
Unsupervised Learning of Monocular Depth and Ego-Motion with Optical Flow Features and Multiple Constraints


Abstract
:1. Introduction
- We propose a novel unsupervised learning framework for estimating the depth and camera ego-motion. By virtue of the optical flow property, the framework extracts the features from the optical flow rather than from the raw RGB images, thereby enhancing unsupervised learning;
- We eliminate the outlier regions such as occlusion regions and moving objects for the learning by generating a mask of the invalid region in the scene according to the forward-backward consistency of the optical flow, thereby preventing the training from being inhibited and improving the performance;
- We propose optical flow consistency loss and depth consistency loss as additional supervision signals to further enhance the training of the models;
- We conduct extensive experiments on multiple benchmark datasets, and the results demonstrate that our method outperforms the existing unsupervised algorithms.
2. Related Work
2.1. Supervised Learning of Monocular Depth and Ego-Motion
2.2. Unsupervised Learning of Monocular Depth and Ego-Motion
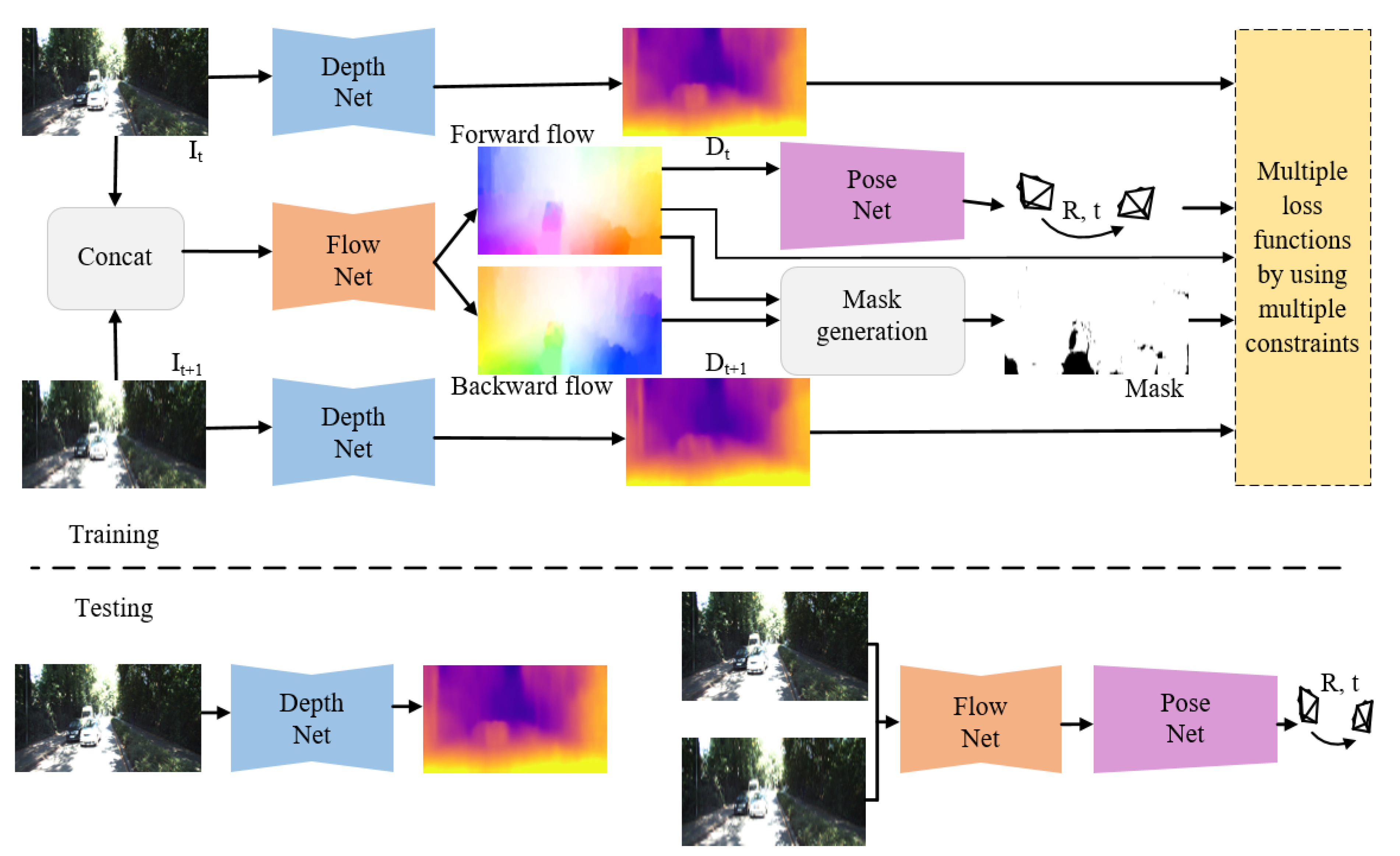
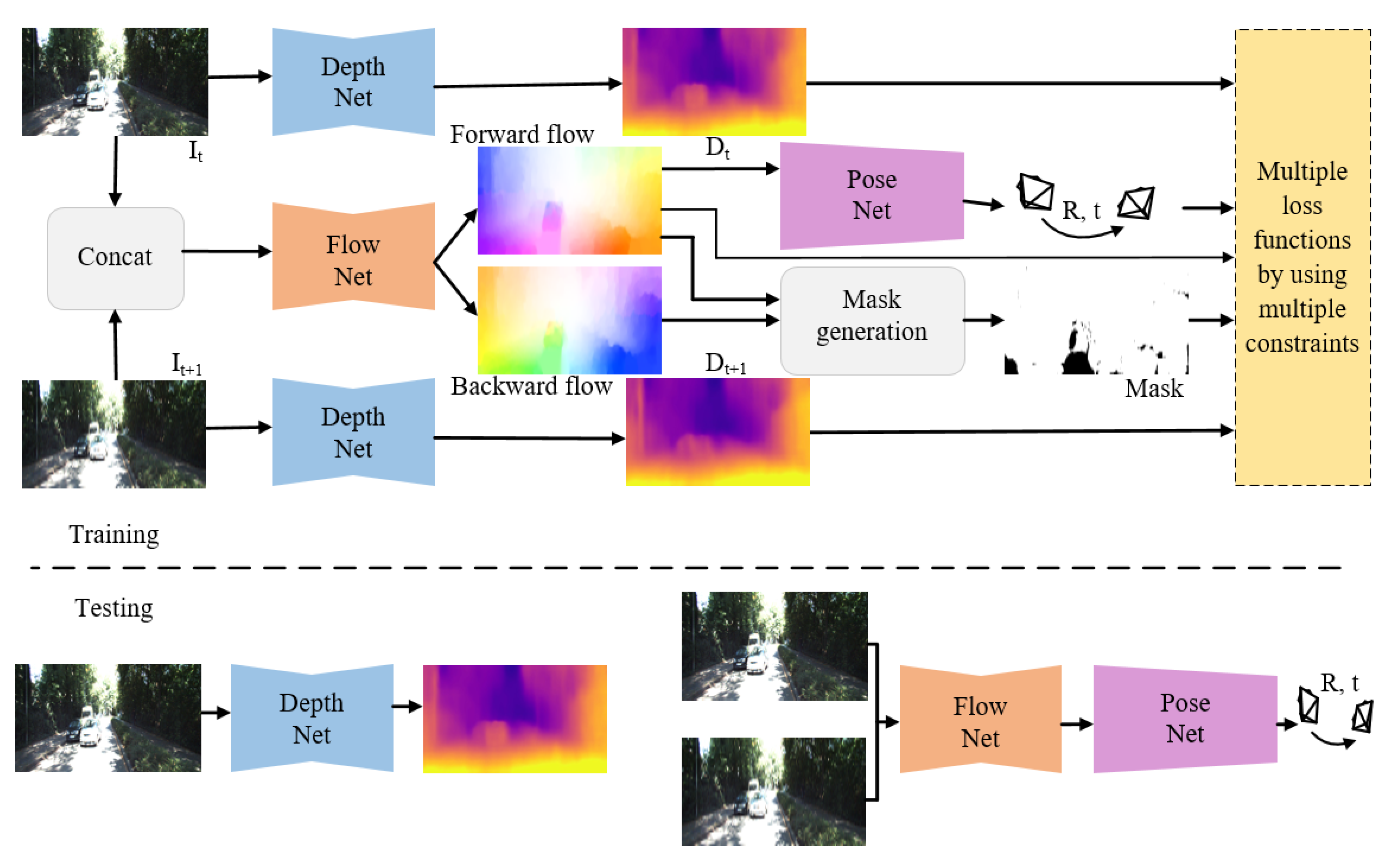
3. Methods
3.1. The Networks
3.2. Photometric Consistency Loss and Smoothness Loss
3.3. Outlier Region Elimination
3.4. Optical Flow Consistency Loss
3.5. Depth Consistency Loss
4. Experiment and Results
4.1. Datasets and Metrics
4.2. Ablation Study
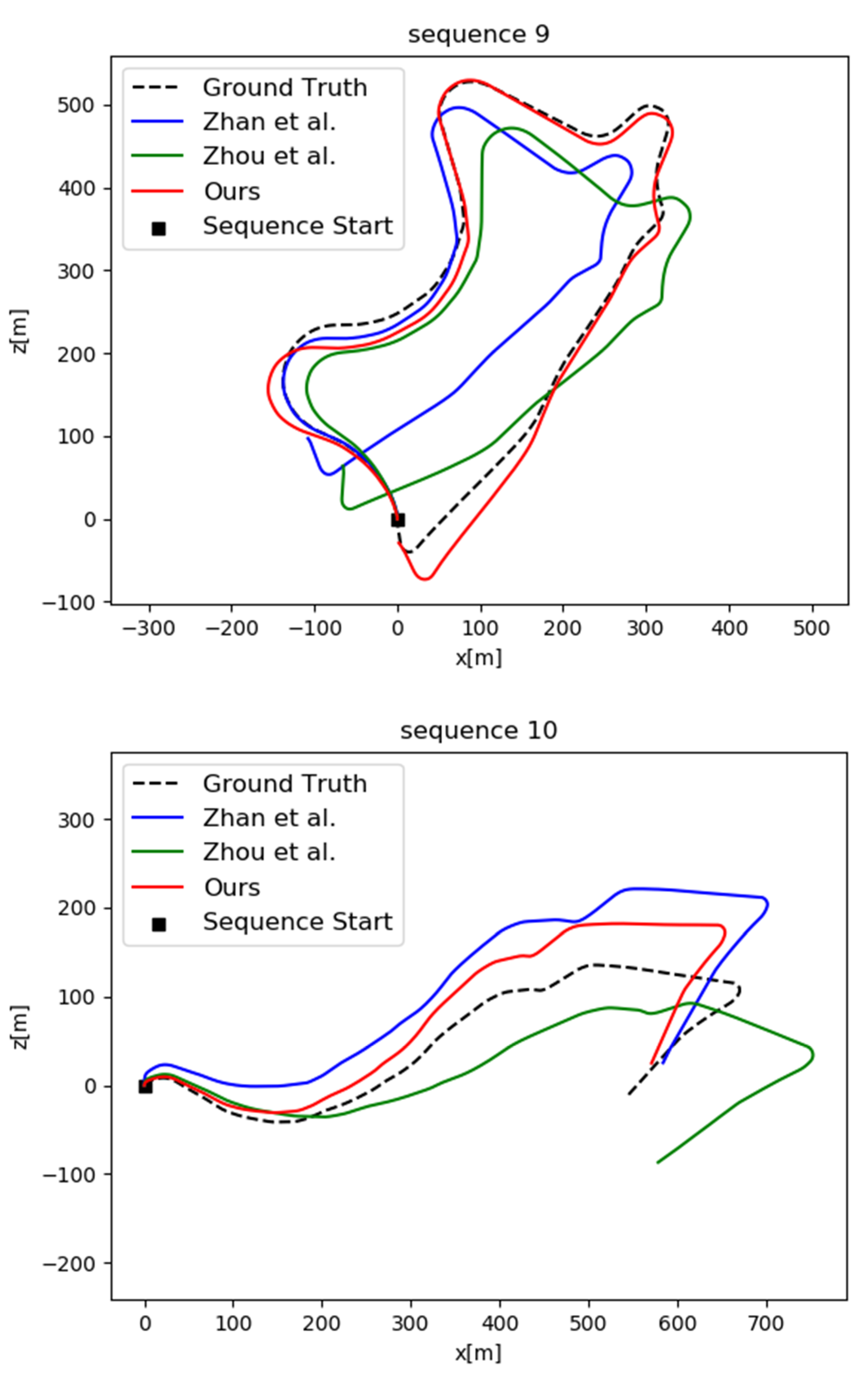
4.3. Evaluation of Ego-Motion Estimation
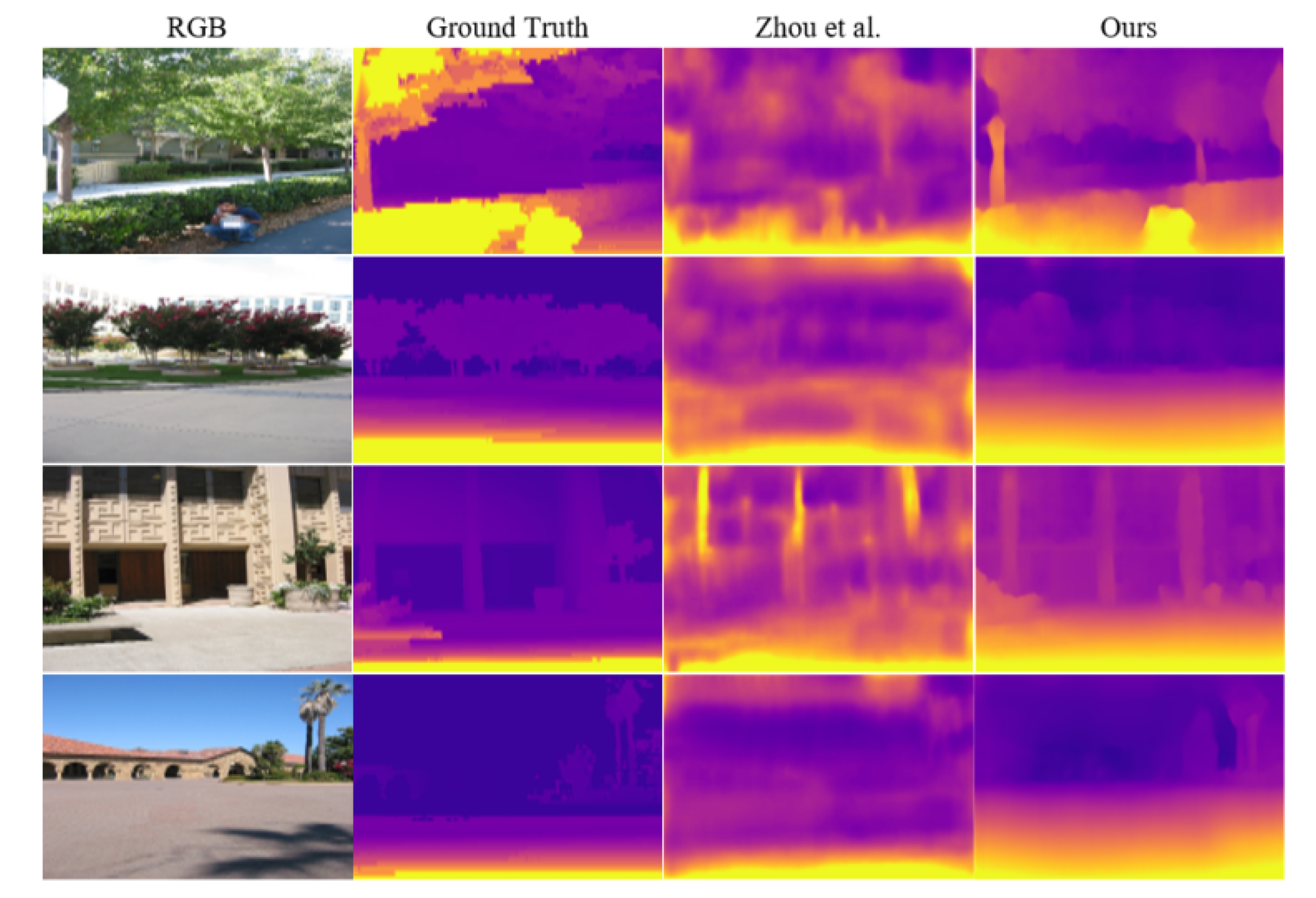
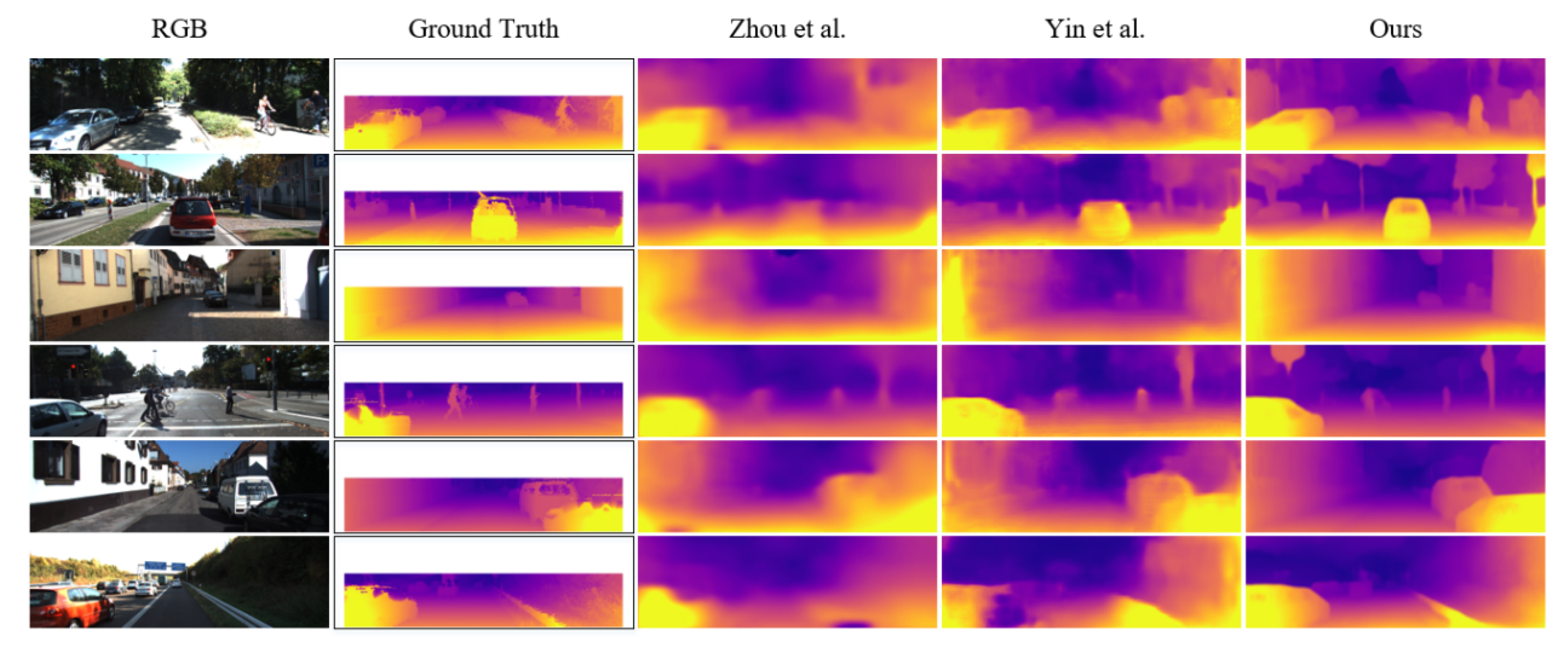
4.4. Evaluation of Depth Estimation
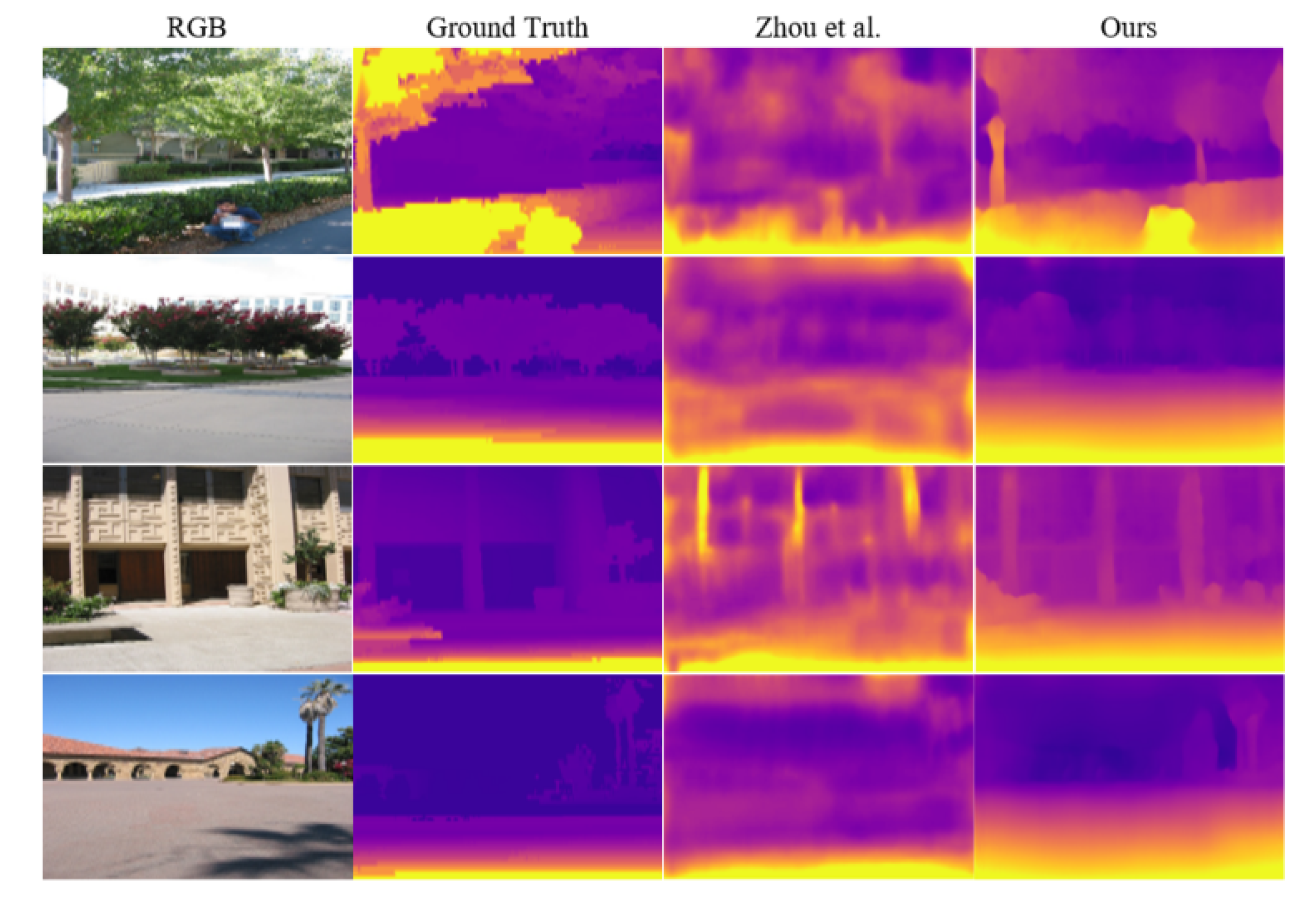
4.5. Generalization to Other Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, K.; Akbarpour, H.A.; Fraser, J.; Nouduri, K.; Palaniappan, K. Local Feature Performance Evaluation for Structure-from-Motion and Multi-View Stereo Using Simulated City-Scale Aerial Imagery. IEEE Sens. J. 2020, 21, 11615–11627. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Wenyan, C.; Huang, Y. A Robust Method for Ego-Motion Estimation in Urban Environment Using Stereo Camera. Sensors 2016, 16, 1704. [Google Scholar]
- Zou, Y.; Eldemiry, A.; Li, Y.; Chen, W. Robust RGB-D SLAM Using Point and Line Features for Low Textured Scene. Sensors 2020, 20, 4984. [Google Scholar] [CrossRef] [PubMed]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 13 December 2014; pp. 2366–2374. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, T.; Gu, D. SGANVO: Unsupervised Deep Visual Odometry and Depth Estimation with Stacked Generative Adversarial Networks. IEEE Robot. Autom. Lett. 2019, 4, 4431–4437. [Google Scholar] [CrossRef] [Green Version]
- Gwn, K.; Reddy, K.; Giering, M.; Bernal, E.A. Generative Adversarial Networks for Depth Map Estimation from RGB Video. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1258–12588. [Google Scholar]
- Zhao, S.; Fu, H.; Gong, M.; Tao, D. Geometry-Aware Symmetric Domain Adaptation for Monocular Depth Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9780–9790. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2043–2050. [Google Scholar]
- Saputra, M.; Gusmao, P.D.; Wang, S.; Markham, A.; Trigoni, N. Learning Monocular Visual Odometry through Geometry-Aware Curriculum Learning. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3549–3555. [Google Scholar]
- Saputra, M.; Gusmao, P.; Almalioglu, Y.; Markham, A.; Trigoni, N. Distilling Knowledge From a Deep Pose Regressor Network. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 263–272. [Google Scholar]
- Costante, G.; Ciarfuglia, T.A. LS-VO: Learning Dense Optical Subspace for Robust Visual Odometry Estimation. IEEE Robot. Autom. Lett. 2018, 3, 1735–1742. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Huang, Y.; Wei, H.; Hu, X. Ego-Motion Estimation Using Recurrent Convolutional Neural Networks through Optical Flow Learning. Electronics 2021, 10, 222. [Google Scholar] [CrossRef]
- Zhao, C.; Sun, K.L.; Yan, Z.; Neumann, G.; Stolkin, R. Learning Kalman Network: A Deep Monocular Visual Odometry for On-Road Driving. Robot. Auton. Syst. 2019, 121, 103234. [Google Scholar] [CrossRef]
- Zhou, T.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 6612–6619. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 340–349. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5667–5675. [Google Scholar]
- Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R. LEGO: Learning Edge with Geometry all at Once by Watching Videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 225–234. [Google Scholar]
- Jiang, H.; Ding, L.; Sun, Z.; Huang, R. Unsupervised Monocular Depth Perception: Focusing on Moving Objects. IEEE Sens. J. 2021, 21, 27225–27237. [Google Scholar] [CrossRef]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Zhang, J.N.; Su, Q.X.; Liu, P.Y.; Ge, H.Y.; Zhang, Z.F. MuDeepNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose Using Multi-view Consistency Loss. Int. J. Control Autom. Syst. 2019, 17, 2586–2596. [Google Scholar] [CrossRef]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Black, M.J. Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12232–12241. [Google Scholar]
- Zhao, S.; Sheng, Y.; Dong, Y.; Chang, I.C.; Xu, Y. MaskFlownet: Asymmetric Feature Matching with Learnable Occlusion Mask. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6277–6286. [Google Scholar]
- Sun, D.; Roth, S.; Black, M. A Quantitative Analysis of Current Practices in Optical Flow Estimation and the Principles behind Them. Int. J. Comput. Vis. 2014, 106, 115–137. [Google Scholar] [CrossRef] [Green Version]
- Sundaram, N.; Brox, T.; Keutzer, K. Dense Point Trajectories by GPU-accelerated Large Displacement Optical Flow. In Proceedings of the 2010 European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 438–451. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Saxena, A.; Min, S.; Ng, A.Y. Learning 3-d scene structure from a single still image. In Proceedings of the 2007 IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 6602–6611. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ATE of Seq.09 | ATE of Seq.10 |
|---|---|---|
| Baseline | 0.017 ± 0.009 | 0.015 ± 0.010 |
| Baseline + outlier elimination | 0.012 ± 0.007 | 0.013 ± 0.007 |
| Baseline + outlier elimination + | 0.011 ± 0.007 | 0.010 ± 0.006 |
| Baseline + outlier elimination + + | 0.010 ± 0.005 | 0.009 ± 0.006 |
| Method | ATE of Seq.09 | ATE of Seq.10 |
|---|---|---|
| ORB-SLAM (full) [2] | 0.014 ± 0.008 | 0.012 ± 0.011 |
| ORB-SLAM (short) | 0.064 ± 0.141 | 0.064 ± 0.130 |
| Zhou et al. [16] | 0.016 ± 0.009 | 0.013 ± 0.009 |
| Mahjourian et al. [18] | 0.013 ± 0.010 | 0.012 ± 0.011 |
| Yin et al. [21] | 0.012 ± 0.007 | 0.012 ± 0.009 |
| Ranjan et al. [23] | 0.012 ± 0.007 | 0.012 ± 0.008 |
| Ours | 0.010 ± 0.005 | 0.009 ± 0.006 |
| Method | Supervision Signal | Training Dataset | Error Metric | Accuracy Metric | |||||
|---|---|---|---|---|---|---|---|---|---|
| Abs.Rel | Sq.Rel | RMSE | RMSE (log) | ||||||
| Eigen et al. [5] Coarse | Depth | K | 0.214 | 1.605 | 6.563 | 0.292 | 0.673 | 0.884 | 0.957 |
| Eigen et al. [5] Fine | Depth | K | 0.203 | 1.548 | 6.307 | 0.282 | 0.702 | 0.890 | 0.958 |
| Liu et al. [6] | Depth | K | 0.202 | 1.614 | 6.523 | 0.275 | 0.678 | 0.895 | 0.965 |
| Zhan et al. [17] | Stereo | K | 0.144 | 1.391 | 5.869 | 0.241 | 0.803 | 0.928 | 0.969 |
| Godard et al. [30] | Stereo | K | 0.148 | 1.344 | 5.927 | 0.247 | 0.803 | 0.922 | 0.964 |
| Zhou et al. [16] | Mono | K | 0.208 | 1.768 | 6.856 | 0.283 | 0.678 | 0.885 | 0.957 |
| Zhou et al. [16] updated | Mono | K | 0.183 | 1.595 | 6.709 | 0.270 | 0.734 | 0.902 | 0.959 |
| Mahjourian et al. [18] | Mono | K | 0.163 | 1.240 | 6.220 | 0.250 | 0.762 | 0.916 | 0.968 |
| Yang et al. [19] | Mono | K | 0.162 | 1.352 | 6.276 | 0.252 | - | - | - |
| Yin et al. [21] | Mono | K | 0.155 | 1.296 | 5.857 | 0.233 | 0.793 | 0.931 | 0.973 |
| Ranjan et al. [23] | Mono | K | 0.140 | 1.070 | 5.326 | 0.217 | 0.826 | 0.941 | 0.975 |
| Godard et al. [30] | Mono | K | 0.154 | 1.218 | 5.699 | 0.231 | 0.798 | 0.932 | 0.973 |
| Ours | Mono | K | 0.138 | 1.065 | 5.289 | 0.215 | 0.827 | 0.943 | 0.979 |
| Zhou et al. [16] | Mono | CS + K | 0.198 | 1.836 | 6.565 | 0.275 | 0.718 | 0.901 | 0.960 |
| Mahjourian et al. [18] | Mono | CS + K | 0.159 | 1.231 | 5.912 | 0.243 | 0.784 | 0.923 | 0.970 |
| Yang et al. [19] | Mono | CS + K | 0.159 | 1.345 | 6.254 | 0.247 | - | - | - |
| Yin et al. [21] | Mono | CS + K | 0.153 | 1.328 | 5.737 | 0.232 | 0.802 | 0.934 | 0.972 |
| Ranjan et al. [23] | Mono | CS + K | 0.139 | 1.032 | 5.199 | 0.213 | 0.827 | 0.943 | 0.977 |
| Ours | Mono | CS + K | 0.136 | 1.031 | 5.186 | 0.209 | 0.831 | 0.947 | 0.981 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, B.; Huang, Y.; Ci, W.; Hu, X. Unsupervised Learning of Monocular Depth and Ego-Motion with Optical Flow Features and Multiple Constraints. Sensors 2022, 22, 1383. https://doi.org/10.3390/s22041383
Zhao B, Huang Y, Ci W, Hu X. Unsupervised Learning of Monocular Depth and Ego-Motion with Optical Flow Features and Multiple Constraints. Sensors. 2022; 22(4):1383. https://doi.org/10.3390/s22041383
Chicago/Turabian StyleZhao, Baigan, Yingping Huang, Wenyan Ci, and Xing Hu. 2022. "Unsupervised Learning of Monocular Depth and Ego-Motion with Optical Flow Features and Multiple Constraints" Sensors 22, no. 4: 1383. https://doi.org/10.3390/s22041383
APA StyleZhao, B., Huang, Y., Ci, W., & Hu, X. (2022). Unsupervised Learning of Monocular Depth and Ego-Motion with Optical Flow Features and Multiple Constraints. Sensors, 22(4), 1383. https://doi.org/10.3390/s22041383