
Robot System Assistant (RoSA): Towards Intuitive Multi-Modal and Multi-Device Human-Robot Interaction

 ,
,  , , , and
, , , and
Abstract
:
1. Introduction
2. Related Work
3. Framework Overview
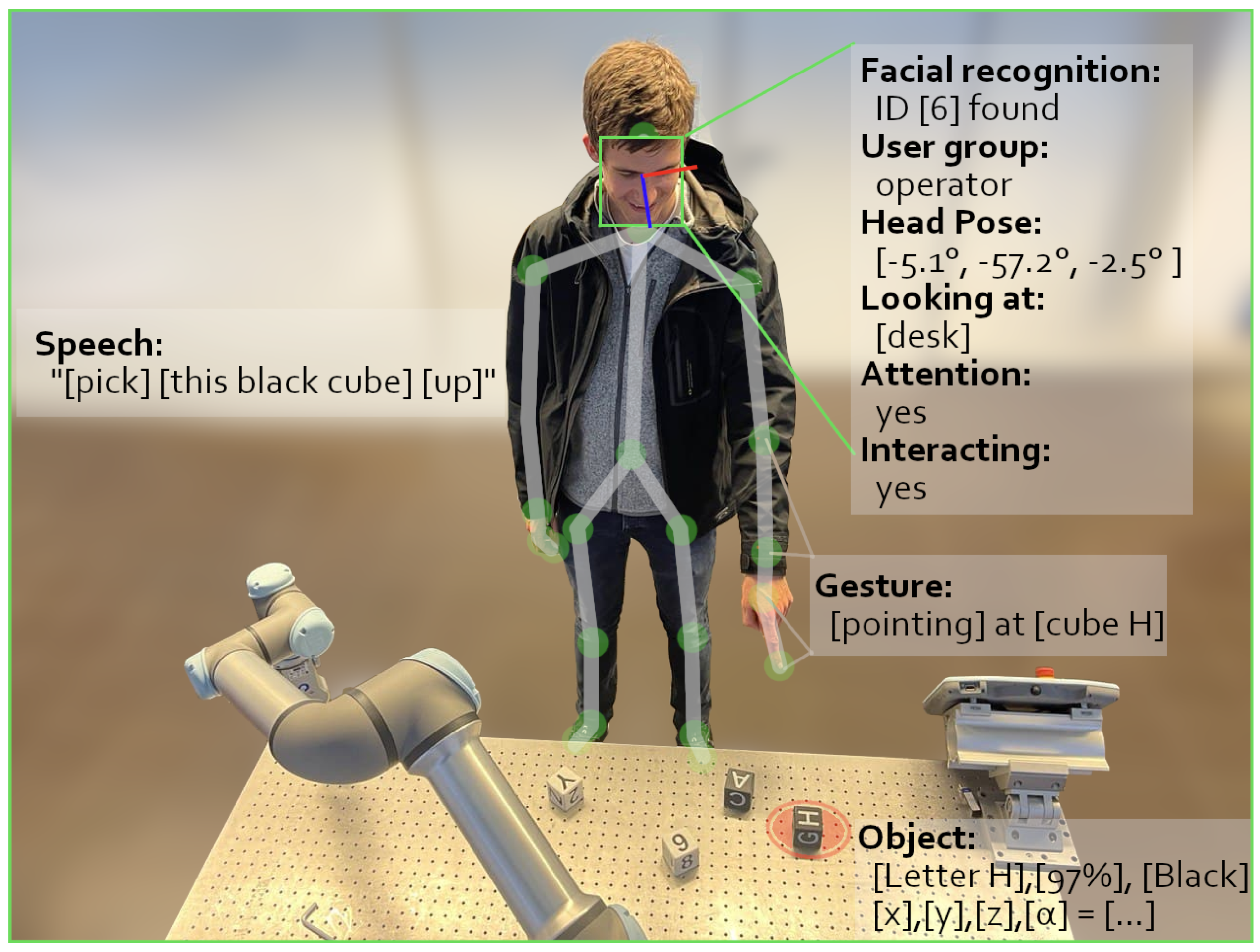
3.1. Concept
3.2. Features
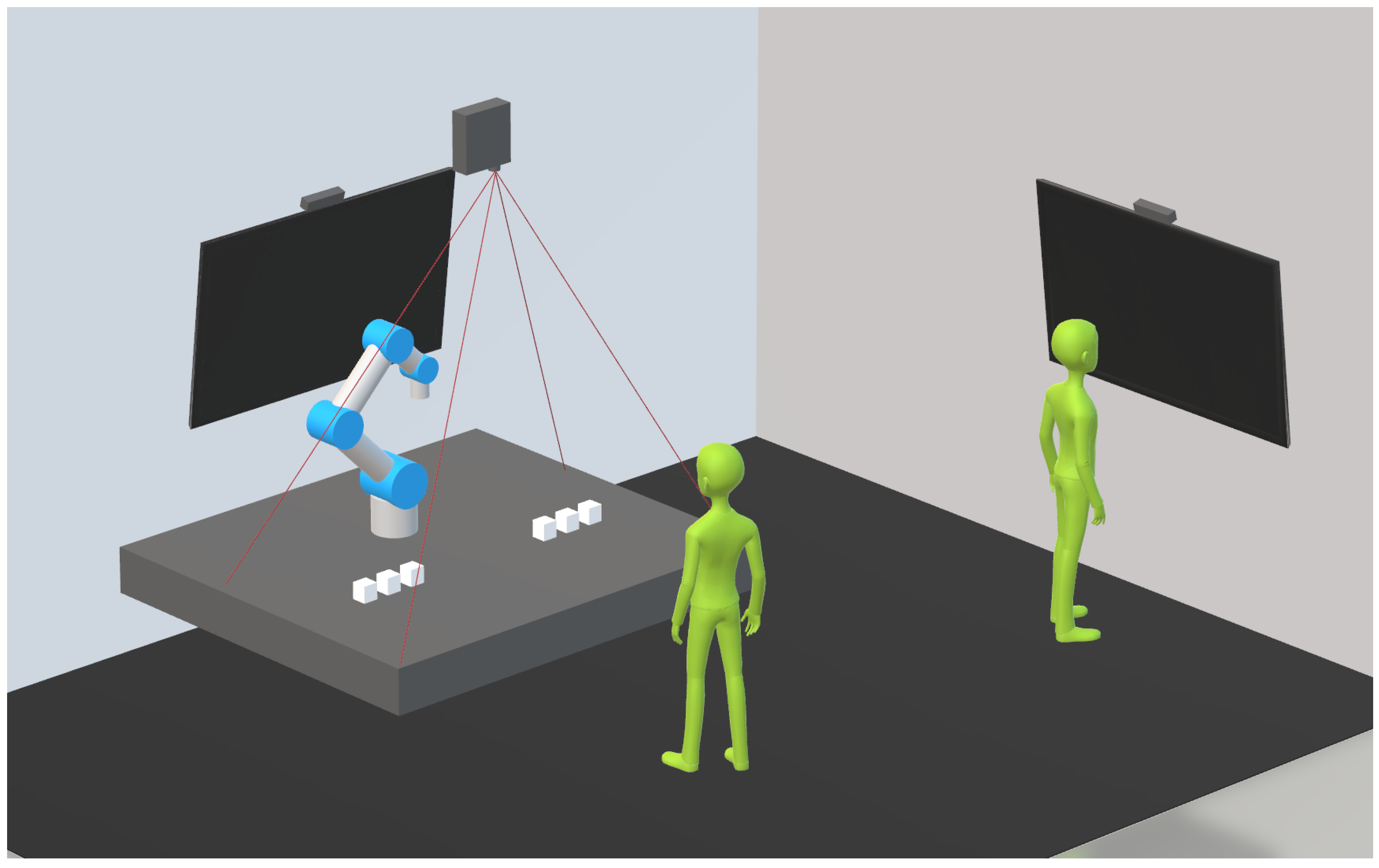
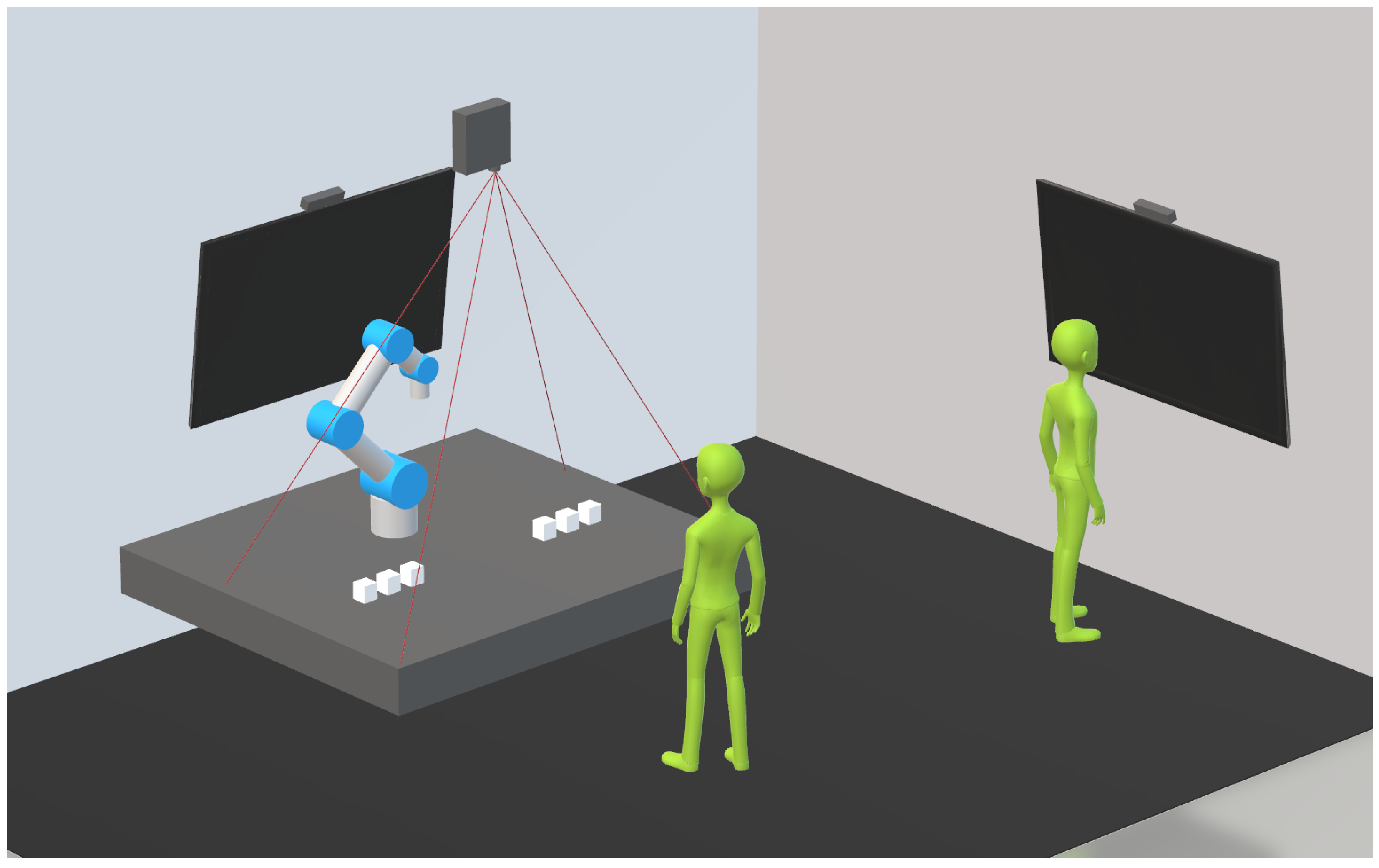
4. System Setup
4.1. Hardware
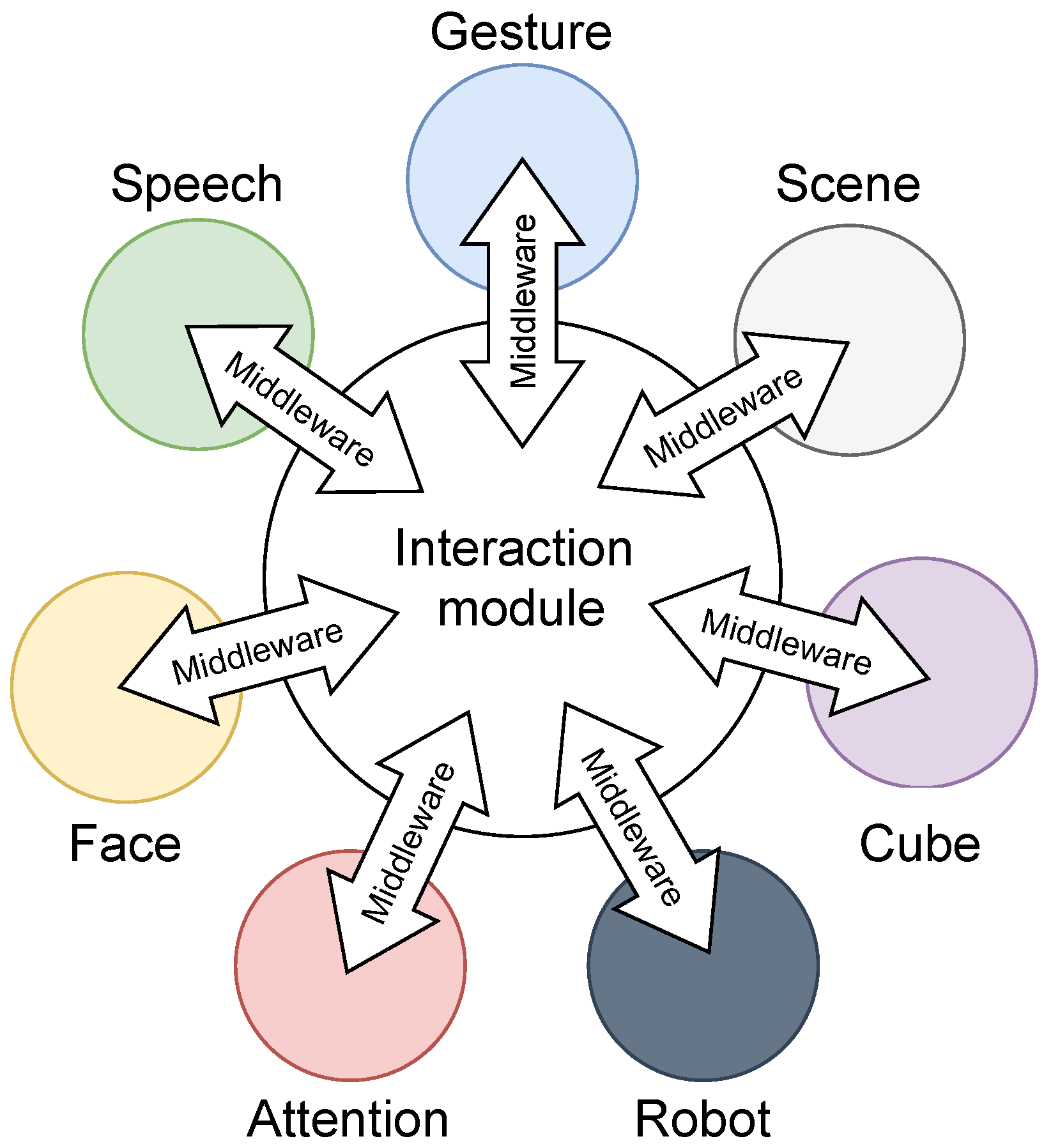
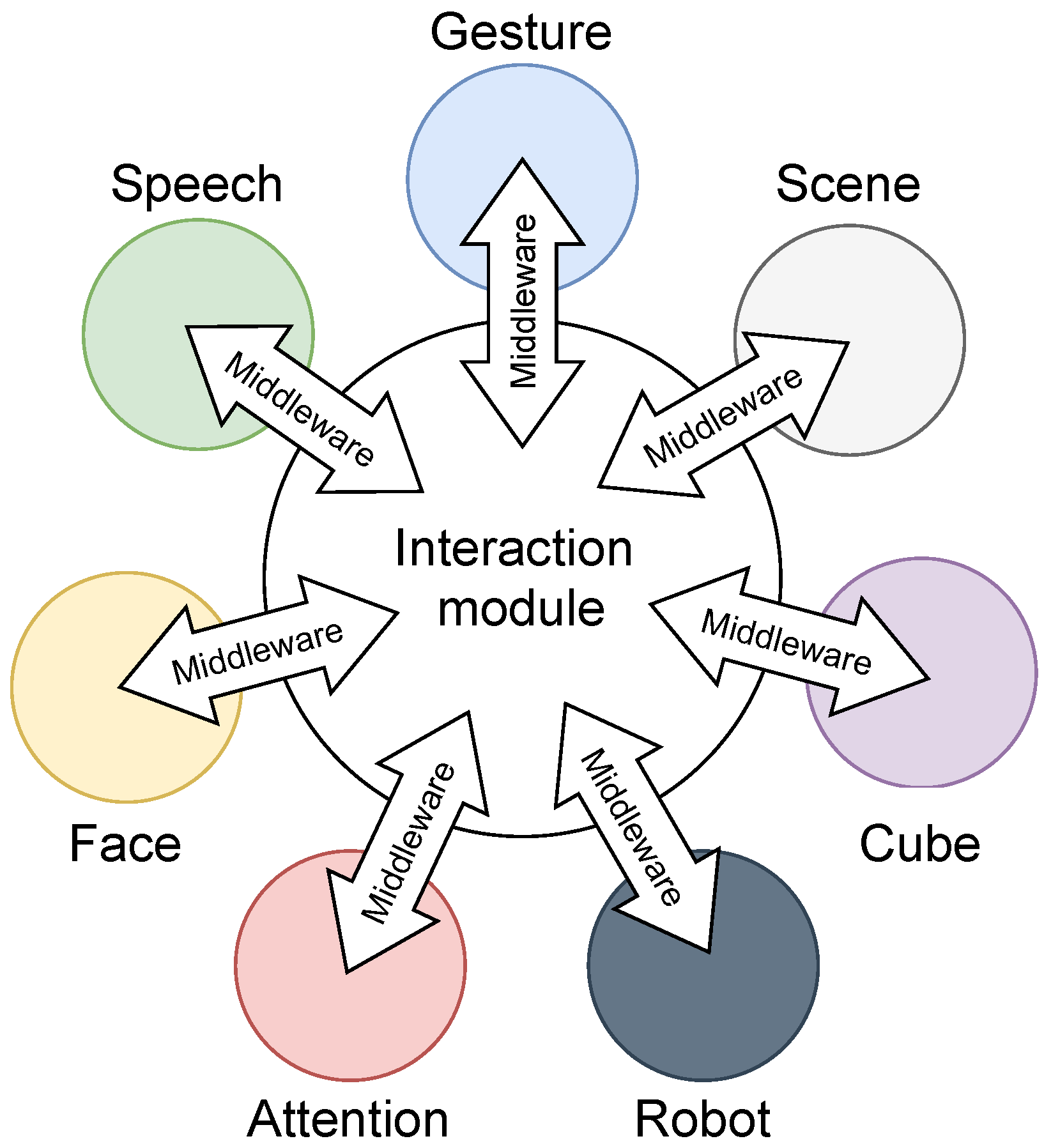
4.2. Middleware
5. Modules
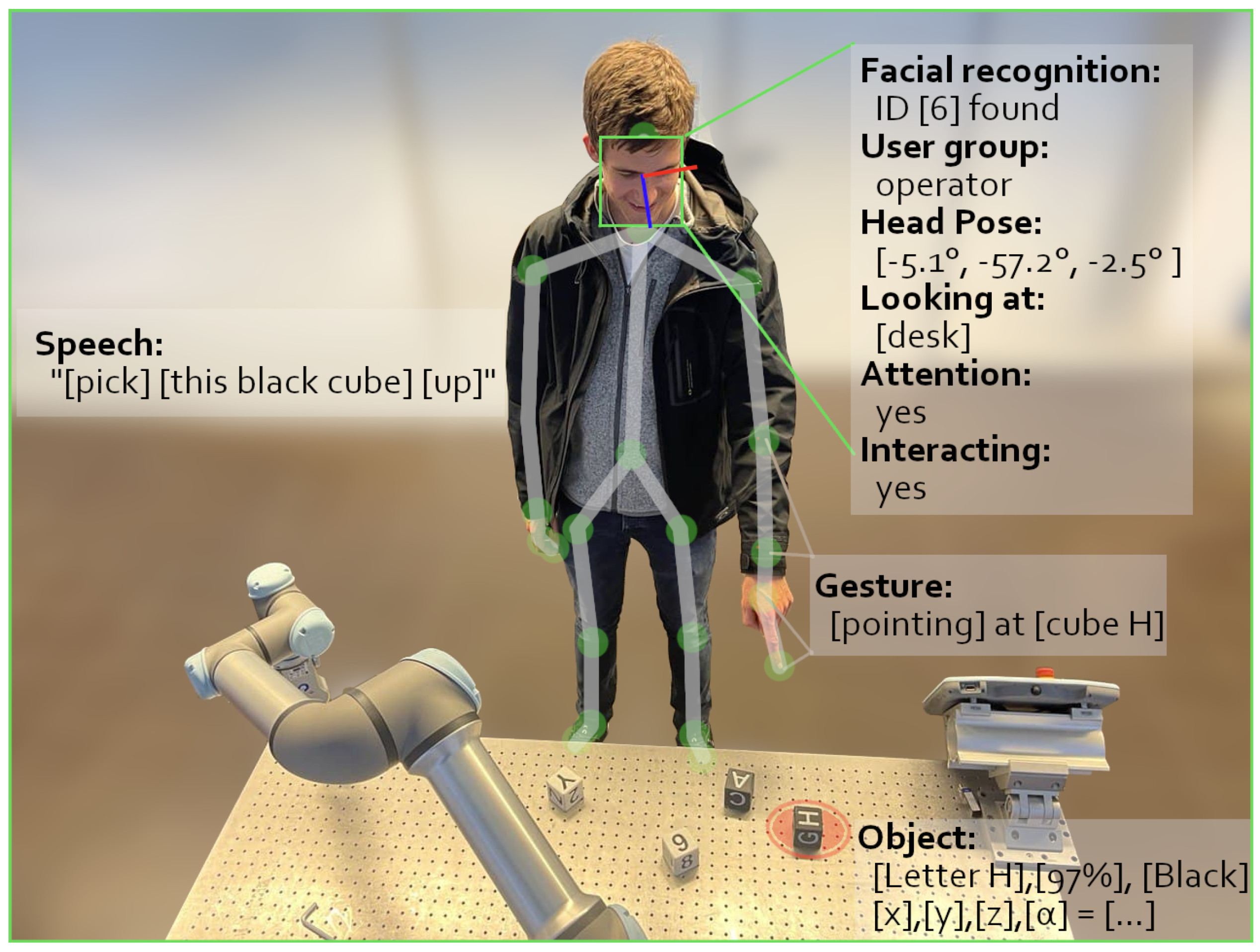
5.1. Scene Module
5.1.1. Skeleton
5.1.2. Spot
5.1.3. Visual Feedback
5.1.4. User
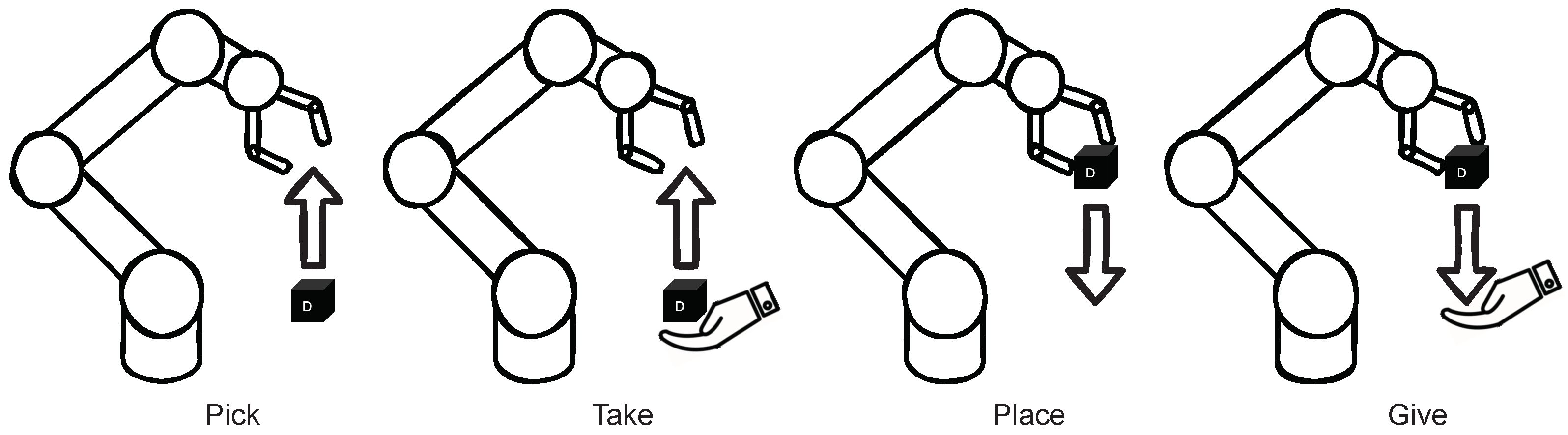
5.2. Robot Module
- Abort: Motion is aborted;
- Home: Robot goes to initial position;
- Sleep: Robot goes to idling position;
- Toggle gripper: Opens or closes the gripper;
- Greet: Robot performs nodding motion.
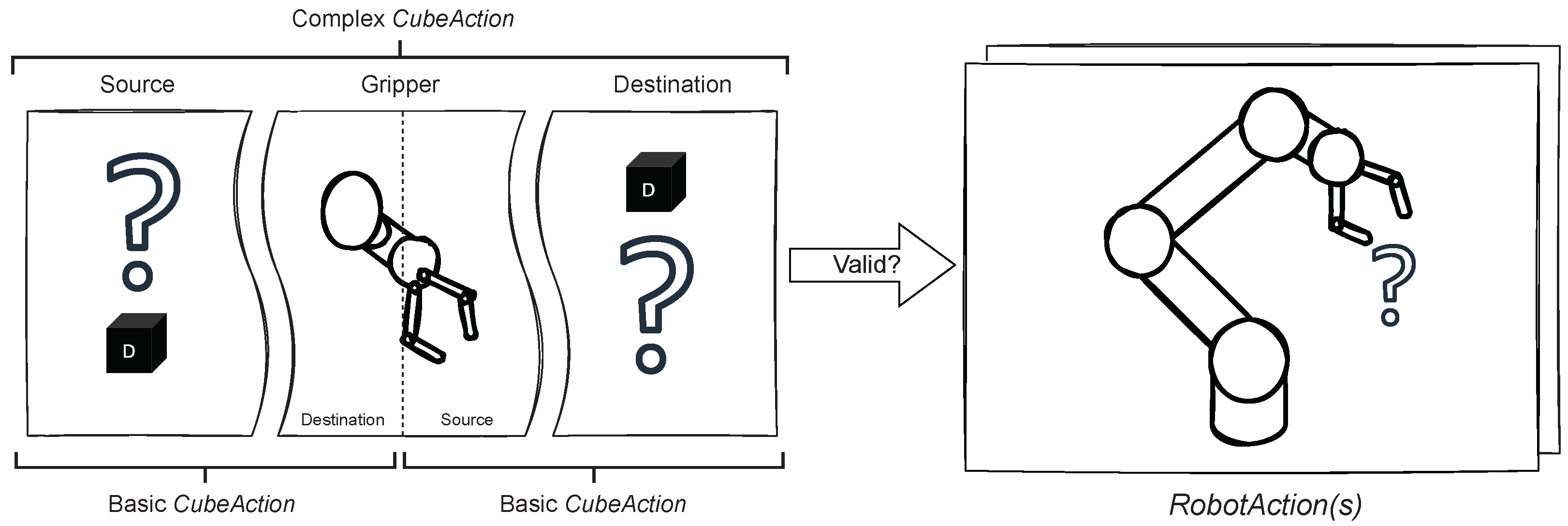
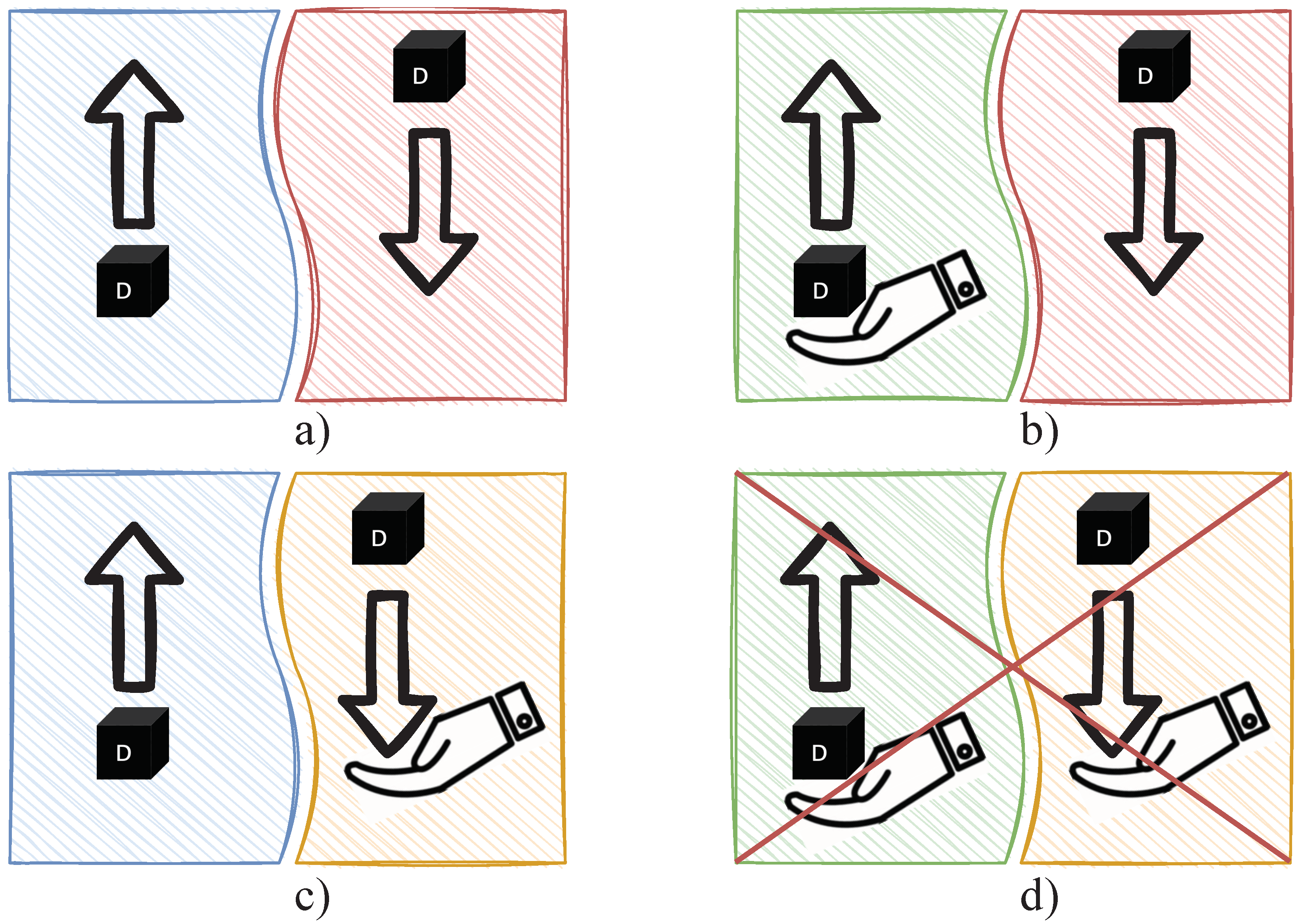
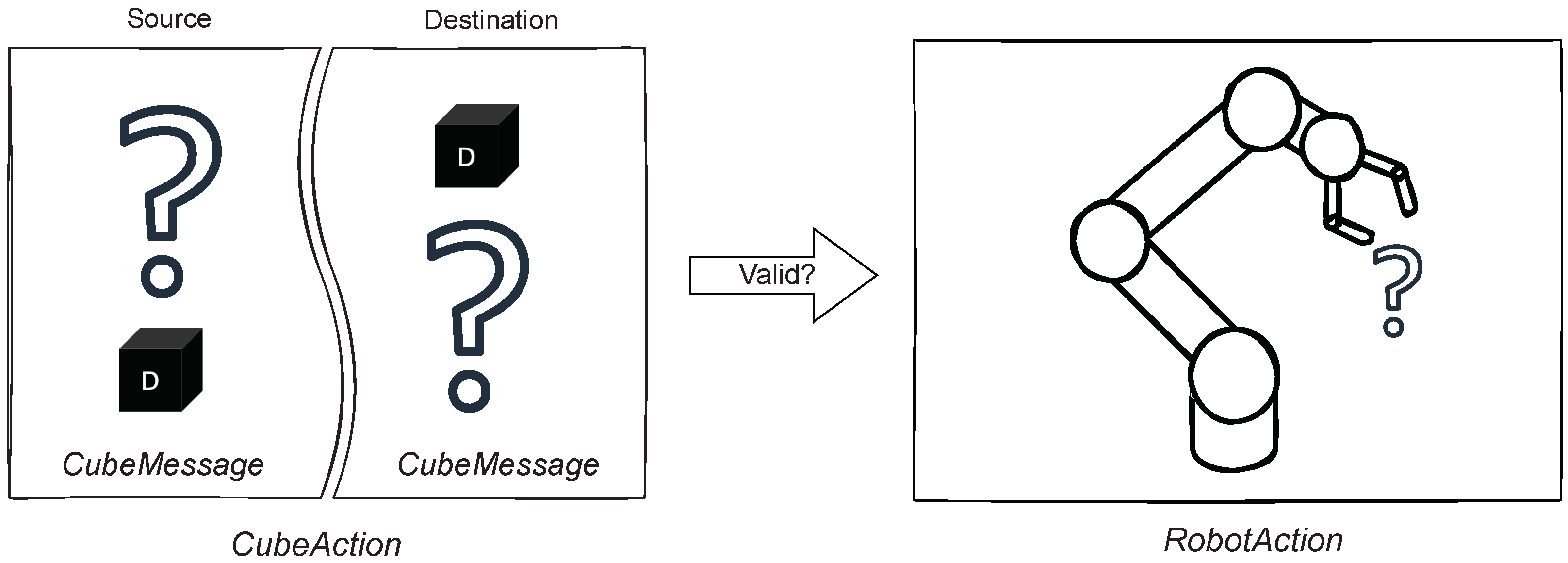
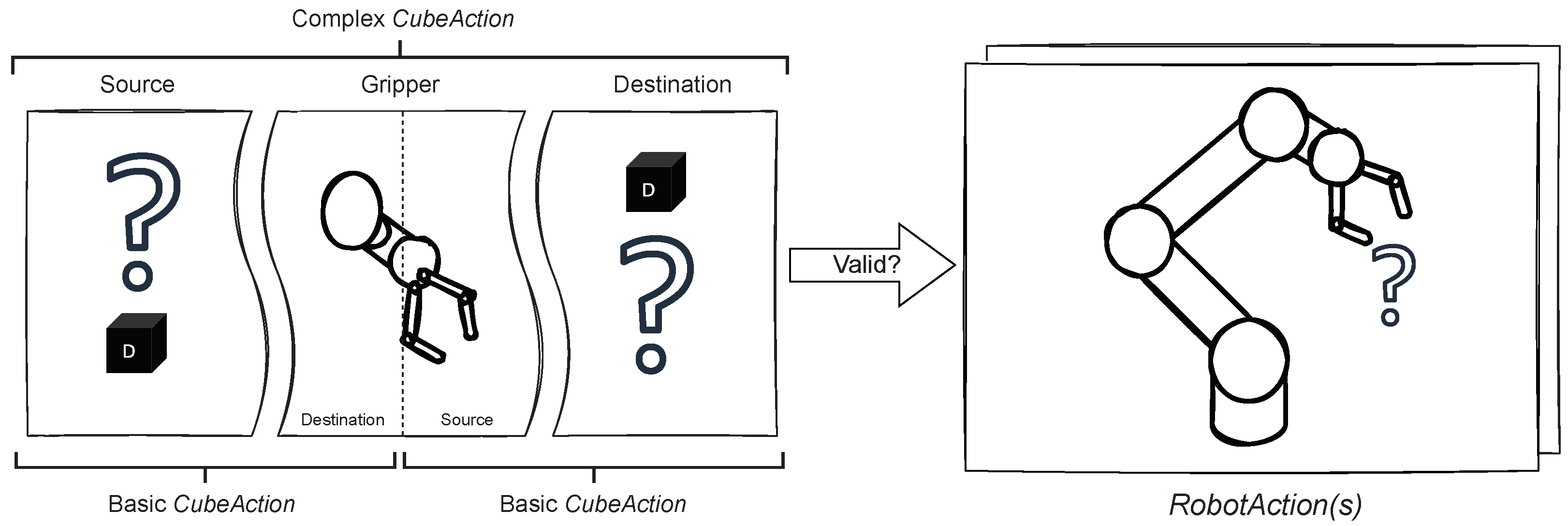
5.3. Cubes Module
5.3.1. Physical Cube
5.3.2. Cube Detection
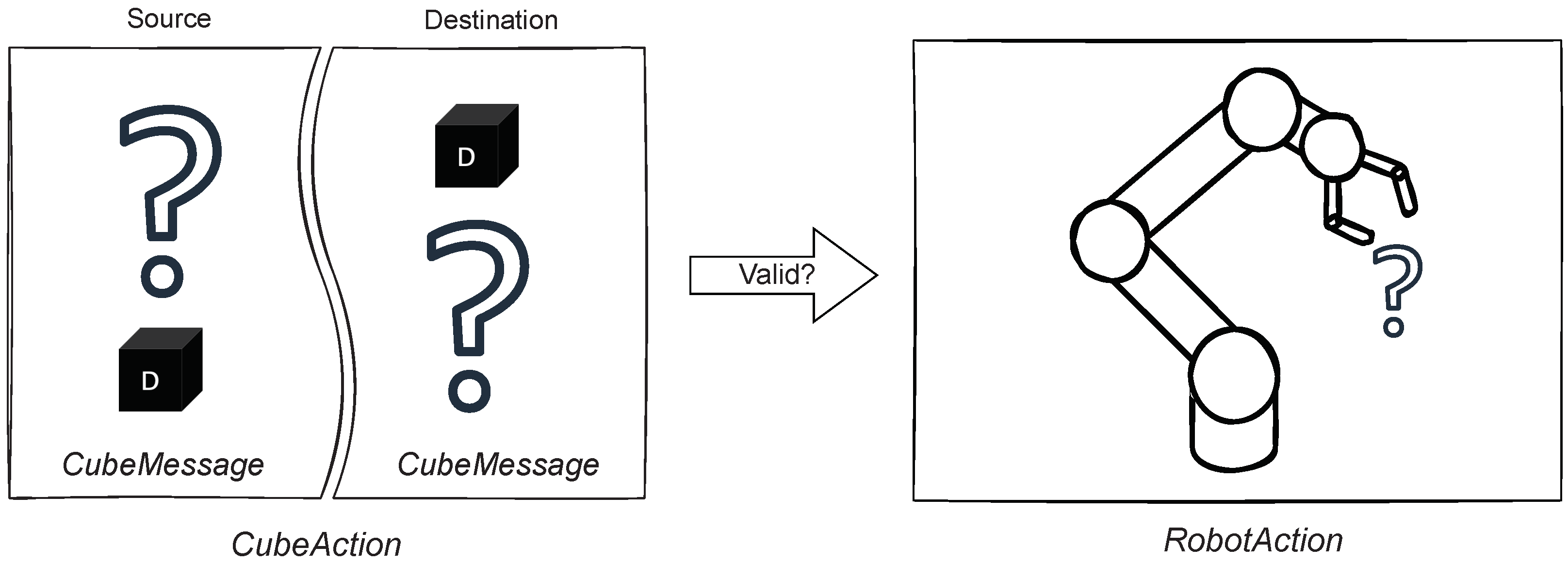
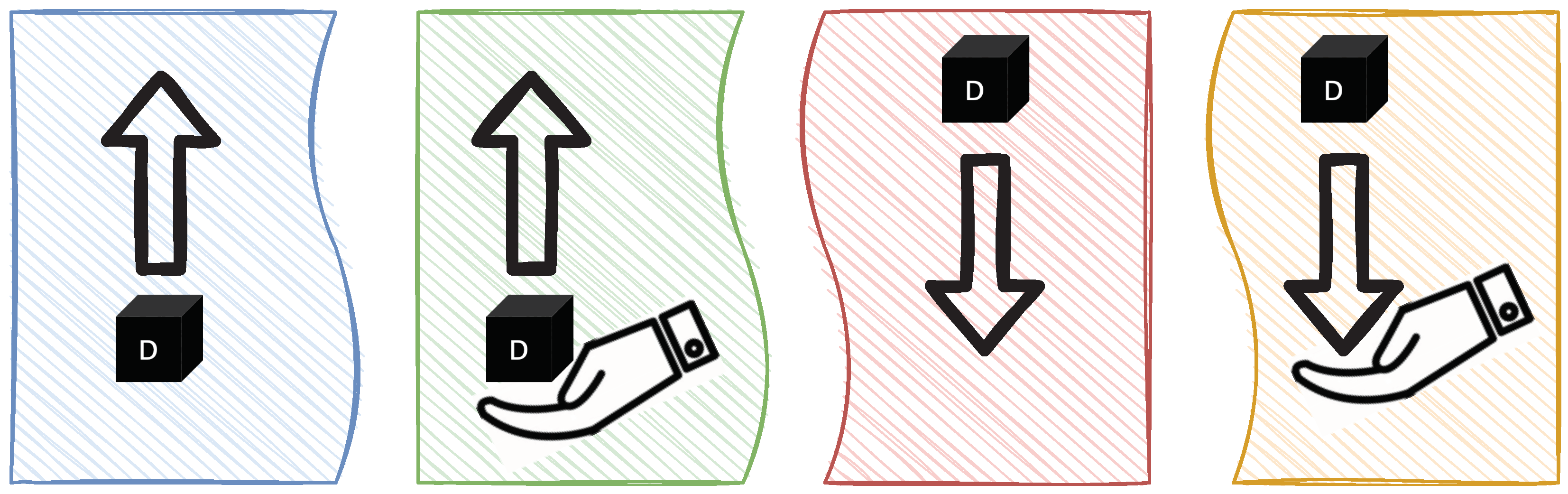
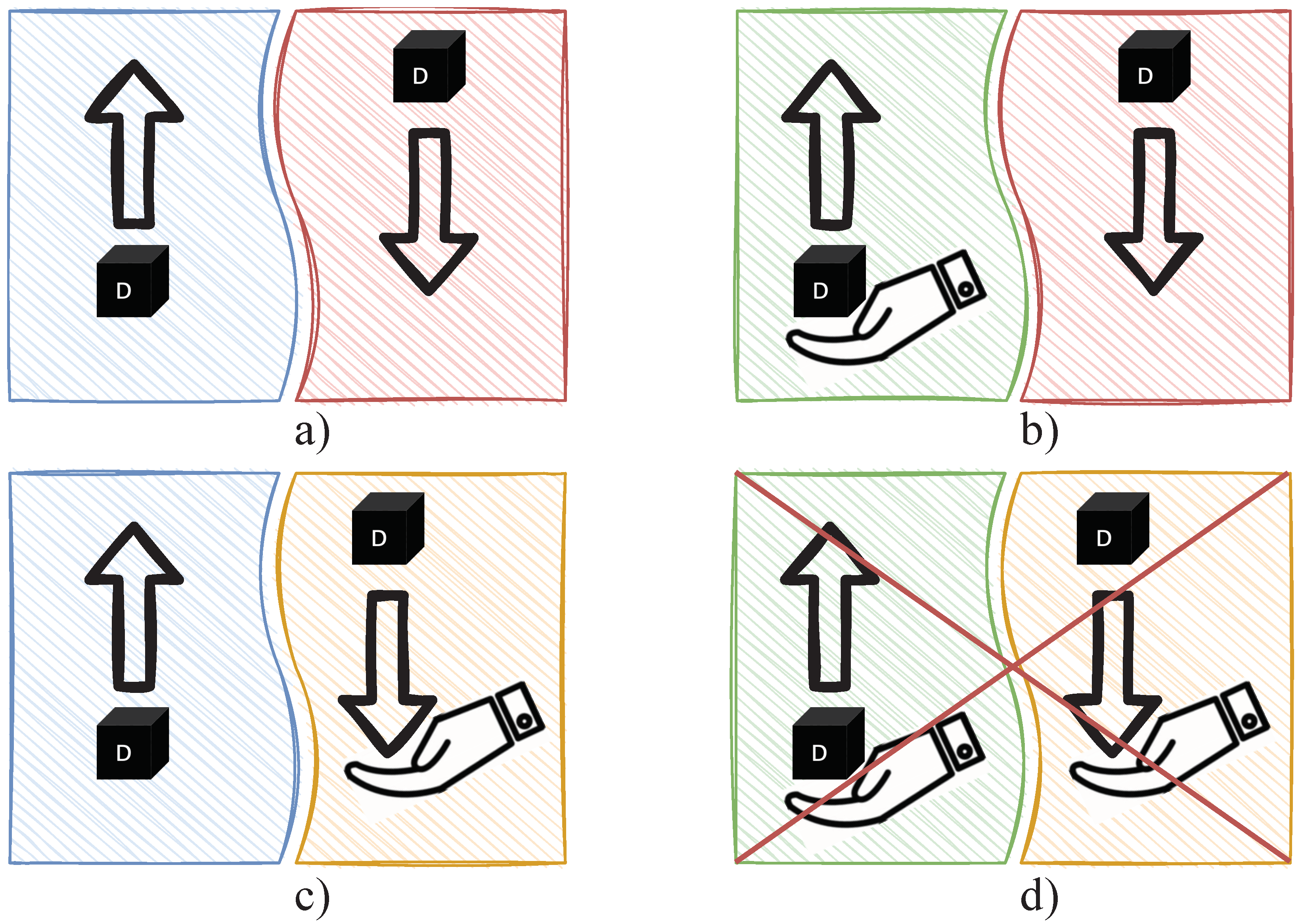
5.3.3. Cube Logic
| Src. | { | letter | [], | color | [], | position | [0,0,-1] | } |
| Dst. | { | letter | [], | color | [], | position | [12,12,1] | }. |
| Src. | { | letter | "A", | color | "black", | position | [4,8,1] | } |
| Dst. | { | letter | "B", | color | [], | position | [6,10,2] | }. |
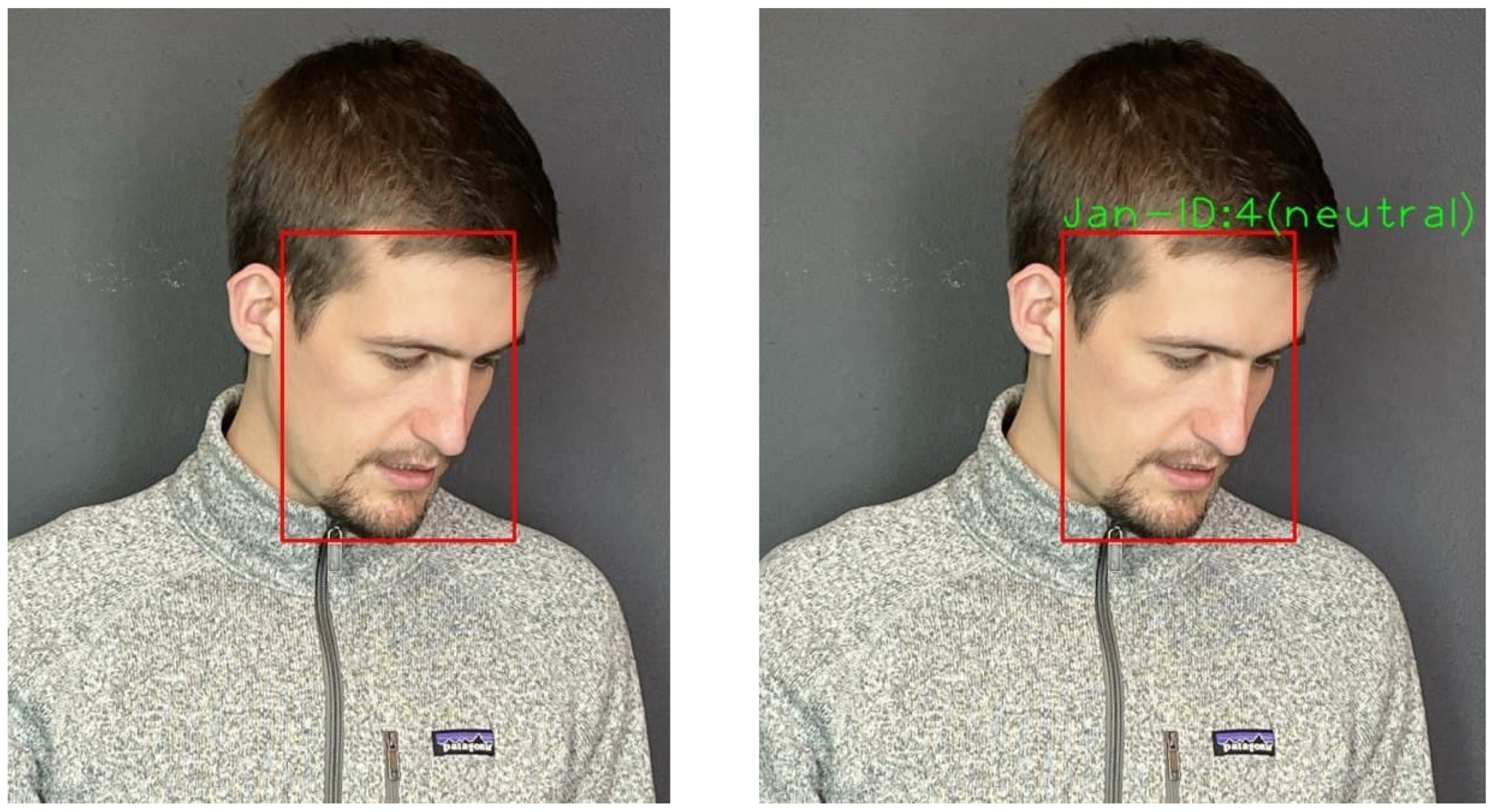
5.4. Face Module
5.4.1. Detection Part
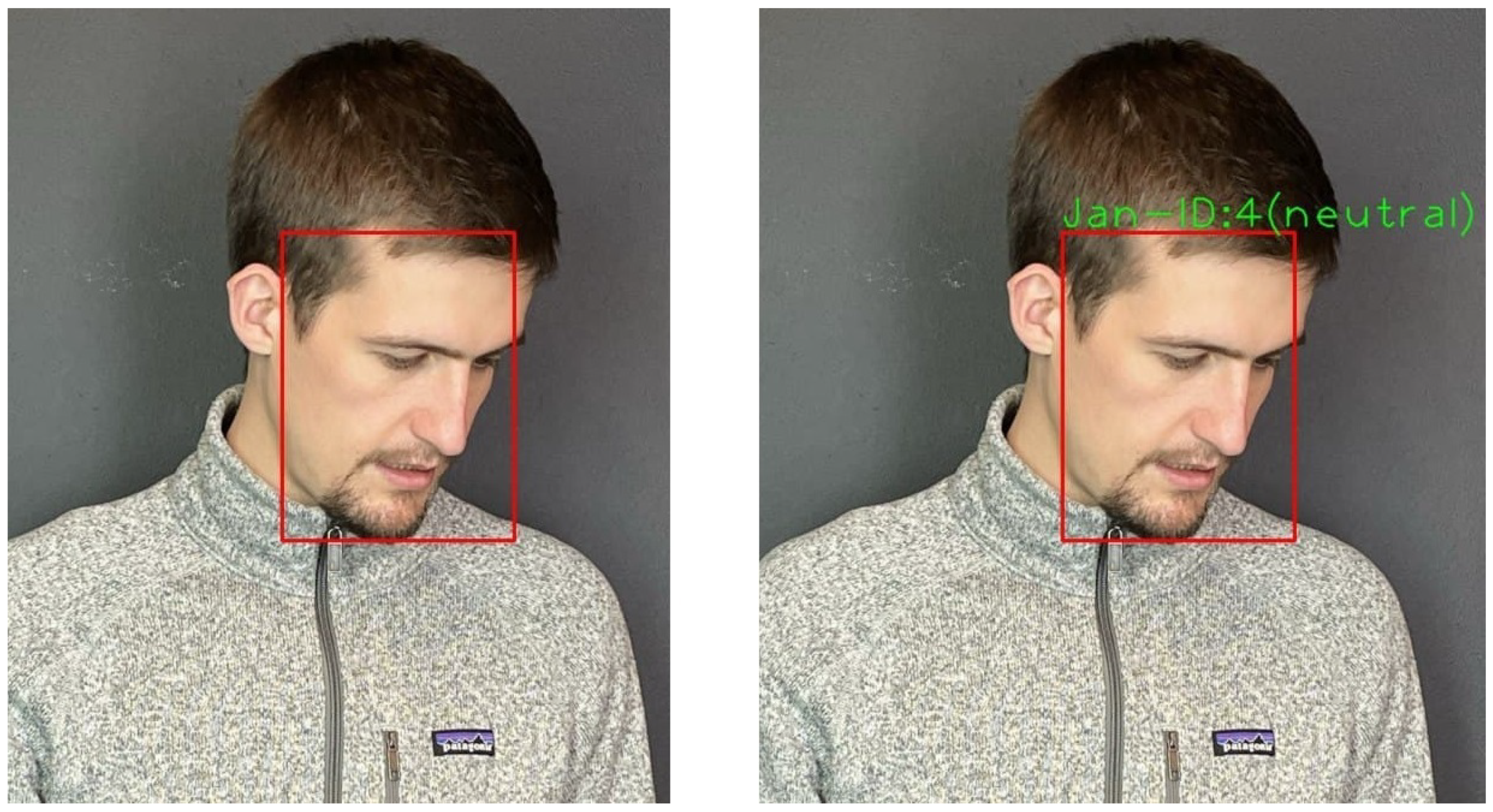
5.4.2. Recognition Part
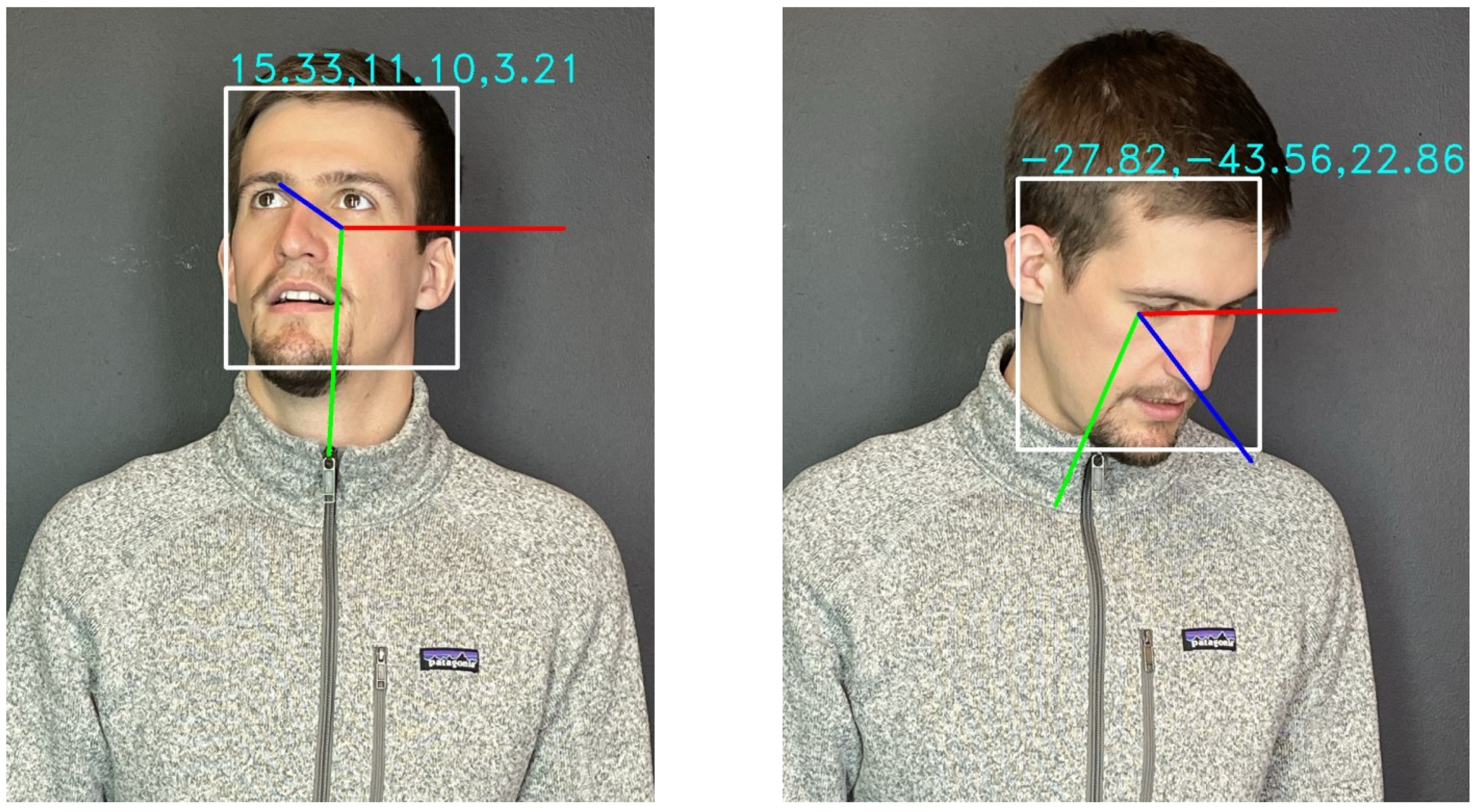
5.5. Attention Module
5.6. Gesture Module
5.7. Speech Module
5.7.1. Wake-Word Detection
5.7.2. Voice Activity Detection (VAD)
5.7.3. Speech-to-Text (STT)
5.7.4. Natural Language Understanding (NLU)
| Src. | { | letter | "A", | color | "white" | position | [] | } |
| Dst. | { | letter | [], | color | [], | position | [0,0,99] | }. |
| Src. | { | letter | "A", | color | "black", | position | [] | } |
| Dst. | { | letter | "spot", | color | [], | position | [] | }. |
| Src. | { | letter | "spot", | color | [], | position | [] | } |
| Dst. | { | letter | [], | color | [], | position | [0,0,99] | }. |
5.7.5. Text-to-Speech (TTS)
- Audio Pitch: Determines the pitch (relative height or depth) of the speech synthesis.
- Include sentence boundary metadata: Determines whether sentence boundary metadata is added to a SpeechSynthesisStream object.
- Punctuation silence: Length of silence added after punctuation in SpeechSynthesis before another utterance begins.
- Speech rate: Sets the tempo, including pauses of the speech synthesis.
5.8. Interaction Module
5.8.1. WS1: Cubes and Cobot
5.8.2. WS2: Registration
6. Experimental Studies
- Informed consent;
- WS2: Registration and collection of sociodemographic data;
- WS1: Collaborative tasks with robot;
- Have RoSA give you a block.
- Spell a specific word with alternating color of blocks.
- Build a 3-2-1-Pyramid with black-white-black layers.
- WS2: Questionnaires;
- WS1: Benchmark: Data collection for module assessment.
7. Results
7.1. Time
7.2. Questionnaires
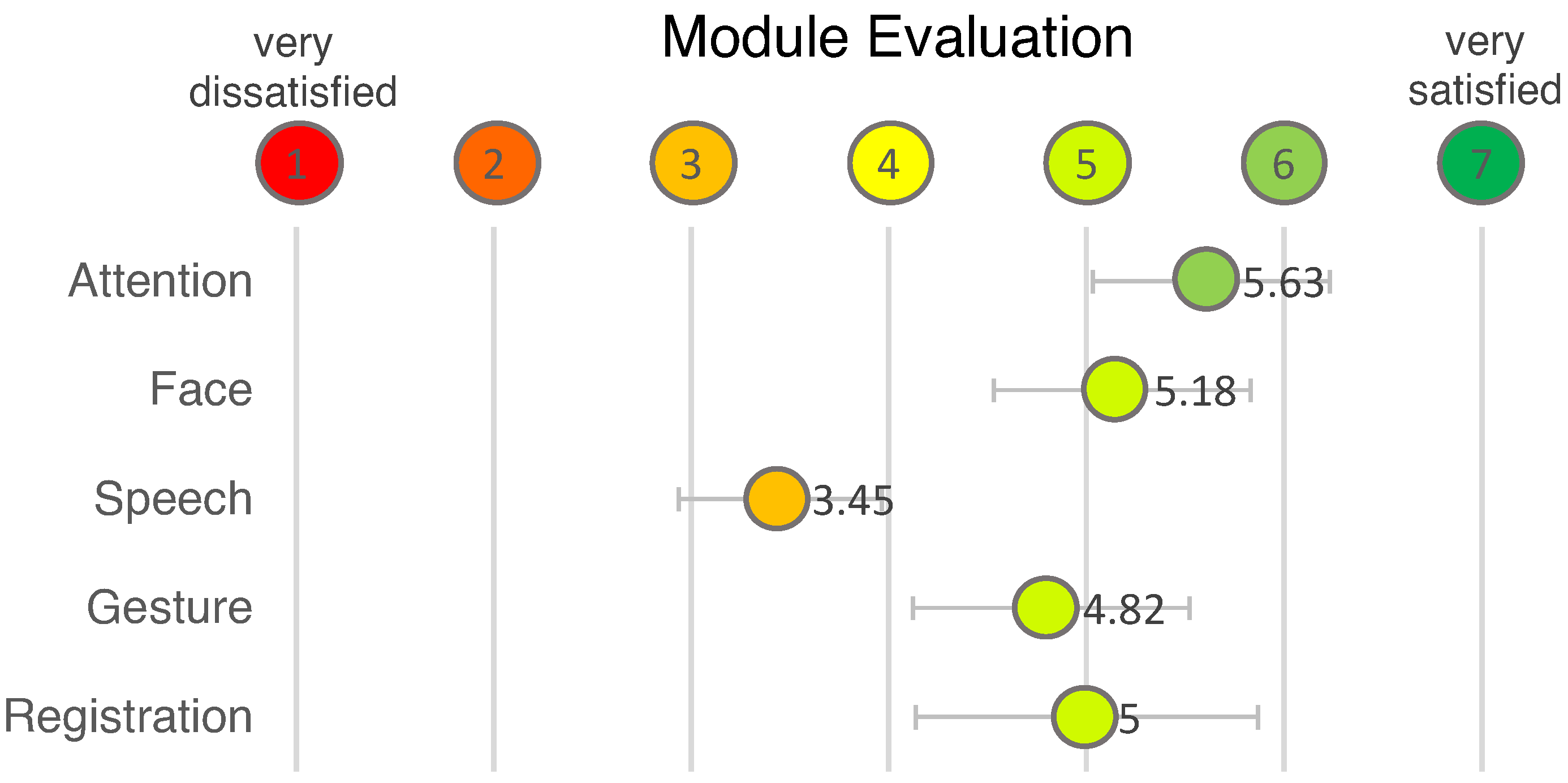
7.3. Modules
7.4. Speech Module Evaluation
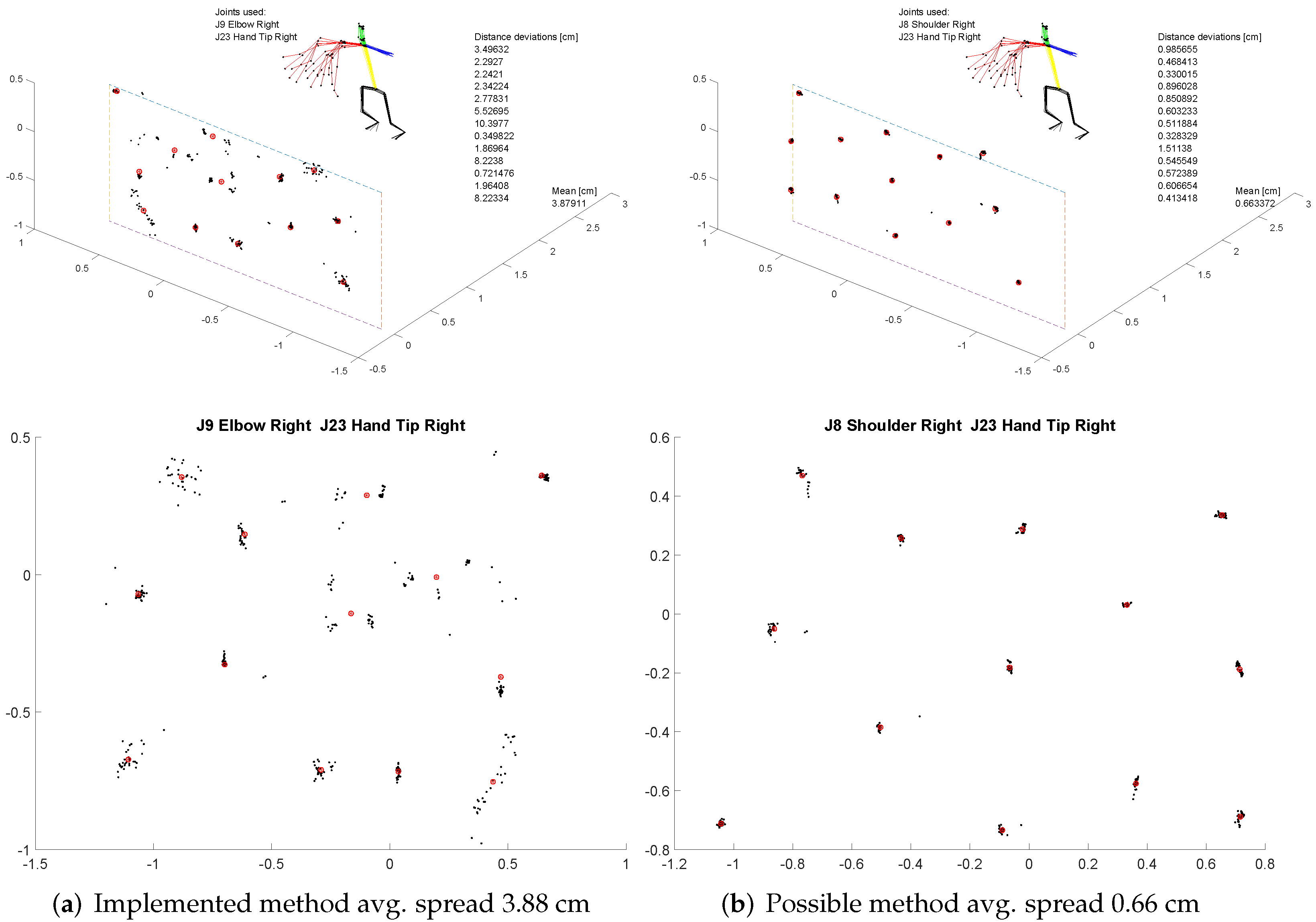
7.5. Gesture Module Evaluation
8. Discussion
8.1. Efficiency
8.2. Usability
8.3. Modules
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Rusch, T.; Ender, H.; Kerber, F. Kollaborative Robotikanwendungen an Montagearbeitsplätzen. HMD Prax. Wirtsch. 2020, 57, 1227–1238. [Google Scholar] [CrossRef]
- Hasnain, S.K.; Mostafaoui, G.; Salesse, R.; Marin, L.; Gaussier, P. Intuitive human robot interaction based on unintentional synchrony: A psycho-experimental study. In Proceedings of the 2013 IEEE Third Joint International Conference on Development and Learning and Epigenetic Robotics (ICDL), Osaka, Japan, 18–22 August 2013; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Reardon, C.M.; Haring, K.S.; Gregory, J.M.; Rogers, J.G. Evaluating Human Understanding of a Mixed Reality Interface for Autonomous Robot-Based Change Detection. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics, SSRR 2021, New York, NY, USA, 25–27 October 2021; pp. 132–137. [Google Scholar] [CrossRef]
- Szafir, D. Mediating Human-Robot Interactions with Virtual, Augmented, and Mixed Reality. In Virtual, Augmented and Mixed Reality. Applications and Case Studies; HCII 2019. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11575. [Google Scholar]
- Al, G.A.; Estrela, P.; Martinez-Hernandez, U. Towards an intuitive human-robot interaction based on hand gesture recognition and proximity sensors. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, Germany, 14–16 September 2020; pp. 330–335. [Google Scholar] [CrossRef]
- Strazdas, D.; Hintz, J.; Felßberg, A.M.; Al-Hamadi, A. Robots and Wizards: An Investigation Into Natural Human–Robot Interaction. IEEE Access 2020, 8, 207635–207642. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO 10218-1:2011 Robots and Robotic Devices—Safety Requirements for Industrial Robots; ISO: Geneva, Switzerland, 2011. [Google Scholar]
- International Organization for Standardization. ISO/TS 15066:2016 Robots and Robotic Devices—Collaborative Robots; ISO: Geneva, Switzerland, 2016. [Google Scholar]
- Pasinetti, S.; Nuzzi, C.; Lancini, M.; Sansoni, G.; Docchio, F.; Fornaser, A. Development and Characterization of a Safety System for Robotic Cells Based on Multiple Time of Flight (TOF) Cameras and Point Cloud Analysis. In Proceedings of the 2018 Workshop on Metrology for Industry 4.0 and IoT, Brescia, Italy, 16–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Strazdas, D.; Hintz, J.; Al-Hamadi, A. Robo-HUD: Interaction Concept for Contactless Operation of Industrial Cobotic Systems. Appl. Sci. 2021, 11, 5366. [Google Scholar] [CrossRef]
- Rogalla, O.; Ehrenmann, M.; Zollner, R.; Becher, R.; Dillmann, R. Using gesture and speech control for commanding a robot assistant. In Proceedings of the 11th IEEE International Workshop on Robot and Human Interactive Communication, Berlin, Germany, 27 September 2002; pp. 454–459. [Google Scholar] [CrossRef]
- Tölgyessy, M.; Dekan, M.; Duchoň, F.; Rodina, J.; Hubinský, P.; Chovanec, L. Foundations of Visual Linear Human–Robot Interaction via Pointing Gesture Navigation. Int. J. Soc. Robot. 2017, 9, 509–523. [Google Scholar] [CrossRef]
- Alvarez-Santos, V.; Iglesias, R.; Pardo, X.M.; Regueiro, C.V.; Canedo-Rodriguez, A. Gesture-based interaction with voice feedback for a tour-guide robot. J. Vis. Commun. Image Represent. 2014, 25, 499–509. [Google Scholar] [CrossRef]
- Fang, H.C.; Ong, S.K.; Nee, A.Y. A novel augmented reality-based interface for robot path planning. Int. J. Interact. Des. Manuf. 2014, 8, 33–42. [Google Scholar] [CrossRef]
- Ong, S.K.; Yew, A.W.; Thanigaivel, N.K.; Nee, A.Y. Augmented reality-assisted robot programming system for industrial applications. Robot. -Comput.-Integr. Manuf. 2020, 61, 101820. [Google Scholar] [CrossRef]
- Gadre, S.Y.; Rosen, E.; Chien, G.; Phillips, E.; Tellex, S.; Konidaris, G. End-user robot programming using mixed reality. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar] [CrossRef]
- Kousi, N.; Stoubos, C.; Gkournelos, C.; Michalos, G.; Makris, S. Enabling human robot interaction in flexible robotic assembly lines: An augmented reality based software suite. Procedia CIRP 2019, 81, 1429–1434. [Google Scholar] [CrossRef]
- Stetco, C.; Muhlbacher-Karrer, S.; Lucchi, M.; Weyrer, M.; Faller, L.M.; Zangl, H. Gesture-based contactless control of mobile manipulators using capacitive sensing. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020. [Google Scholar] [CrossRef]
- Mühlbacher-Karrer, S.; Brandstötter, M.; Schett, D.; Zangl, H. Contactless Control of a Kinematically Redundant Serial Manipulator Using Tomographic Sensors. IEEE Robot. Autom. Lett. 2017, 2, 562–569. [Google Scholar] [CrossRef]
- Magrini, E.; Ferraguti, F.; Ronga, A.J.; Pini, F.; De Luca, A.; Leali, F. Human-robot coexistence and interaction in open industrial cells. Robot. -Comput.-Integr. Manuf. 2020, 61, 1–55. [Google Scholar] [CrossRef]
- Irfan, B.; Lyubova, N.; Garcia Ortiz, M.; Belpaeme, T. Multi-modal open-set person identification in hri. In Proceedings of the 2018 ACM/IEEE International Conference on Human-Robot Interaction Social, Chicago, IL, USA, 5–8 March 2018. [Google Scholar]
- Strazdas, D.; Hintz, J.; Khalifa, A.; Al-Hamadi, A. Robot System Assistant (RoSA): Concept for an intuitive multi-modal and multi-device interaction system. In Proceedings of the 2021 IEEE 2nd International Conference on Human-Machine Systems (ICHMS), Magdeburg, Germany, 8–10 September 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Luan, P.; Huynh, V.; Tuan Anh, T. Facial Expression Recognition using Residual Masking Network. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4513–4519. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]
- Picovoice. Porcupine. 2020. Available online: https://github.com/Picovoice/porcupine (accessed on 22 December 2021).
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deepspeech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Google. WebRTC. 2020. Available online: https://webrtc.org (accessed on 22 December 2021).
- RASA. RASA. 2020. Available online: https://rasa.com/open-source/ (accessed on 22 December 2021).
- Hempel, T. RoSA: Cube Detector. 2021. Available online: https://github.com/thohemp/cube_detector/tree/v1.0.0 (accessed on 17 December 2021). [CrossRef]
- Strazdas, D.; Khalifa, A.; Hempel, T. DoStraTech/rosa_msgs: Initial Release. 2021. Available online: https://github.com/DoStraTech/rosa_msgs/tree/v0.1-alpha (accessed on 15 December 2021). [CrossRef]
- Bramel, J. Alphabet Play Blocks. Available online: https://www.thingiverse.com/thing:2368270 (accessed on 22 December 2021).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Guo, X.; Li, S.; Yu, J.; Zhang, J.; Ma, J.; Ma, L.; Liu, W.; Ling, H. PFLD: A practical facial landmark detector. arXiv 2019, arXiv:1902.10859. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. In Chinese Conference on Biometric Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 428–438. [Google Scholar]
- Foster, M.E.; Gaschler, A.; Giuliani, M. Automatically Classifying User Engagement for Dynamic Multi-party Human–Robot Interaction. Int. J. Soc. Robot. 2017, 9, 659–674. [Google Scholar] [CrossRef] [Green Version]
- Vaufreydaz, D.; Johal, W.; Combe, C. Starting engagement detection towards a companion robot using multimodal features. Robot. Auton. Syst. 2016, 75, 4–16. [Google Scholar] [CrossRef] [Green Version]
- Anzalone, S.M.; Boucenna, S.; Ivaldi, S.; Chetouani, M. Evaluating the engagement with social robots. Int. J. Soc. Robot. 2015, 7, 465–478. [Google Scholar] [CrossRef]
- Li, L.; Xu, Q.; Tan, Y.K. Attention-based addressee selection for service and social robots to interact with multiple persons. In Proceedings of the Workshop at SIGGRAPH Asia; Association for Computing Machinery: New York, NY, USA, 2012; pp. 131–136. [Google Scholar]
- Richter, V.; Carlmeyer, B.; Lier, F.; Meyer zu Borgsen, S.; Schlangen, D.; Kummert, F.; Wachsmuth, S.; Wrede, B. Are you talking to me? Improving the robustness of dialogue systems in a multi party HRI scenario by incorporating gaze direction and lip movement of attendees. In Proceedings of the Fourth International Conference on Human Agent Interaction, Biopolis, Singapore, 4–7 October 2016; pp. 43–50. [Google Scholar]
- Ellgring, J.H. Nonverbale Kommunikation; Universität Würzburg: Würzburg, Germany, 1986. [Google Scholar]
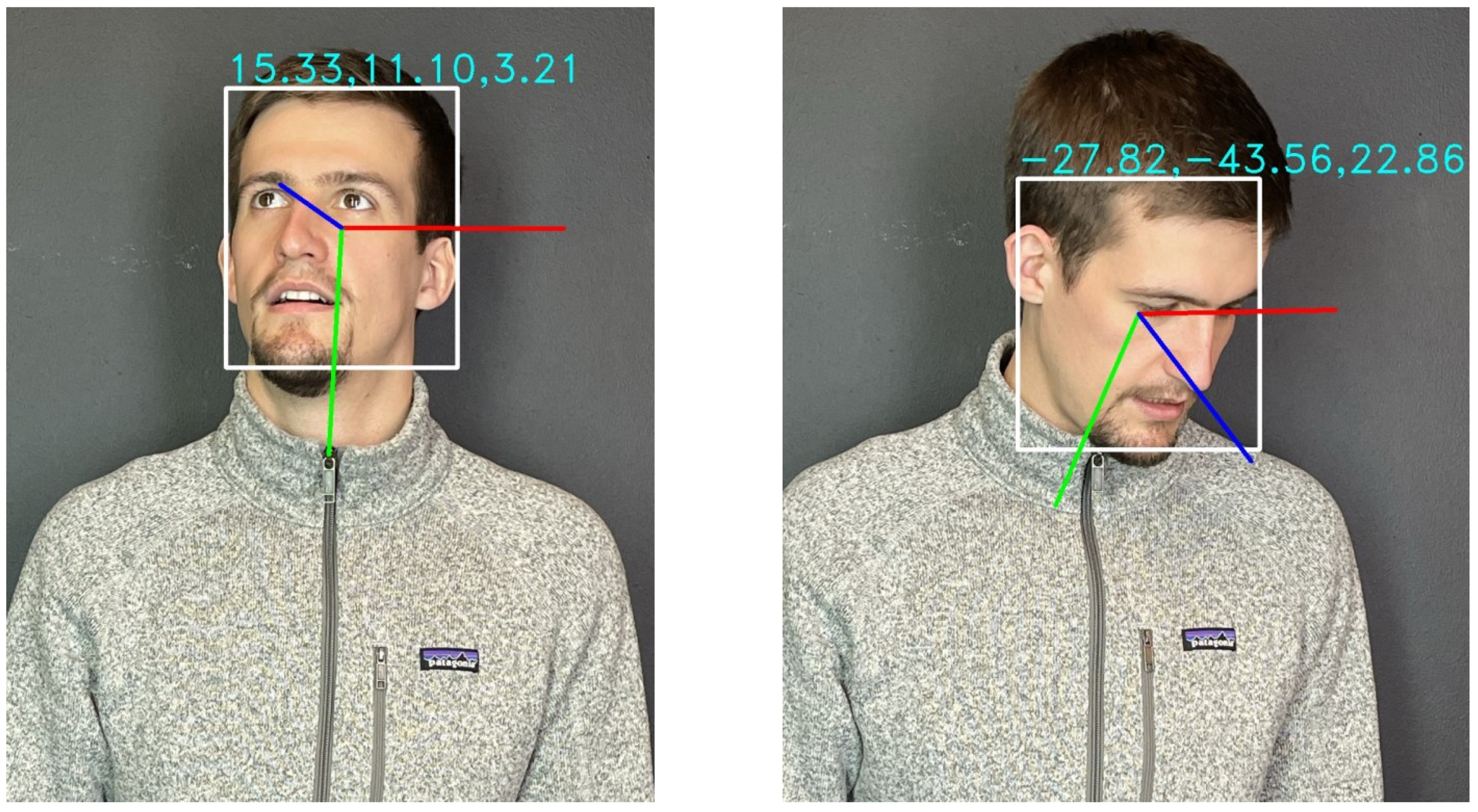
- Murphy-Chutorian, E.; Trivedi, M.M. Head pose estimation in computer vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 607–626. [Google Scholar] [CrossRef]
- Albiero, V.; Chen, X.; Yin, X.; Pang, G.; Hassner, T. img2pose: Face alignment and detection via 6dof, face pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7617–7627. [Google Scholar]
- Kellnhofer, P.; Recasens, A.; Stent, S.; Matusik, W.; Torralba, A. Gaze360: Physically unconstrained gaze estimation in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6912–6921. [Google Scholar]
- Williams, T.; Hirshfield, L.; Tran, N.; Grant, T.; Woodward, N. Using augmented reality to better study human-robot interaction. In International Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2020; pp. 643–654. [Google Scholar]
- Haeb-Umbach, R.; Watanabe, S.; Nakatani, T.; Bacchiani, M.; Hoffmeister, B.; Seltzer, M.L.; Zen, H.; Souden, M. Speech Processing for Digital Home Assistants: Combining Signal Processing with Deep-Learning Techniques. IEEE Signal Process. Mag. 2019, 36, 111–124. [Google Scholar] [CrossRef]
- Ramirez, J.; Górriz, J.M.; Segura, J.C. Voice activity detection. fundamentals and speech recognition system robustness. Robust Speech Recognit. Underst. 2007, 6, 1–22. [Google Scholar]
- Mozzilla. Deepspeech. 2020. Available online: https://github.com/mozilla/DeepSpeech (accessed on 22 December 2021).
- Agarwal, A.; Zesch, T. German End-to-end Speech Recognition based on DeepSpeech. In Preliminary Proceedings of the 15th Conference on Natural Language Processing (KONVENS 2019): Long Papers; German Society for Computational Linguistics & Language Technology: Erlangen, Germany, 2019; pp. 111–119. [Google Scholar]
- Schurick, J.M.; Williges, B.H.; Maynard, J.F. User feedback requirements with automatic speech recognition. Ergonomics 1985, 28, 1543–1555. [Google Scholar] [CrossRef]
- Bocklisch, T.; Faulkner, J.; Pawlowski, N.; Nichol, A. Rasa: Open source language understanding and dialogue management. arXiv 2017, arXiv:1712.05181. [Google Scholar]
- Braun, D.; Hernandez Mendez, A.; Matthes, F.; Langen, M. Evaluating Natural Language Understanding Services for Conversational Question Answering Systems. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue; Association for Computational Linguistics: Saarbrücken, Germany, 2017; pp. 174–185. [Google Scholar] [CrossRef] [Green Version]
- Microsoft. Speechsynthesis. 2020. Available online: https://docs.microsoft.com/de-de/uwp/api/windows.media.speechsynthesis (accessed on 22 December 2021).
- Brooke, J. SUS: A quick and dirty usability scale. Usability Eval. Ind. 1995, 189, 4–7. [Google Scholar]
- Finstad, K. The usability metric for user experience. Interact. Comput. 2010, 22, 323–327. [Google Scholar] [CrossRef]
- Lewis, J.R. Psychometric Evaluation of the PSSUQ Using Data from Five Years of Usability Studies. Int. J. -Hum.-Comput. Interact. 2002, 14, 463–488. [Google Scholar] [CrossRef]
- Lewis, J. Psychometric evaluation of an after-scenario questionnaire for computer usability studies: The ASQ. SIGCHI Bull. 1991, 23, 78–81. [Google Scholar] [CrossRef]
- Malik, M.; Muhammad, K.; Mehmood, K.; Makhdoom, I. Automatic speech recognition: A survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stream | Feature | Description | Methods |
|---|---|---|---|
| Face | Face embedding Facial expression Face box Face center Facial landmark No. detected faces Face Id | 512 features 7 features 4 features for each (in pixels) 1 features for each (in pixels) 5 features for each (in pixels) 1 feature 1 feature | ArcFace [23] Residual Masking Network [24] RetinaFace [25] post processed RetinaFace [25] post processed post processed (cosine similarity) |
| Head | Head angles | 3 features [yaw, pitch, roll] (in degrees) | Im2pose [25] |
| Gaze | Gaze direction Attention visual | 2 features [yaw, pitch] (in degrees) 1 feature | Gaze360 [25] post processed |
| Speech | Wakeword Voice Activity Detection Speech-to-text Natural Language Processing | 1 feature 1 feature n features ∈“spoken text” 2 features ∈ [intent, entity] | Piccovoice [26] Deepspeech [27] WebRCT [28] RASA [29] |
| Distance | 3D head position Face distance | 3 features [x, y, z] 1 feature (in meter) | post processing using kinect post processed |
| Gesture | Hand Pose | 4 Features (Open, Closed, Finger, None) | Kinect for Windows SDK 2.0 |
| Body | Body Joints | 26 Features [x, y, z] | Kinect for Windows SDK 2.0 |
| Object | Cube Location | 4 Features (Letter, Color, Bounding Box, Angle) | CubeDetector [30] |
| Variables | Fastest | Slowest | Mean |
|---|---|---|---|
| Task 1 | 00:00:16 | 00:04:30 | 00:01:21 |
| Task 2 | 00:02:51 | 00:26:36 | 00:12:56 |
| Task 3 | 00:02:36 | 00:36:39 | 00:11:06 |
| Total | 00:06:07 | 01:07:24 | 00:25:20 |
| Variablen | SUS [55] | UMUX [56] | PSSUQ [57] | ASQ [58] |
|---|---|---|---|---|
| Answer Range | 1–5 | 1–7 | 1–7, NA | 1–7, NA |
| Score Range | 0–100 | 0–100 | 1–7 | 1–7 |
| No. of Questions | 10 | 4 | 16 | 3 |
| Normalized Score | 72.27 | 57.57 | 62.90 | 64.06 |
| Total Avg. Score: 64.2 | ||||
| Variables | Task 1 | Task 2 | Task 3 | Total |
|---|---|---|---|---|
| Results | 00:01:21 | 00:12:56 | 00:11:06 | 00:25:20 |
| WoZ study [6] | 00:01:46 | 00:07:57 | 00:09:52 | 00:19:35 |
| Deviation | 00:00:25 | −00:04:59 | −00:01:08 | −00:05:45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strazdas, D.; Hintz, J.; Khalifa, A.; Abdelrahman, A.A.; Hempel, T.; Al-Hamadi, A. Robot System Assistant (RoSA): Towards Intuitive Multi-Modal and Multi-Device Human-Robot Interaction. Sensors 2022, 22, 923. https://doi.org/10.3390/s22030923
Strazdas D, Hintz J, Khalifa A, Abdelrahman AA, Hempel T, Al-Hamadi A. Robot System Assistant (RoSA): Towards Intuitive Multi-Modal and Multi-Device Human-Robot Interaction. Sensors. 2022; 22(3):923. https://doi.org/10.3390/s22030923
Chicago/Turabian StyleStrazdas, Dominykas, Jan Hintz, Aly Khalifa, Ahmed A. Abdelrahman, Thorsten Hempel, and Ayoub Al-Hamadi. 2022. "Robot System Assistant (RoSA): Towards Intuitive Multi-Modal and Multi-Device Human-Robot Interaction" Sensors 22, no. 3: 923. https://doi.org/10.3390/s22030923
APA StyleStrazdas, D., Hintz, J., Khalifa, A., Abdelrahman, A. A., Hempel, T., & Al-Hamadi, A. (2022). Robot System Assistant (RoSA): Towards Intuitive Multi-Modal and Multi-Device Human-Robot Interaction. Sensors, 22(3), 923. https://doi.org/10.3390/s22030923