
LT-FS-ID: Log-Transformed Feature Learning and Feature-Scaling-Based Machine Learning Algorithms to Predict the k-Barriers for Intrusion Detection Using Wireless Sensor Network





Abstract
:1. Introduction
- We introduced a synthetic data generation framework for a cost-effective solution.
- We estimated the relative importance score of each feature by using the regression tree ensemble approach.
- We performed the sensitivity analysis of the features using Partial Dependency Plot (PDP) analysis.
- We proposed a novel algorithm based on log-transformed feature learning and feature-scaling to accurately predict the number of barriers for fast intrusion detection and prevention. We also performed a sensitivity analysis of the proposed algorithm.
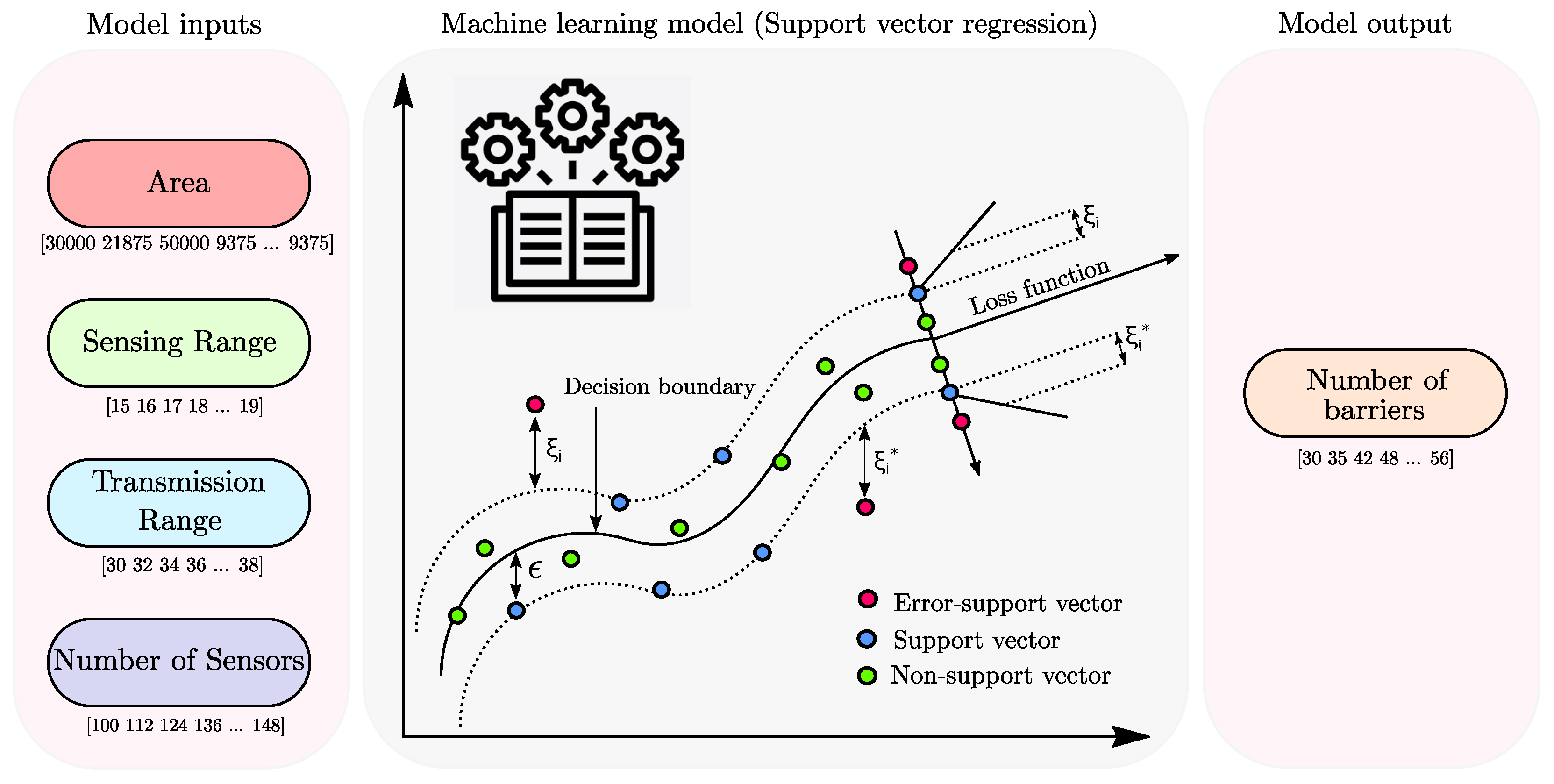
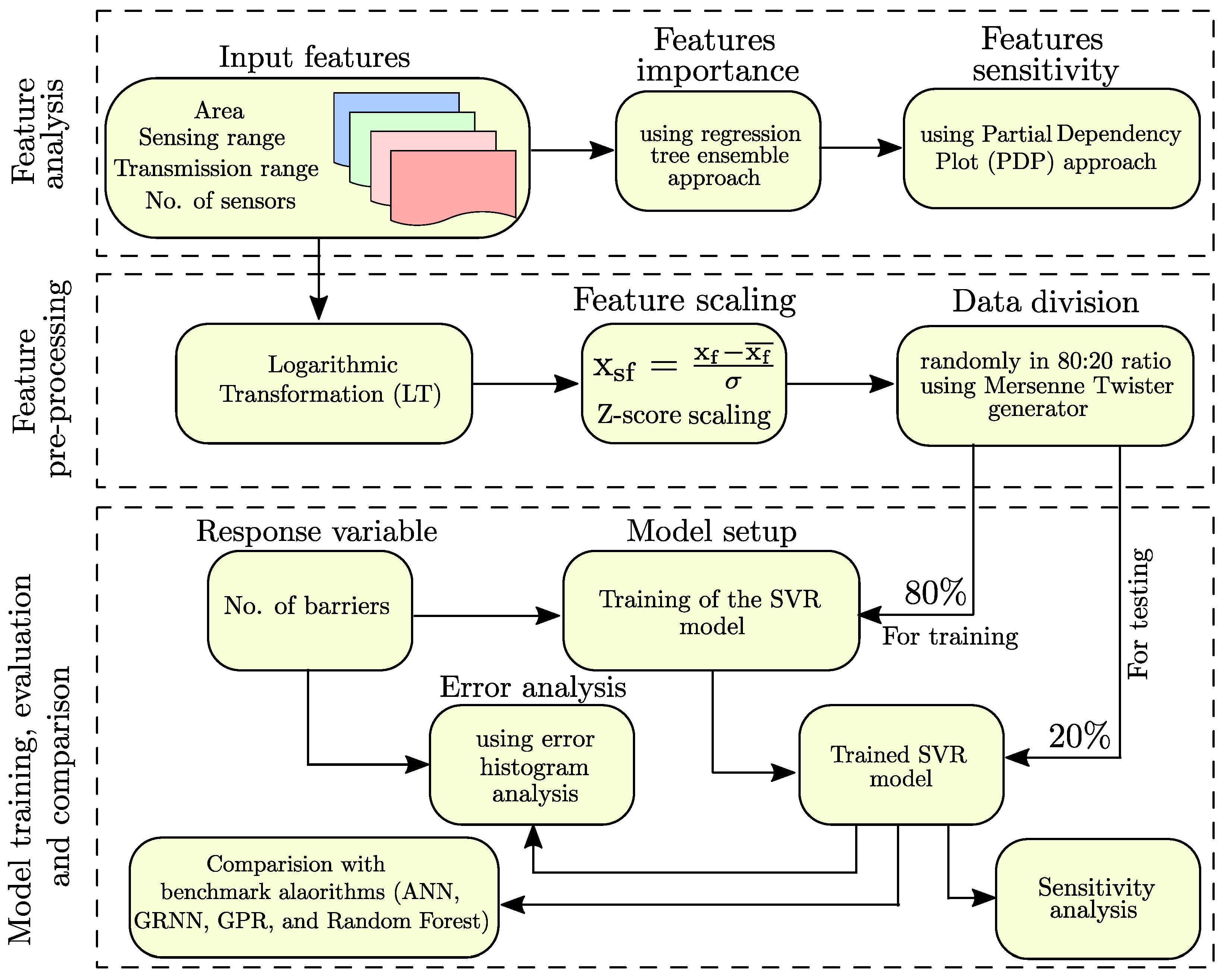
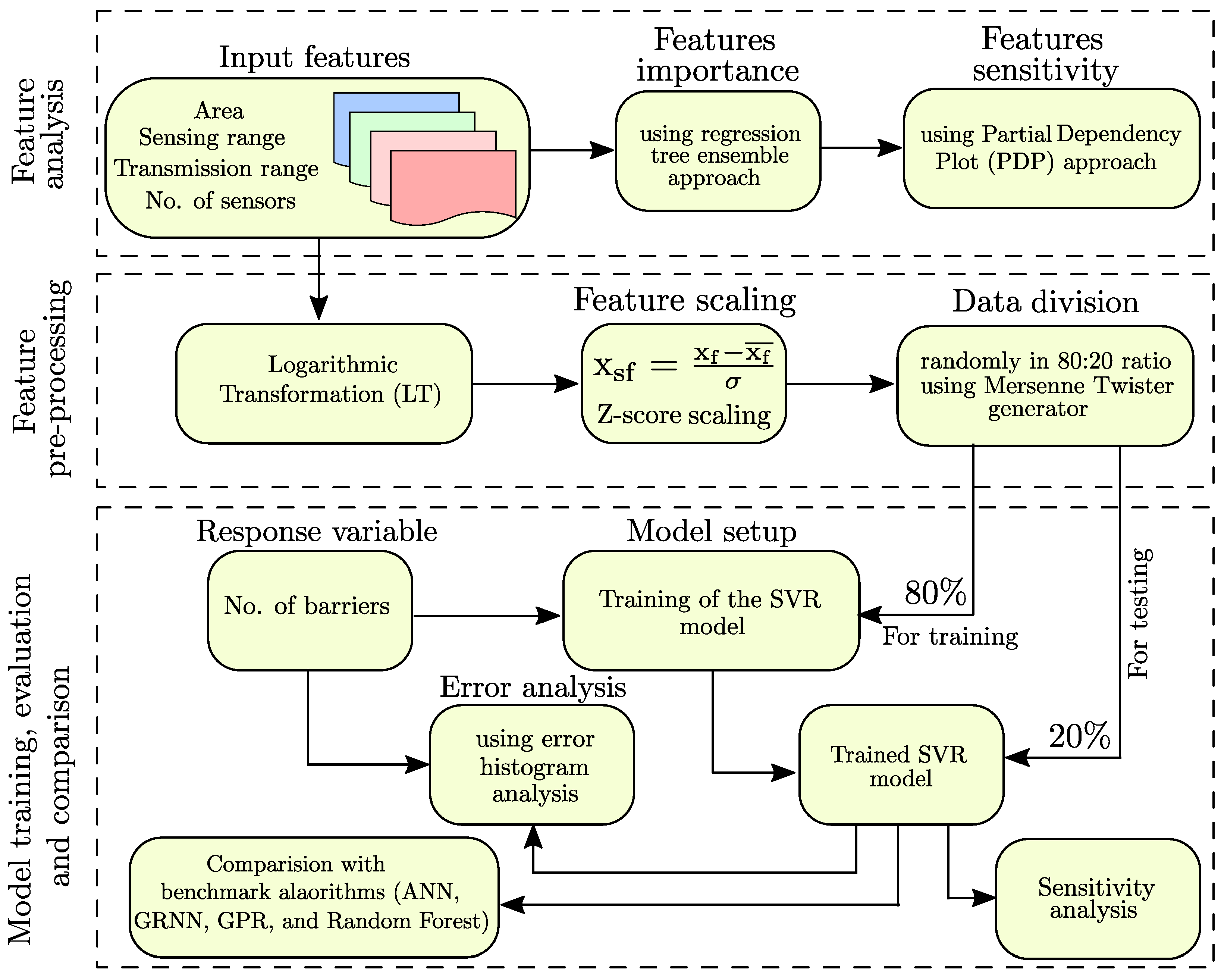
2. Material and Methods
2.1. Preparation of the Datasets
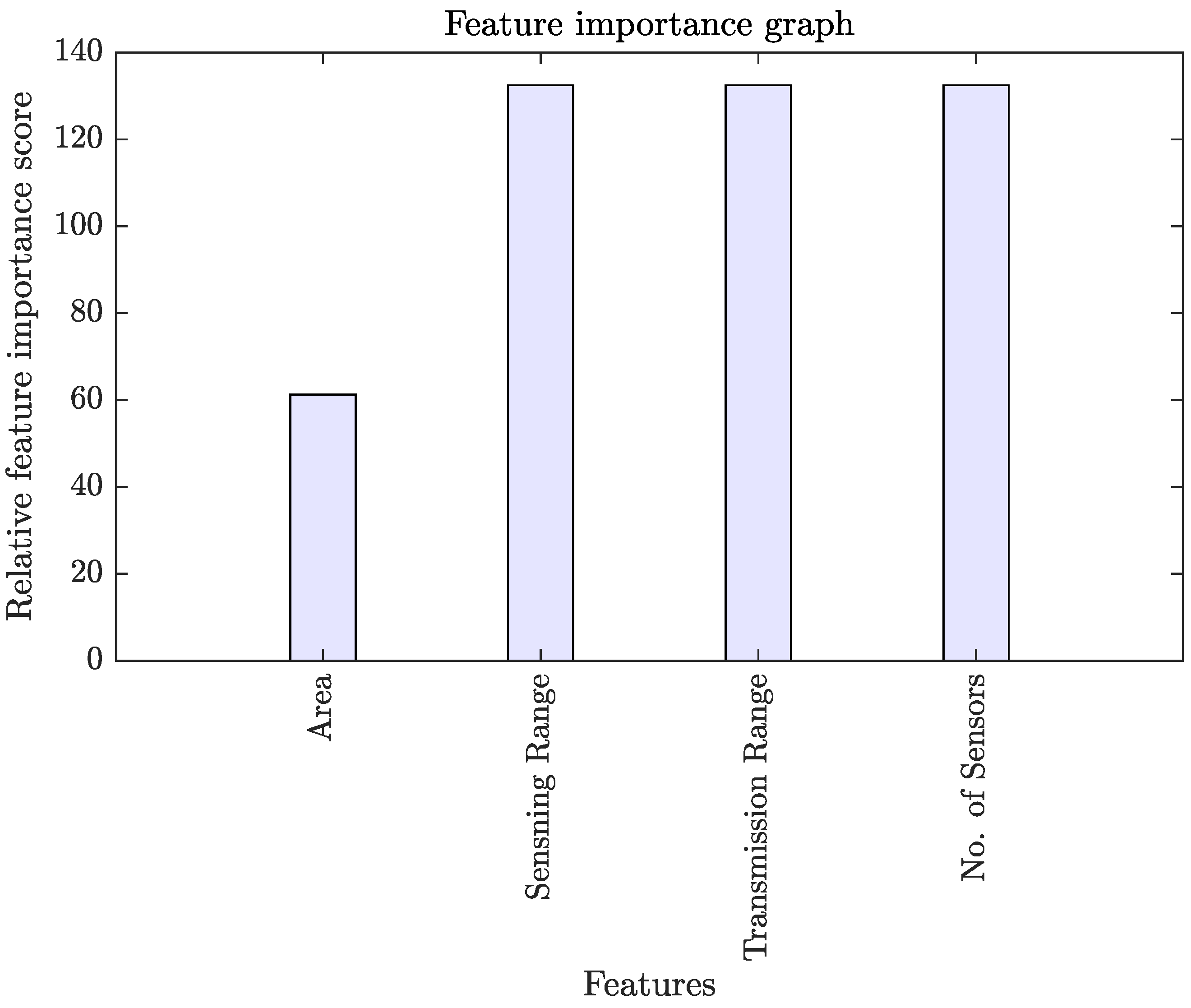
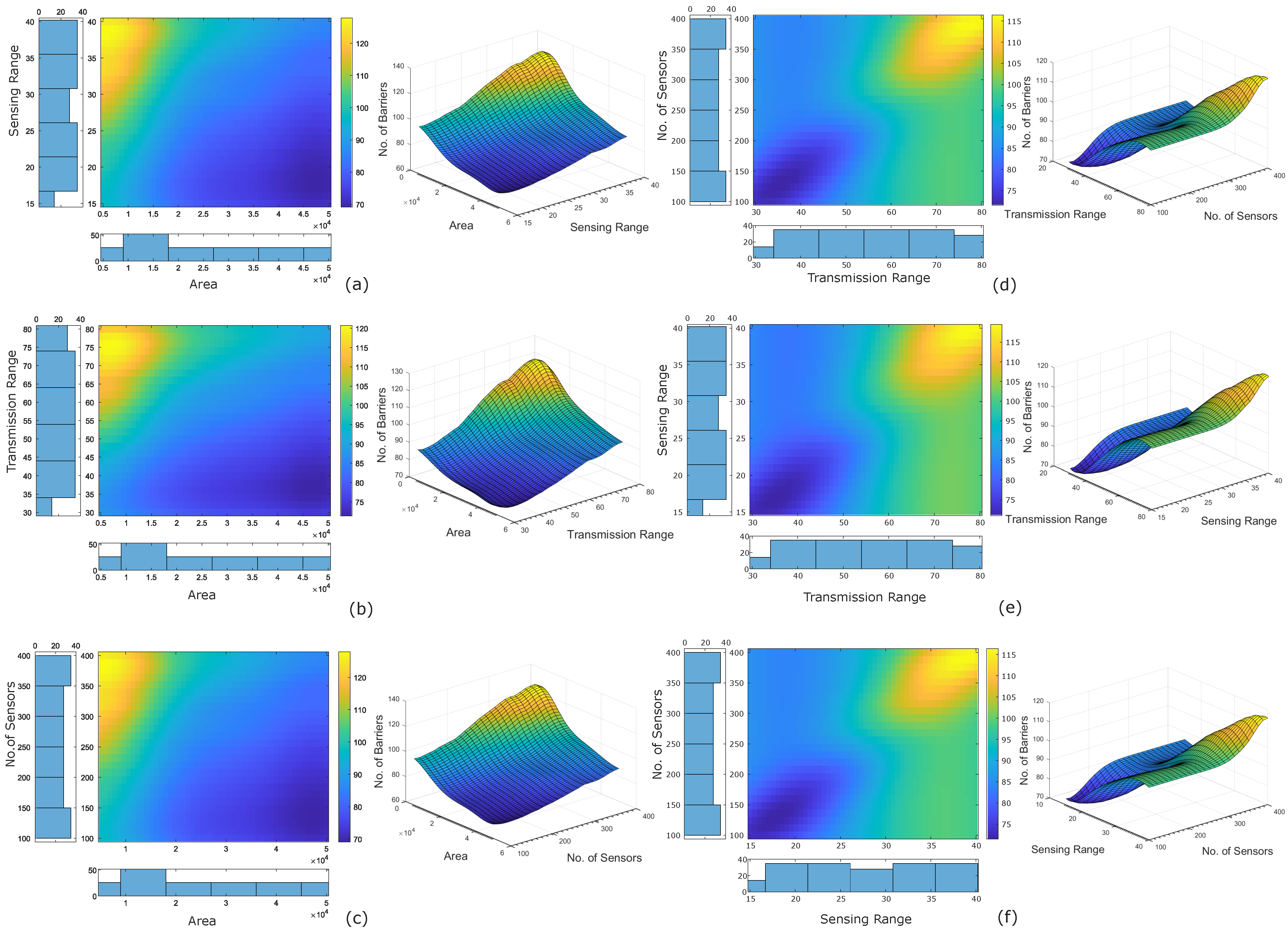
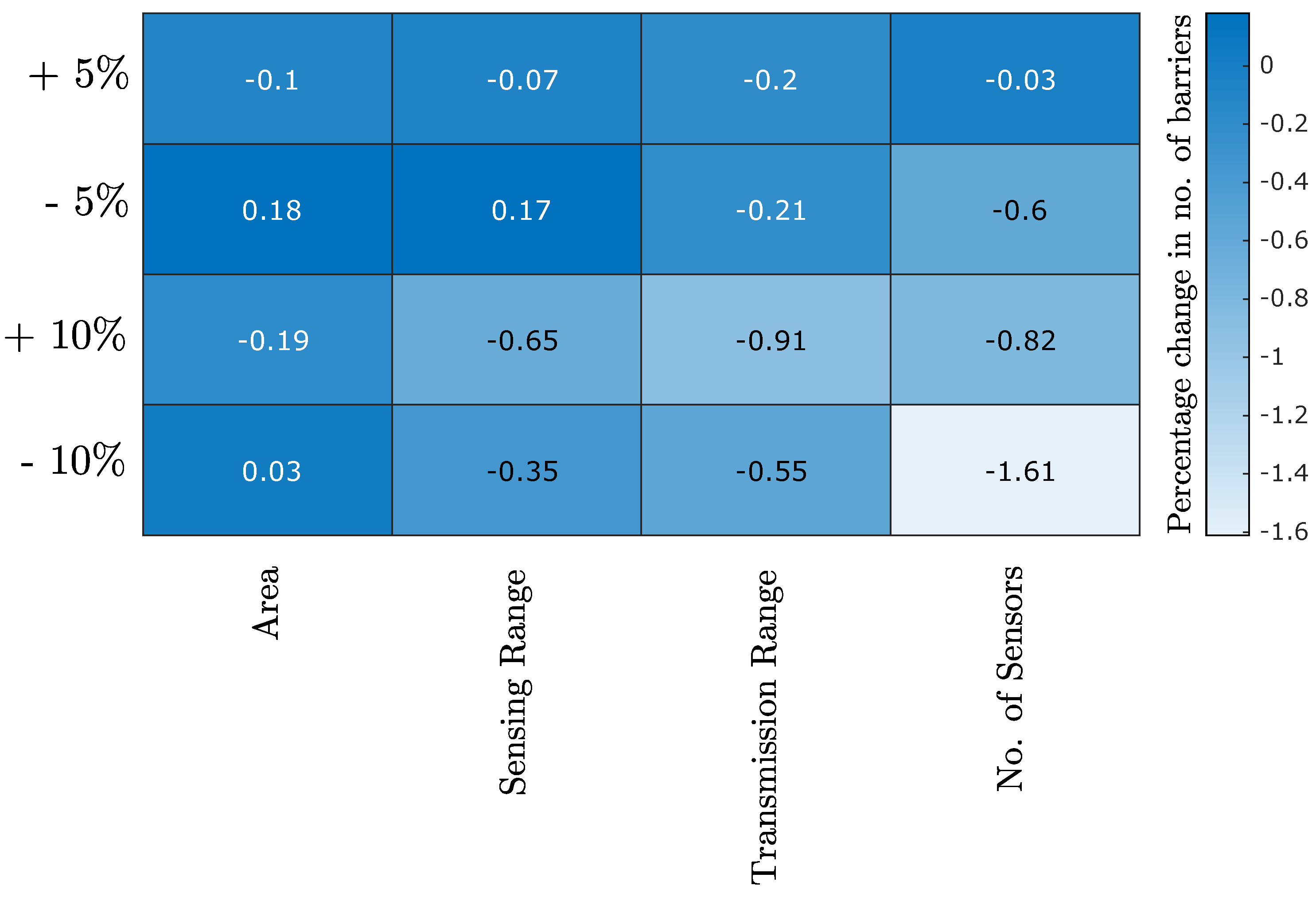
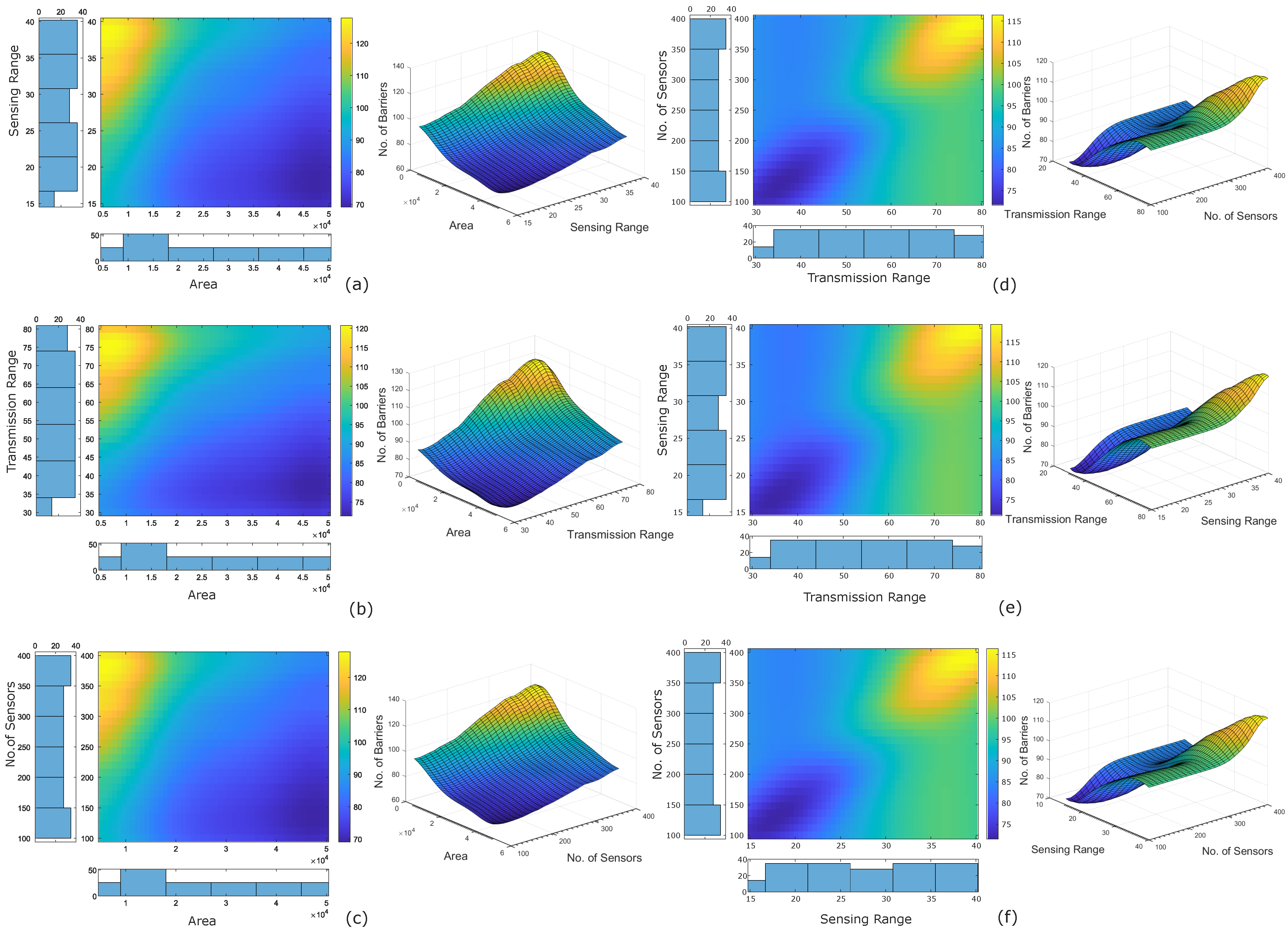
2.2. Calculation of Feature Importance and Sensitivity
2.3. SVR Model Set-Up
- We synthetically generated the input features (i.e., area of the RoI, sensing range of the sensors, transmission range of the sensor, and the number of sensors) through Monte Carlo simulations.
- We trained a regression tree ensemble to estimate each feature’s relative feature importance score.
- We leverage PDP analysis to perform the sensitivity analysis of each feature.
- We applied feature scaling on the selected features post log transformation.
- We used the Mersenne Twister generator with a random seed to randomly divide the datasets for training and testing the model in a ratio of 80:20.
- We used 80% of the datasets to set up the machine learning model.
- We used the remaining 20% of the datasets to test the performance of the trained model.
- We performed the sensitivity analysis of the trained model.
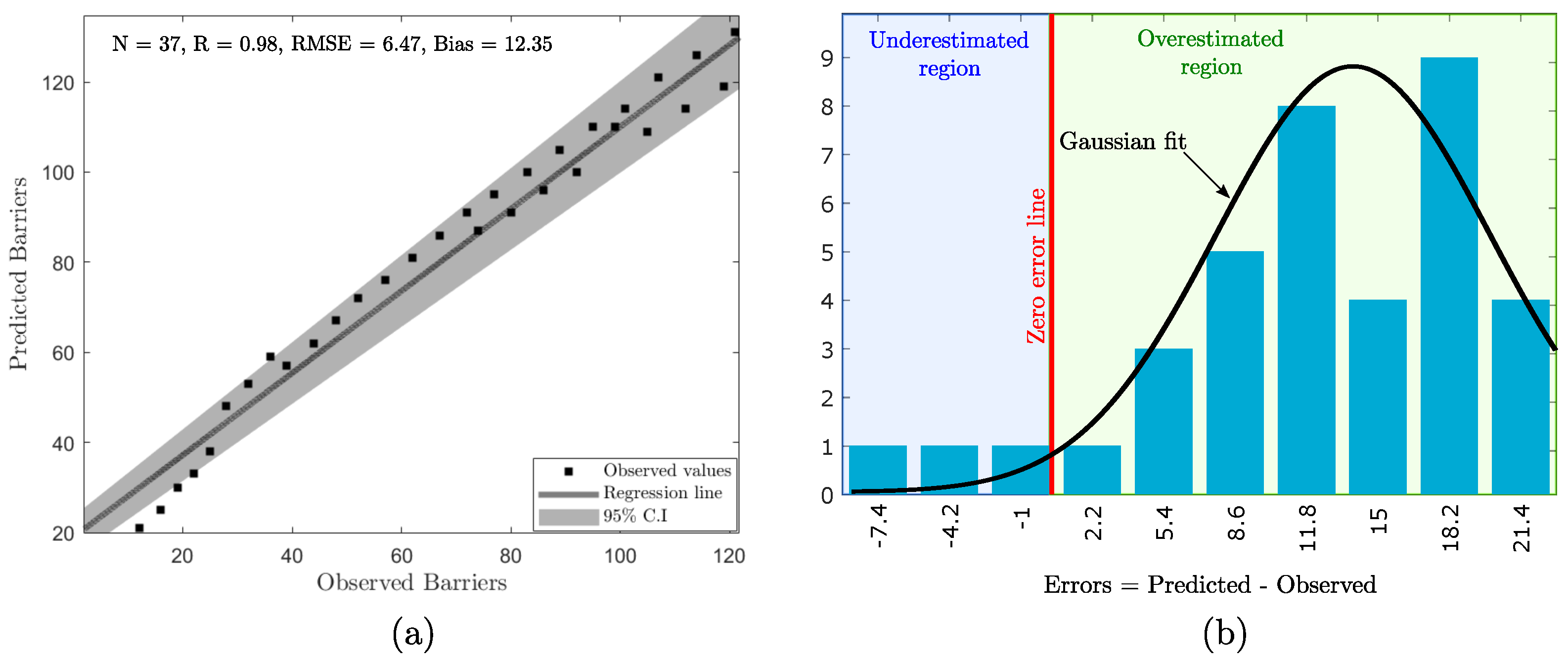
- We performed the error analysis using error histogram analysis to understand the distribution of the errors.
- We compared the performance of the trained model with the benchmark algorithms (i.e., ANN, GRNN, GPR, and Random Forest).
3. Results
3.1. Feature Importance and Sensitivity
3.2. Model Performance
4. Discussion
4.1. Comparison with Other Scaling Methods
4.2. Comparison with Benchmark Algorithms
4.3. Sensitivity Analysis of the LT-ZM-SVR
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mostafaei, H.; Chowdhury, M.U.; Obaidat, M.S. Border surveillance with WSN systems in a distributed manner. IEEE Syst. J. 2018, 12, 3703–3712. [Google Scholar] [CrossRef]
- Lee, S.; Jain, S.; Yuan, Y.; Zhang, Y.; Yang, H.; Liu, J.; Son, Y.J. Design and development of a DDDAMS-based border surveillance system via UVs and hybrid simulations. Expert Syst. Appl. 2019, 128, 109–123. [Google Scholar] [CrossRef]
- Sharma, M.K.; Singal, G.; Gupta, S.K.; Chandraneil, B.; Agarwal, S.; Garg, D.; Mukhopadhyay, D. INTERVENOR: Intelligent Border Surveillance using Sensors and Drones. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Pune, India, 2–4 April 2021; pp. 1–7. [Google Scholar]
- Komar, C.; Donmez, M.Y.; Ersoy, C. Detection quality of border surveillance wireless sensor networks in the existence of trespassers’ favorite paths. Comput. Commun. 2012, 35, 1185–1199. [Google Scholar] [CrossRef]
- Nagar, J.; Chaturvedi, S.K.; Soh, S. An analytical framework with border effects to estimate the connectivity performance of finite multihop networks in shadowing environments. Cluster Comput. 2021, 25, 187–202. [Google Scholar] [CrossRef]
- Singh, A.; Sharma, S.; Singh, J.; Kumar, R. Mathematical modelling for reducing the sensing of redundant information in WSNs based on biologically inspired techniques. J. Intell. Fuzzy Syst. 2019, 37, 6829–6839. [Google Scholar] [CrossRef]
- Nagar, J.; Chaturvedi, S.K.; Soh, S. Wireless Multihop Network Coverage Incorporating Boundary and Shadowing Effects. IETE Tech. Rev. 2021, 1–16. [Google Scholar] [CrossRef]
- Singh, A.; Sharma, S.; Singh, J. Nature-inspired algorithms for wireless sensor networks: A comprehensive survey. Comput. Sci. Rev. 2021, 39, 100342. [Google Scholar] [CrossRef]
- Kandris, D.; Nakas, C.; Vomvas, D.; Koulouras, G. Applications of wireless sensor networks: An up-to-date survey. Appl. Syst. Innov. 2020, 3, 14. [Google Scholar] [CrossRef] [Green Version]
- Kotiyal, V.; Singh, A.; Sharma, S.; Nagar, J.; Lee, C.C. ECS-NL: An Enhanced Cuckoo Search Algorithm for Node Localisation in Wireless Sensor Networks. Sensors 2021, 21, 3576. [Google Scholar] [CrossRef] [PubMed]
- Amutha, J.; Sharma, S.; Sharma, S.K. Strategies based on various aspects of clustering in wireless sensor networks using classical, optimization and machine learning techniques: Review, taxonomy, research findings, challenges and future directions. Comput. Sci. Rev. 2021, 40, 100376. [Google Scholar] [CrossRef]
- Wang, Y.; Fu, W.; Agrawal, D.P. Gaussian versus uniform distribution for intrusion detection in wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 342–355. [Google Scholar] [CrossRef]
- Sharma, A.; Chauhan, S. Sensor fusion for distributed detection of mobile intruders in surveillance wireless sensor networks. IEEE Sens. J. 2020, 20, 15224–15231. [Google Scholar] [CrossRef]
- Nurellari, E.; Licea, D.B.; Ghogho, M.; Rivero-Angeles, M.E. On Trajectory Design for Intruder Detection in Wireless Mobile Sensor Networks. IEEE Trans. Signal Inf. Process. Netw. 2021, 7, 236–248. [Google Scholar] [CrossRef]
- Amutha, J.; Nagar, J.; Sharma, S. A distributed border surveillance (dbs) system for rectangular and circular region of interest with wireless sensor networks in shadowed environments. Wirel. Pers. Commun. 2021, 117, 2135–2155. [Google Scholar] [CrossRef]
- Singh, R.; Singh, S. Smart border surveillance system using wireless sensor networks. Int. J. Syst. Assur. Eng. Manag. 2021, 1–15. [Google Scholar] [CrossRef]
- Vadivelan, N.; Taware, M.S.; Chakravarthi, M.R.R.; Palagan, C.A.; Gupta, S. A border surveillance system to sense terrorist outbreaks. Comput. Electr. Eng. 2021, 94, 107355. [Google Scholar] [CrossRef]
- Sharma, S.; Nagar, J. Intrusion detection in mobile sensor networks: A case study for different intrusion paths. Wirel. Pers. Commun. 2020, 115, 2569–2589. [Google Scholar] [CrossRef]
- Karthy, G.; Harish, M.; Harish, R.; Srivarshan, R.N.; Sridhar, B. BORS (Border Patrol Search) ROBOT by using Wireless Technology. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 449–456. [Google Scholar]
- Roman, R.C.; Precup, R.E.; Petriu, E.M. Hybrid data-driven fuzzy active disturbance rejection control for tower crane systems. Eur. J. Control 2021, 58, 373–387. [Google Scholar] [CrossRef]
- Zhu, Z.; Pan, Y.; Zhou, Q.; Lu, C. Event-triggered adaptive fuzzy control for stochastic nonlinear systems with unmeasured states and unknown backlash-like hysteresis. IEEE Trans. Fuzzy Syst. 2020, 29, 1273–1283. [Google Scholar] [CrossRef]
- Singh, A.; Nagar, J.; Sharma, S.; Kotiyal, V. A Gaussian process regression approach to predict the k-barrier coverage probability for intrusion detection in wireless sensor networks. Expert Syst. Appl. 2021, 172, 114603. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.; Botti, S.; Marques, M.A. Recent advances and applications of machine learning in solid-state materials science. Npj Comput. Mater. 2019, 5, 1–36. [Google Scholar] [CrossRef]
- Nikolenko, S.I. Synthetic data for deep learning. arXiv 2019, arXiv:1909.11512. [Google Scholar]
- Chen, R.J.; Lu, M.Y.; Chen, T.Y.; Williamson, D.F.; Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 2021, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Rankin, D.; Black, M.; Bond, R.; Wallace, J.; Mulvenna, M.; Epelde, G. Reliability of supervised machine learning using synthetic data in health care: Model to preserve privacy for data sharing. JMIR Med. Inform. 2020, 8, e18910. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Kotiyal, V.; Sharma, S.; Nagar, J.; Lee, C.C. A machine learning approach to predict the average localization error with applications to wireless sensor networks. IEEE Access 2020, 8, 208253–208263. [Google Scholar] [CrossRef]
- Abay, N.C.; Zhou, Y.; Kantarcioglu, M.; Thuraisingham, B.; Sweeney, L. Privacy preserving synthetic data release using deep learning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 510–526. [Google Scholar]
- Zou, Y.; Chakrabarty, K. Sensor deployment and target localization in distributed sensor networks. ACM Trans. Embed. Comput. Syst. (TECS) 2004, 3, 61–91. [Google Scholar] [CrossRef]
- Singh, A.; Gaurav, K.; Rai, A.K.; Beg, Z. Machine learning to estimate surface roughness from satellite images. Remote Sens. 2021, 13, 3794. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Garg, R.; Kumar, A.; Bansal, N.; Prateek, M.; Kumar, S. Semantic segmentation of PolSAR image data using advanced deep learning model. Sci. Rep. 2021, 11, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Hong, W.C. Electric load forecasting by seasonal recurrent SVR (support vector regression) with chaotic artificial bee colony algorithm. Energy 2011, 36, 5568–5578. [Google Scholar] [CrossRef]
- Heinonen, M.; Mannerström, H.; Rousu, J.; Kaski, S.; Lähdesmäki, H. Non-stationary gaussian process regression with hamiltonian monte carlo. In Artificial Intelligence and Statistics; PMLR: New York, NY, USA, 2016; pp. 732–740. [Google Scholar]
- Syarif, I.; Prugel-Bennett, A.; Wills, G. SVM parameter optimization using grid search and genetic algorithm to improve classification performance. Telkomnika 2016, 14, 1502. [Google Scholar] [CrossRef]
- Reed, R.; MarksII, R.J. Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Zhan, T.; Gong, M.; Jiang, X.; Li, S. Log-based transformation feature learning for change detection in heterogeneous images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1352–1356. [Google Scholar] [CrossRef]
- Benardos, P.; Vosniakos, G.C. Optimizing feedforward artificial neural network architecture. Eng. Appl. Artif. Intell. 2007, 20, 365–382. [Google Scholar] [CrossRef]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasmussen, C.E. Gaussian Processes in Machine Learning. In Advanced Lectures on Machine Learning; Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]
- Quinonero-Candela, J.; Rasmussen, C.E. A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res. 2005, 6, 1939–1959. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Zhang, X.; Xie, F. Research on Location Algorithm Based on Beacon Filtering Combining DV-Hop and Multidimensional Support Vector Regression. Sensors 2021, 21, 5335. [Google Scholar] [CrossRef]
- Gupta, N.; Khosravy, M.; Patel, N.; Dey, N.; Crespo, R.G. Lightweight Computational Intelligence for IoT Health Monitoring of Off-Road Vehicles: Enhanced Selection Log-scaled Mutation GA Structured ANN. IEEE Trans. Ind. Inf. 2021, 18, 611–619. [Google Scholar] [CrossRef]
- Dibaei, M.; Zheng, X.; Xia, Y.; Xu, X.; Jolfaei, A.; Bashir, A.K.; Tariq, U.; Yu, D.; Vasilakos, A.V. Investigating the prospect of leveraging blockchain and machine learning to secure vehicular networks: A survey. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Simulator | NS-2.35 |
| Network region | Rectangular RoI |
| Network area () | 100 × 50 to 250 × 200 |
| Number of sensors (N) | 100 to 400 |
| Sensing range (Rs) | 15 to 40 |
| Transmission range (Rtx) | 30 to 80 |
| Sensor’s deployment type | Uniform distribution |
| Sensing model | Binary sensing model |
| Performance Metrics | LT-NS-SVR | LT-CM-SVR | LT-ZM-SVR | LT-MM-SVR |
|---|---|---|---|---|
| R | 0.96 | 0.94 | 0.98 | 0.97 |
| RMSE | 12.66 | 2.39 | 6.47 | 4.59 |
| MSE | 160.15 | 5.727 | 41.87 | 21.10 |
| Bias | 36.30 | 6.24 | 12.35 | 15.62 |
| Time (s) | 2.21 | 0.59 | 0.65 | 0.51 |
| Performance Metrics | Methods | ||||
|---|---|---|---|---|---|
| LT-ZM-SVR | ANN | GRNN | GPR | Random Forest | |
| R | 0.98 | 0.38 | 0.96 | 0.94 | 0.99 |
| RMSE | 6.47 | 46.37 | 57.56 | 63.83 | 32.15 |
| MSE | 41.87 | 2150.20 | 3312.00 | 4074.7 | 1033.6 |
| Bias | 12.35 | -36.12 | 49.62 | 50.96 | 28.62 |
| Time (s) | 0.65 | 1.81 | 2.02 | 1.71 | 2.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, A.; Amutha, J.; Nagar, J.; Sharma, S.; Lee, C.-C. LT-FS-ID: Log-Transformed Feature Learning and Feature-Scaling-Based Machine Learning Algorithms to Predict the k-Barriers for Intrusion Detection Using Wireless Sensor Network. Sensors 2022, 22, 1070. https://doi.org/10.3390/s22031070
Singh A, Amutha J, Nagar J, Sharma S, Lee C-C. LT-FS-ID: Log-Transformed Feature Learning and Feature-Scaling-Based Machine Learning Algorithms to Predict the k-Barriers for Intrusion Detection Using Wireless Sensor Network. Sensors. 2022; 22(3):1070. https://doi.org/10.3390/s22031070
Chicago/Turabian StyleSingh, Abhilash, J. Amutha, Jaiprakash Nagar, Sandeep Sharma, and Cheng-Chi Lee. 2022. "LT-FS-ID: Log-Transformed Feature Learning and Feature-Scaling-Based Machine Learning Algorithms to Predict the k-Barriers for Intrusion Detection Using Wireless Sensor Network" Sensors 22, no. 3: 1070. https://doi.org/10.3390/s22031070
APA StyleSingh, A., Amutha, J., Nagar, J., Sharma, S., & Lee, C.-C. (2022). LT-FS-ID: Log-Transformed Feature Learning and Feature-Scaling-Based Machine Learning Algorithms to Predict the k-Barriers for Intrusion Detection Using Wireless Sensor Network. Sensors, 22(3), 1070. https://doi.org/10.3390/s22031070