
Distress Detection in Subway Tunnel Images via Data Augmentation Based on Selective Image Cropping and Patching

 , , and
, , and
Abstract
:1. Introduction
2. Distress Detection Based on Selective Image Cropping and Patching
2.1. Selective Image Cropping and Patching
2.2. Distress Detection with DeepLabv2
3. Experimental Results
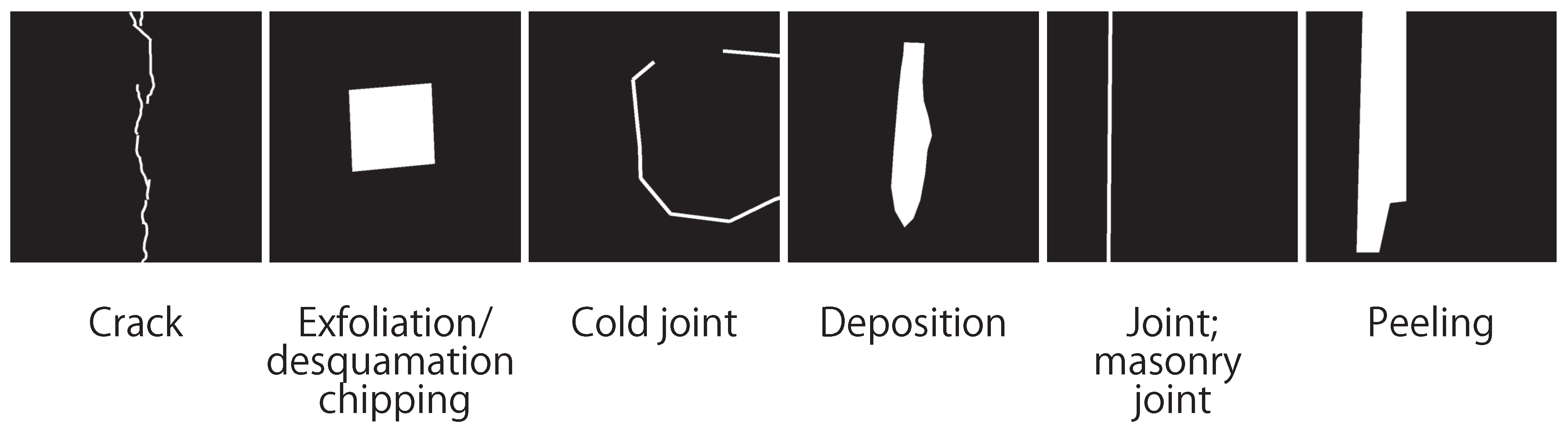
3.1. Dataset
3.2. Settings
- CM1: A method using patches obtained from images of distress of lines A and B together without data augmentation.
- CM2: A data augmentation method based on SamplePairing [49] for CM1. Two images are randomly extracted from the set of images and combined with the same transmittance.
- CM3: A data augmentation method based on SamplePairing [49] using only patches that contain regions of distress for CM1 (Selective SamplePairing).
- CM4: A data augmentation method based on Mixup [48] for CM1. Two images are randomly extracted from the set of images to be augmented, and their transmittances are determined according to the beta distribution.
- CM5: A data augmentation method based on Mixup [48] using only patches that contain regions of distress for CM1 (Selective Mixup).
- CM1: A method using patches obtained from images of distress of line A without data augmentation.
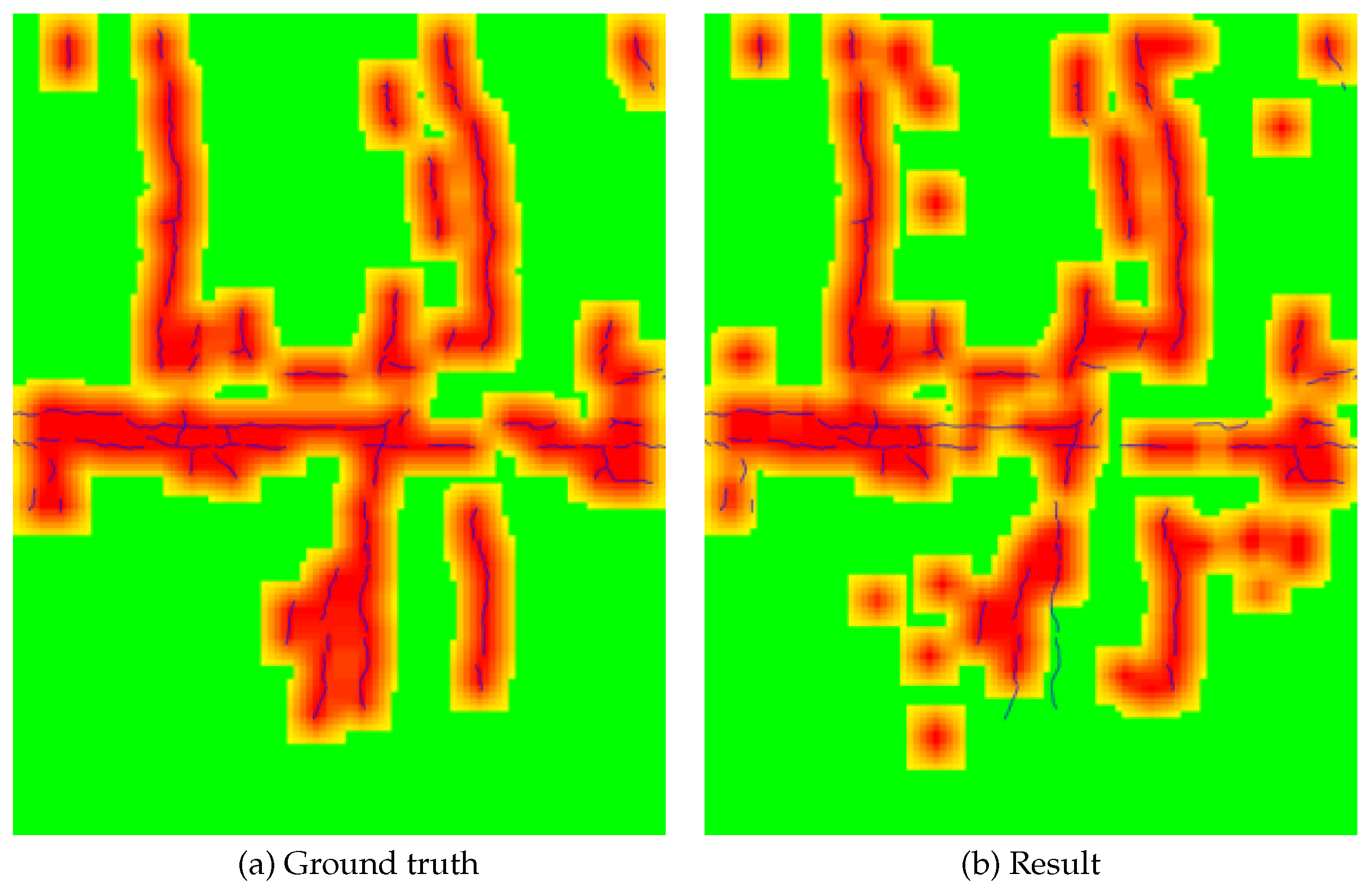
3.3. Experiment: Performing SICAP for All Kinds of Distress
3.4. Ablation Study: Performing SICAP for a Certain Kind of Distress
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, Q.; Ji, X. Automatic pixel-level crack detection for civil infrastructure using Unet++ and deep transfer learning. IEEE Sens. J. 2021, 21, 19165–19175. [Google Scholar] [CrossRef]
- Shen, B.; Zhang, W.Y.; Qi, D.P.; Wu, X.Y. Wireless multimedia sensor network based subway tunnel crack detection method. Int. J. Distrib. Sens. Netw. 2015, 11, 184639. [Google Scholar] [CrossRef]
- Dawood, T.; Zhu, Z.; Zayed, T. Deterioration mapping in subway infrastructure using sensory data of GPR. Tunn. Undergr. Space Technol. 2020, 103, 103487. [Google Scholar] [CrossRef]
- Mehta, P.K.; Burrows, R.W. Building durable structures in the 21st century. Concr. Int. 2001, 23, 57–63. [Google Scholar]
- Ministry of Land, Infrastructure Transport and Tourism. White Paper on Land, Infrastructure, Transport and Tourism in Japan, 2017 (online). 2018. Available online: http://www.mlit.go.jp/common/001269888.pdf (accessed on 13 November 2022).
- Montero, R.; Victores, J.G.; Martinez, S.; Jardón, A.; Balaguer, C. Past, present and future of robotic tunnel inspection. Autom. Constr. 2015, 59, 99–112. [Google Scholar] [CrossRef]
- Bossio, A.; Monetta, T.; Bellucci, F.; Lignola, G.P.; Prota, A. Modeling of concrete cracking due to corrosion process of reinforcement bars. Cem. Concr. Res. 2015, 71, 78–92. [Google Scholar] [CrossRef]
- Woo, S.; Chu, I.; Youn, B.; Kim, K. Development of the corrosion deterioration inspection tool for transmission tower members. KEPCO J. Electr. Power Energy 2016, 2, 293–298. [Google Scholar] [CrossRef] [Green Version]
- Pouliot, N.; Richard, P.L.; Montambault, S. LineScout technology opens the way to robotic inspection and maintenance of high-voltage power lines. IEEE Power Energy Technol. Syst. J. 2015, 2, 1–11. [Google Scholar] [CrossRef]
- Tešić, K.; Baričević, A.; Serdar, M. Non-destructive corrosion inspection of reinforced concrete using ground-penetrating radar: A review. Materials 2021, 14, 975. [Google Scholar] [CrossRef]
- Bergquist, B.; Söderholm, P. Data analysis for condition-based railway infrastructure maintenance. Qual. Reliab. Eng. Int. 2015, 31, 773–781. [Google Scholar] [CrossRef]
- Xu, P.; Sun, Q.; Liu, R.; Souleyrette, R.R.; Wang, F. Optimizing the alignment of inspection data from track geometry cars. Comput.-Aided Civ. Infrastruct. Eng. 2015, 30, 19–35. [Google Scholar] [CrossRef]
- Huang, Z.; Fu, H.; Chen, W.; Zhang, J.; Huang, H. Damage detection and quantitative analysis of shield tunnel structure. Autom. Constr. 2018, 94, 303–316. [Google Scholar] [CrossRef]
- Liu, J.; Huang, Y.; Zou, Q.; Tian, M.; Wang, S.; Zhao, X.; Dai, P.; Ren, S. Learning visual similarity for inspecting defective railway fasteners. IEEE Sens. J. 2019, 19, 6844–6857. [Google Scholar] [CrossRef]
- Ogawa, N.; Maeda, K.; Ogawa, T.; Haseyama, M. Correlation-aware attention branch network using multi-modal data for deterioration level estimation of infrastructures. In Proceedings of the IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 1014–1018. [Google Scholar]
- Ogawa, N.; Maeda, K.; Ogawa, T.; Haseyama, M. Distress image retrieval for infrastructure maintenance via self-Trained deep metric learning using experts’ knowledge. IEEE Access 2021, 9, 65234–65245. [Google Scholar] [CrossRef]
- Calderón, L.S.; Bairán, J. Crack detection in concrete elements from RGB pictures using modified line detection kernels. In Proceedings of the Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 799–805. [Google Scholar]
- Zhang, D.; Li, Q.; Chen, Y.; Cao, M.; He, L.; Zhang, B. An efficient and reliable coarse-to-fine approach for asphalt pavement crack detection. Image Vis. Comput. 2017, 57, 130–146. [Google Scholar] [CrossRef]
- Nguyen, H.N.; Kam, T.Y.; Cheng, P.Y. Automatic crack detection from 2D images using a crack measure-based B-spline level set model. Multidimens. Syst. Signal Process. 2018, 29, 213–244. [Google Scholar] [CrossRef]
- Luo, Q.; Ge, B.; Tian, Q. A fast adaptive crack detection algorithm based on a double-edge extraction operator of FSM. Constr. Build. Mater. 2019, 204, 244–254. [Google Scholar] [CrossRef]
- Nayyeri, F.; Hou, L.; Zhou, J.; Guan, H. Foreground–background separation technique for crack detection. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 457–470. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef] [Green Version]
- Qu, Z.; Guo, Y.; Ju, F.; Liu, L.; Lin, L. The algorithm of accelerated cracks detection and extracting skeleton by direction chain code in concrete surface image. Imaging Sci. J. 2016, 64, 119–130. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Kei, L.S.; Li, C. Automatic pixel-level pavement crack detection using information of multi-scale neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Hadjidemetriou, G.M.; Christodoulou, S.E.; Vela, P.A. Automated detection of pavement patches utilizing support vector machine classification. In Proceedings of the Mediterranean Electrotechnical Conference (MELECON), Limassol, Cyprus, 18–20 April 2016; pp. 1–5. [Google Scholar]
- Turkan, Y.; Hong, J.; Laflamme, S.; Puri, N. Adaptive wavelet neural network for terrestrial laser scanner-based crack detection. Autom. Constr. 2018, 94, 191–202. [Google Scholar] [CrossRef] [Green Version]
- Basavaraju, A.; Du, J.; Zhou, F.; Ji, J. A machine learning approach to road surface anomaly assessment using smartphone sensors. IEEE Sens. J. 2019, 20, 2635–2647. [Google Scholar] [CrossRef]
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Convolutional sparse coding-based deep random vector functional link network for distress classification of road structures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 654–676. [Google Scholar] [CrossRef]
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Estimation of deterioration levels of transmission towers via deep learning maximizing canonical correlation between heterogeneous features. IEEE J. Sel. Top. Signal Process. 2018, 12, 633–644. [Google Scholar] [CrossRef] [Green Version]
- Ogawa, N.; Maeda, K.; Ogawa, T.; Haseyama, M. Deterioration level estimation based on convolutional neural network using confidence-aware attention mechanism for infrastructure inspection. Sensors 2022, 22, 382. [Google Scholar] [CrossRef]
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Neural network maximizing ordinally supervised multi-view canonical correlation for deterioration level estimation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 919–923. [Google Scholar]
- Fan, X.; Wu, J.; Shi, P.; Zhang, X.; Xie, Y. A novel automatic dam crack detection algorithm based on local-global clustering. Multimed. Tools Appl. 2018, 77, 26581–26599. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Guo, X.; Hao, P. Using a random forest model to predict the location of potential damage on asphalt pavement. Appl. Sci. 2021, 11, 10396. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, A.; Togo, R.; Ogawa, T.; Haseyama, M. Detection of distress region from subway tunnel images via U-net-based deep semantic segmentation. In Proceedings of the IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 766–767. [Google Scholar]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef]
- Tizani, W.; Mawdesley, M.J. Advances and challenges in computing in civil and building engineering. Adv. Eng. Inform. 2011, 25, 569–572. [Google Scholar] [CrossRef]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z.; Qi, D.; Liu, Y. Automatic crack detection and classification method for subway tunnel safety monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef]
- Khoa, N.L.D.; Anaissi, A.; Wang, Y. Smart infrastructure maintenance using incremental tensor analysis. In Proceedings of the ACM Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 959–967. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Gong, Q.; Zhu, L.; Wang, Y.; Yu, Z. Automatic subway tunnel crack detection system based on line scan camera. Struct. Control Health Monit. 2021, 28, e2776. [Google Scholar] [CrossRef]
- Özgenel, Ç.F.; Sorguç, A.G. Performance comparison of pretrained convolutional neural networks on crack detection in buildings. In Proceedings of the International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018; Volume 35, pp. 1–8. [Google Scholar]
- Li, Z.; Togo, R.; Ogawa, T.; Haseyama, M. A note on retrieval of visually similar distress regions in subway tunnel images: Introduction of deep features extracted by semantic segmentation network. IEICE Tech. Rep. 2020, 119, 65–68. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Takahashi, R.; Matsubara, T.; Uehara, K. Data augmentation using random image cropping and patching for deep cnns. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2917–2931. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Haruyama, T.; Maeda, K.; Togo, R.; Ogawa, T.; Haseyama, M. A note on improving performance of deep learning-based distress detection for supporting maintenance of subway tunnels Accuracy verification focusing on tunnel wall characteristics. ITE Tech. Rep. 2021, 120, 1–6. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Meanings |
|---|---|
| n | Index of distress images |
| m | Index of patches |
| n-th distress image | |
| m-th patch extracted from | |
| s-th augmented patches | |
| (w, h) | Boundary position of the augmented patch |
| , | Width and height of each region extracted from patch |
| , | Width and height of patch |
| Ground truth of image |
| DA Method | Line A | Line B | |||||
|---|---|---|---|---|---|---|---|
| Crack | Others | Average | Crack | Others | Average | ||
| CM1 | - | 0.2600 | 0.4884 | 0.3741 | 0.2278 | 0.6201 | 0.4240 |
| CM2 | SamplePairing [49] | 0.2878 | 0.3168 | 0.3023 | 0.2084 | 0.5862 | 0.3973 |
| CM3 | Selective SamplePairing | 0.2763 | 0.3872 | 0.3318 | 0.1827 | 0.6471 | 0.4149 |
| CM4 | Mixup [48] | 0.2751 | 0.4443 | 0.3597 | 0.2365 | 0.6073 | 0.4219 |
| CM5 | Selective Mixup | 0.2479 | 0.2514 | 0.2497 | 0.1270 | 0.5254 | 0.3262 |
| CM6 | RICAP [50] | 0.2781 | 0.5177 | 0.3979 | 0.2467 | 0.6229 | 0.4348 |
| PM | SICAP | 0.2983 | 0.5120 | 0.4052 | 0.2171 | 0.6547 | 0.4359 |
| DA Method | Number of Patches | IoU | ||||||
|---|---|---|---|---|---|---|---|---|
| No Distress | Crack | Peeling | Others | Crack | Peeling | Others | ||
| CM1 | - | 75,265 | 19,304 | 3555 | 2483 | 0.3417 | 0.1018 | 0.4332 |
| CM2 | RICAP [50] | 151,075 | 51,830 | 12,800 | 7730 | 0.3236 | 0.1147 | 0.4096 |
| PM-All | SICAP | 151,075 | 94,899 | 46,007 | 33,445 | 0.3094 | 0.1355 | 0.4982 |
| PM-Crack | SICAP | 94,569 | 38,608 | 3555 | 2483 | 0.3503 | 0.1242 | 0.4635 |
| PM-Peeling | SICAP | 91,014 | 19,304 | 19,304 | 2483 | 0.3219 | 0.1583 | 0.4098 |
| PM-Others | SICAP | 92,086 | 19,304 | 3555 | 19,034 | 0.3355 | 0.1423 | 0.5036 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maeda, K.; Takada, S.; Haruyama, T.; Togo, R.; Ogawa, T.; Haseyama, M. Distress Detection in Subway Tunnel Images via Data Augmentation Based on Selective Image Cropping and Patching. Sensors 2022, 22, 8932. https://doi.org/10.3390/s22228932
Maeda K, Takada S, Haruyama T, Togo R, Ogawa T, Haseyama M. Distress Detection in Subway Tunnel Images via Data Augmentation Based on Selective Image Cropping and Patching. Sensors. 2022; 22(22):8932. https://doi.org/10.3390/s22228932
Chicago/Turabian StyleMaeda, Keisuke, Saya Takada, Tomoki Haruyama, Ren Togo, Takahiro Ogawa, and Miki Haseyama. 2022. "Distress Detection in Subway Tunnel Images via Data Augmentation Based on Selective Image Cropping and Patching" Sensors 22, no. 22: 8932. https://doi.org/10.3390/s22228932