
Transmission Line Vibration Damper Detection Using Deep Neural Networks Based on UAV Remote Sensing Image

Abstract
:1. Introduction
- A proposed vibration damper detection model called DamperYOLO based on the YOLOv4 framework, which is more robust than traditional methods and can achieve a good balance between speed and accuracy, and a vibration damper detection dataset called DamperDetSet based on UAVs aerial images.
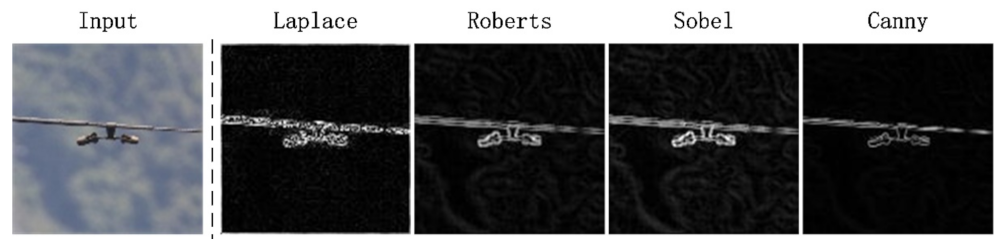
- To enhance images, Gaussian filtering is used to smooth the overexposed points in the aerial image and the Canny algorithm is used to extract the contour information in the image.
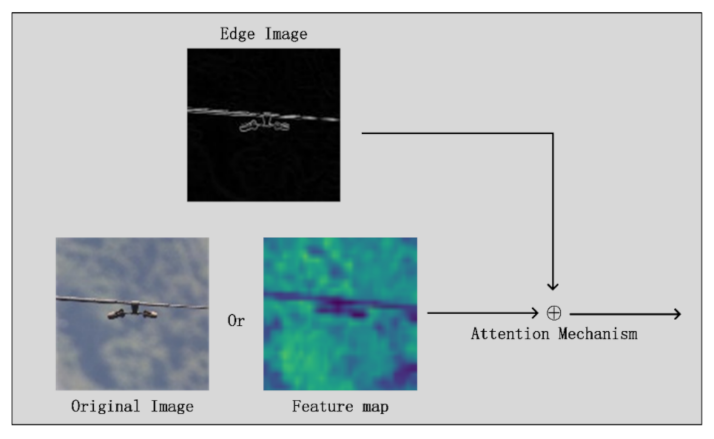
- Introduction of an attention-based structure in the backbone of DamperYOLO. This module can introduce the edge information extracted by Canny into the forward propagation process of the model and provide semantic guidance for the feature extraction of the network.
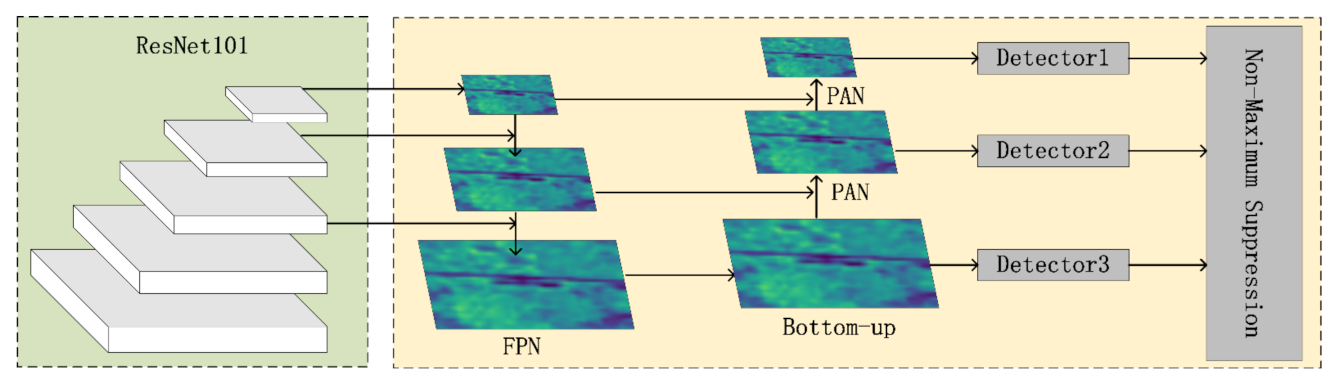
- Addressing the problem that the vibration damper is small and difficult to detect in the UAVs aerial image, we used a feature fusion network based on FPN after the backbone. While outputting feature maps of different resolutions, the semantics and underlying feature information of each layer are maintained, which provides a high-quality data basis for the identification of vibration dampers.
2. Related Work
2.1. Traditional Method
2.2. Deep Neural Networks
2.3. Auxiliary Equipment
2.4. Researches Summary
- Traditional methods based on image processing technology. The detection accuracy is mostly dependent on the quality of the image. If the background in the image is too complex, this leads to the problem that the used feature operator does not cover all situations, which inevitably leads to a decrease in the detection accuracy. The advantage of the traditional method is that it consumes less resources and the calculation speed is fast. Therefore, at present, this type of method is still the most important when the scene is relatively simple, background interference is low, and the real-time requirement is high.
- The method based on deep neural network is the hottest research direction in the field of vibration damper detection. By relying on powerful computing equipment and a large amount of training data, an end-to-end network model can be obtained; on this basis, it is very easy to carry out detection tasks. However, there is currently no public dataset for the vibration damper of overhead transmission lines, and the detection effect of the model is often limited by the lack of computing power of edge devices.
- There is some research work based on auxiliary equipment. Such research uses the characteristics of ultrasonic or infrared imaging equipment to perform the task of vibration damper breakage detection. However, these devices are often inconvenient for use along complex overhead lines, and the maintenance and use costs of the devices are much higher than those of drones.
3. Basic Knowledge of YOLO
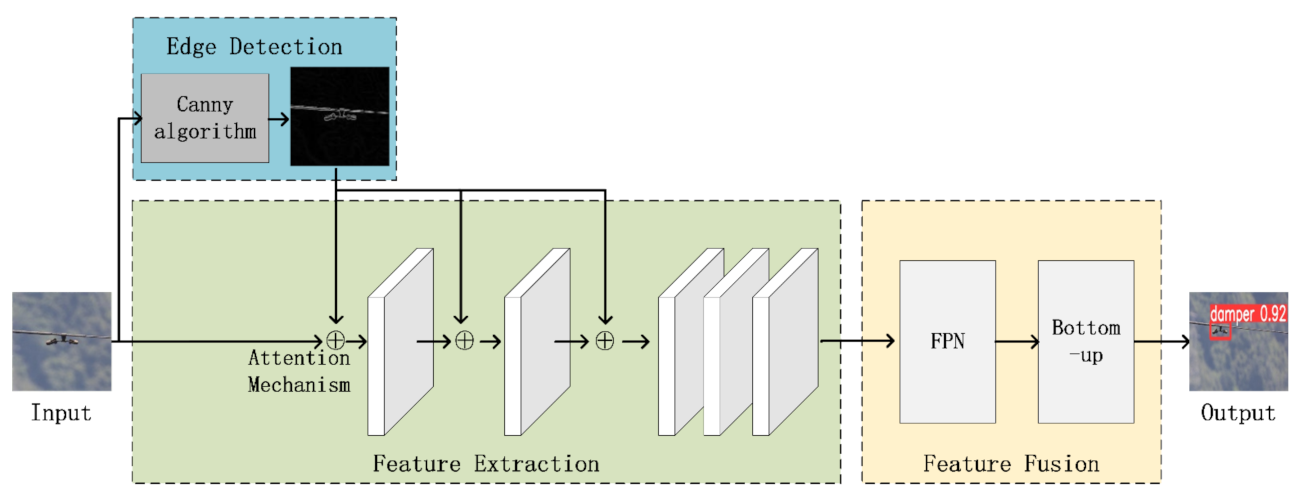
4. DamperYOLO
4.1. Edge Extraction
4.2. Attention Mechanism
4.3. Feature Fusion Network
| Algorithm 1: The Training Process of DamperYOLO. |
| Input: Original damper image set that each image contains dampers. |
| Output: DamperYOLO after training. |
| 1: Initialize DamperYOLO with random weights; |
| 2: repeat |
| 3: for i in 1~epochs do 4: for j in 1~N do 5: Image augment for ; |
| 6: Extract feature map using ResNet101; 7: Output detection results using YOLO; |
| 8: Calculate the penalty value via Formula (2), (5) and (6); |
| 9: Minimize Formula (1) to update the parameters of DamperYOLO; 10: end for |
| 11: end for |
| 12: until DamperYOLO completes convergence |
| 13: return |
5. Experiments and Analysis
5.1. Experiment Description
5.1.1. Dataset
5.1.2. Experiment Configuration
5.2. The Baselines
5.3. Qualitative Evaluation
5.4. Quantitative Evaluation
5.5. Sensitivity Analysis
5.5.1. Backbone
5.5.2. Edge Extraction
5.5.3. Attention Mechanism
5.5.4. Number of Epochs
5.5.5. Minimum Training Data Experiment
5.6. Ablation Analysis
5.7. Computational Complexity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bao, W.; Ren, Y.; Wang, N.; Hu, G.; Yang, X. Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO. Remote Sens. 2021, 13, 4134. [Google Scholar] [CrossRef]
- Wu, H.; Xi, Y.; Fang, W.; Sun, X.; Jiang, L. Damper detection in helicopter inspection of power transmission line. In Proceedings of the 2014 4th International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 18–20 September 2014; pp. 628–632. [Google Scholar] [CrossRef]
- Ma, Y.; Li, Q.; Chu, L.; Zhou, Y.; Xu, C. Real-Time Detection and Spatial Localization of Insulators for UAV Inspection Based on Binocular Stereo Vision. Remote Sens. 2021, 13, 230. [Google Scholar] [CrossRef]
- Hinas, A.; Roberts, J.M.; Gonzalez, F. Vision-Based Target Finding and Inspection of a Ground Target Using a Multirotor UAV System. Sensors 2017, 17, 2929. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Han, W.; Chen, H.; Li, G.; Tang, J. Recognizing Zucchinis Intercropped with Sunflowers in UAV Visible Images Using an Improved Method Based on OCRNet. Remote Sens. 2021, 13, 2706. [Google Scholar] [CrossRef]
- Popescu, D.; Stoican, F.; Stamatescu, G.; Chenaru, O.; Ichim, L. A Survey of Collaborative UAV–WSN Systems for Efficient Monitoring. Sensors 2019, 19, 4690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Yuan, X.; Li, W.; Chen, S. Automatic Power Line Inspection Using UAV Images. Remote Sens. 2017, 9, 824. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Li, J.X.; Xu, W.; Liu, M.Y. A method on recognizing transmission line structure based on multi-level perception. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 512–522. [Google Scholar]
- Huang, X.; Zhang, X.; Zhang, Y.; Zhao, L. A method of identifying rust status of dampers based on image processing. IEEE Trans. Instrum. Meas. 2020, 69, 5407–5417. [Google Scholar] [CrossRef]
- Jin, L.J.; Yan, S.J.; Liu, Y. Vibration damper recognition based on Haar-Like features and cascade adaboost classifier. J. Syst. Simul. 2012, 24, 60–63. [Google Scholar]
- Zhang, K.; Hou, Q.; Huang, W. Defect Detection of Anti-vibration Hammer Based on Improved Faster R-CNN. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 889–893. [Google Scholar] [CrossRef]
- Bao, W.; Ren, Y.; Liang, D.; Yang, X.; Xu, Q. Defect Detection Algorithm of Anti-vibration Hammer Based on Improved Cascade R-CNN. In Proceedings of the 2020 International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Sanya, China, 4–6 December 2020; pp. 294–297. [Google Scholar] [CrossRef]
- Hickey, C.; Young, P.; Mayomi, T.; Noctor, J. Fault Investigation and Analysis of an Overhead Transmission Line Vibration Damper. In Proceedings of the 2021 56th International Universities Power Engineering Conference (UPEC), Middlesbrough, UK, 31 August–3 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, H.; Ling, L. Research on a novel maintenance robot for power transmission lines. In Proceedings of the 2016 4th International Conference on Applied Robotics for the Power Industry (CARPI), Jinan, China, 11–13 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Song, W.; Zuo, D.; Deng, B.; Zhang, H.; Xue, K.; Hu, H. Corrosion defect detection of earthquake hammer for high voltage transmission line. Chin. J. Sci. Instrum. 2016, 37, 113–117. [Google Scholar]
- Yang, H.; Guo, T.; Shen, P.; Chen, F.; Wang, W.; Liu, X. Anti-vibration hammer detection in UAV image. In Proceedings of the 2017 2nd International Conference on Power and Renewable Energy (ICPRE), Chengdu, China, 20–23 September 2017; pp. 204–207. [Google Scholar] [CrossRef]
- Liu, Y.; Wen, S.; Chen, Z.; Zhang, D. Research of the Anti-vibration Hammer Resetting Robot Based on Machine Vision. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 3708–3712. [Google Scholar] [CrossRef]
- Chen, X.; Wu, Y.; Zhao, L. Identification of OPGW vibration damper based on random Hough transformation. Heilongjiang Dianli Jishu Heilongjiang Electric. Power 2010, 32, 1–2. [Google Scholar]
- Miao, S.; Sun, W.; Zhang, H. Intelligent visual method based on wavelet moments for obstacle recognition of high voltage transmission line deicer robot. Jiqiren 2010, 32, 425–431. [Google Scholar] [CrossRef]
- Pan, L.; Xiao, X. Image recognition for on-line vibration monitoring system of transmission line. In Proceedings of the 2009 9th International Conference on Electronic Measurement & Instruments, Beijing, China, 16–19 August 2009; pp. 3–1081. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, L. Vibration Damper Recognition of Transmission System Based on Unmanned Aerial Vehicles. In Proceedings of the 2011 Asia-Pacific Power and Energy Engineering Conference, Wuhan, China, 25–28 March 2011; pp. 1–3. [Google Scholar] [CrossRef]
- Guo, J.; Xie, J.; Yuan, J.; Jiang, Y.; Lu, S. Fault Identification of Transmission Line Shockproof Hammer Based on Improved YOLO V4. In Proceedings of the 2021 International Conference on Intelligent Computing, Automation and Applications (ICAA), Nanjing, China, 25–27 June 2021; pp. 826–833. [Google Scholar] [CrossRef]
- Wang, W.; Wang, Z.; Liu, B.; Yang, Y.; Sun, X. Typical Defect Detection Technology of Transmission Line Based on Deep Learning. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 1185–1189. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, W.; Yang, J. An Improved Quantization Algorithm for Electric Power Inspection. In Proceedings of the 2021 9th International Electrical Engineering Congress (iEECON), Pattaya, Thailand, 10–12 March 2021; pp. 397–400. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z. Improved YOLOv3 Network for Insulator Detection in Aerial Images with Diverse Background Interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-Time Detection of Outdoor High Voltage Insulators Using UAV Imaging. IEEE Trans. Power Deliv. 2020, 35, 1599–1601. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhen, Z.; Zhang, L.; Qi, Y.; Kong, Y.; Zhang, K. Insulator Detection Method in Inspection Image Based on Improved Faster R-CNN. Energies 2019, 12, 1204. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Li, Y.; Li, C. A Visual Detection Method for Foreign Objects in Power Lines Based on Mask R-CNN. Int. J. Ambient. Comput. Intell. IJACI 2020, 11, 34–47. [Google Scholar] [CrossRef]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep Architecture for High-Speed Railway Insulator Surface Defect Detection: Denoising Autoencoder with Multitask Learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Cheng, L.; Liao, R.; Yang, L.; Zhang, F. An Optimized Infrared Detection Strategy for Defective Composite Insulators According to the Law of Heat Flux Propagation Considering the Environmental Factors. IEEE Access 2018, 6, 38137–38146. [Google Scholar] [CrossRef]
- Yu, C.; Pan, W.; Lei, X.; Yu, G.; Qin, W.; Zhu, K.; Zheng, H. Simulation of electric field and potential transfer arc during the on-line process of the live working anti-vibration hammer robot. In Proceedings of the 2021 International Conference on Electrical Materials and Power Equipment (ICEMPE), Chongqing, China, 11–15 April 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Diana, G.; Falco, M.; Cigada, A.; Manenti, A. On the measurement of overhead transmission lines conductor self-damping. IEEE Trans. Power Deliv. 2000, 15, 285–292. [Google Scholar] [CrossRef]
- Si, J.; Rui, X.; Liu, B.; Zhou, L.; Liu, S. Study on a New Combined Anti-Galloping Device for UHV Overhead Transmission Lines. IEEE Trans. Power Deliv. 2019, 34, 2070–2078. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 10 January 2022).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934v1 (accessed on 20 January 2022).
- Wang, C.Y.; Liao, H.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- Bahdanau, D.B.; Kyunghyun, C.; Yoshua, B. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. Available online: https://arxiv.org/abs/1409.0473 (accessed on 10 January 2022).
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef] [Green Version]
- Tao, C.; Ma, K.K.; Chen, L.H. Tri-state median filter for image denoising. IEEE Trans. Image Process. 1999, 8, 1834–1838. [Google Scholar]
- Zhang, X.M.; Xu, B.S.; Dong, S.Y.; Gan, X.M. Adaptive median-weighted mean hybrid filter. Opt. Tech. 2004, 6, 652–659. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 20 January 2022).
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. Available online: https://arxiv.org/abs/1904.07850v2 (accessed on 20 January 2022).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2980–2988. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision-ECCV 2014, Lecture Notes in Computer Science, Zurich, Switzerland, 6–7, 12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8693. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Kernel Size |
|---|---|---|
| conv1 | 304 × 304 | 7 × 7, 64 |
| conv2_x | 152 × 152 | × 3 |
| conv3_x | 76 × 76 | × 4 |
| conv4_x | 38 × 38 | × 23 |
| conv5_x | 19 × 19 | × 3 |
| Model | DamperDetSet | FPS | ||
|---|---|---|---|---|
| AP50 | AP70 | AP90 | ||
| YOLOv4 | 88.23 | 80.67 | 73.26 | 71 |
| SSD | 85.71 | 78.34 | 71.38 | 70 |
| RetinaNet | 87.18 | 79.62 | 72.70 | 73 |
| CenterNet | 84.38 | 77.25 | 69.42 | 118 |
| Cascade R-CNN | 92.26 | 89.52 | 81.43 | 31 |
| DamperYOLO | 92.62 | 89.67 | 81.24 | 74 |
| Backbone | DamperDetSet | FPS | ||
|---|---|---|---|---|
| AP50 | AP70 | AP90 | ||
| CSPDarknet53 | 88.20 | 80.58 | 73.28 | 72 |
| VGG16 | 82.18 | 76.54 | 67.91 | 71 |
| ResNet50 | 84.12 | 77.62 | 70.42 | 78 |
| ResNet101(ours) | 92.62 | 89.67 | 81.24 | 74 |
| ResNet152 | 93.25 | 89.97 | 82.16 | 68 |
| Preprocessing Method | DamperDetSet | FPS | ||
|---|---|---|---|---|
| AP50 | AP70 | AP90 | ||
| No preprocessing | 87.18 | 79.52 | 71.83 | 79 |
| Image denoising | 88.92 | 81.93 | 73.65 | 78 |
| Edge extraction | 91.25 | 86.74 | 79.17 | 77 |
| Image denoising + Edge extraction | 92.62 | 89.67 | 81.24 | 74 |
| Introduced Layer | DamperDetSet | FPS | ||
|---|---|---|---|---|
| AP50 | AP70 | AP90 | ||
| None | 86.28 | 77.36 | 70.03 | 81 |
| C1 | 87.83 | 80.23 | 71.37 | 80 |
| C1, C2 | 91.38 | 84.61 | 77.42 | 77 |
| C1, C2, C3 | 92.62 | 89.67 | 81.24 | 74 |
| C1, C2, C3, C4 | 93.14 | 90.15 | 81.92 | 74 |
| C1, C2, C3, C4, C5 | 89.27 | 83.32 | 73.52 | 73 |
| Number of Epochs | DamperDetSet | FPS | ||
|---|---|---|---|---|
| AP50 | AP70 | AP90 | ||
| 50 | 71.63 | 60.62 | 41.37 | 79 |
| 100 | 80.51 | 72.27 | 65.23 | 77 |
| 150 | 84.15 | 80.16 | 74.38 | 75 |
| 200 | 92.62 | 89.67 | 81.24 | 74 |
| 250 | 93.31 | 88.65 | 80.47 | 74 |
| The Amount of Training Set | DamperDetSet | FPS | ||
|---|---|---|---|---|
| AP50 | AP70 | AP90 | ||
| 2500 (100%) | 92.62 | 89.67 | 81.24 | 74 |
| 2250 (90%) | 89.51 | 86.28 | 78.83 | 75 |
| 2000 (80%) | 85.39 | 81.75 | 75.41 | 74 |
| 1750 (70%) | 82.41 | 77.40 | 71.68 | 74 |
| 1500 (60%) | 73.97 | 69.62 | 64.01 | 72 |
| Model | Architecture | AP50 | AP70 | AP90 |
|---|---|---|---|---|
| A | YOLOv4 | 86.21 | 78.45 | 70.96 |
| B | A + ResNet101 | 88.57 | 82.36 | 73.72 |
| C | B + Edge Extraction | 90.82 | 84.24 | 76.50 |
| D | C + Attention Mechanism | 92.62 | 89.67 | 81.24 |
| Model | Param. | Training Time (h) |
|---|---|---|
| YOLOv4 | 28 M | 6.38 |
| SSD | 34 M | 7.46 |
| RetinaNet | 32 M | 7.03 |
| CenterNet | 14 M | 4.05 |
| Cascade R-CNN | 184 M | 49.84 |
| DamperYOLO | 30 M | 6.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Li, Y.; Zhao, Z. Transmission Line Vibration Damper Detection Using Deep Neural Networks Based on UAV Remote Sensing Image. Sensors 2022, 22, 1892. https://doi.org/10.3390/s22051892
Chen W, Li Y, Zhao Z. Transmission Line Vibration Damper Detection Using Deep Neural Networks Based on UAV Remote Sensing Image. Sensors. 2022; 22(5):1892. https://doi.org/10.3390/s22051892
Chicago/Turabian StyleChen, Wenxiang, Yingna Li, and Zhengang Zhao. 2022. "Transmission Line Vibration Damper Detection Using Deep Neural Networks Based on UAV Remote Sensing Image" Sensors 22, no. 5: 1892. https://doi.org/10.3390/s22051892
APA StyleChen, W., Li, Y., & Zhao, Z. (2022). Transmission Line Vibration Damper Detection Using Deep Neural Networks Based on UAV Remote Sensing Image. Sensors, 22(5), 1892. https://doi.org/10.3390/s22051892