
Color-Dense Illumination Adjustment Network for Removing Haze and Smoke from Fire Scenario Images




Abstract
:1. Introduction
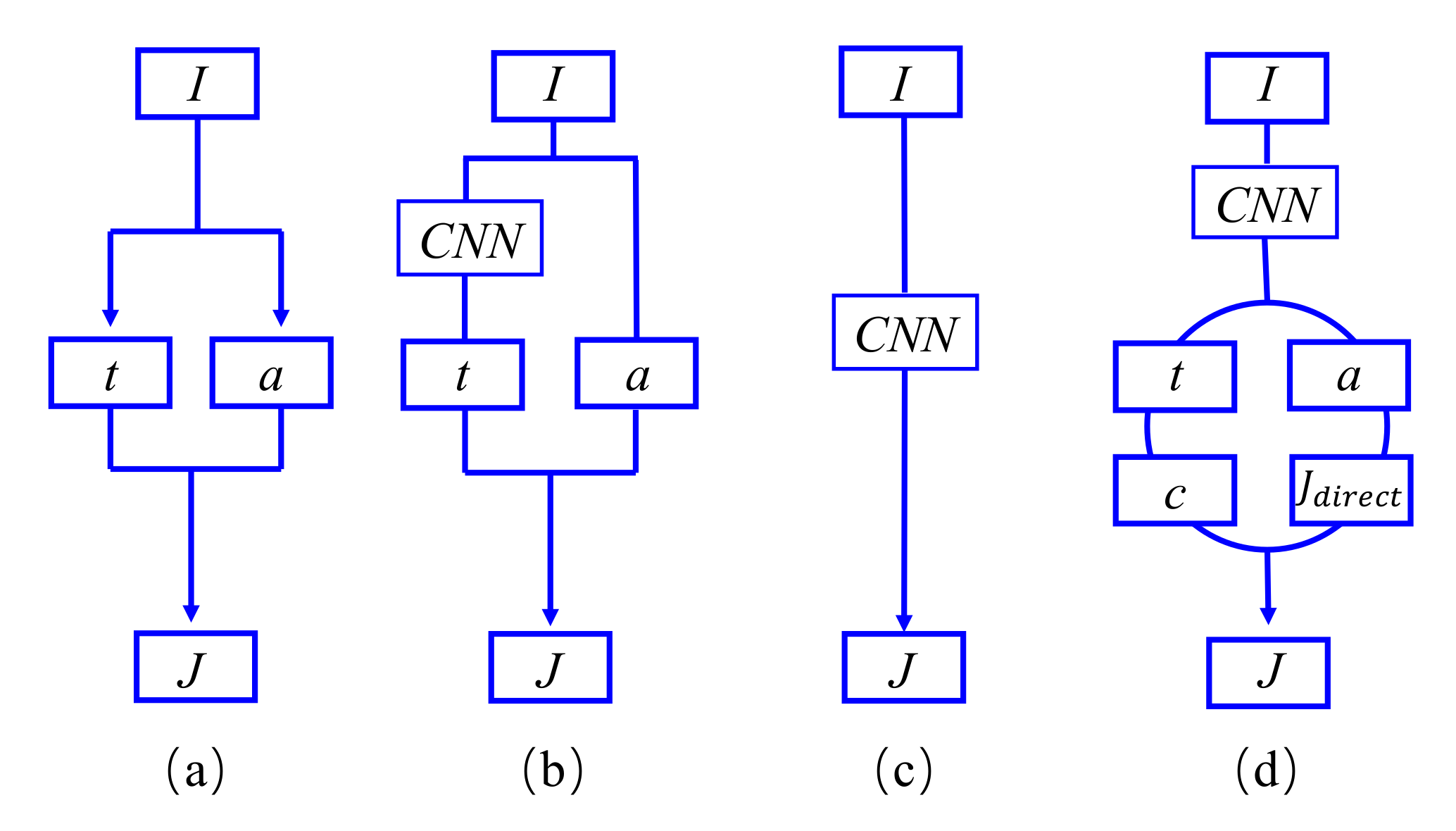
- This paper proposes a novel learning-based dehazing model to improve the quality of images captured from fire scenarios, built with CNN and a physical imaging model. Combining the modern learning-based strategy with a traditional ASM makes the proposed model handle various hazy images in the fire scenarios without incurring additional parameters and computational burden.
- To improve the effect of image dehazing, we improve the existing ASM and propose a new ASM called the aerosol scattering model (ESM). The ESM uses brightness, color, and the transmission information of the images and can generate a more realistic images without causing over enhancement.
- We conducted extensive experiments on multiple datasets, and experiments show that the proposed CIANet achieves better performance quantitatively and qualitatively. The detailed analysis and experiments show the limitation of the classical dehazing algorithms in fire scenarios. Moreover, the insights from the experimental results confirm what is useful in more complex scenarios and suggest new research directions in image enhancement and image dehazing.
2. Related Works
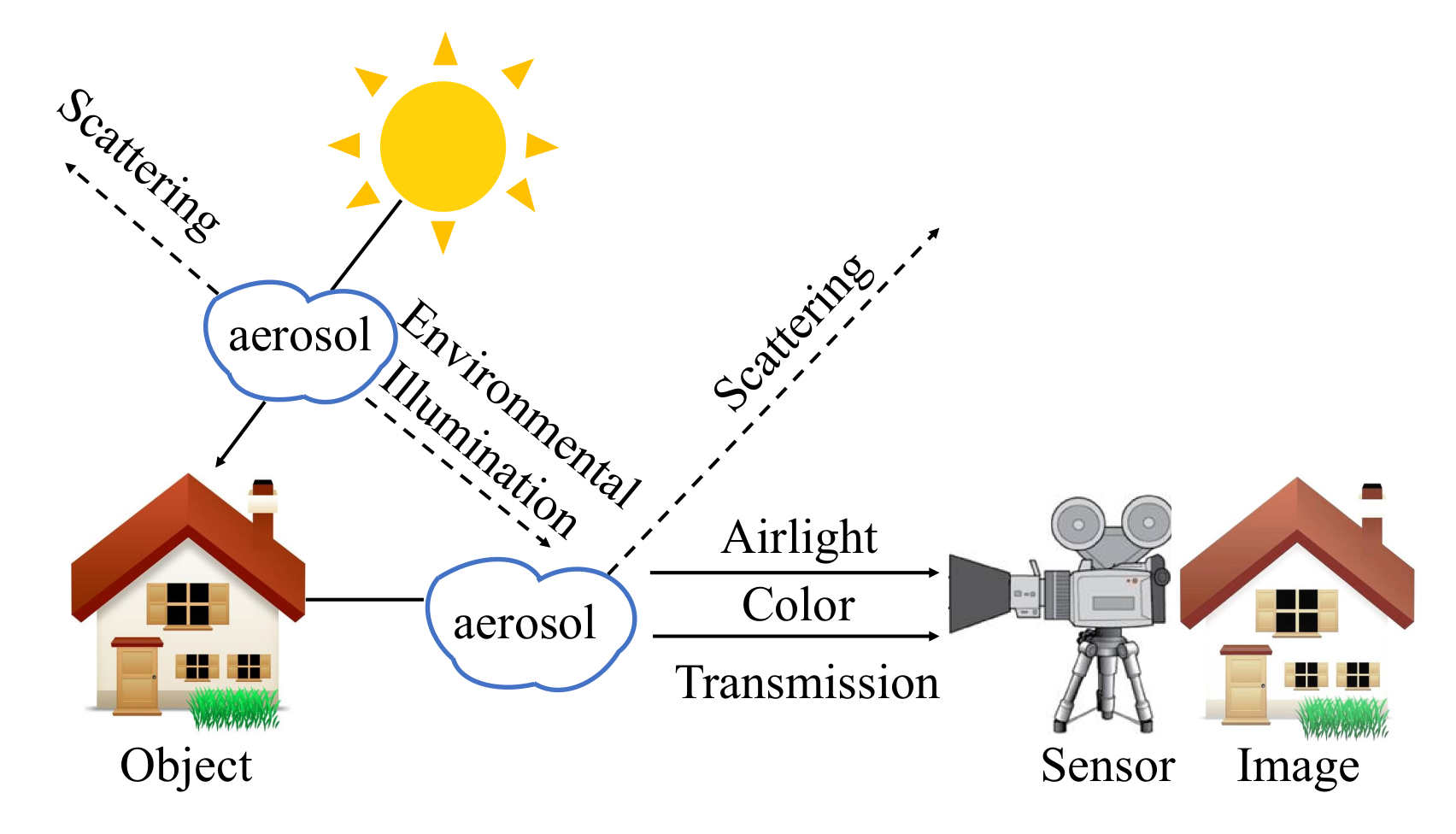
2.1. Atmospheric Scattering Model
2.2. Prior-Based Methods
2.3. Learning-Based Methods
- The image dehazing task can be viewed as a case of the decomposing images into clear layer and haze layer [35]. In the traditional ASM [27], the haze layer color is white by default, so many classical prior-based methods, such as [31], fail on white objects [2]. Therefore, it is necessary to improve the atmospheric model for adapting the different haze scenarios.
- The haze-free images obtained by Equation (4) has obvious defects when the value of atmospheric light received by the prior-based methods and the transmission maps obtained by the learning-based methods are used, due to they fail to cooperate with each other when two independent systems calculate two separate projects.
3. Proposed Method
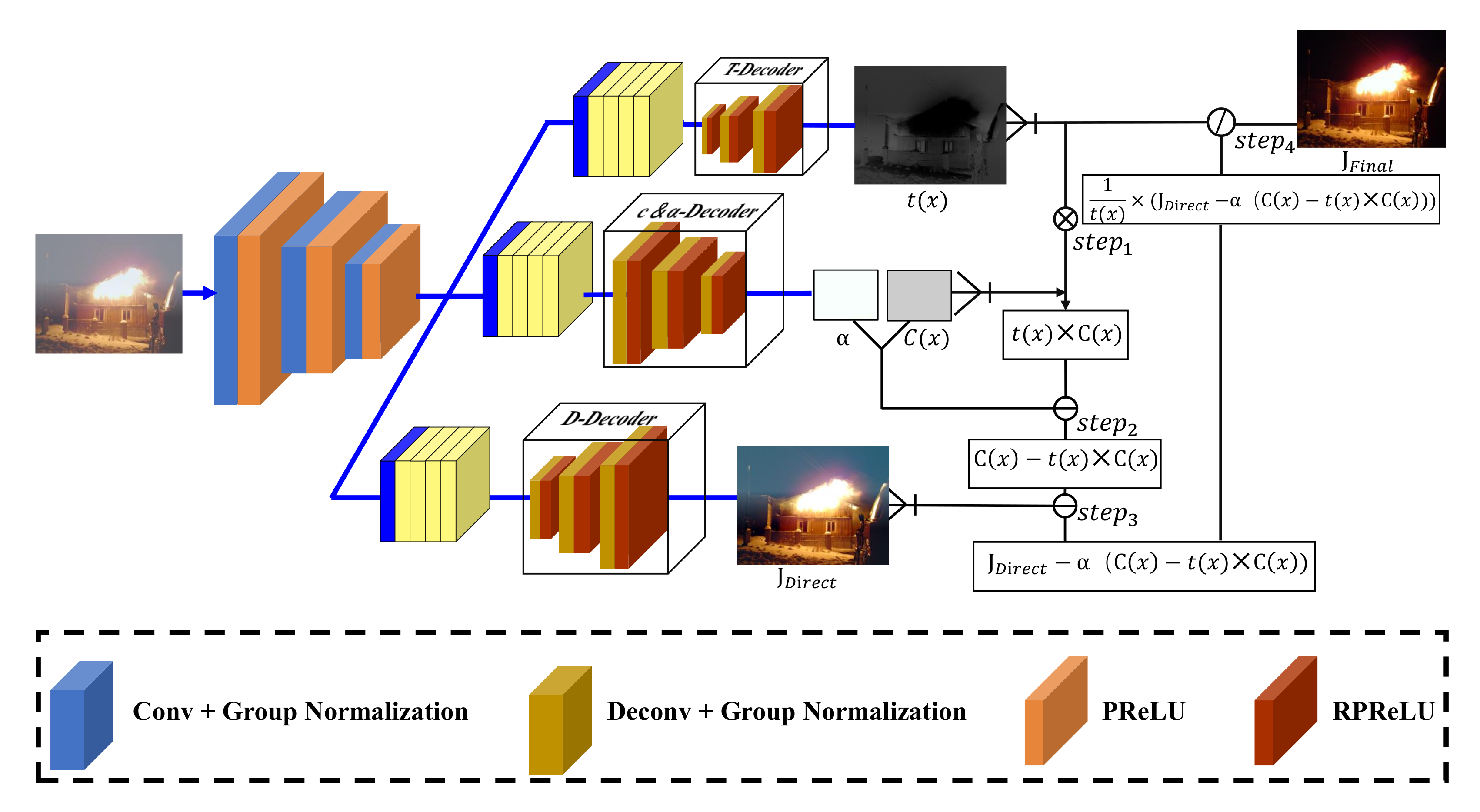
3.1. Color-Dense Illumination Adjustment Network
3.2. Aerosol Scattering Model
3.3. Loss Function
3.3.1. Mean Square Error
3.3.2. Feature Reconstruction Loss
4. Experiment Result
4.1. Experimental Settings
4.2. Ablation Study
4.3. Evaluation on Synthetic Images
4.4. Evaluation on Real-World Images
4.5. Qualitative Visual Results on Challenging Images
4.6. Potential Applications
4.6.1. Object Detection
4.6.2. Local Keypoint Matching
4.7. Runtime Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liang, J.X.; Zhao, J.F.; Sun, N.; Shi, B.J. Random Forest Feature Selection and Back Propagation Neural Network to Detect Fire Using Video. J. Sens. 2022, 2022, 5160050. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 October 2017; pp. 4770–4778. [Google Scholar]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, J. Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Saf. J. 2017, 93, 53–59. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.H.; Yin, Y.H.; Huang, S.F.; Ye, Y.T. The smoke detection for early fire-alarming system base on video processing. In Proceedings of the 2006 International Conference on Intelligent Information Hiding and Multimedia, Pasadena, CA, USA, 18–20 December 2006; pp. 427–430. [Google Scholar]
- Zheng, Z.; Ren, W.; Cao, X.; Hu, X.; Wang, T.; Song, F.; Jia, X. Ultra-High-Definition Image Dehazing via Multi-Guided Bilateral Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16180–16189. [Google Scholar]
- Yoon, I.; Jeong, S.; Jeong, J.; Seo, D.; Paik, J. Wavelength-adaptive dehazing using histogram merging-based classification for UAV images. Sensors 2015, 15, 6633–6651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, T.; Zhao, G.; Wu, J.; Ye, Y.; Shen, Y. Efficient traffic video dehazing using adaptive dark channel prior and spatial–temporal correlations. Sensors 2019, 19, 1593. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; He, L.; Ma, S.; Gao, S.; Bi, D. A sensor image dehazing algorithm based on feature learning. Sensors 2018, 18, 2606. [Google Scholar] [CrossRef] [Green Version]
- Qu, C.; Bi, D.Y.; Sui, P.; Chao, A.N.; Wang, Y.F. Robust dehaze algorithm for degraded image of CMOS image sensors. Sensors 2017, 17, 2175. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, P.W.; Shao, P.C. Variational contrast-saturation enhancement model for effective single image dehazing. Signal Process. 2022, 192, 108396. [Google Scholar] [CrossRef]
- Zhang, Y.; Kwong, S.; Wang, S. Machine learning based video coding optimizations: A survey. Inf. Sci. 2020, 506, 395–423. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, H.; Yu, M.; Kwong, S.; Ho, Y.S. Sparse representation-based video quality assessment for synthesized 3D videos. IEEE Trans. Image Process. 2019, 29, 509–524. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, Z.; Zhou, Y.; Zhu, L. Allowable depth distortion based fast mode decision and reference frame selection for 3D depth coding. Multimed. Tools Appl. 2017, 76, 1101–1120. [Google Scholar] [CrossRef]
- Zhu, L.; Kwong, S.; Zhang, Y.; Wang, S.; Wang, X. Generative adversarial network-based intra prediction for video coding. IEEE Trans. Multimed. 2019, 22, 45–58. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, Y.; Zhang, H.; Fan, C.; Kwong, S.; Kuo, C.C.J.; Fan, X. Deep learning-based picture-wise just noticeable distortion prediction model for image compression. IEEE Trans. Image Process. 2019, 29, 641–656. [Google Scholar] [CrossRef] [PubMed]
- Astua, C.; Barber, R.; Crespo, J.; Jardon, A. Object Detection Techniques Applied on Mobile Robot Semantic Navigation. Sensors 2014, 14, 6734–6757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thanh, L.T.; Thanh, D.N.H.; Hue, N.M.; Prasath, V.B.S. Single Image Dehazing Based on Adaptive Histogram Equalization and Linearization of Gamma Correction. In Proceedings of the 2019 25th Asia-Pacific Conference on Communications, Ho Chi Minh City, Vietnam, 6–8 November 2019; pp. 36–40. [Google Scholar]
- Golts, A.; Freedman, D.; Elad, M. Unsupervised Single Image Dehazing Using Dark Channel Prior Loss. IEEE Trans. Image Process. 2020, 29, 2692–2701. [Google Scholar] [CrossRef] [Green Version]
- Parihar, A.S.; Gupta, Y.K.; Singodia, Y.; Singh, V.; Singh, K. A Comparative Study of Image Dehazing Algorithms. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems, Hammamet, Tunisia, 10–12 March 2020; pp. 766–771. [Google Scholar] [CrossRef]
- Hou, G.; Li, J.; Wang, G.; Pan, Z.; Zhao, X. Underwater image dehazing and denoising via curvature variation regularization. Multimed. Tools Appl. 2020, 79, 20199–20219. [Google Scholar] [CrossRef]
- Nayar, S.K.; Narasimhan, S.G. Vision in bad weather. In Proceedings of the IEEE Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 820–827. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 713–724. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.; Zhang, Y.; Xu, G.; Zhang, Q. Smoke detection on video sequences using 3D convolutional neural networks. Fire Technol. 2019, 55, 1827–1847. [Google Scholar] [CrossRef]
- Shu, Q.; Wu, C.; Xiao, Z.; Liu, R.W. Variational Regularized Transmission Refinement for Image Dehazing. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–29 September 2019; pp. 2781–2785. [Google Scholar] [CrossRef] [Green Version]
- Fu, X.; Cao, X. Underwater image enhancement with global-local networks and compressed-histogram equalization. Signal Process. Image Commun. 2020, 86, 115892. [Google Scholar] [CrossRef]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles. Phys. Bull. 1977, 28, 521–531. [Google Scholar] [CrossRef]
- Tang, K.; Yang, J.; Wang, J. Investigating haze-relevant features in a learning framework for image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2995–3000. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1674–1682. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed] [Green Version]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Ren, W.; Pan, J.; Zhang, H.; Cao, X.; Yang, M.h. Single Image Dehazing via Multi-Scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2020, 128, 240–259. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Densely Connected Pyramid Dehazing Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3194–3203. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Gandelsman, Y.; Shocher, A.; Irani, M. “Double-DIP”: Unsupervised Image Decomposition via Coupled Deep-Image-Priors. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11018–11027. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Li, Z.; Wu, J.; Fan, H.; Xiao, G.; Zhang, H. Deep residual haze network for image dehazing and deraining. IEEE Access 2020, 8, 9488–9500. [Google Scholar] [CrossRef]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Patel, V.M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 695–704. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii Convention Center, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P.H. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017; pp. 1492–1500. [Google Scholar]
- Fisher, Y.; Dequan, W.; Evan, S.; Trevor, D. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2403–2412. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R. NH-HAZE: An Image Dehazing Benchmark with Non-Homogeneous Hazy and Haze-Free Images. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Online, 14–19 June 2020; pp. 1798–1805. [Google Scholar] [CrossRef]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney Conference Centre in Darling Harbour, Sydney, Australia, 3–6 December 2013; pp. 617–624. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3253–3261. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Enc. 1 | Enc. 2 | Enc. 3 | Enc. 4 | Enc. 5 | Enc. 6 | Enc. 7 | |
|---|---|---|---|---|---|---|---|
| Input | Input | Input | Input | Input | Input | Input | Input |
| Structure | |||||||
| Output |
| Dec. 1 | Dec. 2 | Dec. 3 | Dec. 4 | Dec. 5 | Dec. 6 | |
|---|---|---|---|---|---|---|
| [Res. 1] | [Res. 2] | [Res. 3] | [Res. 4] | [Res. 5] | [Res. 6] | |
| T-Decoder | ||||||
| 78 | ||||||
| Dec. 1 | Dec. 2 | Dec. 3 | Dec. 4 | Dec. 5 | Dec. 6 | |
| [Res, 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | |
| c&a-Decoder | ||||||
| Dec. 1 | Dec. 2 | Dec. 3 | Dec. 4 | Dec. 5 | Dec. 6 | |
| [Res, 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | [Res. 4, Trans. 2] | |
| J-Decoder | ||||||
| NTIRE’20 | RFSIE | Time/Epoch | ||||
|---|---|---|---|---|---|---|
| Metric | PSNR | SSIM | PSNR | SSIM | ||
| CIANet | J | 13.11 | 0.56 | 24.81 | 0.82 | 63 min |
| 14.23 | 0.58 | 25.34 | 0.81 | |||
| 18.34 | 0.62 | 31.22 | 0.91 | |||
| -only | 12.11 | 0.51 | 24.96 | 0.78 | 21 min | |
| -only | 14.21 | 0.59 | 25.91 | 0.80 | 21 min | |
| Methods | Hazy | He | Zhu | Ren | Cai | Li | Meng | Ma | Berman | Chen | Zhang | Zheng | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | 12.85 | 17.42 | 19.67 | 23.68 | 21.95 | 23.92 | 24.94 | 26.19 | 26.95 | 27.25 | 27.36 | 26.11 | 31.22 |
| SSIM | 0.78 | 0.80 | 0.82 | 0.85 | 0.87 | 0.82 | 0.82 | 0.82 | 0.85 | 0.85 | 0.85 | 0.82 | 0.91 |
| Image Size | Platform | |
|---|---|---|
| He | 26.03 | Matlab |
| Berman | 8.43 | Matlab |
| Meng | 2.19 | Matlab |
| Ren | 2.01 | Matlab |
| Zhu | 1.02 | Matlab |
| Cai (Matlab) | 2.09 | Matlab |
| Cai (Pytorch) | 6.31 | Pytorch |
| CIANet | 4.77 | Pytorch |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Hu, J.; Luo, X.; Kwan, M.-P.; Chen, W.; Wang, H. Color-Dense Illumination Adjustment Network for Removing Haze and Smoke from Fire Scenario Images. Sensors 2022, 22, 911. https://doi.org/10.3390/s22030911
Wang C, Hu J, Luo X, Kwan M-P, Chen W, Wang H. Color-Dense Illumination Adjustment Network for Removing Haze and Smoke from Fire Scenario Images. Sensors. 2022; 22(3):911. https://doi.org/10.3390/s22030911
Chicago/Turabian StyleWang, Chuansheng, Jinxing Hu, Xiaowei Luo, Mei-Po Kwan, Weihua Chen, and Hao Wang. 2022. "Color-Dense Illumination Adjustment Network for Removing Haze and Smoke from Fire Scenario Images" Sensors 22, no. 3: 911. https://doi.org/10.3390/s22030911
APA StyleWang, C., Hu, J., Luo, X., Kwan, M.-P., Chen, W., & Wang, H. (2022). Color-Dense Illumination Adjustment Network for Removing Haze and Smoke from Fire Scenario Images. Sensors, 22(3), 911. https://doi.org/10.3390/s22030911