolutional networks for automated serous retinal detachment segmentation in SD-OCT images. Comput. Methods Programs Biomed. 2019, 176, 69–80. [Google Scholar] [CrossRef]
- Lee, C.S.; Tyring, A.J.; Deruyter, N.P.; Wu, Y.; Rokem, A.; Lee, A.Y. Deep-learning based, automated segmentation of macular edema in optical coherence tomography. Biomed. Opt. Express 2017, 8, 3440–3448. [Google Scholar] [CrossRef] [Green Version]
- Rao, T.J.N.; Girish, G.N.; Kothari, A.R.; Rajan, J. Deep learning based sub-retinal fluid segmentation in central serous chorioretinopathy optical coherence tomography scans. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC 2019), Berlin, Germany, 23–27 July 2019; pp. 978–981. [Google Scholar] [CrossRef]
- Yang, J.; Ji, Z.; Niu, S.; Chen, Q.; Yuan, S.; Fan, W. RMPPNet: Residual multiple pyramid pooling network for subretinal fluid segmentation in SD-OCT images. OSA Contin. 2020, 3, 1751–1769. [Google Scholar] [CrossRef]
- Bao, D.; Cheng, X.; Zhu, W.; Shi, F.; Chen, X. Attention multi-scale network for pigment epithelial detachment segmentation in OCT images. In Proceedings of the SPIE, Medical Imaging 2020: Image Processing, Houston, TX, USA, 15–20 February 2020; Volume 11313, p. 1131335. [Google Scholar] [CrossRef]
- Pawan, S.J.; Sankar, R.; Jain, A.; Jain, M.; Darshan, D.V.; Anoop, B.N.; Kothari, A.R.; Venkatesan, M.; Rajan, J. Capsule network-based architectures for the segmentation of sub-retinal serous fluid in optical coherence tomography images of central serous chorioretinopathy. Med. Biol. Eng. Comput. 2021, 59, 1245–1259. [Google Scholar] [CrossRef]
- Hu, J.; Chen, Y.; Yi, Z. Automated segmentation of macular edema in OCT using deep neural networks. Med. Image Anal. 2019, 55, 216–227. [Google Scholar] [CrossRef]
- Venhuizen, F.G.; van Ginneken, B.; Liefers, B.; van Asten, F.; Schreur, V.; Fauser, S.; Hoyng, C.; Theelen, T.; Sanchez, C.I. Deep learning approach for the detection and quantification of intraretinal cystoid fluid in multivendor optical coherence tomography. Biomed. Opt. Express 2018, 9, 1545–1569. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Q.; Ji, Z.; Wang, T.; Tand, Y.; Yu, C.; Paul, O.I.; Sappa, L.B. Automatic segmentation of fluid-associated abnormalities and pigment epithelial detachment in retinal SD-OCT images. In Proceedings of the MICCAI Retinal OCT Fluid Challenge (RETOUCH), Quebec City, QC, Canada, 10–14 September 2017; pp. 15–21. [Google Scholar]
- Sanchez, Y.D.; Nieto, B.; Padilla, F.D.; Perdomo, O.; Osorio, F.A.G. Segmentation of retinal fluids and hyperreflective foci using deep learning approach in optical coherence tomography scans. In Proceedings of the 16th International Symposium on Medical Information Processing and Analysis, Lima, Peru, 3–4 October 2020; p. 115830H. [Google Scholar] [CrossRef]
- Wang, Z.; Zhong, Y.; Yao, M.; Ma, Y.; Zhang, W.; Li, C.; Tao, Z.; Jiang, Q.; Yan, B. Automated segmentation of macular edema for the diagnosis of ocular disease using deep learning method. Sci. Rep. 2021, 11, 13392. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Ali, T.K.; Singh, P.; Shah, A.; McKinney, S.M.; Ruamviboonsuk, P.; Turner, A.W.; Keane, P.A.; Chotcomwongse, P.; Nganthavee, V.; et al. Deep learning to detect optical coherence tomography-derived diabetic macular edema from retinal photographs: A multicenter validation study. Ophthalmol. Retin. 2022; in press. [Google Scholar] [CrossRef]
- Sappa, L.B.; Okuwobi, I.P.; Li, M.; Zhang, Y.; Xie, S.; Yuan, S.; Chen, Q. RetFluidNet: Retinal fluid segmentation for SD-OCT images using convolutional neural network. J. Digit. Imaging 2021, 34, 691–704. [Google Scholar] [CrossRef] [PubMed]
- Girish, N.G.; Saikumar, B.; Roychowdhury, S.; Kothari, A.R.; Rajan, J. Depthwise separable convolutional neural network model for intra-retinal cyst segmentation. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC 2019), Berlin, Germany, 23–27 July 2019; pp. 2027–2031. [Google Scholar] [CrossRef]
- Liu, X.; Wang, S. Uncertainty-aware semi-supervised framework for automatic segmentation of macular edema in OCT images. In Proceedings of the 18th International Symposium on Biomedical Imaging (ISBI 2021), Nice, France, 13–16 April 2021; pp. 1453–1456. [Google Scholar]
- LaLonde, R.; Xu, Z.; Irmakci, I.; Jain, S.; Bagci, U. Capsules for biomedical image segmentation. Med Image Anal. 2021, 68, 101889. [Google Scholar] [CrossRef]
- Xing, G.; Chen, L.; Wang, H.; Zhang, J.; Sun, D.; Xu, F.; Lei, J.; Xu, X. Multi-scale pathological fluid segmentation in OCT with a novel curvature loss in convolutional neural network. IEEE Trans. Med. Imaging, 2022; in press. [Google Scholar] [CrossRef]
- Roy, A.G.; Conjeti, S.; Karri, S.P.K.; Sheet, D.; Katouzian, A.; Wachinger, C.; Navab, N. ReLayNet: Retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 2017, 8, 3627–3642. [Google Scholar] [CrossRef]
- Kang, S.H.; Park, H.S.; Jang, J.; Jeon, K. Deep neural networks for the detection and segmentation of the retinal fluid in OCT images. In Proceedings of the MICCAI Retinal OCT Fluid Challenge (RETOUCH), Quebec City, QC, Canada, 10–14 September 2017; pp. 9–14. [Google Scholar]
- Tennakoon, R.; Gostar, A.K.; Hoseinnezhad, R.; Bab-Hadiashar, A. Retinal fluid segmentation in OCT images using adversarial loss based convolutional neural networks. In Proceedings of the 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 605–609. [Google Scholar] [CrossRef]
- Liu, X.; Cao, J.; Fu, T.; Pan, Z.; Hu, W.; Zhang, K.; Liu, J. Semi-supervised automatic segmentation of layer and fluid region in retinal optical coherence tomography images using adversarial learning. IEEE Access 2018, 7, 3046–3061. [Google Scholar] [CrossRef]
- Wei, H.; Peng, P. The segmentation of retinal layer and fluid in SD-OCT images using mutex Dice loss based fully convolutional networks. IEEE Access 2020, 8, 60929–60939. [Google Scholar] [CrossRef]
- Chen, Z.; Li, D.; Shen, H.; Mo, H.; Zeng, Z.; Wei, H. Automated segmentation of fluid regions in optical coherence tomography B-scan images of age-related macular degeneration. Opt. Laser Technol. 2020, 122, 105830. [Google Scholar] [CrossRef]
- Ma, D.; Lu, D.; Chen, S.; Heisler, M.; Dabiri, S.; Lee, S.; Lee, H.; Ding, G.W.; Sarunic, M.V.; Beg, M.F. LF-UNet-A novel anatomical-aware dual-branch cascaded deep neural network for segmentation of retinal layers and fluid from optical coherence tomography images. Comput. Med. Imaging Graph. 2021, 94, 101988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef] [Green Version]
- Rashno, A.; Koozekanani, D.D.; Parhi, K.K. Detection and segmentation of various types of fluids with graph shortest path and deep learning approaches. In Proceedings of the MICCAI Retinal OCT Fluid Challenge (RETOUCH), Quebec City, QC, Canada, 10–14 September 2017; pp. 54–62. [Google Scholar]
- Liu, D.; Liu, X.; Fu, T.; Yang, Z. Fluid region segmentation in OCT images based on convolution neural network. In Proceedings of the 9th International Conference on Digital Image Processing (ICDIP 2017), Hong Kong, China, 19–22 May 2017; p. 104202A. [Google Scholar] [CrossRef]
- Lu, D.; Heisler, M.; Lee, S.; Ding, G.W.; Navajas, E.; Sarunic, M.V.; Beg, M.F. Deep-learning based multiclass retinal fluid segmentation and detection in optical coherence tomography images using a fully convolutional neural network. Med. Image Anal. 2019, 54, 100–110. [Google Scholar] [CrossRef]
- Montuoro, A.; Waldstein, S.M.; Gerendas, B.S.; Schmidt-Erfurth, U.; Bogunovic, H. Joint retinal layer and fluid segmentation in OCT scans of eyes with severe macular edema using unsupervised representation and auto-context. Biomed. Opt. Express 2017, 8, 1874–1888. [Google Scholar] [CrossRef] [PubMed]
- Gopinath, K.; Sivaswamy, J. Segmentation of retinal cysts from optical coherence tomography volumes via selective enhancement. IEEE J. Biomed. Health Inf. 2019, 23, 273–282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, X.; Fang, L.; Tan, M.; Chen, X. Intra- and inter-slice contrastive learning for point supervised OCT fluid segmentation. IEEE Trans. Image Process. 2022, 31, 1870–1881. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Li, D.; Shen, H.; Mo, Y.; Wei, H.; Ouyang, P. Automated retinal layer segmentation in OCT images of age-related macular degeneration. IET Image Process. 2019, 13, 1824–1834. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef] [Green Version]
- Li, M.X.; Yu, S.Q.; Zhang, W.; Zhou, H.; Xu, X.; Qian, T.W.; Wan, Y.J. Segmentation of retinal fluid based on deep learning: Application of three-dimensional fully convolutional neural networks in optical coherence tomography images. Int. J. Ophthalmol. 2019, 12, 1012–1020. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Alsaih, K.; Yusoff, M.Z.; Faye, I.; Tang, T.B.; Meriaudeau, F. Retinal fluid segmentation using ensembled 2-dimensionally and 2.5-dimensionally deep learning networks. IEEE Access 2020, 8, 152452–152464. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Data Size | Manual Labeling | Disease | Web Page |
|---|---|---|---|---|
| RETOUCH | 70 volumes | IRF, SRF, PED | AMD, RVO | https://retouch.grand-challenge.org |
| UMN | 600 B-scan images | IRF, SRF, PED | AMD | http://people.ece.umn.edu/users/parhi/data-and-code/ |
| OPTIMA | 30 volumes | IRF | AMD, RVO, DME | https://optima.meduniwien.ac.at/optima-segmentation-challenge-1/ |
| Duke | 110 B-scan images | Fluid regions | DME | https://people.duke.edu/~sf59/Chiu_BOE_2014_dataset.htm |
| HCMS | 49 B-scan images | Fluid regions | MS | http://iacl.jhu.edu/Resources |
| Kermany | 108,312 B-scan images | Fluid regions | CNV, DME, drusen | https://data.mendeley.com/datasets/rscbjbr9sj/2 |
| Deep Learning | Methodology | Research Works | Paradigms |
|---|---|---|---|
| Schlegl et al. [19] | 8-layer FCN | ||
| Chen et al. [28] | Faster R-CNN | ||
| Modified CNN | Sanchez et al. [29] | SEUNet model | |
| Wang et al. [30] | Deeplab model | ||
| Sappa et al. [32] | CNN (skip-connect operations + atrous spatial pyramid pooling) | ||
| FCN backbones | Girish et al. [33] | Enhanced semantics preprocessing + CNN with a depthwise separable convolution filter | |
| Liu and Wang [34] | Two (Student + Teacher) FCNs | ||
| Pawan et al. [25] | DRIP-Caps (SegCaps with dilation, residual connections, inception blocks, and capsule pooling) | ||
| Modified FCN | Hu et al. [26] | ResNet added with ASPP and modified stochastic ASPP | |
| Gao et al. [20] | FCN with modified loss funciton | ||
| Xing et al. [36] | FCN architecture with attention gate and spatial pyramid pooling module | ||
| Roy et al. [37] | ReLayNet optimized with the weighted logistic regression and Dice loss | ||
| Fine-tuning | Kang et al. [38] | A cascade of two fine-tuned U-Nets (the second U-Net with 2-channel inputs) | |
| Lee et al. [21] | U-Net with 18 convolutional layers and sigmoid activation function for probability distribution mapping | ||
| Tennakoon et al. [39] | Adversarial loss | ||
| Modified loss function | Liu et al. [40] | Semi-supervised loss | |
| U-Net backbones | Wei and Peng [41] | Mutex Dice loss | |
| Chen et al. [42] | Squeeze-and-Excitation block (SE-block) | ||
| Hassan et al. [8] | Multiscale feature extractor module (DAC + ASPP) | ||
| Functional modules | Ma et al. [43] | U-Net + FCN with ASPP module | |
| Ye et al. [9] | Context pyramid guide + Context shrink-age encode | ||
| Yang et al. [23] | Six-string convolutions + Multiscale pyramid pooling module | ||
| Bao et al. [24] | Channel multiscale module + Spatial multiscale module | ||
| 3D U-Net | Lin et al. [44] | Batch normalization + Focal loss | |
| Shortest path methods | Rashno et al. [45] | Graph shortest path + CNN | |
| Liu et al. [46] | BM3D method + Graph shortest path + CNN | ||
| Graph-based methods | Rao et al. [22] | IOWA reference algorithm + U-Net | |
| Hybrid methods | Lu et al. [47] | Graph-cut algorithm + FCN + Random forest | |
| Montuoro et al. [48] | Unsupervised representation + Auto-context loop + Graph-theoretic segmentation | ||
| Unsupervised learning algorithms | Gopinath and Sivaswamy [49] | CNN trained with generalized motion patterns + Clustering | |
| He et al. [50] | Intra- and inter-slice contrastive learning network (ISCLNet) + CNN |
| Research Work | Dataset | Backbone | Loss Function | IRF | SRF | PED |
|---|---|---|---|---|---|---|
| Dice (%) | Dice (%) | Dice (%) | ||||
| Hassan et al. [8] | RETOUCH | U-Net | Dice loss | 90.90 | 91.30 | 91.80 |
| Ye et al. [9] | RETOUCH | U-Net | Combination of cross-entropy and Dice loss | 73.17 | 79.70 | 71.06 |
| Schlegl et al. [19] | Private | FCN | Softmax loss | 77.00 | 79.00 | N/A |
| Gao et al. [20] | Private | FCN | Combination of area and softmax loss | N/A | 95.30 | 91.90 |
| Lee et al. [21] | Private | U-Net | ReLu, sigmoid loss | 72.90 | N/A | N/A |
| Rao et al. [22] | Private | FCN | ReLu, sigmoid loss | N/A | 91.00 | N/A |
| Yang et al. [23] | Private | U-Net | Combination of binary cross-entropy, Dice, and diff loss | N/A | 96.20 | N/A |
| Bao et al. [24] | Private | U-Net | Combination of binary cross-entropy and Dice loss | N/A | N/A | 79.17 |
| Pawan et al. [25] | Private | SegCaps | Margin loss | N/A | 94.04 | N/A |
| Hu et al. [26] | Private | ResNet50 | Cross-entropy loss | N/A | 87.59 | 73.71 |
| Venhuizen et al. [27] | Private | FCN | Weight map loss | 75.40 | N/A | N/A |
| Chen et al. [28] | RETOUCH | Faster R-CNN | Softmax and smooth L1 loss | 70.44 | 58.83 | 70.31 |
| Sappa et al. [32] | RETOUCH | FCN | Combination of softmax and cross entropy loss | 78.95 | 90.90 | 95.78 |
| Girish et al. [33] | OPTIMA | DSCN | Weight map loss | 74.00 | N/A | N/A |
| Liu et al. [34] | RETOUCH | FCN | Combination of Dice loss, cross-entropy, regression and consistency loss | 73.60 | 75.57 | 73.93 |
| Xing et al. [36] | RETOUCH | FCN | Shape prior loss function | 79.00 | 74.00 | 77.00 |
| Kang et al. [38] | RETOUCH | U-Net | Maxout loss | 86.00 | 92.67 | 91.33 |
| Tennakoon et al. [39] | RETOUCH | U-Net | Combination of cross-entropy, Dice loss, and adversarial loss | 69.00 | 67.00 | 85.00 |
| Rashno et al. [45] | RETOUCH | CNN | ReLu, tanh loss | 85.45 | 81.30 | 84.08 |
| Lu et al. [47] | RETOUCH | FCN | Combination of softmax and cross entropy loss | 71.90 | 75.53 | 72.06 |
| Montuoro et al. [48] | Duke | Unsupervised 3D-layer | Probability map | 76.00 | 76.00 | N/A |
| Gopinath et al. [49] | OPTIMA | CNN | Weight binary cross entropy loss | 71.00 | N/A | N/A |
| He et al. [50] | RETOUCH | ISCLNet | Inter-slice loss, cross-entropy loss, and intra-slice loss | N/A | 73.16 | 69.42 |
| Research Work | Dataset | Backbone | Loss Function | Fluid in Dice (%) |
|---|---|---|---|---|
| Ma et al. [43] | Private | U-Net+FCN | Combination of weighted Dice loss and the weighted logistic loss | 51.32 |
| Sanchez et al. [29] | Duke | Ensemble network (SEUNet, DRIU) | Cross-entropy, Dice, Jaccard loss | 62.45 |
| Roy et al. [37] | Duke | U-Net | Combination of weighted logistic regression and Dice loss | 77.00 |
| Liu et al. [40] | Duke | U-Net | Combination of cross entropy, Dice, adversarial, and semi-supervised loss | 80.00 |
| Liu et al. [46] | Private | CNN | Relu and softmax loss | 81.10 |
| Hao et al. [41] | Duke | U-Net | Combination of weighted cross-entropy, Dice and mutex Dice loss | 81.00 |
| Chen et al. [42] | Public | U-Net | Dice loss | 94.21 |
| Wang et al. [30] | Private | DeepLab | Cross-entropy loss | 95.43 |
| Li et al. [56] | Private | 3D U-Net | Combination of weighted loss and focal loss | 95.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, M.; Bao, G.; Sang, X.; Wu, Y. Recent Advanced Deep Learning Architectures for Retinal Fluid Segmentation on Optical Coherence Tomography Images. Sensors 2022, 22, 3055. https://doi.org/10.3390/s22083055
Lin M, Bao G, Sang X, Wu Y. Recent Advanced Deep Learning Architectures for Retinal Fluid Segmentation on Optical Coherence Tomography Images. Sensors. 2022; 22(8):3055. https://doi.org/10.3390/s22083055
Chicago/Turabian StyleLin, Mengchen, Guidong Bao, Xiaoqian Sang, and Yunfeng Wu. 2022. "Recent Advanced Deep Learning Architectures for Retinal Fluid Segmentation on Optical Coherence Tomography Images" Sensors 22, no. 8: 3055. https://doi.org/10.3390/s22083055
APA StyleLin, M., Bao, G., Sang, X., & Wu, Y. (2022). Recent Advanced Deep Learning Architectures for Retinal Fluid Segmentation on Optical Coherence Tomography Images. Sensors, 22(8), 3055. https://doi.org/10.3390/s22083055