
MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review





Abstract
:1. Introduction
- Spatiotemporal calibration: The premise of fusion is to be in the same time and space, which means that mmWave radar and vision information need to be calibrated.
- Information fusion: Object detection algorithms that fuse the sensing information of different sensors to achieve the optimal performance are essential.
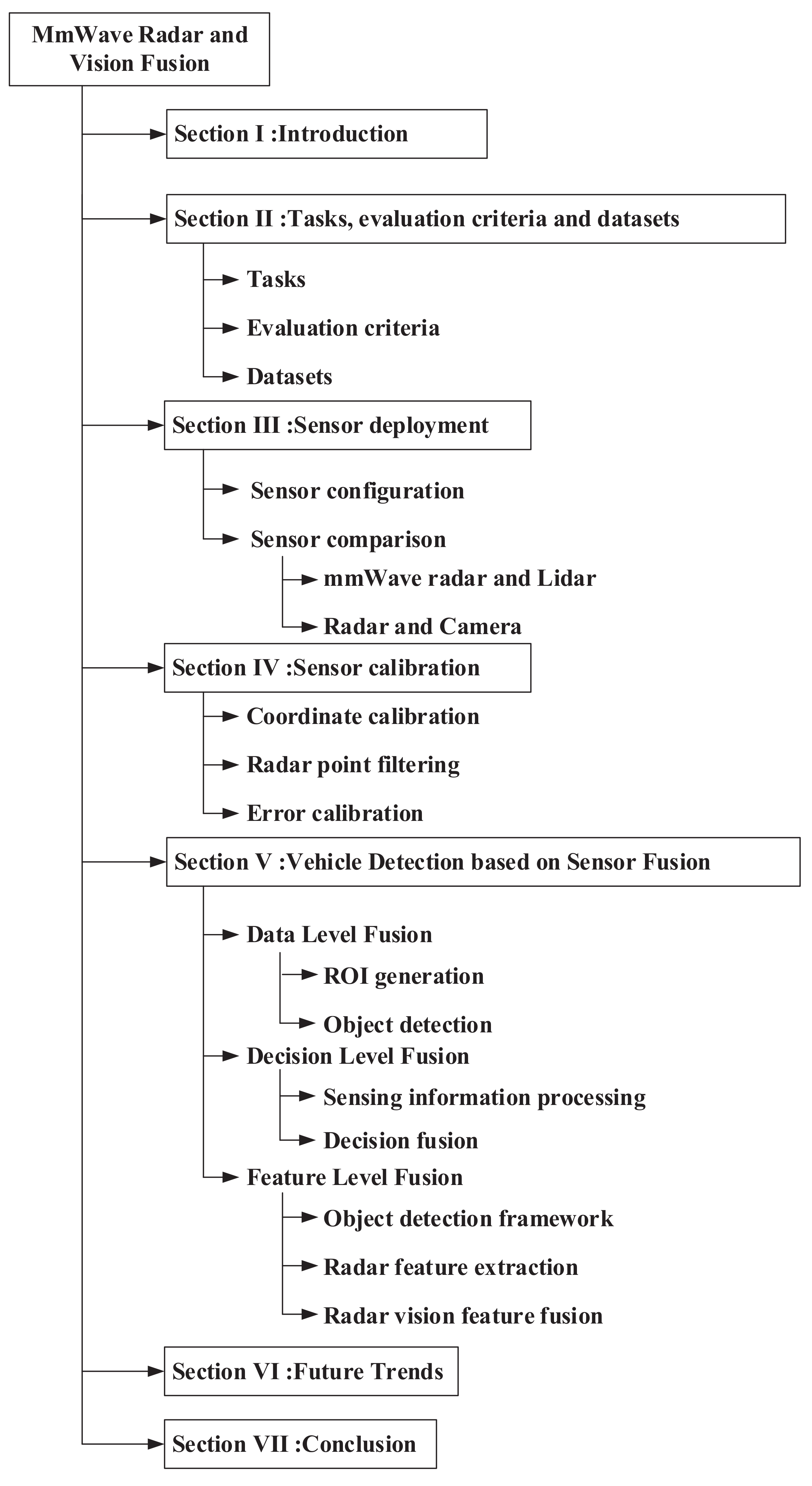
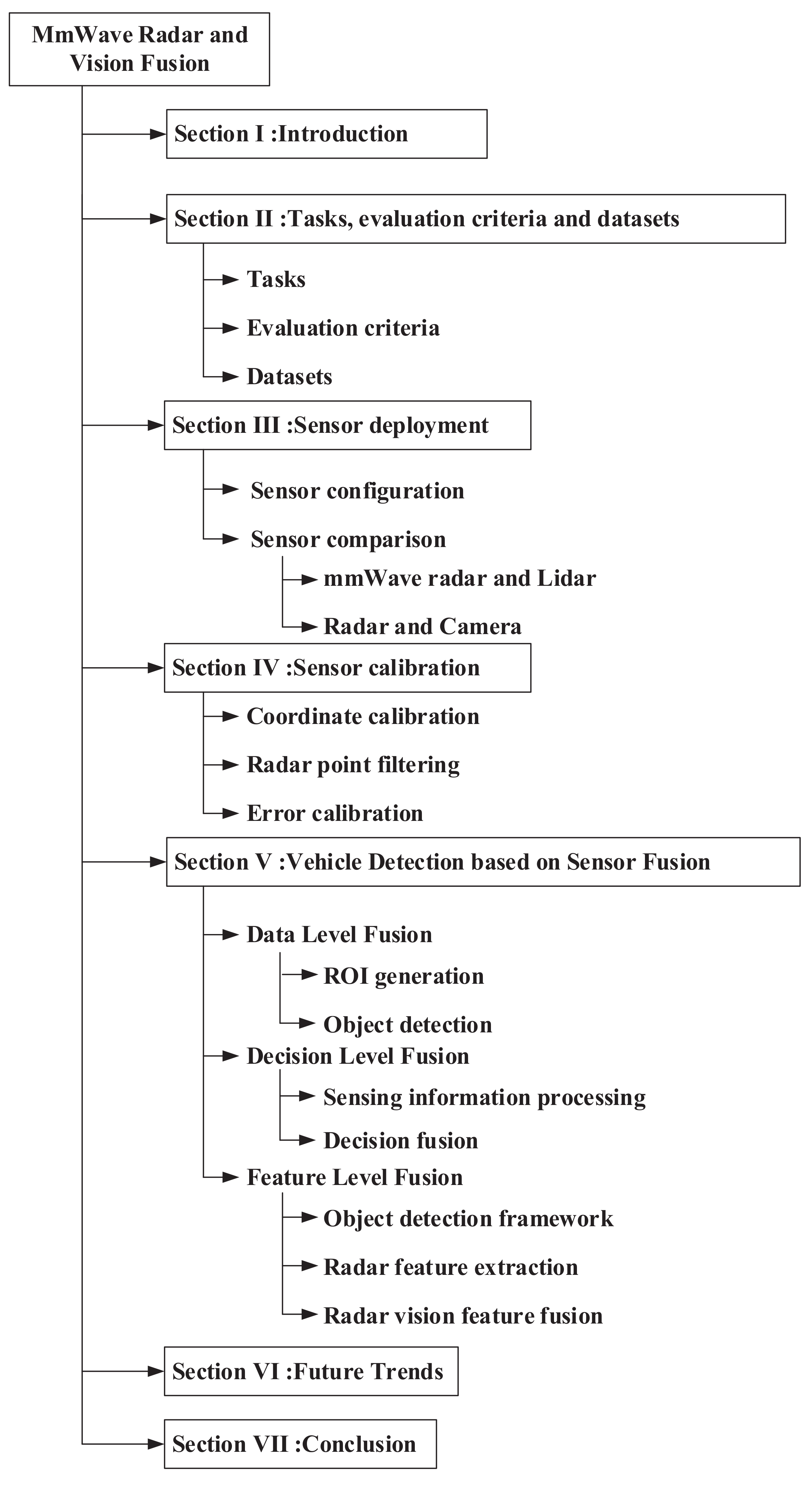
2. Tasks, Evaluation Criteria, and Datasets
2.1. Tasks
2.2. Evaluation Criteria
2.3. Datasets
2.3.1. Apolloscape
2.3.2. KITTI
2.3.3. Cityscapes
2.3.4. Waymo Open Dataset
2.3.5. nuScenes
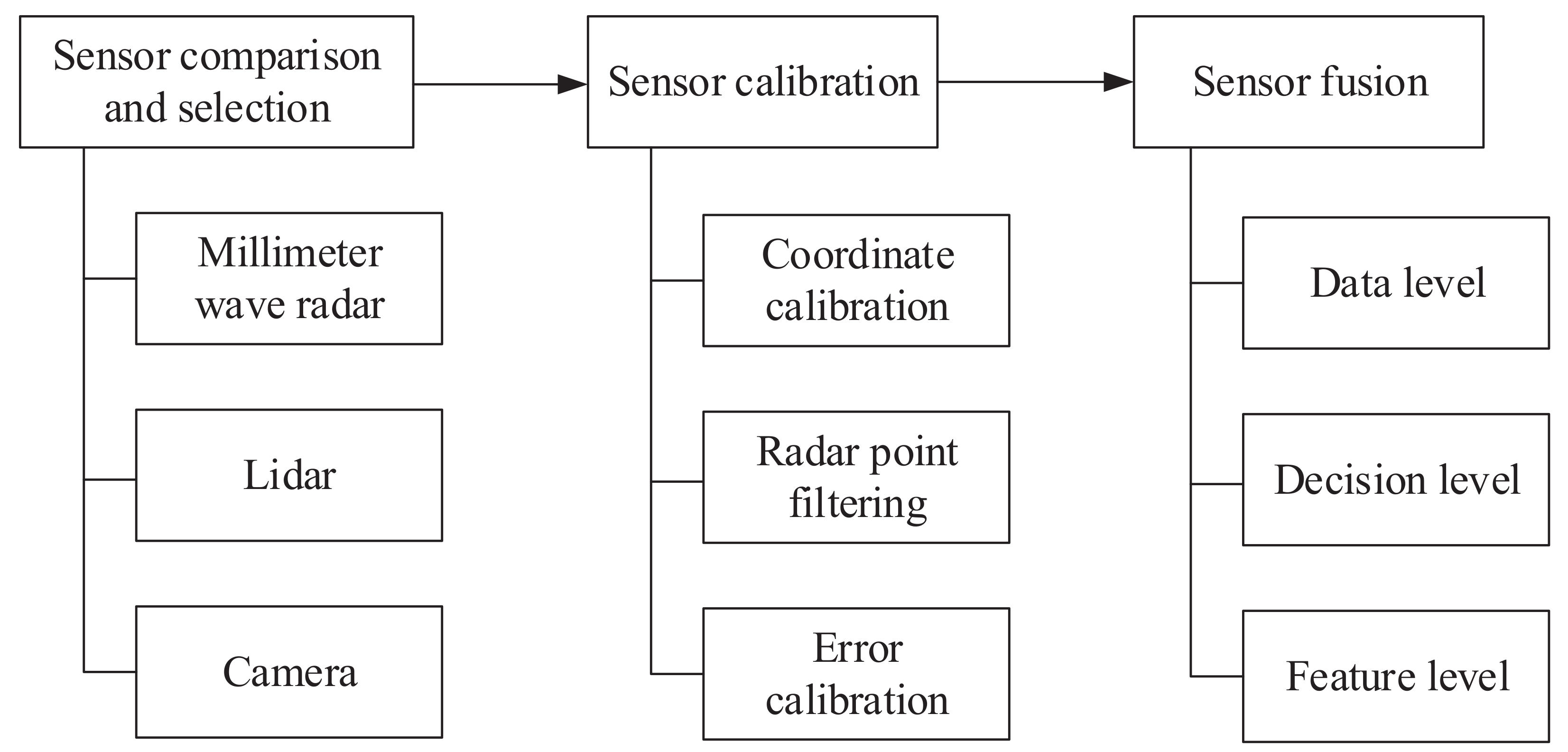
3. Sensor Deployment
3.1. Sensor Configuration
3.2. Sensor Comparison
3.2.1. mmWave Radar and Lidar
- The mmWave radar can detect obstacles within 250 m, which is of vital importance to the security of autonomous driving, whereas the detection range of lidar is within 150 m [41].
- The mmWave radar can measure the relative velocity of the target vehicle based on the Doppler effect with the resolution of 0.1 m/s, which is critical for vehicle decision-making in autonomous driving [41].
- Lidar has relatively higher angle resolution and detection accuracy than mmWave radar. Additionally, the mmWave radar data is sparser.
- The measurements of lidar contain semantic information and satisfy the perception requirements of advanced autonomous driving, which mmWave radar lacks.
- The clutter cannot be completely filtered out from mmWave radar measurements, leading to errors in radar signal processing.
3.2.2. Radar and Camera
4. Sensor Calibration
4.1. Coordinate Calibration
- Coordinate transformation method: The coordinate transformation method unifies the radar information and vision information under the same coordinate system through matrix operations. In [46], space calibration was completed by the method of coordinate transformation according to the spatial position coordinates of mmWave radar and vision sensors. For the time inconsistency caused by different sensor sampling rates, the thread synchronization method is adopted to realize the acquisition of the image frame and mmWave radar data simultaneously. Ref. [45] used the point alignment method based on pseudo-inverse, which obtains the coordinate transformation matrix by using the least square method. The traditional coordinate transformation cannot generate the accurate position of the target, which brings errors to the final results. In [53], Wang et al. proposed a calibration experiment to project the real coordinates into the radar detection map without special tools and radar reflection intensity, which weakens the dependence on calibration errors.
- Sensor verification method: The sensor verification method calibrates multiple sensors to each other with the detection information of different sensors on the same object. In [42], the sensor verification consists of two steps. First, the target list is generated by radar, and then the list is verified by the vision information. In [47], after the coordinate transformation of radar, the image is first searched roughly and then compared with the radar information. The result of the comparison divides the targets into two types: matched target and unmatched target. In [44], Streubel et al. designed a fusion time slot to match the objects detected by radar and vision in the same time slot.
- Vision based method: In [52], the motion stereo technology was used to achieve the matching of radar objects and image objects. In [43], Huang et al. used adaptive background subtraction to detect moving targets in the image, generate candidate areas, and verify the targets by judging whether the radar points are located in the candidate areas.
4.2. Radar Point Filtering
4.3. Error Calibration
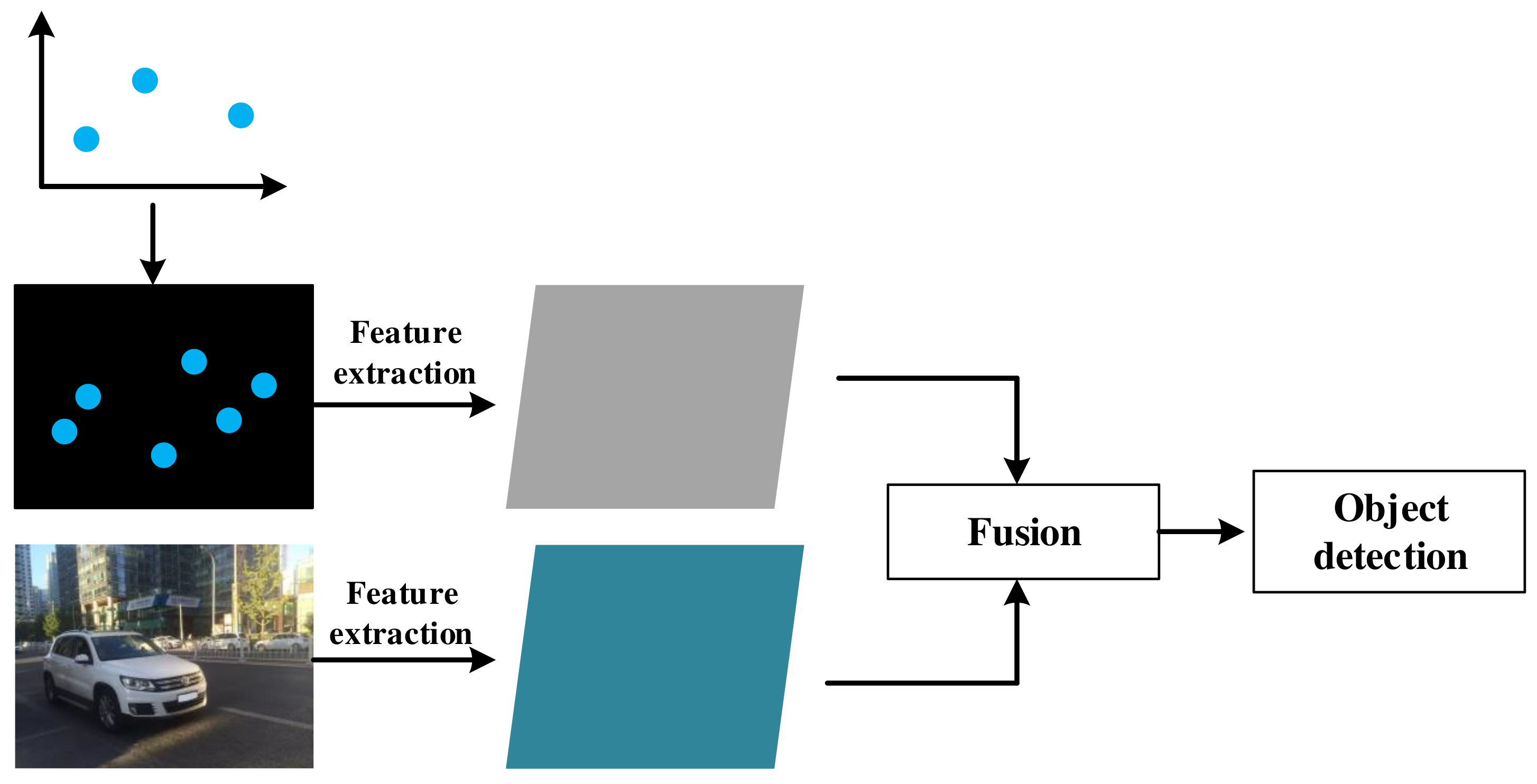
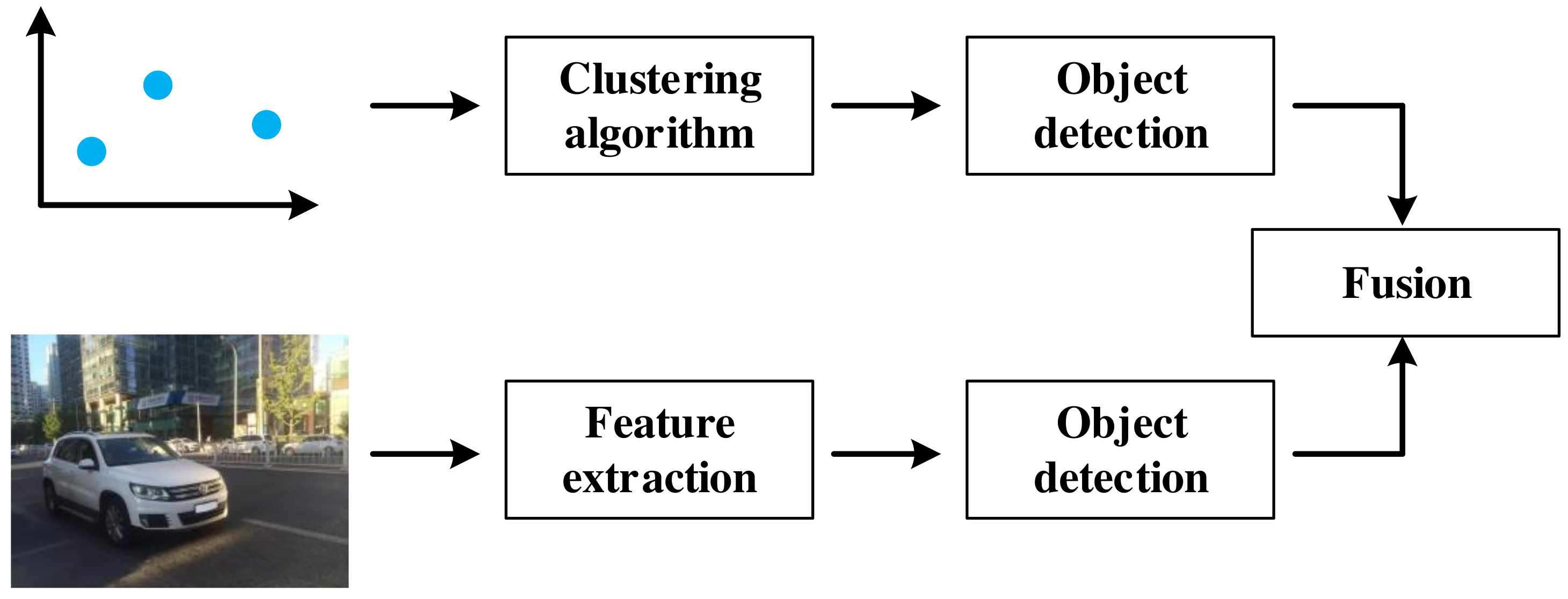
5. Vehicle Detection Based on Sensor Fusion
5.1. Data Level Fusion
5.1.1. ROI Generation
5.1.2. Object Detection
- Image Preprocessing
- Feature Extraction
- Object Classification
5.2. Decision Level Fusion
5.2.1. Sensing Information Processing
- Radar Information
- Image Object Detection
5.2.2. Decision Fusion
- Fusion Methods Based on Bayesian Theory
- Fusion Methods Based on Kalman Filter
- Fusion Methods Based on Dempster Shafer Theory
- Fusion Methods Based on Radar Validation
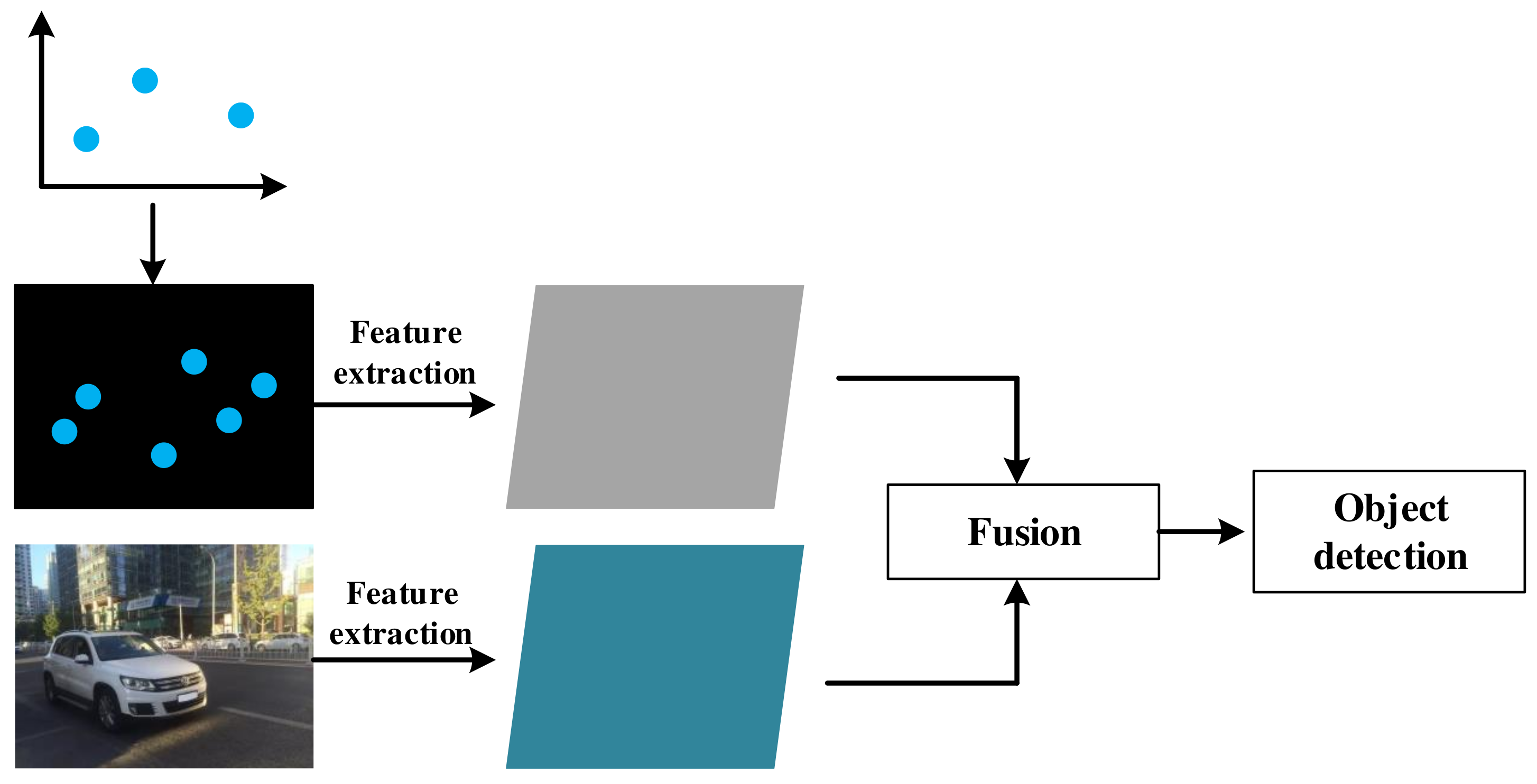
5.3. Feature Level Fusion
5.3.1. Object Detection Framework
- Detection Framework Based on CNN
- Fusion Framework Based on CNN
5.3.2. Radar Feature Extraction
5.3.3. Feature Fusion
6. Challenges and Future Trends
6.1. Challenges
6.2. Future Trends
6.2.1. 3D Object Detection in Autonomous Driving
6.2.2. Lidar in Autonomous Driving
- Object Detection
- Object Classification
- Road Detection
6.2.3. Multimodal Information Fusion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2D | Two-dimensional |
| 3D | Three-dimensional |
| ACC | Autonomous Cruise Control |
| ADAS | Advanced Driver Assistance System |
| ADS | Automated Driving System |
| AI | Artificial Intelligence |
| ALV | Autonomous Land Vehicle |
| AP | Average Precision |
| AR | Average Recall |
| CMGGAN | Conditional Multi-Generator Generative Adversarial Network |
| CNNs | Convolutional Neural Networks |
| DARPA | Defense Advanced Research Projects Agency |
| DCNN | Deep Convolutional Neural Network |
| DPM | Deformable Parts Model |
| EKF | Extended Kalman Filter |
| FCN | Fully Convolutional Neural Network |
| FFT | Fast Fourier Transform |
| FOV | Field of View |
| GPS | Global Positioning System |
| GVF | Gradient Vector Flow |
| HOG | Histograms of Oriented Gradients |
| IoT | Internet of Things |
| IoU | Intersection over Union |
| mAP | Mean Average Precision |
| MILN | Multilayer In-place Learning Network |
| mmWave | Millimeter Wave |
| MTT | Multi-Target Tracking |
| PR | Precision Recall |
| ROI | Region of Interest |
| RPN | Regional Advice Network |
| SAE | Society of Automotive Engineers |
| SAF | Spatial Attention Fusion |
| V2X | Vehicle to Everything |
References
- Towler, J.; Bries, M. Ros-military: Progress and promise. In Proceedings of the Ground Vehicle Systems Engineering & Technology Symposium (GVSETS), Novi, MI, USA, 7–9 August 2018. [Google Scholar]
- Waymo. Journey. Available online: https://www.waymo.com/journey/ (accessed on 23 July 2021).
- SAE On-Road Automated Vehicle Standards Committee. Taxonomy and definitions for terms related to on-road motor vehicle automated driving systems. SAE Stand. J. 2014, 3016, 1–16. [Google Scholar]
- Ren, K.; Wang, Q.; Wang, C. The security of autonomous driving: Threats, defenses, and future directions. Proc. IEEE 2019, 3, 357–372. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2015; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Doll´ar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 346–361. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Michaelis, C.; Mitzkus, B.; Geirhos, R. Benchmarking robustness in object detection: Autonomous driving when winter is coming. arXiv 2019, arXiv:1907.07484. [Google Scholar]
- Geirhos, R.; Temme, C.R.M.; Rauber, J. Generalisation in humans and deep neural networks. arXiv 2018, arXiv:1808.08750. [Google Scholar]
- Zhang, R.; Cao, S. Real-time human motion behavior detection via CNN using mmWave radar. IEEE Sens.Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Yoneda, K.; Hashimoto, N.; Yanase, R. Vehicle Localization using 76GHz Omnidirectional Millimeter-Wave Radar for Winter Automated Driving. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 971–977. [Google Scholar]
- Nagasaku, T.; Kogo, K.; Shinoda, H. 77 GHz Low-Cost Single-Chip Radar Sensor for Automotive Ground Speed Detection. In Proceedings of the IEEE Compound Semiconductor Integrated Circuits Symposium, Monterey, CA, USA, 12–15 October 2008; pp. 1–4. [Google Scholar]
- Hines, M.E.; Zelubowski, S.A. Conditions affecting the accuracy of speed measurements by low power MM-wave CW Doppler radar. In Proceedings of the Vehicular Technology Society 42nd VTS Conference-Frontiers of Technology, Denver, CO, USA, 10–13 May 1992; Volume 2, pp. 1046–1050. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Ziebinski, A.; Cupek, R.; Erdogan, H. A survey of ADAS technologies for the future perspective of sensor fusion. In Proceedings of the International Conference on Computational Collective Intelligence, Halkidiki, Greece, 28–30 September 2016; Volume 9876, pp. 135–146. [Google Scholar]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-sensor fusion in automated driving: A survey. IEEE Access 2019, 8, 2847–2868. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? In The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2011 (VOC2011) Results. Available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2011/index.html (accessed on 8 March 2022).
- The KITTI Vision Benchmark Suite. 3D Object Detection Evaluation 2017. Available online: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d (accessed on 16 February 2022).
- Simonelli, A.; Bulò, S.R.; Porzi, L. Disentangling Monocular 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 1991–1999. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 22–18 June 2018; pp. 1067–10676. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2443–2451. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; p. 11618. [Google Scholar]
- Tesla. Future of Driving. Available online: https://www.tesla.com/autopilot (accessed on 13 July 2021).
- Apollo. Robotaxi Autonomous Driving Solution. Available online: https://apollo.auto/robotaxi/index.html (accessed on 23 July 2021).
- NIO. NIO Autonomous Driving. Available online: https://www.nio.cn/nad (accessed on 23 July 2021).
- XPENG. XPILOT Driving. Available online: https://www.xiaopeng.com/p7.html?fromto=gqad004 (accessed on 23 July 2021).
- Audi. Audi AI Traffic Jam Pilot. Available online: https://www.audi-technology-portal.de/en/electrics-electronics/driver-assistant-systems/audi-a8-audi-ai-traffic-jam-pilot (accessed on 23 July 2021).
- Daimler. Drive Pilot. Available online: https://www.daimler.com/innovation/case/autonomous/drive-pilot-2.html (accessed on 23 July 2021).
- Cho, M. A Study on the Obstacle Recognition for Autonomous Driving RC Car Using LiDAR and Thermal Infrared Camera. In Proceedings of the Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 544–546. [Google Scholar]
- Zhou, T.; Yang, M.; Jiang, K. MMW Radar-Based Technologies in Autonomous Driving: A Review. Sensors 2020, 20, 7283. [Google Scholar] [CrossRef] [PubMed]
- Dickmann, J.; Klappstein, J.; Hahn, M.; Appenrodt, N.; Bloecher, H.L.; Werber, K.; Sailer, A. Automotive radar the key technology for autonomous driving: From detection and ranging to environmental understanding. In Proceedings of the IEEE Radar Conference (RadarConf), Philadelphia, PA, USA, 2–6 May 2016; pp. 1–6. [Google Scholar]
- Dickmann, J.; Appenrodt, N.; Bloecher, H.L.; Brenk, C.; Hackbarth, T.; Hahn, M.; Klappstein, J.; Muntzinger, M.; Sailer, A. Radar contribution to highly automated driving. In Proceedings of the 2014 11th European Radar Conference, Rome, Italy, 8–10 October 2014; pp. 412–415. [Google Scholar]
- Alland, S.; Stark, W.; Ali, M.; Hegde, M. Interference in Automotive Radar Systems: Characteristics, Mitigation Techniques, and Current and Future Research. IEEE Signal Process. Mag. 2019, 36, 45–59. [Google Scholar] [CrossRef]
- Continental. Radars Autonomous Mobility. Available online: https://www.continental-automotive.com/en-gl/Passenger-Cars/Autonomous-Mobility/Enablers/Radars (accessed on 23 July 2021).
- Milch, S.; Behrens, M. Pedestrian detection with radar and computer vision. In Proceedings of the PAL 2001—Progress in Automobile Lighting, Darmstadt, Germany, 25–26 September 2001; Volume 9, pp. 657–664. [Google Scholar]
- Huang, W.; Zhang, Z.; Li, W.; Tian, J. Moving object tracking based on millimeter-wave radar and vision sensor. J. Appl. Sci. Eng. 2018, 21, 609–614. [Google Scholar]
- Streubel, R.; Yang, B. Fusion of stereo camera and MIMO-FMCW radar for pedestrian tracking in indoor environments. In Proceedings of the 2016 IEEE International Conference on Information Fusion, Heidelberg, Germany, 5–8 July 2016; pp. 565–572. [Google Scholar]
- Guo, X.; Du, J.; Gao, J.; Wang, W. Pedestrian Detection Based on Fusion of Millimeter Wave Radar and Vision. In Proceedings of the 2018 International Conference on Artificial Intelligence and Pattern Recognition, Beijing, China, 18–20 August 2018; pp. 38–42. [Google Scholar]
- Mo, C.; Yi, L.; Zheng, L.; Ren, Y.; Wang, K.; Li, Y.; Xiong, Z. Obstacles detection based on millimetre-wave radar and image fusion technique. In Proceedings of the IET International Conference on Intelligent and Connected Vehicles, Chongqing, China, 22–23 September 2016. [Google Scholar]
- Bi, X.; Tan, B.; Xu, Z.; Huang, L. A New Method of Target Detection Based on Autonomous Radar and Camera Data Fusion; SAE Technical Paper; SAE: Warrendale, PA, USA, 2017. [Google Scholar]
- Steux, B.; Laurgeau, C.; Salesse, L.; Wautier, D. Fade: A vehicle detection and tracking system featuring monocular color vision and radar data fusion. In Proceedings of the 2002 IEEE Intelligent Vehicles Symposium, Versailles, France, 17–21 June 2002; Volume 2, pp. 632–639. [Google Scholar]
- Liu, F.; Sparbert, J.; Stiller, C. IMMPDA vehicle tracking system using asynchronous sensor fusion of radar and vision. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 168–173. [Google Scholar]
- Alencar, F.; Rosero, L.; Filho, C.; Osório, F.; Wolf, D. Fast Metric Tracking by Detection System: Radar Blob and Camera Fusion. In Proceedings of the 2015 Latin American Robotics Symposium and Brazilian Symposium on Robotics (LARS-SBR), Uberlândia, Brazil, 28 October–1 November 2015; pp. 120–125. [Google Scholar]
- Richter, E.; Schubert, R.; Wanielik, G. Radar and vision based data fusion—Advanced filtering techniques for a multi object vehicle tracking system. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 120–125. [Google Scholar]
- Kato, T.; Ninomiya, Y.; Masaki, I. An obstacle detection method by fusion of radar and motion stereo. IEEE Trans. Intell. Transp. Syst. 2002, 3, 182–188. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, N.; Xin, J.; Ma, Z. Integrating millimeter wave radar with a monocular vision sensor for on-road obstacle detection applications. Sensors 2011, 11, 8992–9008. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garcia, F.; Cerri, P.; Broggi, A.; Escalera, A.; Armingol, J.M. Data fusion for overtaking vehicle detection based on radar and optical flow. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 494–499. [Google Scholar]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. Bionic vision inspired on-road obstacle detection and tracking using radar and visual information. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 39–44. [Google Scholar]
- Haselhoff, A.; Kummert, A.; Schneider, G. Radar-vision fusion for vehicle detection by means of improved haar-like feature and adaboost approach. In Proceedings of the IEEE European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 2070–2074. [Google Scholar]
- Wang, T.; Xin, J.; Zheng, N. A Method Integrating Human Visual Attention and Consciousness of Radar and Vision Fusion for Autonomous Vehicle Navigation. In Proceedings of the 2011 IEEE Fourth International Conference on Space Mission Challenges for Information Technology, Palo Alto, CA, USA, 2–4 August 2011; pp. 192–197. [Google Scholar]
- Bombini, L.; Cerri, P.; Medici, P.; Alessandretti, G. Radar-vision fusion for vehicle detection. In Proceedings of the International Workshop on Intelligent Transportation, Hamburg, Germany, 14–15 March 2006; Volume 65, p. 70. [Google Scholar]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. On-Road Vehicle Detection and Tracking Using MMW Radar and Monovision Fusion. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2075–2084. [Google Scholar] [CrossRef]
- Tan, Y.; Han, F.; Ibrahim, F. A Radar Guided Vision System for Vehicle Validation and Vehicle Motion Characterization. In Proceedings of the 2007 IEEE Intelligent Transportation Systems Conference, Bellevue, WA, USA, 30 September–3 October 2007; pp. 1059–1066. [Google Scholar]
- Yang, J.; Lu, Z.G.; Guo, Y.K. Target Recognition and Tracking based on Data Fusion of Radar and Infrared Image Sensors. In Proceedings of the International Conference on Information Fusion, Sunnyvale, CA, USA, 6–8 July 1999; pp. 6–8. [Google Scholar]
- Ji, Z.P.; Prokhorov, D. Radar-vision fusion for object classificatio. In Proceedings of the IEEE International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- Alessandretti, G.; Broggi, A.; Cerri, P. Vehicle and guard rail detection using radar and vision data fusion. IEEE Trans. Intell. Transp. Syst. 2007, 8, 95–105. [Google Scholar] [CrossRef] [Green Version]
- Kadow, U.; Schneider, G.; Vukotich, A. Radar-vision based vehicle recognition with evolutionary optimized and boosted features. In Proceedings of the IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 749–754. [Google Scholar]
- Bertozzi, M.; Bombini, L.; Cerri, P.; Medici, P.; Antonello, P.C.; Miglietta, M. Obstacle detection and classification fusing radar and vision. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 608–613. [Google Scholar]
- Hyun, E.; Jin, Y.S. Multi-level Fusion Scheme for Target Classification using Camera and Radar Sensors. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV), Las Vegas, NV, USA, 25–28 July 2017; pp. 111–114. [Google Scholar]
- Langer, D.; Jochem, T. Fusing radar and vision for detecting, classifying and avoiding roadway obstacles. In Proceedings of the IEEE Conference on Intelligent Vehicles, Tokyo, Japan, 19–20 September 1996; pp. 333–338. [Google Scholar]
- Chavez, R.O.; Burlet, J.; Vu, T.D.; Aycard, O. Frontal object perception using radar and mono-vision. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 159–164. [Google Scholar]
- Long, N.; Wang, K.; Cheng, R.; Yang, K.; Bai, J. Fusion of millimeter wave radar and RGB-depth sensors for assisted navigation of the visually impaired. In Proceedings of the Millimeter Wave and Terahertz Sensors and Technology XI, Berlin, Germany, 5 October 2018; Volume 10800, pp. 21–28. [Google Scholar]
- Long, N.; Wang, K.; Cheng, R.; Hu, W.; Yang, K. Unifying obstacle detection, recognition, and fusion based on millimeter wave radar and RGB-depth sensors for the visually impaired. Rev. Sci. Instrum. 2019, 90, 044102. [Google Scholar] [CrossRef]
- Wang, J.G.; Chen, S.J.; Zhou, L.B.; Wan, K.W.; Yau, W.Y. Vehicle Detection and Width Estimation in Rain by Fusing Radar and Vision. In Proceedings of the 2018 International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 Novemeber 2018; pp. 1063–1068. [Google Scholar]
- Kim, J.; Emeršič, Ž.; Han, D.S. Vehicle Path Prediction based on Radar and Vision Sensor Fusion for Safe Lane Changing. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 267–271. [Google Scholar]
- Coué, C.; Fraichard, T.; Bessiere, P.; Mazer, E. Multi-sensor data fusion using Bayesian programming: An automotive application. In Proceedings of the 2002 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2002; Volume 2, pp. 442–447. [Google Scholar]
- Kawasaki, N.; Kiencke, U. Standard platform for sensor fusion on advanced driver assistance system using bayesian network. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 250–255. [Google Scholar]
- Ćesić, J.; Marković, I.; Cvišić, I.; Petrović, I. Radar and stereo vision fusion for multitarget tracking on the special Euclidean group. Robot. Auton. Syst. 2016, 83, 338–348. [Google Scholar] [CrossRef]
- Zhong, Z.; Liu, S.; Mathew, M.; Dubey, A. Camera radar fusion for increased reliability in ADAS applications. Electron. Imaging Auton. Veh. Mach. 2018, 17, 258-1–258-4. [Google Scholar] [CrossRef]
- Kim, D.Y.; Jeon, M. Data fusion of radar and image measurements for multi-object tracking via Kalman filtering. Inf. Sci. 2014, 278, 641–652. [Google Scholar] [CrossRef]
- Obrvan, M.; Ćesić, J.; Petrović, I. Appearance based vehicle detection by radar-stereo vision integration. In Proceedings of the Robot 2015: Second Iberian Robotics Conference, Lisbon, Portugal, 19–21 November 2015; Volume 417, pp. 437–449. [Google Scholar]
- Wu, S.; Decker, S.; Chang, P.; Camus, T.; Eledath, J. Collision sensing by stereo vision and radar sensor fusion. IEEE Trans. Intell. Transp. Syst. 2009, 10, 606–614. [Google Scholar]
- Jha, H.; Lodhi, V.; Chakravarty, D. Object Detection and Identification Using Vision and Radar Data Fusion System for Ground-Based Navigation. In Proceedings of the 2019 International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 Mach 2019; pp. 590–593. [Google Scholar]
- Chadwick, S.; Maddern, W.; Newman, P. Distant Vehicle Detection Using Radar and Vision. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8311–8317. [Google Scholar]
- John, V.; Mita, S. RVNet: Deep Sensor Fusion of Monocular Camera and Radar for Image-Based Obstacle Detection in Challenging Environment. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology, Sydney, Australia, 18–22 November 2019; Volume 11854, pp. 351–364. [Google Scholar]
- Nobis, F.; Geisslinger, M.; Weber, M.; Betz, J.; Lienkamp, M. A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection. In Proceedings of the 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF 2019), Bonn, Germany, 15–17 October 2019; pp. 1–7. [Google Scholar]
- Chang, S.; Zhang, Y.; Zhang, F.; Zhao, X.; Huang, S.; Feng, Z.; Wei, Z. Spatial Attention Fusion for Obstacle Detection Using MmWave Radar and Vision Senso. Sensors 2020, 20, 956. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lekic, V.; Babic, Z. Automotive radar and camera fusion using Generative Adversarial Networks. Comput. Vis. Image Underst. 2019, 184, 1–8. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F. Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1521–1529. [Google Scholar]
- Brazil, G.; Liu, X. M3d-rpn: Monocular 3d region proposal network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9287–9296. [Google Scholar]
- Roddick T, Kendall A, Cipolla R. Orthographic feature transform for monocular 3d object detection. arXiv 2018, arXiv:1811.08188. [Google Scholar]
- Nabati, R.; Qi, H. CenterFusion: Center-Based Radar and Camera Fusion for 3D Object Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1527–1536. [Google Scholar]
- Du, X.; Ang, M.H.; Rus, D. Car detection for autonomous vehicle: LIDAR and vision fusion approach through deep learning framework. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 749–754. [Google Scholar]
- Zhao, X.; Sun, P.; Xu, Z.; Min, H.; Yu, H. Fusion of 3D LIDAR and Camera Data for Object Detection in Autonomous Vehicle Applications. IEEE Sens. J. 2020, 20, 4901–4913. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Release Year | RGB Image | Radar | Lidar |
|---|---|---|---|---|
| Apolloscape | 2018 | Y | N | Y |
| KITTI | 2012 | Y | N | Y |
| Cityscapes | 2016 | Y | N | N |
| Waymo Open Dataset | 2019 | Y | N | Y |
| nuScense | 2019 | Y | Y | Y |
| Company | Autonomous Driving System | Sensor Configuration |
|---|---|---|
| Tesla | Autopilot | 8 cameras, 12 ultrasonic radars, mmWave radar |
| Baidu | Apollo | Lidar, mmWave radar, Camera |
| NIO | Aquila | Lidar, 11 cameras, 5 mmWave radars, 12 ultrasonic radars |
| Xpeng | XPILOT | 6 cameras, 2 mmWave radars, 12 ultrasonic radars |
| Audi | Traffic Jam Pilot | 6 cameras, 5 mmWave radars, 12 ultrasonic radars, Lidar |
| Mercedes Benz | Drive Pilot | 4 panoramic cameras, Lidar, mmWave radar |
| Sensor Type | mmWave Radar | Lidar | Camera |
|---|---|---|---|
| Range resolution | 4 | 5 | 2 |
| Angle resolution | 4 | 5 | 6 |
| Speed detection | 5 | 4 | 3 |
| Detection accuracy | 2 | 5 | 6 |
| Anti-interference performance | 5 | 5 | 6 |
| Requirements for weather conditions | 1 | 4 | 4 |
| Operating hours | All weather | All weather | Depends on light conditions |
| Cost and processing overhead | 2 | 4 | 3 |
| Fusion Level | Advantages | Disadvantages |
|---|---|---|
| Data level | Minimum data loss and the highest reliability | Dependence on the number of radar points |
| Decision level | Making full use of sensor information | Modeling the joint probability density function of sensors is difficult |
| Feature level | Making full use of feature information and achieving best detection performance | Complicated computation and overhead of radar information transformation |
| Reference | Contribution | ||
|---|---|---|---|
| ROI generation | [42] | Using radar points to increase the speed of ROI generation. | |
| [45] | Proposing the conclusion that distance determines the initial size of ROI. | ||
| [54] | Extending ROI application to overtaking detection. | ||
| Object detection | Image preprocessing | [45,56,61] | Using histogram equalization, grayscale variance and contrast normalization to preprocess the image. |
| [53,57,61] | Image segmentation preprocessing with radar point as reference center. | ||
| Feature extraction | [55,57,58,59,61,63] | Using features such as symmetry and shadow to extract vehicle contours. | |
| [56,64] | Using Haar-like model for feature extraction. | ||
| Object classification | [56] | Adaboost algorithm for object classification. | |
| [47,60] | SVM for object classification. | ||
| [61,62] | Neural network-based classifier for object classification. | ||
| Reference | Contribution | ||
|---|---|---|---|
| Sensing information processing | Radar information | [67,68] | The techniques involved in radar signal processing and what physical states can be obtained from radar information are analyzed. |
| Image object detection | [68] | Pedestrian detection using feature extraction combined with classifiers. | |
| [69] | Detecting objects in depth images with MeanShift algorithm. | ||
| [70] | An upgraded version of [69], using MaskRCNN for target detection. | ||
| [71,72,80] | Using one-stage object detection algorithm YOLO for radar vision fusion object detection tasks. | ||
| Decision fusion | Based on Bayesian theory | [73] | Proposing Bayesian programming to solve multi-sensor data fusion problems through probabilistic reasoning |
| [74] | A dynamic fusion method based on Bayesian network is proposed to facilitate the addition of new sensors. | ||
| Based on Kalman filter | [75] | Proposing a decision level fusion filter based on EKF framework. | |
| [76] | The proposed fusion methon can track the object simultaneously in 3D space and 2D image plane. | ||
| [77] | Functional equivalence of centralized and decentralized information fusion schemes is demonstrated. | ||
| Based on Dempster Shafer theory | [68] | A decision level sensor fusion method based on Dempster-Shafer is proposed. | |
| Based on Radar validation | [78] | Using radar detection results to validate visuals. | |
| [79] | Using radar information to correct vehicle position information in real time to achieve object tracking. | ||
| Reference | Technology Features | |
|---|---|---|
| Fusion framework | [81] | Based on SSD framework improvement, concatenation fusion is used. |
| [82] | A fusion framework similar to YOLO structure is proposed named RVNet. | |
| [83] | Proposing CRF-Net built on the VGG backbone network and RetinaNet, and the radar input branch is extended. | |
| [84] | Join the radar branch based on the FCOS detection framework and embedded SAF module. | |
| Radar feature extraction | [85] | Proposing a network named CMGGAN that can generate environmental images. |
| [82,84] | Using a new radar feature description method called radar sparse image, the detected objects are presented as radar points. | |
| [83] | Stretching the radar points in the radar sparse image vertically to supplement the height information. | |
| Feature fusion | [81,82,83] | The fusion method of concatenation and element-wise addition is adopted. |
| [84] | A feature fusion block named spatial attention fusion is proposed that uses attention mechanism. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Z.; Zhang, F.; Chang, S.; Liu, Y.; Wu, H.; Feng, Z. MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review. Sensors 2022, 22, 2542. https://doi.org/10.3390/s22072542
Wei Z, Zhang F, Chang S, Liu Y, Wu H, Feng Z. MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review. Sensors. 2022; 22(7):2542. https://doi.org/10.3390/s22072542
Chicago/Turabian StyleWei, Zhiqing, Fengkai Zhang, Shuo Chang, Yangyang Liu, Huici Wu, and Zhiyong Feng. 2022. "MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review" Sensors 22, no. 7: 2542. https://doi.org/10.3390/s22072542
APA StyleWei, Z., Zhang, F., Chang, S., Liu, Y., Wu, H., & Feng, Z. (2022). MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review. Sensors, 22(7), 2542. https://doi.org/10.3390/s22072542