
Real-Time Stylized Humanoid Behavior Control through Interaction and Synchronization




Abstract
:1. Introduction
2. Related Work
3. Style-Based Teleoperation Framework under Human Behavior Analysis
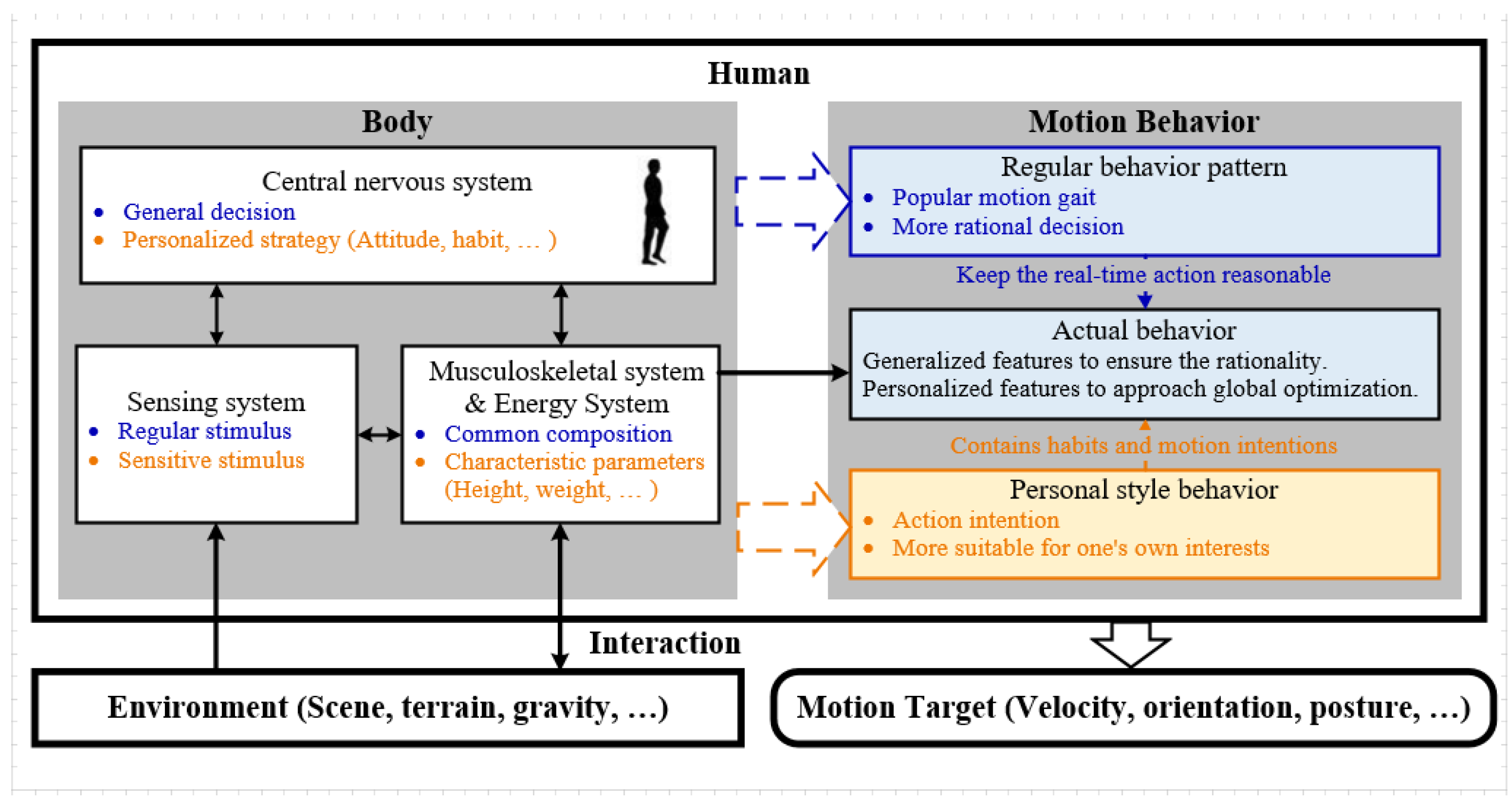
3.1. Human Style Analysis
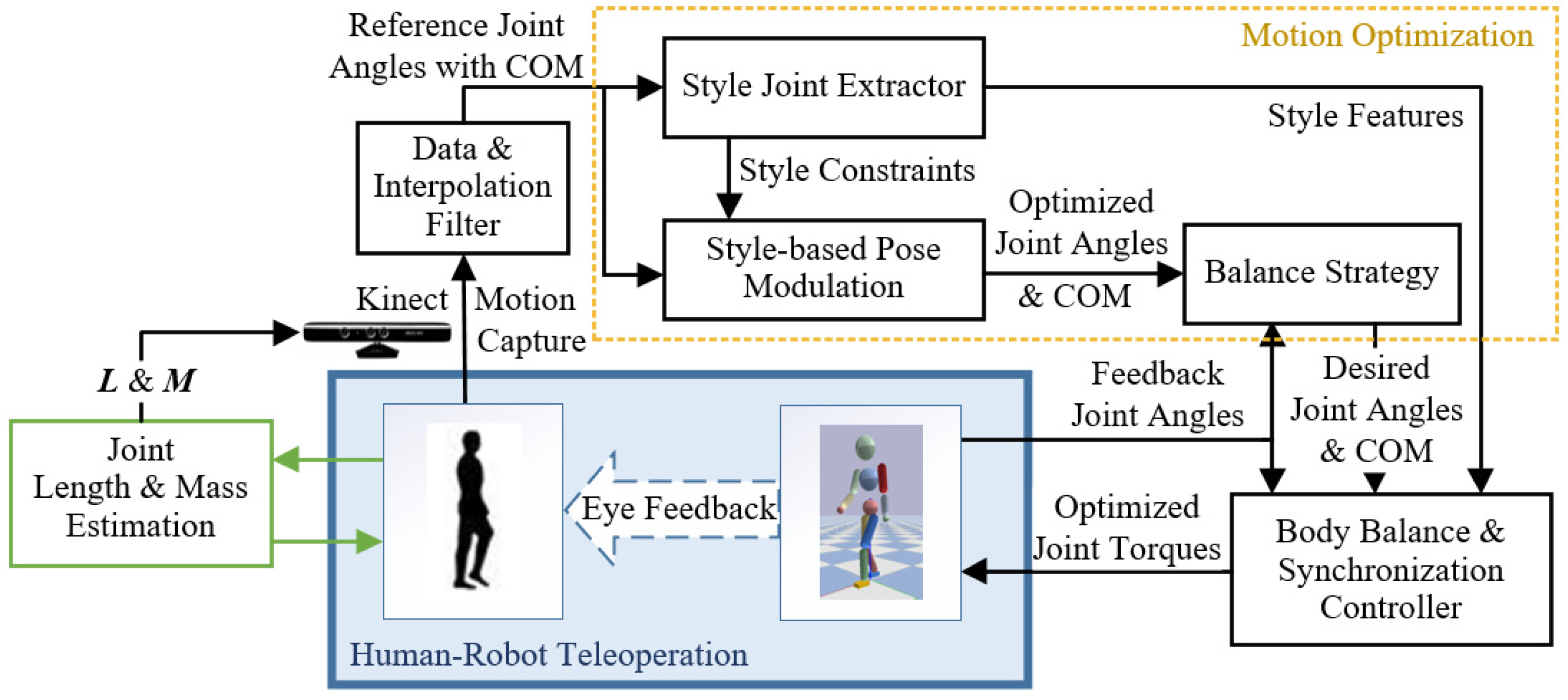
3.2. System Overview
4. Kinect Motion Capture and Data Processing
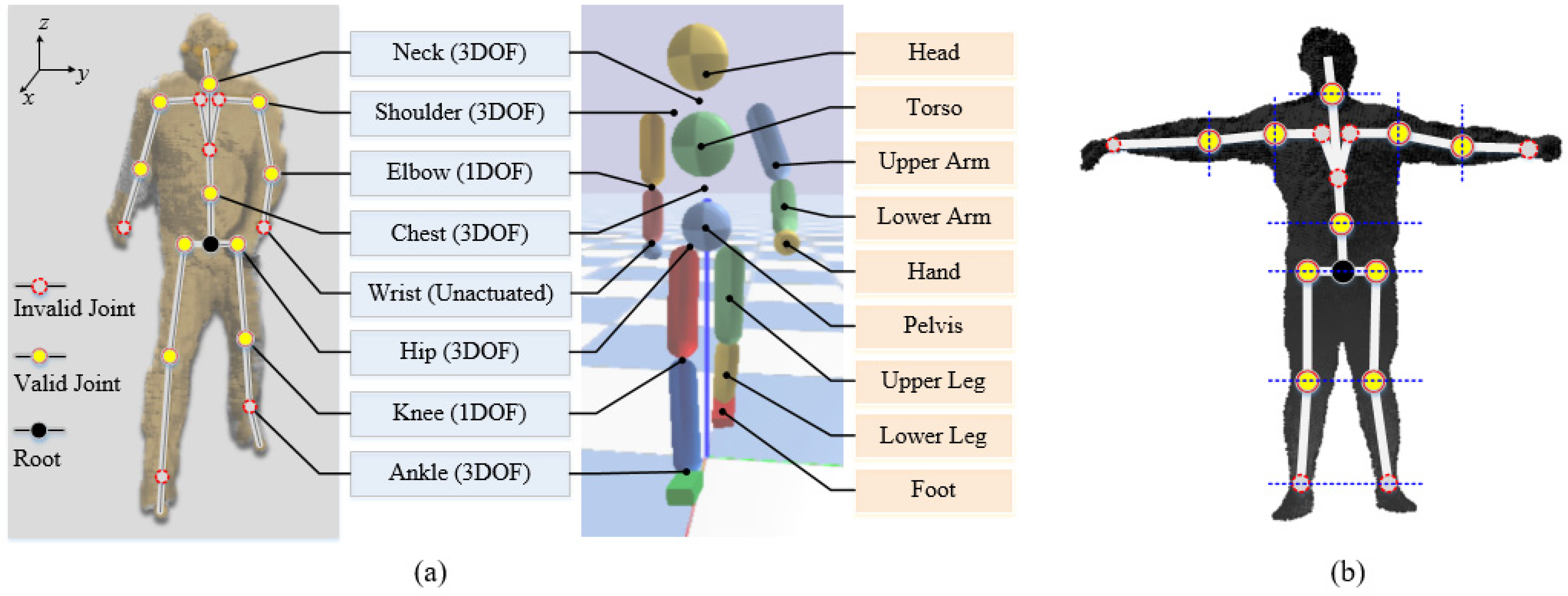
4.1. Joint Map between Kinect Model and Character Model
4.2. 3D Human Body Parameters’ Measurement
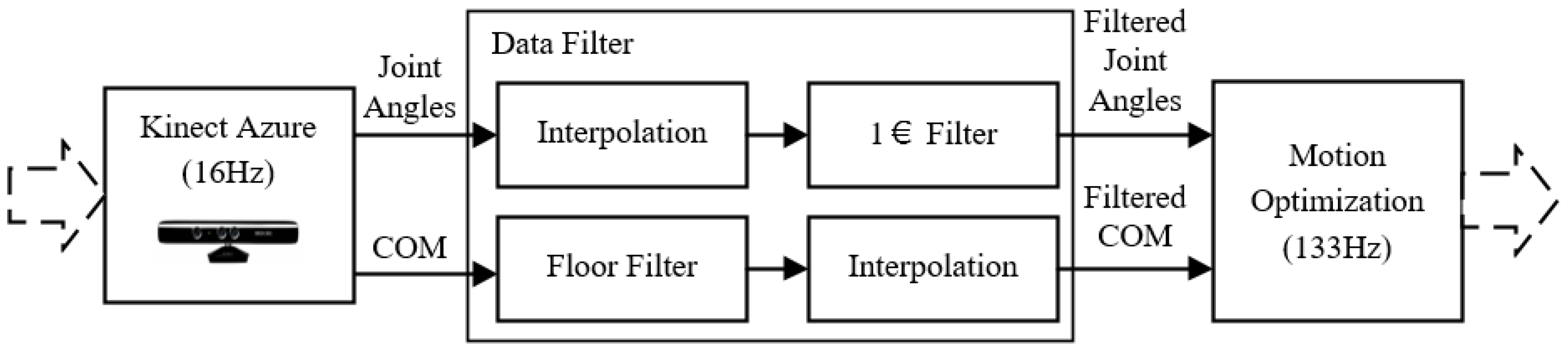
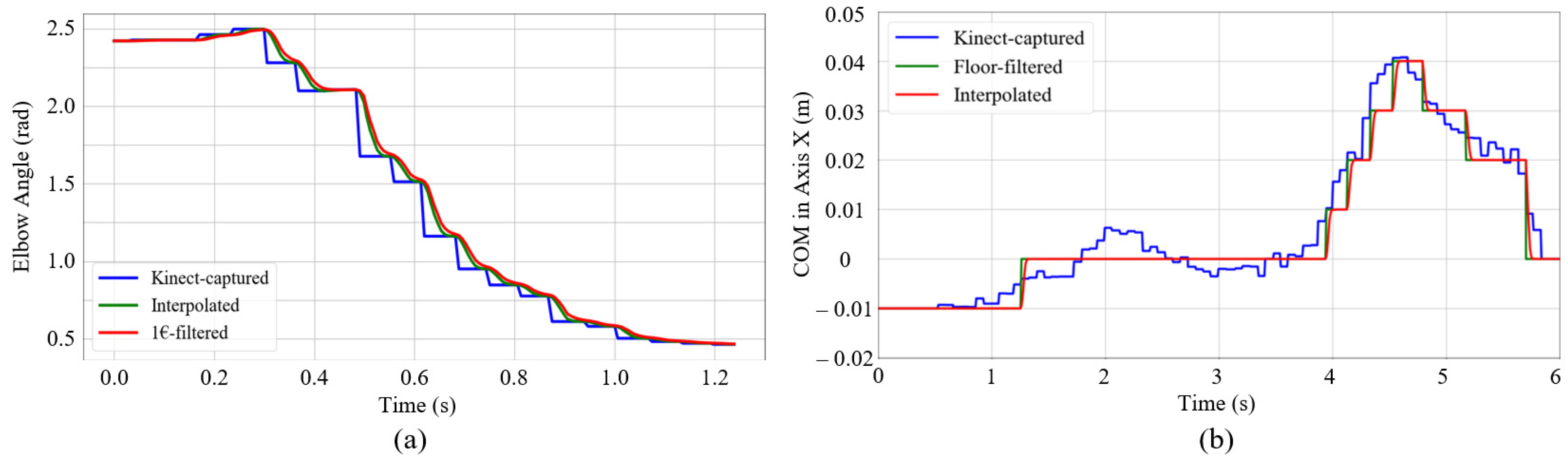
4.3. Data Interpolation and Filter
5. Motion Optimization
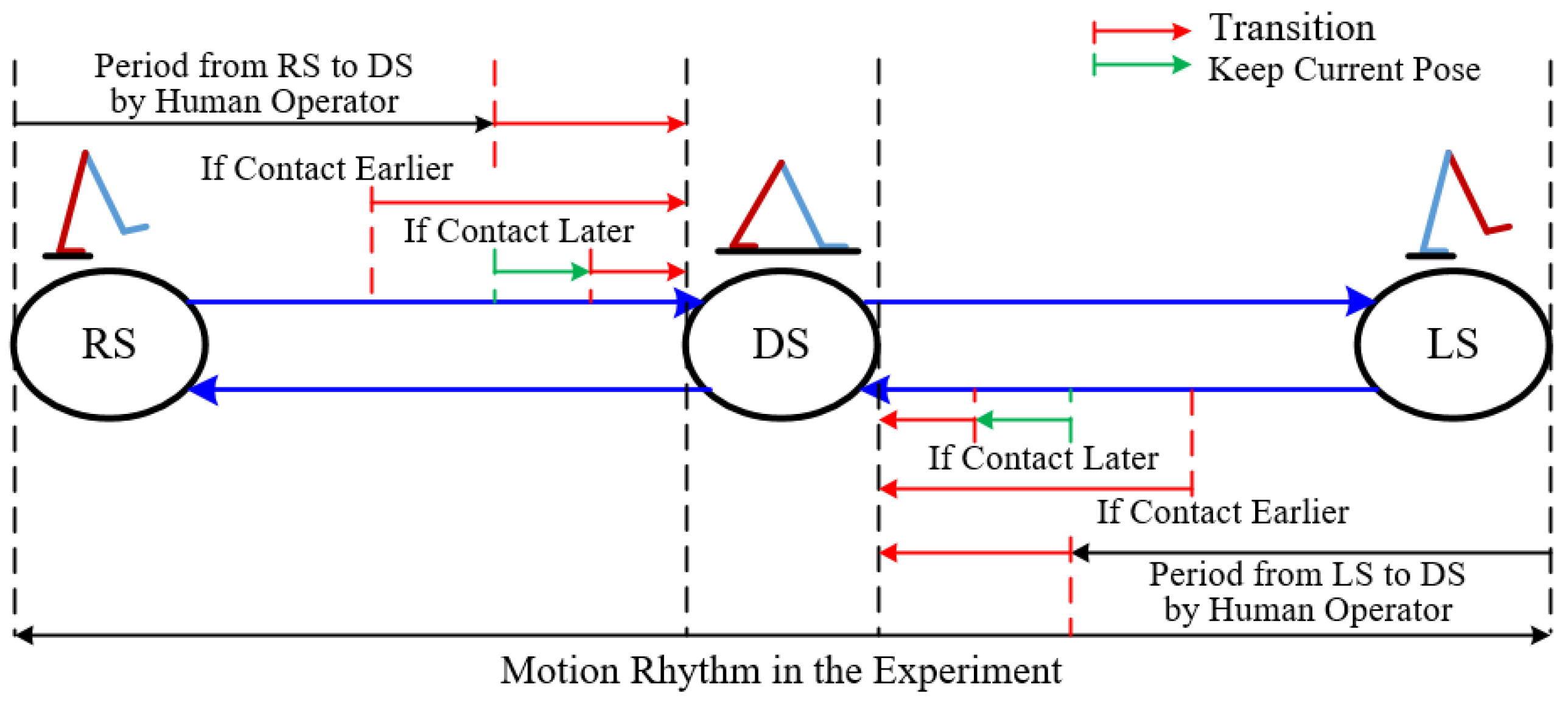
5.1. Motion States and State Transitions
5.2. Style Feature Extractor
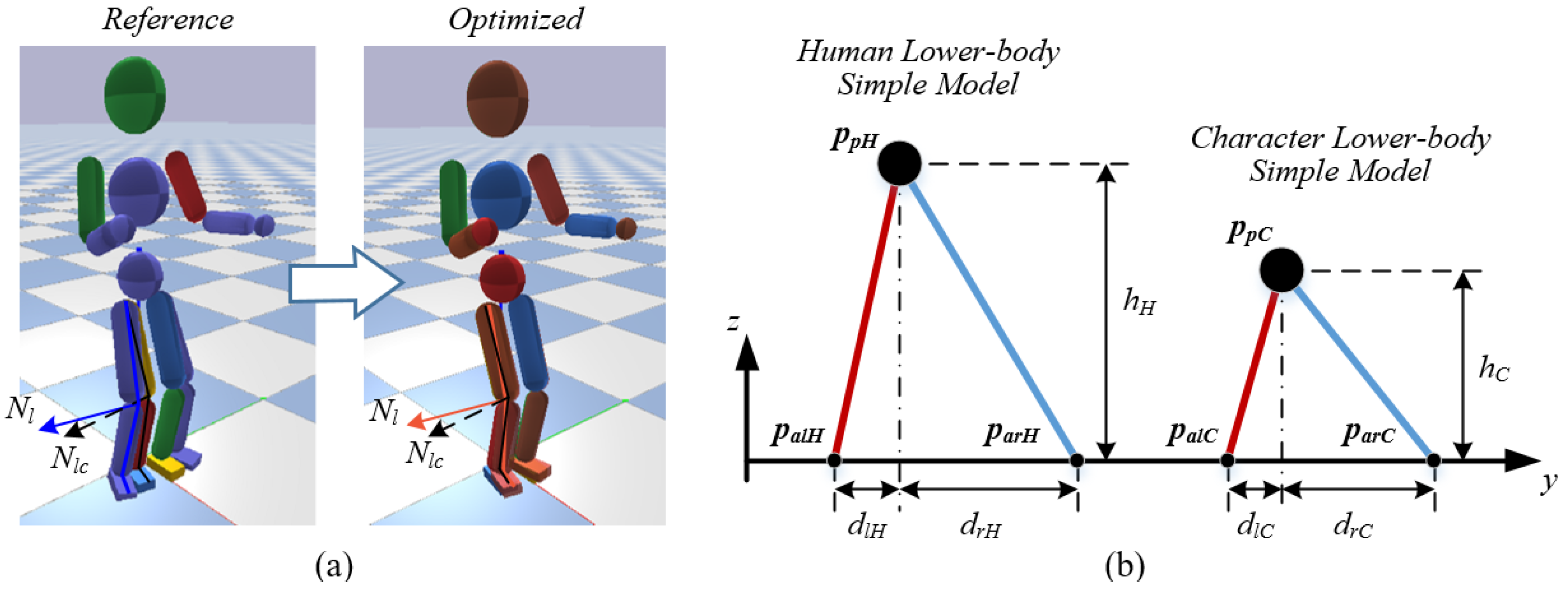
5.3. Style-Based Pose Optimization
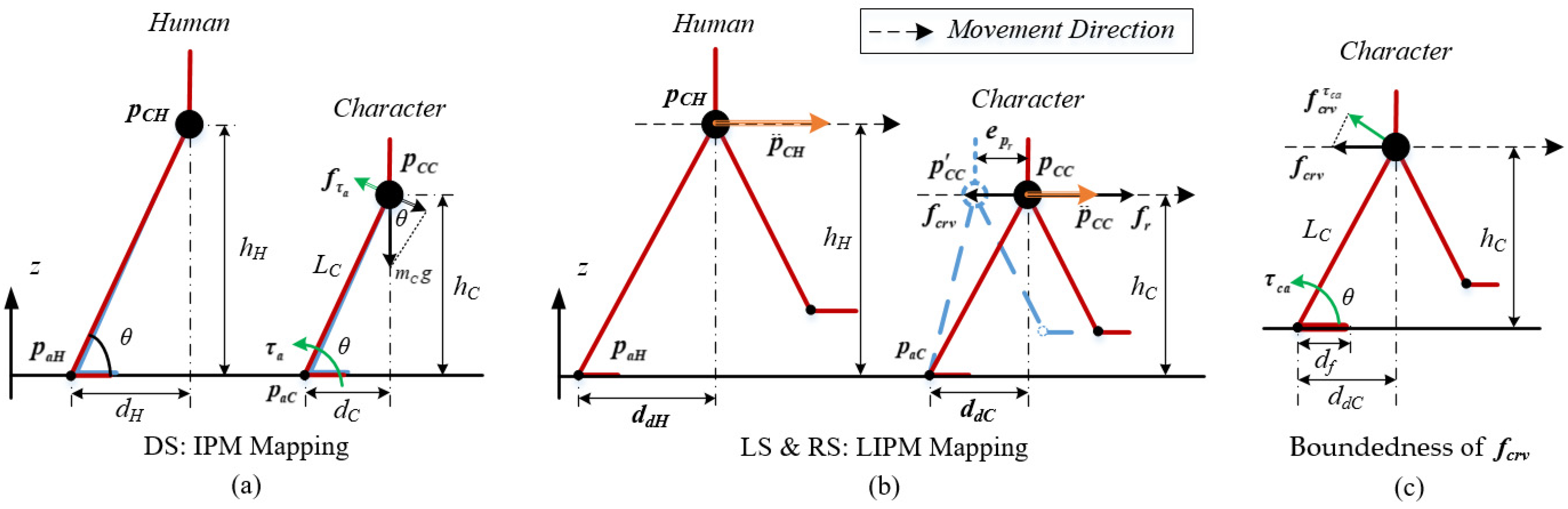
5.4. Balance Strategy
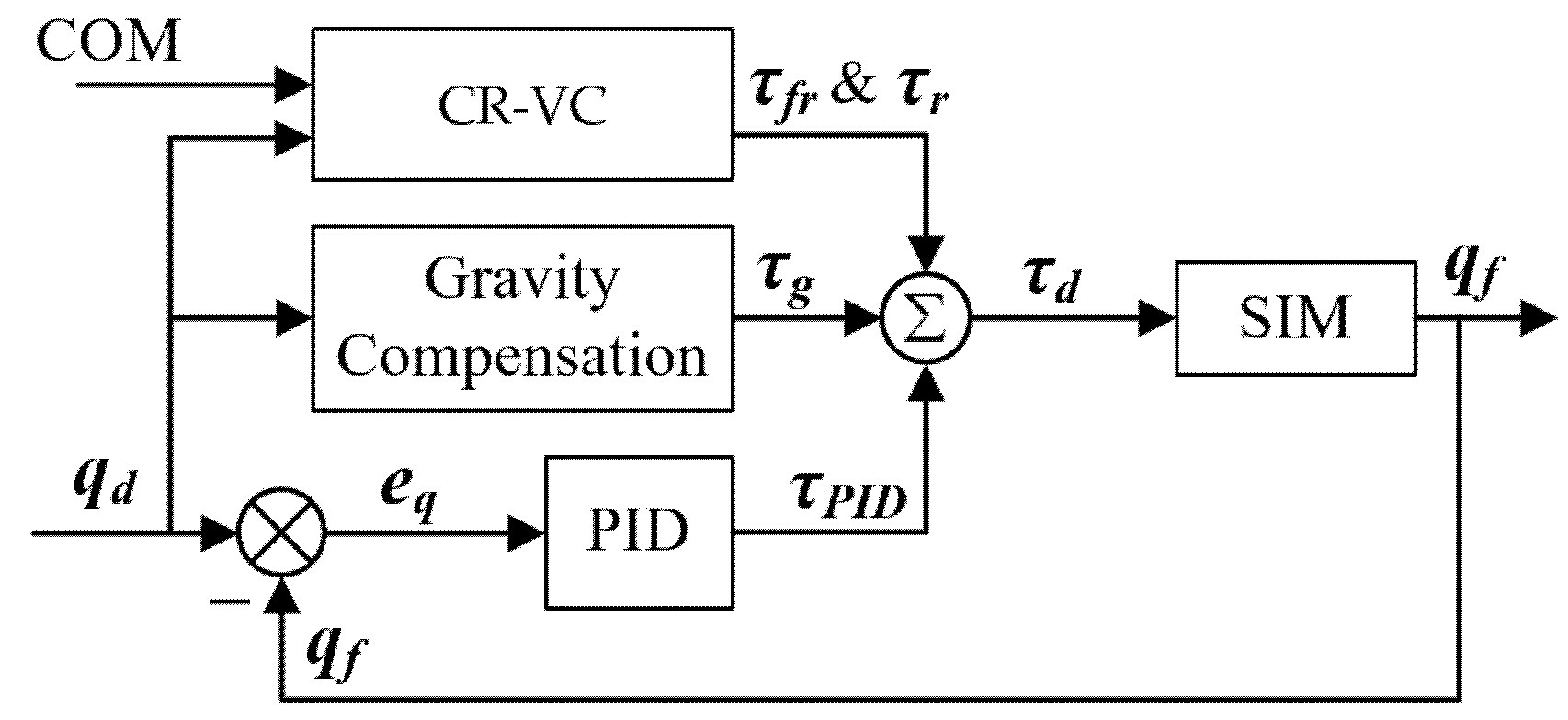
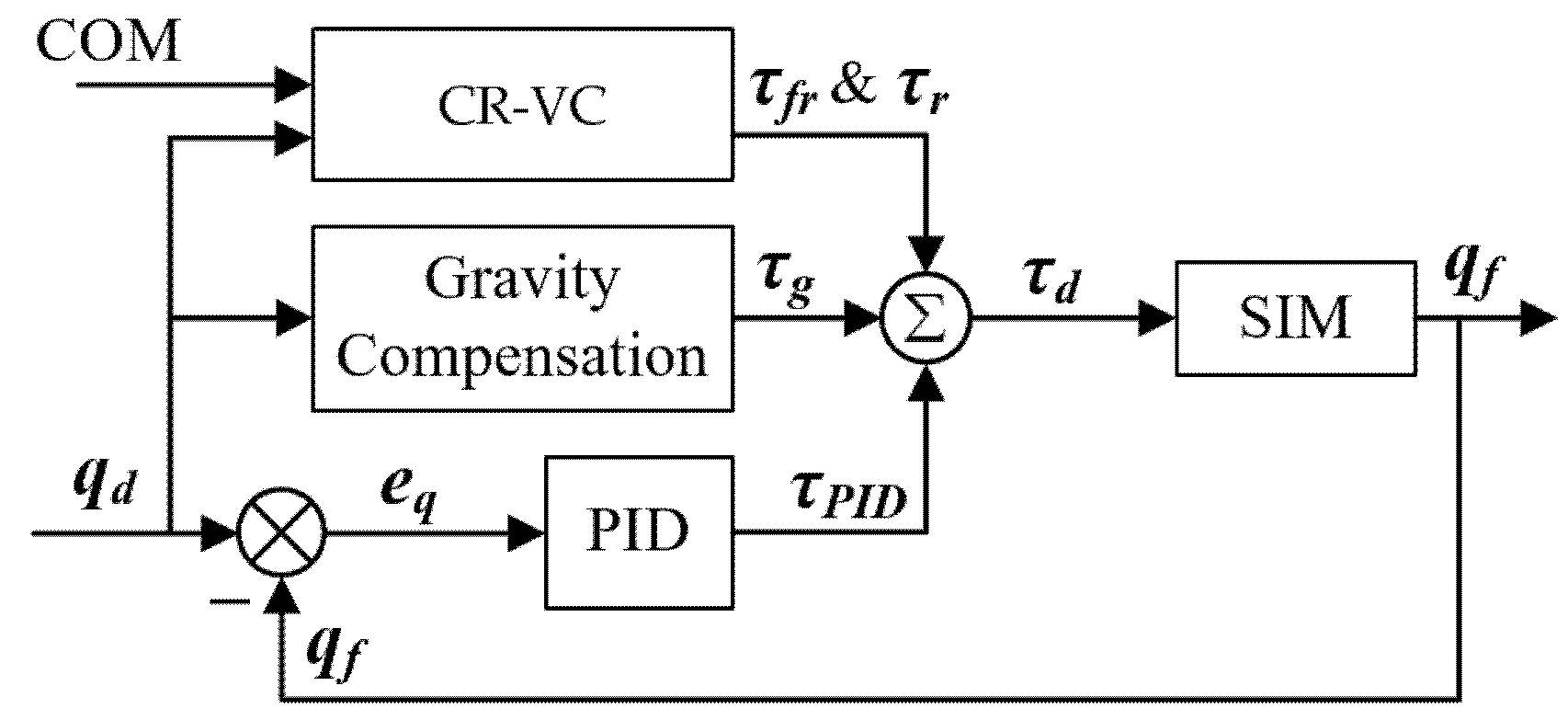
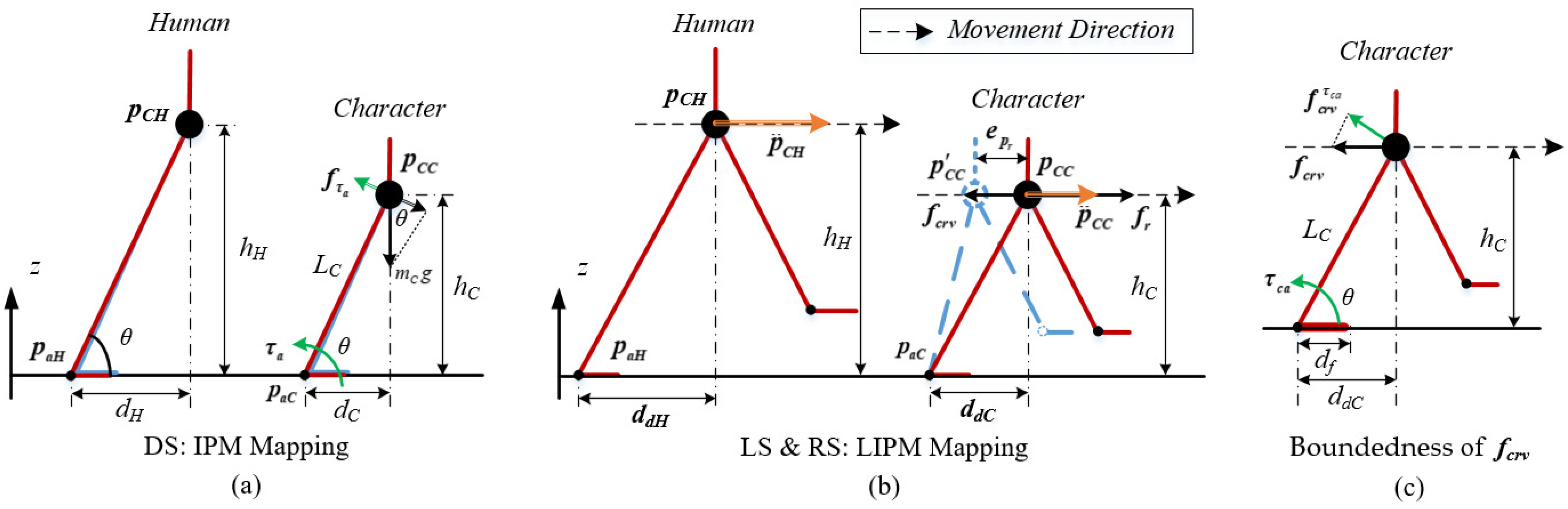
6. Body Balance and Synchronization Controller
6.1. PID Joint Controller with Gravity Compensation
6.2. COM and Root Virtual Controller (CR-VC)
6.3. Model-Based Torque Compensation for the CR-VC
6.4. Movement Boundedness of the CR-VC
7. Experimental Results
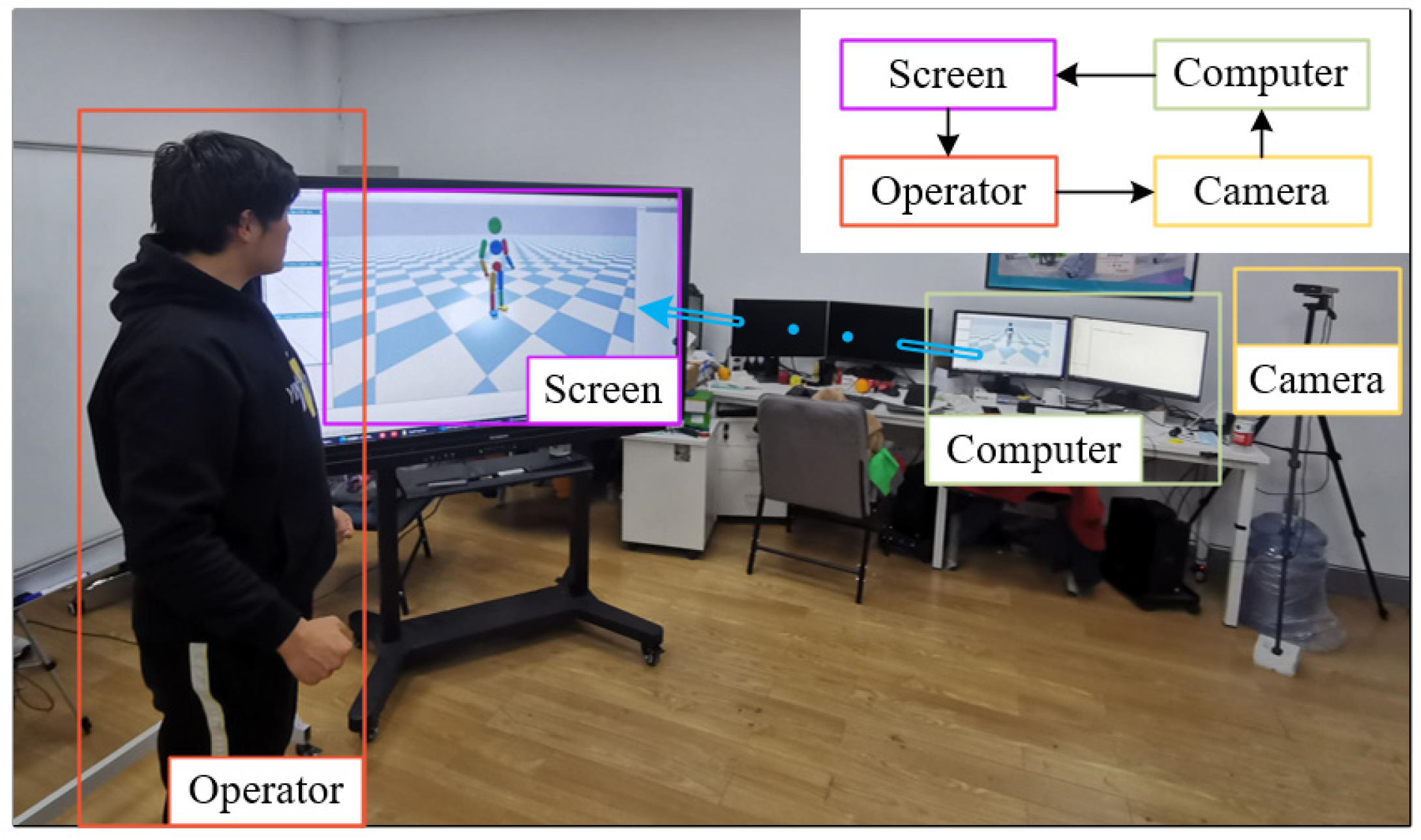
7.1. Experimental Platform
7.2. Parameter Settings
7.3. Remarks for Teleoperators
- The motion data captured by the Kinect camera should be unabridged, so the operator should act more than two meters away from the camera for the whole-body motion capture.
- While walking, the operator’s lower body needs to be kept bent to satisfy the LIPM simplification of the pose optimization and the feasibility of its IK solution.
- When the operator double-stands on the ground, the COM should be landed in the standing area to avoid foot flipping.
- The stepping length of the operator is bounded by Equation (28).
- High dynamic motions, of which models conflict with IPM or LIPM, should be avoided.
7.4. Experiments
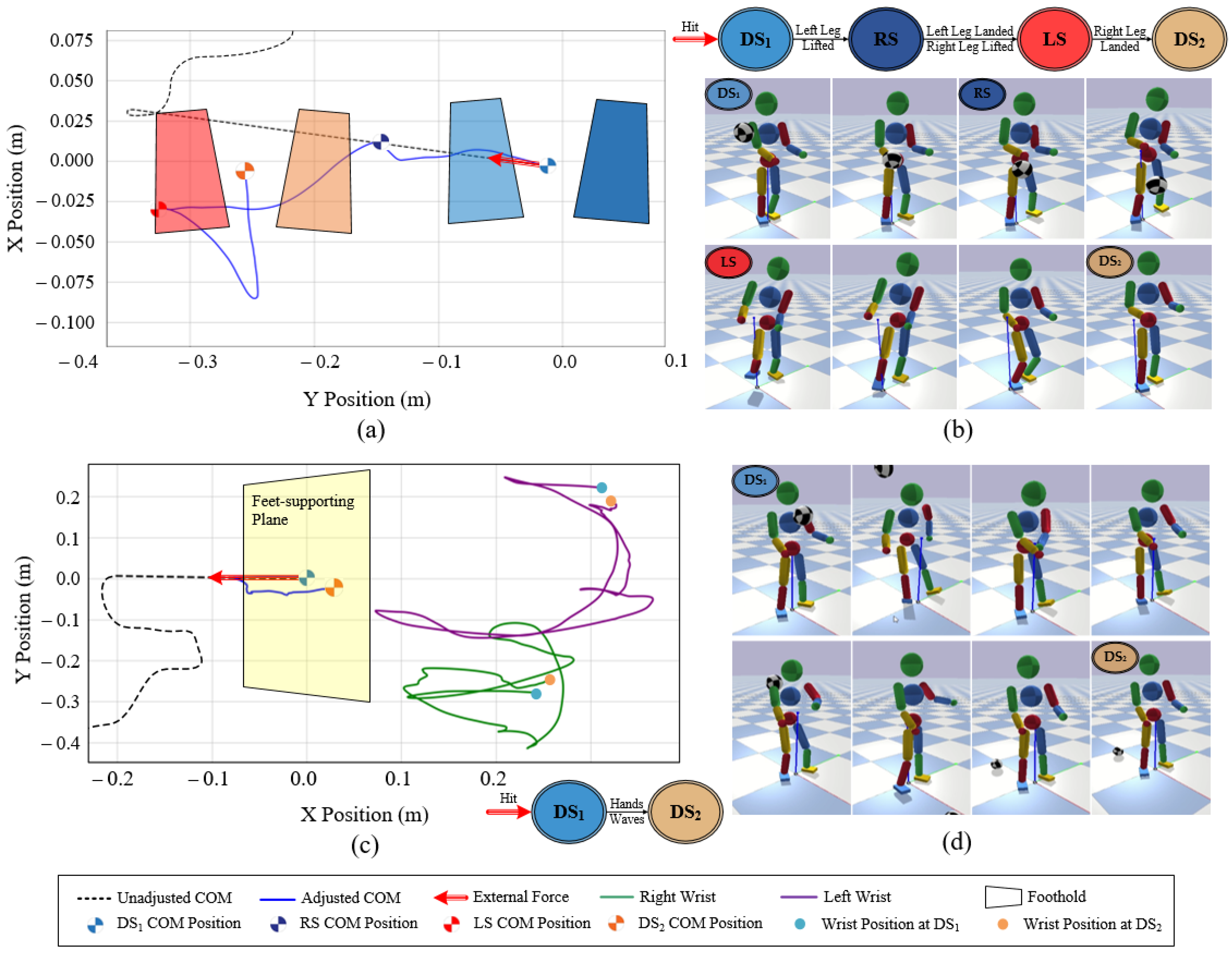
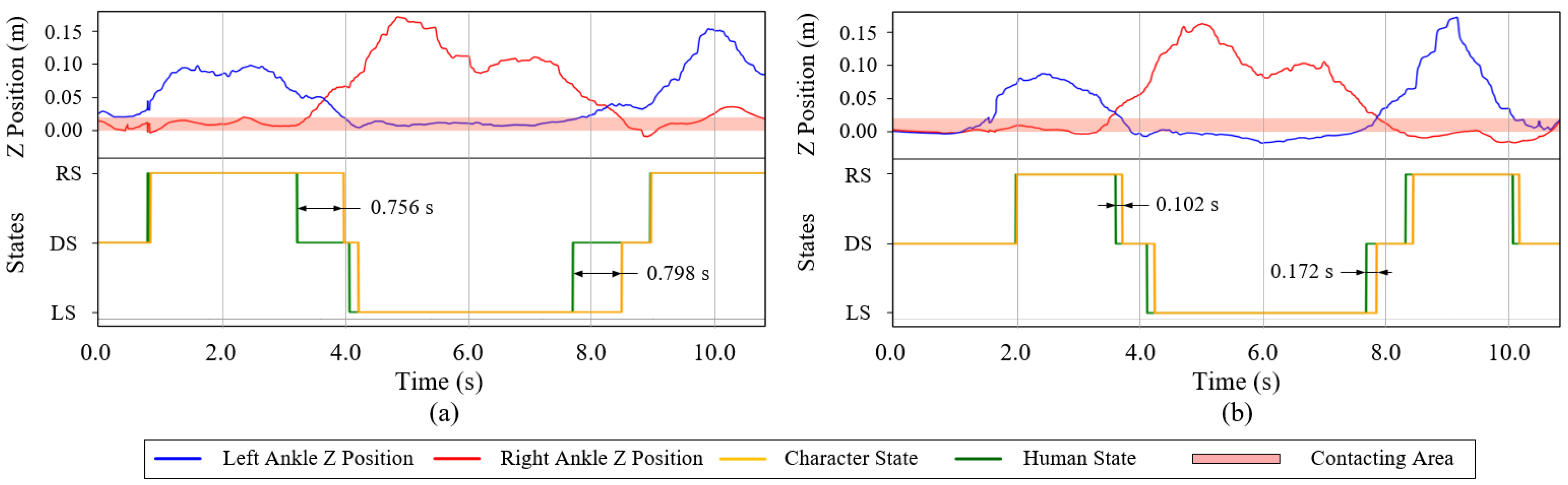
7.4.1. Teleoperating under Human-Character Synchronization
7.4.2. Teleoperating with Different Patterns
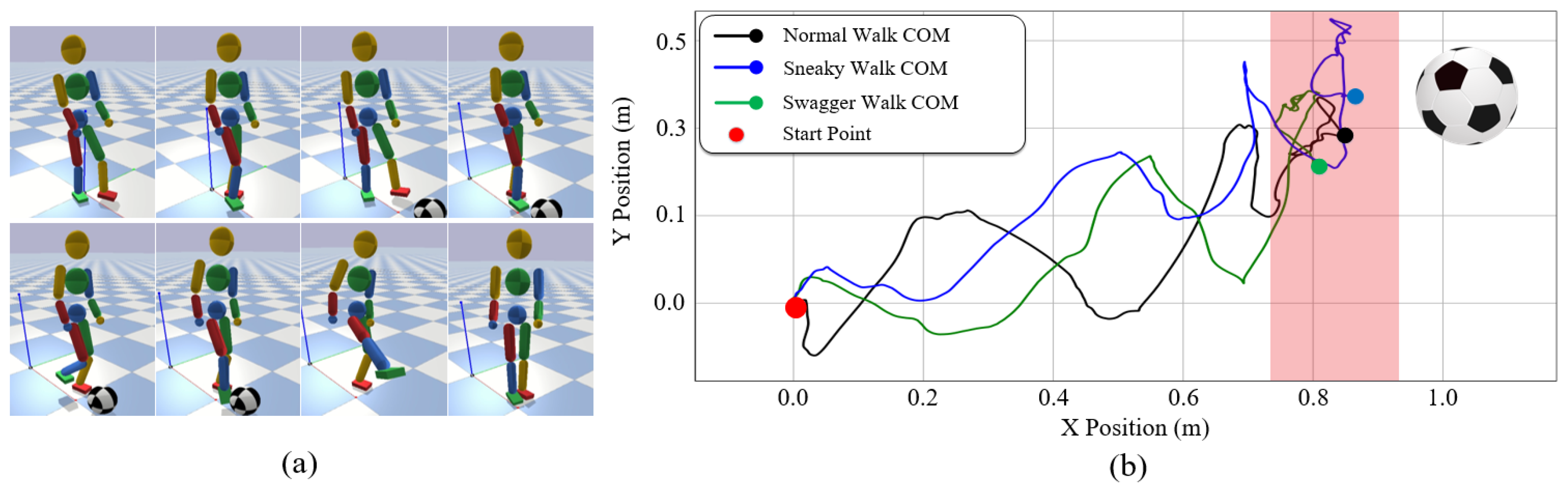
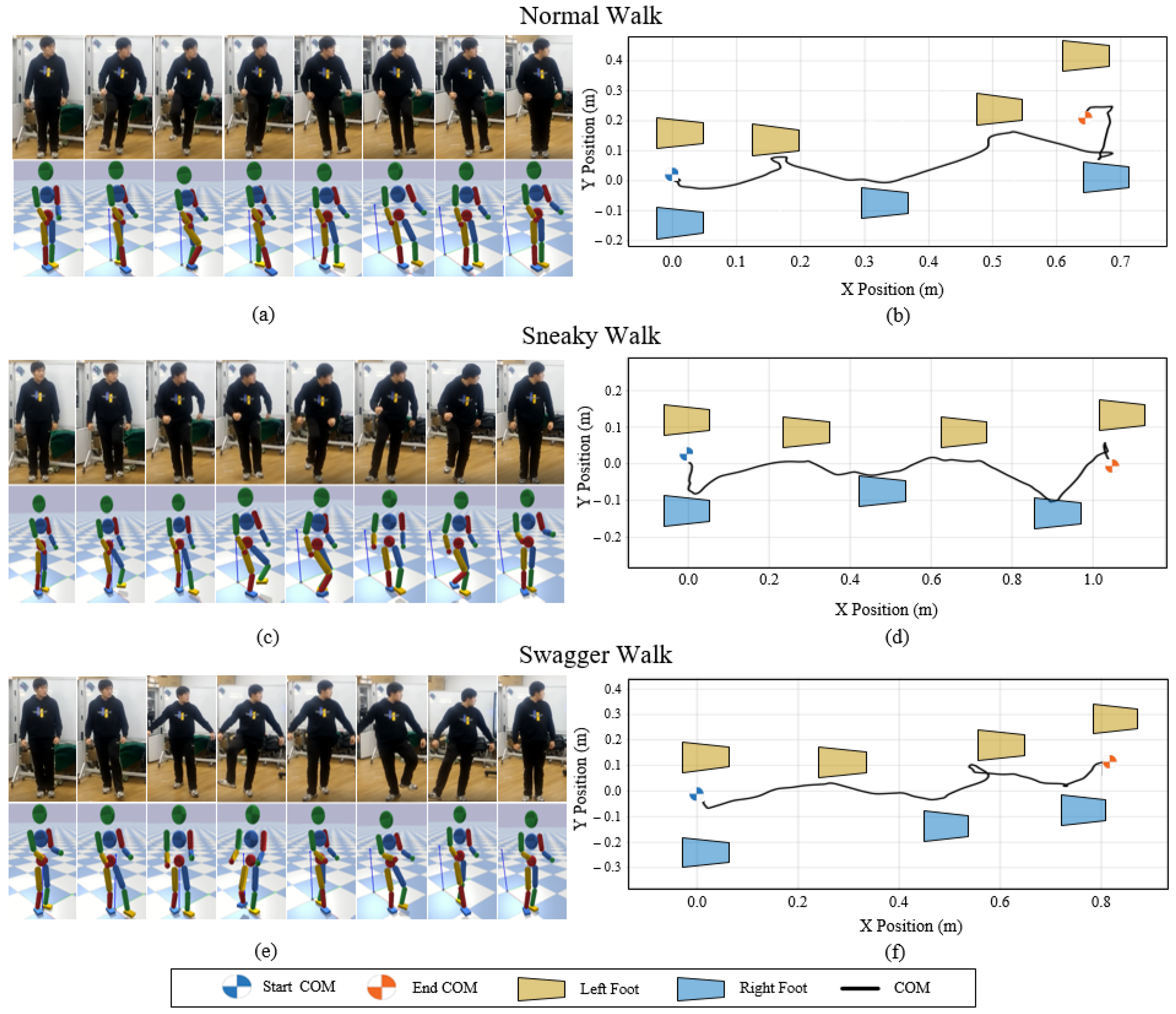
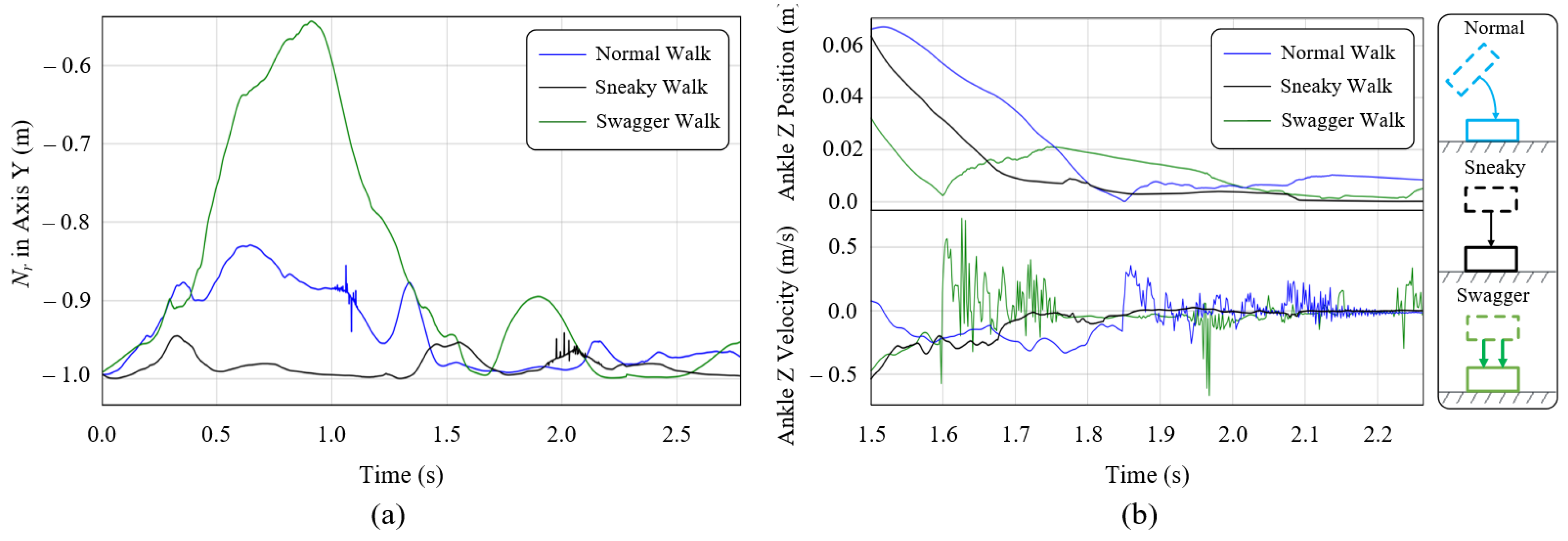
7.4.3. Teleoperating with Different Styles
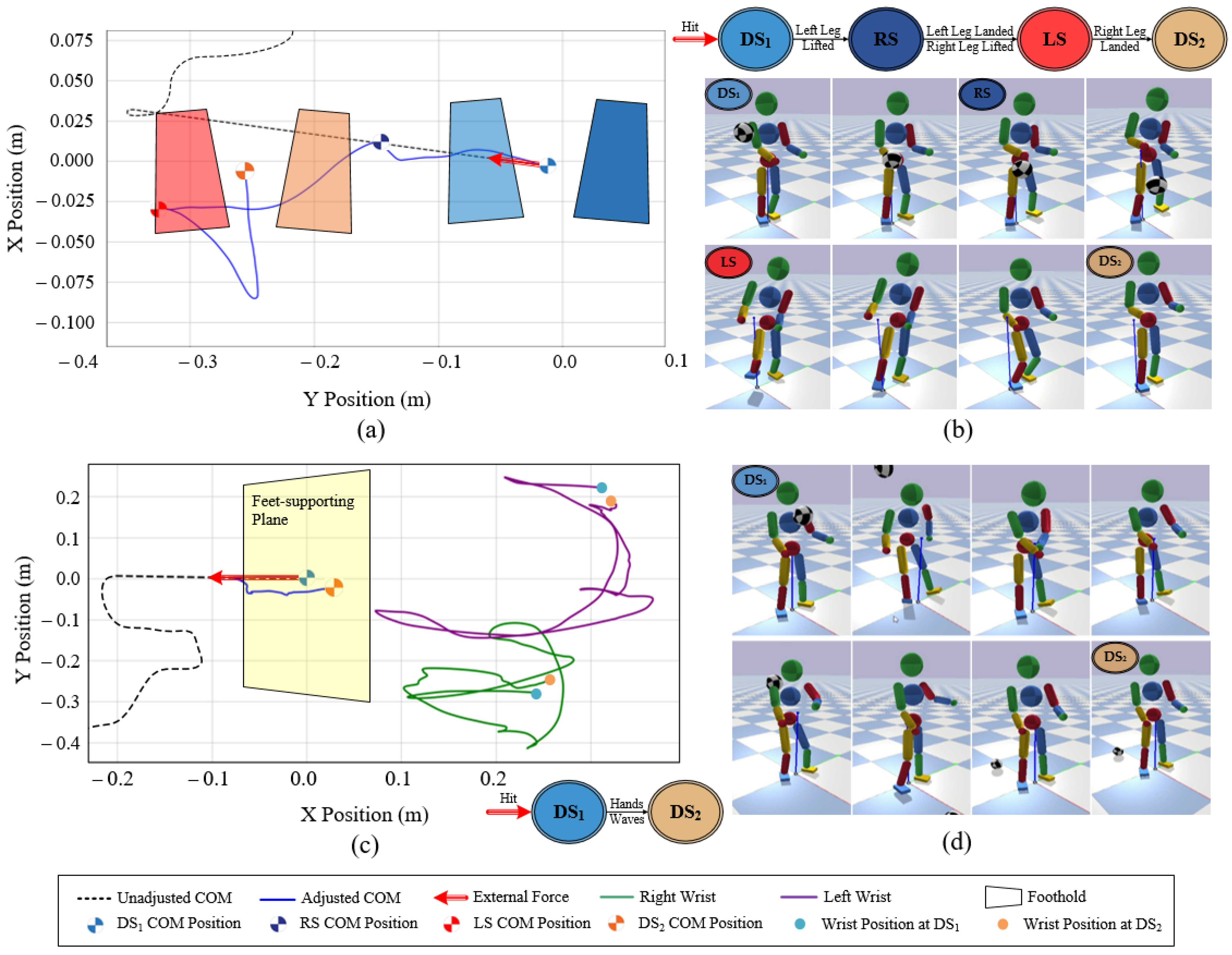
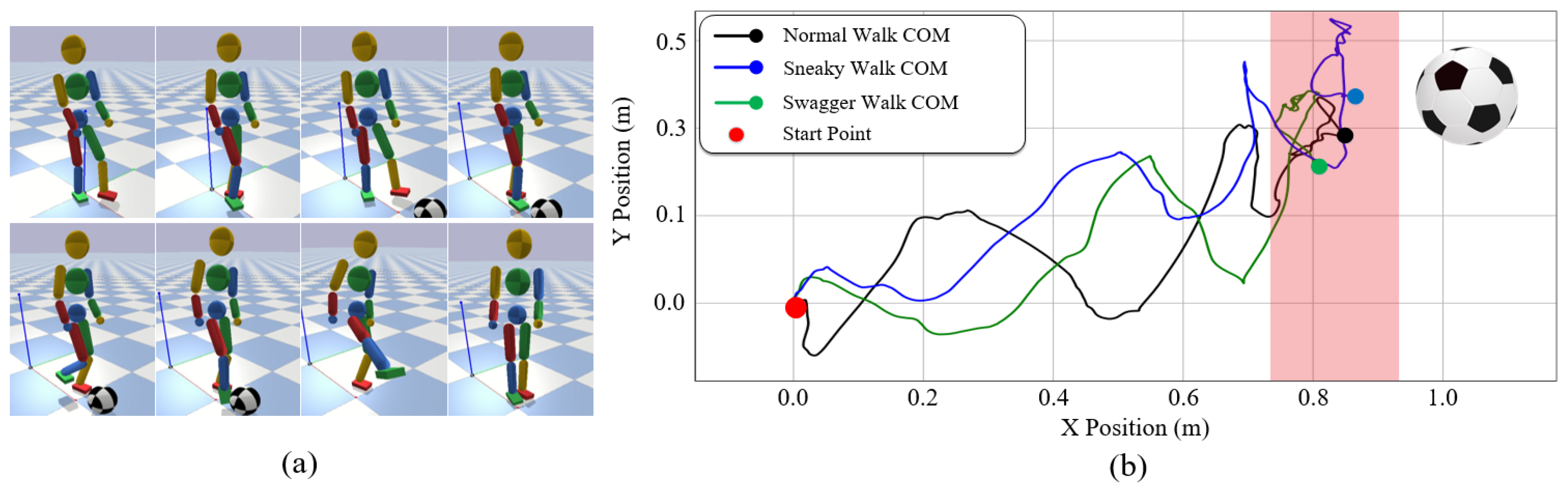
7.4.4. Teleoperating for a Target
7.4.5. Generalization of the Teleoperation
8. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Müller, B.; Wolf, S.I. Handbook of Human Motion; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Yin, K.; Loken, K.; Van De Panne, M. Simbicon: Simple biped locomotion control. ACM Trans. Graph. TOG 2007, 26, 105-es. [Google Scholar] [CrossRef]
- Coros, S.; Beaudoin, P.; Van De Panne, M. Generalized biped walking control. ACM Trans. Graph. TOG 2010, 29, 1–9. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, S.; Lee, J. Data-driven biped control. In Proceedings of the SIGGRAPH ‘10: Special Interest Group on Computer Graphics and Interactive Techniques Conference, Los Angeles, CA, USA, 26–30 July 2010; pp. 1–8. [Google Scholar]
- Geijtenbeek, T.; Pronost, N.; Van Der Stappen, A.F. Simple data-driven control for simulated bipeds. In Proceedings of the 11th ACM SIGGRAPH/Eurographics Conference on Computer Animation, Lausanne, Switzerland, 29–31 July 2012; pp. 211–219. [Google Scholar]
- Da Silva, M.; Abe, Y.; Popović, J. Interactive simulation of stylized human locomotion. In Proceedings of the SIGGRAPH ‘08: Special Interest Group on Computer Graphics and Interactive Techniques Conference, Los Angeles, CA, USA, 11–15 August 2008; Volume 27, pp. 1–10. [Google Scholar]
- Da Silva, M.; Abe, Y.; Popović, J. Simulation of human motion data using short-horizon model-predictive control. Comput. Graph. Forum 2008, 27, 371–380. [Google Scholar] [CrossRef]
- Kavafoglu, Z.; Kavafoglu, E.; Cimen, G.; Capin, T.; Gurcay, H. Style-based biped walking control. Vis. Comput. 2018, 34, 359–375. [Google Scholar] [CrossRef]
- Alamri, A.; Eid, M.; Iglesias, R.; Shirmohammadi, S.; El Saddik, A. Haptic Virtual Rehabilitation Exercises for Poststroke Diagnosis. IEEE Trans. Instrum. Meas. 2008, 57, 1876–1884. [Google Scholar] [CrossRef]
- Vakanski, A.; Jun, H.-p.; Paul, D.; Baker, R. A Data Set of Human Body Movements for Physical Rehabilitation Exercises. Data 2018, 3, 2. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Lun, R.; Espy, D.D.; Reinthal, M.A. Rule based realtime motion assessment for rehabilitation exercises. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Healthcare and E-Health (CICARE), Orlando, FL, USA, 9–12 December 2014; pp. 133–140. [Google Scholar]
- Mihajlovic, Z.; Popovic, S.; Brkic, K.; Cosic, K. A system for head-neck rehabilitation exercises based on serious gaming and virtual reality. Multimed. Tools Appl. 2018, 77, 19113–19137. [Google Scholar] [CrossRef]
- Pratt, J.; Tedrake, R. Velocity Based Stability Margins for Fast Bipedal Walking. In Fast Motions in Biomechanics and Robotics; Diehl, M., Mombaur, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Tsai, Y.Y.; Lin, W.C.; Cheng, K.B.; Lee, J.; Lee, T.Y. Real-time physics-based 3D biped character animation using an inverted pendulum model. IEEE Trans. Vis. Comput. Graph. 2009, 16, 325–337. [Google Scholar] [CrossRef] [Green Version]
- Ramos, J.; Kim, S. Dynamic bilateral teleoperation of the cart-pole: A study toward the synchronization of human operator and legged robot. IEEE Robot. Autom. Lett. 2018, 3, 3293–3299. [Google Scholar] [CrossRef]
- Kwon, T.; Hodgins, J.K. Momentum-mapped inverted pendulum models for controlling dynamic human motions. ACM Trans. Graph. TOG 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Hwang, J.; Suh, I.H.; Park, G.; Kwon, T. Human character balancing motion generation based on a double inverted pendulum model. In Proceedings of the Tenth International Conference on Motion in Games, Barcelona, Spain, 8–10 November 2017; pp. 1–6. [Google Scholar]
- Hwang, J.; Kim, J.; Suh, I.H.; Kwon, T. Real-time locomotion controller using an inverted-pendulum-based abstract model. Comput. Graph. Forum 2018, 37, 287–296. [Google Scholar] [CrossRef]
- Al Borno, M.; Righetti, L.; Black, M.J.; Delp, S.L.; Fiume, E.; Romero, J. Robust Physics-based Motion Retargeting with Realistic Body Shapes. Comput. Graph. Forum 2018, 37, 81–92. [Google Scholar] [CrossRef]
- Kavafoglu, Z.; Kavafoglu, E.; Egges, A. Robust standing control with posture optimization. Comput. Animat. Virtual Worlds 2018, 29, e1746. [Google Scholar] [CrossRef]
- Han, D.; Noh, J.; Jin, X.; Shin, J.S.; Shin, S.Y. On-line real-time physics-based predictive motion control with balance recovery. Comput. Graph. Forum 2014, 33, 245–254. [Google Scholar] [CrossRef]
- Zordan, V.; Brown, D.; Macchietto, A.; Yin, K. Control of rotational dynamics for ground and aerial behavior. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1356–1366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, G.C.; Lee, Y. Finite State Machine-Based Motion-Free Learning of Biped Walking. IEEE Access 2021, 9, 20662–20672. [Google Scholar] [CrossRef]
- Wang, J.M.; Fleet, D.J.; Hertzmann, A. Optimizing walking controllers. In Proceedings of the ACM SIGGRAPH Asia, Yokohama, Japan, 16–19 December 2009; pp. 1–8. [Google Scholar]
- Peng, X.B.; Abbeel, P.; Levine, S.; van de Panne, M. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Trans. Graph. TOG 2018, 37, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Ramos, J.; Kim, S. Dynamic locomotion synchronization of bipedal robot and human operator via bilateral feedback teleoperation. Sci. Robot. 2019, 4, eaav4282. [Google Scholar] [CrossRef]
- Oh, J.; Lee, I.; Jeong, H.; Oh, J.H. Real-time humanoid whole-body remote control framework for imitating human motion based on kinematic mapping and motion constraints. Adv. Robot. 2019, 33, 293–305. [Google Scholar] [CrossRef]
- Oh, J.; Sim, O.; Jeong, H.; Oh, J.H. Humanoid whole-body remote-control framework with delayed reference generator for imitating human motion. Mechatronics 2019, 62, 102253. [Google Scholar] [CrossRef]
- Oh, J.; Sim, O.; Cho, B.; Lee, K.; Oh, J.H. Online Delayed Reference Generation for a Humanoid Imitating Human Walking Motion. IEEE/ASME Trans. Mechatron. 2020, 26, 102–112. [Google Scholar] [CrossRef]
- Silva, D.B.; Vidal, C.A.; Cavalcante-Neto, J.B.; Pessoa, I.N.; Nunes, R.F. Topple-free foot strategy applied to real-time motion capture data using kinect sensor. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, Virtual, 22–26 March 2021; pp. 98–106. [Google Scholar]
- Winter, D.A. Human balance and posture control during standing and walking. Gait Posture 1995, 3, 193–214. [Google Scholar] [CrossRef]
- Skoyles, J.R. Human Balance, the Evolution of Bipedalism and Dysequilibrium Syndrome. Med. Hypotheses 2006, 66, 1060–1068. [Google Scholar] [CrossRef] [PubMed]
- Microsoft Ignite China. Available online: https://docs.microsoft.com/zh-cn/azure/kinect-dk/body-sdk-download (accessed on 19 December 2021).
- Clauser, C.E.; McConville, J.T.; Young, J.W. Weight, Volume, and Center of Mass of Segments of the Human Body; Antioch College: Yellow Springs, OH, USA, 1969. [Google Scholar]
- Casiez, G.; Roussel, N.; Vogel, D. 1€ Filter: A simple speed-based low-pass filter for noisy input in interactive systems. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 2527–2530. [Google Scholar]
- Macchietto, A.; Zordan, V.; Shelton, C.R. Momentum control for balance. In Proceedings of the SIGGRAPH09: Special Interest Group on Computer Graphics and Interactive Techniques Conference, New Orleans, LO, USA, 3–7 August 2009; pp. 1–8. [Google Scholar]
- Alexander, R.M. Principles of Animal Locomotion; Princeton University Press: Princeton, NJ, USA, 2013. [Google Scholar]
- Bullet Physics Engine. Available online: https://pybullet.org/wordpress/ (accessed on 19 December 2021).
- Jessell, T.M.; Siegelbaum, S.A.; Hudspeth, A.J. Principles of Neural Science; Schwartz, J.H., Kandel, E.R., Eds.; Elsevier: New York, NY, USA, 2013; pp. 173–193. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Balance | Style | ||
|---|---|---|---|
| Hip | Active Balance | Feet orientation | Expressive Style |
| Shoulder | Leg Motion Plane | ||
| Knee | Conformable Balance | Arm Motion Plane | |
| Elbow | Hands’ and Feet Position | Target-based Style | |
| Ankle | COM Heading and Position | ||
| Wrist | |||
| Link Name | Character Link Attributes | Human Link Attributes | ||||
|---|---|---|---|---|---|---|
| Mass (kg) | Size (m) | Mass (kg) | Size (m) | |||
| Pelvis | 6.0 | Sphere Radius | 0.09 | 19.8 | Radius | 0.17 |
| Torso | 14.0 | Sphere Radius | 0.11 | 10.3 | Radius | 0.15 |
| Head | 2.0 | Sphere Radius | 0.10 | 5.7 | Radius | 0.09 |
| Upper Arm | 1.5 | Radius | 0.05 | 2.0 | Radius | 0.08 |
| Length | 0.18 | Length | 0.20 | |||
| Lower Arm | 1.0 | Radius | 0.1 | 1.2 | Radius | 0.1 |
| Length | 0.14 | Length | 0.20 | |||
| Upper Leg | 4.5 | Radius | 0.06 | 11.5 | Radius | 0.09 |
| Length | 0.30 | Length | 0.40 | |||
| Lower Leg | 3.0 | Radius | 0.06 | 3.3 | Radius | 0.40 |
| Length | 0.31 | Length | 0.40 | |||
| Foot | 1.0 | Length | 0.18 | 2.0 | Length | 0.30 |
| Width | 0.08 | Width | 0.10 | |||
| Height | 0.05 | Height | 0.06 | |||
| Joint Name | Gain Parameters of PID Controller | ||
| Chest | 2500 | 40 | 36 |
| Neck | 30 | 5 | 3 |
| Hip | 500 | 100 | 20 |
| Knee | 360 | 72 | 20 |
| Ankle | 60 | 15 | 2 |
| Shoulder | 60 | 15 | 7 |
| Elbow | 60 | 15 | 1 |
| Virtual Compensation | Gain Parameters of CR-VC | ||
| Virtual Force | 50 | 30 | |
| Virtual Torque | 5000 | 1000 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Z.; Bao, T.; Ren, Z.; Fan, Y.; Deng, K.; Jia, W. Real-Time Stylized Humanoid Behavior Control through Interaction and Synchronization. Sensors 2022, 22, 1457. https://doi.org/10.3390/s22041457
Cao Z, Bao T, Ren Z, Fan Y, Deng K, Jia W. Real-Time Stylized Humanoid Behavior Control through Interaction and Synchronization. Sensors. 2022; 22(4):1457. https://doi.org/10.3390/s22041457
Chicago/Turabian StyleCao, Zhiyan, Tianxu Bao, Zeyu Ren, Yunxin Fan, Ken Deng, and Wenchuan Jia. 2022. "Real-Time Stylized Humanoid Behavior Control through Interaction and Synchronization" Sensors 22, no. 4: 1457. https://doi.org/10.3390/s22041457
APA StyleCao, Z., Bao, T., Ren, Z., Fan, Y., Deng, K., & Jia, W. (2022). Real-Time Stylized Humanoid Behavior Control through Interaction and Synchronization. Sensors, 22(4), 1457. https://doi.org/10.3390/s22041457