
Performance and Capability Assessment in Surgical Subtask Automation



Abstract
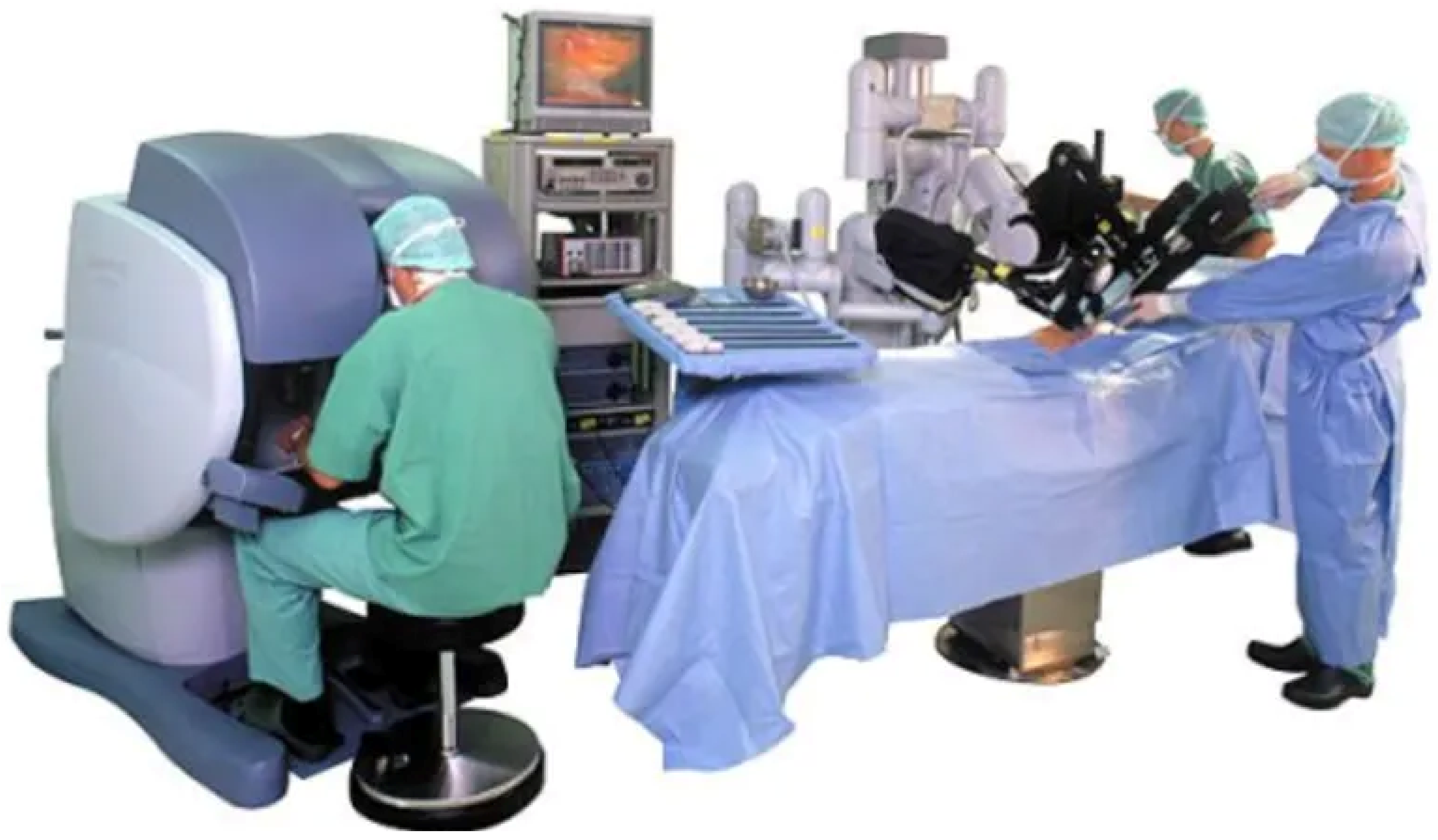
1. Introduction
2. Characterization of Autonomy
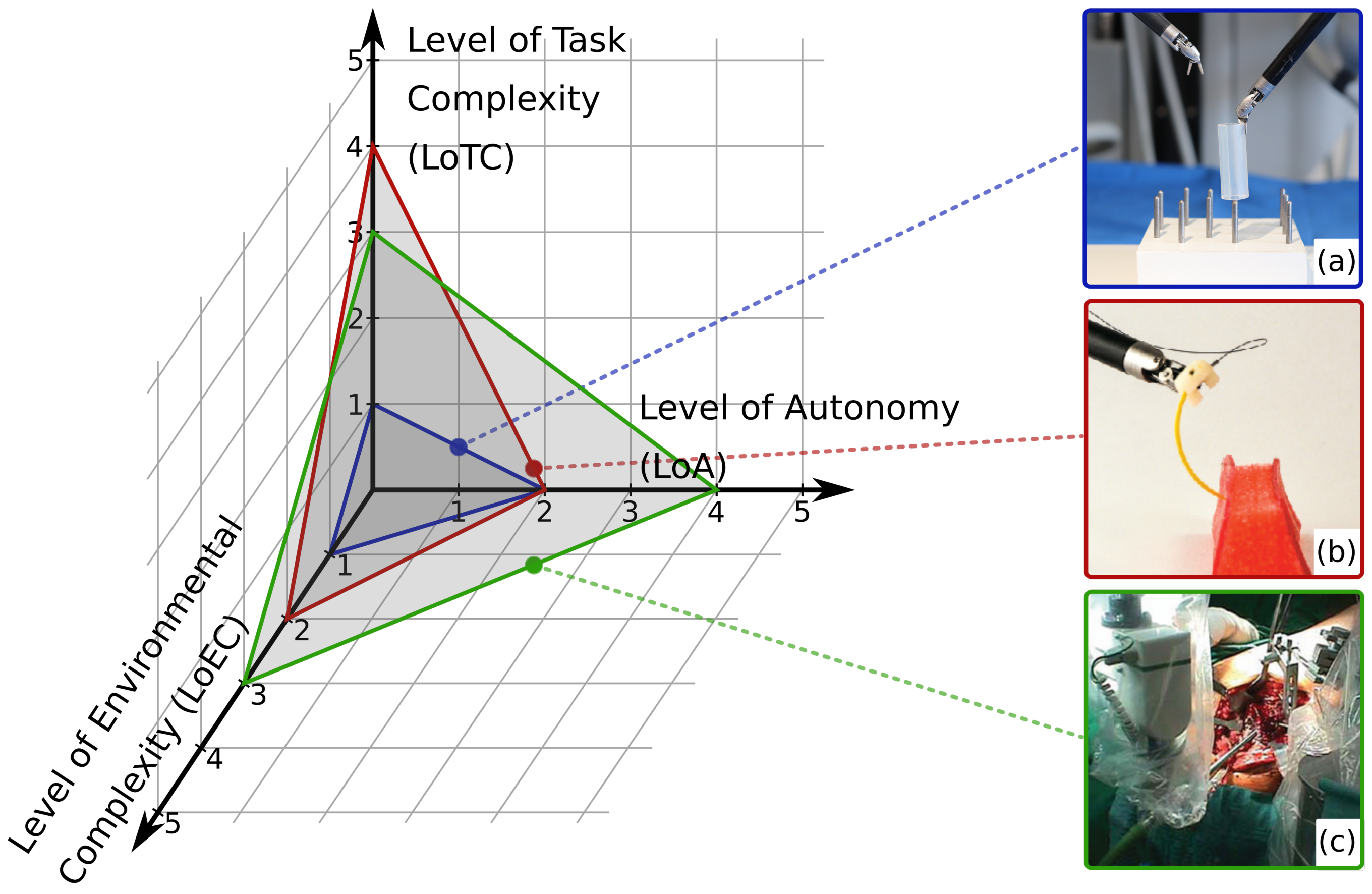
- LoCR 1 – Training tasks with rigid phantoms;
- LoCR 2 – Surgical tasks with simple phantoms;
- LoCR 3 – Surgical tasks with realistic phantoms, but little or no soft-tissue interaction;
- LoCR 4 – Surgical tasks with soft-tissue interaction;
- LoCR 5 – Surgical tasks with soft-tissue topology changes.
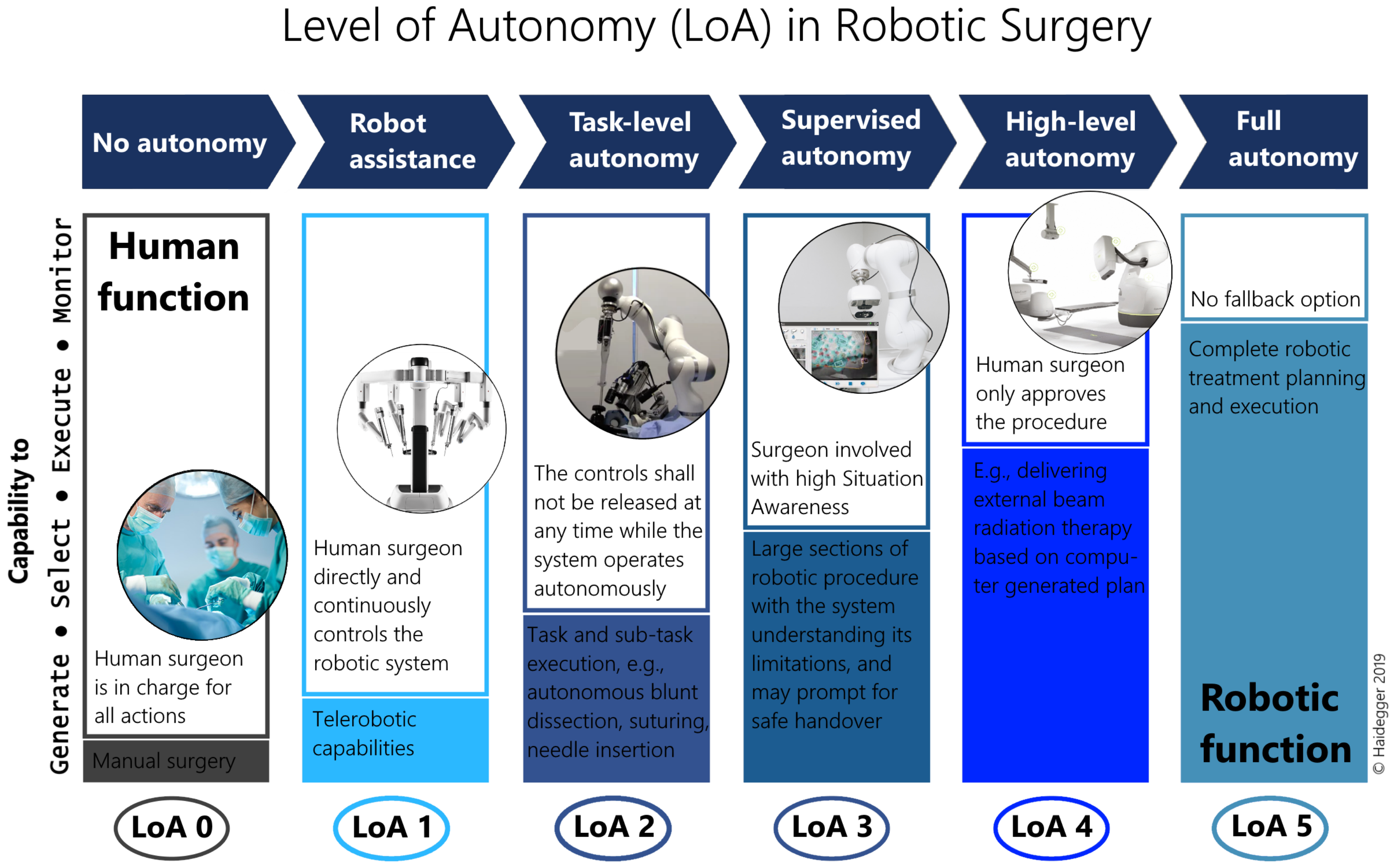
2.1. Level of Autonomy
- LoA 0 – No autonomy;
- LoA 1 – Robot assistance;
- LoA 2 – Task-level autonomy;
- LoA 3 – Supervised autonomy;
- LoA 4 – High-level autonomy;
- LoA 5 – Full autonomy.
2.2. Level of Environmental Complexity
- LoEC 1 – Training phantoms: made for the training of surgical skills (e.g., hand–eye coordination), no or limited, highly abstract representation of the surgical environment, e.g., wire chaser;
- LoEC 2 – Simple surgical phantoms: made for certain surgical subtasks, modeling one or few related key features of the real environment, e.g., silicone phantom for pattern cutting;
- LoEC 3 – Rigid, realistic surgical environment: realistic surgical phantoms or ex/in vivo tissues/organs, little or no soft-tissue interaction, e.g., ex vivo bone for orthopedic procedures;
- LoEC 4 – Soft, realistic surgical environment: realistic surgical phantoms or ex/in vivo tissues/organs, soft-tissue interaction, e.g., anatomically accurate phantoms for certain procedures or ex vivo environment;
- LoEC 5 – Dynamic, realistic surgical environment: realistic surgical phantoms or ex/in vivo tissues/organs, soft-tissue topology changes, e.g., in vivo environment with all relevant physiological motions.
2.3. Level of Task Complexity
- Level 1 SA – perception of the environment;
- Level 2 SA – comprehension of the current situation;
- Level 3 SA – projection of future status.
- LoTC 1 – Simple training tasks: no or limited, distant representation of surgical task, no or Level 1 SA is required, e.g., peg transfer;
- LoTC 2 – Advanced training tasks: no or distant representation of surgical task, basic reasoning and Level 2 or 3 SA is required, e.g., peg transfer with swapping rings;
- LoTC 3 – Simple surgical tasks: no or Level 1 SA is required, e.g., debridement;
- LoTC 4 – Advanced surgical tasks: Level 2 SA, spatial knowledge and understanding of the scene are required, e.g., suturing;
- LoTC 5 – Complex surgical tasks: Level 3 SA, clinical and anatomical knowledge are required, e.g., stop acute bleeding.
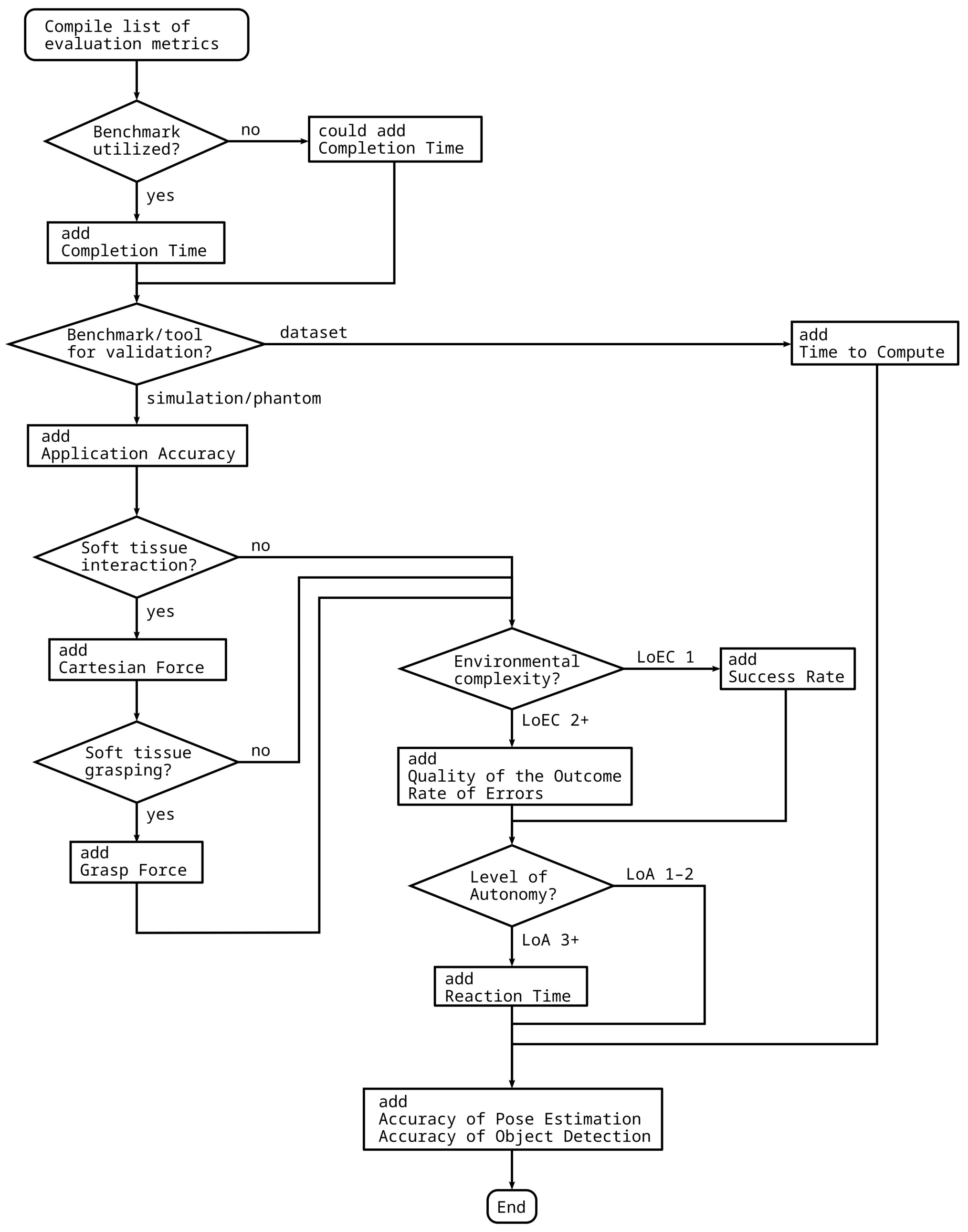
3. Performance Metrics
- (a)
- to the ground truth utilized in the case of human surgeons;
- (b)
- to the metrics from human execution that are found to be correlated with surgical skill;
- (c)
- to new ground truth for autonomous execution.
3.1. Performance Metrics in MIS Skill Assessment
3.2. Metrics by Modality
3.2.1. Temporal Metrics
3.2.2. Outcome Metrics
3.2.3. Motion-Based Metrics
3.2.4. Velocity and Acceleration Metrics
3.2.5. Jerk Metrics
3.2.6. Force-Based Metrics
3.2.7. Accuracy Metrics
3.3. Conclusions on Performance Metrics
4. Benchmarking Techniques
5. Human–Machine Interface Quality
6. Robustness
- The ability...to react appropriately to abnormal circumstances (i.e., circumstances “outside of specifications“). [A system] may be correct without being robust. [95];
- Insensitivity against small deviations in the assumptions [96];
- The degree to which a system is insensitive to effects that are not considered in the design [97].
7. Legal Questions and Ethics
- International Organization for Standardization (ISO);
- International Electrotechnical Commission (IEC);
- Institute of Electrical and Electronics Engineers (IEEE)
- Strategic Advisory Group of Experts (SAGE), advising World Health Organization (WHO);
- European Society of Surgery (E.S.S.) in Europe;
- Food and Drug Administration (FDA) in the USA.
8. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ALFUS | Autonomy Levels for Unmanned Systems |
| AMBF | Asynchronous Multi-Body Framework |
| CAC | Contextual Autonomous Capability |
| DoA | Degree of Autonomy |
| E.S.S. | European Society of Surgery |
| FDA | Food and Drug Administration |
| GDPR | General Data Protection Regulation (EU) |
| GEARS-E | Global Evaluative Assessment of Robotic Skills in Endoscopy |
| HMI | Human–Machine Interface |
| IEC | International Electrotechnical Commission |
| IEEE | Institute of Electrical and Electronics Engineers |
| ISO | International Organization for Standardization |
| JIGSAWS | JHU-ISI Gesture and Skill Assessment Working Set |
| LoA | Level of Autonomy |
| LoCR | Level of Clinical Realism |
| LoEC | Level of Environmental Complexity |
| LoTC | Level of Task Complexity |
| MDR | Medical Devices Regulation (EU) |
| MIS | Minimally Invasive Surgery |
| NASA-TLX | NASA Task Load Index |
| RAMIS | Robot-Assisted Minimally Invasive Surgery |
| R-OSATS | Robotic Objective Structured Assessments of Technical Skills |
| SA | Situation Awareness |
| SAGE | Strategic Advisory Group of Experts |
| SCAC | Surgical Contextual Autonomous Capability |
| UMS | Unmanned System |
| WHO | World Health Organization |
References
- Takács, Á.; Nagy, D.Á.; Rudas, I.J.; Haidegger, T. Origins of Surgical Robotics: From Space to the Operating Room. Acta Polytech. Hung. 2016, 13, 13–30. [Google Scholar]
- Haidegger, T.; József, S. Robot-Assisted Minimally Invasive Surgery in the Age of Surgical Data Science. Hung. J. Surg. 2021, 74, 127–135. [Google Scholar]
- Haidegger, T.; Speidel, S.; Stoyanov, D.; Richard, S. Robot-Assisted Minimally Invasive Surgery—Surgical Robotics in the Data Age. In Proceedings of the IEEE; 2022; in press; pp. 1–11. ISSN 0018-9219. [Google Scholar]
- Fagin, R. Da Vinci Prostatectomy: Athermal Nerve Sparing and Effect of the Technique on Erectile Recovery and Negative Margins. J. Robot. Surg. 2007, 1, 139–143. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Tewari, A.; Peabody, J.O.; Fischer, M.; Sarle, R.; Vallancien, G.; Delmas, V.; Hassan, M.; Bansal, A.; Hemal, A.K.; Guillonneau, B.; et al. An Operative and Anatomic Study to Help in Nerve Sparing during Laparoscopic and Robotic Radical Prostatectomy. Eur. Urol. 2003, 43, 444–454. [Google Scholar] [CrossRef]
- D’Ettorre, C.; Mariani, A.; Stilli, A.; Rodriguez y Baena, F.; Valdastri, P.; Deguet, A.; Kazanzides, P.; Taylor, R.H.; Fischer, G.S.; DiMaio, S.P.; et al. Accelerating Surgical Robotics Research: A Review of 10 Years With the Da Vinci Research Kit. IEEE Robot. Autom. Mag. 2021, 28, 56–78. [Google Scholar] [CrossRef]
- Klodmann, J.; Schlenk, C.; Hellings-Kuß, A.; Bahls, T.; Unterhinninghofen, R.; Albu-Schäffer, A.; Hirzinger, G. An Introduction to Robotically Assisted Surgical Systems: Current Developments and Focus Areas of Research. Curr. Robot. Rep. 2021, 2, 321–332. [Google Scholar] [CrossRef]
- Khamis, A.; Meng, J.; Wang, J.; Azar, A.T.; Prestes, E.; Li, H.; Hameed, I.A.; Rudas, I.J.; Haidegger, T. Robotics and Intelligent Systems Against a Pandemic. Acta Polytech. Hung. 2021, 18, 13–35. [Google Scholar]
- Yang, G.Z.; Cambias, J.; Cleary, K.; Daimler, E.; Drake, J.; Dupont, P.E.; Hata, N.; Kazanzides, P.; Martel, S.; Patel, R.V.; et al. Medical Robotics—Regulatory, Ethical, and Legal Considerations for Increasing Levels of Autonomy. Sci. Robot. 2017, 2, eaam8638. [Google Scholar] [CrossRef]
- Haidegger, T. Autonomy for Surgical Robots: Concepts and Paradigms. IEEE Trans. Med. Robot. Bion. 2019, 1, 65–76. [Google Scholar]
- Gumbs, A.A.; Frigerio, I.; Spolverato, G.; Croner, R.; Illanes, A.; Chouillard, E.; Elyan, E. Artificial Intelligence Surgery: How Do We Get to Autonomous Actions in Surgery? Sensors 2021, 21, 5526. [Google Scholar] [CrossRef]
- Elek, R.; Nagy, T.D.; Nagy, D.Á.; Kronreif, G.; Rudas, I.J.; Haidegger, T. Recent Trends in Automating Robotic Surgery. In Proceedings of the 20th IEEE Jubilee International Conference on Intelligent Engineering Systems (INES), Budapest, Hungary, 30 June–2 July 2016; pp. 27–32. [Google Scholar]
- Nagy, T.D.; Haidegger, T. Autonomous Surgical Robotics at Task and Subtask Levels. In Advanced Robotics and Intelligent Automation in Manufacturing; Advances in Computational Intelligence and Robotics (ACIR) Book Series; IGI Global: Hershey, PA, USA, 2020; pp. 296–319. [Google Scholar]
- Shademan, A.; Decker, R.S.; Opfermann, J.; Leonard, S.; Krieger, A.; Kim, P.C.W. Supervised Autonomous Robotic Soft Tissue Surgery. Sci. Transl. Med. 2016, 8, 337ra64. [Google Scholar] [CrossRef] [PubMed]
- Lu, B.; Li, B.; Chen, W.; Jin, Y.; Zhao, Z.; Dou, Q.; Heng, P.A.; Liu, Y. Toward Image-Guided Automated Suture Grasping Under Complex Environments: A Learning-Enabled and Optimization-Based Holistic Framework. IEEE Trans. Autom. Sci. Eng. 2021, 1–15. [Google Scholar] [CrossRef]
- Wartenberg, M.; Schornak, J.; Carvalho, P.; Patel, N.; Iordachita, I.; Tempany, C.; Hata, N.; Tokuda, J.; Fischer, G. Closed-Loop Autonomous Needle Steering during Cooperatively Controlled Needle Insertions for MRI-guided Pelvic Interventions. In Proceedings of the The Hamlyn Symposium on Medical Robotics, London, UK, 25–28 June 2017; pp. 33–34. [Google Scholar]
- Sen, S.; Garg, A.; Gealy, D.V.; McKinley, S.; Jen, Y.; Goldberg, K. Automating Multi-Throw Multilateral Surgical Suturing with a Mechanical Needle Guide and Sequential Convex Optimization. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4178–4185. [Google Scholar] [CrossRef]
- Garg, A.; Sen, S.; Kapadia, R.; Jen, Y.; McKinley, S.; Miller, L.; Goldberg, K. Tumor Localization Using Automated Palpation with Gaussian Process Adaptive Sampling. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016; pp. 194–200. [Google Scholar] [CrossRef]
- Seita, D.; Krishnan, S.; Fox, R.; McKinley, S.; Canny, J.; Goldberg, K. Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6651–6658. [Google Scholar]
- Nagy, D.Á.; Nagy, T.D.; Elek, R.; Rudas, I.J.; Haidegger, T. Ontology-Based Surgical Subtask Automation, Automating Blunt Dissection. J. Med. Robot. Res. 2018, 3, 1841005. [Google Scholar] [CrossRef]
- Attanasio, A.; Scaglioni, B.; Leonetti, M.; Frangi, A.; Cross, W.; Biyani, C.S.; Valdastri, P. Autonomous Tissue Retraction in Robotic Assisted Minimally Invasive Surgery—A Feasibility Study. IEEE Robot. Autom. Lett. 2020, 5, 6528–6535. [Google Scholar] [CrossRef]
- Nagy, T.D.; Haidegger, T. A DVRK-based Framework for Surgical Subtask Automation. Acta Polytech. Hung. 2019, 16, 61–78. [Google Scholar] [CrossRef]
- Fiorini, P. Autonomy in Robotic Surgery: The First Baby Steps. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Rahman, M.M.; Sanchez-Tamayo, N.; Gonzalez, G.; Agarwal, M.; Aggarwal, V.; Voyles, R.M.; Xue, Y.; Wachs, J. Transferring Dexterous Surgical Skill Knowledge between Robots for Semi-autonomous Teleoperation. In Proceedings of the 2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019. [Google Scholar] [CrossRef]
- Ginesi, M.; Meli, D.; Roberti, A.; Sansonetto, N.; Fiorini, P. Autonomous Task Planning and Situation Awareness in Robotic Surgery. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 3144–3150. [Google Scholar]
- Ginesi, M.; Meli, D.; Roberti, A.; Sansonetto, N.; Fiorini, P. Dynamic Movement Primitives: Volumetric Obstacle Avoidance Using Dynamic Potential Functions. J. Intell. Robot. Syst. 2021, 101, 1–20. [Google Scholar] [CrossRef]
- Hwang, M.; Thananjeyan, B.; Seita, D.; Ichnowski, J.; Paradis, S.; Fer, D.; Low, T.; Goldberg, K. Superhuman Surgical Peg Transfer Using Depth-Sensing and Deep Recurrent Neural Networks. arXiv 2020, arXiv:2012.12844. [Google Scholar]
- Gonzalez, G.T.; Kaur, U.; Rahman, M.; Venkatesh, V.; Sanchez, N.; Hager, G.; Xue, Y.; Voyles, R.; Wachs, J. From the Dexterous Surgical Skill to the Battlefield—A Robotics Exploratory Study. Mil. Med. 2021, 186, 288–294. [Google Scholar] [CrossRef]
- Murali, A.; Sen, S.; Kehoe, B.; Garg, A.; McFarland, S.; Patil, S.; Boyd, W.D.; Lim, S.; Abbeel, P.; Goldberg, K. Learning by Observation for Surgical Subtasks: Multilateral Cutting of 3D Viscoelastic and 2D Orthotropic Tissue Phantoms. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1202–1209. [Google Scholar] [CrossRef]
- Nguyen, T.; Nguyen, N.D.; Bello, F.; Nahavandi, S. A New Tensioning Method Using Deep Reinforcement Learning for Surgical Pattern Cutting. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, Australia, 13–15 February 2019; pp. 1339–1344. [Google Scholar] [CrossRef]
- Xu, J.; Li, B.; Lu, B.; Liu, Y.H.; Dou, Q.; Heng, P.A. SurRoL: An Open-source Reinforcement Learning Centered and dVRK Compatible Platform for Surgical Robot Learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, September 27–1 October 2021; pp. 1821–1828. [Google Scholar]
- Fontana, G.; Matteucci, M.; Sorrenti, D.G. Rawseeds: Building a Benchmarking Toolkit for Autonomous Robotics. In Methods and Experimental Techniques in Computer Engineering; Amigoni, F., Schiaffonati, V., Eds.; SpringerBriefs in Applied Sciences and Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 55–68. [Google Scholar] [CrossRef]
- Nagy, T.D.; Haidegger, T. Towards Standard Approaches for the Evaluation of Autonomous Surgical Subtask Execution. In Proceedings of the 25th IEEE International Conference on Intelligent Engineering Systems (INES), Budapest, Hungary, 7–9 July 2021; pp. 67–74. [Google Scholar] [CrossRef]
- Huang, H.M. Autonomy Levels for Unmanned Systems (ALFUS) Framework Volume II: Framework Models. NIST ALFUS Working Group SAE AS4D Committee. 2007. Available online: https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=823618 (accessed on 11 April 2021).
- Kazanzides, P.; Fischer, G. AccelNet: International Collaboration on Data Collection and Machine Learning. 2020. [Google Scholar]
- Nigicser, I.; Szabo, B.; Jaksa, L.; Nagy, D.A.; Garamvolgyi, T.; Barcza, S.; Galambos, P.; Haidegger, T. Anatomically Relevant Pelvic Phantom for Surgical Simulation. In Proceedings of the 2016 7th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Wroclaw, Poland, 16–18 October 2016; pp. 427–432. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Arif, S.H. Midline Gallbladder Makes a Challenge for Surgeons during Laparoscopic Cholecystectomy; Case Series of 6 Patients. Ann. Med. Surg. 2019, 40, 14–17. [Google Scholar] [CrossRef]
- Kazanzides, P.; Fichtinger, G.; Hager, G.D.; Okamura, A.M.; Whitcomb, L.L.; Taylor, R.H. Surgical and Interventional Robotics—Core Concepts, Technology, and Design [Tutorial]. IEEE Robot. Autom. Mag. 2008, 15, 122–130. [Google Scholar] [CrossRef]
- Haidegger, T. Taxonomy and Standards in Robotics. In Encyclopedia of Robotics; Ang, M.H., Khatib, O., Siciliano, B., Eds.; Springer Nature: Berlin/Heidelberg, Germany, 2022; pp. 1–10. [Google Scholar]
- Chinzei, K. Safety of Surgical Robots and IEC 80601-2-77: The First International Standard for Surgical Robots. Acta Polytech. Hung. 2019, 16, 174–184. [Google Scholar] [CrossRef]
- Drexler, D.A.; Takacs, A.; Nagy, D.T.; Haidegger, T. Handover Process of Autonomous Vehicles—Technology and Application Challenges. Acta Polytech. Hung. 2019, 15, 101–120. [Google Scholar]
- Endsley, M. Situation Awareness Global Assessment Technique (SAGAT). In Proceedings of the IEEE 1988 National Aerospace and Electronics Conference, Dayton, OH, USA, 23–27 May 1988; pp. 789–795. [Google Scholar] [CrossRef]
- Endsley, M. Situation Awareness in Aviation Systems. In Handbook of Aviation Human Factors; CRC Press: Boca Raton, FL, USA, 1999; pp. 257–276. [Google Scholar] [CrossRef]
- Nagyné Elek, R.; Haidegger, T. Robot-Assisted Minimally Invasive Surgical Skill Assessment—Manual and Automated Platforms. Acta Polytech. Hung. 2019, 16, 141–169. [Google Scholar] [CrossRef]
- Nguyen, J.H.; Chen, J.; Marshall, S.P.; Ghodoussipour, S.; Chen, A.; Gill, I.S.; Hung, A.J. Using Objective Robotic Automated Performance Metrics and Task-Evoked Pupillary Response to Distinguish Surgeon Expertise. World J. Urol. 2020, 38, 1599–1605. [Google Scholar] [CrossRef] [PubMed]
- Reiley, C.E.; Lin, H.C.; Yuh, D.D.; Hager, G.D. Review of Methods for Objective Surgical Skill Evaluation. Surg. Endosc. 2011, 25, 356–366. [Google Scholar] [CrossRef] [PubMed]
- Takeshita, N.; Phee, S.J.; Chiu, P.W.; Ho, K.Y. Global Evaluative Assessment of Robotic Skills in Endoscopy (GEARS-E): Objective Assessment Tool for Master and Slave Transluminal Endoscopic Robot. Endosc. Int. Open 2018, 6, E1065–E1069. [Google Scholar] [CrossRef]
- Polin, M.R.; Siddiqui, N.Y.; Comstock, B.A.; Hesham, H.; Brown, C.; Lendvay, T.S.; Martino, M.A. Crowdsourcing: A Valid Alternative to Expert Evaluation of Robotic Surgery Skills. Am. J. Obstet. Gynecol. 2016, 215. [Google Scholar] [CrossRef]
- Joshi, A.; Kale, S.; Chandel, S.; Pal, D. Likert Scale: Explored and Explained. Br. J. Appl. Sci. Technol. 2015, 7, 396–403. [Google Scholar] [CrossRef]
- Raison, N.; Ahmed, K.; Fossati, N.; Buffi, N.; Mottrie, A.; Dasgupta, P.; Poel, H.V.D. Competency Based Training in Robotic Surgery: Benchmark Scores for Virtual Reality Robotic Simulation. BJU Int. 2017, 119, 804–811. [Google Scholar] [CrossRef]
- Nagyné Elek, R.; Haidegger, T. Non-Technical Skill Assessment and Mental Load Evaluation in Robot-Assisted Minimally Invasive Surgery. Sensors 2021, 21, 2666. [Google Scholar] [CrossRef]
- Kwong, J.C.; Lee, J.Y.; Goldenberg, M.G. Understanding and Assessing Nontechnical Skills in Robotic Urological Surgery: A Systematic Review and Synthesis of the Validity Evidence. J. Surg. Educ. 2019, 76, 193–200. [Google Scholar] [CrossRef] [PubMed]
- Trejos, A.L.; Patel, R.V.; Malthaner, R.A.; Schlachta, C.M. Development of Force-Based Metrics for Skills Assessment in Minimally Invasive Surgery. Surg. Endosc. 2014, 28, 2106–2119. [Google Scholar] [CrossRef] [PubMed]
- Kehoe, B.; Kahn, G.; Mahler, J.; Kim, J.; Lee, A.; Lee, A.; Nakagawa, K.; Patil, S.; Boyd, W.D.; Abbeel, P.; et al. Autonomous Multilateral Debridement with the Raven Surgical Robot. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1432–1439. [Google Scholar] [CrossRef]
- Hwang, M.; Seita, D.; Thananjeyan, B.; Ichnowski, J.; Paradis, S.; Fer, D.; Low, T.; Goldberg, K. Applying Depth-Sensing to Automated Surgical Manipulation with a Da Vinci Robot. In Proceedings of the 2020 International Symposium on Medical Robotics (ISMR), Atlanta, GA, USA, 18–20 November 2020. [Google Scholar]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A Surgical Activity Dataset for Human Motion Modeling. In Proceedings of the MICCAI Workshop: M2CAI, Boston, MA, USA, 14 September 2014; Volume 3. [Google Scholar]
- McKinley, S.; Garg, A.; Sen, S.; Gealy, D.V.; McKinley, J.; Jen, Y.; Goldberg, K. Autonomous Multilateral Surgical Tumor Resection with Interchangeable Instrument Mounts and Fluid Injection Device. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 19–20 May 2016. [Google Scholar]
- Datta, V.; Mandalia, M.; Mackay, S.; Chang, A.; Cheshire, N.; Darzi, A. Relationship between Skill and Outcome in the Laboratory-Based Model. Surgery 2002, 131, 318–323. [Google Scholar] [CrossRef] [PubMed]
- Cavallo, F.; Megali, G.; Sinigaglia, S.; Tonet, O.; Dario, P. A Biomechanical Analysis of Surgeon’s Gesture in a Laparoscopic Virtual Scenario. Med. Meets Virtual Reality. Stud. Health Technol. Inform. 2006, 119, 79–84. [Google Scholar]
- Rivas-Blanco, I.; Pérez-del-Pulgar, C.J.; Mariani, A.; Quaglia, C.; Tortora, G.; Menciassi, A.; Muñoz, V.F. A Surgical Dataset from the Da Vinci Research Kit for Task Automation and Recognition. arXiv 2021, arXiv:2102.03643. [Google Scholar]
- Boyle, E.; Al-Akash, M.; Gallagher, A.G.; Traynor, O.; Hill, A.D.K.; Neary, P.C. Optimising Surgical Training: Use of Feedback to Reduce Errors during a Simulated Surgical Procedure. Postgrad. Med. J. 2011, 87, 524–528. [Google Scholar] [CrossRef]
- Cotin, S.; Stylopoulos, N.; Ottensmeyer, M.; Neumann, P.; Bardsley, R.; Dawson, S. Surgical Training System for Laparoscopic Procedures. U.S. Patent US20050142525A1, 30 June 2005. [Google Scholar]
- Rohrer, B.; Fasoli, S.; Krebs, H.I.; Hughes, R.; Volpe, B.; Frontera, W.R.; Stein, J.; Hogan, N. Movement Smoothness Changes during Stroke Recovery. J. Neurosci. 2002, 22, 8297–8304. [Google Scholar] [CrossRef]
- Takada, K.; Yashiro, K.; Takagi, M. Reliability and Sensitivity of Jerk-Cost Measurement for Evaluating Irregularity of Chewing Jaw Movements. Physiol. Meas. 2006, 27, 609–622. [Google Scholar] [CrossRef]
- Moody, L.; Baber, C.; Arvanitis, T.N.; Elliott, M. Objective Metrics for the Evaluation of Simple Surgical Skills in Real and Virtual Domains. Presence Teleoperators Virtual Environ. 2003, 12, 207–221. [Google Scholar] [CrossRef]
- Nagy, T.D.; Haidegger, T. Recent Advances in Robot-Assisted Surgery: Soft Tissue Contact Identification. In Proceedings of the 13th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 29–31 May 2019; pp. 99–105. [Google Scholar]
- Li, T.; Shi, C.; Ren, H. A High-Sensitivity Tactile Sensor Array Based on Fiber Bragg Grating Sensing for Tissue Palpation in Minimally Invasive Surgery. IEEE/ASME Trans. Mechatron. 2018, 23, 2306–2315. [Google Scholar] [CrossRef]
- Jung, W.J.; Kwak, K.S.; Lim, S.C. Vision-Based Suture Tensile Force Estimation in Robotic Surgery. Sensors 2020, 21, 110. [Google Scholar] [CrossRef]
- Trejos, A.L.; Patel, R.V.; Naish, M.D.; Lyle, A.C.; Schlachta, C.M. A Sensorized Instrument for Skills Assessment and Training in Minimally Invasive Surgery. J. Med. Devices 2009, 3. [Google Scholar] [CrossRef]
- Jones, D.; Wang, H.; Alazmani, A.; Culmer, P.R. A Soft Multi-Axial Force Sensor to Assess Tissue Properties in RealTime. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5738–5743. [Google Scholar] [CrossRef]
- Osa, T.; Sugita, N.; Mitsuishi, M. Online Trajectory Planning in Dynamic Environments for Surgical Task Automation. In Proceedings of the Robotics: Science and Systems Foundation, Berkeley, CA, USA, 12–16 July 2014; pp. 1–9. [Google Scholar] [CrossRef]
- Lu, B.; Chu, H.K.; Cheng, L. Robotic Knot Tying through a Spatial Trajectory with a Visual Servoing System. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5710–5716. [Google Scholar] [CrossRef]
- Elek, R.; Nagy, T.D.; Nagy, D.Á.; Garamvölgyi, T.; Takács, B.; Galambos, P.; Tar, J.K.; Rudas, I.J.; Haidegger, T. Towards Surgical Subtask Automation—Blunt Dissection. In Proceedings of the IEEE 21st International Conference on Intelligent Engineering Systems (INES), Larnaca, Cyprus, 20–23 October 2017; pp. 253–258. [Google Scholar]
- Haidegger, T. Theory and Method to Enhance Computer-Integrated Surgical Systems. Ph.D. Thesis, Budapest University of Technology and Economics, Budapest, Hungary, 2010. [Google Scholar]
- Pedram, S.A.; Shin, C.; Ferguson, P.W.; Ma, J.; Dutson, E.P.; Rosen, J. Autonomous Suturing Framework and Quantification Using a Cable-Driven Surgical Robot. IEEE Trans. Robot. 2021, 37, 404–417. [Google Scholar] [CrossRef]
- Haidegger, T.; Kazanzides, P.; Rudas, I.; Benyó, B.; Benyó, Z. The Importance of Accuracy Measurement Standards for Computer-Integrated Interventional Systems. In Proceedings of the EURON GEM Sig Workshop on the Role of Experiments in Robotics Research at IEEE ICRA, Anchorage, AK, USA, 3 May 2010. [Google Scholar]
- Nagy, T.D.; Ukhrenkov, N.; Drexler, D.A.; Takács, Á.; Haidegger, T. Enabling Quantitative Analysis of Situation Awareness: System Architecture for Autonomous Vehicle Handover Studies. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 914–918. [Google Scholar]
- Fiorini, P. Automation and Autonomy in Robotic Surgery. In Robotic Surgery; Springer International Publishing: Cham, Switzerland, 2021; pp. 237–255. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Kondermann, D.; Nair, R.; Honauer, K.; Krispin, K.; Andrulis, J.; Brock, A.; Gussefeld, B.; Rahimimoghaddam, M.; Hofmann, S.; Brenner, C.; et al. The HCI Benchmark Suite: Stereo and Flow Ground Truth with Uncertainties for Urban Autonomous Driving. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 19–28. [Google Scholar] [CrossRef]
- Song, X.; Wang, P.; Zhou, D.; Zhu, R.; Guan, C.; Dai, Y.; Su, H.; Li, H.; Yang, R. ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5452–5462. [Google Scholar]
- Izquierdo, R.; Quintanar, A.; Parra, I.; Fernández-Llorca, D.; Sotelo, M.A. The PREVENTION Dataset: A Novel Benchmark for PREdiction of VEhicles iNTentIONs. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3114–3121. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Osinski, B.; Milos, P.; Jakubowski, A.; Ziecina, P.; Martyniak, M.; Galias, C.; Breuer, A.; Homoceanu, S.; Michalewski, H. CARLA Real Traffic Scenarios—Novel Training Ground and Benchmark for Autonomous Driving. arXiv 2020, arXiv:2012.11329. [Google Scholar]
- Chen, R.; Arief, M.; Zhang, W.; Zhao, D. How to Evaluate Proving Grounds for Self-Driving? A Quantitative Approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5737–5748. [Google Scholar]
- Hasan, S.M.K.; Linte, C.A. U-NetPlus: A Modified Encoder-Decoder U-Net Architecture for Semantic and Instance Segmentation of Surgical Instrument. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019. [Google Scholar]
- Zia, A.; Bhattacharyya, K.; Liu, X.; Wang, Z.; Kondo, S.; Colleoni, E.; van Amsterdam, B.; Hussain, R.; Hussain, R.; Maier-Hein, L.; et al. Surgical Visual Domain Adaptation: Results from the MICCAI 2020 SurgVisDom Challenge. arXiv 2021, arXiv:2102.13644. [Google Scholar]
- Munawar, A.; Wang, Y.; Gondokaryono, R.; Fischer, G.S. A Real-Time Dynamic Simulator and an Associated Front-End Representation Format for Simulating Complex Robots and Environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1875–1882. [Google Scholar] [CrossRef]
- Munawar, A.; Wu, J.Y.; Fischer, G.S.; Taylor, R.H.; Kazanzides, P. Open Simulation Environment for Learning and Practice of Robot-Assisted Surgical Suturing. IEEE Robot. Autom. Lett. 2022, 7, 3843–3850. [Google Scholar] [CrossRef]
- Takacs, K.; Moga, K.; Haidegger, T. Sensorized Psychomotor Skill Assessment Platform Built on a Robotic Surgery Phantom. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 23–25 January 2020; pp. 95–100. [Google Scholar] [CrossRef]
- Fernandez-Lozano, J.; de Gabriel, J.; Munoz, V.; Garcia-Morales, I.; Melgar, D.; Vara, C.; Garcia-Cerezo, A. Human-Machine Interface Evaluation in a Computer Assisted Surgical System. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004; Volume 1, pp. 231–236. [Google Scholar] [CrossRef]
- Li, Z.; Gordon, A.; Looi, T.; Drake, J.; Forrest, C.; Taylor, R.H. Anatomical Mesh-Based Virtual Fixtures for Surgical Robots. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Takács, Á.; Drexler, D.A.; Nagy, T.D.; Haidegger, T. Handover Process of Autonomous Driver Assist Systems—A Call for Critical Performance Assessment. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots Ans Systems (IROS), Macau, China, 4–8 November 2019; p. 3390. [Google Scholar]
- Baker, J.W.; Schubert, M.; Faber, M.H. On the Assessment of Robustness. Struct. Saf. 2008, 30, 253–267. [Google Scholar]
- Meyer, B. Object-Oriented Software Construction; Interactive Software Engineering (ISE) Inc.: Santa Barbara, CA, USA, 1997. [Google Scholar]
- Huber, P.J. Robust Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 523. [Google Scholar]
- Slotine, J.J.E.; Li, W. Applied Nonlinear Control; Prentice Hall: Englewood Cliffs, NJ, USA, 1991; Volume 199. [Google Scholar]
- Hutchison, C.; Zizyte, M.; Lanigan, P.E.; Guttendorf, D.; Wagner, M.; Goues, C.L.; Koopman, P. Robustness Testing of Autonomy Software. In Proceedings of the 40th International Conference on Software Engineering: Software Engineering in Practice, Gothenburg, Sweden, 30 May–1 June 2018; pp. 276–285. [Google Scholar] [CrossRef]
- Rudzicz, F.; Saqur, R. Ethics of Artificial Intelligence in Surgery. arXiv 2020, arXiv:2007.14302. [Google Scholar]
- Boesl, D.B.O.; Bode, M. Signaling Sustainable Robotics—A Concept to Implement the Idea of Robotic Governance. In Proceedings of the 2019 IEEE 23rd International Conference on Intelligent Engineering Systems (INES), Gödöllő, Hungary, 25–27 April2019; pp. 143–146. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Metric | Task | Relevance | Clinical | Overall |
|---|---|---|---|---|---|
| Independency | with Quality | Importance | Score | ||
| Temporal | Completion Time | 2 | 2 | 2 | 6 |
| Time to Compute | 2 | 2 | 2 | 6 | |
| Reaction Time | 3 | 2 | 3 | 8 | |
| Outcome | Rate of Errors | 2 | 3 | 3 | 8 |
| Quality of the Outcome | 2 | 3 | 3 | 8 | |
| Success Rate | 2 | 3 | 3 | 8 | |
| Motion-based | Distance Traveled | 2 | 2 | 1 | 5 |
| Economy of Motion | 2 | 2 | 1 | 5 | |
| Number of Movements | 2 | 2 | 1 | 5 | |
| Velocity and Acc. | Peak Speed | 2 | 1 | 1 | 4 |
| Number of Accelerations | 2 | 1 | 1 | 4 | |
| Mean Acceleration | 2 | 1 | 1 | 4 | |
| Jerk | Jerk | 3 | 1 | 1 | 5 |
| Force-based | Grasp Force | 1 | 3 | 3 | 7 |
| Cartesian Force | 2 | 3 | 3 | 8 | |
| Accuracy | Accuracy of Pose Estimation | 3 | 3 | 3 | 9 |
| Accuracy of Object Detection | 3 | 3 | 3 | 9 | |
| Application Accuracy | 2 | 3 | 3 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagy, T.D.; Haidegger, T. Performance and Capability Assessment in Surgical Subtask Automation. Sensors 2022, 22, 2501. https://doi.org/10.3390/s22072501
Nagy TD, Haidegger T. Performance and Capability Assessment in Surgical Subtask Automation. Sensors. 2022; 22(7):2501. https://doi.org/10.3390/s22072501
Chicago/Turabian StyleNagy, Tamás D., and Tamás Haidegger. 2022. "Performance and Capability Assessment in Surgical Subtask Automation" Sensors 22, no. 7: 2501. https://doi.org/10.3390/s22072501
APA StyleNagy, T. D., & Haidegger, T. (2022). Performance and Capability Assessment in Surgical Subtask Automation. Sensors, 22(7), 2501. https://doi.org/10.3390/s22072501