
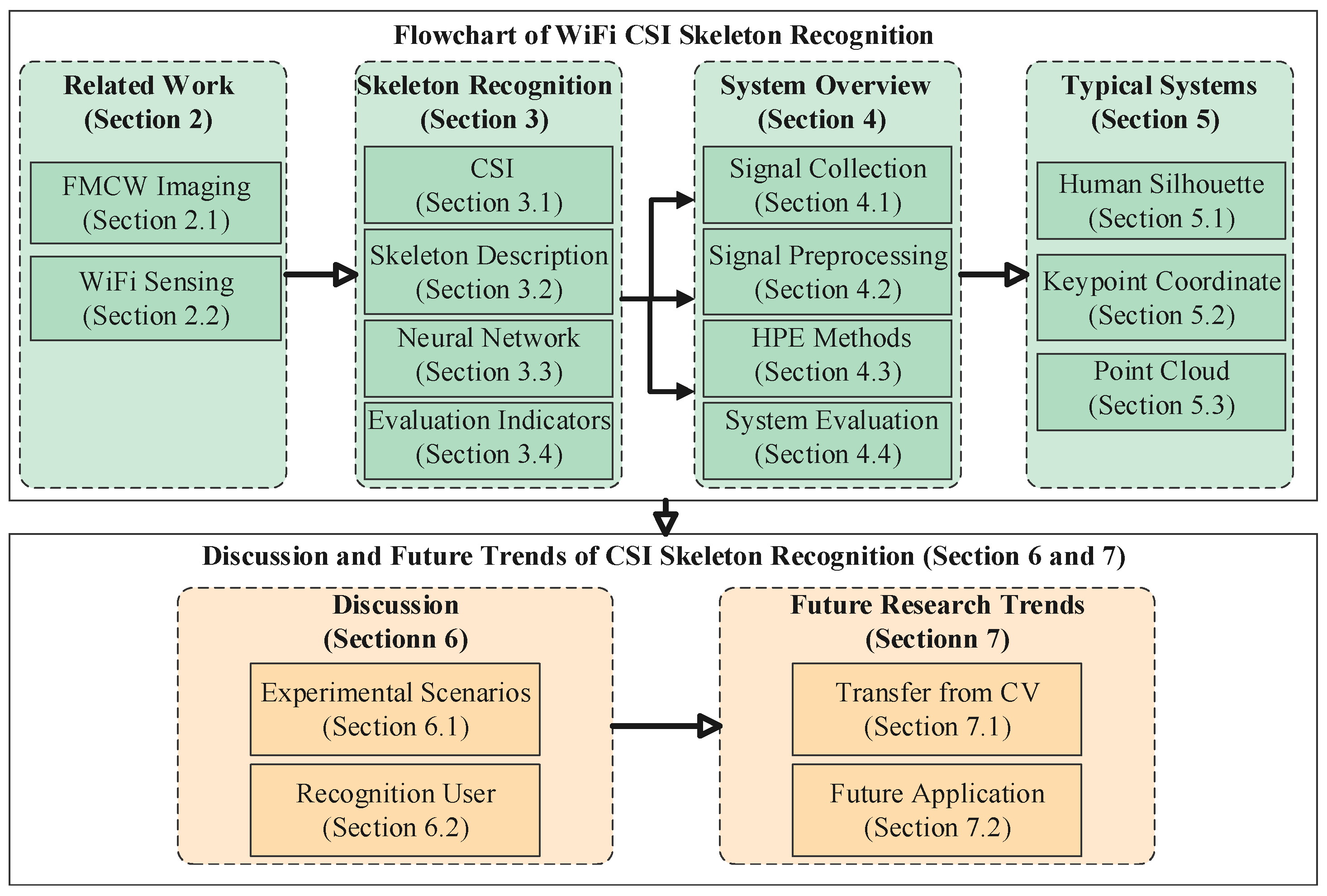
Skeleton-Based Human Pose Recognition Using Channel State Information: A Survey
Abstract
:
1. Introduction
- The first review. We investigate behavior recognition methods that are based on Wi-Fi signals and human skeletons. To the best of our knowledge, this is the first review of human pose recognition using CSI and human skeletons. This paper serves as a practical guide for understanding real-life applications using CSI to identify human skeletons.
- Comprehensive investigation. We present a general framework of precise pose recognition and comprehensively analyze the system components, which include data processing methods, neural network models, and performance results.
- Typical skeleton generation model. We classify skeleton model generation methods into three categories: the human silhouette, key point coordinate, and point cloud. We emphasize the crucial difference among these typical applications, as well as the advantages and disadvantages of these models.
- Discussion and future trends. We extensively discuss related factors that affect pose recognition from six aspects. In particular, we discuss the techniques that may be transferred from computer vision to CSI pose recognition.
2. Related Work on Human Pose Recognition Using RF
2.1. FMCW Imaging
2.1.1. Human Silhouette Generation by FMCW
2.1.2. Human Skeleton Generation by FMCW
2.2. Wi-Fi Sensing
2.2.1. Wi-Fi CSI Shape
2.2.2. Wi-Fi CSI Skeleton
3. Fundamental Knowledge of CSI Skeleton Recognition
3.1. Introduction to CSI
3.2. Basic Description of the Skeleton
- Skeleton-based action recognition has been widely used in computer vision due to its fast execution speed and strong ability to handle large datasets. Researchers can realize human action recognition by detecting changes in the position of joints, usually using techniques such as Kinect depth sensors (Xbox 360 Kinect, Kinect V2) [51,76,77,85], OpenPose [86], and Alphapose [87] to extract bone trajectories or poses.
- OpenPose and AlphaPose are the most commonly used algorithms in the process of generating human skeletons from images or video frames. OpenPose, which is a bottom-up approach, finds key points of the human body and joins them to the frame of the human [33,48,53,54,88]. In addition, it can estimate the human body and foot joints with the confidence score of each joint, e.g., 15 (OpenPose MPI), 18 (OpenPose-COCO), or 25 (OpenPose Body-25) keypoints, as shown in Figure 10c. In contrast, AlphaPose adopts the regional multiperson pose estimation (RMPE) framework to improve the pose estimation performance [49,52]. AlphaPose can estimate the 17 (Alphapose-COCO) or 26 (Halpe) key points of human joints. In CSI-based pose recognition, we usually choose a suitable method to extract the skeleton as the ground truth value.
3.3. Typical Neural Network Models
3.4. Performance Evaluation Indicators
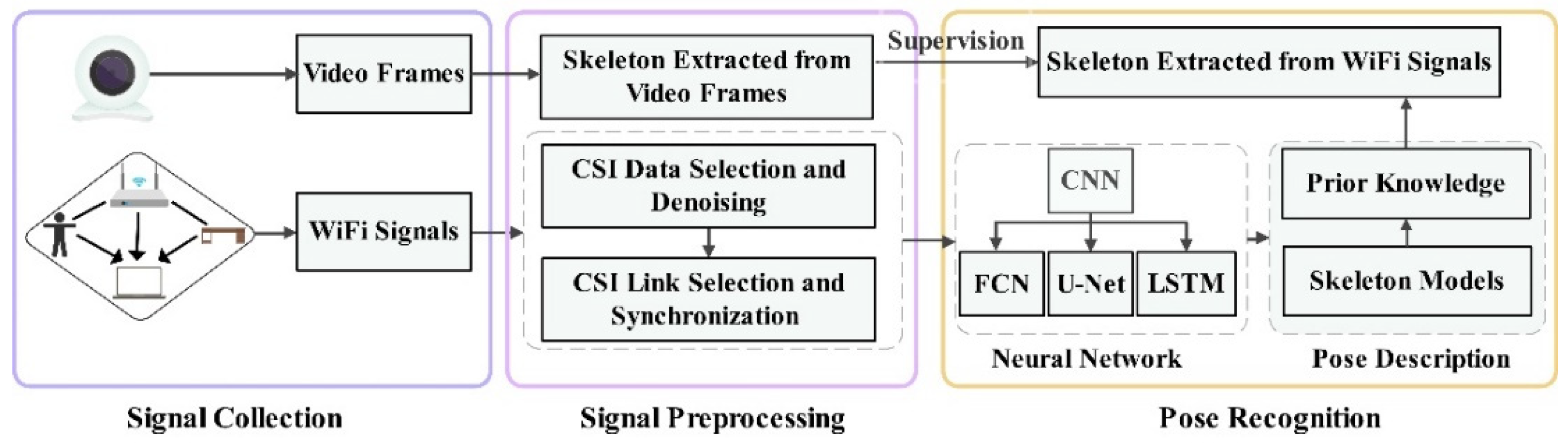
4. Pose Recognition Procedure
4.1. Signal Collection
4.2. Signal Preprocessing
4.2.1. CSI Signal Characteristics Selection and Denoising
4.2.2. Synchronization of Video Frames with CSI Samples
4.3. Pose Recognition Methods
4.4. System Performance Evaluation
4.4.1. Loss Function Selection
4.4.2. System Recognition Results
5. Typical Models of Generating the Human Skeleton
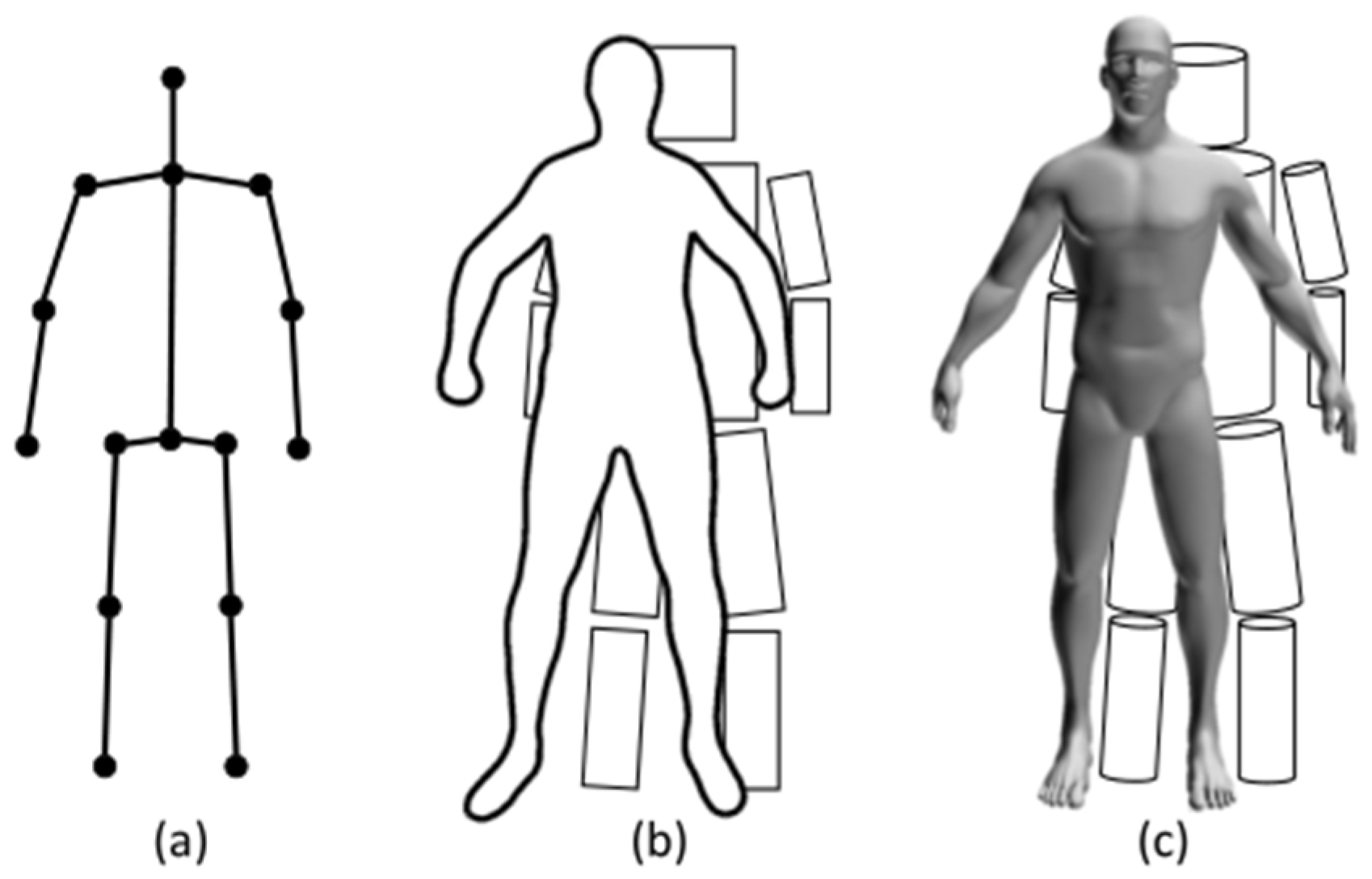
5.1. Skeleton Models Based on the Human Silhouette
5.2. Skeleton Models Based on Key Point Coordinate Regression
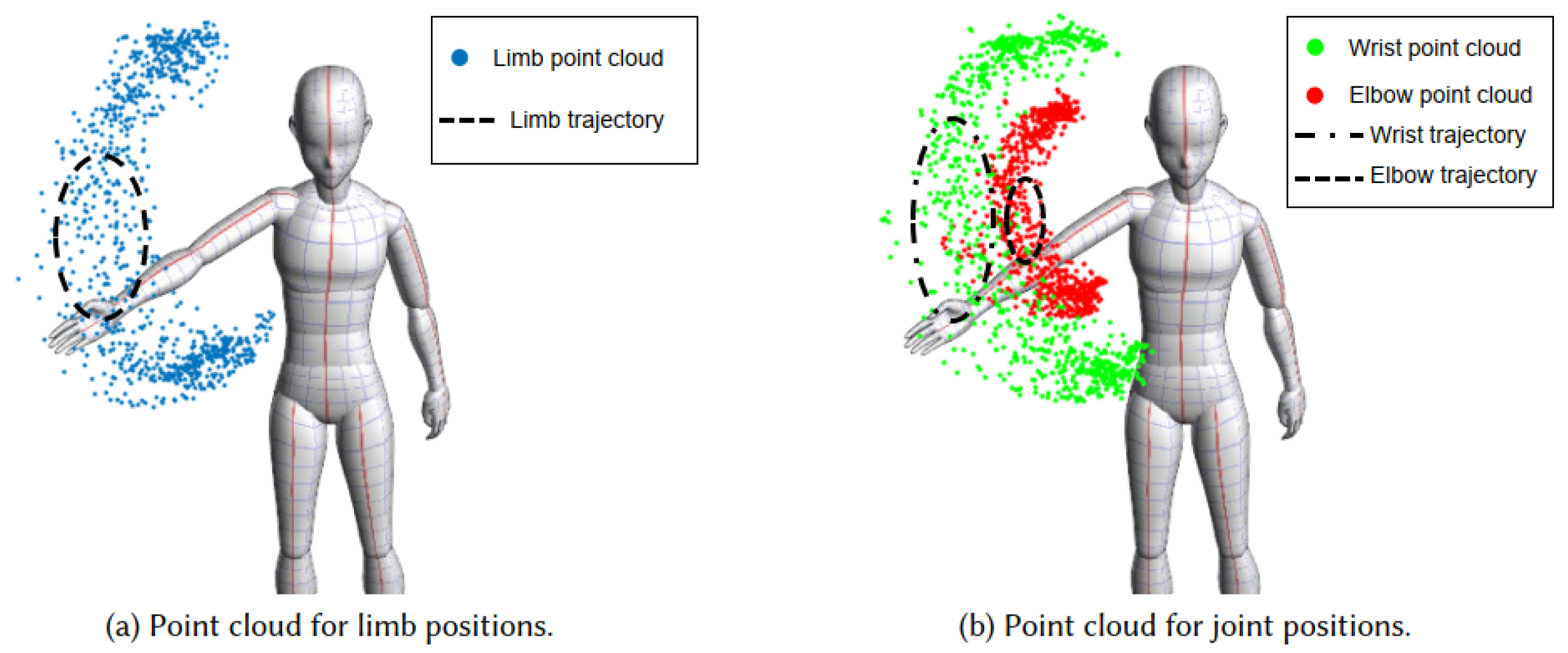
5.3. Skeleton Models Based on the Point Cloud

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Applications | Generating Skeleton Process | Strength | Weaknesses |
|---|---|---|---|---|
| Human Silhouette | [48,55,88] | CSI Data -> Segmentation Masks -> HeatMap (JHM and PAF) -> Silhouette -> Skeleton | This model has satisfactory spatial generalize ability and improves the positioning accuracy of key points. | Slow training and inference. |
| Key Point Coordinate | [33,49,52,53,54] | CSI Data -> Key Point Coordinate -> Skeleton | This model has the advantage of fast training speed. | Poor spatial generalization. |
| Skeleton Tree: [51]. | ||||
| Point Cloud | [77,97] | CSI Data -> Phase: AoA Estimate -> Joint Trajectory: Point Cloud -> Skeleton | This model combines a variety of data analysis algorithms to fully separate the CSI signals. | Unable to solve complex signal reflection separation in dynamic scenes. |
6. Discussion
6.1. Experimental Scenarios
6.1.1. LoS or NLoS
6.1.2. Robustness Discussion: Cross-Domain Scenarios and Stranger Situations
6.1.3. Different Distances and Packet Rate of Wi-Fi Devices
| System | Distance; Metric Performance | Packet Rate; Metric Performance |
|---|---|---|
| Winect [77] | 2 m; 4.6 cm | 250 pkts/s; 5.7 cm |
| 2.5 m; 4.9 cm | 500 pkts/s; 5.0 cm | |
| 3 m; 5.1 cm | 1000 pkts/s; 4.5 cm | |
| 3.5 m; 5.4 cm | - | |
| GoPose [97] | 2.5 m; 4.7 cm | 250 pkts/s; 5.7 cm |
| 3 m; 5.1 cm | 500 pkts/s; 5.3 cm | |
| 3.5 m; 5.8 cm | 1000 pkts/s; 4.7 cm |
6.2. Recognition User
6.2.1. 2D or 3D HPR
6.2.2. Single-Person or Multiperson HPR
6.2.3. Static or Dynamic HPR
7. Future Research Trends
7.1. Technique Transfer from Computer Vision
7.1.1. New Neural Network Structure
7.1.2. Realistic Pose Model and Complex Activity Description
7.2. Future Application Scenarios
7.2.1. Comprehensive Elderly Family Health Monitoring
7.2.2. Behavior Recognition in Public Areas
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Yu, Z.; Wang, Z. Human Behavior Analysis: Sensing and Understanding; Springer Nature Singapore Pte Ltd.: Singapore, 2020. [Google Scholar]
- Liu, J.; Liu, H.; Chen, Y.; Wang, Y.; Wang, C. Wireless Sensing for Human Activity: A Survey. IEEE Commun. Surv. Tutor. 2020, 22, 1629–1645. [Google Scholar] [CrossRef]
- Gupta, N.; Gupta, S.K.; Pathak, R.K.; Jain, V.; Rashidi, P.; Suri, J.S. Human activity recognition in artificial intelligence framework: A narrative review. Artif. Intell. Rev. 2022, 55, 4755–4808. [Google Scholar] [CrossRef] [PubMed]
- Pareek, P.; Thakkar, A. A survey on video-based Human Action Recognition: Recent updates, datasets, challenges, and applications. Artif. Intell. Rev. 2021, 54, 2259–2322. [Google Scholar] [CrossRef]
- Minh Dang, L.; Min, K.; Wang, H.; Jalil Piran, M.; Hee Lee, C.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Zhou, H.; Gao, Y.; Song, X.; Liu, W.; Dong, W. LimbMotion: Decimeter-level Limb Tracking for Wearable-based Human-Computer Interaction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 161. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.C. Wearable Sensors for Human Activity Monitoring: A Review. IEEE Sens. J. 2015, 15, 1321–1330. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Gao, Q.; Pan, M.; Fang, Y. Device-Free Wireless Sensing: Challenges, Opportunities, and Applications. IEEE Netw. 2018, 32, 132–137. [Google Scholar] [CrossRef]
- Zhang, R.; Jing, X.; Wu, S.; Jiang, C.; Mu, J.; Yu, F.R. Device-Free Wireless Sensing for Human Detection: The Deep Learning Perspective. IEEE Internet Things J. 2021, 8, 2517–2539. [Google Scholar] [CrossRef]
- Jayasundara, V.; Jayasekara, H.; Samarasinghe, T.; Hemachandra, K.T. Device-Free User Authentication, Activity Classification and Tracking Using Passive Wi-Fi Sensing: A Deep Learning-Based Approach. IEEE Sens. J. 2020, 20, 9329–9338. [Google Scholar] [CrossRef]
- Hussain, Z.; Sheng, Q.Z.; Zhang, W.E. A review and categorization of techniques on device-free human activity recognition. J. Netw. Comput. Appl. 2020, 167, 102738. [Google Scholar] [CrossRef]
- Thariq Ahmed, H.F.; Ahmad, H.; Vaithilingam, C.A. Device free human gesture recognition using Wi-Fi CSI: A survey. Eng. Appl. Artif. Intell. 2020, 87, 103281. [Google Scholar] [CrossRef]
- Adib, F.; Katabi, D. See through walls with WiFi! SIGCOMM Comput. Commun. Rev. 2013, 43, 75–86. [Google Scholar] [CrossRef] [Green Version]
- Cianca, E.; Sanctis, M.D.; Domenico, S.D. Radios as Sensors. IEEE Internet Things J. 2017, 4, 363–373. [Google Scholar] [CrossRef]
- Tan, S.; Yang, J. Commodity Wi-Fi Sensing in 10 Years: Current Status, Challenges, and Opportunities. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Zheng, T.; Chen, Z.; Luo, J.; Ke, L.; Zhao, C.; Yang, Y. SiWa: See into walls via deep UWB radar. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), New Orleans, LA, USA, 25–29 October 2021; pp. 323–336. [Google Scholar]
- Yamada, H.; Horiuchi, T. High-resolution Indoor Human detection by Using Millimeter-Wave MIMO Radar. In Proceedings of the 2020 International Workshop on Electromagnetics: Applications and Student Innovation Competition (iWEM), Makung, Taiwan, 26–28 August 2020; pp. 1–2. [Google Scholar]
- Nam, D.V.; Gon-Woo, K. Solid-State LiDAR based-SLAM: A Concise Review and Application. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 17–20 January 2021; pp. 302–305. [Google Scholar]
- Guan, J.; Madani, S.; Jog, S.; Gupta, S.; Hassanieh, H. Through Fog High-Resolution Imaging Using Millimeter Wave Radar. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 13–19 June 2020; pp. 11464–11473. [Google Scholar]
- Zheng, T.; Chen, Z.; Ding, S.; Luo, J. Enhancing RF Sensing with Deep Learning: A Layered Approach. IEEE Commun. Mag. 2021, 59, 70–76. [Google Scholar] [CrossRef]
- Haseeb, M.; Parasuraman, R. Wisture: RNN-based Learning of Wireless Signals for Gesture Recognition in Unmodified Smartphones. arXiv 2017, arXiv:1707.08569. [Google Scholar]
- Wang, J.; Zhang, X.; Gao, Q.; Yue, H.; Wang, H. Device-Free Wireless Localization and Activity Recognition: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2017, 66, 6258–6267. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor Localization via Channel Response. ACM Comput. Surv. 2013, 46, 25. [Google Scholar] [CrossRef]
- Li, W.; Bocus, M.J.; Tang, C.; Vishwakarma, S.; Piechocki, R.J.; Woodbridge, K.; Chetty, K. A Taxonomy of WiFi Sensing: CSI vs Passive WiFi Radar. In Proceedings of the IEEE Global Communications Conference (GlobeCom), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Pham, C.; Nguyen, L.; Nguyen, A.; Nguyen, N.; Nguyen, V.-T. Combining skeleton and accelerometer data for human fine-grained activity recognition and abnormal behaviour detection with deep temporal convolutional networks. Multimed. Tools Appl. 2021, 80, 28919–28940. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, F.; Hu, Y.; Liu, K.J.R. GaitWay: Monitoring and Recognizing Gait Speed Through the Walls. IEEE Trans. Mob. Comput. 2021, 20, 2186–2199. [Google Scholar] [CrossRef]
- Ngamakeur, K.; Yongchareon, S.; Yu, J.; Rehman, S.U. A Survey on Device-free Indoor Localization and Tracking in the Multi-resident Environment. ACM Comput. Surv. 2020, 53, 71. [Google Scholar] [CrossRef]
- Li, H.; Zeng, X.; Li, Y.; Zhou, S.; Wang, J. Convolutional neural networks based indoor Wi-Fi localization with a novel kind of CSI images. China Commun. 2019, 16, 250–260. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, F.; Wu, C.; Wang, B.; Liu, K.J.R. ViMo: Vital Sign Monitoring Using Commodity Millimeter Wave Radio. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8304–8308. [Google Scholar]
- Zhang, F.; Wu, C.; Wang, B.; Wu, M.; Bugos, D.; Zhang, H.; Liu, K.J.R. SMARS: Sleep Monitoring via Ambient Radio Signals. IEEE Trans. Mob. Comput. 2021, 20, 217–231. [Google Scholar] [CrossRef]
- Zeng, Y.; Wu, D.; Xiong, J.; Yi, E.; Gao, R.; Zhang, D. FarSense: Pushing the Range Limit of WiFi-Based Respiration Sensing with CSI Ratio of Two Antennas. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 121. [Google Scholar] [CrossRef] [Green Version]
- Guo, L.; Lu, Z.; Zhou, S.; Wen, X.; He, Z. When Healthcare Meets Off-the-Shelf WiFi: A Non-Wearable and Low-Costs Approach for In-Home Monitoring. arXiv 2020, arXiv:2009.09715. [Google Scholar]
- Li, C.; Cao, Z.; Liu, Y. Deep AI Enabled Ubiquitous Wireless Sensing: A Survey. ACM Comput. Surv. 2021, 54, 32. [Google Scholar] [CrossRef]
- Ren, B.; Liu, M.; Ding, R.; Liu, H. A Survey on 3D Skeleton-Based Action Recognition Using Learning Method. arXiv 2020, arXiv:2002.05907. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-End Recovery of Human Shape and Pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7122–7131. [Google Scholar]
- Zhao, M.; Liu, Y.; Raghu, A.; Zhao, H.; Li, T.; Torralba, A.; Katabi, D. Through-Wall Human Mesh Recovery Using Radio Signals. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 10112–10121. [Google Scholar]
- Isogawa, M.; Yuan, Y.; Toole, M.O.; Kitani, K. Optical Non-Line-of-Sight Physics-Based 3D Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 13–19 June 2020; pp. 7011–7020. [Google Scholar]
- Ruget, A.; Tyler, M.; Mora-Martín, G.; Scholes, S.; Zhu, F.; Gyöngy, I.; Hearn, B.; Mclaughlin, S.; Halimi, A.; Leach, J. Real-time, low-cost multi-person 3D pose estimation. arXiv 2021, arXiv:1901.03953. [Google Scholar]
- Kotaru, M.; Satat, G.; Raskar, R.; Katti, S. Light-Field for RF. arXiv 2019, arXiv:1901.03953. [Google Scholar]
- Kato, S.; Fukushima, T.; Murakami, T.; Abeysekera, H.; Iwasaki, Y.; Fujihashi, T.; Watanabe, T.; Saruwatari, S. CSI2Image: Image Reconstruction from Channel State Information Using Generative Adversarial Networks. IEEE Access 2021, 9, 47154–47168. [Google Scholar] [CrossRef]
- Zhong, W.; He, K.; Li, L. Through-the-Wall Imaging Exploiting 2.4 GHz Commodity Wi-Fi. arXiv 2019, arXiv:1903.03895. [Google Scholar]
- Kefayati, M.H.; Pourahmadi, V.; Aghaeinia, H. Wi2Vi: Generating Video Frames from WiFi CSI Samples. IEEE Sens. J. 2020, 20, 11463–11473. [Google Scholar] [CrossRef]
- Adib, F.; Hsu, C.-Y.; Mao, H.; Katabi, D.; Durand, F. Capturing the human figure through a wall. ACM Trans. Graph. 2015, 34, 219. [Google Scholar] [CrossRef]
- Hsu, C.-Y.; Hristov, R.; Lee, G.-H.; Zhao, M.; Katabi, D. Enabling Identification and Behavioral Sensing in Homes using Radio Reflections. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Yu, C.; Wu, Z.; Zhang, D.; Lu, Z.; Hu, Y.; Chen, Y. RFGAN: RF-Based Human Synthesis. arXiv 2021, arXiv:2112.03727. [Google Scholar] [CrossRef]
- Zheng, Z.; Pan, J.; Ni, Z.; Shi, C.; Ye, S.; Fang, G. Human Posture Reconstruction for through-the-Wall Radar Imaging Using Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, F.; Zhou, S.; Panev, S.; Han, J.; Huang, D. Person-in-WiFi: Fine-Grained Person Perception Using WiFi. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5451–5460. [Google Scholar]
- Wang, F.; Panev, S.; Ziyi, D.; Han, J.; Huang, D. Can WiFi Estimate Person Pose? arXiv 2019, arXiv:1904.00277. [Google Scholar]
- Li, C.; Liu, Z.; Yao, Y.; Cao, Z.; Zhang, M.; Liu, Y. Wi-fi see it all: Generative adversarial network-augmented versatile wi-fi imaging. In Proceedings of the 18th Conference on Embedded Networked Sensor Systems, Virtual Event, 16–19 November 2020; pp. 436–448. [Google Scholar]
- Jiang, W.; Xue, H.; Miao, C.; Wang, S.; Lin, S.; Tian, C.; Murali, S.; Hu, H.; Sun, Z.; Su, L. Towards 3D human pose construction using wifi. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London, UK, 21–25 September 2020; pp. 1–14. [Google Scholar]
- Wang, Y.; Guo, L.; Lu, Z.; Wen, X.; Zhou, S.; Meng, W. From Point to Space: 3D Moving Human Pose Estimation Using Commodity WiFi. IEEE Commun. Lett. 2020, 25, 2235–2239. [Google Scholar] [CrossRef]
- Guo, L.; Lu, Z.; Wen, X.; Zhou, S.; Han, Z. From Signal to Image: Capturing Fine-Grained Human Poses with Commodity Wi-Fi. IEEE Commun. Lett. 2020, 24, 802–806. [Google Scholar] [CrossRef]
- Zhou, S.; Guo, L.; Lu, Z.; Wen, X.; Zheng, W.; Wang, Y. Subject-independent Human Pose Image Construction with Commodity Wi-Fi. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Avola, D.; Cascio, M.; Cinque, L.; Fagioli, A.; Foresti, G.L. Human Silhouette and Skeleton Video Synthesis through Wi-Fi signals. arXiv 2022, arXiv:2203.05864. [Google Scholar] [CrossRef]
- Yang, C.; Wang, L.; Wang, X.; Mao, S. Environment Adaptive RFID based 3D Human Pose Tracking with a Meta-learning Approach. IEEE J. Radio Freq. Identif. 2022, 6, 413–425. [Google Scholar] [CrossRef]
- Ma, Y.; Zhou, G.; Wang, S. WiFi Sensing with Channel State Information: A Survey. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Jiang, K.; Hou, Y.; Dou, W.; Zhang, C.; Huang, Z.; Guo, Y. A Survey on Human Behavior Recognition Using Channel State Information. IEEE Access 2019, 7, 155986–156024. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A.; Abd Elaziz, M.; Kim, S.; Ewees, A.A.; Abbasi, A.A.; Alhaj, Y.A.; Hawbani, A. Channel State Information from Pure Communication to Sense and Track Human Motion: A Survey. Sensors 2019, 19, 3329. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Wu, W.; Yang, T.; Zhu, S.; Chen, C.; Liu, R.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep Learning-Based Human Pose Estimation: A Survey. arXiv 2020, arXiv:2012.13392. [Google Scholar]
- Yang, Z.; Qian, K.; Wu, C.; Zhang, Y. Smart Wireless Sensing—From IoT to AIoT; Springer: Berlin/Heidelberg, Germany, 2021; pp. 3–234. [Google Scholar]
- Yanik, M.E.; Torlak, M. Near-Field MIMO-SAR Millimeter-Wave Imaging with Sparsely Sampled Aperture Data. IEEE Access 2019, 7, 31801–31819. [Google Scholar] [CrossRef]
- Li, T.; Fan, L.; Yuan, Y.; Katabi, D. Unsupervised Learning for Human Sensing Using Radio Signals. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1091–1100. [Google Scholar]
- Wu, Z.; Zhang, D.; Xie, C.; Yu, C.; Chen, J.; Hu, Y.; Chen, Y. RFMask: A Simple Baseline for Human Silhouette Segmentation with Radio Signals. IEEE Trans. Multimed. 2022, 1–12. [Google Scholar] [CrossRef]
- Guo, H.; Zhang, N.; Shi, W.; Ali-Alqarni, S.; Wang, H. Real-Time Indoor 3D Human Imaging Based on MIMO Radar Sensing. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1408–1413. [Google Scholar]
- Meng, K.; Meng, Y. Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 14–21. [Google Scholar]
- Zhao, M.; Li, T.; Alsheikh, M.A.; Tian, Y.; Zhao, H.; Torralba, A.; Katabi, D. Through-Wall Human Pose Estimation Using Radio Signals. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7356–7365. [Google Scholar]
- Zhao, M.; Tian, Y.; Zhao, H.; Alsheikh, M.A.; Li, T.; Hristov, R.; Kabelac, Z.; Katabi, D.; Torralba, A. RF-based 3D skeletons. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 267–281. [Google Scholar]
- Li, T.; Fan, L.; Zhao, M.; Liu, Y.; Katabi, D. Making the Invisible Visible: Action Recognition Through Walls and Occlusions. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 872–881. [Google Scholar]
- Du, H.; Jin, T.; He, Y.; Song, Y.; Dai, Y. Segmented convolutional gated recurrent neural networks for human activity recognition in ultra-wideband radar. Neurocomputing 2020, 396, 451–464. [Google Scholar] [CrossRef]
- Sengupta, A.; Cao, S. mmPose-NLP: A Natural Language Processing Approach to Precise Skeletal Pose Estimation Using mmWave Radars. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Ding, W.; Cao, Z.; Zhang, J.; Chen, R.; Guo, X.; Wang, G. Radar-Based 3D Human Skeleton Estimation by Kinematic Constrained Learning. IEEE Sens. J. 2021, 21, 23174–23184. [Google Scholar] [CrossRef]
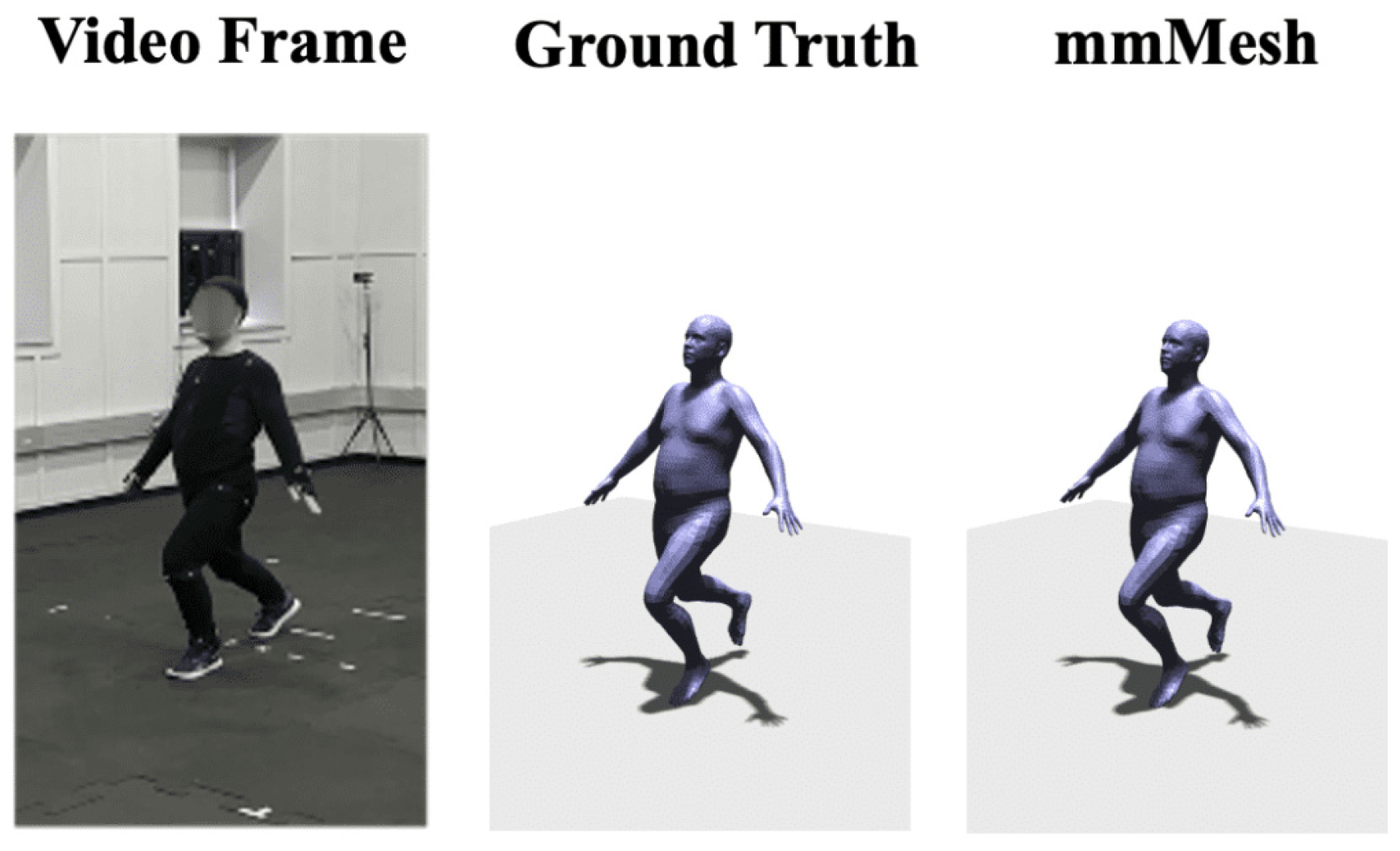
- Xue, H.; Ju, Y.; Miao, C.; Wang, Y.; Wang, S.; Zhang, A.; Su, L. mmMesh: Towards 3D real-time dynamic human mesh construction using millimeter-wave. In Proceedings of the 19th Annual International Conference on Mobile Systems, Applications, and Services, Virtual Event, 24 June–2 July 2021; pp. 269–282. [Google Scholar]
- Shi, C.; Lu, L.; Liu, J.; Wang, Y.; Chen, Y.; Yu, J. mPose: Environment- and subject-agnostic 3D skeleton posture reconstruction leveraging a single mmWave device. Smart Health 2022, 23, 100228. [Google Scholar] [CrossRef]
- Fürst, M.; Gupta, S.T.P.; Schuster, R.; Wasenmüller, O.; Stricker, D. HPERL: 3D Human Pose Estimation from RGB and LiDAR. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7321–7327. [Google Scholar]
- Zhang, F.; Wu, C.; Wang, B.; Liu, K.J.R. mmEye: Super-Resolution Millimeter Wave Imaging. IEEE Internet Things J. 2021, 8, 6995–7008. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, Z.; Tan, S.; Chen, Y.; Yang, J. Winect: 3D Human Pose Tracking for Free-form Activity Using Commodity WiFi. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 5, 176. [Google Scholar] [CrossRef]
- IEEE Std. 802.11n-2009; Enhancements for Higher Throughput. IEEE: New York, NY, USA, 2009; pp. 1–565.
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool release: Gathering 802.11n traces with channel state information. SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Predictable 802.11 packet delivery from wireless channel measurements. In Proceedings of the ACM SIGCOMM 2010 Conference, New Delhi, India, 30 August–3 September 2010; pp. 159–170. [Google Scholar]
- Xie, Y.; Li, Z.; Li, M. Precise Power Delay Profiling with Commodity Wi-Fi. IEEE Trans. Mob. Comput. 2019, 18, 1342–1355. [Google Scholar] [CrossRef]
- Gringoli, F.; Schulz, M.; Link, J.; Hollick, M. Free Your CSI: A Channel State Information Extraction Platform for Modern Wi-Fi Chipsets. In Proceedings of the 13th International Workshop on Wireless Network Testbeds, Experimental Evaluation & Characterization, Los Cabos, Mexico, 25 October 2019; pp. 21–28. [Google Scholar]
- Hernandez, S.M.; Bulut, E. Lightweight and Standalone IoT Based WiFi Sensing for Active Repositioning and Mobility. In Proceedings of the 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Cork, Ireland, 31 August–3 September 2020; pp. 277–286. [Google Scholar]
- Ramacher, U.; Raab, W.; Hachmann, U.; Langen, D.; Berthold, J.; Kramer, R.; Schackow, A.; Grassmann, C.; Sauermann, M.; Szreder, P.; et al. Architecture and implementation of a Software-Defined Radio baseband processor. In Proceedings of the 2011 IEEE International Symposium of Circuits and Systems (ISCAS), Rio de Janeiro, Brazil, 15–18 May 2011; pp. 2193–2196. [Google Scholar]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE MultiMedia 2012, 19, 4–10. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Fang, H.; Xie, S.; Tai, Y.-W.; Lu, C. RMPE: Regional Multi-person Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2353–2362. [Google Scholar]
- Huang, Y.; Li, X.; Wang, W.; Jiang, T.; Zhang, Q. Towards Cross-Modal Forgery Detection and Localization on Live Surveillance Videos. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Ahad, M.A.R.; Mahbub, U.; Rahman, T. (Eds.) Contactless Human Activity Analysis; Springer: Cham, Switzerland, 2021; Volume 200. [Google Scholar]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and Wireless Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Lecun, Y.; Hinton, G. Deep learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2019, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Nirmal, I.; Khamis, A.; Hassan, M.; Hu, W.; Zhu, X.Q. Deep Learning for Radio-Based Human Sensing: Recent Advances and Future Directions. IEEE Commun. Surv. Tutor. 2021, 23, 995–1019. [Google Scholar] [CrossRef]
- Luigi, B.; Francesco Carlo, M. Neural Network Design using a Virtual Reality Platform. Glob. J. Comput. Sci. Technol. 2022, 22, 45–61. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, D.; Xu, C.; Wang, H.; Li, X. Device-Free WiFi Human Sensing: From Pattern-Based to Model-Based Approaches. IEEE Commun. Mag. 2017, 55, 91–97. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, Z.; Wang, Y.; Tan, S.; Chen, Y.; Yang, J. GoPose: 3D Human Pose Estimation Using WiFi. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 69. [Google Scholar] [CrossRef]
- Abrard, F.; Deville, Y. A time-frequency blind signal separation method applicable to underdetermined mixtures of dependent sources. Signal Process. 2005, 85, 1389–1403. [Google Scholar] [CrossRef]
- Güler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation in the Wild. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7297–7306. [Google Scholar]
- Feng, M.; Meunier, J. Skeleton Graph-Neural-Network-Based Human Action Recognition: A Survey. Sensors 2022, 22, 2091. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, Y.; Zhao, W.; Tang, J. A comparative review of graph convolutional networks for human skeleton-based action recognition. Artif. Intell. Rev. 2021, 55, 4275–4305. [Google Scholar] [CrossRef]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11636–11645. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–13. [Google Scholar] [CrossRef]
- Liu, S.; Bai, X.; Fang, M.; Li, L.; Hung, C.-C. Mixed graph convolution and residual transformation network for skeleton-based action recognition. Appl. Intell. 2022, 52, 1544–1555. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Y.; Yang, J.; Luo, J. Action Recognition with Spatio–Temporal Visual Attention on Skeleton Image Sequences. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2405–2415. [Google Scholar] [CrossRef] [Green Version]
- Sekii, T. Pose Proposal Networks. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 350–366. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Yan, S.J.; Xiong, Y.J.; Lin, D.H. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the Thirty-Second Aaai Conference on Artificial Intelligence/Thirtieth Innovative Applications of Artificial Intelligence Conference/Eighth Aaai Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Joo, H.; Simon, T.; Sheikh, Y. Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8320–8329. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional Human Pose Regression. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2621–2630. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Directed Graph Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 13–19 June 2020; pp. 7912–7921. [Google Scholar]
- Li, M.; Chen, S.; Zhao, Y.; Zhang, Y.; Wang, Y.; Tian, Q. Dynamic Multiscale Graph Neural Networks for 3D Skeleton Based Human Motion Prediction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 13–19 June 2020; pp. 211–220. [Google Scholar]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Song, L.; Yu, G.; Yuan, J.; Liu, Z. Human pose estimation and its application to action recognition: A survey. J. Vis. Commun. Image Represent. 2021, 76, 103055. [Google Scholar] [CrossRef]
- Duan, H.; Zhao, Y.; Chen, K.; Shao, D.; Lin, D.; Dai, B. Revisiting Skeleton-based Action Recognition. arXiv 2022, arXiv:2104.13586. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Neural Networks for High Performance Skeleton-Based Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1963–1978. [Google Scholar] [CrossRef] [Green Version]
- Shao, D.; Zhao, Y.; Dai, B.; Lin, D. FineGym: A Hierarchical Video Dataset for Fine-Grained Action Understanding. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 13–19 June 2020; pp. 2613–2622. [Google Scholar]
- Xu, J.; Rao, Y.; Yu, X.; Chen, G.; Zhou, J.; Lu, J. FineDiving: A Fine-grained Dataset for Procedure-aware Action Quality Assessment. arXiv 2022, arXiv:2204.03646. [Google Scholar]
- Toshpulatov, M.; Lee, W.; Lee, S.; Haghighian Roudsari, A. Human pose, hand and mesh estimation using deep learning: A survey. J. Supercomput. 2022, 78, 7616–7654. [Google Scholar] [CrossRef]
- Ge, Y.; Taha, A.; Shah, S.A.; Dashtipour, K.; Zhu, S.; Cooper, J.M.; Abbasi, Q.; Imran, M. Contactless WiFi Sensing and Monitoring for Future Healthcare—Emerging Trends, Challenges and Opportunities. IEEE Rev. Biomed. Eng. 2022. [Google Scholar] [CrossRef]
- Niu, X.P.; Li, S.J.; Zhang, Y.; Liu, Z.P.; Wu, D.; Shah, R.C.; Tanriover, C.; Lu, H.; Zhang, D.Q. WiMonitor: Continuous Long-Term Human Vitality Monitoring Using Commodity Wi-Fi Devices. Sensors 2021, 21, 751. [Google Scholar] [CrossRef]
- Cotton, R.J. PosePipe: Open-Source Human Pose Estimation Pipeline for Clinical Research. arXiv 2022, arXiv:2203.08792. [Google Scholar]
- Qiu, J.; Yan, X.; Wang, W.; Wei, W.; Fang, K. Skeleton-Based Abnormal Behavior Detection Using Secure Partitioned Convolutional Neural Network Model. IEEE J. Biomed. Health Inform. 2021. [Google Scholar] [CrossRef]
- Yu, B.X.B.; Liu, Y.; Chan, K.C.C.; Yang, Q.; Wang, X. Skeleton-based human action evaluation using graph convolutional network for monitoring Alzheimer’s progression. Pattern Recognit. 2021, 119, 108095. [Google Scholar] [CrossRef]
- Guo, L.; Lu, Z.; Zhou, S.; Wen, X.; He, Z. Emergency Semantic Feature Vector Extraction from WiFi Signals for In-Home Monitoring of Elderly. IEEE J. Sel. Top. Signal Process. 2021, 15, 1423–1438. [Google Scholar] [CrossRef]
- Cormier, M.; Clepe, A.; Specker, A.; Beyerer, J. Where are we with Human Pose Estimation in Real-World Surveillance? In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 4–8 January 2022; pp. 591–601. [Google Scholar]
- Depatla, S.; Mostofi, Y. Passive Crowd Speed Estimation in Adjacent Regions with Minimal WiFi Sensing. IEEE Trans. Mob. Comput. 2020, 19, 2429–2444. [Google Scholar] [CrossRef]
- Yu, S.; Zhao, Z.; Fang, H.; Deng, A.; Su, H.; Wang, D.; Gan, W.; Lu, C.; Wu, W. Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection. arXiv 2021, arXiv:2112.03649. [Google Scholar]








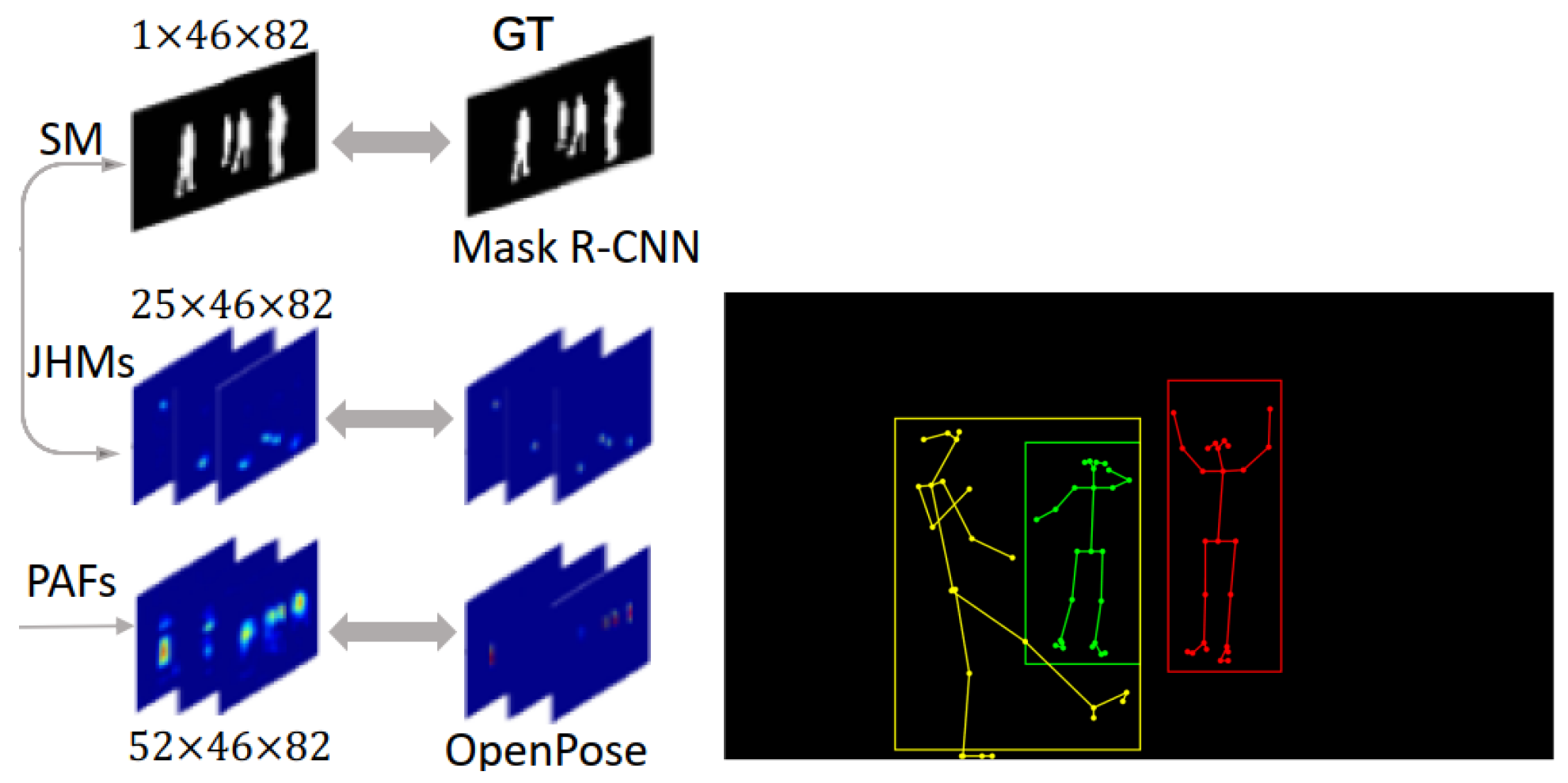


| Evaluation Metric | Application | Formula | |
|---|---|---|---|
| Percentage of Correct Keypoints (PCK) PCK@a | [48,49,88] | (4) | |
| Average Precision (AP) | [48] | (5) | |
| Percentage of Correct Skeletons (PCS) PCS ◦ θ | [33,53,54,55] | (6) | |
| Mean Per Joint Position Error (P-MPJPE)(mm) | [51,52] | (7) | |
| System | Device | Signals and Preprocess | Experiment | Number of Data |
|---|---|---|---|---|
| WiSPPN [49] | 5300NIC; one sender and one receiver; 2.4 GHz frequency with 20 MHz. | Amplitude | Eight volunteers, daily actions in two rooms of the campus, one laboratory room and one classroom. | 80 k images, training and testing sample sizes are 79,496 and 19,931; 80%: training; 20%: test. |
| Person-in-Wi-Fi [48] | 5300NIC; three receiver antennas, 2.4 GHz, 20 MHz. | Amplitude | Eight volunteers, one laboratory room and one classroom; 100 Hz from receiver antennas and videos at 20 FPS. | Training and testing sample sizes are 123,631 and 30,996; 80%: training; 20%: test. |
| Wi-Pose [53] | 5300NIC; 3 commodity Wi-Fi devices (one transmitter and two transceivers); 5 GHz, 20 MHz. | Amplitude; DWT | Five volunteers, environment is approximately 7 m × 8 m; CSI at 100 Hz and videos at 20 Hz; | 1,800,000 CSI samples at each receiver; 75%: training; 25%: test. |
| [33] | 5300NIC; 3 commodity Wi-Fi devices; 5 GHz, 20 MHz. | Amplitude and phase; PCA; DWT; Hampel Filtering. | CSI at 100 Hz, and the video collection frequency at 20 Hz. | - |
| DINN [54] | 5300NIC; 5 GHz frequency band with 20 MHz. | Amplitude | 7 m × 8 m | 10 h of data for 5 people; 5,400,000 CSI samples at each receiver; 75%: training; 25%: test. |
| Wi-Pose [51] | One laptop and three desktops, 5300NIC; 21 VICON Vantage cameras; 5.825 GHz; 20 MHz. | Amplitude and phase; conjugate multiplication (CM). | Ten volunteers; CSI at 1000 Hz, and the video collection frequency at 10 Hz. | 70%: training; 30%: test. |
| Wi-Mose [52] | Three commodity Wi-Fi devices; 5 GHz; 20 MHz. | Amplitude and phase; CM. | Five volunteers; the environment is approximately 7 m × 8 m; CSI data at 150 Hz and video frames at 30 Hz. | 10 h of data for 5 people; 5,400,000 CSI samples at each receiver; 75%: training; 25%: test. |
| Secure-Pose [88] | A Logitech 720p camera and Intel 5300 NICs; 5.6 GHz; 20 MHz. | Amplitude; Hampel Filtering. | Five volunteers; environment is approximately 8 m × 16 m; CSI at 100 Hz, and the video collection frequency at 20 Hz. | 12,000 CSI samples |
| Winect [77] | Five laptops: one transmitter, four receivers; 5.32 GHz; 40 MHz. | Amplitude and phase; BSS. | Six volunteers (3 males and 3 females); one living room and bedroom. | Each volunteer performs various activities for at least 20 min. |
| [55] | 5300NIC; 3 commodity Wi-Fi devices; 5 GHz, 20 MHz. | Amplitude; Hampel Filtering. | Five volunteers, environment is approximately 7 m × 8 m; CSI at 100 Hz and videos at 20 Hz. | 75%: training; 25%: test. |
| mmEye [76] | Qualcomm 802.11ad Chipsets; 60 GHz frequency band with 3.52 GHz. | Amplitude and phase | Four volunteers; a typical office is approximately 28 m × 36 m. | Each subject performs 10 to 15 different postures for approximately 30 s. |
| GoPose [97] | Five laptops: one transmitter, four receivers; 5.32 GHz; 40 MHz. | AoA | Ten volunteers; a living room (4 m × 4 m), a dining room (3.6 m × 3.6 m), and a bedroom (4 m × 3.8 m). | The total time span of data collection is one month. |
| Model | System | Neural Network Implementation | Training Details | Output |
|---|---|---|---|---|
| CNN | Wi-Pose [53] | Encoder network: three layers (3 × 3 convolutions), one layer (1 × 1 convolutions) and a fully connected layer. Decoder network: two layers (1 × 1 convolutions) and five layers (3 × 3 convolutions). | Adam optimizer; learning rate: 0.001; batch size: 16. | Key point coordinates |
| [33] | Encoder network: three layers (3 × 3 convolutions), three layers (1 × 1 convolutions), a fully connected layer and an SE block. Decoder network: the same structure as in [53]. | Adam optimizer; learning rate: 0.001; batch size: 16. | Key point coordinates | |
| Wi-Mose [52] | Feature network: 13 residual blocks and a batch normalization layer. Key-point regression network: two fully connected layers | Adam optimizer. The initial learning rate is 0.001, which is multiplied by 0.9 after every epoch. | Key point coordinates | |
| DINN [54] | Feature extractor, generator and domain discriminator. | Two Adam optimizers. One optimizes the feature extractor and generator networks: 0.001, the other optimizes the discriminator network: 0.0001. | Key point coordinates and the predicted domain | |
| Secure-Pose [88] | CSI transformer, JHM generator and PAF generator. | The batch size is 1, and an RMSprop optimizer with a weight decay of 1 × 10−8 and momentum of 0.9 is used. The CSI2Pose network: 1 × 10−6, the detection network: 1 × 10−5. | JHMs, PAFs | |
| Winect [77] | ResNet 18: 17 convolutional layers and one fully connected layer. | Adam optimizer, dropout rate is 0.1. | Key point coordinates | |
| Hybrid model | Person-in-Wi-Fi [48] | CNN + U-Net | Adam optimizer; learning rate: 0.001; batch size: 32. | JHMs, PAFs |
| WiSPPN [49] | ResNet + CSI-Net + FCN | Adam optimizer; Initial learning rate of 0.001, which decays by 0.5 at the 5th, 10th and 15th epochs; a batch size of 32. | Key point coordinates | |
| Wi-Pose [51] | CNN + LSTM | - | Key point coordinates | |
| [55] | LSTM + 3D-CNN | Adam optimizer; Initial learning rate of 0.0002; an ϵ numerical stability parameter is 1 × 10−8. | JHMs, PAFs | |
| GoPose [97] | CNN + LSTM | - | Key point coordinates |
| Loss Functions | Applications | Formula | |
|---|---|---|---|
| Binary Cross Entropy Loss | [48,54] | (8) | |
| Average of Binary Cross Entropy Loss | [39,53] | (9) | |
| Average Euclidean Distance Error | [51,52,77] | (10) | |
| Mean Squared Error (MSE) Loss | [55,88] | (11) | |
| Pose Adjacent Matrix Similarity Loss | [49] | (12) | |
| Dice Loss | [88] | (13) | |
| Model | Metric Performance |
|---|---|
| WiSPPN [49] | PCK@a; PCK@5,0.04;PCK@10,0.14;PCK@20,0.38;PCK@30,0.59;PCK@40,0.73;PCK@50,0.82. |
| Person-in Wi-Fi [48] | PCK@0.2 PCK@0.2,78.75% |
| Wi-Pose [53] | PCS ◦ θ; θ = 30, 26.2%; θ = 50, 90.9%. |
| [33] | PCS ◦ θ Case1: θ = 30, 80.7%; θ = 50, 99.3% Case2: θ = 30, 73.0%; θ = 50, 99.4% Case3: θ = 30, 26.9%; θ = 50, 91.6% Case4: θ = 30, 15.0%; θ = 50, 80.3% |
| Wi-Mose [52] | P-MPJPE (mm); [51]: 37.6%; [52]: 29.7%. |
| DINN [54] | PCS ◦ θ 65.99% (50.27%) and 100% (99.82%). |
| Wi-Pose [51] | Basic Scenario; Occluded Scenario; Cross-domain Posture Construction. |
| Secure-Pose [88] | Cumulative Distribution Function (CDF); It has achieved a high detection accuracy of 95.1%. |
| Winect [77] | CDF (cm) Wi-Pose: 10.1 cm; Winect: 4.6 cm. |
| [55] | PCS ◦ θ PCS ◦ 50 Wi-Pose: 90.9%; [55]: 100.0%. |
| GoPose [97] | CDF (cm) GoPose: 4.7 cm |
| System | Scenarios | Metric Performance |
|---|---|---|
| DINN [54] | Visible Scenario | PCS:100% (loosely), 66.5% (strictly) |
| Through-wall Scenario | 99.82% (loosely), 57.83% (strictly) | |
| [33] | Visible Scenario | PCS ◦ θ same volunteer: θ = 25, 26.7%; θ = 30, 80.7%; θ = 40, 98.7%; θ = 50, 99.3% different volunteers: θ = 25, 2.5%; θ = 30, 26.9%; θ = 40, 77.2%; θ = 50, 91.6% |
| Occluded Scenario | same volunteer: θ = 25, 23.4%; θ = 30, 73.0%; θ = 40, 98.9%; θ = 50, 99.4% different volunteers: θ = 25, 1.6%; θ = 30, 15.0%; θ = 40, 60.1%; θ = 50, 80.3% | |
| Wi-Pose [51] | Visible Scenario | Average joint localization errors (mm): 95.3 |
| Occluded Scenario | Average joint localization errors (mm): 121.6 | |
| Wi-Mose [52] | Visible Scenario | (The larger the P-MPJPE is, the larger the error is) 42.6 mm |
| Occluded Scenario | 46.8 mm | |
| Winect [77] | Visible Scenario | Average joint localization errors (mm): 4.3 |
| Occluded Scenario | Average joint localization errors (mm): 5.5 | |
| GoPose [97] | Visible Scenario | Average joint localization errors (mm): 4.7 |
| Occluded Scenario | Average joint localization errors (mm): 5.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Ma, M.; Feng, X.; Li, X.; Liu, F.; Guo, Y.; Chen, D. Skeleton-Based Human Pose Recognition Using Channel State Information: A Survey. Sensors 2022, 22, 8738. https://doi.org/10.3390/s22228738
Wang Z, Ma M, Feng X, Li X, Liu F, Guo Y, Chen D. Skeleton-Based Human Pose Recognition Using Channel State Information: A Survey. Sensors. 2022; 22(22):8738. https://doi.org/10.3390/s22228738
Chicago/Turabian StyleWang, Zhengjie, Mingjing Ma, Xiaoxue Feng, Xue Li, Fei Liu, Yinjing Guo, and Da Chen. 2022. "Skeleton-Based Human Pose Recognition Using Channel State Information: A Survey" Sensors 22, no. 22: 8738. https://doi.org/10.3390/s22228738
APA StyleWang, Z., Ma, M., Feng, X., Li, X., Liu, F., Guo, Y., & Chen, D. (2022). Skeleton-Based Human Pose Recognition Using Channel State Information: A Survey. Sensors, 22(22), 8738. https://doi.org/10.3390/s22228738