1. Introduction
With an increasing number of 3D sensors available, such as Light Detection and Ranging (LiDAR), the demand for 3D data processing is also increasing. The range of interest extends from autonomous driving [
1,
2,
3] to infrastructure mapping [
4,
5,
6,
7] up to biomedical analysis [
8].
The task of understanding a scene is challenging for a computer. It can be divided into classification, object recognition, semantic, and instance segmentation. The research community has made extreme progress in recent years for 2D semantic segmentation on images [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18]. Methods for 3D processing on point clouds, on the other hand, are rarer and suffer from computational cost and inaccuracy. The progress achieved in the field of image processing cannot be applied without further ado. There are a few main differences between images and point clouds. First of all, point clouds are very sparse compared to images. Furthermore, the density of points within the same point cloud may vary. Commonly, the point density close to the sensor is denser than the point density further away from it. Thirdly, point clouds are irregular. This means the number of points within a respective point cloud differs. Moreover, point clouds are unstructured, which implies that each point is independent, and the distance between adjacent points varies. In addition to that, point clouds are unordered and invariant to permutation.
To circumvent the problems described above, we work with projection-based methods. This paper can be divided into three parts. First, we show different projection-based approaches and how they can be used. Instead of working with a single view, we examine the spherical, the bird’s eye, and the cylindrical views. Stating their advantages and disadvantages allows us to compare the views with each other and shows how to improve them. By using multiple projection planes as feature maps and combining them with dimensionality reducing filters, the bird’s-eye and the cylindrical view can be drastically improved. The second part is about fusing multiple views. Complementary views allow the avoidance of errors that occur, such as occlusion. This means we can improve the overall performance. To investigate the fusion process itself, we define our baseline model and compare it to non-learnable and learnable approaches. Within the third part, we answer the question about generalization. This does not only mean to apply the approaches to unseen data but also to a new sensor with a different setup, as well as to synthetic generated data.
This paper makes three major contributions:
comparing different projection-based methods with each other to highlight the advantages and disadvantages
improving the performance for the regular bird’s eye and cylindrical view
proposing methods that can be used to fuse multiple projections with each other to improve the overall performance
2. Related Work
There are a lot of different approaches to tackle the task of 3D segmentation today. A general overview is given in [
19]. Mainly, these approaches can be divided into projection-based, discretization-based, and point-based methods.
The idea of the projection-based method is to map the 3D data into a 2D image. The point cloud is transformed into a spherical image in [
20,
21] and SalsaNext [
22]. Each of them uses a different 2D backbone for the segmentation, and both use k Nearest Neighbors (kNN) for post-processing the re-projected prediction. Instead of a spherical image, a bird’s-eye view image is used in [
23]. In addition to that, Polar coordinates are used instead of Cartesian coordinates and an MLP to learn a fixed-size representation. There are already several works that fuse multiple projections. The authors of [
24] extract features from both views and use an early fusion approach. Segmenting the spherical image first and projecting the results into the bird’s-eye view for further processing is done in [
25]. Ref. [
26] separates the two projections and adds up the resulting probabilities. In [
27], the late fusion is learned by an MLP. Multiple different projections are used in [
28] to perform shape segmentation. All of the named approaches have achieved excellent results. The main advantage of this method is that well-studied 2D convolution can be applied. This makes the approach very fast and accurate at the same time. Nevertheless, this approach suffers from discretization errors and occlusion. Furthermore, it highly depends on the used sensor.
The discretization-based method converts the 3D point cloud into a discrete representation. This could be voxels, octrees, or lattices, for example. Transforming the point cloud into a set of occupancy voxels is done in [
29]. This way, they avoid suffering from sparsity. All points within one voxel get assigned the same label as the voxel itself after voxel-wise segmentation. Ref. [
30] adopts sparse tensors and generalizes sparse convolution to work faster on sparse volumetric data. Preventing sparsity by storing feature representations within the leaves of octrees is done in [
31]. Ref. [
32] embeds the point cloud into sparse lattices. The convolution is applied to the lattices, and the learned features are projected back to the point cloud. First, employing cylindrical partition and then applying sparse, asymmetrical 3D convolution is performed in [
33]. Even though all of these approaches achieve good results in terms of accuracy, the main problem is the computational complexity.
Point-based methods directly work on point clouds. Due to the fact that they are unstructured and orderless, regular convolution can not be applied. These methods make use of pointwise Multilayer perceptron (MLP), generalized point convolution, or graph structures. Ref. [
34] was the first architecture using MLP’s to learn 3D features. In RandLA-Net [
35], the same method is used to downsample the point cloud aggressively. This way, the approach can be applied to larger point clouds. Others adapt the convolution in some way to make it applicable to point clouds, such as [
36], KPConv [
37], or [
38]. Ref. [
39] represents the point cloud as a graph. By doing so, graph convolution gets applied. These approaches have achieved outstanding results in some cases as well. Unfortunately, they are limited to a maximum number of points due to their memory consumption, and they usually cannot be applied in real-time.
Moreover, there is an increasing amount of methods that fuse multiple of the above-mentioned approaches. To allow for more efficient large-scene processing, voxel-based and point-based learning get combined in [
40] and in [
41]. All three approaches get combined in [
42]. These methods currently are leading the benchmark [
43].
All of the above approaches have their advantages and disadvantages. However, if compared in terms of runtime and memory consumption, the projection-based approaches have a clear advantage.
Figure 1 shows how the memory increases for point-based methods. In comparison, the memory requirement for the projection-based methods remains the same since it does not depend on the number of points but on the projection size. In our example, we used an image of size [3 × 256 × 256] and [3 × 512 × 512] jointly with a U-Net [
11] architecture. By working with point clouds with more than 100 k points, the projection-based methods need, by far, less memory.
In summary, it can be said that the projection-based approaches are the fastest. However, the geometric shapes are ignored, and discretization errors and occlusion of points occur. By using a discrete 3D representation, the geometric information can be retained, but the computational cost increases. For example, even if sparse tensors are used, the memory for the learned filters still increases in a cubic way instead of quadratic. Furthermore, discretization errors also occur with these approaches. Point-based methods avoid these errors by working without discretization steps, which is one of the biggest advantages. Currently, however, the number of points to be processed is a limiting factor. The fusion of complementary methods is a good way to balance the weaknesses of one method with the strengths of another. As the complexity increases, the methods should be chosen carefully to achieve the best ratio for the complexity and performance.
3. Projection-Based Methods
We focus on three different views that are going to be described shortly. All of them share the idea of mapping the point cloud . Projecting the 3D point cloud into a 2D image brings some significant advantages. First, the resulting image is always the same size, making it easier to train a model and combine the images into batches. Secondly, the projection is structured again. Thus, we know the neighboring pixels, and the well-studied 2D convolution can be applied, allowing for feature learning. This makes the model fast and keeps the required memory lower than 3D convolutions, as the number of parameters for the kernel grows only in a quadratic way instead of cubic. There are some disadvantages on the other hand. Due to the projection, we lose 3D geometric information. By ordering the point cloud and projecting them into an image, discretization errors occur, and points can overlap. This leads to occlusion errors and aggravates projecting the segmented points back to the point cloud.
3.1. Spherical View
To use this approach, the Cartesian coordinates get initially mapped into spherical coordinates. Afterward, the points get discretized into a spherical image
, with
w and
h representing the width and height of the projected image. The mapping is described in the following:
The vertical field of view depends on the sensor. The values for u and v are holding the image coordinates for each point. The resulting tensor has the shape of with a feature channel. The input features might be the depth d, if given the intensity i, the coordinates x, y, and z, or surface normals n. Since multiple points can be within one coordinate tuple, the points are ordered descending. This means that only the features for the closest point within a tuple are used.
By knowing the point coordinates and considering the image holding them as a function
, we can calculate a normal from the parametrization
, given:
The last equation can be implemented efficiently by using a GPU and a high abstraction deep learning framework.
As this type of projection is the most developed one, we will use the architecture from [
22]. We focus on investigating the input features and the size of the image itself. For the Velodyne HDL-64E, the angular resolution is 0.08° and the vertical approximately 0.4°. The horizontal field of view is 360°, and the vertical is 26.9°. This means by using an image width
and an image height
∼67, we are theoretically able to project every point into the image without problems, such as occluding points. Nevertheless, the computational effort increases and the image becomes more sparse. For this reason, we are interested in keeping the image small.
3.2. Bird’s-Eye View
The idea of this approach is to collapse the point cloud and project it into the ground plane, which most commonly is the
plane. To find the plane to project on, we are using the RANdom SAmple Consensus (RANSAC) algorithm [
44], and we use it to normalize the points. We discretize the point cloud into multiple planes instead of a single one to avoid suffering from too much occlusion. The resulting tensor has the shape of
with
height channels.
We use U-Net [
11] as our base network architecture. To combine the feature maps with each other and to increase the receptive filter field, we replace all double convolution blocks, but the input and output one, with an adapted version of the inception module [
45]. Instead of the max-pooling branch, we use another convolution one with a kernel of
, which is dilated by
. The padding size of each branch is chosen to allow for equivalent output sizes. Each block is followed by a batch normalization layer and ReLu as an activation function. All blocks with
that are followed by another convolution reduce the amount of feature channels by a factor of 8 compared to the desired overall output channels. The convolution block afterward doubles the feature map again. The solo reducing filter quarters the feature channels. Concatenating all branches ends up in the desired output size. This approach reduces the trainable parameters by a factor of approximately 10 compared to the regular U-Net. In
Figure 2 both modules are visualized.
3.3. Cyclindrical View
Mapping some given point cloud into a cylindrical image is similar to Equation (
1). As most used LiDAR sensors are spherical by nature, this method is not commonly used. Nevertheless, we have investigated this view for the purpose of completeness and to avoid the disadvantage of deforming physical dimensions caused by the spherical view. Since occlusion is highly relevant for this approach, we use the same idea and architecture as for the bird’s-eye approach. Instead of using
height maps, we divide the radial distance
and use it as our feature input.
5. Experiments
5.1. Evaluation Metric
For the evaluation of each model, we use the mean intersection-over-union (mIoU) given by:
with the class prediction
and the class ground truth
.
5.2. Datasets
We use three different datasets for training and evaluation. The SemanticKITTI [
43] and the ParisLille [
47] as real-world datasets and the simulation framework Carla [
48] to generate synthetic data. SemanticKITTI is used for training, and the other ones are used for generalization and knowledge transfer causes.
SemanticKITTI is a large dataset that uses a Velodyne HDL64 LiDAR mounted on top of a car pointing forward. The data were collected by KITTI [
49] in the metropolitan area of Karlsruhe. It contains more than 43 k scans that are divided into 22 sequences. The first half is commonly used for training and the second half for testing. Sequence number 8 is used for validation purposes. First, all frames are pointwise labeled into 28 classes. Next, the moving classes are merged with the non-moving classes, which leaves 19 classes, ignoring the unlabeled points.
Carla is an open-source simulation framework that has been developed for autonomous driving purposes. Since the setup and adaption of sensors are highly flexible, Carla can quickly generate training data. There are eight different maps available. Each map offers a different environment. For collecting data, the simulated sensor gets mounted on top of the car. The sensor can be adapted to comply with the specification given by the actual sensor. We created the same sensor as used in the SemanticKITTI dataset. While the car drives automatically through the environment, every time the car has traveled a distance longer than some threshold, a point cloud gets saved. This procedure is used to guarantee diverse point clouds.
ParisLille is, again, a real-world dataset. A Velodyne HDL32 Lidar, mounted at the back of the car, facing downwards, is used. Multiple scans are mapped together, which results in three large sequences (Lille1, Lille2, and Paris). All points are labeled into 50 different classes. For easier usage, we split each sequence back into the original scans and transform the annotation. The raw data is used to gather the necessary information. These provide the spherical angles and , as well as the origins of the sensor during recording. The raw data is not annotated. Therefore, we have to search for the nearest neighbor within the training data to assign the right labels. To make future comparisons easier, we further map the labels into the SemanticKITTI definition. The described procedure ends with eight sequences for Lille1, three for Lille2, and five for Paris.
We chose these three datasets for the following reasons. First, SemanticKITTI is used since it contains the most labeled points. Training will be performed on this dataset. ParisLille is selected since the sensor setup and the sensor itself differ. This allows evaluating if it is possible to transfer the learning process and the generalization for the methods. Lastly, Carla offers great flexibility with regard to collecting data in any setup without the need for labeling.
5.3. Training Details
All models and the whole training pipeline is implemented using pytorch [
50]. As the classes within the datasets are highly imbalanced, we will use a weight for each class
leading to the weighted cross-entropy loss
:
The Lovász-Softmax loss
[
51] allows for optimizing the IoU metric. It is defined as:
where
is the vector of pixel errors for class
c and
is the Lovász extension of the IoU.
To optimize for the pixel wise accuracy and the IoU, we use a linear combination of both losses .
Stochastic gradient descent (SGD) [
52] is used as an optimizer. We followed [
53] to estimated reasonable boundary values for the one cycle learning rate [
54] and used a momentum
within the range
. The L2 penalty is set to
, and a dropout probability of
is applied.
To avoid overfitting, the data gets augmented. First, we drop a random amount of points. Afterward, the x and y position of each point gets shifted by the value of , and the point cloud gets rotated around the z-axis by an angle between 30° and 330°. For the bird’s-eye view, the z position of each point gets shifted by additionally. Each augmentation but the first gets applied independently with a probability of . Note that all augmentation is applied to the point cloud and not the projection.
5.4. Single Projection
5.4.1. Spherical View
Table 1 clearly shows that it is not necessary to project the points themselves into the image. Even by only using the depth, the performance is quite good. The best results were achieved by the network, which uses the normals as an additional feature. It has to be taken into account that this model takes slightly more time for the projection itself.
Even though the results are very good in comparison to the benchmark, it must be noted that by decreasing the image size, the occlusion increases.
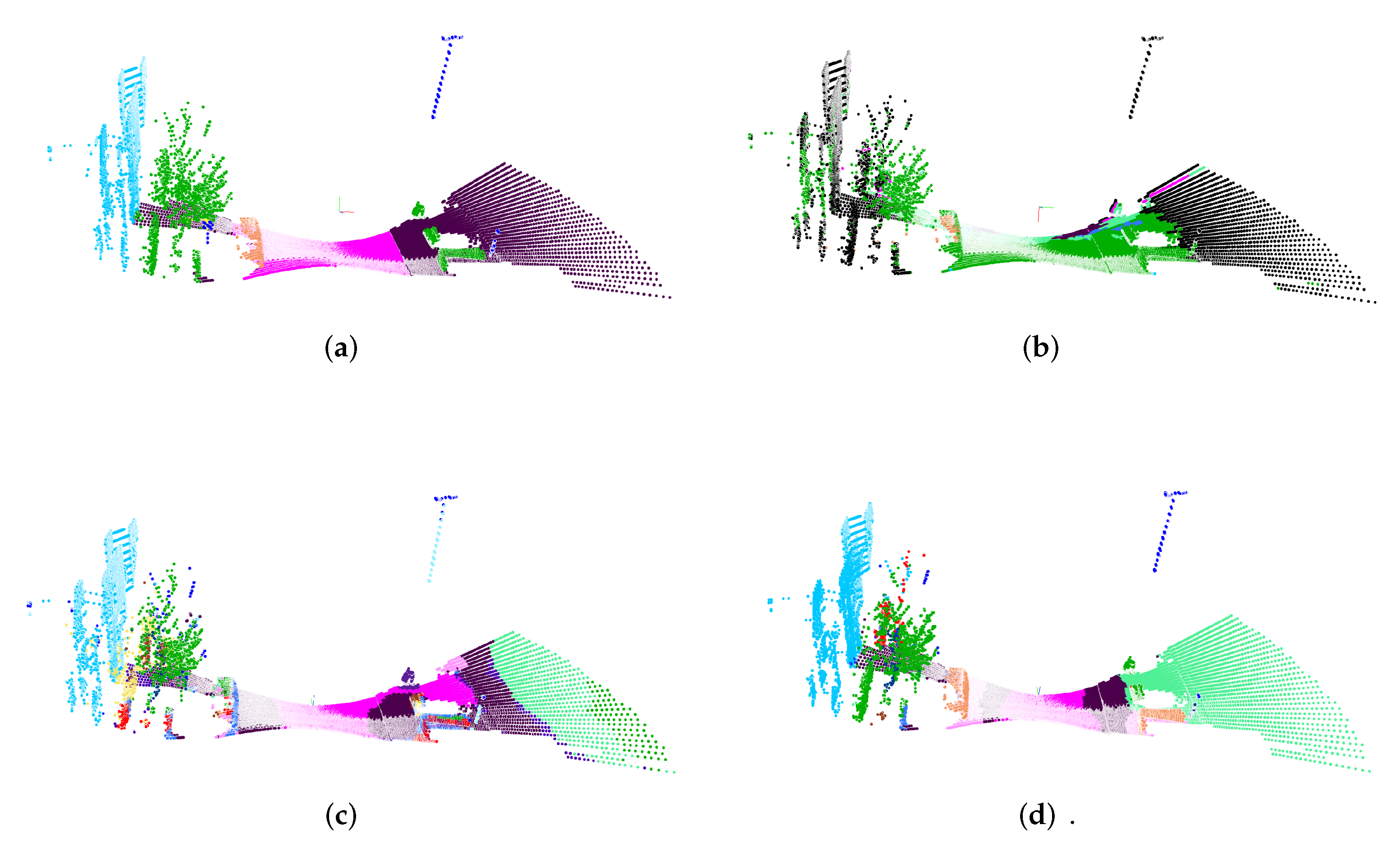
Figure 5 shows how the occlusion affects the re-projection error. Since we want to fuse the approach and compensate for such errors, the results are acceptable for now. Nevertheless, we should be careful because post-processing becomes more difficult with an increasing number of projected errors. For example, using a NN method with
neighbors could avoid the errors for the large image but not for the smaller one. It would need a larger amount of neighboring points, which would result in more computation during post-processing.
5.4.2. Bird’s-Eye View
To avoid too much unused space, we limited the range for points taking into account
for
x and
y and
for
z as we normalize around the ground plane. In
Figure 6, the depth distribution for all SemanticKITTI sequences up to sequence 10 are visualized. By taking only the points within the described range, we keep more than 97% of all points.
To compare the impact of using multiple projected images, we first trained our bird’s-eye model with three different grid sizes. The maximum height, the intensity, and the amount of points within each grid cell are used as input features. For the multi plane bird’s-eye view we voxelized the point cloud into 16 and 32 planes. As a feature, we simply projected the intensity value into each 3D cell. The results can be seen in
Table 2. Using multiple planes highly increases the mIoU.
As expected, the occlusion error highly decreases by using multiple planes instead of single planes.
Figure 5 shows that the terrain on the ground is labeled like the leaves of the tree. For the multiple plane approach, the ground gets labeled correctly, as it is not occluded. For the multi plane approach, occlusion only appears on top of the trunk.
5.4.3. Cylindrical View
The feature map is created by the distance
, which has an approximated value range of
. The value range of
z, used for the multi plane bird’s-eye projection, is about
. Comparing the ranges with each other leads to the conclusion that we have to use a larger feature map. Taking the same size would end up in an unacceptable resolution of about
m. The experiment visualized in
Figure 6 highlights that we can limit the values without losing much information. By reducing the range to
and doubling the input size for the feature map, the resolution decreases to
m or by doubling the feature map again to
m.
The experiments in
Table 3 show significant improvement by using multiple planes as feature maps. However, the results are still not comparable to the other proposed views. The IoU values from Table 6 are clear that, for the most part, small objects, such as bicycles, are very poorly recognized.
5.5. Fused Projection
The baseline, as well as the NN fusion, are non-learnable approaches. For this reason, we will only show quantitative results within
Section 5.6. For the approach of learning the fusion, we will take an input tensor of [3 × 64 × 512] or [3 × 64 × 2048] for the spherical branch and [32 × 400 × 400] or [32 × 512 × 512] for the bird’s-eye one.
5.5.1. KPConv Fusion
First, we investigated how many layers are necessary. Since the bottleneck in this approach is in the calculation of the
k NNs, we allow for up to three convolution layers. We remove the softmax function for each branch to directly use the output from the previously learned models. In
Table 4, the results for different amounts of convolution layers and for different projection branches is shown. As already suspected, the increase of occluded points caused by the decreased image size causes problems for the fusion. Even though the fusion is able to compensate for most projection errors, the overall performance does not improve. By using a larger input image for both branches, the overall performance learned by the fusion highly increases.
5.5.2. PointNet Fusion
For the PointNet fusion, we first investigate how many points are left by taking only the disagreeing ones. Taking the smaller inputs ends up with an agreement rate of about 86.4% on the whole validation set. For the larger images, the agreement rate increases to 89.1%. As expected, the agreement rate is high for classes where both networks are strong. This leads to the fact that classes, such as
,
, or
, are no longer relevant within the disagreement map. An example of the map is shown in
Figure 7.
As the PointNet model, we use only three layers of MLP’s, increasing the feature size up to 512 channels, to keep the fusion block small. Each layer is followed by batch normalization and ReLu as the activation function. The whole block has approximately 150 k parameters.
The results are shown in
Table 5. By using the smaller input images, the performance is weak. Our PointNet model is not able to compensate errors, and does not provide any further advantage. The results are pretty much comparable to those with only just taking the agreeing points and assigning the disagreeing ones as unlabeled.
5.6. Comparison
The achieved results for each model on the SemanticKITTI validation split are shown in
Table 6. The first part shows the results for our benchmark models. Within the second part, the performance of our single models is shown. The first 3D bird’s-eye uses a tensor of shape [32 × 400 × 400] and the second one [32 × 512 × 512]. Parts three and four are dedicated to the fusion results. The first fusion part uses the small and the second one the large images.
First, we compare the different views with each other. While the spherical one contains the highest information density, it suffers from deforming physical dimensions. The bird’s-eye and the cylindrical view, on the other hand, are keeping the dimensions but suffer from occluding points. Using multiple planes as input features addresses this problem but slightly increases the computation time. Nevertheless, the increase in performance is much more remarkable than the increase in computing time.
Fusing two views has proven to increase the overall performance. The baseline, the nearest neighbor, as well as the KPFusion, allow for error compensation. By using the larger input images and the KPConv as the fusion block, the highest overall performance can be achieved.
5.7. Generalization Analyses
We did figure out that the returned values for the intensity differ even in cases of using the same sensor brand. All Velodyne HDL64 are calibrated individually, making the transfer to a newer sensor almost impossible. To address this problem, the distribution of the normalized values ascribed to the intensity is visualized in the following
Figure 8. The red histogram shows the intensity distribution for the SemanticKITTI and the black histogram for the ParisLille data. While the intensity values are comparable for the classes car and building, the values are different for the classes road and vegetation.
To still investigate the generalization to new setups, we have decided to remove the intensity channel and to use only the points itself, even if we could show that this channel has high information content. To evaluate the models, we use the sequence 01, 05, 13, and 23. Some classes are not included within this data set. Therefore, these classes are ignored within the mIoU. The results for the experiments are shown in
Table 7. Column
indicates the results that were achieved on the validation set from the SemantiKITTI data. Due to the different sensor setup, the bird’s-eye projection without the plane detection achieves poor results. Adding this feature increases the mIoU, but the performance is still poor compared to the results achieved within the SemanticKITTI evaluation. Even the multi plane bird’s-eye projection is not able to further improve the performance. Nevertheless, the model with the highest score on the SemanticKITTI evaluation has the poorest performance. An example for the predictions is given in
Figure 9.
Carla offers high flexibility, but so far, there is no intensity value available for the simulated LiDAR module. Further, the output point cloud and the projections highly differ compared to a real sensor. Directly applying projection-based approaches has proven to be difficult. In [
55], CycleGANs [
56] are used to learn a sensor model for generating realistic bird’s-eye view images from the simulated LiDAR.
The experiment illustrates the biggest disadvantage of the projection-based approach. They highly depend on the used sensor and are not able to circumvent the problem of being invariant to permutation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Car
Car Bicycle
Bicycle Motorcycle
Motorcycle Truck
Truck Other Vehicle
Other Vehicle Person
Person Bicyclist
Bicyclist Motorcyclist
Motorcyclist Road
Road Parking
Parking Sidewalk
Sidewalk Other Ground
Other Ground Building
Building Fence
Fence Vegetation
Vegetation Trunk
Trunk Terrain
Terrain Pole
Pole Traffic Sign
Traffic Sign