
A Novel Domain Transfer-Based Approach for Unsupervised Thermal Image Super-Resolution


Abstract
:1. Introduction
- Improve results from previous work by using a CycleGAN-based approach with novel losses functions.
- Use an attention module in the generator for a better high feature extraction reaching better results.
- Evaluate the approach with different datasets overcoming state-of-the-art results.
2. Related Work
2.1. Benchmark Datasets
2.2. Super-Resolution Approaches
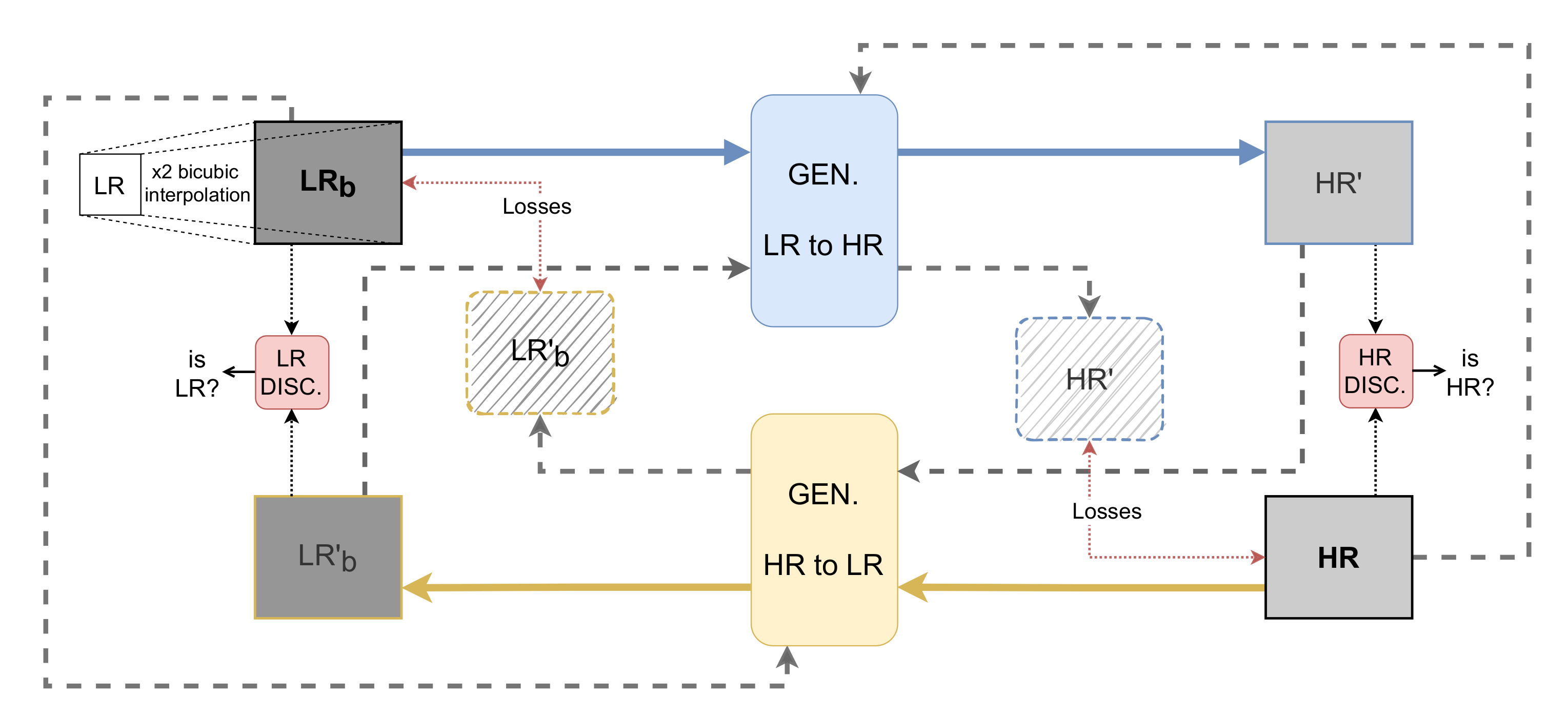
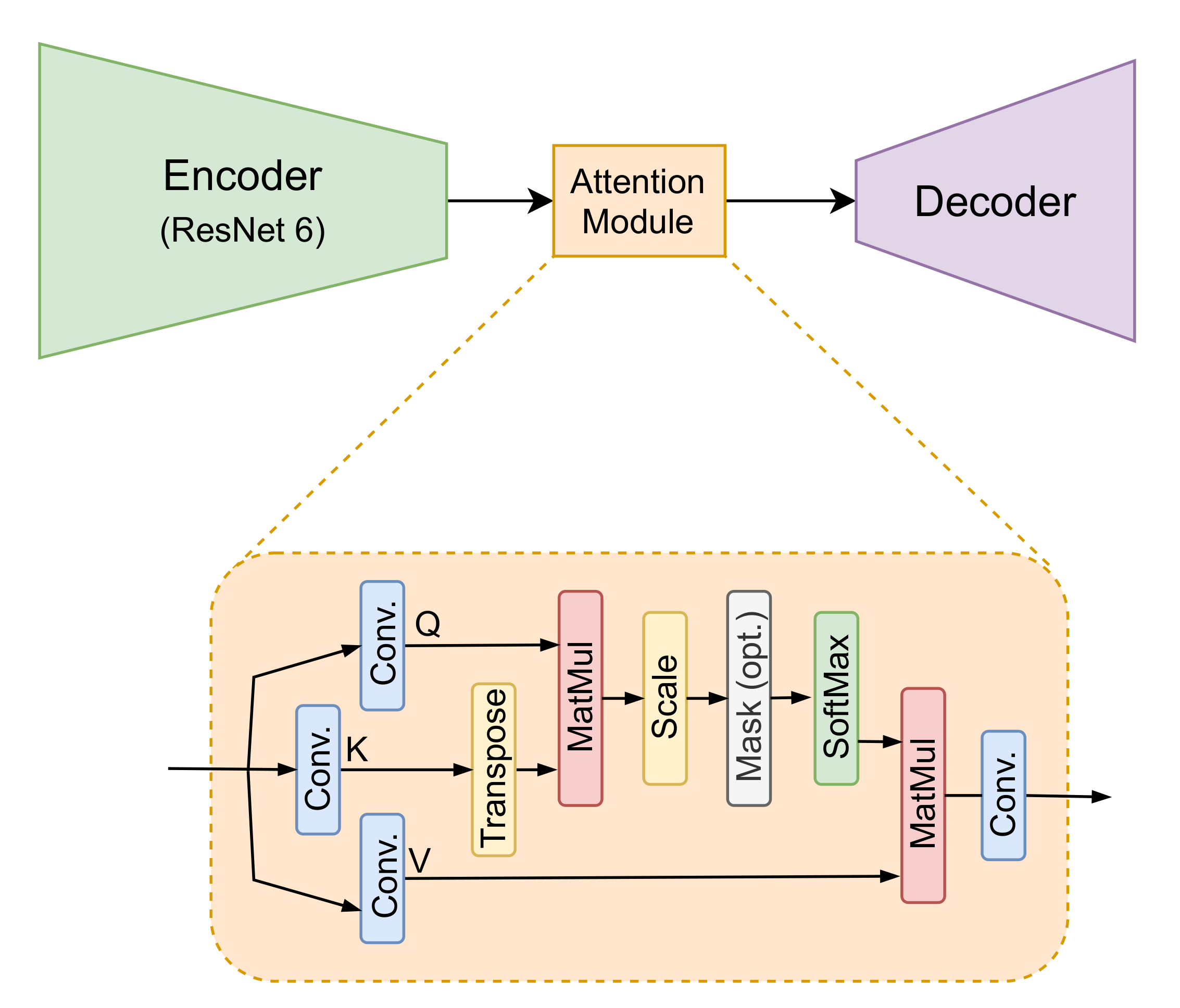
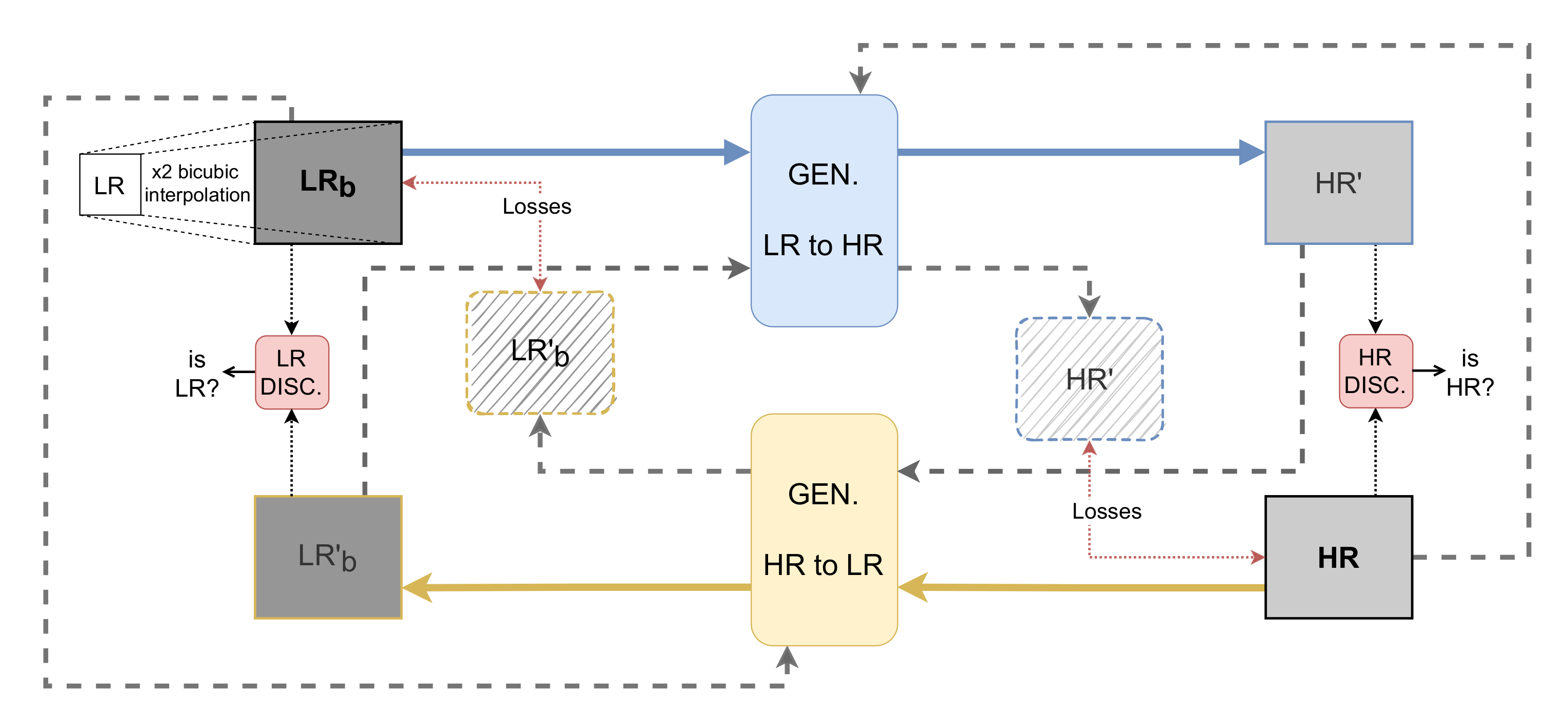
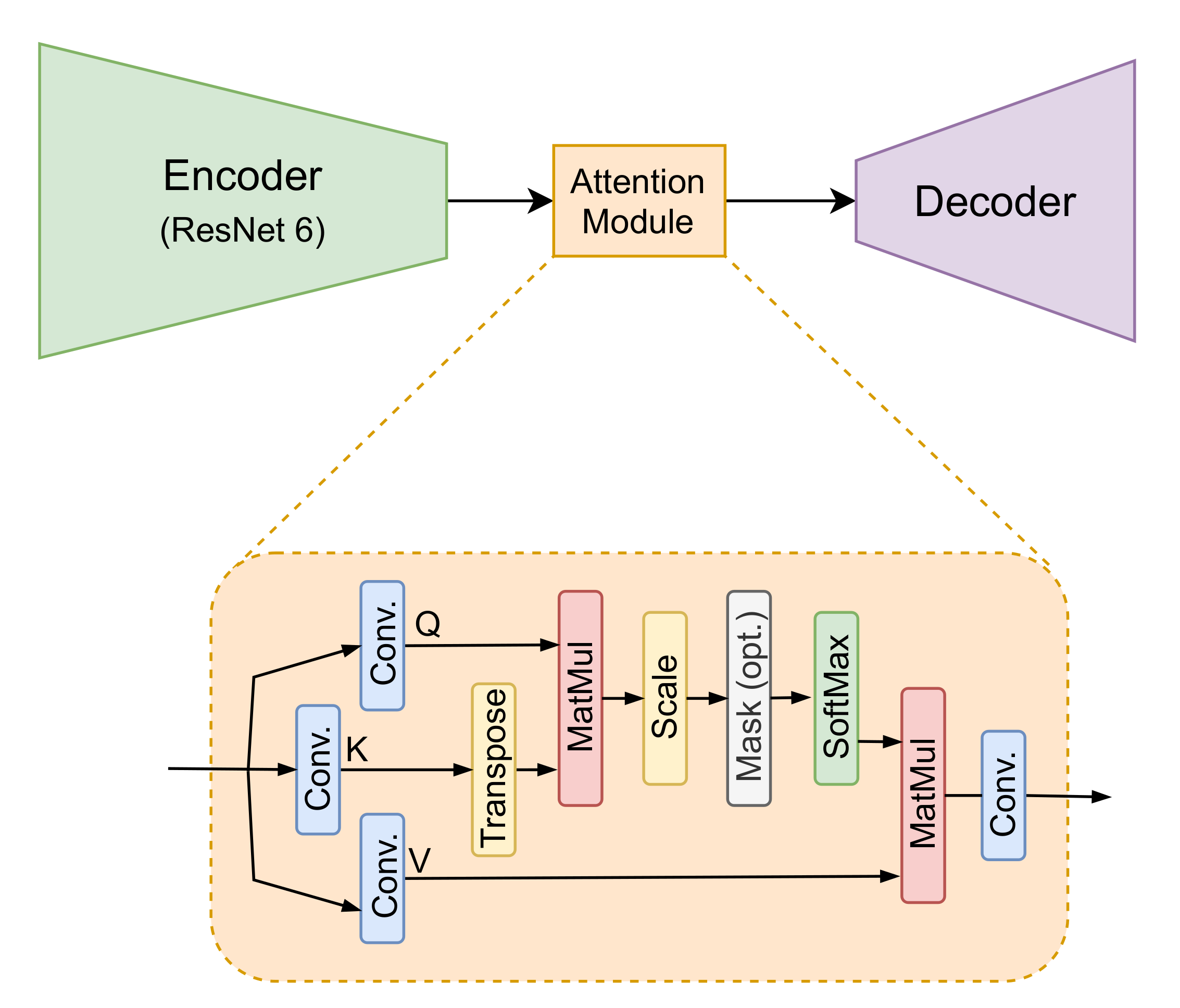
3. Proposed Approach
3.1. Architecture
3.2. Datasets
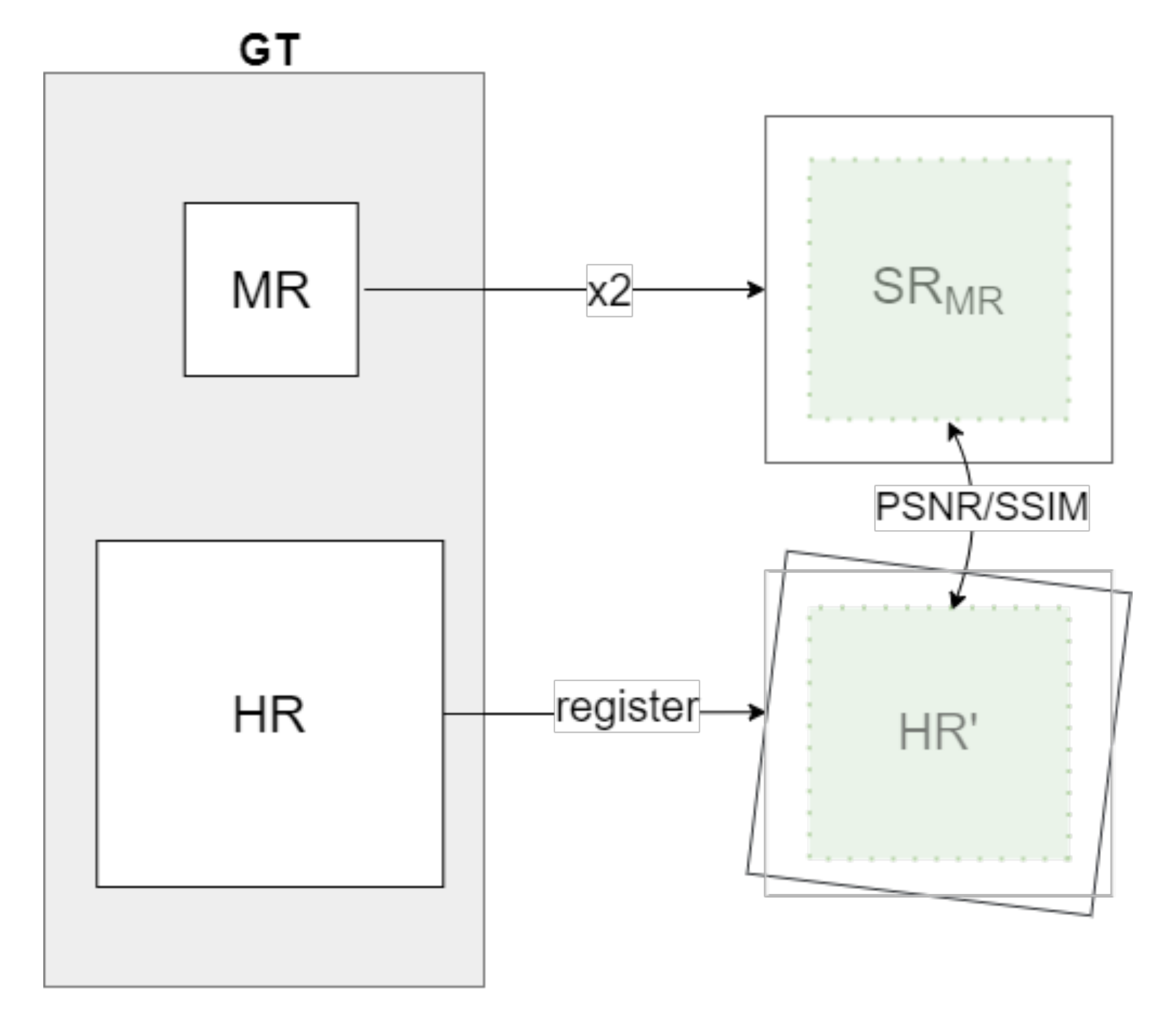
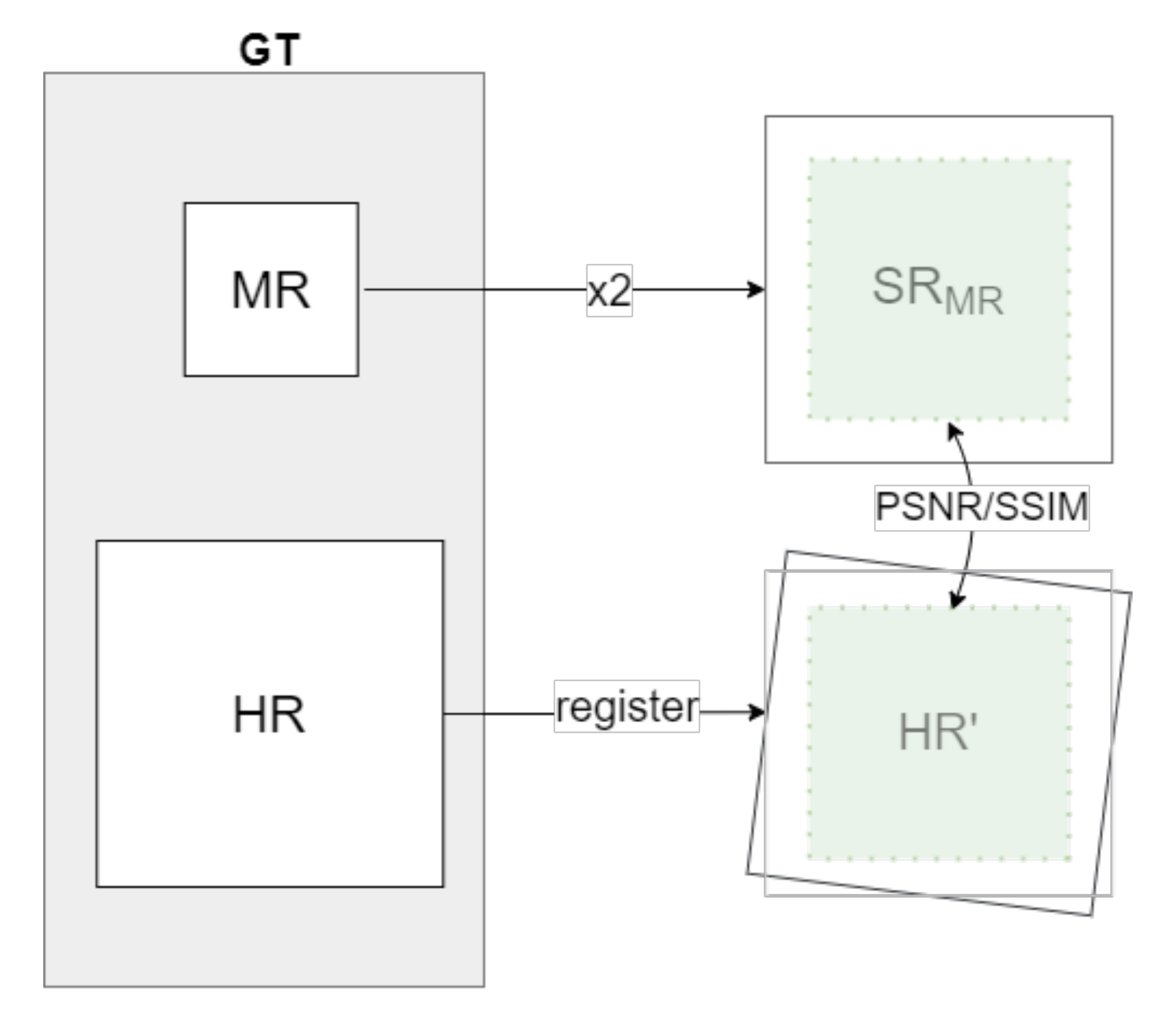
3.3. Evaluation
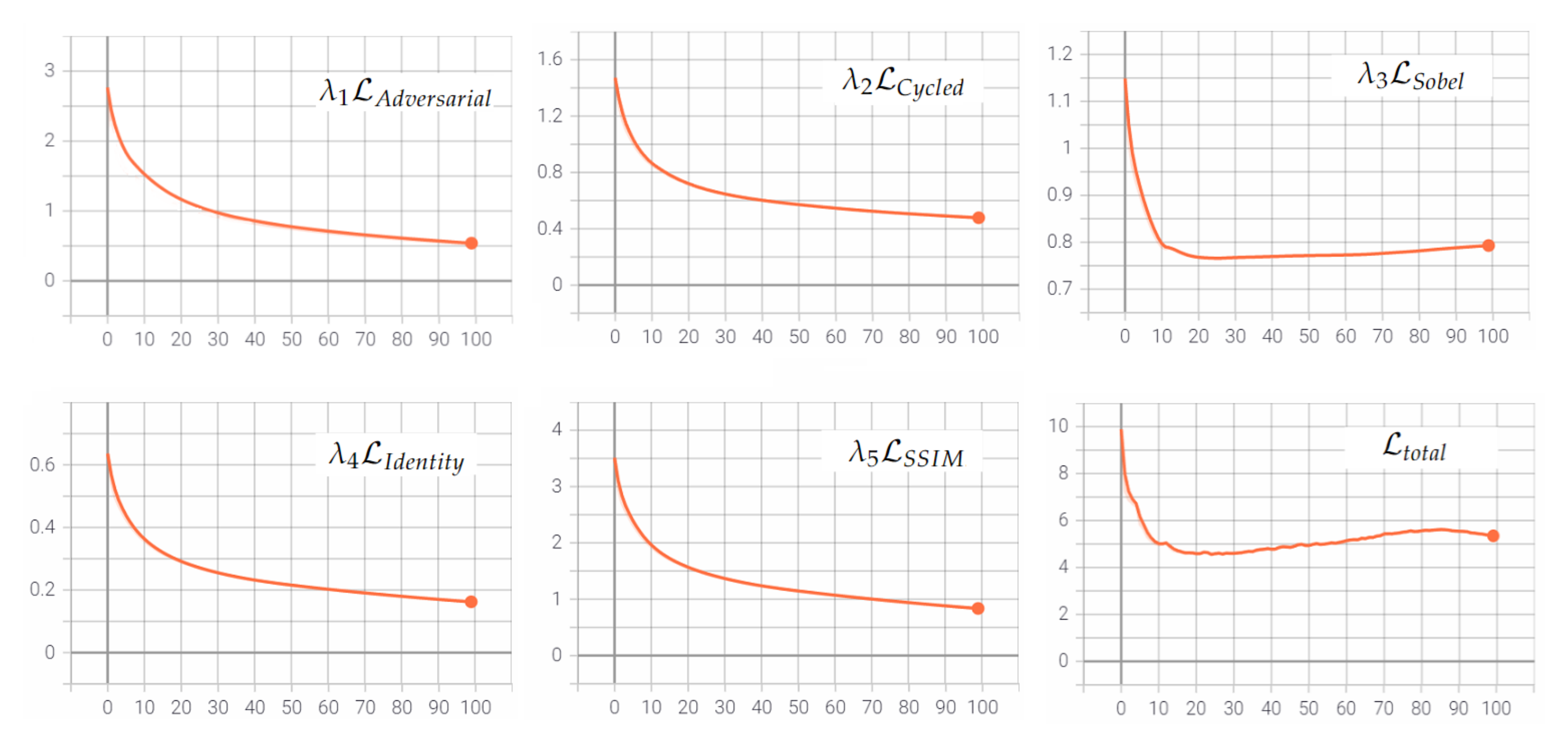
4. Experimental Results
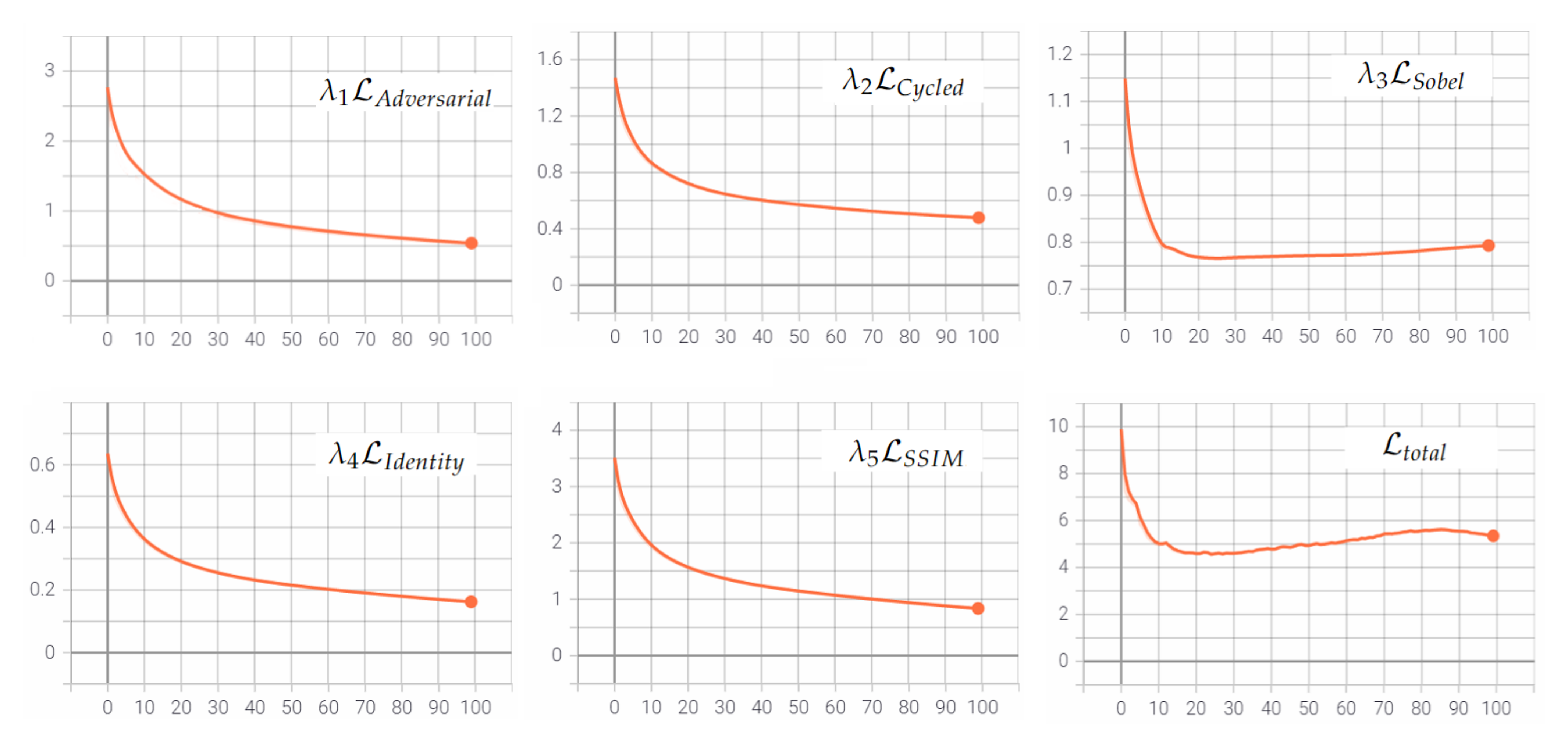
4.1. Settings
4.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SR | Super-Resolution |
| SISR | Single Image Super-Resolution |
| LR | Low-Resolution |
| MR | Mid-Resolution |
| HR | High-Resolution |
| GT | Ground Truth |
| ML | Machine Learning |
| CNN | Convolutional Neural Networks |
| LWIR | Long-Wavelength InfraRed |
| GAN | Generative Adversarial Network |
| AM | Attention Module |
| ROI | Region Of Interest |
| PA | Proposed Approach |
| PSRN | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
References
- Pesavento, M.; Volino, M.; Hilton, A. Attention-Based Multi-Reference Learning for Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 March 2021; pp. 14697–14706. [Google Scholar]
- Han, J.; Yang, Y.; Zhou, C.; Xu, C.; Shi, B. EvIntSR-Net: Event Guided Multiple Latent Frames Reconstruction and Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 March 2021; pp. 4882–4891. [Google Scholar]
- Song, D.; Wang, Y.; Chen, H.; Xu, C.; Xu, C.; Tao, D. AdderSR: Towards Energy Efficient Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, QC, Canada, 10–17 March 2021; pp. 15648–15657. [Google Scholar]
- Wei, Y.; Gu, S.; Li, Y.; Timofte, R.; Jin, L.; Song, H. Unsupervised Real-World Image Super Resolution via Domain-Distance Aware Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, QC, Canada, 10–17 March 2021; pp. 13385–13394. [Google Scholar]
- Zhang, L.; Zhang, H.; Shen, H.; Li, P. A super-resolution reconstruction algorithm for surveillance images. Signal Process. 2010, 90, 848–859. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Jain, D.K.; Jain, V.K.; Yang, J. Deep convolution network for surveillance records super-resolution. Multimed. Tools Appl. 2019, 78, 23815–23829. [Google Scholar] [CrossRef]
- Mudunuri, S.P.; Biswas, S. Low resolution face recognition across variations in pose and illumination. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1034–1040. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Lobanov, A.P. Resolution limits in astronomical images. arXiv 2005, arXiv:astro-ph/0503225. [Google Scholar]
- Rövid, A.; Vámossy, Z.; Sergyán, S. Thermal image processing approaches for security monitoring applications. In Critical Infrastructure Protection Research; Springer: Berlin/Heidelberg, Germany, 2016; pp. 163–175. [Google Scholar]
- Herrmann, C.; Ruf, M.; Beyerer, J. CNN-based thermal infrared person detection by domain adaptation. Autonomous Systems: Sensors, Vehicles, Security, and the Internet of Everything. Int. Soc. Opt. Photonics 2018, 10643, 1064308. [Google Scholar]
- Ding, M.; Zhang, X.; Chen, W.H.; Wei, L.; Cao, Y.F. Thermal infrared pedestrian tracking via fusion of features in driving assistance system of intelligent vehicles. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 6089–6103. [Google Scholar] [CrossRef]
- Zefri, Y.; ElKettani, A.; Sebari, I.; Ait Lamallam, S. Thermal infrared and visual inspection of photovoltaic installations by UAV photogrammetry—application case: Morocco. Drones 2018, 2, 41. [Google Scholar] [CrossRef] [Green Version]
- Haider, A.; Shaukat, F.; Mir, J. Human detection in aerial thermal imaging using a fully convolutional regression network. Infrared Phys. Technol. 2021, 116, 103796. [Google Scholar] [CrossRef]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2014, 25, 245–262. [Google Scholar] [CrossRef] [Green Version]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X. Thermal Image Super-resolution: A Novel Architecture and Dataset. In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2020), Valletta, Malta, 27–29 February 2020; Volume 4, pp. 111–119. [Google Scholar]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Guo, L.; Hou, J.; Mehri, A.; Behjati Ardakani, P.; Patel, H.; Chudasama, V.; Prajapati, K.; et al. Thermal Image Super-Resolution Challenge-PBVS 2020. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 96–97. [Google Scholar]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Nathan, S.; Kansal, P.; Mehri, A.; Ardakani, P.B.; Dalal, A.; Akula, A.; Sharma, D.; et al. Thermal Image Super-Resolution Challenge-PBVS 2021. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 March 2021; pp. 4359–4367. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012; pp. 135.1–135.10. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In International Conference on Curves and Surfaces; Springer: Berlin/Heidelberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Davis, J.W.; Keck, M.A. A two-stage template approach to person detection in thermal imagery. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05), Breckenridge, CO, USA, 5–7 January 2005; Volume 1, pp. 364–369. [Google Scholar]
- Olmeda, D.; Premebida, C.; Nunes, U.; Armingol, J.M.; de la Escalera, A. Pedestrian detection in far infrared images. Integr. Comput. Aided Eng. 2013, 20, 347–360. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Fuller, N.; Theriault, D.; Betke, M. A thermal infrared video benchmark for visual analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 201–208. [Google Scholar]
- Rivadeneira, R.E.; Suárez, P.L.; Sappa, A.D.; Vintimilla, B.X. Thermal Image SuperResolution Through Deep Convolutional Neural Network. In International Conference on Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 417–426. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2672–2680. [Google Scholar]
- Shi, W.; Ledig, C.; Wang, Z.; Theis, L.; Huszar, F. Super Resolution Using a Generative Adversarial Network. U.S. Patent No. 15/706,428, 15 March 2018. [Google Scholar]
- Mehri, A.; Sappa, A.D. Colorizing Near Infrared Images through a Cyclic Adversarial Approach of Unpaired Samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Chang, H.; Lu, J.; Yu, F.; Finkelstein, A. Pairedcyclegan: Asymmetric style transfer for applying and removing makeup. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 40–48. [Google Scholar]
- Suarez, P.L.; Sappa, A.D.; Vintimilla, B.X.; Hammoud, R.I. Image Vegetation Index through a Cycle Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Chen, Y.S.; Wang, Y.C.; Kao, M.H.; Chuang, Y.Y. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6306–6314. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Li, Z.; Luo, S.; Chen, M.; Wu, H.; Wang, T.; Cheng, L. Infrared thermal imaging denoising method based on second-order channel attention mechanism. Infrared Phys. Technol. 2021, 116, 103789. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Liu, Y.; Wang, Y.; Li, N.; Cheng, X.; Zhang, Y.; Huang, Y.; Lu, G. An attention-based approach for single image super resolution. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2777–2784. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 12744–12753. [Google Scholar]
- Yao, T.; Luo, Y.; Hu, J.; Xie, H.; Hu, Q. Infrared image super-resolution via discriminative dictionary and deep residual network. Infrared Phys. Technol. 2020, 107, 103314. [Google Scholar] [CrossRef]
- Long, J.; Peng, Y.; Li, J.; Zhang, L.; Xu, Y. Hyperspectral image super-resolution via subspace-based fast low tensor multi-rank regularization. Infrared Phys. Technol. 2021, 116, 103631. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, N.; Hwang, S.; Kweon, I.S. Thermal image enhancement using convolutional neural network. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 223–230. [Google Scholar]
- Sun, C.; Lv, J.; Li, J.; Qiu, R. A rapid and accurate infrared image super-resolution method based on zoom mechanism. Infrared Phys. Technol. 2018, 88, 228–238. [Google Scholar] [CrossRef]
- Batchuluun, G.; Lee, Y.W.; Nguyen, D.T.; Pham, T.D.; Park, K.R. Thermal image reconstruction using deep learning. IEEE Access 2020, 8, 126839–126858. [Google Scholar] [CrossRef]
- Chudasama, V.; Patel, H.; Prajapati, K.; Upla, K.P.; Ramachandra, R.; Raja, K.; Busch, C. TherISuRNet-A Computationally Efficient Thermal Image Super-Resolution Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 86–87. [Google Scholar]
- Kansal, P.; Nathan, S. A Multi-Level Supervision Model: A Novel Approach for Thermal Image Super Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 94–95. [Google Scholar]
- Prajapati, K.; Chudasama, V.; Patel, H.; Sarvaiya, A.; Upla, K.P.; Raja, K.; Ramachandra, R.; Busch, C. Channel Split Convolutional Neural Network (ChaSNet) for Thermal Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 4368–4377. [Google Scholar]
- Kittler, J. On the accuracy of the Sobel edge detector. Image Vis. Comput. 1983, 1, 37–42. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | PSNR | SSIM |
|---|---|---|
| Our Previous Work [16] | 22.42 | 0.7989 |
| NPU-MPI-LAB [18] | 21.96 | 0.7618 |
| SVNIT-NTNU-2 [18] | 21.44 | 0.7758 |
| ULB-LISA | 22.32 | 0.7899 |
| Current Work (PA-D1) | 22.98 (±2.02) | 0.7991 (±0.0829) |
| Current Work (PA-D1-D2) | 21.93 (±2.07) | 0.8117 (±0.0656) |
| Current Work (PA-D1-AT) | 23.19 (±2.01) | 0.8023 (±0.0751) |
| Current Work (PA-D1-D2-AT) | 21.23 (±2.03) | 0.8167 (±0.0619) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Hammoud, R. A Novel Domain Transfer-Based Approach for Unsupervised Thermal Image Super-Resolution. Sensors 2022, 22, 2254. https://doi.org/10.3390/s22062254
Rivadeneira RE, Sappa AD, Vintimilla BX, Hammoud R. A Novel Domain Transfer-Based Approach for Unsupervised Thermal Image Super-Resolution. Sensors. 2022; 22(6):2254. https://doi.org/10.3390/s22062254
Chicago/Turabian StyleRivadeneira, Rafael E., Angel D. Sappa, Boris X. Vintimilla, and Riad Hammoud. 2022. "A Novel Domain Transfer-Based Approach for Unsupervised Thermal Image Super-Resolution" Sensors 22, no. 6: 2254. https://doi.org/10.3390/s22062254
APA StyleRivadeneira, R. E., Sappa, A. D., Vintimilla, B. X., & Hammoud, R. (2022). A Novel Domain Transfer-Based Approach for Unsupervised Thermal Image Super-Resolution. Sensors, 22(6), 2254. https://doi.org/10.3390/s22062254