
Fast Panoptic Segmentation with Soft Attention Embeddings


Abstract
:1. Introduction
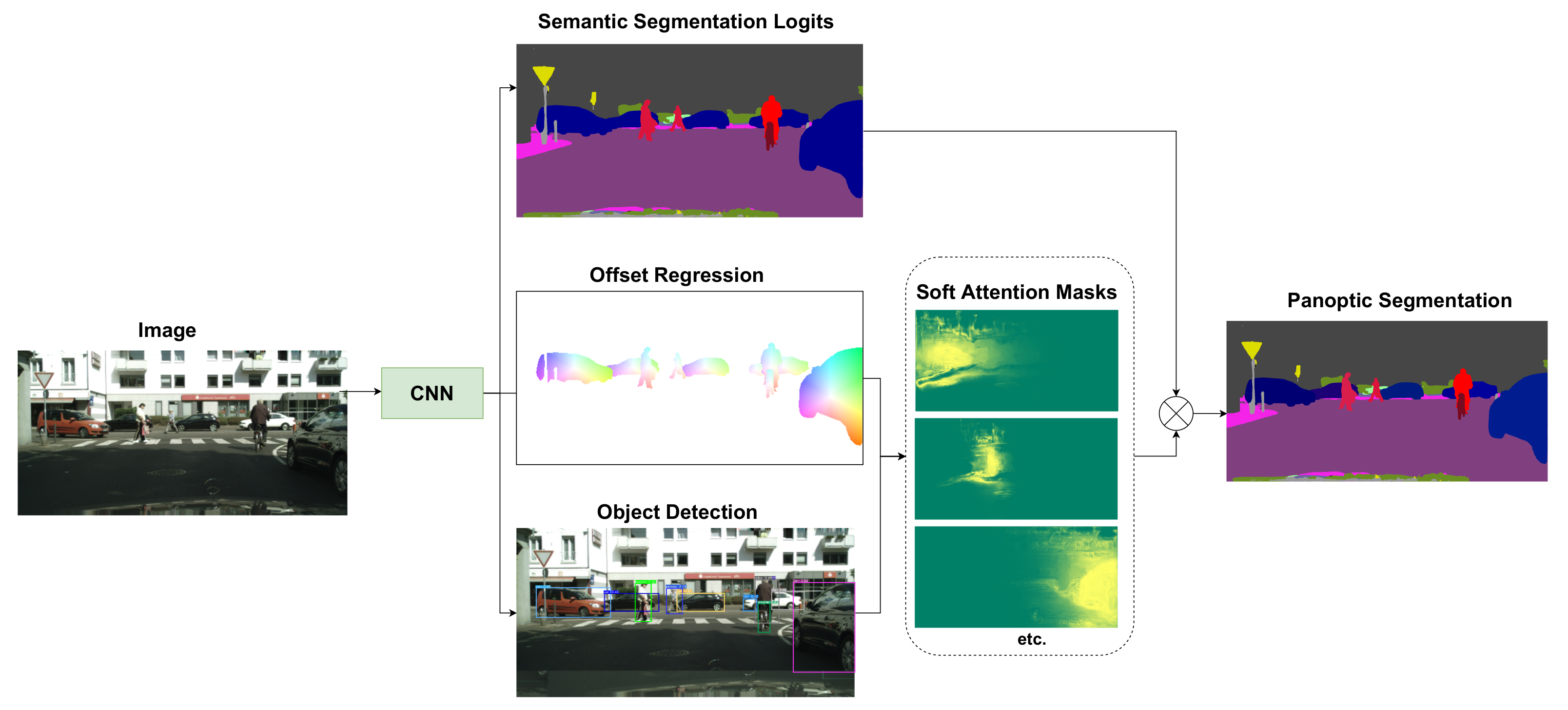
- We propose a lightweight fully convolutional architecture for panoptic segmentation based on a single-stage object detector which we extend with novel semantic and panoptic heads;
- We propose a novel panoptic head that predicts instance-specific soft attention masks based on instance center offsets and object detections;
- The proposed network has simplified inference and training pipelines, does not require merging heuristics for panoptic segmentation, and thus is suitable for real-world applications;
- We perform extensive experiments on COCO and Cityscapes datasets, and achieve faster inference speeds and better or on-par accuracy compared to existing methods.
2. Related Work
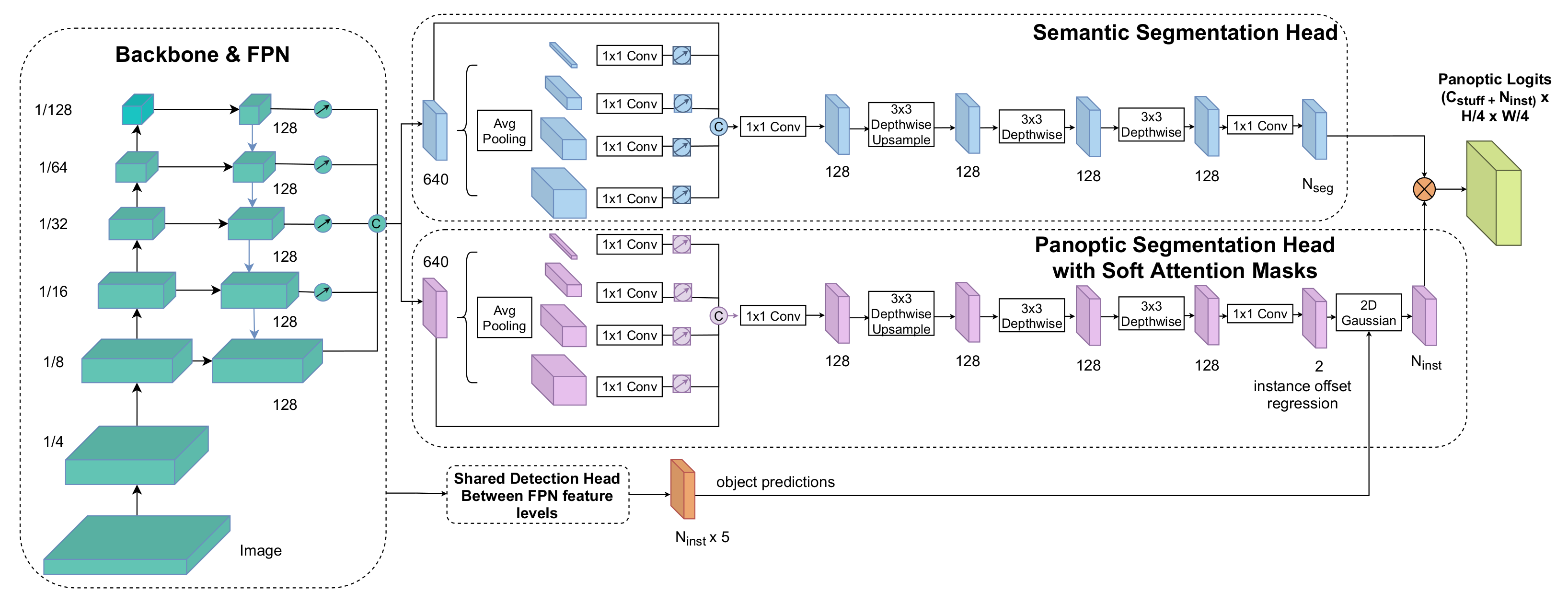
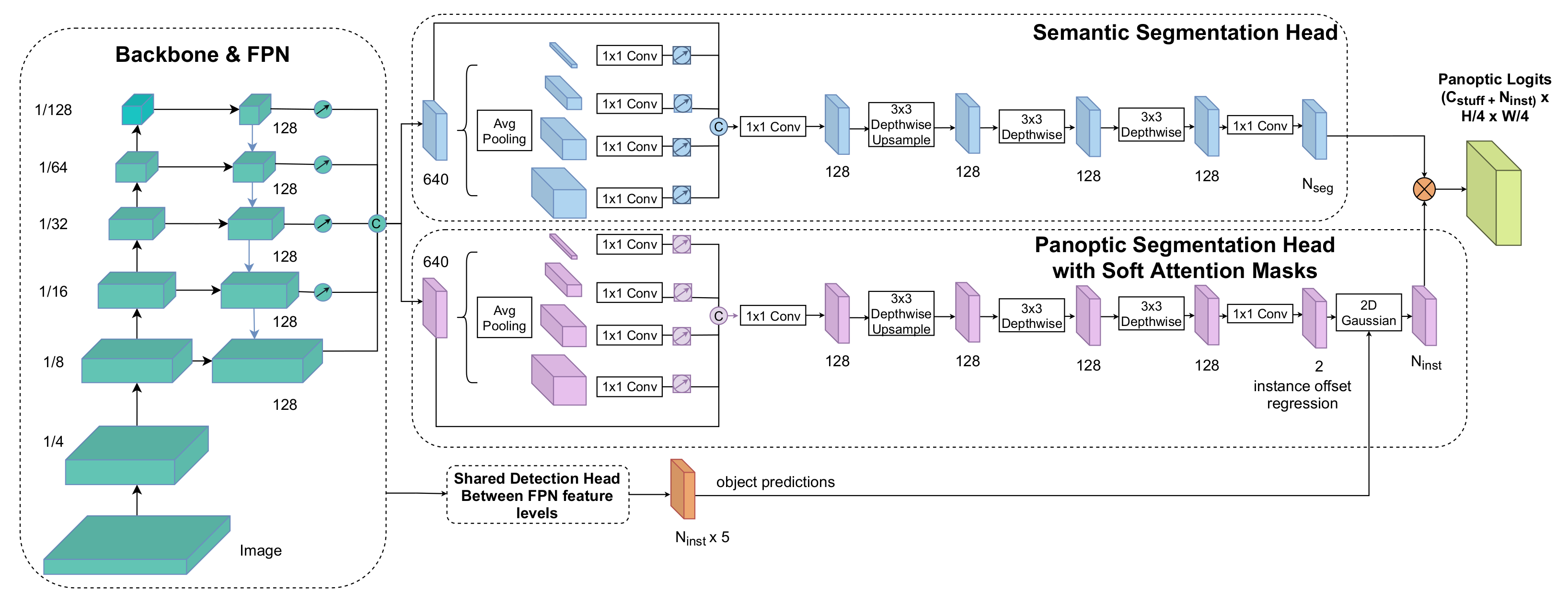
3. Panoptic Segmentation Network
3.1. Model Architecture
3.2. Implementation Details
4. Experiments
4.1. Experimental Setup
4.2. Ablation Studies
4.3. Performance on Cityscapes
4.4. Performance on COCO
4.5. 2D Panoptic Perception
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Rota Bulo, S.; Kontschieder, P. The mapillary vistas dataset for semantic understanding of street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4990–4999. [Google Scholar]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef] [Green Version]
- Porzi, L.; Bulo, S.R.; Colovic, A.; Kontschieder, P. Seamless scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8277–8286. [Google Scholar]
- Petrovai, A.; Nedevschi, S. Multi-task Network for Panoptic Segmentation in Automated Driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, NZ, USA, 27–30 October 2019; pp. 2394–2401. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. Upsnet: A unified panoptic segmentation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8818–8826. [Google Scholar]
- De Geus, D.; Meletis, P.; Dubbelman, G. Fast panoptic segmentation network. IEEE Robot. Autom. Lett. 2020, 5, 1742–1749. [Google Scholar] [CrossRef] [Green Version]
- Hou, R.; Li, J.; Bhargava, A.; Raventos, A.; Guizilini, V.; Fang, C.; Lynch, J.; Gaidon, A. Real-Time Panoptic Segmentation from Dense Detections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8523–8532. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12475–12485. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar]
- Sofiiuk, K.; Barinova, O.; Konushin, A. Adaptis: Adaptive instance selection network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7355–7363. [Google Scholar]
- Mohan, R.; Valada, A. Efficientps: Efficient panoptic segmentation. Int. J. Comput. Vis. 2021, 129, 1551–1579. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Weber, M.; Luiten, J.; Leibe, B. Single-shot panoptic segmentation. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 8476–8483. [Google Scholar]
- Gao, N.; Shan, Y.; Wang, Y.; Zhao, X.; Yu, Y.; Yang, M.; Huang, K. Ssap: Single-shot instance segmentation with affinity pyramid. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 642–651. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 17–30 June 2016; pp. 770–778. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- NVIDIA TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 14 January 2022).
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar]
- Neven, D.; Brabandere, B.D.; Proesmans, M.; Gool, L.V. Instance segmentation by jointly optimizing spatial embeddings and clustering bandwidth. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8837–8845. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Petrovai, A.; Nedevschi, S. Real-Time Panoptic Segmentation with Prototype Masks for Automated Driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1400–1406. [Google Scholar]
- Yang, T.J.; Collins, M.D.; Zhu, Y.; Hwang, J.J.; Liu, T.; Zhang, X.; Sze, V.; Papandreou, G.; Chen, L.C. Deeperlab: Single-shot image parser. arXiv 2019, arXiv:1902.05093. [Google Scholar]
- Li, Q.; Qi, X.; Torr, P.H. Unifying training and inference for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13320–13328. [Google Scholar]
- Wang, H.; Luo, R.; Maire, M.; Shakhnarovich, G. Pixel consensus voting for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9464–9473. [Google Scholar]
- Varga, R.; Costea, A.; Florea, H.; Giosan, I.; Nedevschi, S. Super-sensor for 360-degree environment perception: Point cloud segmentation using image features. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Urban Parking and Driving H2020 European Project (UP-Drive). Available online: https://up-drive.ethz.ch/ (accessed on 14 January 2022).
- The Automotive Data and Time Triggered Framework. Available online: https://www.elektrobit.com/products/automated-driving/eb-assist/adtf (accessed on 14 January 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dec × 1 | Dec × 2 | Att Mean | Att Scale | Seg Loss | Reg Loss | Th Seg | PQ | mIoU | Speed (ms) |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 53.1 | 75.4 | 92 | ||||
| ✓ | ✓ | ✓ | ✓ | 57.2 | 74.9 | 92 | |||
| ✓ | ✓ | ✓ | ✓ | 57.6 | 91 | ||||
| ✓ | ✓ | ✓ | ✓ | 58.5 | 74.4 | 92 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | 59.7 | 76.4 | 92 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 59.6 | 76.2 | 92 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 58.7 | 75.6 | 87 |
| Backbone | mIoU | Inference Time (ms) | |||||
|---|---|---|---|---|---|---|---|
| Full image size: 1024 × 2048 | |||||||
| ResNet50-FPNlite | 59.3 | 52.8 | 64.1 | 80.0 | 72.7 | 76.0 | 88 |
| VoVNet2-39-FPNlite | 59.7 | 52.9 | 64.7 | 80.2 | 73.1 | 76.4 | 92 |
| VoVNet2-57-FPNlite | 60.4 | 53.6 | 65.4 | 80.3 | 73.9 | 76.8 | 132 |
| Half image size: 512 × 1024 | |||||||
| VoVNet2-39-FPNlite | 48.9 | 41.5 | 54.3 | 76.7 | 61.2 | 69.8 | 42 |
| Method | Backbone | PQ | mIoU | Time (ms) | ||
|---|---|---|---|---|---|---|
| Bottom-up | ||||||
| DeeperLab [29] | Xception-71 | 56.5 | - | - | - | - |
| SSAP [19] | ResNet50-FPN | 58.4 | 50.6 | - | - | - |
| AdaptIS [15] | ResNet50 | 59.0 | 55.8 | 61.3 | - | - |
| Panoptic DeepLab [12] | ResNet50 | 59.7 | - | - | - | 117 |
| Box-based Two-Stage | ||||||
| MTN Panoptic [7] | ResNet50-FPN | 57.3 | 53.9 | 59.7 | - | 150 |
| Panoptic-FPN [14] | ResNet50-FPN | 58.1 | 52 | 62.5 | 75.7 | - |
| UPSNet [9] | ResNet50-FPN | 59.3 | 54.6 | 62.7 | 75.2 | 140 |
| Seamless Panoptic [6] | ResNet50-FPN | 60.3 | 56.1 | 63.3 | 77.5 | 150 |
| EfficientPS [16] | ResNet50-FPN | 63.9 | 60.7 | 66.2 | 79.3 | 166 |
| Box-based Single-Stage | ||||||
| FPSNet [10] | ResNet50-FPN | 55.1 | 48.3 | 60.1 | - | 98 |
| Prototype Panoptic [28] | VoVNet2-39-FPNlite | 57.3 | 50.4 | 62.4 | - | 82 |
| DenseBox [11] | ResNet50-FPN | 58.8 | 52.1 | 63.7 | 77.0 | 99 |
| AttentionPS (ours) | ResNet50-FPNlite | 59.3 | 52.8 | 64.1 | 76.0 | 88 |
| AttentionPS (ours) | VoVNet2-39-FPNlite | 59.7 | 52.8 | 64.7 | 76.4 | 92 |
| Method | Backbone | PQ | Time (ms) | ||
|---|---|---|---|---|---|
| Bottom-up | |||||
| DeeperLab [29] | Xception-71 | 33.8 | - | - | 92 |
| Panoptic DeepLab [12] | ResNet50 | 35.1 | - | - | 50 |
| AdaptIS [15] | ResNet50 | 34.4 | 50. | 29.3 | - |
| PCV [31] | ResNet50 | 37.5 | 40.7 | 33.1 | - |
| Box-based Two-Stage | |||||
| Panoptic-FPN [14] | ResNet50-FPN | 41.5 | 48.3 | 31.2 | - |
| UPSNet [9] | ResNet50-FPN | 42.5 | 48.6 | 33.4 | 109 |
| Unifying [30] | ResNet50-FPN | 43.4 | 48.6 | 35.5 | - |
| Box-based Single-Stage | |||||
| SingleShot-576 [18] | ResNet50-FPN | 32.4 | 34.8 | 28.6 | 43 |
| DenseBox-800 [11] | ResNet50-FPN | 37.1 | 41.0 | 31.3 | 63 |
| AttentionPS-800 (ours) | ResNet50-FPNlite | 34.4 | 39.3 | 27.1 | 45 |
| AttentionPS-640 (ours) | ResNet50-FPNlite | 33.4 | 37.8 | 26.7 | 32 |
| Backbone | GPU | Resolution | PQ | Time (ms) |
|---|---|---|---|---|
| ResNet50-FPNlite | GTX 1080 | 1024 × 2048 | 59.3 | 70 |
| ResNet50-FPNlite | Tesla V100 | 1024 × 2048 | 59.3 | 44 |
| VoVNet2-39-FPNlite | GTX 1080 | 512 × 1024 | 48.9 | 31 |
| VoVNet2-39-FPNlite | Tesla V100 | 512 × 1024 | 48.9 | 20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrovai, A.; Nedevschi, S. Fast Panoptic Segmentation with Soft Attention Embeddings. Sensors 2022, 22, 783. https://doi.org/10.3390/s22030783
Petrovai A, Nedevschi S. Fast Panoptic Segmentation with Soft Attention Embeddings. Sensors. 2022; 22(3):783. https://doi.org/10.3390/s22030783
Chicago/Turabian StylePetrovai, Andra, and Sergiu Nedevschi. 2022. "Fast Panoptic Segmentation with Soft Attention Embeddings" Sensors 22, no. 3: 783. https://doi.org/10.3390/s22030783
APA StylePetrovai, A., & Nedevschi, S. (2022). Fast Panoptic Segmentation with Soft Attention Embeddings. Sensors, 22(3), 783. https://doi.org/10.3390/s22030783