
Load-Balancing of Kubernetes-Based Edge Computing Infrastructure Using Resource Adaptive Proxy



Abstract
:1. Introduction
- We address the problem of the default load-balancing operation in K8s that cause long network delays and degrade the overall throughput in edge computing environments where the edge nodes are geographically distributed;
- To solve the aforesaid problem, we propose a novel approach called RAP that has two main features. First, RAP monitors the resources of each pod and the round-trip delay among worker nodes in the cluster required to perform resource adaptive load-balancing. Second, RAP handles requests locally as much as possible to improve the latency and throughput, and it redirects requests to remote worker nodes only when local nodes are overloaded;
- We conducted extensive evaluations that demonstrated the limitations of the default kube-proxy and the benefits of the proposed RAP algorithm in a K8s-based edge computing environment. The experimental results proved that, compared to default kube-proxy modes, RAP significantly improves the overall throughput and maintains the latency at a sufficiently low level to be suitable for latency-sensitive applications.
2. Related Work
3. Preliminaries of Kubernetes
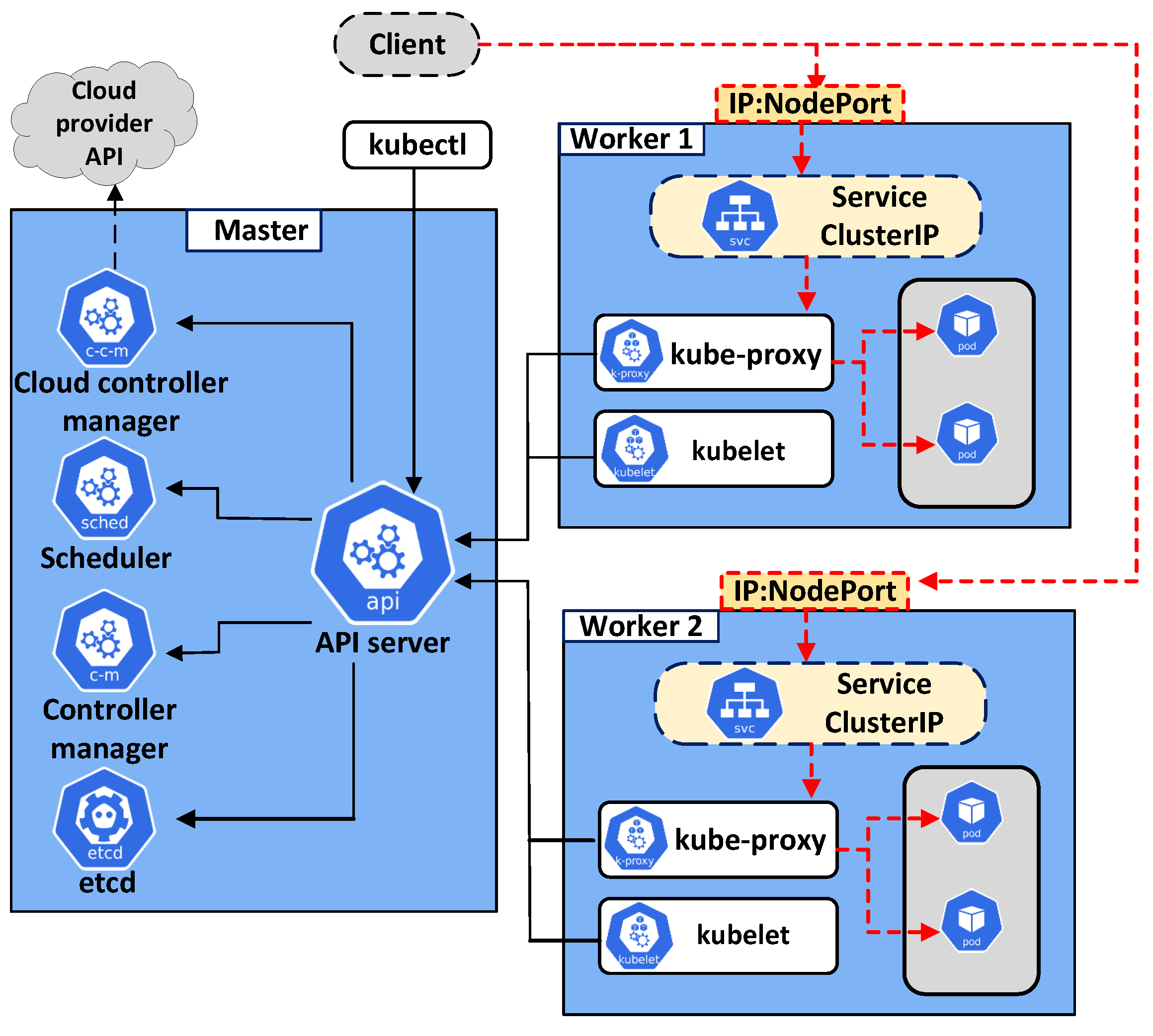
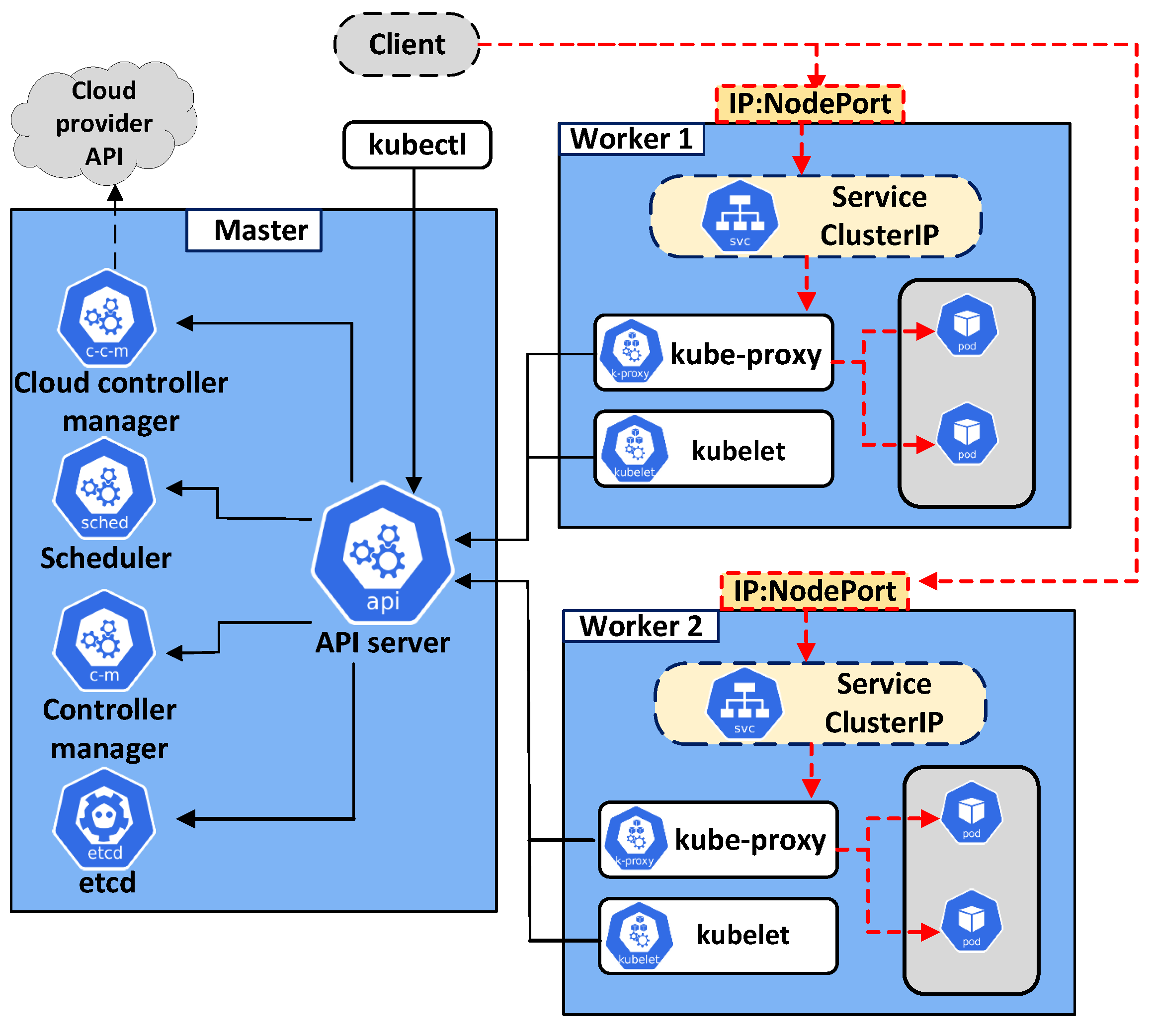
3.1. Kubernetes Architecture
- etcd: This is the key data storage component of a K8s cluster. It saves all events that occur in a cluster except for the application data;
- kube-scheduler: This is responsible for finding the best node to deploy a new pod. A suitable node is selected based on several criteria, such as the resource request by the pod, available node resources, and affinity and anti-affinity rules [27];
- kube-apiserver: Through kube-apiserver, an administrator can communicate with a K8s cluster using the kubectl command-line tool. Moreover, kube-apiserver has a connection to worker nodes to manage pod operations through the kubelet and kube-proxy tools;
- kube-controller-manager: This is a critical monitoring loop of the cluster. kube-controller-manager monitors the current state of the cluster—which must match the desired state—and adjusts resources to make the current state close to the designed state.
- kubelet: This component has a connection to kube-apiserver of the control plane to receive commands and return status reports about pods and worker nodes;
- kube-proxy: This is an essential component of each worker node. It maintains the connection between application pods and load-balancing requests in the cluster;
- container runtime: This component is used to execute containers and manage the container images on each worker node. The container runtime must be installed on each node to deploy pods.
3.2. kube-proxy
4. Resource Adaptive Proxy (RAP)
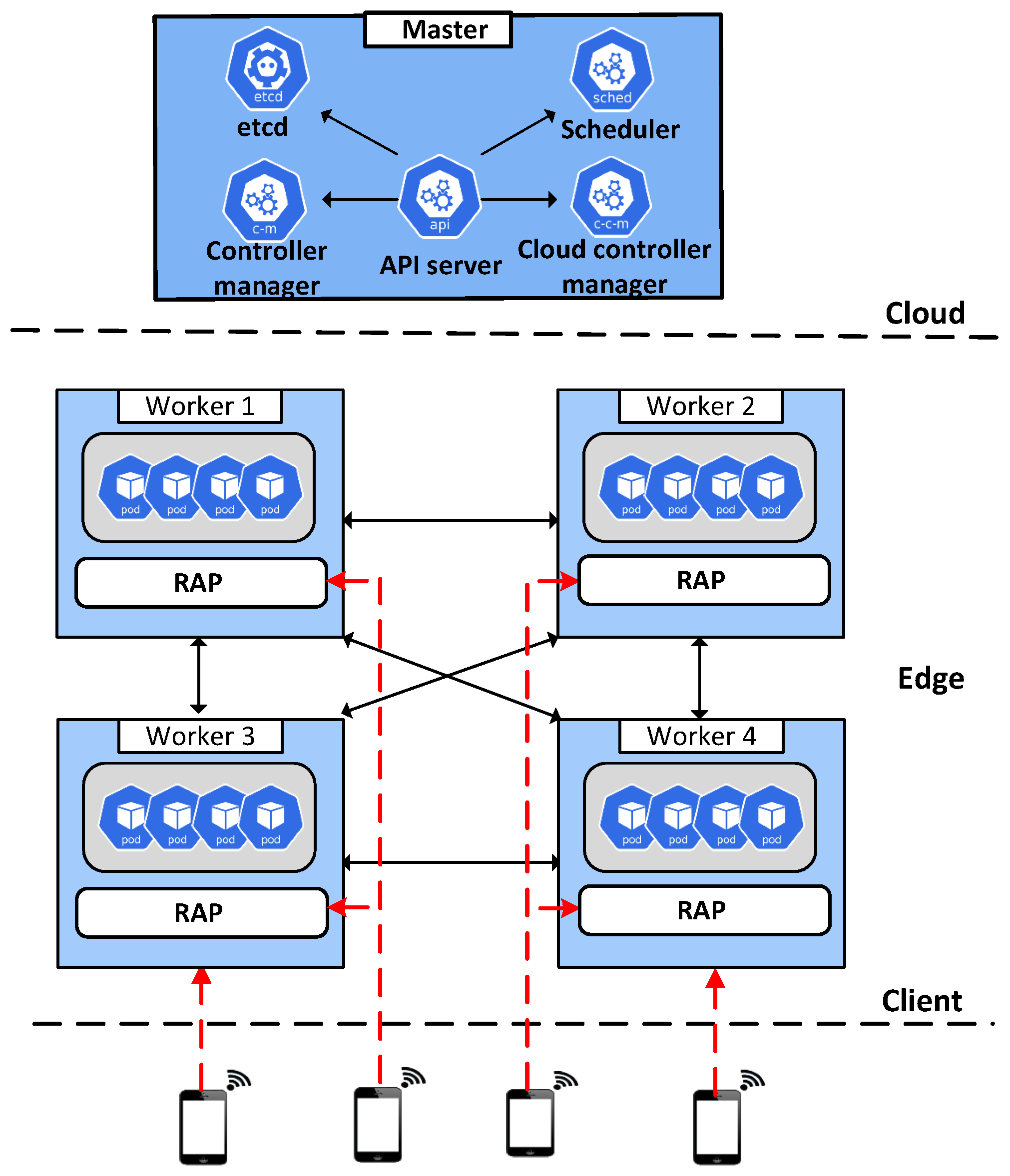
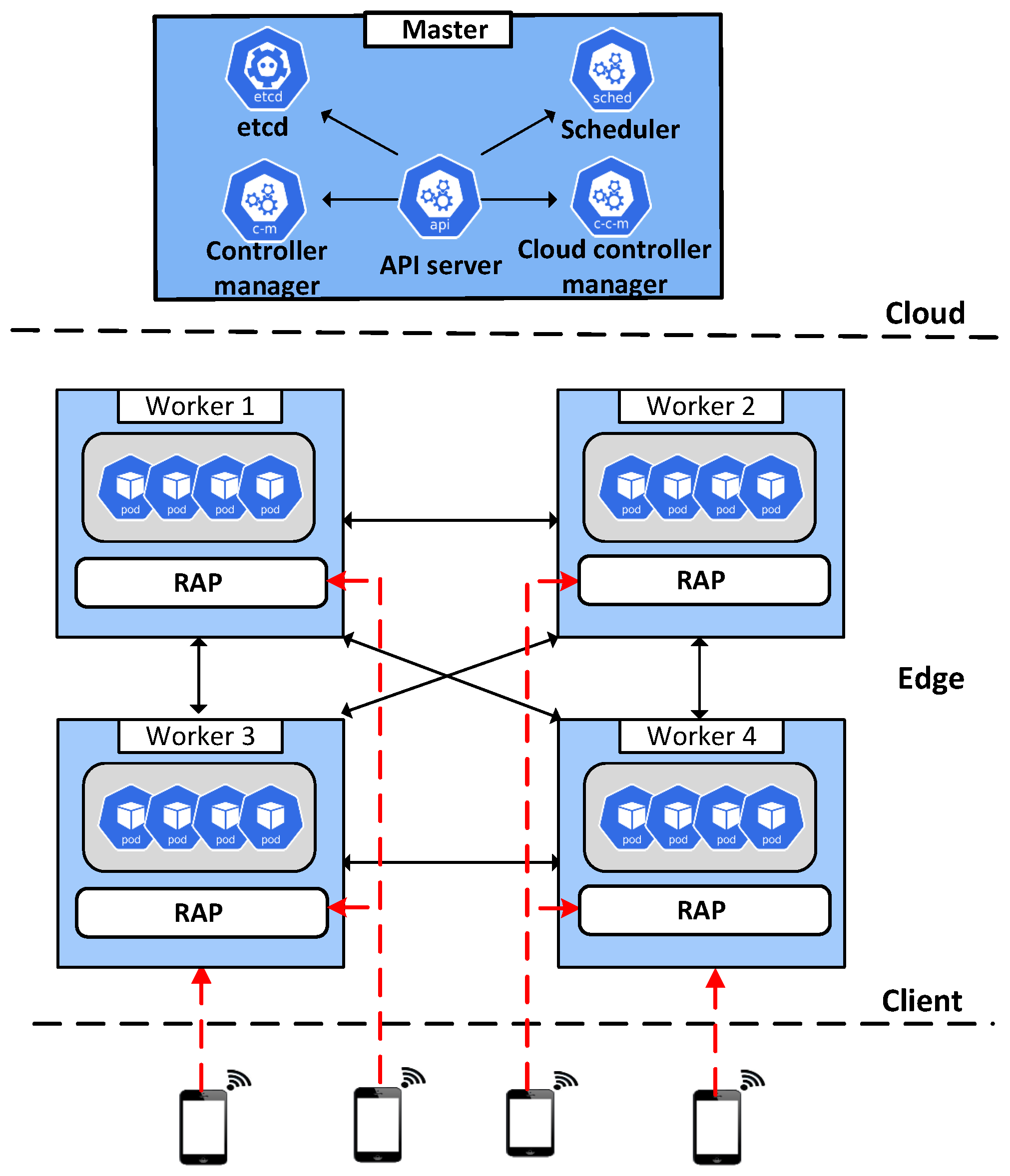
4.1. Kubernetes-Based Edge Computing Architecture
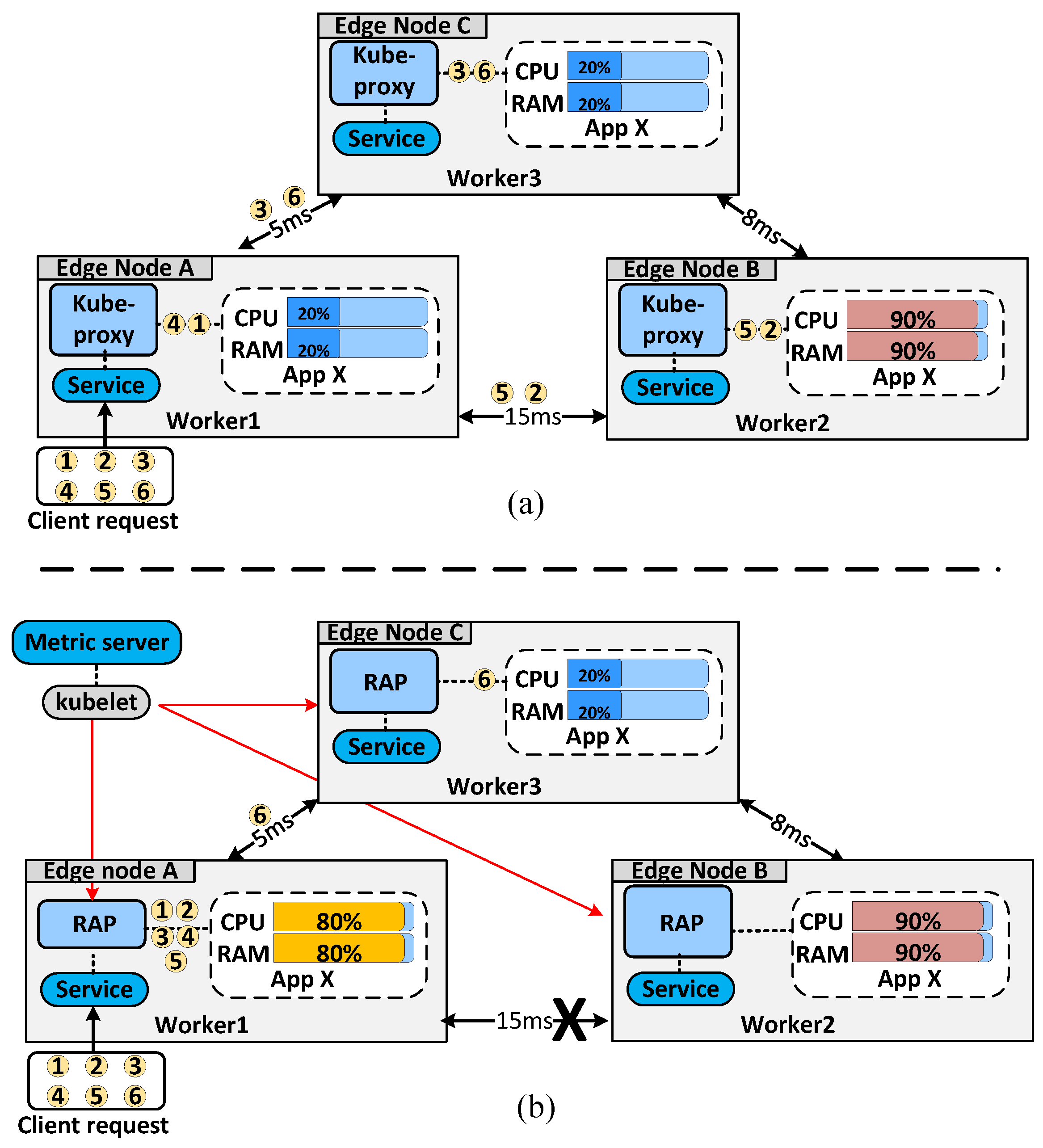
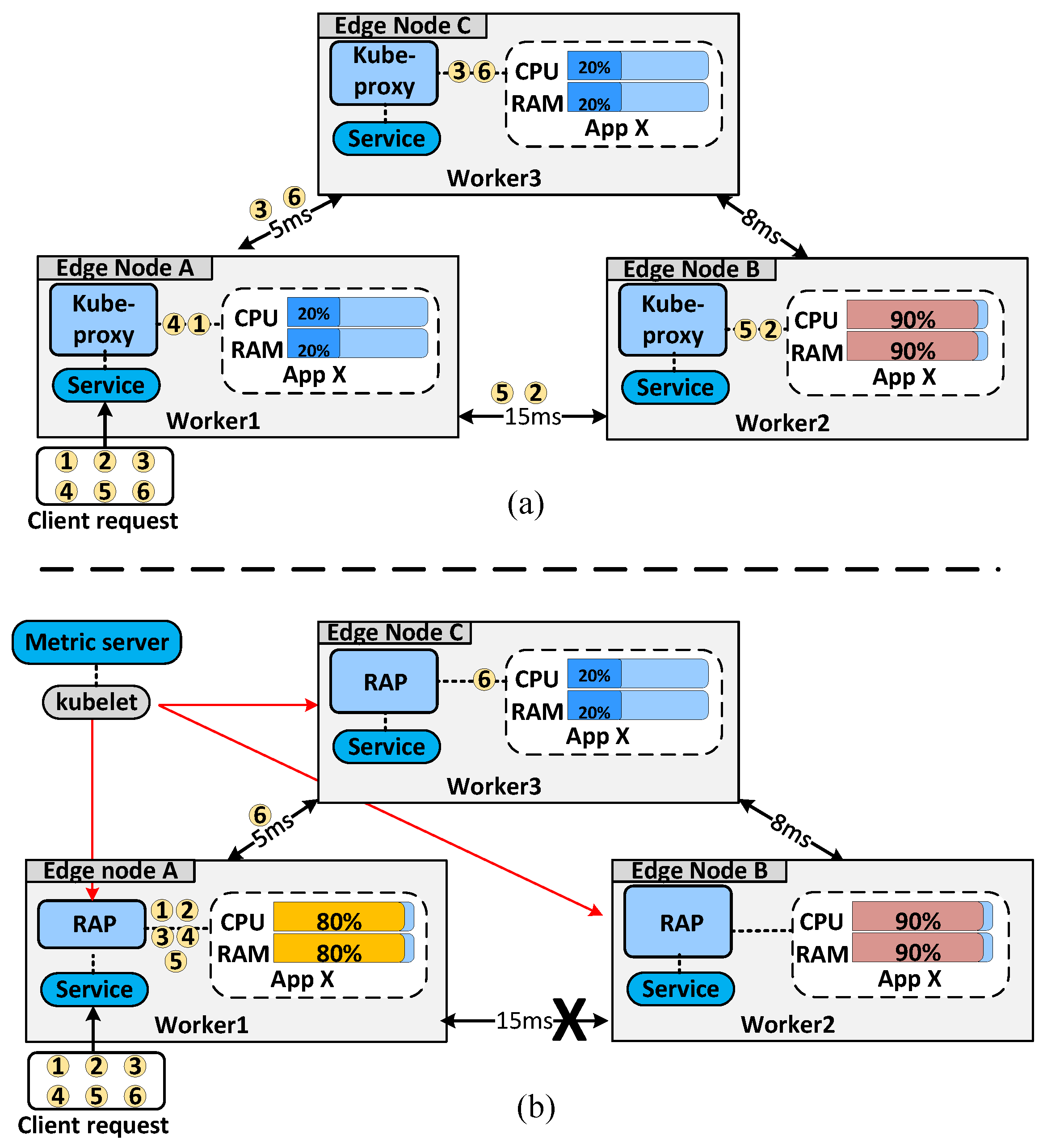
4.2. RAP Workflow and Algorithm
| Algorithm 1 Resource Adaptive Proxy (RAP) |
|
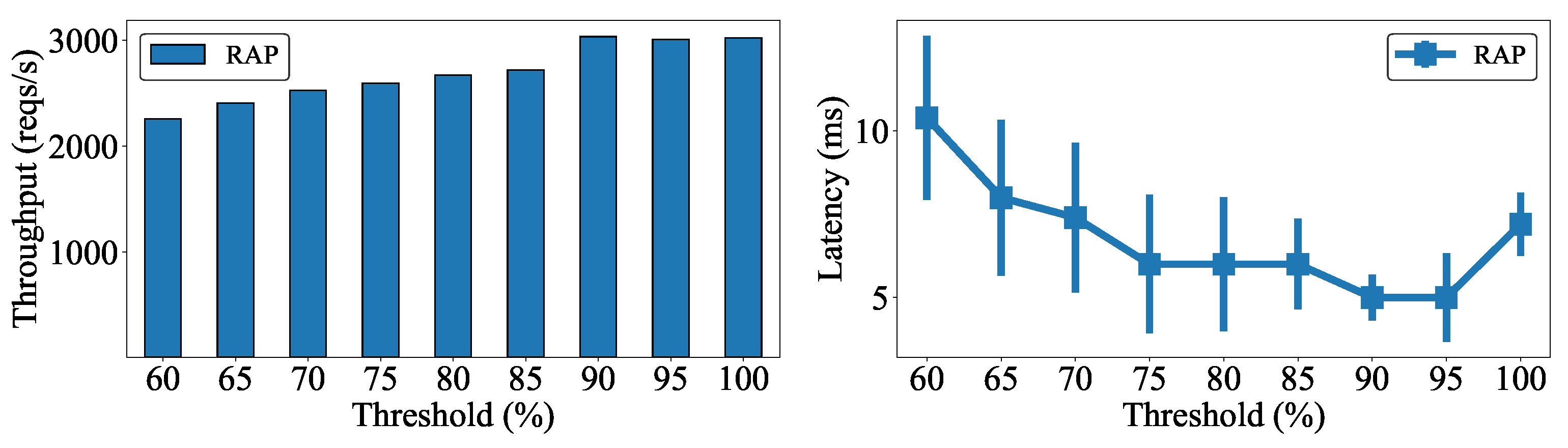
5. Performance Evaluations
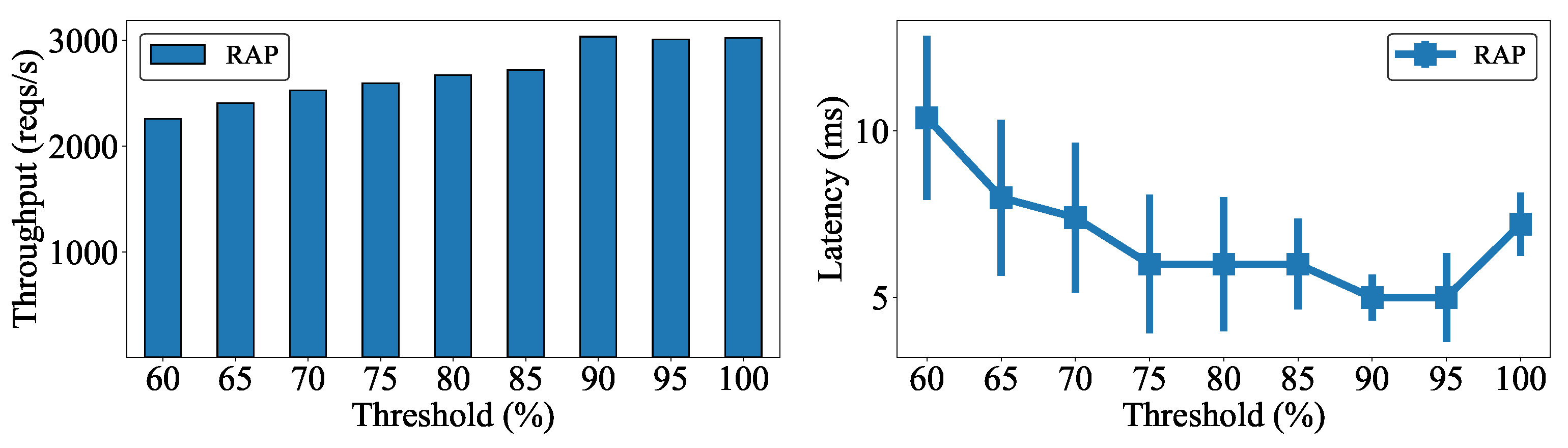
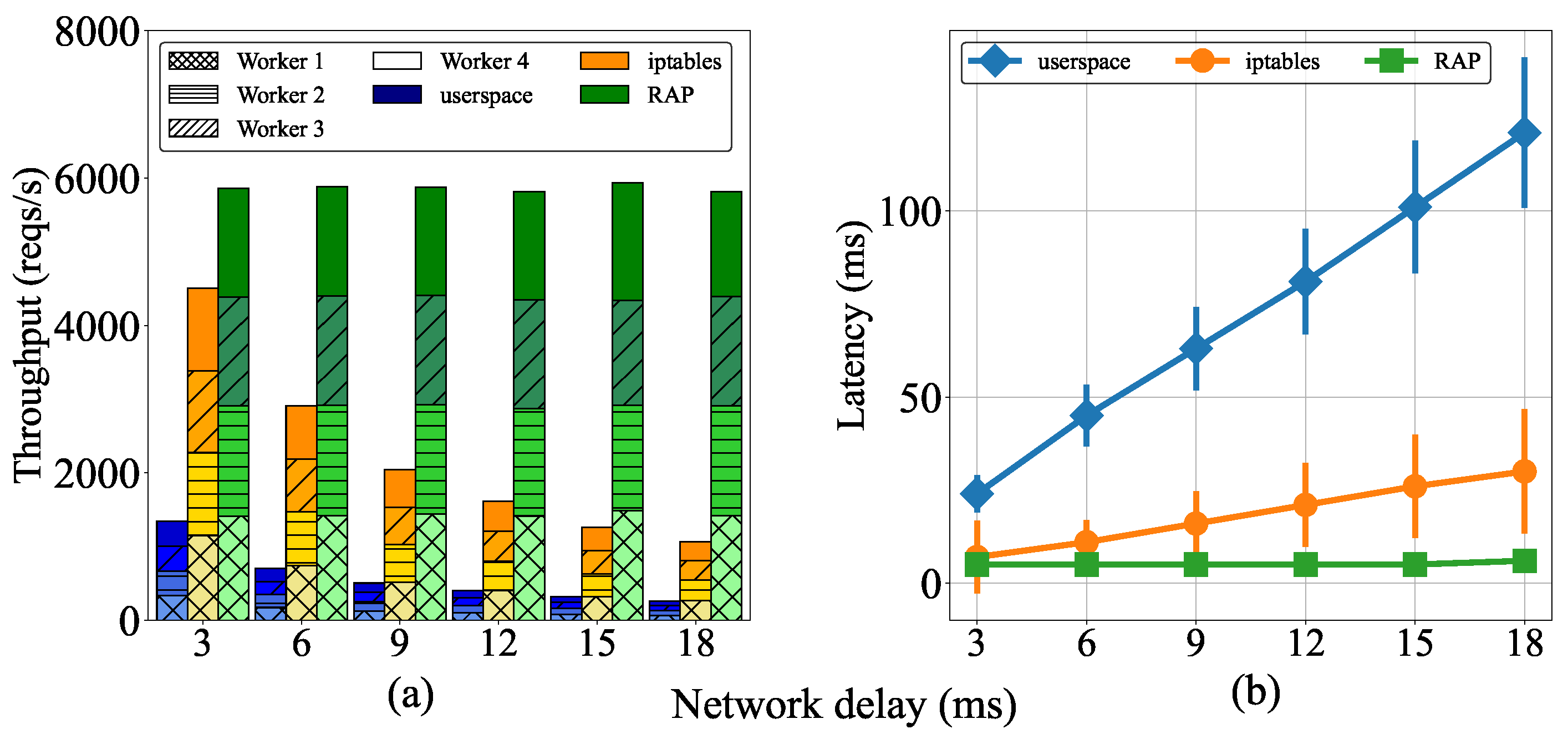
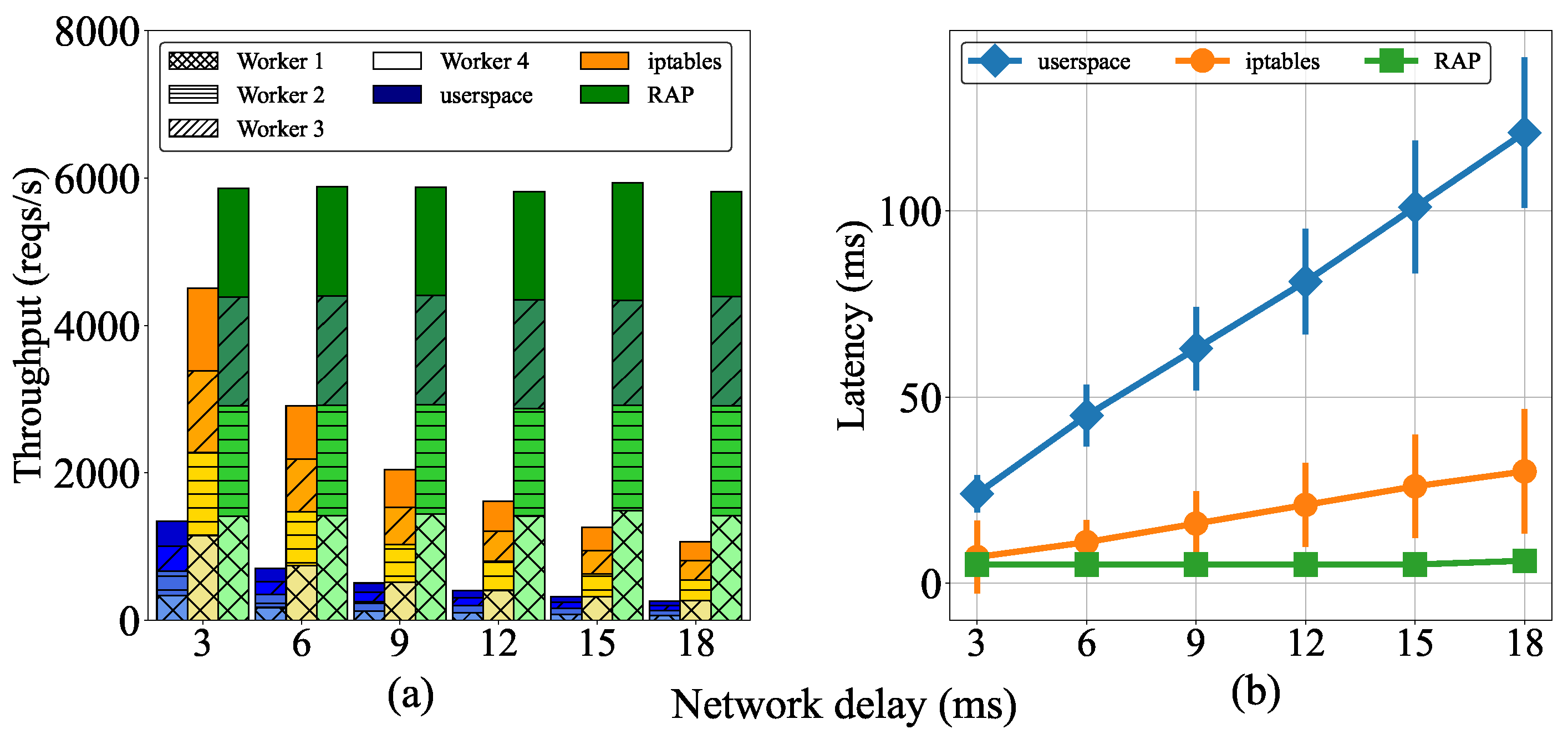
5.1. Effect of Delay between Worker Nodes on Cluster Performance
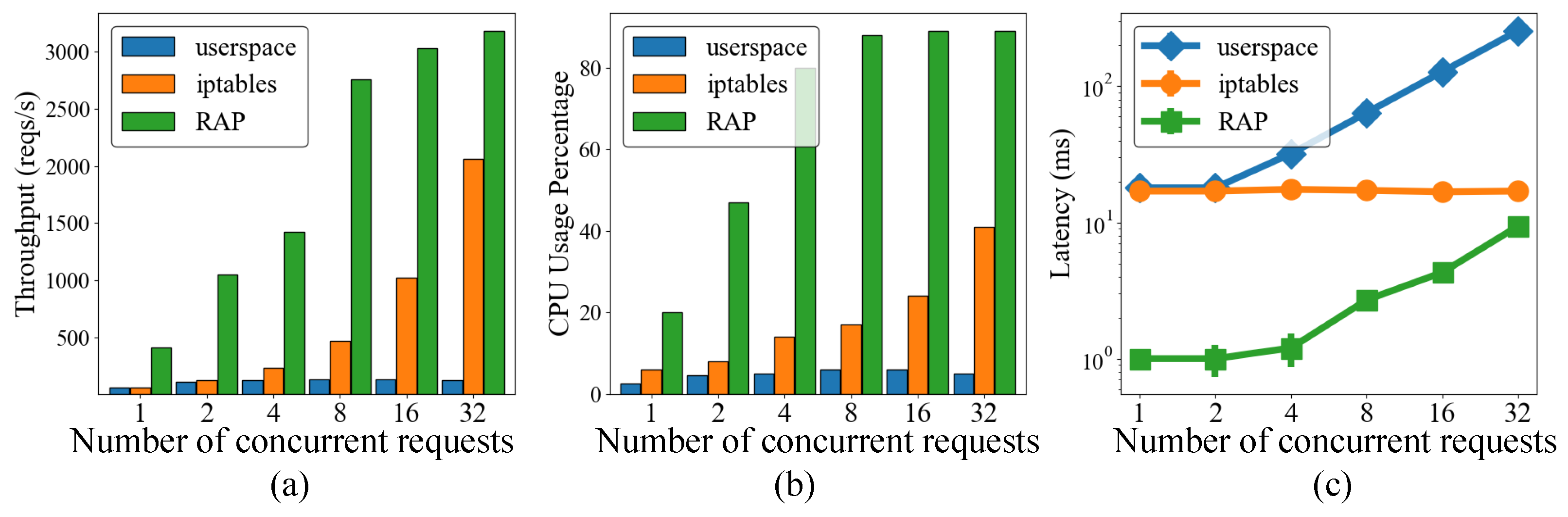
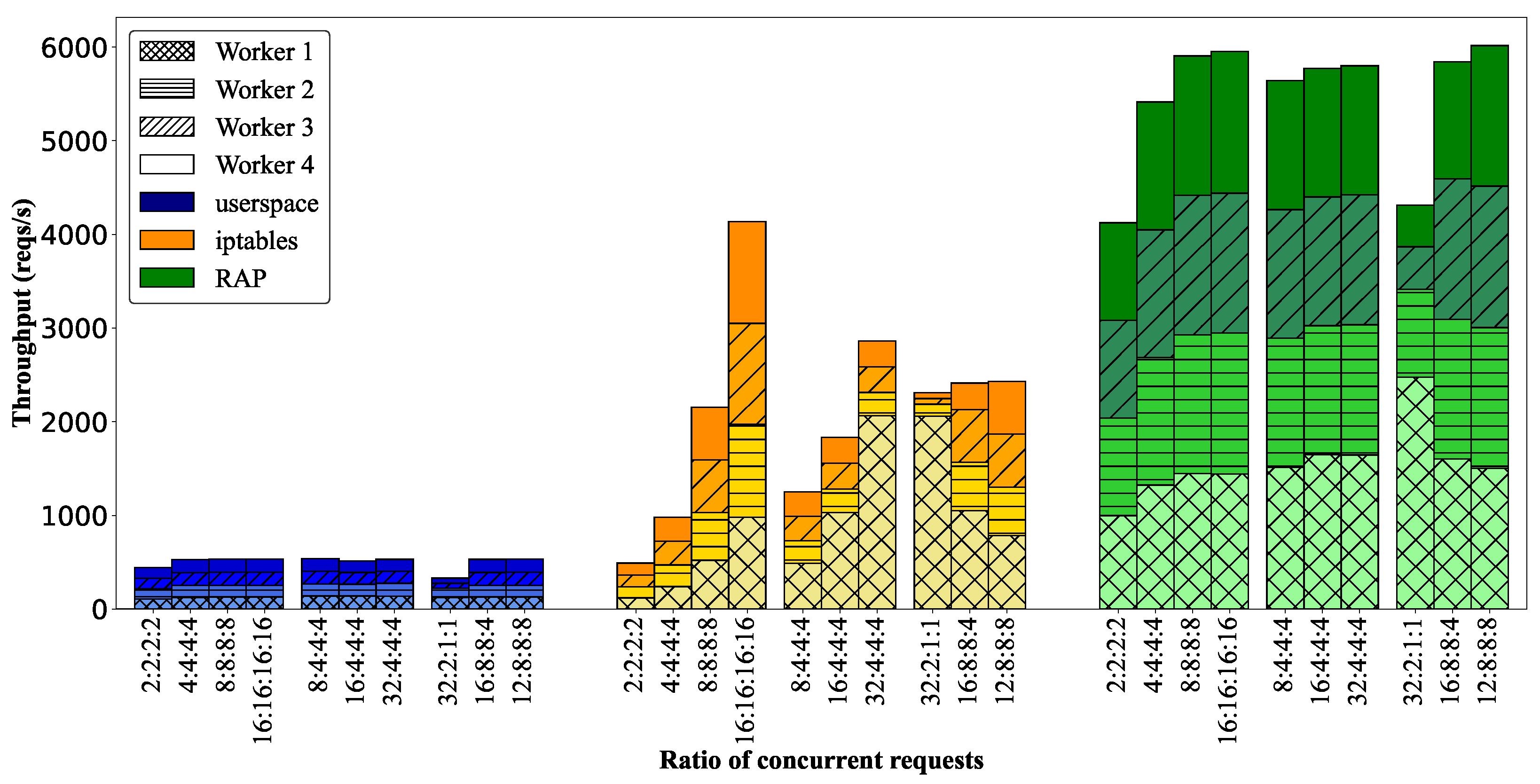
5.2. Effect of Client Requests on Cluster Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Pan, J.; McElhannon, J. Future Edge Cloud and Edge Computing for Internet of Things Applications. IEEE Internet Things J. 2017, 5, 439–449. [Google Scholar] [CrossRef]
- Hwang, J.; Nkenyereye, L.; Sung, N.; Kim, J.; Song, J. IoT Service Slicing and Task Offloading for Edge Computing. IEEE Internet Things J. 2021, 8, 11526–11547. [Google Scholar] [CrossRef]
- Felter, W.; Ferreira, A.; Rajamony, R.; Rubio, J. An updated performance comparison of virtual machines and linux containers. In Proceedings of the 2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Philadelphia, PA, USA, 29–31 March 2015; pp. 171–172. [Google Scholar]
- Xu, H.; Huang, W.; Zhou, Y.; Yang, D.; Li, M.; Han, Z. Edge Computing Resource Allocation for Unmanned Aerial Vehicle Assisted Mobile Network With Blockchain Applications. IEEE Trans. Wirel. Commun. 2021, 20, 3107–3121. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog Computing and Its Role in the Internet of Things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, MCC ’12, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar] [CrossRef]
- Zhou, N.; Georgiou, Y.; Pospieszny, M.; Zhong, L.; Zhou, H.; Niethammer, C.; Pejak, B.; Marko, O.; Hoppe, D. Container orchestration on HPC systems through Kubernetes. J. Cloud Comput. 2021, 10, 16. [Google Scholar] [CrossRef]
- Pahl, C. Containerization and the PaaS Cloud. J. Cloud Comput. 2015, 2, 24–31. [Google Scholar] [CrossRef]
- Divya, V.; Sri, R.L. Docker-Based Intelligent Fall Detection Using Edge-Fog Cloud Infrastructure. IEEE Internet Things J. 2020, 8, 8133–8144. [Google Scholar] [CrossRef]
- Khan, A. Key Characteristics of a Container Orchestration Platform to Enable a Modern Application. IEEE Cloud Comput. 2017, 4, 42–48. [Google Scholar] [CrossRef]
- Kaur, K.; Garg, S.; Kaddoum, G.; Ahmed, S.H.; Atiquzzaman, M. KEIDS: Kubernetes-Based Energy and Interference Driven Scheduler for Industrial IoT in Edge-Cloud Ecosystem. IEEE Internet Things J. 2020, 7, 4228–4237. [Google Scholar] [CrossRef]
- Zhao, D.; Mohamed, M.; Ludwig, H. Locality-aware scheduling for containers in cloud computing. IEEE Trans. Cloud Comput. 2018, 8, 635–646. [Google Scholar] [CrossRef]
- Yin, L.; Luo, J.; Luo, H. Tasks scheduling and resource allocation in fog computing based on containers for smart manufacturing. IEEE Trans. Ind. Inform. 2018, 14, 4712–4721. [Google Scholar] [CrossRef]
- Nguyen, N.; Kim, T. Toward Highly Scalable Load Balancing in Kubernetes Clusters. IEEE Commun. Mag. 2020, 58, 78–83. [Google Scholar] [CrossRef]
- De Donno, M.; Tange, K.; Dragoni, N. Foundations and Evolution of Modern Computing Paradigms: Cloud, IoT, Edge, and Fog. IEEE Access 2019, 7, 150936–150948. [Google Scholar] [CrossRef]
- Baktir, A.C.; Ozgovde, A.; Ersoy, C. How Can Edge Computing Benefit From Software-Defined Networking: A Survey, Use Cases, and Future Directions. IEEE Commun. Surv. Tutor. 2017, 19, 2359–2391. [Google Scholar] [CrossRef]
- Abouaomar, A.; Cherkaoui, S.; Mlika, Z.; Kobbane, A. Resource Provisioning in Edge Computing for Latency-Sensitive Applications. IEEE Internet Things J. 2021, 8, 11088–11099. [Google Scholar] [CrossRef]
- Phan, L.A.; Nguyen, D.T.; Lee, M.; Park, D.H.; Kim, T. Dynamic fog-to-fog offloading in SDN-based fog computing systems. Future Gener. Comput. Syst. 2021, 117, 486–497. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Yeom, Y.J.; Kim, T.; Park, D.H.; Kim, S. Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration. Sensors 2020, 20, 4621. [Google Scholar] [CrossRef]
- Kayal, P. Kubernetes in Fog Computing: Feasibility Demonstration, Limitations and Improvement Scope: Invited Paper. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Santos, J.; Wauters, T.; Volckaert, B.; De Turck, F. Towards delay-aware container-based Service Function Chaining in Fog Computing. In Proceedings of the NOMS 2020—2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Toka, L. Ultra-Reliable and Low-Latency Computing in the Edge with Kubernetes. J. Grid Comput. 2021, 19, 31. [Google Scholar] [CrossRef]
- Wojciechowski, Ł.; Opasiak, K.; Latusek, J.; Wereski, M.; Morales, V.; Kim, T.; Hong, M. NetMARKS: Network Metrics-AwaRe Kubernetes Scheduler Powered by Service Mesh. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Nguyen, N.D.; Phan, L.A.; Park, D.H.; Kim, S.; Kim, T. ElasticFog: Elastic Resource Provisioning in Container-Based Fog Computing. IEEE Access 2020, 8, 183879–183890. [Google Scholar] [CrossRef]
- Phuc, L.H.; Phan, L.A.; Kim, T. Traffic-Aware Horizontal Pod Autoscaler in Kubernetes-Based Edge Computing Infrastructure. IEEE Access 2022, 10, 18966–18977. [Google Scholar] [CrossRef]
- Rossi, F.; Cardellini, V.; Presti, F.L.; Nardelli, M. Geo-distributed efficient deployment of containers with Kubernetes. Comput. Commun. 2020, 159, 161–174. [Google Scholar] [CrossRef]
- Kubernetes. Kubernetes Components. Available online: https://kubernetes.io/ (accessed on 16 February 2022).
- Caminero, A.C.; Muñoz-Mansilla, R. Quality of Service Provision in Fog Computing: Network-Aware Scheduling of Containers. Sensors 2021, 21, 3978. [Google Scholar] [CrossRef] [PubMed]
- Netto, H.V.; Lung, L.C.; Correia, M.; Luiz, A.F.; de Souza, L.M.S. State machine replication in containers managed by Kubernetes. J. Syst. Archit. 2017, 73, 53–59. [Google Scholar] [CrossRef]
- Nguyen, N.D.; Kim, T. Balanced Leader Distribution Algorithm in Kubernetes Clusters. Sensors 2021, 21, 869. [Google Scholar] [CrossRef] [PubMed]
- Kubernetes. Kubernetes Service. Available online: https://kubernetes.io/ (accessed on 16 February 2022).
- Santos, J.; Wauters, T.; Volckaert, B.; De Turck, F. Towards Network-Aware Resource Provisioning in Kubernetes for Fog Computing Applications. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 351–359. [Google Scholar] [CrossRef] [Green Version]
- Hong, C.H.; Lee, K.; Kang, M.; Yoo, C. qCon: QoS-Aware network resource management for fog computing. Sensors 2018, 18, 3444. [Google Scholar] [CrossRef] [Green Version]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative Cloud and Edge Computing for Latency Minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Sun, X.; Ansari, N. EdgeIoT: Mobile Edge Computing for the Internet of Things. IEEE Commun. Mag. 2016, 54, 22–29. [Google Scholar] [CrossRef]
- Al-Nabhan, N.; Alenazi, S.; Alquwaifili, S.; Alzamzami, S.; Altwayan, L.; Alaloula, N.; Alowaini, R.; Al Islam, A.B.M.A. An Intelligent IoT Approach for Analyzing and Managing Crowds. IEEE Access 2021, 9, 104874–104886. [Google Scholar] [CrossRef]
- Aljanabi, S.; Chalechale, A. Improving IoT Services Using a Hybrid Fog-Cloud Offloading. IEEE Access 2021, 9, 13775–13788. [Google Scholar] [CrossRef]
- Eidenbenz, R.; Pignolet, Y.A.; Ryser, A. Latency-Aware Industrial Fog Application Orchestration with Kubernetes. In Proceedings of the 2020 Fifth International Conference on Fog and Mobile Edge Computing (FMEC), Paris, France, 20–23 April 2020; pp. 164–171. [Google Scholar] [CrossRef]
- Kubernetes Metrics Server. Available online: https://github.com/kubernetes-sigs/metrics-server (accessed on 16 February 2022).
- Apache HTTP Server Benchmarking Tool. Available online: https://httpd.apache.org/ (accessed on 16 February 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Application deployed in edge computing | |
| r | Resource parameter including CPU, RAM, and latency |
| N | Set of remote workers |
| i | Individual remote worker, where |
| Resource r of worker i | |
| Individual denominator of resource r for worker i | |
| Weight factor of resource r | |
| Score of each worker node | |
| Score of the best worker node |
| Test Cases | Requests | Note | Ratio Worker 1:Worker 2:Worker 3:Worker 4 |
|---|---|---|---|
| 1–6 | Concentrated requests | [1, 2, 4, 8, 16, 32]:0:0:0 | |
| 7 | Distributed requests | Balance requests | 2:2:2:2 |
| 8 | 4:4:4:4 | ||
| 9 | 8:8:8:8 | ||
| 10 | 16:16:16:16 | ||
| 11 | Imbalance requests | 8:4:4:4 | |
| 12 | 16:4:4:4 | ||
| 13 | 32:4:4:4 | ||
| 14 | Equal total throughput | 32:2:1:1 | |
| 15 | 16:8:8:4 | ||
| 16 | 12:8:8:8 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, Q.-M.; Phan, L.-A.; Kim, T. Load-Balancing of Kubernetes-Based Edge Computing Infrastructure Using Resource Adaptive Proxy. Sensors 2022, 22, 2869. https://doi.org/10.3390/s22082869
Nguyen Q-M, Phan L-A, Kim T. Load-Balancing of Kubernetes-Based Edge Computing Infrastructure Using Resource Adaptive Proxy. Sensors. 2022; 22(8):2869. https://doi.org/10.3390/s22082869
Chicago/Turabian StyleNguyen, Quang-Minh, Linh-An Phan, and Taehong Kim. 2022. "Load-Balancing of Kubernetes-Based Edge Computing Infrastructure Using Resource Adaptive Proxy" Sensors 22, no. 8: 2869. https://doi.org/10.3390/s22082869
APA StyleNguyen, Q.-M., Phan, L.-A., & Kim, T. (2022). Load-Balancing of Kubernetes-Based Edge Computing Infrastructure Using Resource Adaptive Proxy. Sensors, 22(8), 2869. https://doi.org/10.3390/s22082869