
Using a Clustering Method to Detect Spatial Events in a Smartphone-Based Crowd-Sourced Database for Environmental Noise Assessment

Abstract
:1. Introduction
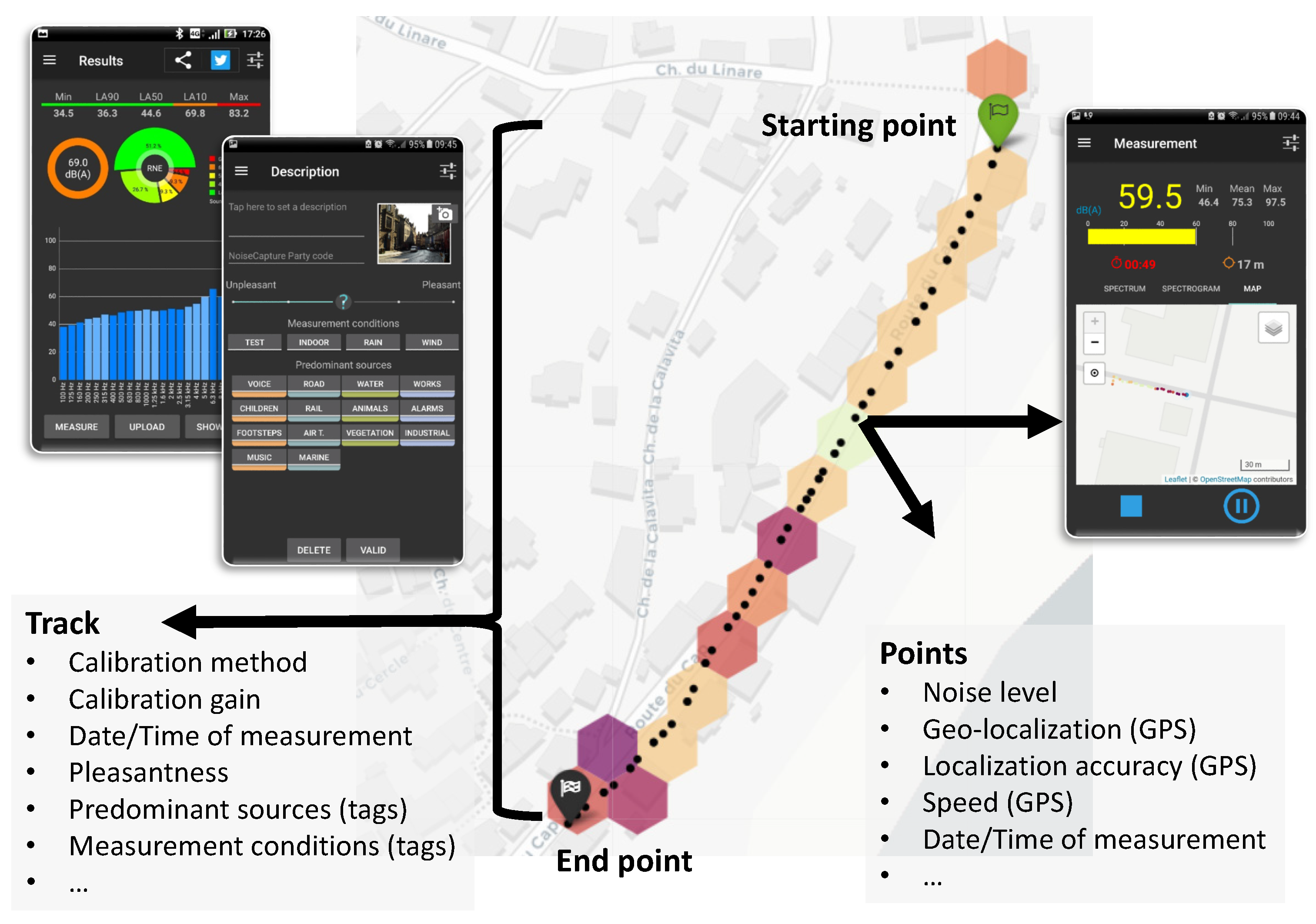
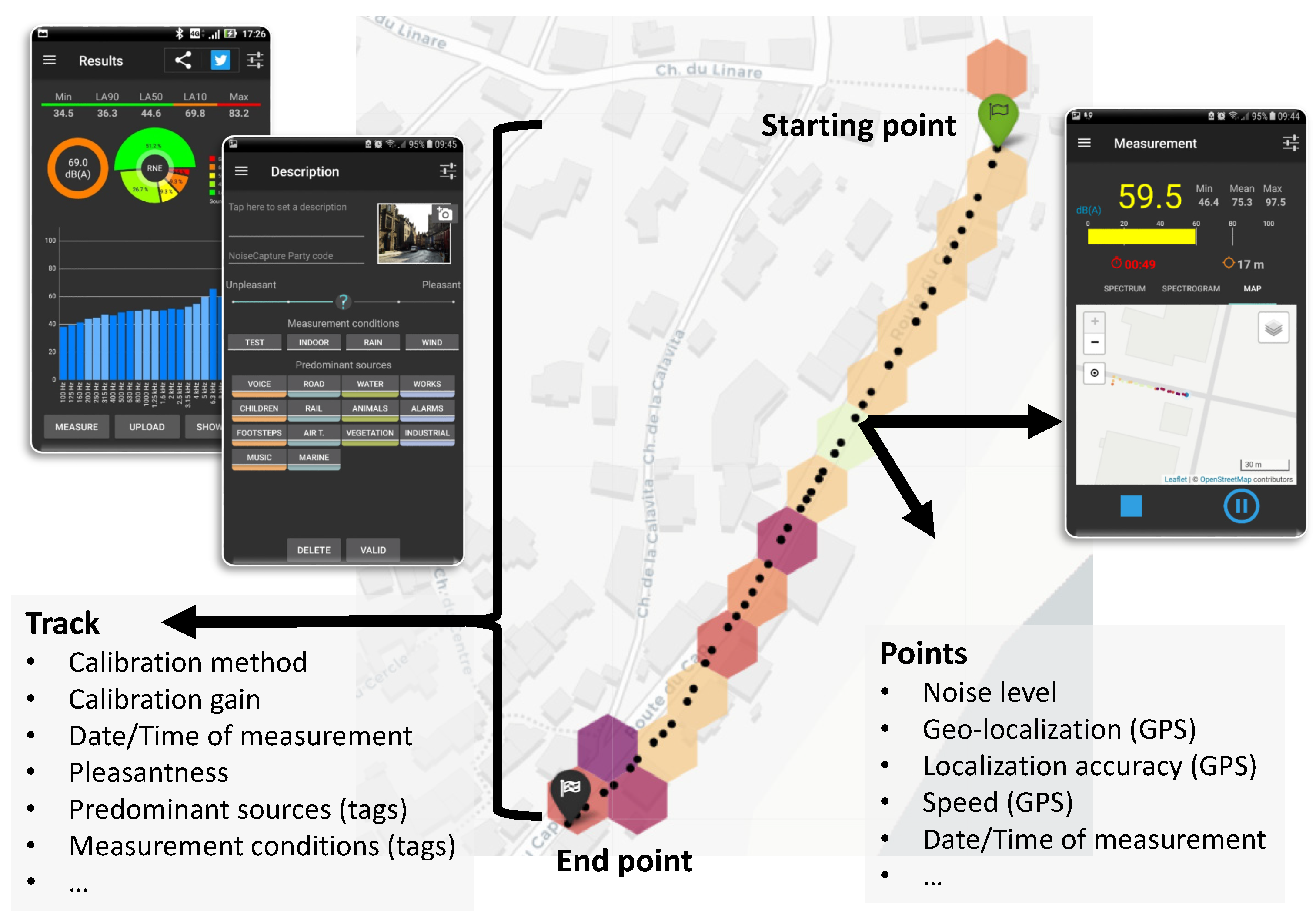
1.1. Noise Mapping Using Data Collected with Smartphones
1.2. Data Quality Control and the Need for a Reference Database
1.3. Objective of the Paper
2. Spatial Clustering Related Work
- Partition Clustering allows grouping data in K non-overlapping sub-groups (i.e., K clusters), one datum being in only one subgroup. One can consider several methodologies, for example, the K-means, K-medians, or K-medoids methods, depending on the choice of the cluster center, at the average point, the median point, or the point in the data set closest to the median point, respectively.
- Hierarchical Clustering, using the Agglomerative or the Divisive Hierarchical Clustering methods, tries to build a hierarchy of clusters using a bottom-up approach (each datum starts in its own cluster, then the two closest clusters according to a chosen distance are merged until all clusters are merged, creating a tree that one has to cut according to the relevant number of clusters) or a top-down approach (at the opposite of the bottom-up approach, all data are initially in the same cluster and, then, the cluster is split according to the hierarchy level), respectively.
- Fuzzy Clustering is another form of data clustering in which each datum can be included into several clusters. As a possible approach, the Fuzzy C-means method, which is the most widely used, is quite similar to the K-means clustering method.
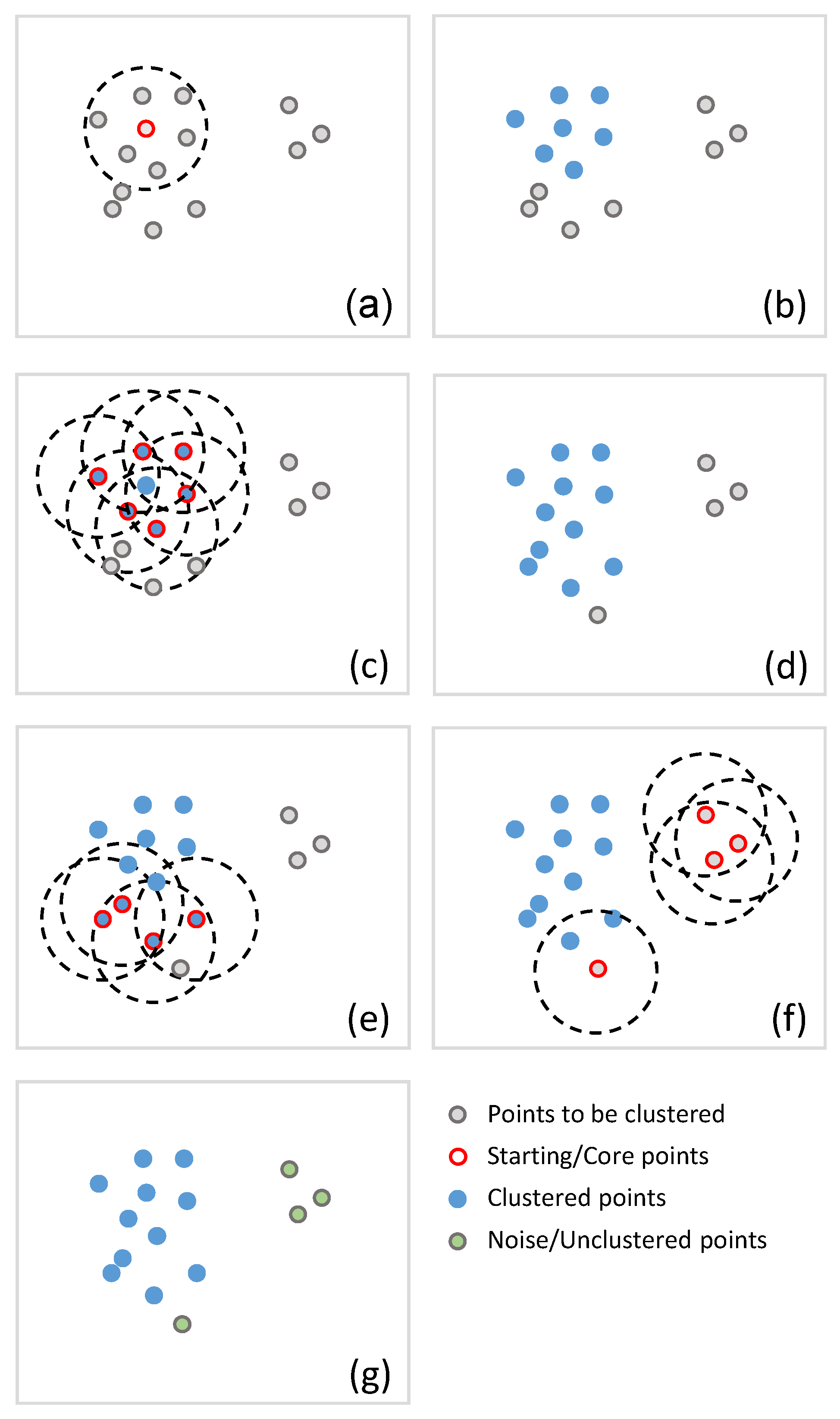
- Density-Based Clustering methods propose to group data by considering the density of data. Then, each cluster is built by considering regions with a high density of data.
- Lastly, the Model-Based Clustering method groups data by considering that they are generated by probability distributions and that each cluster represents one given distribution.
3. Spatial Clustering of the NoiseCapture Data with the DBSCAN Method
3.1. Implementation of the DBSCAN Method
3.2. NoiseCapture Database
3.3. Filtering Variables
- Time window
- The temporal dimension is not considered in the classical DBSCAN method, which implies that in the context of NC all data are considered simultaneously, just spatially, without any consideration of date. It can then be difficult to identify NC events of relatively short duration if the corresponding measurement points are ”drowned“ in the mass of data that can be collected progressively (i.e., out of a particular event), to the same spatial extent but over a long time. As mentioned above, the past NC parties have durations of a few days. Thus, it seems interesting to test the DBSCAN methodology, filtering the NC database to focus only on data collected over a ”day“, a ”week“ or a ”month“.
- GPS accuracy
- The accuracy of the DBSCAN method is necessarily based on the accuracy of the location of the measurement points; if the points are poorly located, then their membership in a cluster may be questioned. In the NC application, the localization of the measurement is based on the GPS system of the smartphone. In some cases, the measurement points may not be located at all; in this case, as mentioned before, the corresponding measurement points were removed from the database. For the remaining points, the associated location uncertainty can reach several tens of meters. The variable related to the accuracy of localization can also be an important element in the quality of the clusters obtained by the DBSCAN method. The method will therefore also be tested by filtering the data on the GPS accuracy values.
- Zone of study
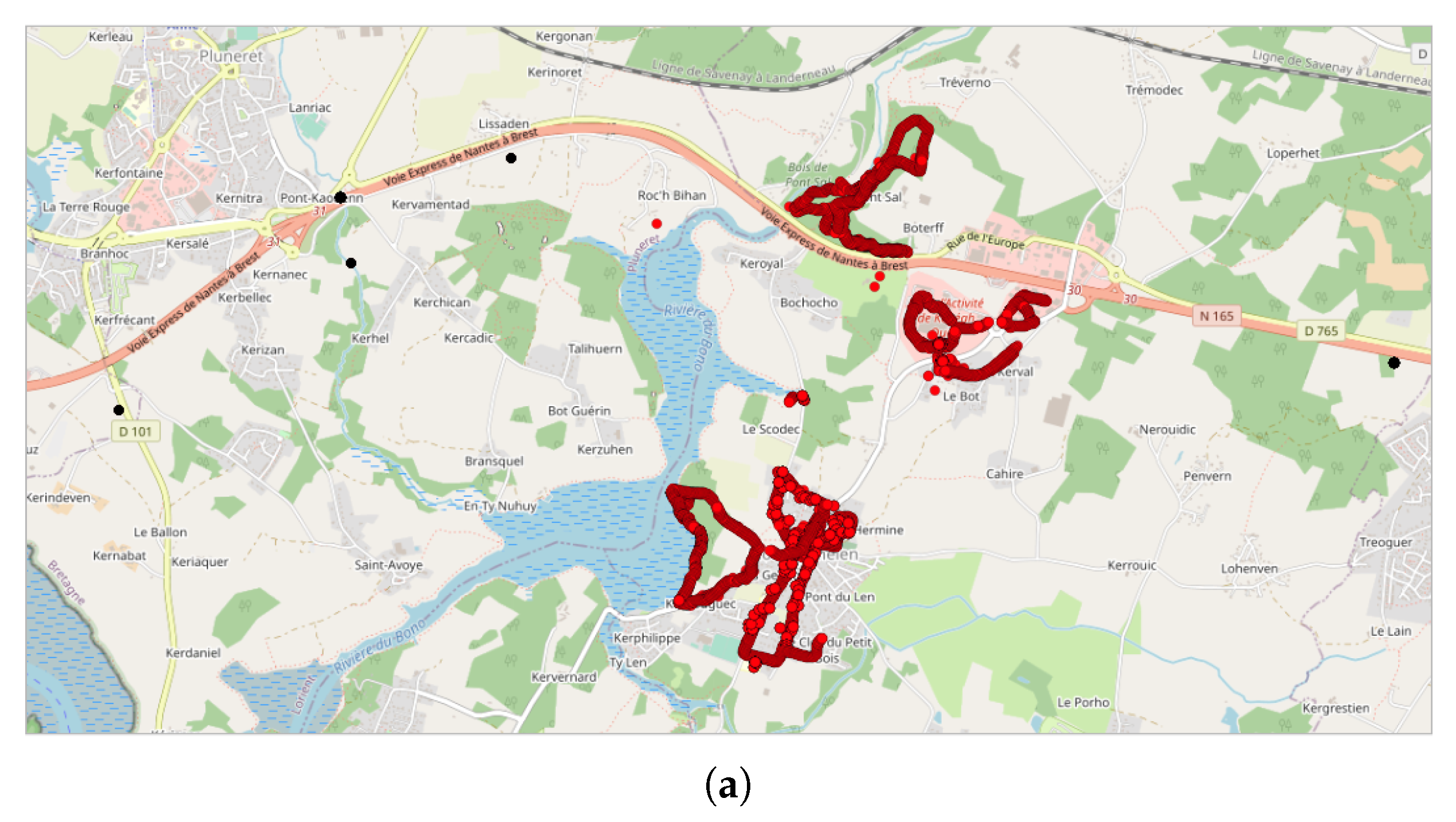
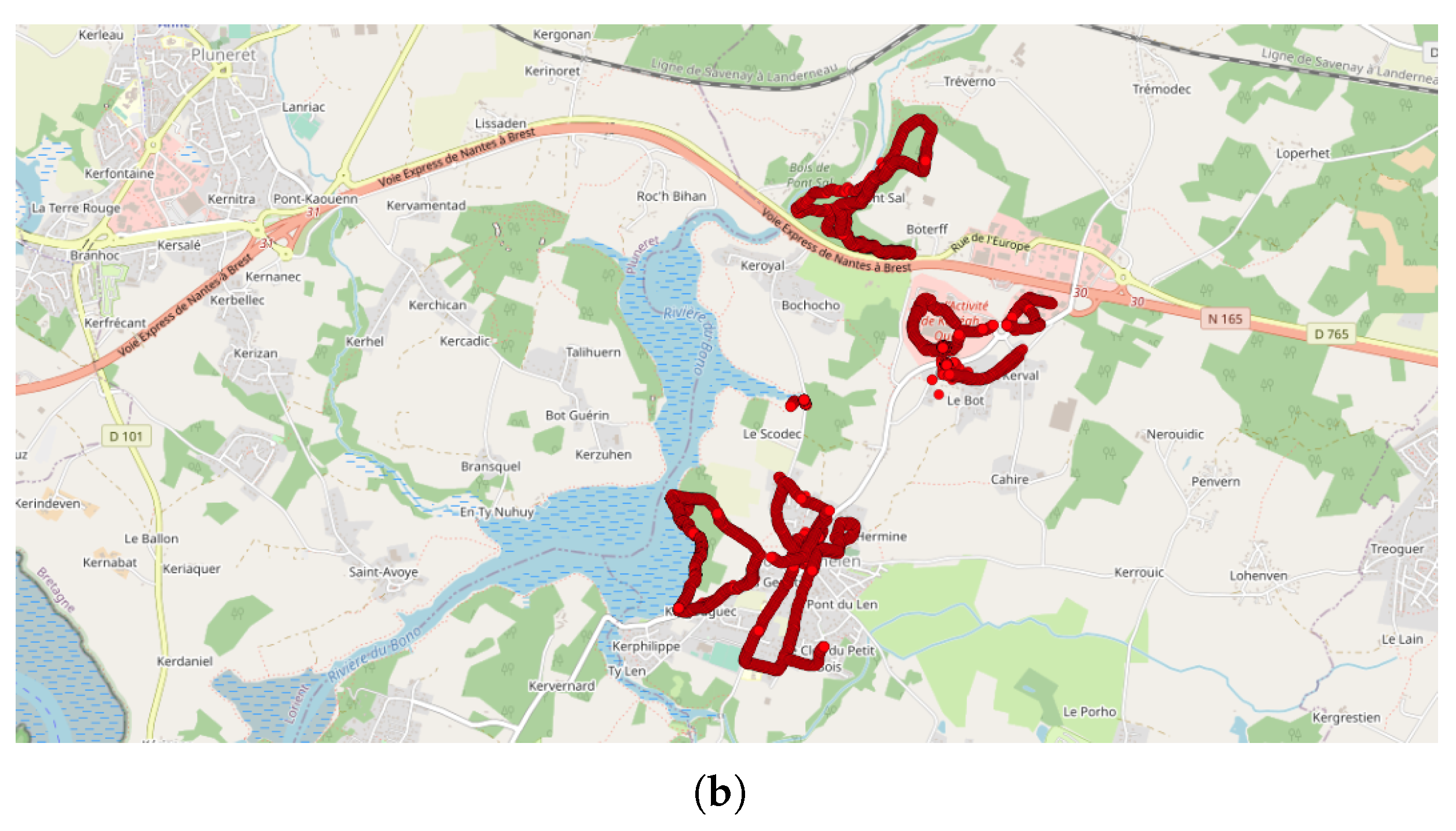
- The search for clusters depends on the number of points in the database and thus, in particular, on the size of the study area. The larger the study area is, the longer the processing time will be. Reducing the study area to territories in which NC events are potentially expected will reduce the computational time.
3.4. Validation of DBSCAN
3.4.1. Methodology
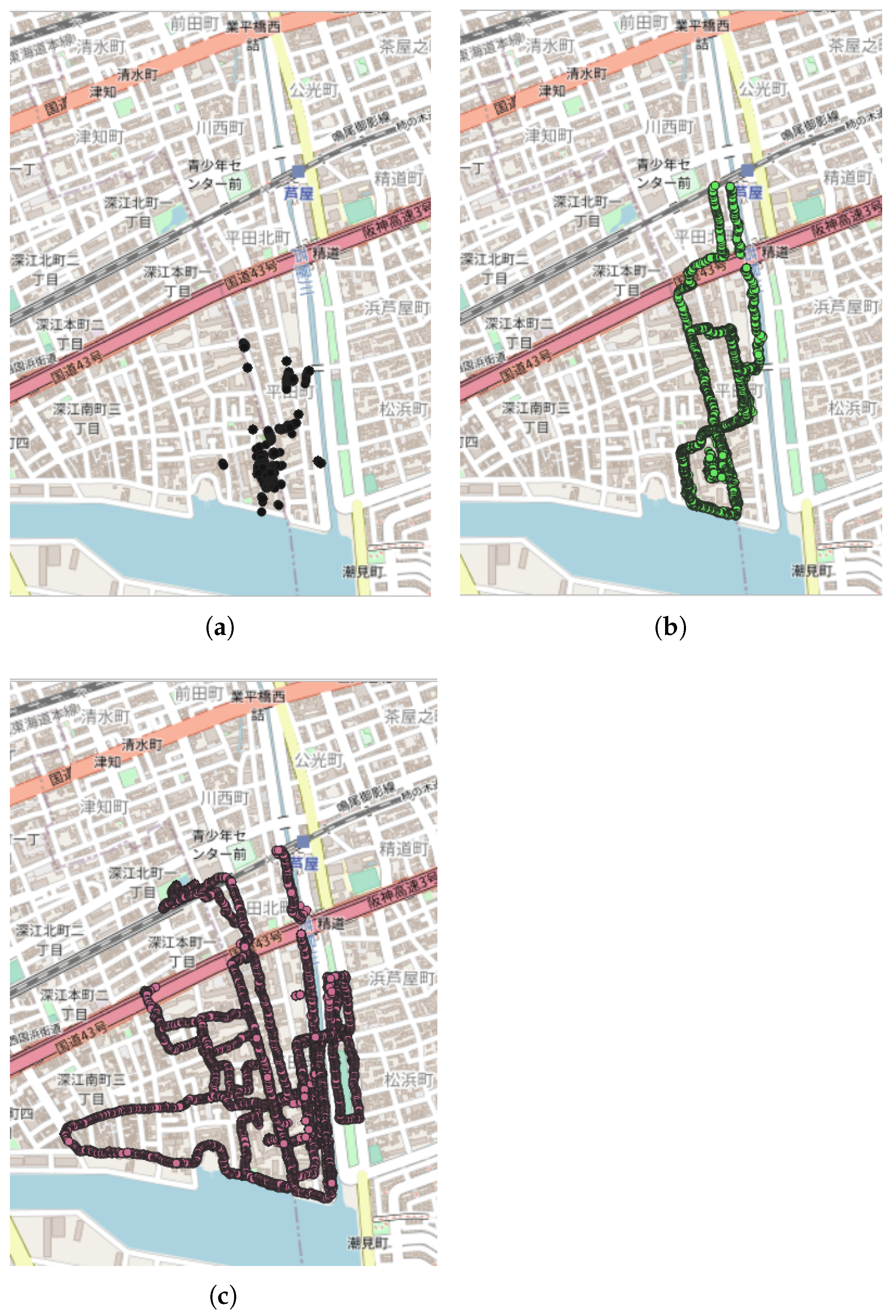
- Eps was started from 50 m as the initial distance and then gradually increased (by 50 m between 50 m and 500 m, then by 100 m from 500 m to 2000 m and finally by 500 m from 2000 m forward) until a maximum of NC party events were detected as clusters.
- MinPts was started from 20 points as the initial value and then gradually increased (firstly 50, then 100, and finally by 100 until the maximum number of points for each respective NC party event) until a maximum of NC party events were detected as clusters.
- Time window: due to the typology of current NC parties, the clusters analysis was performed by filtering the NC database by day, by week, and by month, on a total duration that includes all the NC points (i.e., if an NC party took place over a period between 2 months, the 2 months concerned were fully considered).
- GPS accuracy: the DBSCAN process was performed with two settings for the GPS accuracy: “Off”, meaning that the GPS accuracy is not considered; “On”, meaning that measurements with a GPS accuracy strictly greater than 15 m are removed from the data.
- Zone of study: in order to reduce the computational time, the zone of study was reduced to the spatial areas that contained the current NC parties. However, the area must be large enough to avoid edge effects, especially if the points of a cluster are too close to the spatial boundaries.
3.4.2. Results
4. Application of DBSCAN on the NoiseCapture Database
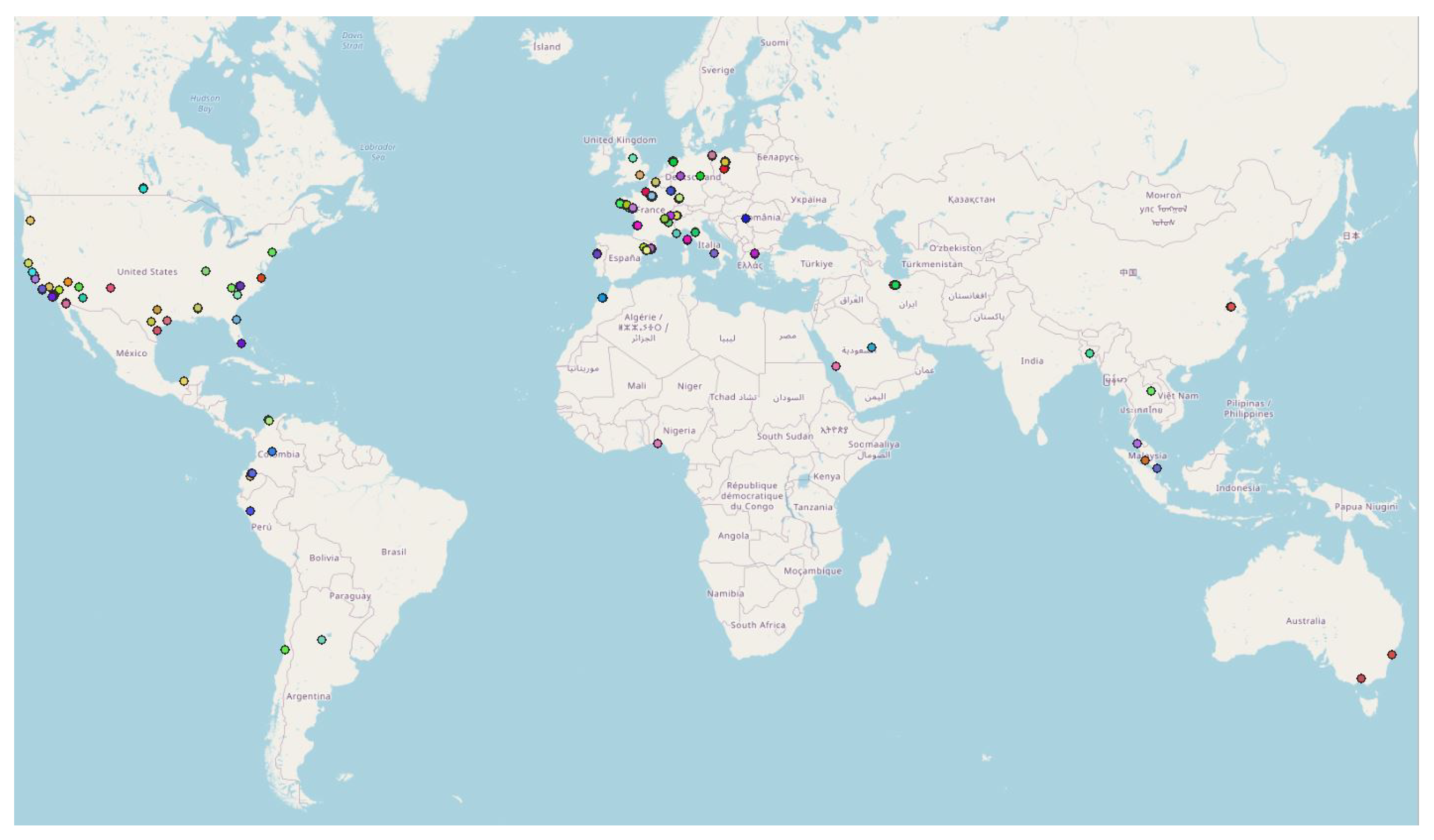
4.1. Preliminary Results of DBSCAN in Some Countries
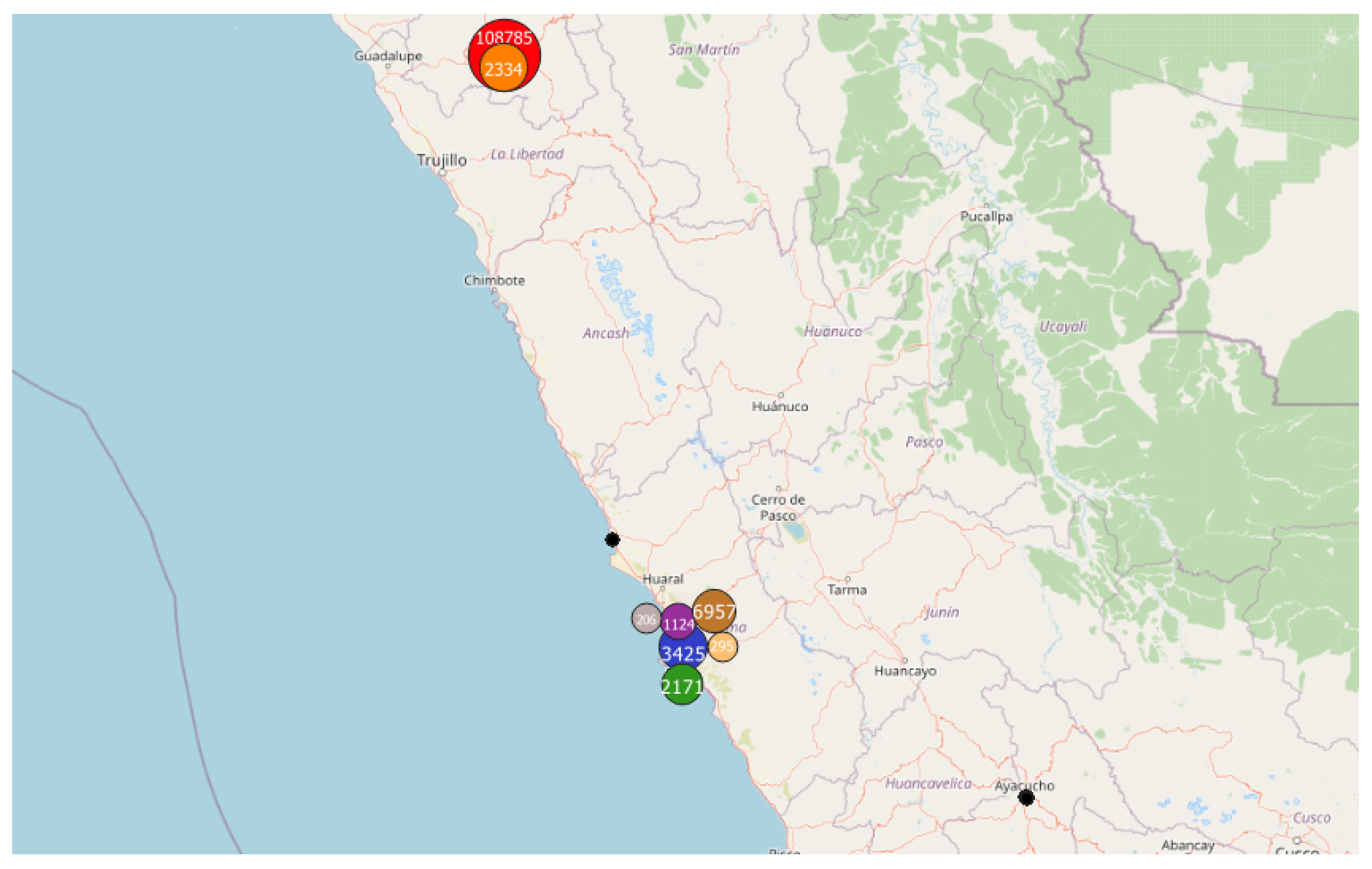
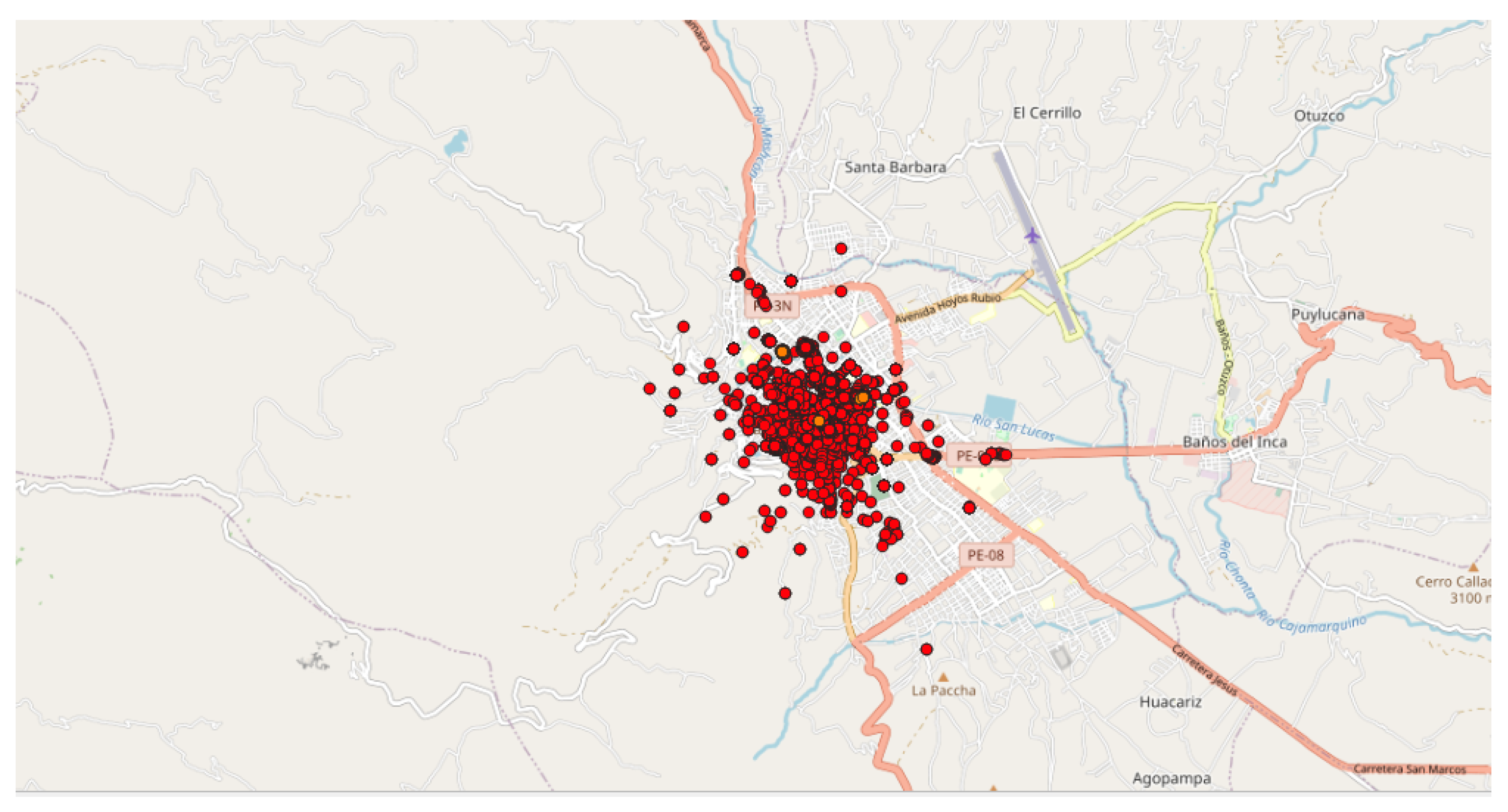
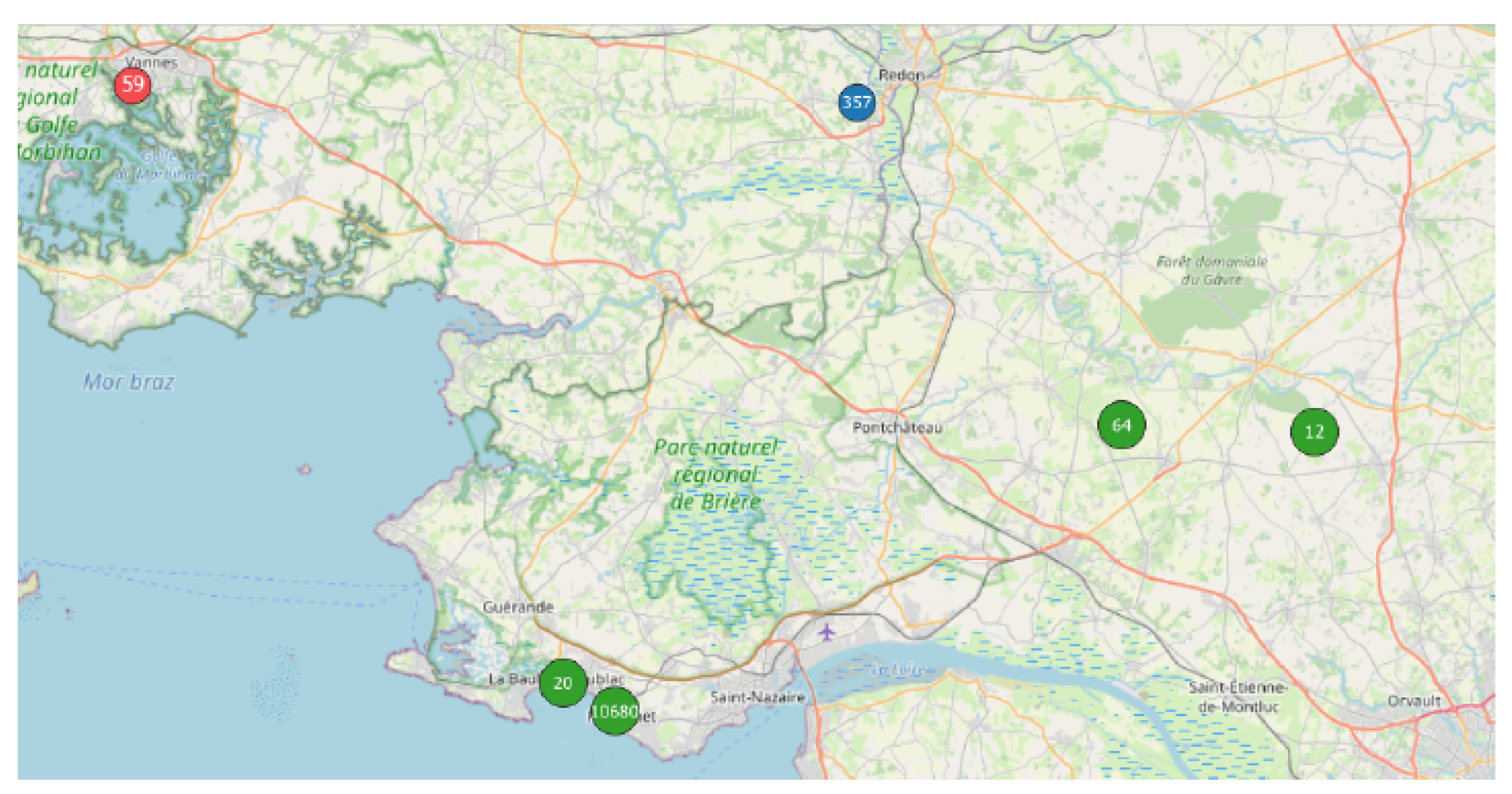
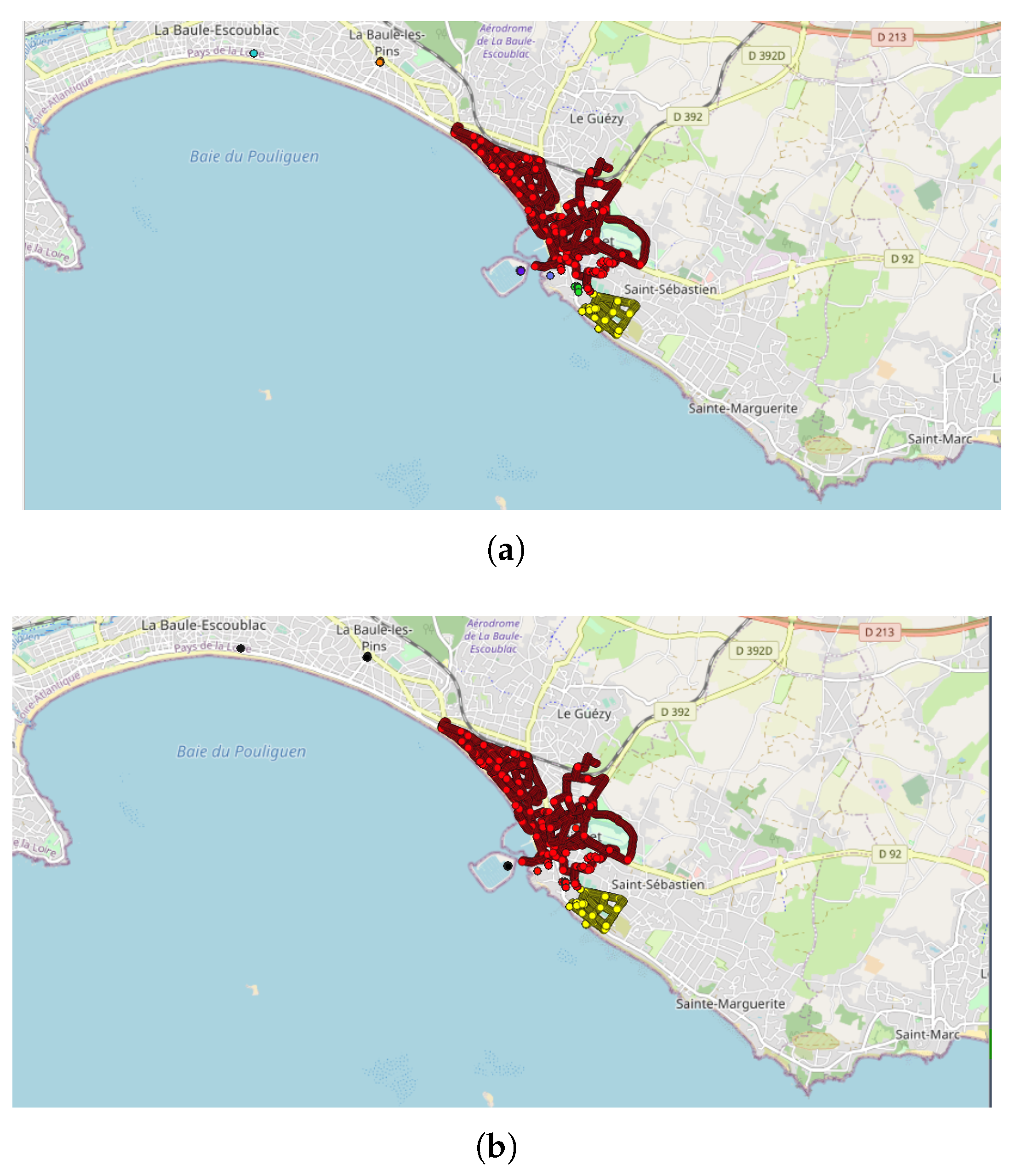
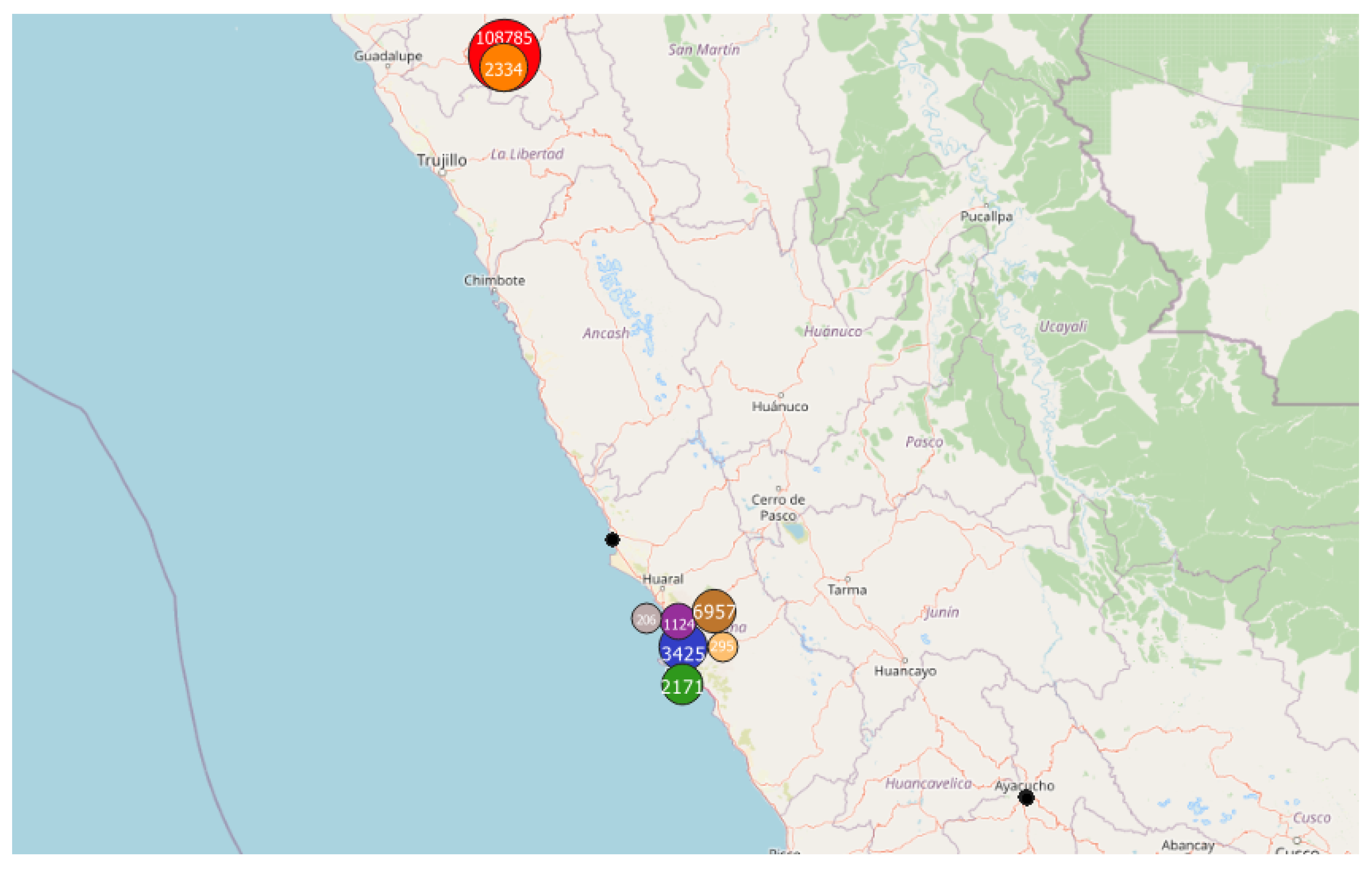
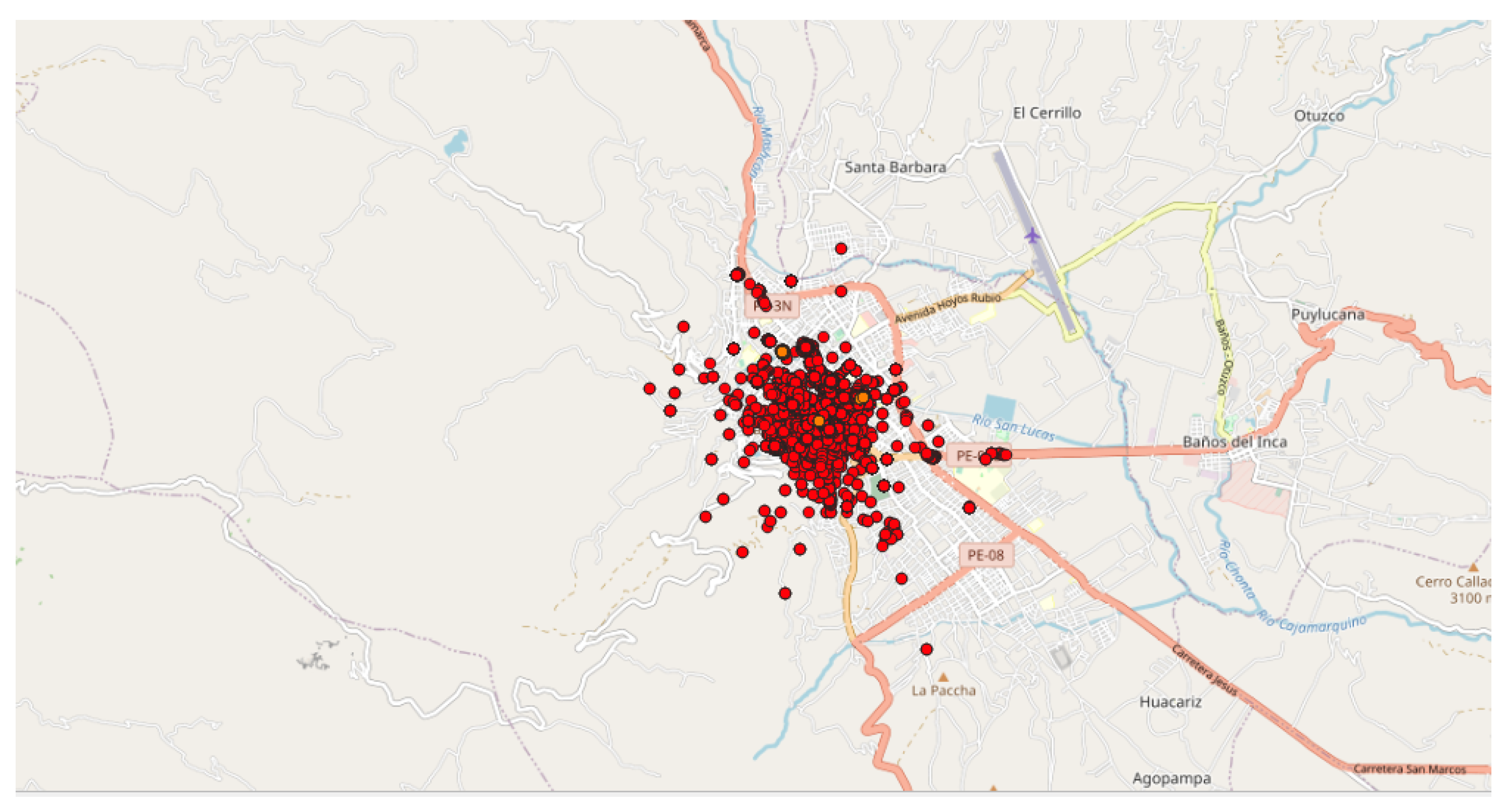
- The first application was carried out in Peru since an unusual and large amount of collected data was observed on 8–9 October 2018 in a past study [8]. Applying the DBSCAN method leads to eight clusters (Figure 6 and Table 3). Among them, one of the most important clusters effectively took place in October 2018 in the City of Cajamarca (Figure 7, green points, 10,740 tracks, 108,785 points). Another cluster was also identified in November 2018 (Figure 7, pink points, 248 tracks and 2334 points) at the same place. The tracks for the green cluster were collected by 23 contributors in 18 days, with a high concentration of measurements on a few days. Moreover, the highest number of points were collected between 09:00 and 09:59 (18.6% of points) and between 13:00 and 13:59 (17.2% of points). For the pink cluster, data were collected in 2 days by 3 users, who have also participated in collecting tracks for the green cluster. Moreover, most points were collected between 07:00 and 07:59 (90.8%). Considering the distribution of measurements over time and the total number of measurements, it is likely that these two clusters are the result of specifically coordinated events.
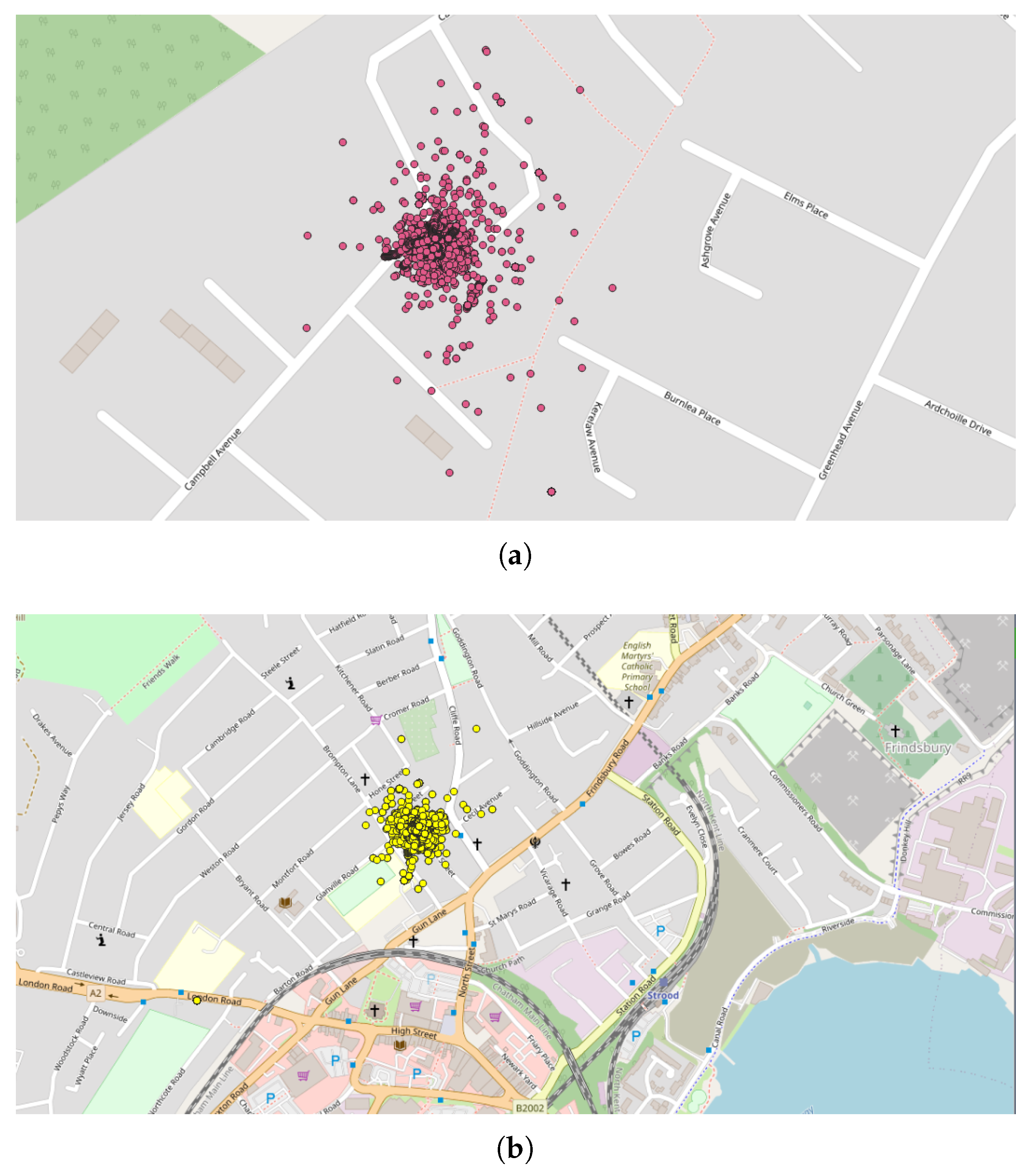
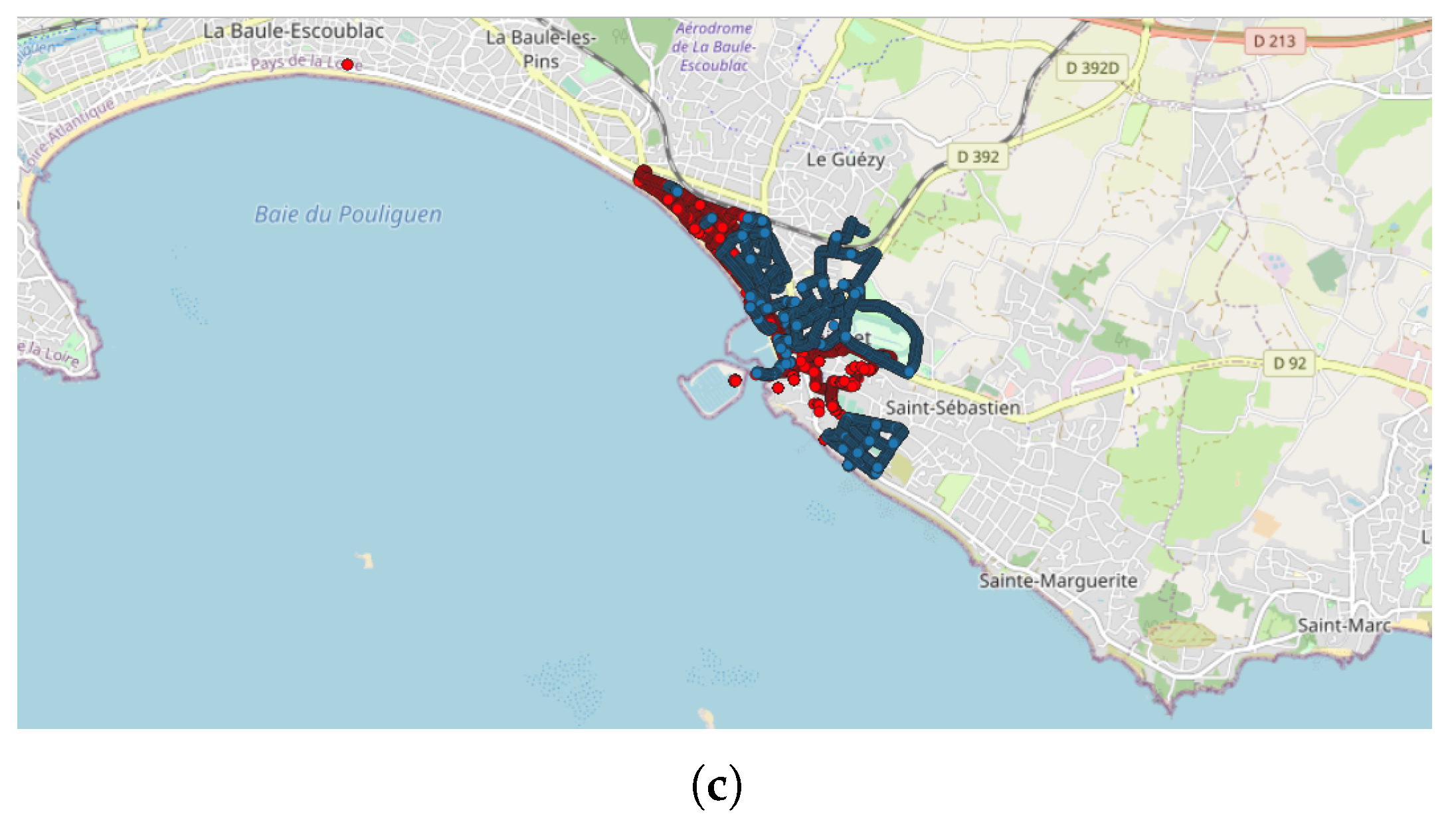
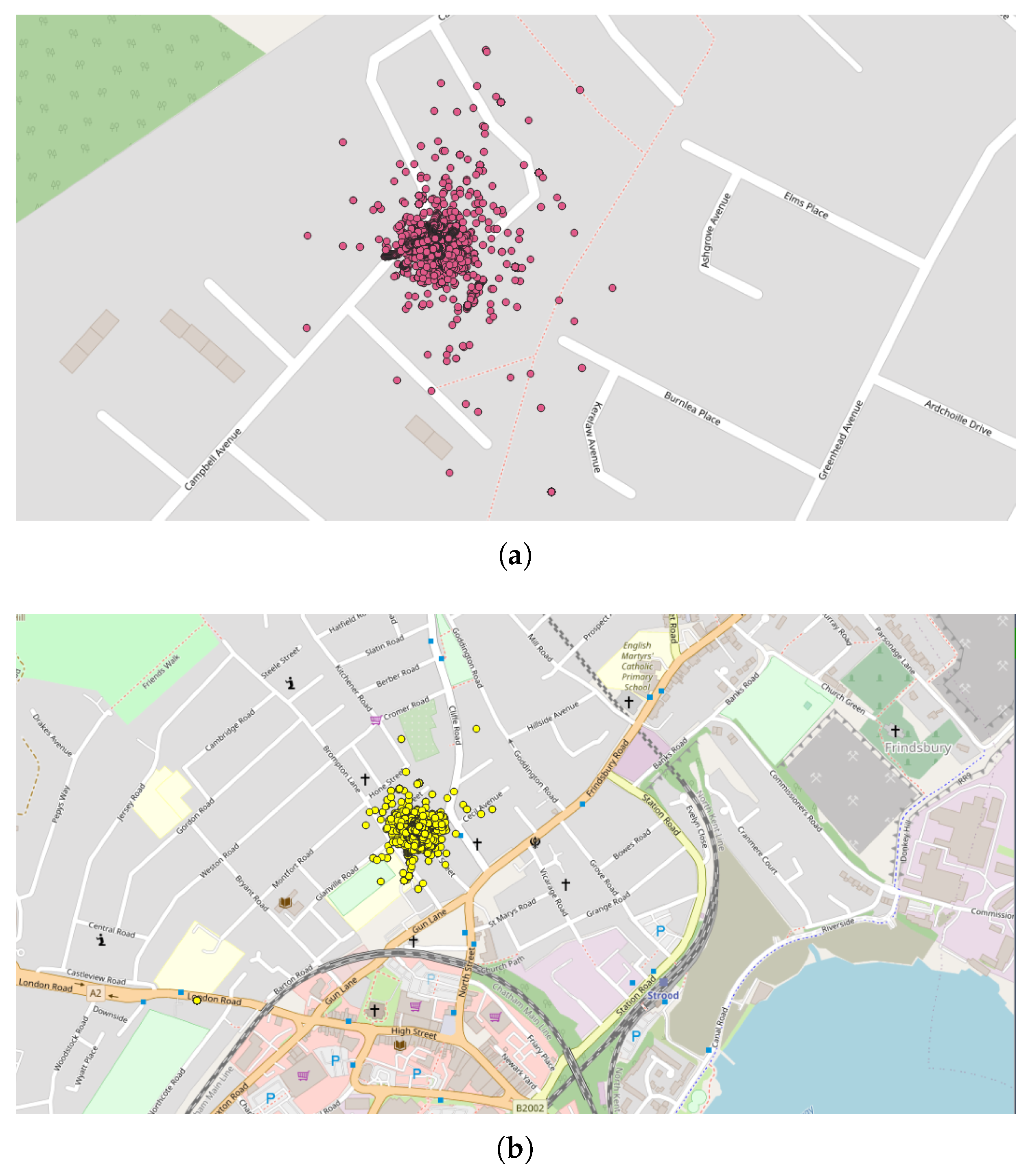
- The next application was realized in the United Kingdom, one of the top contributors to the NC database with 4693 tracks (4th in tracks contribution) and 2,067,182 points (3rd in points contribution). Applying the DBSCAN method leads to 440 clusters. The cluster with the highest number of points (126,533 points with 33 tracks) took place in October 2019, close to the city of Stevenston in Scotland (Figure 8). This cluster was collected by one user only during 12 days, with a few tracks per days; the highest number of the data collection was performed between 22:00 and 01:59 (25.8% points) and between 06:00 and 06:59 (8.5% points), which could suggest that an objective of the measurements was to evaluate the noise distribution during late night and early morning. The metadata show that the smartphone was calibrated for all the measurements, but the calibration value (40 dB) seems excessive in relation to what can normally be expected. The cluster with the highest number of tracks (248 tracks for 38,104 points) took place on November 2018 in the city of Strood in England. This cluster was gathered by two users, and all of the tracks were calibrated to the same value (0 dB). This cluster was collected in 21 days, with 10 to 20 tracks per day, mostly between 16:00 to 17:59 (12.1% points).
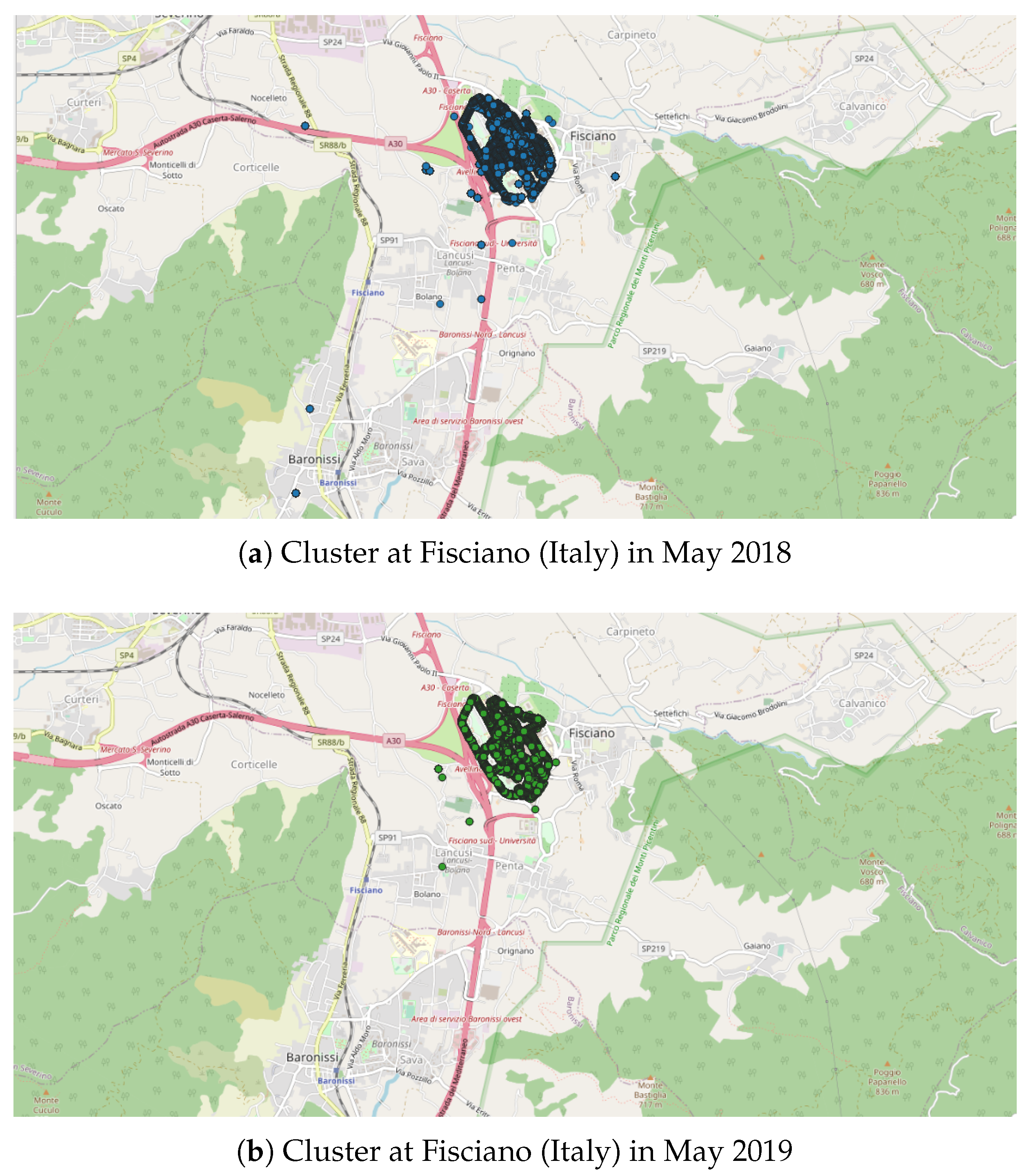
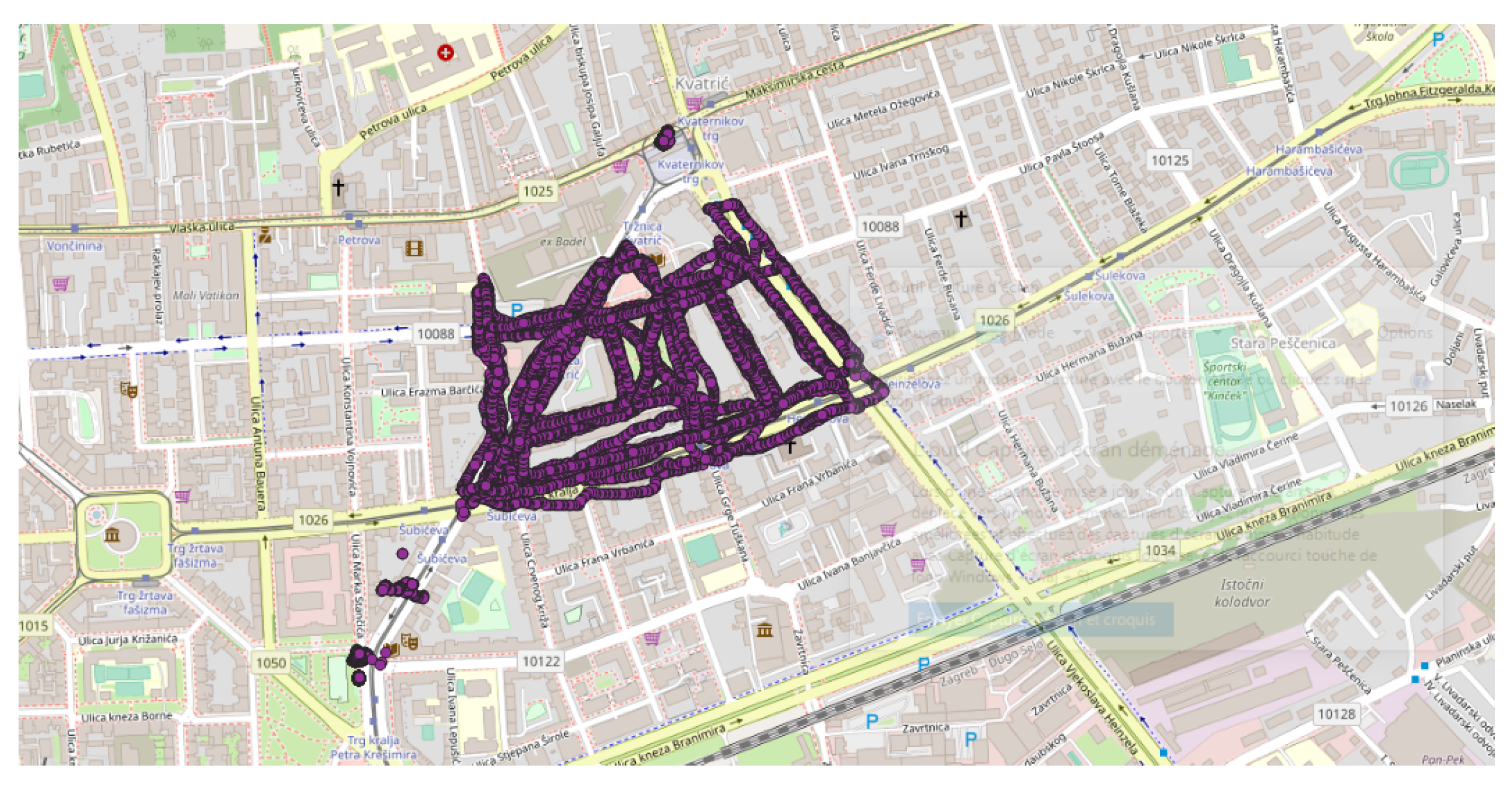
- Italy was also considered, since it is also one of the major contributors to the NC database with 2654 tracks (ranked 11th) and 364,613 points (ranked 18th) and because few NC parties have been organized. Applying the DBSCAN method gives 151 clusters, among them, the two known NC party events, which took place in Fisciano in May 2018 and May 2019 [42,43] (Figure 9).
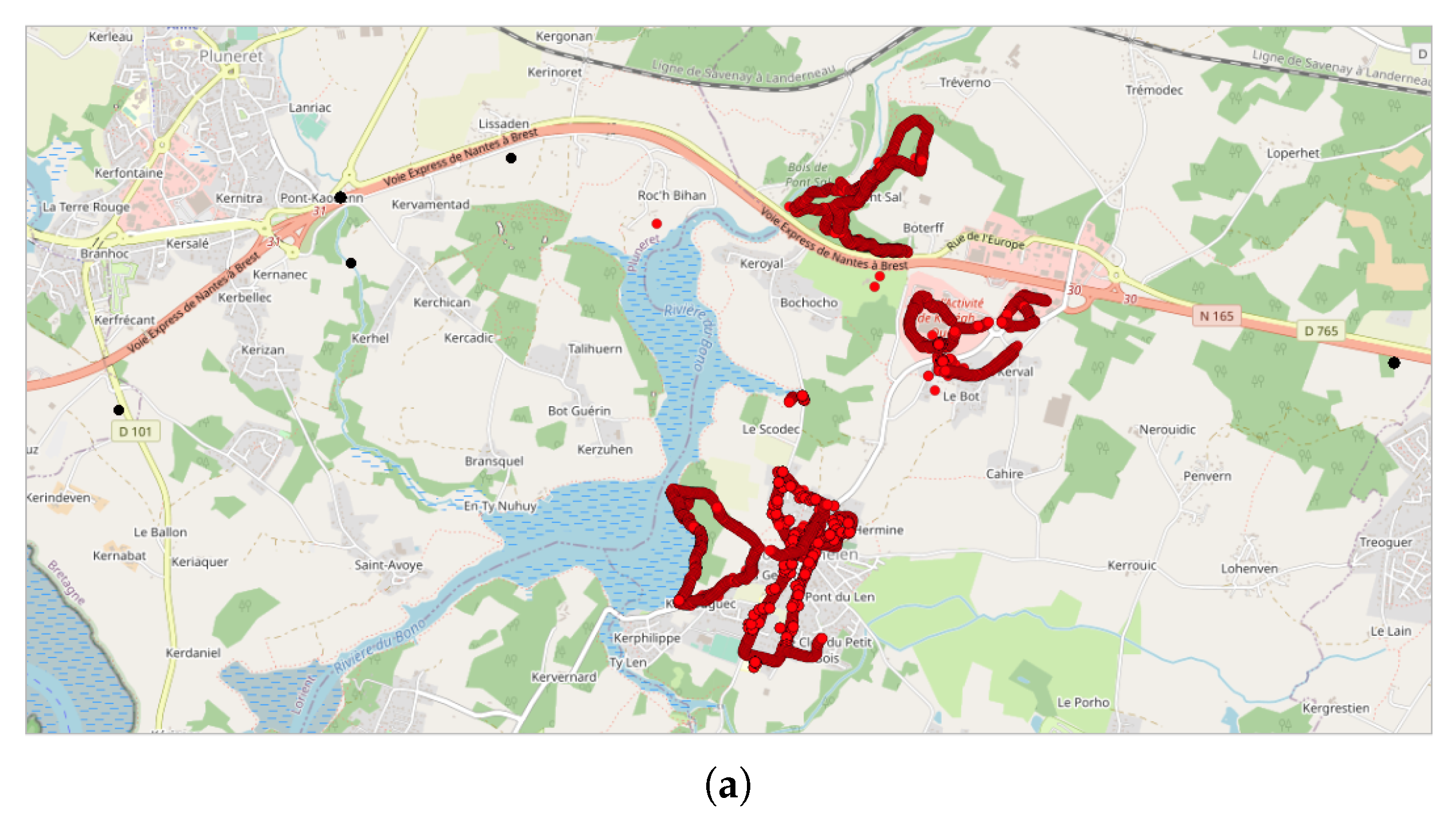
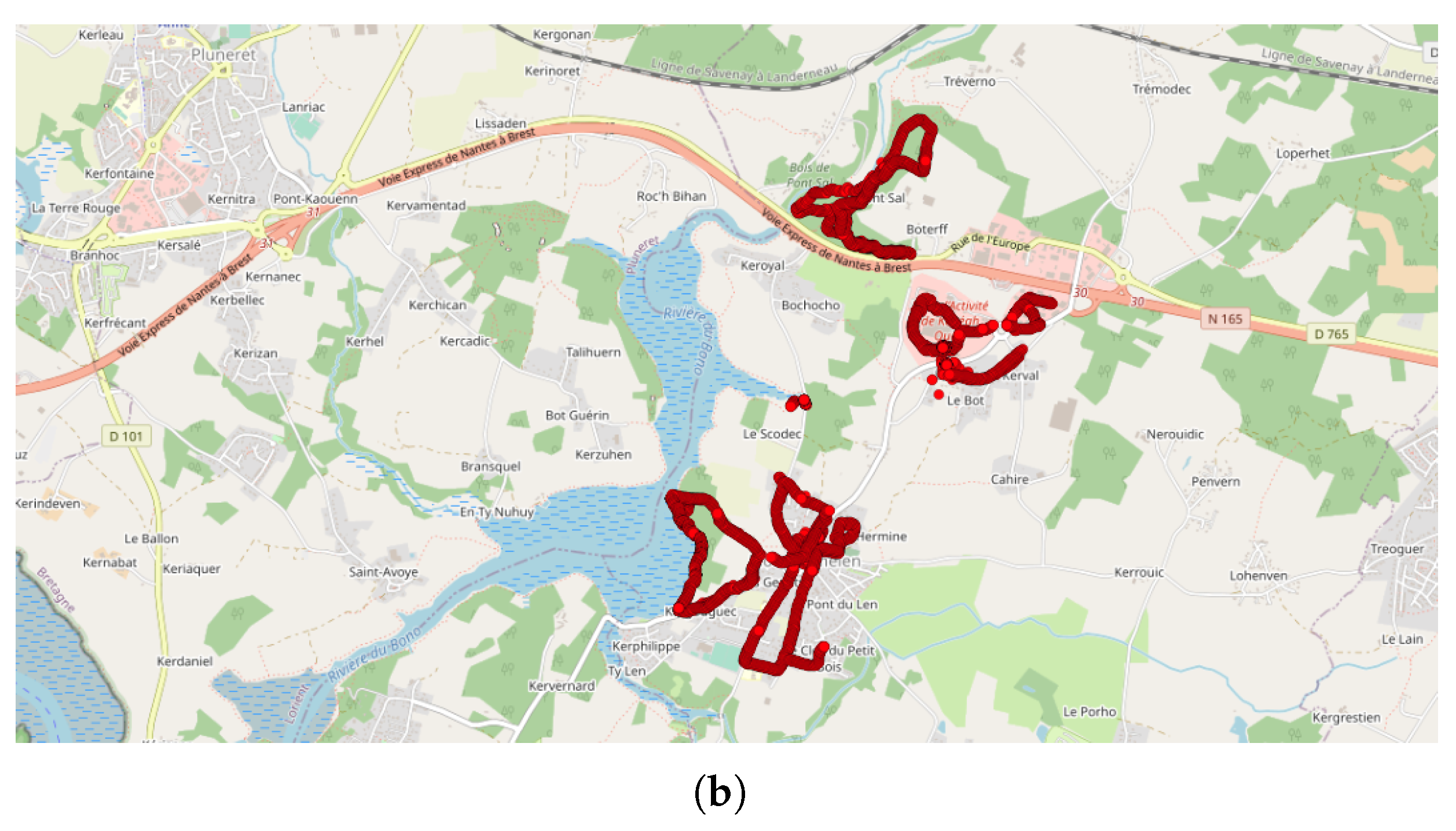
- Lastly, the DBSCAN method was also applied to France, where most of the NC parties were carried out and potentially, some non-official events. A total of 1852 clusters were found, among them 211 during the month of September 2017, which corresponds to the first month of the application’s existence. The cluster with the most tracks and points (1358 tracks/32,0850 points by 429 contributors) is observed in Paris in September 2017. This cluster was collected during the entire month with a majority of points collected on 11, 12, and 13 of the month, with most points collected between 12:00 and 12:59, 10:00 and 10:59, and 19:00 and 19:59. Using corresponding DBSCAN parameters in the case of France, the method returns too many clusters to make a detailed and individual analysis. It is also unlikely that all these clusters are associated with events. This suggests that the number of clusters should perhaps be limited to be sure of their interest.
4.2. Cluster Typology
- Type A (38.0%): Clusters composed of a large number of tracks/points and with data collected by multiple users during a period of a month or less. This is the most expected cluster type, since it typically corresponds to an NC party type event.
- Type B (40.7%): Clusters with data that are collected by one or a few users express the involvement of one or a few people in the collection of a large number of measurements. It is a priori an individual behavior, which can illustrate the involvement of some people in the “crowd-sourced” spirit of the NC project. This type of cluster can be interesting, especially if the user is considered an expert.
- Type C (4.4%): Clusters composed of a lot of tracks but with a small number of points in total.
- Type D (13.5%): Clusters that are composed of only one track and contain a few points (between 200 and 500 points).
- Type E (3.4%): Clusters with a regular daily collection for more than several days.
- Clusters of data collected during the same time period (day or hour) but in different locations.
- Clusters that are close together and may be related to the same event.
- Clusters of data collected by the same users in the same location but at different times.
4.3. Applying the DBSCAN Method to the Full NC Database
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Peris, E. Environmental noise in Europe: 2020. EEA Report No 22/2019; European Environment Agency, Publications Office: Luxembourg, 2020. [Google Scholar] [CrossRef]
- Picaut, J.; Can, A.; Fortin, N.; Ardouin, J.; Lagrange, M. Low-Cost Sensors for Urban Noise Monitoring Networks—A Literature Review. Sensors 2020, 20, 2256. [Google Scholar] [CrossRef] [PubMed]
- Santini, S.; Ostermaier, B.; Adelmann, R. On the use of sensor nodes and mobile phones for the assessment of noise pollution levels in urban environments. In Proceedings of the 2009 Sixth International Conference on Networked Sensing Systems (INSS), Pittsburgh, PA, USA, 17–19 June 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Rana, R.K.; Chou, C.T.; Kanhere, S.S.; Bulusu, N.; Hu, W. Ear-phone: An End-to-end Participatory Urban Noise Mapping System. In Proceedings of the 9th International Conference on Information Processing in Sensor Networks, IPSN 2010, Stockholm, Sweden, 12–16 April 2010; ACM: New York, NY, USA, 2010; pp. 105–116. [Google Scholar] [CrossRef]
- Kanjo, E. NoiseSPY: A Real-Time Mobile Phone Platform for Urban Noise Monitoring and Mapping. Mob. Netw. App. 2010, 15, 562–574. [Google Scholar] [CrossRef] [Green Version]
- Maisonneuve, N.; Stevens, M.; Ochab, B. Participatory Noise Pollution Monitoring Using Mobile Phones. Info. Pol. 2010, 15, 51–71. [Google Scholar] [CrossRef] [Green Version]
- Picaut, J.; Fortin, N.; Bocher, E.; Petit, G.; Aumond, P.; Guillaume, G. An open-science crowdsourcing approach for producing community noise maps using smartphones. Build. Environ. 2019, 148, 20–33. [Google Scholar] [CrossRef]
- Picaut, J.; Boumchich, A.; Bocher, E.; Fortin, N.; Petit, G.; Aumond, P. A Smartphone-Based Crowd-Sourced Database for Environmental Noise Assessment. Int. J. Environ. Res. Public Health 2021, 18, 7777. [Google Scholar] [CrossRef] [PubMed]
- Noise-Planet Website. Noise-Planet-Data. 2021. Available online: https://data.noise-planet.org/index.html (accessed on 16 September 2022).
- NoiseCapture Map Public Webpage. Available online: https://noise-planet.org/map_noisecapture (accessed on 16 September 2022).
- Noise-Planet Website. Available online: https://noise-planet.org (accessed on 3 October 2022).
- Jhaveri, R.H.; Revathi, A.; Ramana, K.; Raut, R.; Dhanaraj, R.K. A Review on Machine Learning Strategies for Real-World Engineering Applications. Mob. Inform. Syst. 2022, 2022, 1833507. [Google Scholar] [CrossRef]
- Lease, M. On quality control and machine learning in crowdsourcing. In Proceedings of the Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 8 August 2011. [Google Scholar]
- McNicholas, C.; Mass, C.F. Smartphone Pressure Collection and Bias Correction Using Machine Learning. J. Atmos. Ocean. Technol. 2018, 35, 523–540. [Google Scholar] [CrossRef]
- Sheng, V.S.; Zhang, J. Machine Learning with Crowdsourcing: A Brief Summary of the Past Research and Future Directions. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9837–9843. [Google Scholar] [CrossRef] [Green Version]
- Niu, G.; Yang, P.; Zheng, Y.; Cai, X.; Qin, H. Automatic Quality Control of Crowdsourced Rainfall Data With Multiple Noises: A Machine Learning Approach. Water Resour. Res. 2021, 57. [Google Scholar] [CrossRef]
- Kisilevich, S.; Mansmann, F.; Nanni, M.; Rinzivillo, S. Spatio-temporal clustering. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: New York, NY, USA, 2010; pp. 855–874. [Google Scholar] [CrossRef]
- Jobson, J.D. Applied Multivariate Data Analysis: Categorical and Multivariate Methods/Book and Disk, 1st ed.; 1992, corr. 2nd printing 1994 édition ed.; Springer: New York, NY, USA, 1994. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. Data Clustering: Algorithms and Applications, 1st ed.; Chapman and Hall/CRC Data Mining and Knowledge Discovery Series: Boca Raton, FL, USA, 2013. [Google Scholar]
- Shahzad, A.; Coenen, F. Efficient Distributed MST Based Clustering for Recommender Systems. In Proceedings of the 20th IEEE International Conference on Data Mining Workshops (ICDMW 2020), Sorrento, Italy, 17–20 November 2020; pp. 206–210. [Google Scholar] [CrossRef]
- Li, C.-L.; Lian, B.; Lu, H.-S. The Application of Factor Cluster Composite Analysis in Market Segmentation Research. In Proceedings of the 2011 International Conference on Management Science & Engineering 18th Annual Conference Proceedings, Rome, Italy, 13–15 September 2011; pp. 563–568. [Google Scholar]
- Ayanegui-Santiago, H.; Reyes-Galaviz, O.F.; Chavez-Aragon, A.; Ramirez-Cruz, F.; Portilla, A.; Garcia-Banuelos, L. Mining Social Networks on the Mexican Computer Science Community. In Proceedings of the MICAI 2009: Advances in Artificial Intelligence, Guanajuato, Mexico, 9–13 November 2009; Aguirre, A.H., Borja, R.M., Garcia, C.A.R., Eds.; Springer: Berlin, Germany, 2009; Volume 5845, pp. 213–224. [Google Scholar]
- Hsieh, L.C.; Wu, G.L.; Hsu, Y.M.; Hsu, W. Online image search result grouping with MapReduce-based image clustering and graph construction for large-scale photos. J. Vis. Commun. Image Represent. 2014, 25, 384–395. [Google Scholar] [CrossRef]
- Zhao, M.; Chen, J. A Review of Methods for Detecting Point Anomalies on Numerical Dataset. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 559–565. [Google Scholar]
- Akdemir, S.; Tagarakis, A. Investigation of Spatial Variability of Air Temperature, Humidity and Velocity in Cold Stores by Using Management Zone Analysis. J. Agric. Sci.-Tarim Bilim. Derg. 2014, 20, 175–186. [Google Scholar] [CrossRef]
- Dupuis, D.J.; Trapin, L. Structural change to the persistence of the urban heat island. Environ. Res. Lett. 2020, 15, 104076. [Google Scholar] [CrossRef]
- Fakhruddin, M.; Putra, P.S.; Wijaya, K.P.; Sopaheluwakan, A.; Satyaningsih, R.; Komalasari, K.E.; Mamenun; Sumiati; Indratno, S.W.; Nuraini, N.; et al. Assessing the interplay between dengue incidence and weather in Jakarta via a clustering integrated multiple regression model. Ecol. Complex. 2019, 39, 100768. [Google Scholar] [CrossRef]
- Smith, M.J.d.; Goodchild, M.F.; Longley, P.A. Geospatial Analysis: A Comprehensive Guide, hardback ed.; The Winchelsea Press: London, UK, 2018. [Google Scholar]
- Craig, A.; Moore, D.; Knox, D. Experience sampling: Assessing urban soundscapes using in-situ participatory methods. Appl. Acoust. 2017, 117, 227–235. [Google Scholar] [CrossRef] [Green Version]
- De Coensel, B.; Botteldooren, D.; Debacq, K.; Nilsson, M.E.; Berglund, B. Clustering outdoor soundscapes using fuzzy ants. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1556–1562. [Google Scholar] [CrossRef]
- Pita, A.; Rodriguez, F.J.; Navarro, J.M. Cluster Analysis of Urban Acoustic Environments on Barcelona Sensor Network Data. Int. J. Environ. Res. Public Health 2021, 18, 8271. [Google Scholar] [CrossRef] [PubMed]
- Zambon, G.; Benocci, R.; Brambilla, G. Cluster categorization of urban roads to optimize their noise monitoring. Environ. Monit. Assess. 2016, 188, 26. [Google Scholar] [CrossRef] [Green Version]
- Socoró, J.C.; Alías, F.; Alsina-Pagès, R.M. WASN-Based Spectro-Temporal Analysis and Clustering of Road Traffic Noise in Urban and Suburban Areas. Appl. Sci. 2022, 12, 981. [Google Scholar] [CrossRef]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Lim, Z.Y.; Ong, L.Y.; Leow, M.C. A Review on Clustering Techniques: Creating Better User Experience for Online Roadshow. Future Int. 2021, 13, 233. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; The AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- ST_ClusterDBSCAN. Available online: https://postgis.net/docs/ST_ClusterDBSCAN.html (accessed on 20 April 2022).
- WGS 84-WGS84-World Geodetic System 1984. Available online: https://epsg.org/crs_4326/WGS-84.html (accessed on 25 September 2022).
- WGS 84/Pseudo-Mercator. Available online: https://epsg.org/crs_3857/WGS-84-Pseudo-Mercator.html (accessed on 25 September 2022).
- ST_Transform. Available online: https://postgis.net/docs/ST_Transform.html (accessed on 3 October 2022).
- Picaut, J.; Fortin, N.; Bocher, E.; Petit, G. NoiseCapture Data Extraction from August 29, 2017 until August 28, 2020 (3 Years). 2021. Available online: https://research-data.ifsttar.fr/dataset.xhtml?persistentId=doi:10.25578/J5DG3W (accessed on 3 October 2022).
- Graziuso, G.; Grimaldi, M.; Mancini, S.; Quartieri, J.; Guarnaccia, C. Crowdsourcing Data for the Elaboration of Noise Maps: A Methodological Proposal. J. Phys. Conf. Ser. 2020, 1603, 012030. [Google Scholar] [CrossRef]
- Graziuso, G.; Mancini, S.; Francavilla, A.B.; Grimaldi, M.; Guarnaccia, C. Geo-Crowdsourced Sound Level Data in Support of the Community Facilities Planning. A Methodological Proposal. Sustainability 2021, 13, 5486. [Google Scholar] [CrossRef]
- Sakagami, K. How did the ‘state of emergency’ declaration in Japan due to the COVID-19 pandemic affect the acoustic environment in a rather quiet residential area? UCL Open Environ. 2020, 2, e009. [Google Scholar] [CrossRef]
- Dubey, R.; Bharadwaj, S.; Zafar, M.I.; Bhushan Sharma, V.; Biswas, S. Collaborative noise mapping using smartphone. Int. Arch. Photogramm. Remote Sens. Spat. Inform. Sci. 2020, XLIII-B4-2020, 253–260. [Google Scholar] [CrossRef]
- Njegovan, A. Analiza Slobodnih Aplikacija za mjerenje Buke (Analysis of Free Applications for Noise Measurement); Technical Report; Geodetski Fakultet, Zagreb: Zagreb, Croatia, 2018. [Google Scholar]
- Mohammed, H.M.E.H.S.; Badawy, S.S.I.; Hussien, A.I.H.; Gorgy, A.A.F. Assessment of noise pollution and its effect on patients undergoing surgeries under regional anesthesia, is it time to incorporate noise monitoring to anesthesia monitors: An observational cohort study. Ain-Shams J. Anesthesiol. 2020, 12, 20. [Google Scholar] [CrossRef]
- Chowdhury, A.R.; Mollah, M.E.; Rahman, M.A. An efficient method for subjectively choosing parameter ‘k’ automatically in VDBSCAN (Varied Density Based Spatial Clustering of Applications with Noise) algorithm. In Proceedings of the 2010 The 2nd International Conference on Computer and Automation Engineering (ICCAE), Singapore, 26–28 February 2010; Volume 1, pp. 38–41. [Google Scholar] [CrossRef]
- Wang, W.T.; Wu, Y.L.; Tang, C.Y.; Hor, M.K. Adaptive density-based spatial clustering of applications with noise (DBSCAN) according to data. In Proceedings of the 2015 International Conference on Machine Learning and Cybernetics (ICMLC), Guangzhou, China, 12–15 July 2015; Volume 1, pp. 445–451. [Google Scholar] [CrossRef]
- Bushra, A.A.; Yi, G. Comparative Analysis Review of Pioneering DBSCAN and Successive Density-Based Clustering Algorithms. IEEE Acc. 2021, 9, 87918–87935. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering Points To Identify the Clustering Structure. ACM SIGMOD Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory Clustering: A Partition-and-Group Framework. In Proceedings of the SIGMOD ’07: Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NoiceCapture Party | All Data | Geo-Localized Data | Not Geo-Localized Data | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ID | NC party Code | Contributors | Date/Duration | Points | Tracks | Points | Tracks | Points | Tracks |
| 1 | SNDIGITALWEEK | 7 | 20 September 2017 | 11,523 | 133 | 11,192 | 118 | 331 | 15 |
| 2 | ANQES | 4 | 16–27 October 2017 | 4479 | 29 | 4458 | 28 | 21 | 1 |
| 3 | FDS2017 | 2 | 15 October 2017 | 1239 | 6 | 1209 | 5 | 30 | 1 |
| 5 | IMS2018 | 13 | 28 March 2018 | 18,793 | 0 | 18,758 | 67 | 35 | 0 |
| 6 | UDC | 8 | 17 April–27 June 2018 | 6879 | 56 | 4509 | 44 | 2370 | 12 |
| 9 | TEST44 | 1 | 2 May 2018 | 91 | 3 | 91 | 3 | 0 | 0 |
| 10 | UNISA | 13 | 17, 24 May 2018 and 6 June 2018 | 15,912 | 149 | 15,479 | 141 | 433 | 8 |
| 11 | PNRGM | 2 | 9 June 2018 | 6089 | 13 | 5957 | 12 | 132 | 2 |
| 12 | AMSOUNDS | 2 | 20, 21 June 2018 | 693 | 18 | 660 | 17 | 33 | 1 |
| 13 | PNRGM | 14 | 18, 20 July 2018 | 21,470 | 100 | 19,812 | 92 | 1658 | 8 |
| 14 | FDSSTRAS | 5 | 12, 13 October 2018 | 2967 | 31 | 2909 | 25 | 58 | 6 |
| 15 | AGGLOBASTIA | 19 | 4 October–26 November 2018 | 59,838 | 507 | 58,771 | 506 | 1067 | 1 |
| 17 | FDSNTS | 7 | 12–14 October 2018 | 5916 | 66 | 5840 | 61 | 76 | 5 |
| 18 | H2020 | 11 | 6–9 December 2018 | 22,060 | 89 | 19,869 | 88 | 2191 | 1 |
| 19 | UDC | 20 | 25 February–5 April 2019 | 5866 | 138 | 4946 | 108 | 920 | 30 |
| 20 | MSA | 9 | 10 January 2019 | 1885 | 9 | 1883 | 9 | 2 | 0 |
| 21 | GEO2019 | 43 | 12–14 March 2019 | 63,521 | 420 | 62,199 | 409 | 1322 | 11 |
| 22 | IMS2019 | 23 | 28, 29 March 2019 | 17,309 | 192 | 14,161 | 189 | 148 | 3 |
| 23 | FPSLYO | 11 | 6, 17, 18 May 2019 | 10,285 | 34 | 9548 | 31 | 737 | 3 |
| 24 | SSSOROLL2019 | 68 | 16 April–19 May 2019 | 36,272 | 372 | 35,253 | 361 | 979 | 11 |
| 26 | UNISA | 20 | 24 May 2019 | 23,220 | 332 | 22,937 | 328 | 283 | 4 |
| 27 | FDSSTRAS | 3 | 12, 13 October 2019 | 1771 | 7 | 1730 | 6 | 41 | 1 |
| 28 | H2020 | 9 | 4–8 December 2019 | 32,948 | 39 | 31,659 | 35 | 1289 | 4 |
| 29 | UDC | 9 | 3, 5, 6 March 2020 | 2099 | 73 | 2036 | 71 | 63 | 2 |
| 30 | MSA | 10 | 23 January 2020 | 3665 | 10 | 3659 | 9 | 9 | 1 |
| 31 | CICAM | – | – | – | – | – | – | – | – |
| 32 | UDC_COVID | 33 | 5–20 May 2020 | 14,785 | 249 | 14,691 | 249 | 94 | 0 |
| NoiceCapture Party | DBSCAN Parameters and Filtering Variables | Main Cluster | Secondary Clusters | Non Clustered Data | Nb Of | Extra Data in the Main Cluster | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | ID | Points | Tracks | Eps | MinPts | Time Window | Acc. | Zone (Country) | Points | Tracks | Points | Tracks | Points | Tracks | Clusters | Points | Tracks |
| 1 | 1 | 10,700 | 113 | 50 | 20 | 1 M (September 2017) | Off | PdL (FR) | 93.5% | 91.2% | 6.5% | 8.8% | 0% | 0% | 7 | 12,212 | 76 |
| 2 | 1 | 10,700 | 113 | 50 | 100 | 1 M (September 2017) | Off | PdL (FR) | 93.5% | 91.2% | 5.9% | 8% | 0.6% | 0.8% | 2 | 12,212 | 76 |
| 3 | 1 | 10,700 | 113 | 50 | 700 | 1 M (September 2017) | Off | PdL (FR) | 93.5% | 91.2% | 0% | 0% | 6.5% | 8.8% | 1 | 12,212 | 76 |
| 4 | 1 | 10,700 | 113 | 100 | 20 | 1 M (September 2017) | Off | PdL (FR) | 97.2% | 96.5% | 2.8% | 3.5% | 0% | 0% | 2 | 17,147 | 119 |
| 5 | 1 | 10,700 | 113 | 500 | 20 | 1 M (September 2017) | Off | PdL (FR) | 99.8% | 100% | 0.2% | 0% | 0% | 0% | 2 | 17,148 | 119 |
| 6 | 1 | 10,700 | 113 | 4000 | 20 | 1 M (September 2017) | Off | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 17,244 | 122 |
| 7 | 1 | 9380 | 89 | 50 | 20 | 1 M (September 2017) | On | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 7 | 11,828 | 70 |
| 8 | 1 | 10,700 | 113 | 50 | 20 | 1 W (18–24 September 2017) | Off | PdL (FR) | 93.5% | 91.2% | 6.5% | 8.8% | 0% | 0% | 7 | 11,315 | 74 |
| 9 | 1 | 9380 | 89 | 50 | 20 | 1 W (18–24 September 2017) | On | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 10,956 | 68 |
| 10 | 1 | 10,700 | 113 | 3000 | 20 | 1 D (20 September 2017) | Off | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 16,231 | 117 |
| 11 | 3 | 1209 | 5 | 3000 | 20 | 1 D (15 October 2017) | Off | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 19 | 1 |
| 12 | 5 | 18,758 | 67 | 3000 | 20 | 1 D (28 March 2018) | Off | Quimper (FR) | 97.3% | 100% | 2.7% | 0% | 0% | 0% | 2 | 15,044 | 114 |
| 13 | 6 | 4509 | 44 | 3000 | 20 | 3 M (April–June 2018) | Off | Coruña (SP) | 99.4% | 95.5% | 0.6% | 4.5% | 0% | 0% | 4 | 718 | 35 |
| 14 | 9 | 91 | 3 | 3000 | 20 | 1 M (May 2017) | Off | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 0 | 0 |
| 15 | 10 | 15,479 | 141 | 3000 | 20 | 2 M (May–June 2018) | Off | Fisciano (IT) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 9691 | 77 |
| 16 | 11 | 5957 | 12 | 3000 | 20 | 1 D (9 June2018) | Off | Elven (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 0 | 0 |
| 17 | 12 | 660 | 17 | 3000 | 20 | 1 W (18–24 June 2018) | Off | Amsterdam (NL) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 495 | 12 |
| 18 | 13 | 19,812 | 92 | 3000 | 20 | 1 W (16–22 July 2018) | Off | Morbihan (FR) | 99.8% | 100% | 0% | 0% | 0.2% | 0% | 1 | 1021 | 21 |
| 19 | 13 | 16,374 | 84 | 3000 | 20 | 1 W (16–22 July 2018) | On | Morbihan (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 961 | 21 |
| 20 | 14 | 2909 | 25 | 3000 | 20 | 1 W (8–14 October 2018) | Off | Strasbourg (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 1028 | 21 |
| 21 | 15 | 58,771 | 506 | 3000 | 20 | 2 M (October–November 2018) | Off | Corse (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 9654 | 124 |
| 22 | 17 | 5840 | 61 | 3000 | 20 | 1 W (8–14 October 2018) | Off | PdL (FR) | 100% | 100% | 0% | 0% | 0% | 0% | 1 | 1669 | 35 |
| 23 | 24 | 35,253 | 361 | 5000 | 20 | 2 M (April–May 2019) | Off | Catalonia (SP) | 50.7% | 79.9% | 48.8% | 19.5% | 0.5% | 0.6% | 9 | 25,578 | 246 |
| Cluster Nb | Tracks | Points | Contributors | Month (Year) | Nearest City | Comments |
|---|---|---|---|---|---|---|
| 1 | 10,740 | 108,785 | 23 | October (2018) | Cajamarca | |
| 2 | 248 | 2334 | 3 | November (2018) | Cajamarca | 3 users were part of Cluster 1 |
| 3 | 23 | 3425 | 2 | March (2019) | Lima | |
| 4 | 1124 | 1 | 1 | March (2019) | Lima | |
| 5 | 16 | 2171 | 1 | May (2019) | Lima | Same users as for Cluster 3 |
| 6 | 1 | 295 | 1 | May (2019) | Lima | Same users as for Cluster 4 |
| 7 | 20 | 6957 | 2 | November (2019) | Lima | Same users as for Clusters 3 and 4 |
| 8 | 4 | 206 | 1 | November (2019) | Lima | Same users as for Cluster 3 |
| Country | Eps | MinPts | Period | Number of Clusters | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 1 Track | 1 Contributor | 2 Contributors | Regular Daily Collection | Failed NC party | Partly Failed NC party | ||||
| France | 3000 | 20 | Month | 5204 | 2416 | 4370 | 471 | 635 | 0 (18) | 0 (18) |
| 3000 | 200 | Month | 1852 | 429 | 1278 | 260 | 143 | 1 (18) | 0 (18) | |
| 3000 | 5000 | Month | 224 | 19 | 98 | 28 | 29 | 3 (18) | 0 (18) | |
| 3000 | 10,000 | Month | 125 | 8 | 42 | 13 | 27 | 7 (18) | 0 (18) | |
| 3000 | 5000 | Week | 297 | 32 | 164 | 41 | 0 | 4 (18) | 1 (18) | |
| 3000 | 10,000 | Week | 125 | 12 | 61 | 14 | 0 | 8 (18) | 1 (18) | |
| Italy | 3000 | 20 | Month | 564 | 270 | 525 | 27 | 5 | 0 (2) | 0 (2) |
| 3000 | 200 | Month | 155 | 34 | 129 | 14 | 4 | 0 (2) | 0 (2) | |
| 3000 | 5000 | Month | 16 | 3 | 11 | 1 | 0 | 0 (2) | 0 (2) | |
| 3000 | 10,000 | Month | 9 | 1 | 6 | 0 | 0 | 0 (2) | 0 (2) | |
| 3000 | 5000 | Week | 15 | 2 | 10 | 1 | 0 | 0 (2) | 0 (2) | |
| 3000 | 10,000 | Week | 7 | 0 | 4 | 1 | 0 | 0 (2) | 0 (2) | |
| United | 3000 | 20 | Month | 1094 | 509 | 1024 | 51 | 22 | – | – |
| Kingdom | 3000 | 200 | Month | 440 | 122 | 389 | 32 | 24 | – | – |
| 3000 | 5000 | Month | 77 | 19 | 62 | 4 | 5 | – | – | |
| 3000 | 10,000 | Month | 48 | 7 | 37 | 4 | 1 | – | – | |
| 3000 | 5000 | Week | 111 | 23 | 99 | 9 | 0 | – | – | |
| 3000 | 10,000 | Week | 57 | 10 | 49 | 6 | 0 | – | – | |
| Peru | 3000 | 20 | Month | 83 | 40 | 72 | 9 | 2 | – | – |
| 3000 | 200 | Month | 17 | 3 | 11 | 4 | 0 | – | – | |
| 3000 | 5000 | Month | 2 | 0 | 0 | 1 | 0 | – | – | |
| 3000 | 10,000 | Month | 1 | 0 | 0 | 0 | 0 | – | – | |
| 3000 | 5000 | Week | 2 | 0 | 0 | 1 | 0 | – | – | |
| 3000 | 10,000 | Week | 1 | 0 | 0 | 0 | 0 | – | – | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boumchich, A.; Picaut, J.; Bocher, E. Using a Clustering Method to Detect Spatial Events in a Smartphone-Based Crowd-Sourced Database for Environmental Noise Assessment. Sensors 2022, 22, 8832. https://doi.org/10.3390/s22228832
Boumchich A, Picaut J, Bocher E. Using a Clustering Method to Detect Spatial Events in a Smartphone-Based Crowd-Sourced Database for Environmental Noise Assessment. Sensors. 2022; 22(22):8832. https://doi.org/10.3390/s22228832
Chicago/Turabian StyleBoumchich, Ayoub, Judicaël Picaut, and Erwan Bocher. 2022. "Using a Clustering Method to Detect Spatial Events in a Smartphone-Based Crowd-Sourced Database for Environmental Noise Assessment" Sensors 22, no. 22: 8832. https://doi.org/10.3390/s22228832
APA StyleBoumchich, A., Picaut, J., & Bocher, E. (2022). Using a Clustering Method to Detect Spatial Events in a Smartphone-Based Crowd-Sourced Database for Environmental Noise Assessment. Sensors, 22(22), 8832. https://doi.org/10.3390/s22228832