
A Resource-Efficient CNN-Based Method for Moving Vehicle Detection



Abstract
:1. Introduction
2. Related Work
2.1. DL for Foreground Generation
2.2. DL for Background Generation
2.3. DL for Moving Object Classification
3. Problem Formulation
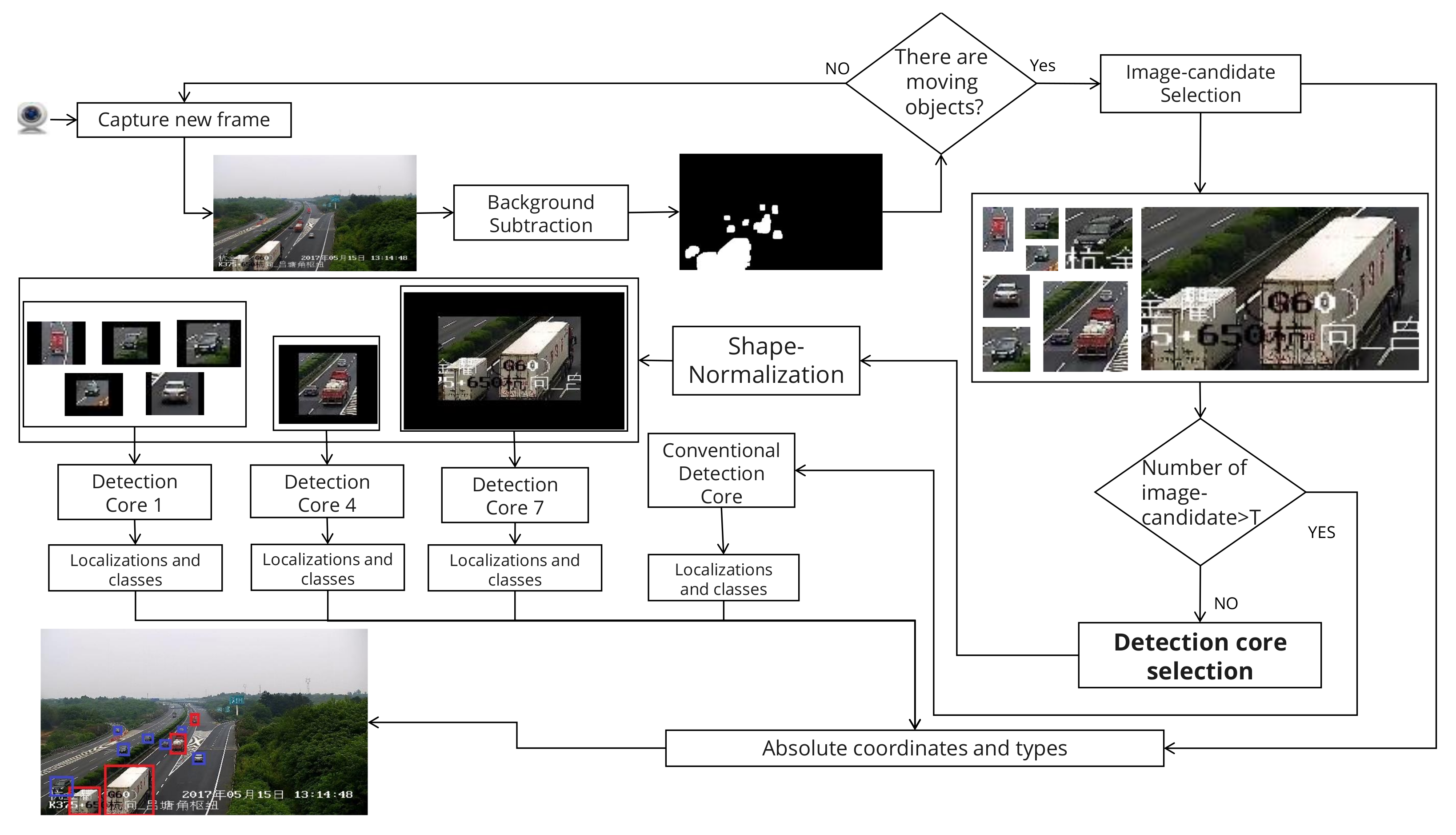
4. The Proposed Framework
4.1. Background Subtraction
4.1.1. Background
4.1.2. Data Preparation
4.2. CNN-Based Core
4.2.1. Background
4.2.2. Preprocessing
4.2.3. Model Design
4.3. The Overall Architecture
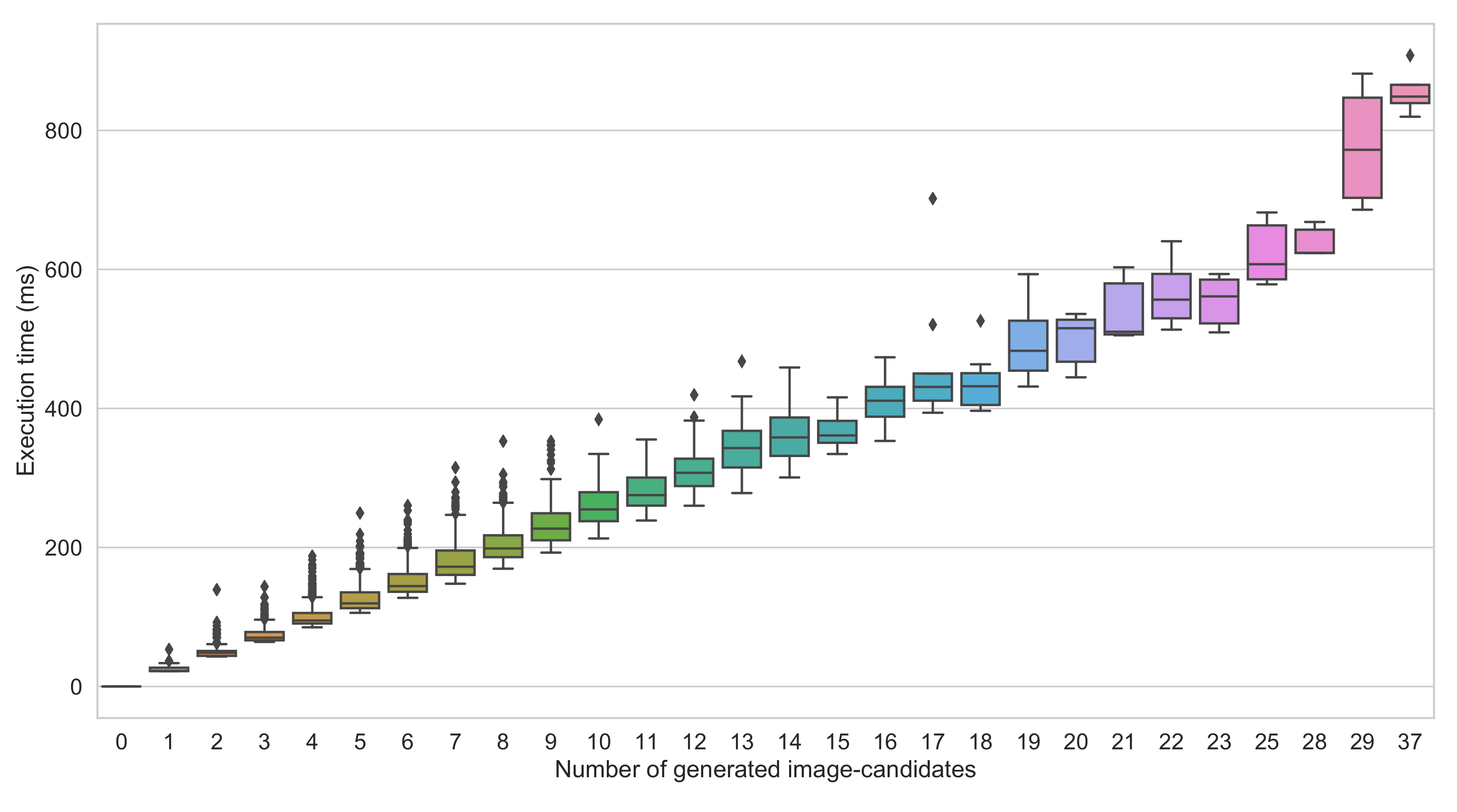
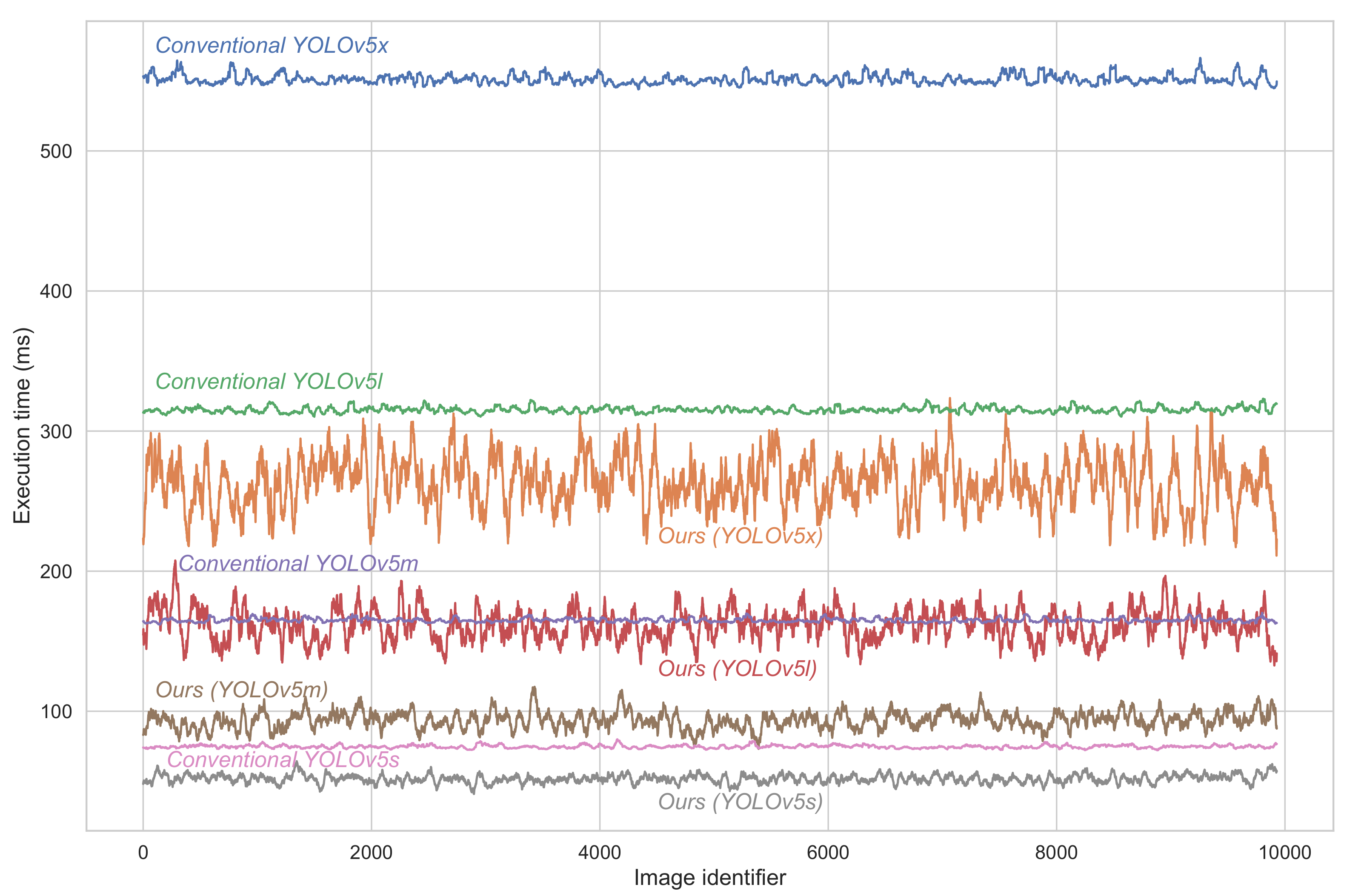
5. Tests and Results
5.1. Dataset
5.2. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Garcia-Garcia, B.; Bouwmans, T.; Silva, A.J.R. Background subtraction in real applications: Challenges, current models and future directions. Comput. Sci. Rev. 2020, 35, 100204. [Google Scholar] [CrossRef]
- Charouh, Z.; Ghogho, M.; Guennoun, Z. Improved background subtraction-based moving vehicle detection by optimizing morphological operations using machine learning. In Proceedings of the 2019 IEEE International Symposium on Innovations in Intelligent Systems and Applications (INISTA), Sofia, Bulgaria, 3–5 July 2019; pp. 1–6. [Google Scholar]
- Kim, J.; Ha, J.E. Foreground Objects Detection by U-Net with Multiple Difference Images. Appl. Sci. 2021, 11, 1807. [Google Scholar] [CrossRef]
- Pardas, M.; Canet, G. Refinement Network for unsupervised on the scene Foreground Segmentation. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 705–709. [Google Scholar]
- Srigrarom, S.; Chew, K.H. Hybrid motion-based object detection for detecting and tracking of small and fast moving drones. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 1–4 September 2022; pp. 615–621. [Google Scholar]
- Rabidas, R.; Ravi, D.K.; Pradhan, S.; Moudgollya, R.; Ganguly, A. Investigation and Improvement of VGG based Encoder-Decoder Architecture for Background Subtraction. In Proceedings of the 2020 Advanced Communication Technologies and Signal Processing (ACTS), Silchar, India, 4–6 December 2020; pp. 1–6. [Google Scholar]
- Bakkay, M.C.; Rashwan, H.A.; Salmane, H.; Khoudour, L.; Puig, D.; Ruichek, Y. BSCGAN: Deep background subtraction with conditional generative adversarial networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4018–4022. [Google Scholar]
- Babaee, M.; Dinh, D.T.; Rigoll, G. A deep convolutional neural network for video sequence BS. Pattern Recognit. 2018, 76, 635–649. [Google Scholar] [CrossRef]
- Wang, X.; Liu, L.; Li, G.; Dong, X.; Zhao, P.; Feng, X. Background subtraction on depth videos with convolutional neural networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Behnaz, R.; Amirreza, F.; Ostadabbas, S. DeepPBM: Deep Probabilistic Background Model Estimation from Video Sequences. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 608–621. [Google Scholar]
- Yu, W.; Bai, J.; Jiao, L. Background subtraction based on GAN and domain adaptation for VHR optical remote sensing videos. IEEE Access 2020, 8, 119144–119157. [Google Scholar] [CrossRef]
- Sultana, M.; Mahmood, A.; Bouwmans, T.; Jung, S.K. Unsupervised adversarial learning for dynamic background modeling. In International Workshop on Frontiers of Computer Vision; Springer: Singapore, 2020; pp. 248–261. [Google Scholar]
- Braham, M.; Van Droogenbroeck, M. Deep background subtraction with scene-specific convolutional neural networks. In Proceedings of the 2016 International Conference on Systems, Signals and Image Processing (IWSSIP), Bratislava, Slovakia, 23–25 May 2016; pp. 1–4. [Google Scholar]
- Xu, P.; Ye, M.; Li, X.; Liu, Q.; Yang, Y.; Ding, J. Dynamic background learning through deep auto-encoder networks. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 107–116. [Google Scholar]
- Taspinar, Y.S.; Selek, M. Object Recognition with Hybrid deep learning Methods and Testing on Embedded Systems. Int. J. Intell. Syst. Appl. Eng. 2020, 8, 71–77. [Google Scholar] [CrossRef]
- Yu, T.; Yang, J.; Lu, W. Combining background subtraction and Convolutional Neural Network for Anomaly Detection in Pumping-Unit Surveillance. Algorithms 2019, 12, 115. [Google Scholar] [CrossRef] [Green Version]
- Yousif, H.; Yuan, J.; Kays, R.; He, Z. Object detection from dynamic scene using joint background modeling and fast deep learning classification. J. Vis. Commun. Image Represent. 2018, 55, 802–815. [Google Scholar] [CrossRef]
- Kim, C.; Lee, J.; Han, T.; Kim, Y.M. A hybrid framework combining background subtraction and deep neural networks for rapid person detection. J. Big Data 2018, 5, 1–24. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Wen, S. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Jocher, G.; Nishimura, K.; Mineeva, T.; Vilariño, R. Yolov5. Code Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 January 2022).
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 1–16. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Shape | Detection-Core 1 | Detection-Core 2 |
|---|---|---|---|
| Input | - | (96 × 64 × 3) | (640 × 384 × 3) |
| Conv. 2D | (3 × 3 × 32) | (48 × 32 × 32) | (320 × 192 × 32) |
| Conv. 2D | (3 × 3 × 64) | (24 × 16 × 64) | (160 × 96 × 64) |
| Conv. 2D | (1 × 1 × 32) | (24 × 16 × 32) | (160 × 96 × 32) |
| Conv. 2D | (1 × 1 × 32) | (24 × 16 × 32) | (160 × 96 × 32) |
| Conv. 2D | (3 × 3 × 32) | (24 × 16 × 32) | (160 × 96 × 32) |
| Conv. 2D | (1 × 1 × 32) | (24 × 16 × 32) | (160 × 96 × 32) |
| Conv. 2D | (1 × 1 × 64) | (24 × 16 × 64) | (160 × 96 × 64) |
| Conv. 2D | (3 × 3 × 128) | (12 × 8 × 128) | (80 × 48 × 128) |
| Scenario | Params | Conventional | Ours | ||||
|---|---|---|---|---|---|---|---|
| AP@50 | mAP | Time | AP@50 | mAP | Time | ||
| YOLOv5s | 7.3 M | 58.11 | 38.03 | 75 | 58.11 | 38.03 | 52 |
| YOLOv5m | 21.4 M | 64.66 | 46.72 | 165 | 64.66 | 46.72 | 93 |
| YOLOv5l | 47.0 M | 62.72 | 43.89 | 315 | 62.72 | 43.89 | 162 |
| YOLOv5x | 87.7 M | 59.4 | 40.79 | 551 | 59.4 | 40.79 | 263 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Charouh, Z.; Ezzouhri, A.; Ghogho, M.; Guennoun, Z. A Resource-Efficient CNN-Based Method for Moving Vehicle Detection. Sensors 2022, 22, 1193. https://doi.org/10.3390/s22031193
Charouh Z, Ezzouhri A, Ghogho M, Guennoun Z. A Resource-Efficient CNN-Based Method for Moving Vehicle Detection. Sensors. 2022; 22(3):1193. https://doi.org/10.3390/s22031193
Chicago/Turabian StyleCharouh, Zakaria, Amal Ezzouhri, Mounir Ghogho, and Zouhair Guennoun. 2022. "A Resource-Efficient CNN-Based Method for Moving Vehicle Detection" Sensors 22, no. 3: 1193. https://doi.org/10.3390/s22031193
APA StyleCharouh, Z., Ezzouhri, A., Ghogho, M., & Guennoun, Z. (2022). A Resource-Efficient CNN-Based Method for Moving Vehicle Detection. Sensors, 22(3), 1193. https://doi.org/10.3390/s22031193