
Evaluation of Decision Fusion Methods for Multimodal Biometrics in the Banking Application


Abstract
1. Introduction
2. Overview of Multimodal Biometric System
2.1. Biometric Sensors
2.2. Data Collection Procedure
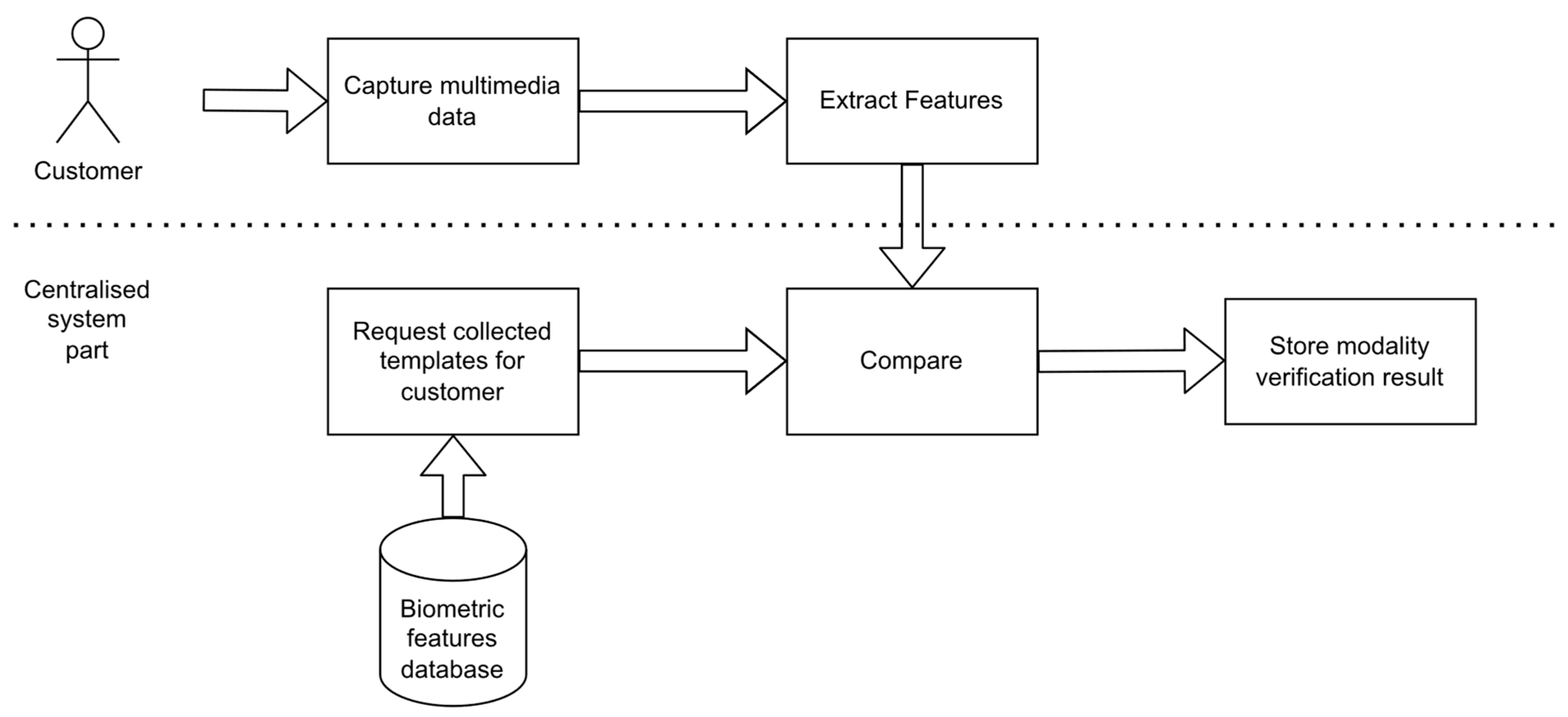
2.3. Identity Verification Procedure
2.4. System Architecture
- -
- Apache server supporting two versions of the frontend application used on the MS Surface screen and monitor screen, communicating with each other using the indicated protocol,
- -
- RabbitMQ communication server—supporting communication between solution components,
- -
- MongoDB database with a dedicated microservice to handle all interactions with the database.
2.5. Decision Fusion
3. Multimodal Biometric Fusion Methods
3.1. Feature Level Fusion
3.2. Comparison Score Level Fusion
3.3. Decision Level Fusion
3.4. Dempster–Shafer Theory in Data Fusion
4. Implementation of Comparison Score Fusion
- Signature—accelerometer and a gyroscope signals processed with the triplet loss method, involving training a neural network to learn a new latent space representation, most suitable for maximization of the distance between signatures from different persons and minimization of the distance between signatures of the same person [31],
- 3D face image—the minimal distance between parameterized 3d meshes [32],
- Gaze tracking—the minimal distance in descriptor space, including statistical features of registered rapid eye movement speed (saccades), average, maximal, standard deviation, acceleration, length, distance, etc.
4.1. Characterization of Biometric Algorithms
4.2. Dempster-Shafer Theory Application in Biometric Verification
4.2.1. Imprecision vs. Uncertainty
4.2.2. Belief Model in DST
4.2.3. Mass and Base Probability
- Ω—universal set of all facts, e.g., Ω = {a, b}, later also denoted as e (“either”)
- 2Ω—power set of all possible subsets of Ω, e.g., 2Ω = {ø, {a}, {b}, {a, b}}
- m( )—mass function, the base probability function for any of elements in 2Ω, following three properties (1):m: 2Ω → [0, 1],
m(ø) = 0,
ΣA∈2Ω m(A) = 1.
4.2.4. Probability in the DST Belief Model
Pl(A) = Σ (B∩A)≠∅ m(B).
4.2.5. Probability Estimation Methods
4.2.6. Masses and Probabilities for a Binary User Identity Verification
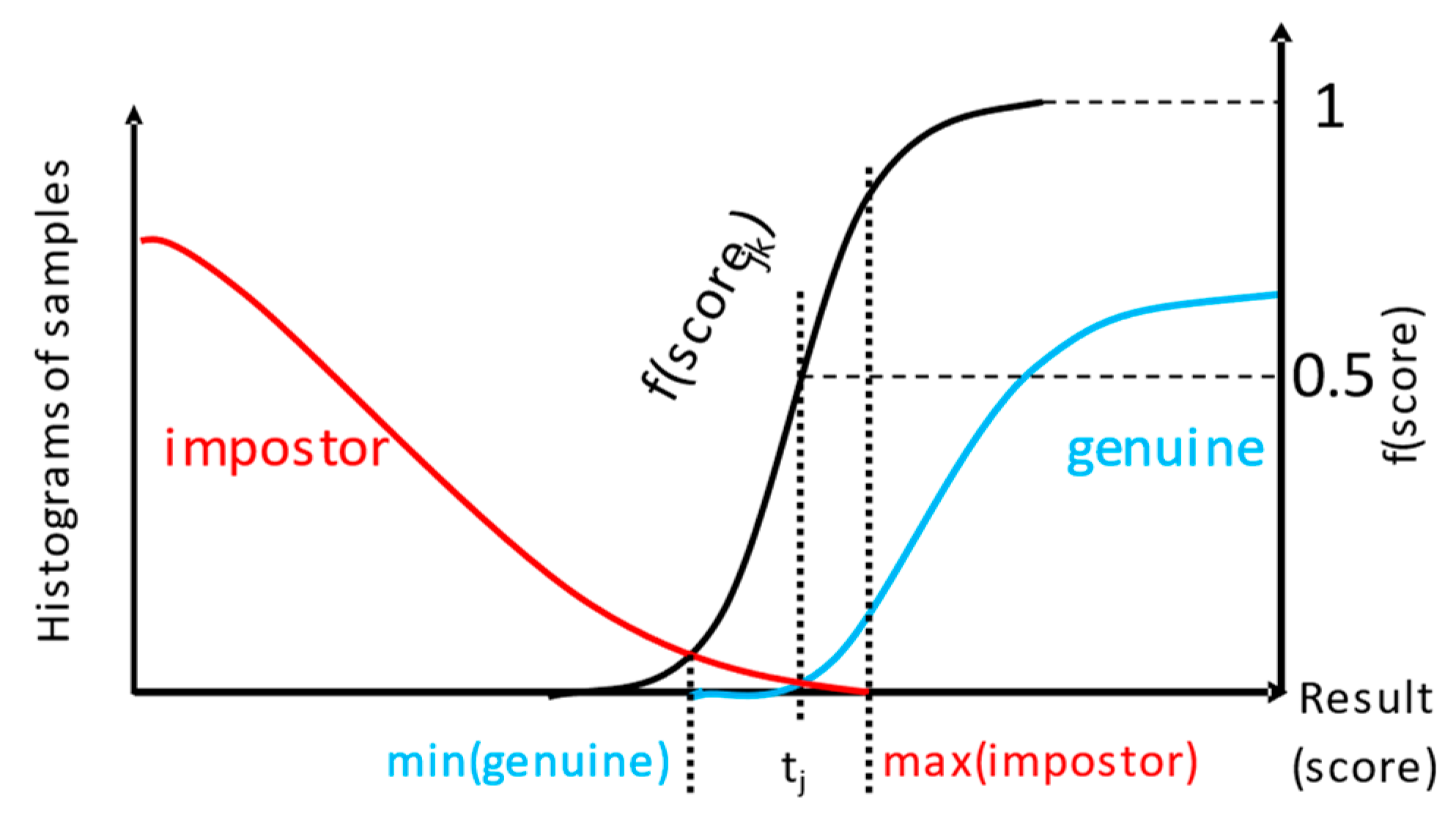
4.2.7. Conversion of Classifier Score to Mass Value
- j—the j-th modality detector
- k—the k-th examined sample
- Ω—the set of probable facts Ω = {g, i}, further denoted also as e (“either”)
- m()—base probability, mass
- tj—threshold for which the fj(scorejk) will be 0.5.
- r—curve parameter, the speed of saturation of the fj( ), depends on the design decision about the score value where the mass should be large enough, e.g., surpass 0.9.
4.3. Fusion of Decisions in Multimodal Binary Classification
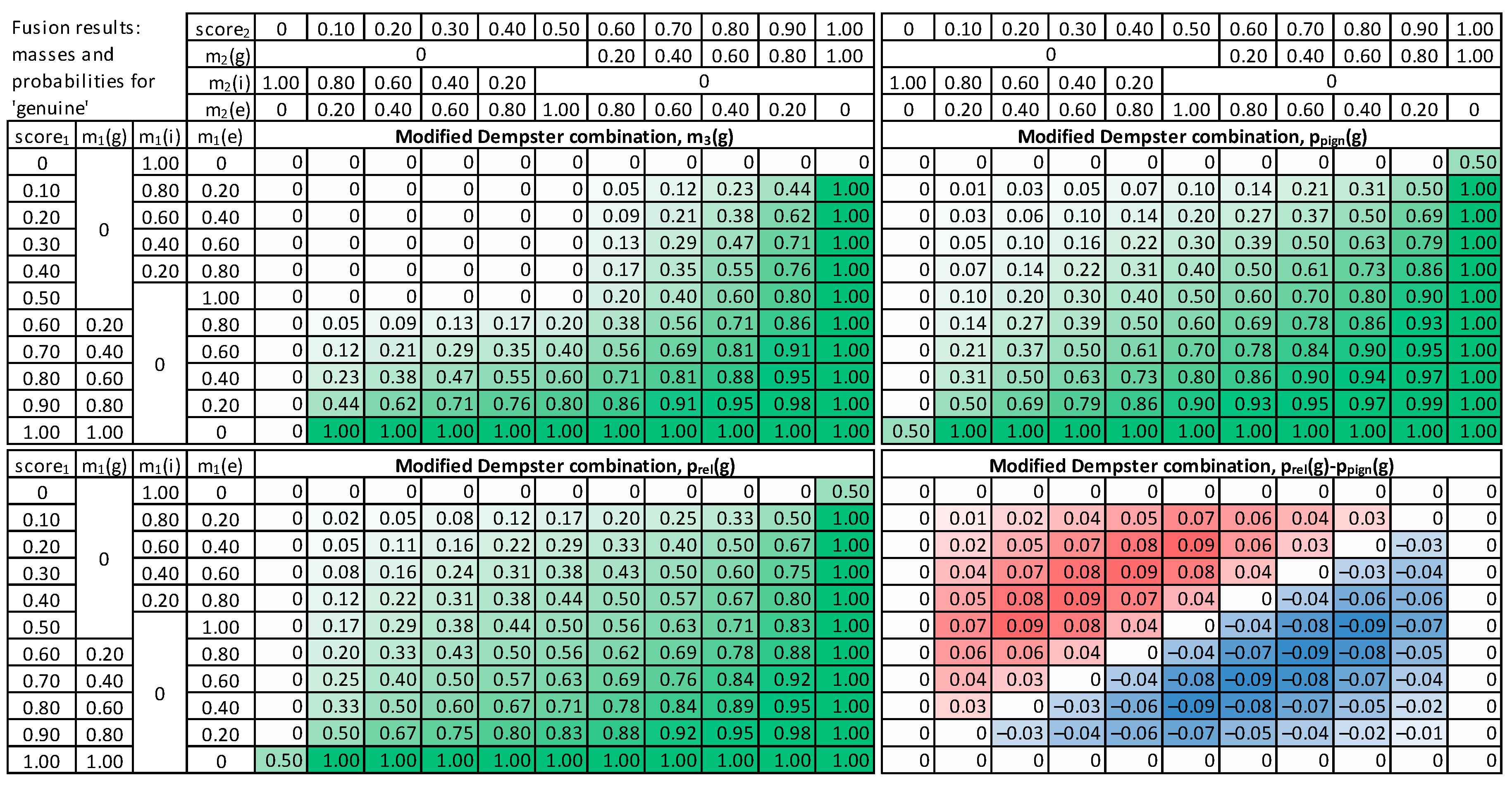
4.3.1. Dempster’s Fusion of Evidence
4.3.2. Modified Combination of Evidence
5. Fusion Methods Evaluation
6. Fusion Experiments on Multimodal Biometrics Dataset
6.1. Biometric Database
6.2. Experiment Design
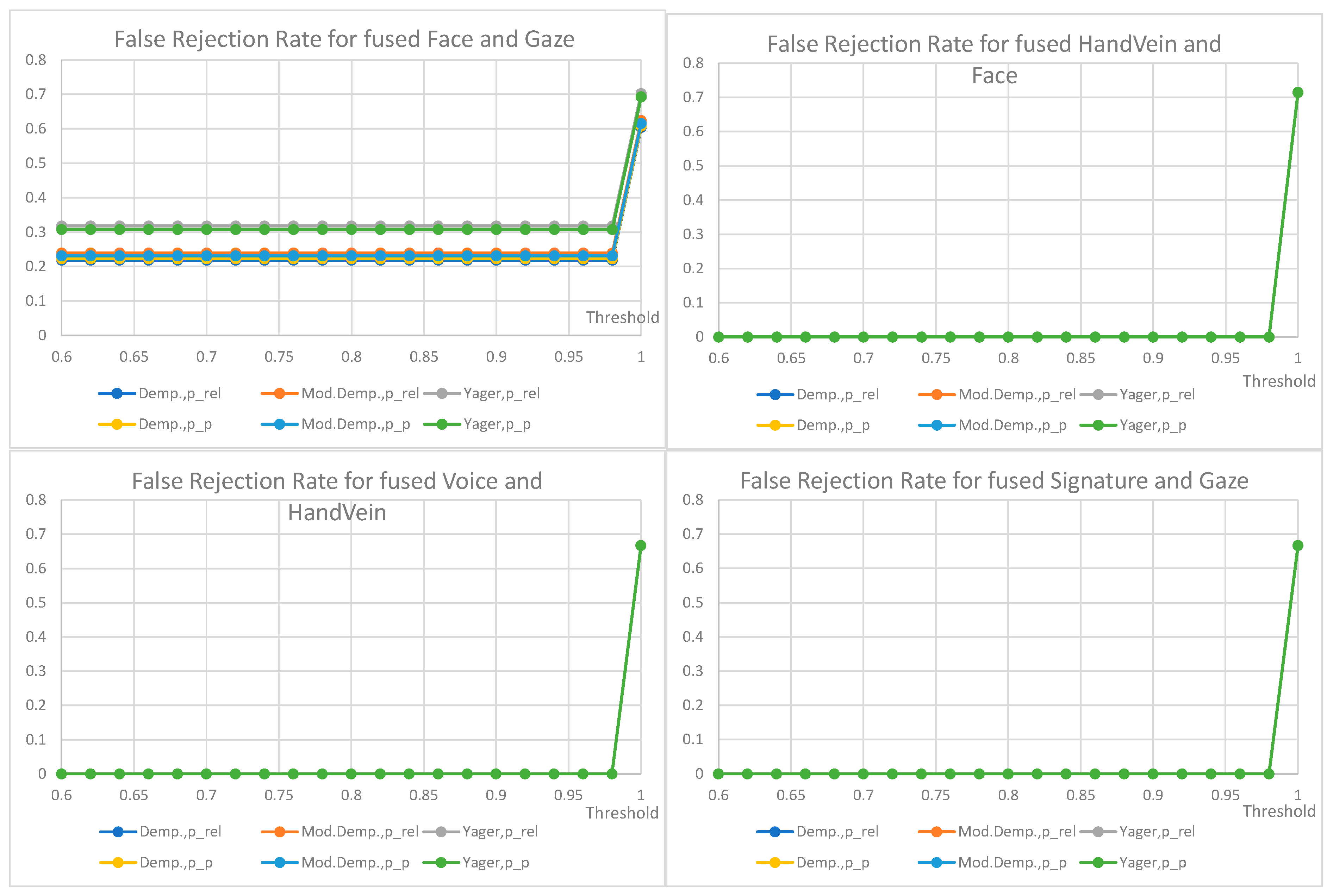
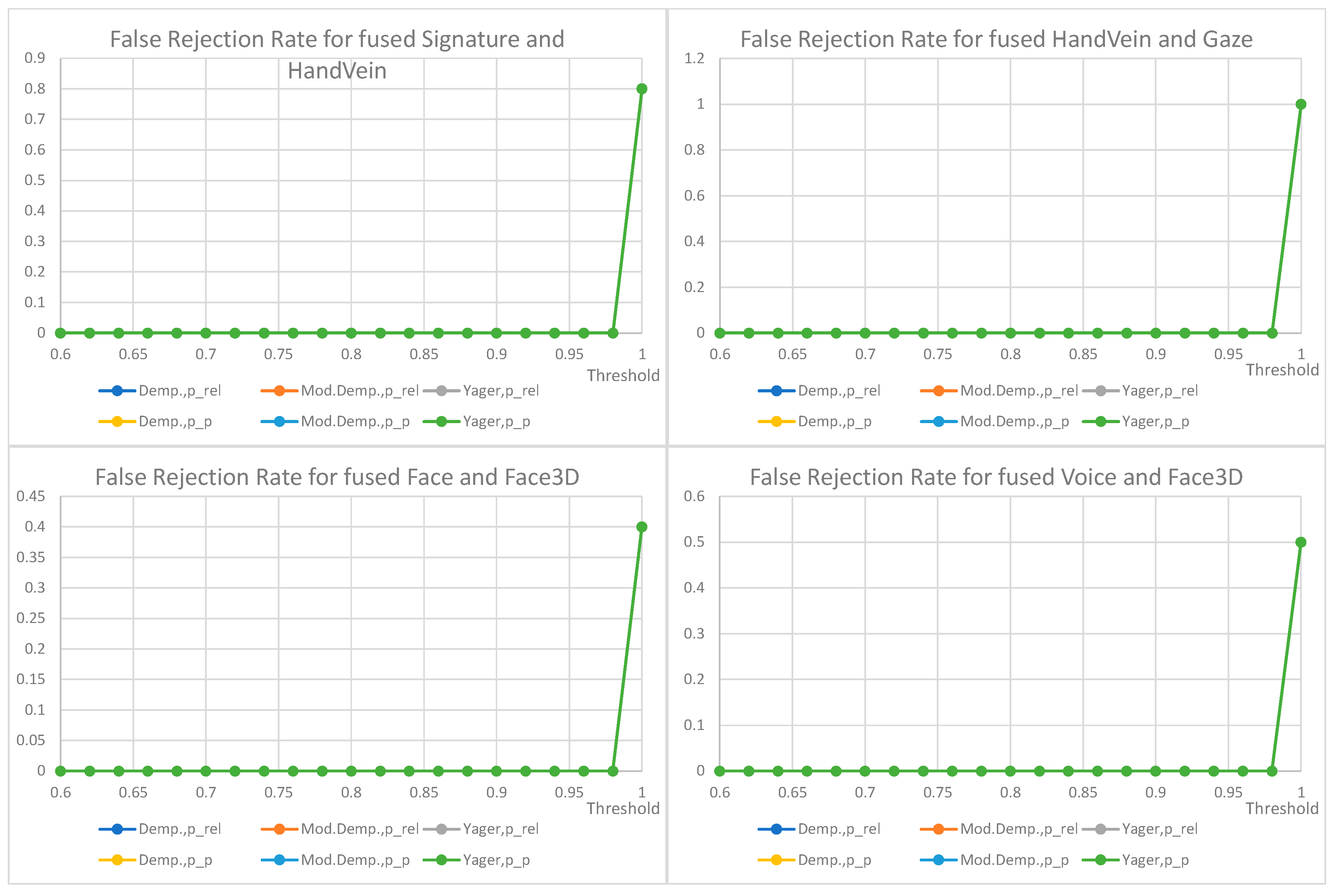
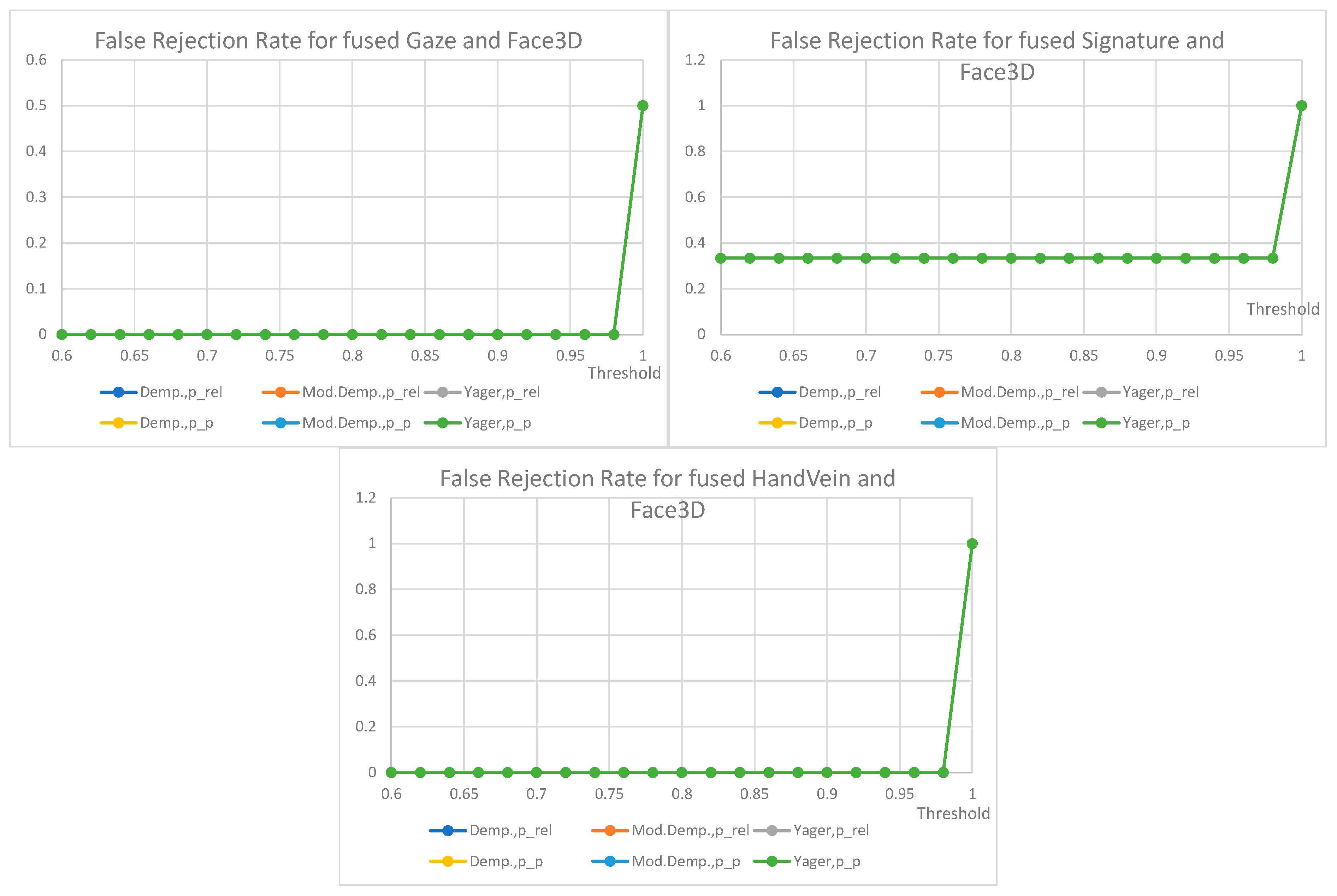
7. Results
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- El-Abed, M.; Giot, R.; Hemery, B.; Rosenberger, C. A study of users’ acceptance and satisfaction of biometric systems. In Proceedings of the IEEE International Carnahan Conference on Security Technology (ICCST), San Francisco, CA, USA, 5–8 October 2010; pp. 170–178. [Google Scholar]
- Czyżewski, A.; Hoffmann, P.; Szczuko, P.; Kurowski, A.; Lech, M.; Szczodrak, M. Analysis of results of large-scale multimodal biometric identity verification experiment. IET Biom. 2018, 8, 92–100. [Google Scholar] [CrossRef]
- Szczuko, P.; Czyżewski, A.; Hoffmann, P.; Bratoszewski, P.; Lech, M. Validating data acquired with experimental multimodal biometric system installed in bank branches. J. Intell. Inf. Syst. 2019, 52, 1–31. [Google Scholar] [CrossRef]
- Ross, A.; Jain, A. Multimodal biometrics: An overview. In Proceedings of the 12th European Signal Processing Conference (EUSIPCO), Vienna, Austria, 6–10 September 2004; pp. 1221–1224. [Google Scholar]
- Sanjekar, P.S.; Patil, J.B. An overview of multimodal biometrics. Signal Image Process. 2013, 4, 57. [Google Scholar]
- Oloyede, M.O.; Hancke, G.P. Unimodal and multimodal biometric sensing systems: A review. IEEE Access 2016, 4, 7532–7555. [Google Scholar] [CrossRef]
- Jain, A.; Kumar, A. Biometrics of next generation: An overview. In Second Generation Biometrics; Springer: Berlin/Heidelberg, Germany, 2010; Volume 12, pp. 2–3. [Google Scholar]
- Gudavalli, M.; Raju, S.V.; Babu, A.V.; Kumar, D.S. Multimodal biometrics—Sources, architecture and fusion techniques: An overview. In Proceedings of the International Symposium on Biometrics and Security Technologies, Taipei, Taiwan, 26–29 March 2012; pp. 27–34. [Google Scholar]
- Kind, A. Biometrics and the metaphysics of personal identity. IET Biom. 2021, 1–7. [Google Scholar] [CrossRef]
- Arora, S.; Bhatia, M. Challenges and opportunities in biometric security: A survey. Inf. Secur. J. A Glob. Perspect. 2022, 31, 28–48. [Google Scholar] [CrossRef]
- European Parliament. EU Regulation 2016/679 of the European Parliament and of the Council (General Data Protection Regulation); European Parliament: Luxemburg, 2016. [Google Scholar]
- ISO/IEC 24745:2011. Information Technology—Security Techniques—Biometric Information Protection; International Organization for Standardization: Geneva, Switzerland, 2011. [Google Scholar]
- Haghighat, M.; Abdel-Mottaleb, M.; Alhalabi, W. Discriminant correlation analysis: Real-time feature level fusion for multimodal biometric recognition. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1984–1996. [Google Scholar] [CrossRef]
- Shekhar, S.; Patel, V.M.; Nasrabadi, N.M.; Chellappa, R. Joint sparse representation for robust multimodal biometrics recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 113–126. [Google Scholar] [CrossRef]
- Hezil, N.; Boukrouche, A. Multimodal biometric recognition using human ear and palmprint. IET Biom. 2017, 6, 351–359. [Google Scholar] [CrossRef]
- ISO/IEC 2382-37:2017. Information Technology—Vocabulary—Part 37: Biometrics; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- ISO/IEC 19795-1:2021. Information Technology—Biometric Performance Testing and Reporting—Part 1: Principles and Framework; International Organization for Standardization: Geneva, Switzerland, 2021. [Google Scholar]
- Jain, A.; Nandakumar, K.; Ross, A. Score normalization in multimodal biometric systems. Pattern Recognit. 2005, 38, 2270–2285. [Google Scholar] [CrossRef]
- Ross, A.; Jain, A. Information fusion in biometrics. Pattern Recognit. Lett. 2003, 24, 2115–2125. [Google Scholar] [CrossRef]
- Hanmandlu, M.; Grover, J.; Madasu, V.K.; Vasirkala, S. Score level fusion of hand based biometrics using t-norms. In Proceedings of the IEEE International Conference on Technologies for Homeland Security (HST), Waltham, MA, USA, 8–10 November 2010; pp. 70–76. [Google Scholar]
- Abdolahi, M.; Mohamadi, M.; Jafari, M. Multimodal biometric system fusion using fingerprint and iris with fuzzy logic. Int. J. Soft Comput. Eng. 2013, 2, 504–510. [Google Scholar]
- Benaliouche, H.; Touahria, M. Comparative study of multimodal biometric recognition by fusion of iris and Fingerprint. Sci. World J. 2014, 2014, 829369. [Google Scholar] [CrossRef] [PubMed]
- Mohandes, M.; Deriche, M. Arabic sign language recognition by decisions fusion using Dempster-Shafer theory of evidence. In Proceedings of the Computing, Communications and IT Applications Conference (ComComAp), Hong Kong, China, 1–4 April 2013; pp. 90–94. [Google Scholar]
- Arif, M.; Brouard, T.; Vincent, N. A fusion methodology based on Dempster-Shafer Evidence theory for two Biometric applications. In Proceedings of the International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 590–593. [Google Scholar]
- Singh, R.; Vatsa, M.; Noore, A.; Singh, S.K. Dempster-Shafer theory based classifier fusion for improved fingerprint verification performance. In Computer Vision, Graphics Image Processing; Springer: Berlin, Germany, 2006; pp. 941–949. [Google Scholar]
- Cuzzocrea, A.; Mumolo, E. Dempster-Shafer-based fusion of multi-modal biometrics for supporting identity verification effectively and efficiently. In Proceedings of the 2nd International Conference on Human-Machine Systems (ICHMS), Magdeburg, Germany, 8–10 September 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Szczuko, P.; Czyżewski, A.; Szczodrak, M. Variable length sliding models for banking clients face biometry. Multimedia Tools Appl. 2019, 78, 7749–7766. [Google Scholar] [CrossRef]
- Czyżewski, A. Performance analysis of developed multimodal biometric identity verification system. ELEKTRONIKA-Konstr. Technol. Zastos. 2018, 4, 37–44. [Google Scholar] [CrossRef]
- Szczodrak, M.; Czyżewski, A. Evaluation of face detection algorithms for the bank client identity verification. Found. Comput. Decis. Sci. 2017, 42, 137–148. [Google Scholar] [CrossRef]
- Bratoszewski, P.; Szwoch, G.; Czyżewski, A. Comparison of acoustic and visual voice activity detection for noisy speech recognition. In Proceedings of the Signal Processing: Algorithms Architectures, Arrangements, and Applications Conference (SPA), Poznan, Poland, 21–23 September 2016; pp. 287–291. [Google Scholar] [CrossRef]
- Kurowski, M.; Sroczyński, A.; Bogdanis, G.; Czyżewski, A. An automated method for biometric handwritten signature authentication employing neural networks. Electronics 2021, 10, 456. [Google Scholar] [CrossRef]
- Papatheodorou, T.; Rueckert, D. 3D Face Recognition, Face Recognition; Kresimir, D., Mislav, G., Eds.; IntechOpen: London, UK, 2007. [Google Scholar] [CrossRef]
- Fujitsu. Identity Management and PalmSecure. 2017. Available online: https://www.fujitsu.com/au/Images/PalmSecure_Global_Solution_Catalogue.pdf (accessed on 25 February 2022).
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Smets, P.; Kennes, R. The transferable belief model. Artif. Intell. 1994, 66, 191–234. [Google Scholar] [CrossRef]
- Nguyen, K.; Denman, S.; Sridharan, S.; Fookes, C. Score-level multibiometric fusion based on Dempster–Shafer theory incorporating uncertainty factors. IEEE Trans. Hum.-Mach. Syst. 2014, 45, 132–140. [Google Scholar] [CrossRef][Green Version]
- Kahneman, D.; Slovic, P.; Tversky, A. Judgement Under Uncertainty: Heuristics and Biases; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar] [CrossRef]
- Smets, P. The combination of evidence in the transferable belief model. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 447–458. [Google Scholar] [CrossRef]
- Denoeux, T. Logistic regression revisited: Belief function analysis. In Proceedings of the 5th International Conference on Belief Functions (BELIEF), Compiègne, France, 17–21 September 2018; pp. 57–64. [Google Scholar] [CrossRef]
- Gan, D.; Yang, B.; Tang, Y. An extended base belief function in dempster–shafer evidence theory and its application in conflict data fusion. Mathematics 2020, 8, 2137. [Google Scholar] [CrossRef]
- Haenni, R. Shedding new light on Zadeh’s criticism of Dempster’s rule of combination. In Proceedings of the 7th International Conference on Information Fusion, Philadelphia, PA, USA, 25–28 July 2008; p. 6. [Google Scholar] [CrossRef]
- Yager, R.R. On the dempster-shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Zadeh, L. A simple view of the Dempster–Shafer Theory of Evidence and its implication for the rule of combination. AI Mag. 1986, 7, 85–90. [Google Scholar]
- Fixsen, D.; Mahler, R. The modified Dempster-Shafer approach to classification. IEEE Trans. Syst. Man, Cybern.-Part A Syst. Humans 1997, 27, 96–104. [Google Scholar] [CrossRef]
- Mezai, L.; Hachouf, F.; Bengherabi, M. Score fusion of face and voice using Dempster-Shafer theory for person authentication. In Proceedings of the International Conference on Intelligent Systems Design and Applications, ISDA, Córdoba, Spain, 22–24 November 2011; pp. 894–899. [Google Scholar] [CrossRef]
- Sentz, K.; Ferson, S. Combination of Evidence in Dempster-Shafer Theory; Sandia Report SAND2002-0835; Sandia Laboratories: Albuquerque, NM, USA, 2002. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Type of Modality | Sensor | Connection |
|---|---|---|---|
| 1 | Signature | Dynamic biometric pen | Bluetooth |
| 2 | Voice | Microphone | Internal MS Surface |
| 3 | Face image | External RGB camera integrated with 3D | USB-C |
| 4 | 3D face image | External RGB camera integrated with 3D | USB-C |
| 5 | Gaze tracking | Gaze-tracker | USB 2.0 |
| 6 | Hand vein pattern | Hand vein sensor | USB 2.0 |
| Decision | Belief | Plausibility | Probability | Pignistic Probability | Relative Probability |
|---|---|---|---|---|---|
| Genuine | Bel(g) = m(g) | Pl(g) = m(g) + m(e) | Bel(g) ≤ p(g) ≤ Pl(g) | ppign(g) = m(g) + 0.5m(e) | prel(g) = (1-m(i))/(1 + m(e)) |
| Impostor | Bel(i) = m(i) | Pl(i) = m(i) + m(e) | Bel(i) ≤ p(i) ≤ Pl(i) | ppign(i) = m(i) + 0.5m(e) | prel(i) = (1-m(i))/(1 + m(e)) |
| Modality | Number of Samples |
|---|---|
| Gaze | 2047 |
| Face | 1034 |
| Signature | 790 |
| Voice | 759 |
| Face3D | 98 |
| HandVein | 16 |
| Total: | 4744 |
| The Lowest Number n of Modalities Registered by the Single Individual in a Session | The Number of Individuals with at Least n Different Traits Registered |
|---|---|
| 1 | 197 |
| 2 | 85 |
| 3 | 39 |
| 4 | 9 |
| 5 | 3 |
| 6 | 2 |
| Signature | Voice | HandVein | Face | Gaze | Face3D | |
|---|---|---|---|---|---|---|
| Signature | - | 48 | 5 | 56 | 6 | 3 |
| Voice | - | 6 | 79 | 13 | 4 | |
| HandVein | - | 7 | 5 | 2 | ||
| Face | - | 13 | 5 | |||
| Gaze | - | 4 | ||||
| Face3D | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szczuko, P.; Harasimiuk, A.; Czyżewski, A. Evaluation of Decision Fusion Methods for Multimodal Biometrics in the Banking Application. Sensors 2022, 22, 2356. https://doi.org/10.3390/s22062356
Szczuko P, Harasimiuk A, Czyżewski A. Evaluation of Decision Fusion Methods for Multimodal Biometrics in the Banking Application. Sensors. 2022; 22(6):2356. https://doi.org/10.3390/s22062356
Chicago/Turabian StyleSzczuko, Piotr, Arkadiusz Harasimiuk, and Andrzej Czyżewski. 2022. "Evaluation of Decision Fusion Methods for Multimodal Biometrics in the Banking Application" Sensors 22, no. 6: 2356. https://doi.org/10.3390/s22062356
APA StyleSzczuko, P., Harasimiuk, A., & Czyżewski, A. (2022). Evaluation of Decision Fusion Methods for Multimodal Biometrics in the Banking Application. Sensors, 22(6), 2356. https://doi.org/10.3390/s22062356